Python网络爬虫总结v1.0
目录
Python网络爬虫总结v1.0 1
一、开发环境配置 2
1.请求库 2
2.解析库 2
3.数据库 3
4.存储库 3
5.Web库 3
6.APP爬取相关库 3
7.爬虫框架 4
8.部署相关库 4
二、爬虫基础 5
1.HTTP基本原理 5
2.GET和POST请求方法有如下区别 5
3.网页的组成 7
4.爬虫的基本原理 8
5.JavaScript渲染页面 8
6.Cookie的几个属性 8
7.代理的基本原理 9
三、基本库使用 9
1.Urllib 9
2.Requests 11
3.抓取猫眼电影排行案例 11
四、解析库使用 11
1.XpathXPath 11
2.Xpath规则 12
3.BeautifulSoup 12
4.pyquery 13
五、数据存储 13
六、Ajax数据爬取 13
1.什么是Ajax? 14
2.Ajax基本原理 14
3.Ajax分析方法 14
4.分析Ajax爬取今日头条街拍美图 15
七、动态渲染页面爬取 15
1.使用Selenium爬取淘宝商品 15
八、验证码的识别 15
九、代理的使用 15
十、模拟登陆 15
1.模拟登录并爬取GitHub 15
2.Cookies池的搭建 15
十一、APP的爬取 16
1.Appium爬取微信朋友圈 16
2.Appium+mitmdump爬取京东商品 16
十二、Pyspider框架使用 16
十三、Scrapy框架使用 16
1. Scrapy爬取新浪微博 16
十四、分布式爬虫 16
十五、分布式爬虫的部署 16
参考文献:Python3网络爬虫开发实战,崔庆才著
一、开发环境配置
1.请求库
- Request
requests库是一个阻塞式HTTP请求库(当我们发出一个请求后,程序会一直等待服务器响应,直到得到响应后,程序才会进行下一步处理。其实,这个过程比较耗费时间。如果程序可以在这个等待过程中做一些其他的事情,如进行请求的调度、响应的处理等,那么爬取效率一定会大大提高。)
- Selenium
自动化测试工具,驱动浏览器执行特定的动作。
- ChromeDrive
谷歌浏览器驱动的配置
- GeckoDriver
火狐浏览器驱动的配置
- PhantomJS
是一个无界面的、可脚本编程的WebKit浏览器引擎,它原生支持多种Web标准:DOM操作、CSS选择器、JSON、Canvas以及SVG。Selenium支持PhantomJS,这样在运行的时候就不会再弹出一个浏览器了。
- Aiohttp
是这样一个提供异步Web服务的库,从Python3.5版本开始,Python中加入了async/await的关键字,使得回调的写法更加直观和人性化。aiohttp的异步操作借助于async/await关键字的写法变得更加简洁,架构更加清晰。使用异步请求库进行数据抓取时,会大大提高效率。
2.解析库
- lxml
支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
- BeautifulSoup
是Python的一个HTML或XML的解析库,我们可以用它来方便地从网页中提取数据。它拥有强大的API和多样的解析方式。
- Pyquery
pyquery同样是一个强大的网页解析工具,它提供了和jQuery类似的语法来解析HTML文梢,支持css选择器。
- Tesserocr
在爬虫过程中,难免会遇到各种各样的验证码,而大多数验证码还是图形验证码,这时候我们可以直接用OCR来识别。tesserocr是Python的一个OCR识别库,但其实是对tesseract验证码层PythonAPI封装,所以它的核心是tesseract。因此,在安装tesserocr之前,我们需要先安装tesseract。
3.数据库
- Mysql
MySQL是一个轻量级的关系型数据库
- MongoDB
是由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,它的字段值可以包含其他文档、数组及文档数组,非常灵活。
- Redis
是一个基于内存的高效的非关系型数据库
4.存储库
- PyMySQ
如果想要将数据存储到MySQL中,就需要借助PyMySQL来操作
- PyMongo
如果想要和MongoDB进行交互,就需要借助于PyMongo库
- redis-py
对于Redis来说,我们要使用redis-py库来与其交互
- RedisDump
是一个用于Redis数据导人/导出的工具,是基于Ruby实现的,所以要安装RedisDump,需要先安装Ruby。
5.Web库
- Flask是一个轻量级的Web服务程序,它简单、易用、灵活,这里主要用来做一些API服务
- Tornado是一个支持异步的Web框架,通过使用非阻塞I/O流,它可以支撑成千上万的开放连接,效率非常高
6.APP爬取相关库
- Charles
是一个网络抓包工具,相比Fiddler,其功能更为强大,而且跨平台支持得更好,所以这里选用它来作为主要的移动端抓包工具
- Mitmproxy
是一个支持HTTP和HTTPS的抓包程序,类似Fiddl町、Charles的功能,只不过它通过控制台的形式操作。此外,mitmproxy还有两个关联组件,一个是mitmdump,它是mitmproxy的命令行接口,利用它可以对接Python脚本,实现监听后的处理;另一个是mitmweb,它是一个Web程序,通过它以沾楚地观察到mitmproxy捕获的请求。
- Appium
是移动端的自动化测试工具,类似于前面所说的Selenium,利用它可以驱动Android、iOS等设备完成向动化测试,比如模拟点击、滑动、输入等操作
7.爬虫框架
- Pyspider
pyspider是国人binux编写的强大的网络爬虫框架,它带有强大的WebUI、脚本编辑器、任务监控器、项目管理器以及结果处理器,同时支持多种数据库后端、多种消息队列,另外还支持JavaScript渲染页面的爬取
- Scrapy
是一个十分强大的爬虫框架,依赖的库比较多,至少需要依赖的库有Twisted14.0、lxml3.4和pyOpenSSL0.14。在不同的平台环境下,它所依赖的库也各不相同,所以在安装之前,最好确保把一些基本库安装好。
- Scrapy-Splash
是一个Scrapy中支持JavaScript渲染的工具
- Scrapy-Redis
是Scrapy的分布式扩展模块,有了它,我们就可以方便地实现Scrapy分布式爬虫的搭建
8.部署相关库
- Docker
是一种容器技术,可以将应用和环境等进行打包,形成一个独立的、类似于iOS的App形式的“应用”。这个应用可以直接被分发到任意一个支持Docker的环境中,通过简单的命令即可启动运行。Docker是一种最流行的容器化实现方案,和虚拟化技术类似,它极大地方便了应用服务的部署;又与虚拟化技术不同,它以一种更轻量的方式实现了应用服务的打包。使用Docker,可以让每个应用彼此相互隔离,在同一台机器上同时运行多个应用,不过它们彼此之间共享同一个操作系统。Docker的优势在于,它可以在更细的粒度上进行资源管理,也比虚拟化技术更加节约资源。对于爬虫来说,如果我们需要大规模部署爬虫系统的话,用Docker会大大提高效率。
- Scrapyd
是一个用于部署和运行Scrapy项目的工具,有了它,你可以将写好的Scrapy项目上传到云主机并通过API来控制它的运行。既然是Scrapy项目部署,基本上都使用Linux主机
- Scrapyd-Client
在将Scrapy代码部署到远程Scrapyd的时候,第一步就是要将代码打包为EGG文件,其次需要将EGG文件上传到远程主机。这个过程如果用程序来实现,也是完全可以的,但是我们并不需要做这些t作,因为Scrapyd-Client已经为我们实现了这些功能。
- ScrapydAPI
安装好了Scrapyd之后,我们可以直接请求它提供的API来获取当前主机的Scrapy任务运行状况。比如,某台主机的IP为192.168.l.l,则可以直接运行如下命令获取当前主机的所有Scrapy项目
- Scrapyrt
为Scrapy提供了一个调度的HTTP接口,有了它,我们就不需要再执行Scrapy命令而是通过请求一个HTTP接口来调度Scrapy任务了。Scrapyrt比Scrapyd更轻量,如果不需要分布式多任务的话,可以简单使用Scrapyrt实现远程Scrapy任务的调度。
- Gerapy
是一个Scrapy分布式管理模块
二、爬虫基础
1.HTTP基本原理
HTTP的全称是HyperTextTransferProtocol,中文名叫作超文本传输协议。HTTP协议是用于从网络传输超文本数据到本地浏览器的传送协议,它能保证高效而准确地传送超文本文档。HTTP由万维网协会(WorldWideWebConsortium)和Internet工作小组IETF(InternetEngineeringTaskForce)共同合作制定的规范,目前广泛使用的是HTTP1.1版本。
HTTPS的全称是HyperTextTransferProtocoloverSecureSocketLayer,是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,简称为HTTPS。
HTTP的安全基础是SSL,因此通过它传输的内容都是经过ssl加密的它的主要作用可以分2种,一是建立一个信息安全通道来保证数据传输的安全。二是确认网站的真实性,凡是使用了HTTPS的网站,都可以通过点击浏览器地址栏的锁头标志来查看网站认证之后的真实信息,也可以通过CA机构颁发的安全签章来查询。
而某些网站虽然使用了HTTPS协议,但还是会被浏览器提示不安全,例如我们在Chrome浏览器里面打开12306,链接为:https://www.l2306.cn/,这时浏览器就会提示“您的连接不是私密连接”这样的话,这是因为12306的CA证书是中国铁道部自行签发的,而这个证书是不被CA机构信任的,所以这里证书验证就不会通过而提示这样的话,但是实际上它的数据传输依然是经过SSL加密的。如果要爬取这样的站点,就需要设置忽略证书的选项,否则会提示SSL链接错误。
2.GET和POST请求方法有如下区别
GET请求中的参数包含在URL里面,数据可以在URL中看到,而POST请求的URL不会包含这些数据,数据都是通过表单形式传输的,会包含在请求体中。
GET请求提交的数据最多只有1024字节,而POST方式没有限制。
一般来说,登录时,需要提交用户名和密码,其中包含了敏感信息,使用GET方式请求的话,密码就会暴露在URL里面,造成密码泄露,所以这里最好以POST方式发送。上传文件时,由于文件内容比较大,也会选用POST方式。
3.网页的组成
网页可以分为三大部分一一-HTML,CSS和JavaScript。如果把网页比作一个人的话,HTML相当于骨架,JavaScript相当于肌肉,css相当于皮肤,‘三者结合起来才能形成一个完善的网页。下面我们分别来介绍一下这三部分的功能。
HTML是用来描述网页的一种语言,其全称叫作HyperTextMarkupLanguage,即超文本标记语言。
css,全称叫作CascadingStyleSheets,即层叠样式表。“层叠”是指当在HTML中引用了数个样式文件,并且样式发生冲突时,浏览器能依据层叠顺序处理。“样式”指网页中文字大小、颜色、元素间距、排列等格式。css是目前唯一的网页页面排版样式标准,有了它的帮助,页面才会变得更为美观。
JavaScript,简称JS,是一种脚本语言。HTML和css配合使用,提供给用户的只是一种静态信息,缺乏交互性。我们在网页里可能会看到一些交互和动画效果,如下载进度条、提示框、轮播图等,这通常就是JavaScript的功劳。它的出现使得用户与信息之间不只是一种浏览与显示的关系,而是实现了一种实时、动态、交互的页面功能。

4.爬虫的基本原理
我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛。把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息。可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网站的数据就可以被抓取下来了。
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序。
获取网页>提取信息>保存数据>自动化程序
5.JavaScript渲染页面
有时候,我们在用时urlib或request“抓取网页时,得到的游、代码实际和浏览器中看到的不一样。
这是一个非常常见的问题。现在网页越来越多地采用Ajax、前端模块化工具来构建,整个网页可能都是由JavaScript渲染出来的,也就是说原始的HTML代码就是一个空壳。
因此,使朋基本HTTP请求库得到的源代码可能跟浏览器中的页面源代码不太一样。对于这样的情况,我们可以分析其后台Ajax接口,也可使用Selenium、Splash这样的库来实现模拟JavaScript渲染。
6.Cookie的几个属性
Name:该Cookie的名称。一旦创建,该名称便不可更改。
Value:该Cookie的值。如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码。
Domain:可以访问该Cookie的域名。例如,如果设置为.zhihu.com,则所有以zhihu.com结尾的域名都可以访问该Cookie。
MaxAge:该Cookie失效的时间,单位为秒,也常和Expires一起使用,通过它可以计算其有效时间。MaxAge如果为正数,则该Cookie在MaxAge秒之后失效。如果为负数,则关闭浏览器时Cookie即失效,浏览器也不会以任何形式保存该Cookie。
Path:该Cookie的使用路径。如果设置为/path/,则只有路径为/path/的页面可以访问该Cookie。如果设置为人则本域名下的所有页面都可以访问该Cookie。
Size字段:此Cookie的大小。
HTTP字段:Cookie的httponly属性。若此属性为true,则只有在HTTP头中会带有此Cookie的信息,而不能通过document.cookie来访问此Cookie。
Secure:该Cookie是否仅被使用安全协议传输。安全协议有HTTPS和SSL等,在网络上传输数据之前先将数据加密。默认为false。
7.代理的基本原理
代理实际上指的就是代理服务器,英文叫作proxyserver,它的功能是代理网络用户去取得网络信息。形象地说,它是网络信息的中转站。在我们正常请求一个网站时,是发送了请求给Web服务器,Web服务器把响应传回给我们。如果设置了代理服务器,实际上就是在本机和服务器之间搭建了一个桥,此时本机不是直接向Web服务器发起请求,而是向代理服务器发出请求,请求会发送给代理服务器,然后由代理服务器再发送给Web服务器,接着由代理服务器再把Web服务器返回的响应转发给木机。这样我们同样可以正常访问网页,但这个过程中Web服务器识别出的真实IP就不再是我们本机的IP了,就成功实现了IP伪装,这就是代理的基本原理。
常见代理设置:
使用网上的免费代理:最好使用高匿代理,另外可用的代理不多,需要在使用前筛选一下可用代理,也可以进一步维护一个代理池。
使用付费代理服务:互联网上存在许多代理商,可以付费使用,质量比免费代理好很多。
ADSL拨号:拨一次号换一次IP,稳定性高,也是一种比较有效的解决方案。在后文我们会详细介绍这几种代理的使用方式。
三、基本库使用
1.Urllib
发送请求:urlopen()
importurllib.request
response=urllib.request.urlopen(‘https://www.python.org‘)
处理异常:URLError\HTTPError
fromurllibimportrequest,error
try:
response=request.urlopen(’https://cuiqingcai.com/index.htm‘)
excepterror.URLErrorase:
print(e.reason)
解析链接:urlparse()\urlunparse()\urlsplit()……等等
fromurllib.parseimporturlparse
result=urlparse(’http://www.baidu.com/index.htr比user?id=S#comment’)print(type(result),result)
分析Robots协议
2.Requests
Get、post请求
r=requests.post(“http://httpbin.org/post”,data=data)
print’(r.text)
3.抓取猫眼电影排行案例
Github代码地址:https://github.com/Python3WebSpider/MaoYan
四、解析库使用
解决正则表达式提取页面信息的不便,这种解析库已经非常多,其中比较强大的库有lxml、BeautifulSoup、pyquery等,本章就来介绍这3个解析库的用法。
1.XpathXPath
全称XMLPathLanguage,即XML路径语言,它是一门在XML文档中查找信息的语言。它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。

2.Xpath规则
3.BeautifulSoup
就是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。官方解释如下:
BeautifulSoup提供一些简单的、Python式的函数来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要#.取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。Beaut1也lSoup自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码。你不需妥考虑、编码方式,除非文档没有指定一个编码方式,这时你仅仅需妥说明一下原始编码方式就可以了。BeautifulSoup已成为和lxml、html6lib一样出色的Python解释器,为用户灵活地提供不同的解析策略或强劲的速度。

4.pyquery
如果你对Web有所涉及,如果你比较喜欢用css选择器,如果你对jQuery有所了解,那么这里有一个更适合你的解析库一-pyquery。
五、数据存储
六、Ajax数据爬取
有时候我们在用requests抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但是使用requests得到的结果并没有。这是因为rquests获取的都是原始的HTML文档,而浏览器中的页面则是经过JavaScript处理数据后生成的结果,这些数据的来源有多种,可能是通过Ajax加载的,可能是包含在HTML文档中的,也可能是经过JavaScript和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式,原始的页面最初不会包含某些数据,原始页面加载完后,会再向服务器请求某个接口获取数据,然后数据才被处理从而呈现到网页上,这其实就是发送了一个jax请求。
照Web发展的趋势来看,这种形式的页面越来越多。网页的原始HTML文档不会包含任何数据,数据都是通过Ajax统一加载后再呈现出来的,这样在Web开发上可以做到前后端分离,而且降低服务器直接渲染页面带来的压力。所以如果遇到这样的页面,直接利用requests等库来抓取原始页面,是无法获取到有效数据的,这时需要分析网页后台向接口发送的Ajax请求,如果可以用requests来模拟Ajax请求,那么就可以成功抓取了。所以,本章我们的主要目的是了解什么是Ajax以及如何去分析和抓取Ajax请求。
1.什么是Ajax?
Ajax,全称为AsynchronousJavaScriptandXML,即异步的JavaScript和XML。它不是一门编程语言,而是利用JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。(比如微博刷新)
2.Ajax基本原理
1.发送请求
这是JavaScript对Ajax最底层的实现,实际上就是新建了XMLHttpRequest对象,然后调用onreadystatechange属性设置了监昕,然后调用open()和send()方法向某个链接(也就是服务器)发送了请求。前面用Python实现请求发送之后,可以得到响应结果,但这里请求的发送变成JavaScript来完成。由于设置了监听,所以当服务器返回响应时,onreadystatechange对应的方法便会被触发,然后在这个方法里面解析响应内容即可。
2.解析内容
得到响应之后,onreadystatechange属性对应的方法便会被触发,此时利用xmlhttp的responseText属性便可取到响应内容。这类似于Python中利用requests向服务器发起请求,然后得到响应的过程。那么返回内容可能是HTML,可能是JSON,接下来只需要在方法中用JavaScript进一步处理即可。比如,如果是JSON的话,可以进行解析和转化。
3.渲染网页
JavaScr刷有改变网页内容的能力,解析完响应内容之后,就可以调用JavaScript来针对解析完的内容对网页进行下一步处理了。比如,通过document.getElementByid().innerHTML这样的操作,便可以对某个元素内的源代码进行更改,这样网页显示的内容就改变了,这样的操作也被称作DOM操作,即对Document网页文档进行操作,如更改、删除等。
3.Ajax分析方法
Ajax其实有其特殊的请求类型,它叫作xhr。
查看请求,模拟请求,重新构造爬取的URL
代码:https://github.com/Python3WebSpider/WeiboList
4.分析Ajax爬取今日头条街拍美图
https://github.com/Python3WebSpider/Jiepai
七、动态渲染页面爬取
1.使用Selenium爬取淘宝商品
代码地址:https://github.com/Python3WebSpider/TaobaoProduct。
八、验证码的识别
九、代理的使用
十、模拟登陆
1.模拟登录并爬取GitHub
代码:https://github.com/Python3WebSpider/githublogin。
2.Cookies池的搭建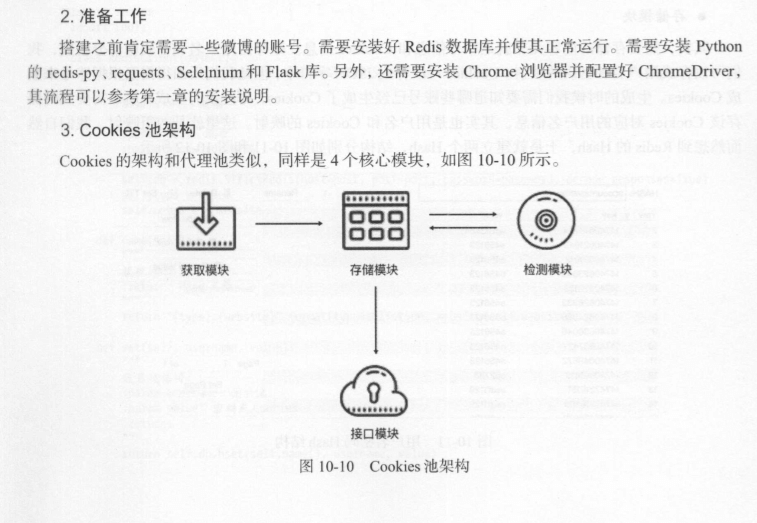
十一、APP的爬取
1.Appium爬取微信朋友圈
2.Appium+mitmdump爬取京东商品
十二、Pyspider框架使用
十三、Scrapy框架使用
- Scrapy爬取新浪微博
本节代码地址为:https://github.comPython3WebSpider/Weibo。
十四、分布式爬虫
https://github.com/Python3WebSpider/Weibo/tree/distributed
十五、分布式爬虫的部署

若有收获,就点个赞吧
0 人点赞
