风控回捞怎么做?拒绝推断到底能不能行?
早在15年前出版的信贷扫盲书《信用评分卡研究》中就已经在介绍拒绝推断了,但从笔者实际经历和同业交流中了解到,目前拒绝推断效果大都呵呵。那么拒绝推断到底靠不靠谱,能不能做,该怎么做,这是本文试图回答的问题。
目录
Part1: 为什么要做拒绝推断?
Part2: 拒绝推断怎么做?
Part3: 如何提高拒绝推断效果?
Part4: 总结
致谢
版权声明
Part1:为什么要做拒绝推断?
在评估模型性能时,往往会出现高估的情况——模型在测试(OOT)数据集上表现优越,但是实际上线后发现效果不及预期。
其中的原因固然方方面面,客群、流量、市场环境等种种因素都会影响模型的实际表现,但一个非常重要的原因在于样本偏差。
样本偏差更通俗的叫法是幸存者偏差,我们在进行统计分析时,用局部样本代替了总体样本,未考虑到局部样本本身是否有足够的代表性,进而对总体的分析出现偏差,从而得出错误的结论。(样本有偏)
在风控领域,样本偏差的问题一大核心痛点。风控建模使用的样本是有贷后表现的通过人群,而模型上线用需要应用在所有人群上。
由于通过人群与拒绝人群本身是由风控策略决定的分布完全不同的两部分人群,因此,使用通过人群建模得到的模型在拒绝人群上的表现完全无法保障,进而导致模型上线之后的实际表现远不如预期。
实际上,由于通过客群的分布是经过筛选的,经常会发现一些强变量在通过客群上效果大幅降低,而模型调优后该变量的权重下降,进而导致模型上线迭代后效果反而降低。但该变量效果下降原因只是因为通过客群已经用该变量筛选过了,实际仍然非常有效。这种情况对于很多刚从事风控建模行业不久的数据科学人员来说,如果没有比较丰富的行业经验,是经常会犯的错误。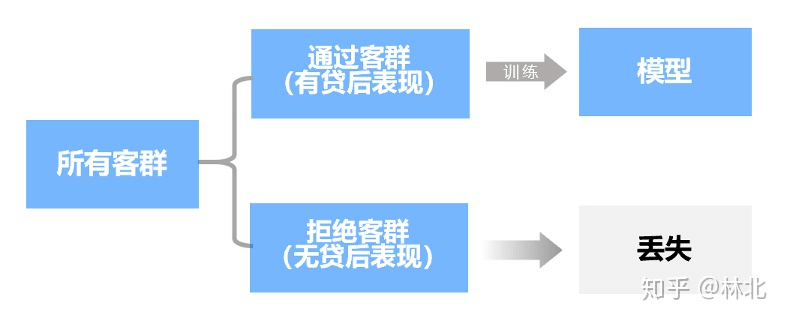
Part2: 拒绝推断怎么做?
业界在解决样本偏差上做过很多尝试,这就引出了拒绝推断(Reject Inference)的概念,拒绝推断的核心在于:
拒绝客群如果被通过,那么该客户贷后表现会如何?
逻辑上理解非常简单,通过各种手段,给拒绝客群加上贷后表现,那么自然而然的可以消除样本偏差,建立完美无偏的风控模型。那么如何才能知道拒绝客群的贷后表现呢?这里笔者归纳为三种做法:
- 获得客户在其他机构的贷后表现。
某一客户在本机构被拒绝,但申请其他机构的贷款时通过了,那么可以通过与其他机构合作/征信报告等形式,获得该客户的贷后表现。
这种做法最大的局限在于,获得客户在其他机构上的贷后表现难上加上,一是贷后表现是核心数据资产不会向外共享,二是监管也不会同意。就算能获得贷后表现,那么信贷产品的差异(利率/期数等)与标签定义也是需要解决的问题。
- 人工通过一部分本应拒绝的客户。
这种方式,在不考虑给拒绝客户放款带来的坏账情况下是最好的选择。优点是客户准确获得拒绝客群贷后表现,缺点只有一个,费钱。
不过费钱这一点可以尝试使用主动学习(Active Learning),可以在相同效果的情况下,减少需要通过的拒绝客户数量。但信贷领域贷后表现的表现期问题确实让主动学习大大降低的用武之地,着实头疼。
- 经典拒绝推断法(Inference methods)。
包括重新加权法(Reweighting)、展开法(Augmentation)、打包法(Parcelling)等。该方法基本原理为基于通过客群建模,给拒绝客群打标签,再把有标签的拒绝客群和通过客群结合建模。
显然,我们做拒绝推断的本质原因在于基于通过客群建立的模型无法准确评估拒绝客群,而该做法一定程度上是建立在通过客群建立的模型在拒绝客群上有效的假设上,因此拒绝推断法虽能带来部分增益,但效果往往因为模型在拒绝客群上效果不佳导致最终拒绝推断的效果不及预期。
Part3:如何提高拒绝推断效果?
目前的几类拒绝推断做法,要么纸上谈兵(盼着竞争对手给样本?),要么费钱(老板不同意),比较好的探索方向就剩下给拒绝客群打标签这类拒绝推断中法了,但偏偏效果又不及预期。那么如何才能做到提升拒绝推断的效果呢?
仔细考虑拒绝推断为什么效果不佳?我们把问题逐步拆解推导:
a. 原因在于给拒绝客群打的标签不够准确
b. 如果能够极大的提高给拒绝客群打标签的准确率,那么拒绝推断的效果势必会极大的提高
c. 如何提高基于通过客群建立的模型在拒绝客群上的效果?
d. 使用了贷后信息的三方数据效果远超回溯的三方数据
e. 使用客户申请时间点后N个月的三方数据信息,基于这些包含贷后信息的三方数据的通过客群建立模型,给拒绝客群打标签
f. 拒绝客群有了准确的标签,与通过客群合并,使用真实回溯的数据建模,得到完整的无偏模型
根据经验,包含了贷后信息的三方数据,相对于真实回溯的三方数据,KS通常有20个点以上的提升。如果同时使用多个包含贷后信息的三方数据进行拒绝客群打标签,会有超出预期的效果。
Part4:可以尝试下模型暴力组合
样本有偏影响的本质在于,通过客群的分布不是随机抽样,而是经过原有风控策略与模型筛选的。我们如果没有无偏样本去重新训练模型,且已知原有风控模型效果还不错,其实直接把原有风控模型与基于通过客群建的新模型直接做stacking,有时候效果能比拒绝推断更佳,笔者在测试中发现,这种做法在大多数场景下效果比拒绝推断更好。有机会的朋友可以做做尝试。
Part5:总结
样本偏差是信贷风控从业人员绕不开的难题,基于通过客群建立的模型无法适用在拒绝客群上,导致模型上线后风控超出预期,而传统拒绝推断方案在实践中效果不佳,无法解决样本偏差问题。本文从拒绝推断原理角度出发,提出拒绝推断的改进方案,欢迎各位业界朋友一起交流看法。

若有收获,就点个赞吧
0 人点赞
