信贷评分模型的评估指标常见的有P-R曲线、AUC、KS、混淆矩阵、AR、洛伦茨曲线等,各个评估指标之间都有或多或少的联系和区别,从而从不同角度对模型进行评估。本文尝试写一些各个评估指标间的联系,从而对模型评估指标有更加深入的理解。
目录
- 正负样本的选择
- 混淆矩阵与概率密度分布
- 提升图与洛伦茨曲线
- 洛伦茨曲线与KS
- KS与AUC值
- 参考资料
一、正负样本的选择
直观上,在信贷风控建模中都以好样本为正样本,以坏样本为负样本。其实正负样本的选择不同直接影响的就是混淆矩阵,在以好样本为正样本的情况下,信贷业务的一些指标如通过率与坏账率如下:
通过率,即模型判断为好样本的数量占总样本的数量。
坏账率为模型判断为好样本(P)中真正的坏样本(FP)所占的比例。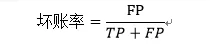
而模型的准确率Precison定义为模型判断为好样本中真正的好样本所占比例,即:
由此可见,坏账率就是1-Precison,在模型优化时设法让Precison值更高,即通过样本中的好样本占比尽可能高,这是一个很好的性质,也是将好样本作为正样本的优点。但同时其他的一些指标比如F1指标,这个时候就是无效的。
在机器学习中,往往是将少数样本定义为正样本,在信贷模型也就是将坏样本定义为正样本,表示希望模型在训练时更加关注坏样本,控制模型对坏样本的预测能力,这也更符合业务场景。
总结一下,正负样本的选择没有强制要求,根据自身需求而定,不同正负样本的选择会对指标的表现方式产生影响。
二、混淆矩阵与概率密度分布
为了便于理解,以好样本为正样本,将混淆矩阵与正负样本的概率密度函数对应到一张图上: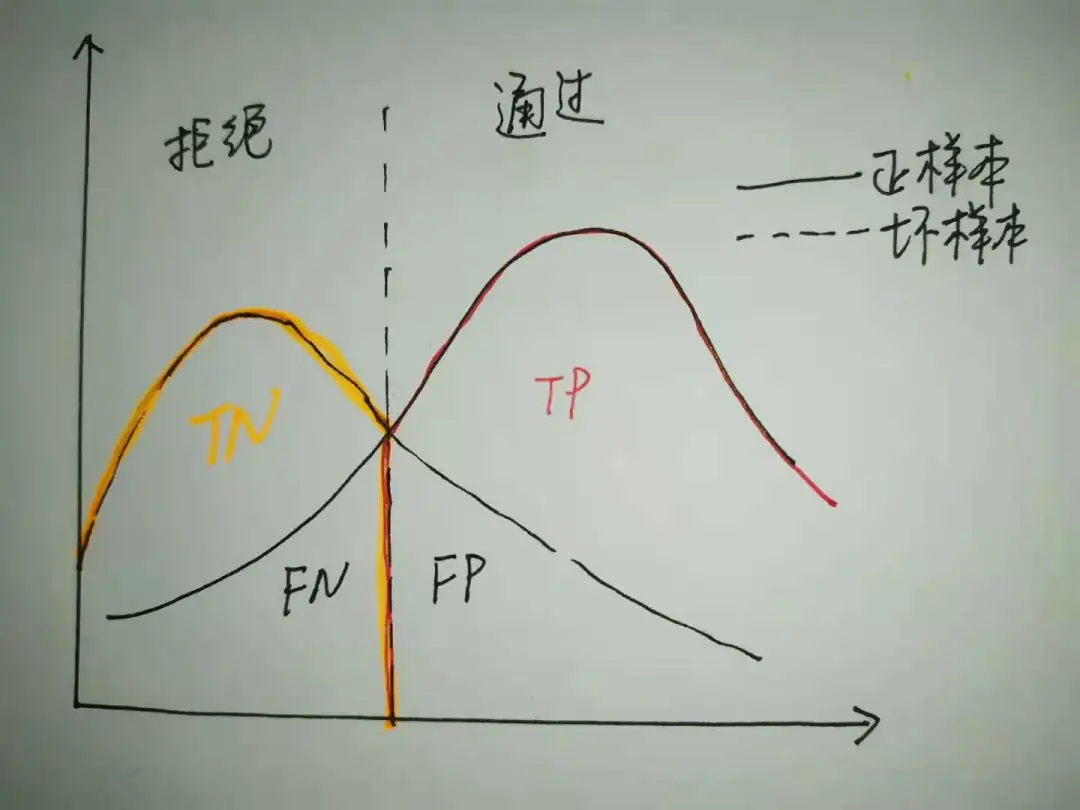
虚线左边为拒绝的样本,即经模型预测低于cutoff值的坏样本;右边为通过的样本,即经模型预测高于cutoff的好样本。FN为模型预测为坏样本但实际为正样本,即被误拒的好人;FP为模型预测为好样本但实际为坏样本,即误准入的坏人。
TPR为预测为正例且实际为正例的样本占所有正例样本的比例,即所有好样本中通过样本的占比。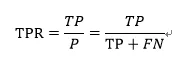
FPR为预测为正例但实际为负例(误准入)的样本占所有负例样本的比例,即所有坏样本中被误准入的样本占比。
由于KS值是取TPR和FPR之差的最大值,可以理解为两个累计分布之差。以上图中的cutoff值为例,虚线往左移则TP增加的比例要小于FP增加的比例,虚线往右移则TP减少的比例大于FP减少的比例,因此只有在虚线处TP的占比与FP的占比差值最大,也就是KS的取值。所以上图中三条线交叉的地方取到的cutoff值,正好为KS值对应的cutoff值。
三、提升图与洛伦茨曲线
提升图比较的是采用模型与不采用模型带来的改善,即采用模型后对坏样本识别能力的提升程度。计算过程如下图: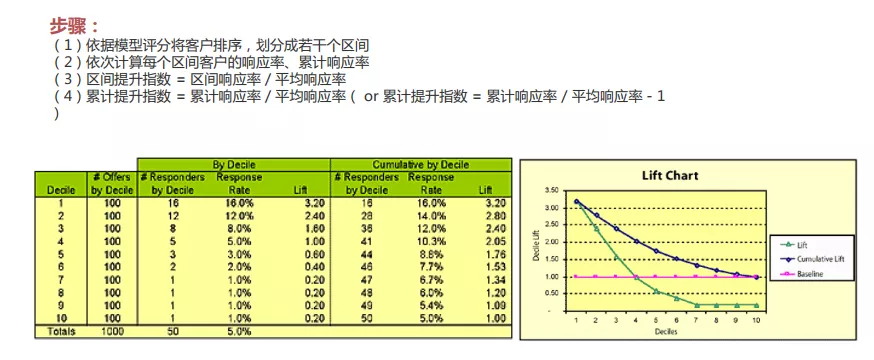
上图中的右侧有两条曲线,绿色的这根是Lift曲线,它是将每一组的坏样本占比除以整体的坏样本占比得到。这条曲线是趋于0的,且越陡说明模型的区分度越高。还有一根蓝色的曲线是累计的Lift曲线,是将累计的坏样本比例除以整体的坏样本占比所得,这条线是的临界点是1。
如果将用模型判断得到的每组累计坏样本占比与随机判断每组的累计坏样本占比进行绘图,就得到洛伦茨曲线,计算方式如下图: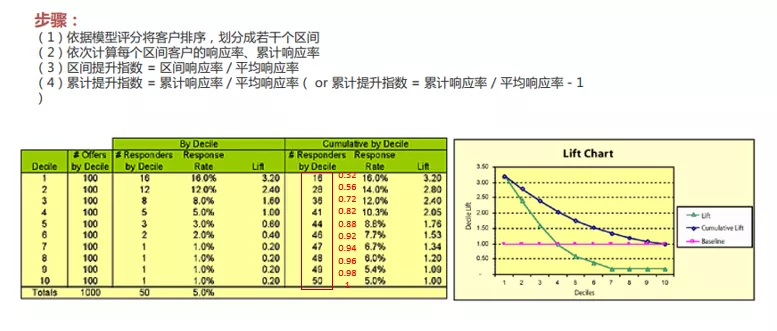
洛伦茨曲线如下: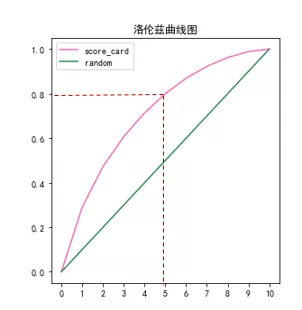
用洛伦茨曲线比较模型性能时,较好的模型的洛伦茨图应该更偏向于左上方坐标轴,这种比较模型性能的方式与ROC曲线相同。上图中洛伦茨曲线上一点的含义是:在通过率为50%的情况下,模型可以识别出80%的坏样本。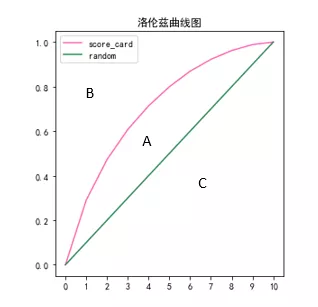
现在知道洛伦茨曲线越往左上方说明模型的性能越好,因此可以用一个指标来量化这种性质,如上图将图形分为A、B、C三块区域,理想状态下A的面积等于A+B的和,此时可以完美地识别所有坏样本。因此,将A和A+B的比值定义为基尼系数,也叫作AR值。
四、洛伦茨曲线与KS
洛伦茨曲线中在给定通过率后,只能得到对坏样本的识别能力,并没有反应对好样本的识别能力。而K-S曲线的本质是对坏样本的洛伦茨曲线和好样本的洛伦兹曲线构成的。
所以,上图中坏样本的累计占比曲线就是FPR,好样本的累计占比曲线就是TPR。上图中KS值为0.36,其含义是在通过率为62%时,模型能识别70%的逾期用户,但有34%的好样本被误判为坏样本拒绝。
KS值的高低与建模样本中的坏样本浓占比相关,并不是KS值越高风控就越好。下面是知乎”独孤qiu败”文章中的一个例子:
(1)如果建模样本中好坏样本比例good/bad=50/50,坏账率为50%;k-s值0.6指的是如果在误杀20%好用户的情况下可以识别80%的坏样本;那么使用模型之后的结果为good/bad=40/10,坏账率变为20%;这个我们做风控策略的人都知道在使用一些较好的变量的情况下是有可能的,因为毕竟做到50%的坏账已经是够烂的了。
(2)如果建模样本中好坏样本比例good/bad=80/20,坏账率为20%;k-s值0.6指的是如果在误杀20%好用户的情况下可以识别80%的坏样本;那么使用模型之后的结果为good/bad=64/4,坏账率变为5.88%,其实我们知道这个一个模型是很难做到。
五、KS与AUC值
这一部分直接搬运求是汪的文章了,风控模型—区分度评估指标(KS)深入理解应用。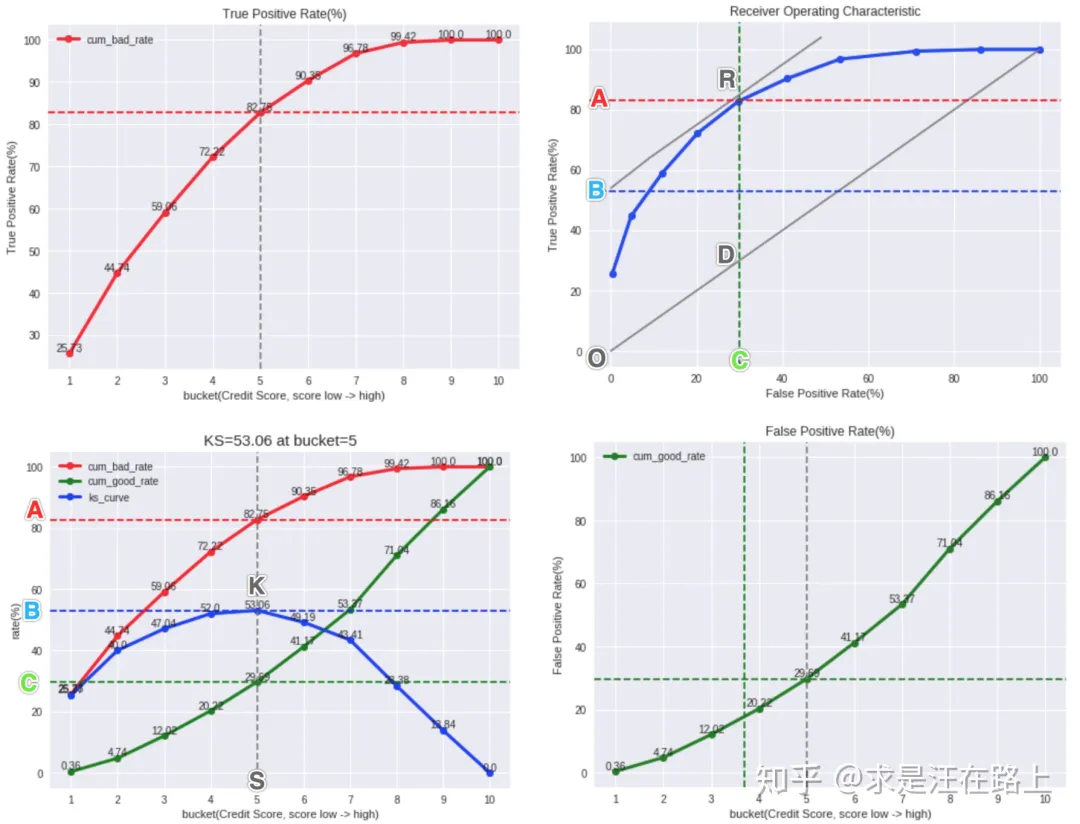
因为KS = |TPR - FPR|,如果添加辅助线TPR = FPR + KS,那么这条直线的截距就是KS值。当与ROC曲线相切时,截距最大,也就对应max_ks。
在理解KS和ROC曲线的关系后,我们也就更容易理解——为什么通常认为KS在高于75%时就不可靠?我们可以想象,如果KS达到80%以上,此时ROC曲线就会变得很畸形,如下图: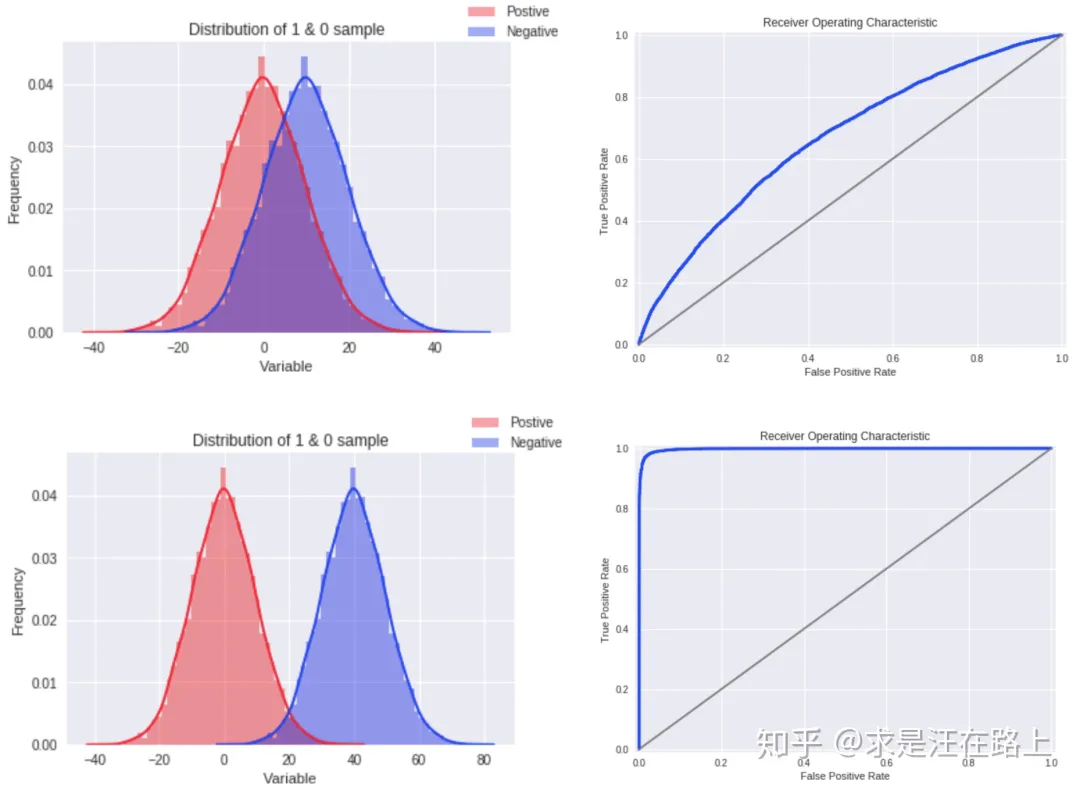
六、参考资料
1.《Python金融大数据风控建模实战》

若有收获,就点个赞吧
0 人点赞
