xgboost对比gbdt/boosting Tree有了哪些方向上的优化?
- 显示的把树模型复杂度作为正则项加到优化目标中
- 优化目标计算中用到二阶泰勒展开代替一阶,更加准确
- 实现了分裂点寻找近似算法
- 暴力枚举
- 近似算法(分桶)
更加高效和快速
模型优化上:
- 基模型的优化:
- gbdt用的是cart回归树作为基模型,xgboost还可以用线性模型,加上天生的正则项,就是带L1和L2逻辑回归(分类)和线性回归(回归)
- 损失函数上的优化:
- gbdt对loss是泰勒一阶展开,xgboost是泰勒二阶展开
- gbdt没有在loss中带入结点个数和预测值的正则项
- 特征选择上的优化:
- 实现了一种分裂节点寻找的近似算法,用于加速和减小内存消耗,而不是gbdt的暴力搜索
- 节点分裂算法解决了缺失值方向的问题,gbdt则是沿用了cart的方法进行加权
- 正则化的优化:
- 特征采样
- 样本采样
- 基模型的优化:
工程优化上:
原始:
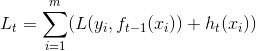
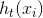 为泰勒一阶展开,
为泰勒一阶展开,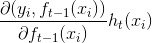
改变:
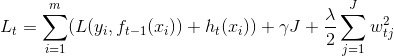
利用可导的函数逼近MAE或MAPE
暴力枚举
- 法尝试所有特征和所有分裂位置,从而求得最优分裂点。当样本太大且特征为连续值时,这种暴力做法的计算量太大
近似算法(approx)
训练时:缺失值数据会被分到左子树和右子树分别计算损失,选择较优的那一个
预测时:如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树
xgboost在计算速度上有了哪些点上提升?
特征预排序
’weight‘:代表着某个特征被选作分裂结点的次数;
- ’gain‘:使用该特征作为分类结点的信息增益;
-
XGBoost中如何对树进行剪枝?
在目标函数中增加了正则项:叶子结点树+叶子结点权重的L2模的平方
- 在结点分裂时,定义了一个阈值,如果分裂后目标函数的增益小于该阈值,则不分裂
- 当引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值(最小样本权重和),也会放弃此次分裂
XGBoost 先从顶到底建立树直到最大深度,再从底到顶反向检查是否有不满足分裂条件的结点,进行剪枝
XGBoost模型如果过拟合了怎么解决?
直接修改模型:
- 降低树的深度
- 增大叶子结点的权重
- 增大惩罚系数
- subsample的力度变大,降低异常点的影响
-
xgboost如何调参数?
先确定learningrate和estimator
- 再确定每棵树的基本信息,max_depth和 min_child_weight
- 再确定全局信息:比如最小分裂增益,子采样参数,正则参数
- 重新降低learningrate,得到最优解
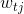 为第j个叶子结点中的最优值
为第j个叶子结点中的最优值 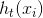 为泰勒二阶展开,
为泰勒二阶展开,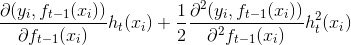
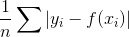 MAPE:
MAPE: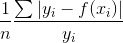

若有收获,就点个赞吧
0 人点赞
