来源:https://blog.csdn.net/baidu_39413110/article/details/106430745
1、为什么要做拒绝推断
解决建模时的样本偏差问题
在开发准入模型(A卡)的时候,我们开发模型用的是通过的有表现的样本,而我们使用模型是在进件样本上,这就导致了模型开发和使用上的样本偏差。这种样本偏差有什么影响呢,我们可以从两方面去看。
从样本维度上:
假设这样一个场景,在一万人的申请样本中,存在这么一小撮具有相同特征的人,假设有1000人,这1000人整体坏账水平非常高,假设能有50%,而之前策略精挑细选,优中选优在这1000人中选出了50人给予了放款,这50人在后期表现上也毫无意外地表现良好。此时,如果我们仅使用有放款表现的样本建模,这50人的标签就是好人,模型对这样一小撮人的判断就是优质人群。而一旦我们用这样一个模型替代了原策略,就会导致这50%坏账水平的1000人全部被放进来。如果我们能通过拒绝推断推演出在拒绝样本上,这一小撮人是非常坏的,那我们构建的模型就不会对这样一小撮人的判断产生大的偏差。
从变量维度上:
假设有一个区分度很强的变量var1,因为其效果很好,所以我们会在策略中或老模型中对它相当倚重(比如策略中会用var1拒绝很大比例的人,或者模型中var1重要性排名第一)。而如果我们在迭代新模型时,选用的是近期通过样本,那这些样本则都是经过了var1变量筛选过的样本,自然var1在这样的样本上区分度会相对弱很多,很可能导致var1变量无法入模,或者即便入模了重要性也很低。这就会导致我们新迭代的模型没有使用到var1这个最好用的变量,导致模型远未达到它应有的效果。
业务上通过率越低,这种样本偏差带来的影响越大,尤其是当风控收紧导致业务出现大规模缩量时,如果继续用通过样本来建模,那很有可能导致风控再次宽松后的风险不可控。
方便策略下探时风险评估
规则下探时:
假设现在业务的首要任务是放量,策略要做的就是对某些规则进行下探,比如之前模型通过3挡,现在想要打开通过5挡,而4-5挡的人之前都是我们拒绝的人,表现根本看不到,如何评估这两档人群的风险呢。如果能有合理的拒绝推断,就能够对拒绝人群的风险进行一个估算。
替换评分卡时:
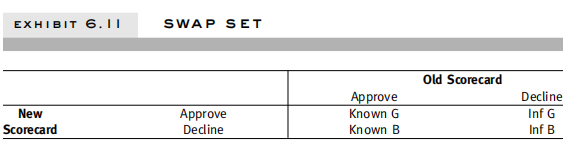
每次新评分卡迭代完成,我们都会做一个新老评分卡的swap分析(如图所示),其中老评分卡拒绝但新评分卡通过的人群,我们称之为swap-in人群(图中的Inf G人群),一旦用新卡替换老卡,这部分我们未知风险的人群就会被我们放进来,所以为了评分卡替换后风险的可估可控,我们需要拒绝推断来帮助我们评估swap-in这部分人群的风险水平。
2、拒绝推断的几种方法
开放部分测试集
最直接有效的拒绝推断办法就是开放一部分测试人群,给他们放款,直接看这部分人的表现怎样。根据需求放开的这部分人可以是所有进件人群,也可以是反欺诈规则之后的人群,还可以是模型决策时点的人群。一旦我们有了这部分测试人群的真实表现,就可以用来纠正建模样本偏差,或是用于策略风险估算。这种方式是最直接,最有效的拒绝推断方法,比任何其它理论推断都要精准,但这种方法缺点也很明显,一是成本高,因为放开策略往往意味着风险水平提高;二是定价不好定,这部分测试人群要怎么给他们定额度和费率呢,如果从节省成本的角度考虑,就给最低的额度,那这样会不会导致很对人风险暴露不出来呢。
开放测试方案建议把每天的测试准入人群缩小,但把时间线拉长,这样的样本可以平滑掉季节性振荡的影响。
借助外部数据
我们这边因拒绝而看不到表现的样本,可以借助外部数据源来反映他们的风险信息。比如中国互金协会和百行征信等等,都能够提供客户的历史逾期及多头信息,我们可以直接根据他们的数据来定义拒绝样本的好坏。
但使用外部数据同样存在很多问题,比如逾期口径不一致的问题,这个问题可以通过交叉对比外部数据标签和内部标签来解决,如果在表现样本上内外部标签的一致性足够高,那我们就可以直接使用。另一个问题就是坏容易定义但好不好区分,因为外部数据查不到并不代表这个客户每逾期,毕竟每个数据源覆盖度都有限,而且这个客户也可能是白户。
简单数据扩充
第一步:根据已知好坏的样本训练一个模型;
第二步:用这个模型给拒绝所有拒绝样本打分;
第三步:设置一个切点,对于所有拒绝样本,得分高于该切点标记为坏,反之标记为好;
第四步:把所有标记样本加入到表现样本中重新训练模型。
为了使结果更加可靠,我们可以对第3-4步进行迭代,知道模型对样本的打分基本稳定。
打包法
打包法类似于上面提到的简单数据扩充法,区别之处在于在给拒绝样本打好坏标签时,不单单使用一个切分点,而是根据模型打分,把样本进行分组,并依据每组的预期坏账水平对该组样本进行好坏标记: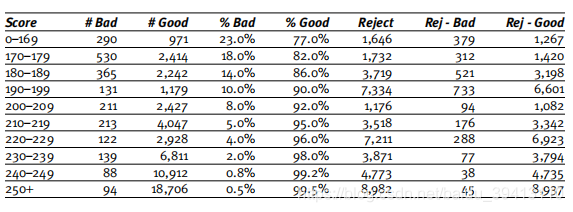
如图中所示,我们根据表现样本得分分了十档,根据每一档表现样本的坏账率,我们对组内的拒绝样本按照该组的坏账率随机打标记,比如190-199这一档,坏账是10%,拒绝样本有7334个,就可以根据比例,随机取733个标记为坏,剩下的标记为好。但根据业务经验,拒绝样本的坏账水平一般会高于通过样本,所以我们在给拒绝样本打标的时候可以适当对通过样本的坏账率乘以2-4倍。
模糊扩增法
这种方法和简单数据扩增法类似,但不同于简单数据扩增法中根据切点简单粗暴打出好坏标签,模糊扩增法对每个拒绝样本一分为二,并分别乘以P(good)和P(bad)作为权重,步骤如下:
第一步:根据表现样本训练的模型对拒绝样本进行打分;
第二步:给出每个拒绝样本的好坏概率P(good)和P(bad);
第三步:把每个拒绝样本一分为二,一个好一个坏;
第四步:对好样本乘以权重P(good),对坏样本乘以权重P(bad),当然可以根据业务经验,对拒绝样本的坏权重进行2-4倍的放大;
第五步:把拒绝好通过样本放在一起构建新模型。
聚类法
聚类法不需要借助于任何已知模型进行打分,直接把有表现的好坏样本分为两类,分别计算每一类的的中心点;对于每个拒绝样本,分别计算它到两个中心点的欧式距离,并根据距离进行归类。
3、如何验证拒绝推断的效果
坏账和分箱
拒绝推断的效果验证一般也要根据业务经验来判断,一方面是看坏账率,通过拒绝推断推测出的拒绝样本的坏账率,一般来讲应该达到通过样本的2-4倍,才是合理的;另一方面就是看每个单变量的分箱变化和IV值的变化,一般加入拒绝样本后,单变量的IV值都是提高的。
部分通过样本做验证
在执行拒绝推断过程中,我们可以把通过样本分出70%来做拒绝推断模型,剩下的30%来当做验证集(即把这30%的通过样本当做已知表现的拒绝样本,用来验证拒绝推断的准确性)。
AB测试
当然最准确的方法还是用事实来说话,所以最准确的验证方法也需要线上表现来验证。可以在业务中开一定比例的灰度,用拒绝推断的模型来做决策,并通过对比通过样本模型效果,来量化拒绝推断模型的提升。
————————————————
版权声明:本文为CSDN博主「白白的一团团」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/baidu_39413110/article/details/106430745

若有收获,就点个赞吧
0 人点赞
