来源:https://www.modb.pro/db/100995
业务背景
**
Hubble(哈勃,其含义是数据如浩瀚宇宙之大,Hubble 如太空望远镜,能窥见璀璨的星辰,发现数据的真正价值)平台定位为微博广告智能全景监控、数据透视和商业洞察。
计算广告系统是集智能流量分发、投放、结算、CTR 预估、客户关系管理等为一体的大型互联网业务系统。随着微博业务的快速增长,广告系统复杂度越来越高,成千上万的模块需要不停地进行计算和通信,如何保证这么复杂的系统正常健康运行是一个巨大的挑战。
微博广告 Hubble 平台每日处理 TB 级别的监控数据和万级别的报警规则,Hubble 平台利用机器学习技术进行趋势预测和报警阈值的智能调整,保证商业产品上千台服务器和数百个系统及服务的正常运行。
下面我将详细介绍一下微博商业广告 Hubble 系统的设计原理及在智能全景监控实践中的一些思考。
**
核心问题
**
设计系统架构之前,应该首先从业务和系统等角度深度挖掘架构要解决的核心问题,对于监控平台而言,可以从平台化视角、业务视角及系统架构视角三个层面解析核心问题。
从平台化视角考虑,监控报警平台要解决的问题是
- 是否能指导 RD 快速定位问题?
- 是否为业务发展的预估提供参考?
从业务视角考虑,监控和报警平台所要解决的核心问题主要有以下几个方面
- 监控指标:精准性和覆盖率(Accuracy and Coverage rate)
- 报警:实效性和准确性(real-time performance and Accuracy)
- 故障诊断(fault diagnosis)
- 自动处理(Automatic processing)
从系统架构及设计视角考虑,监控报警平台要能解决:
- 大数据分析处理能力,包括数据采集、ETL和数据抽象分析
- 数据分析处理实时性
- 大规模监控指标等时序数据存储、报警规则存储及报警触发
- 高可用性
- 数据聚合能力
简单的讲,Hubble 全景监控的核心功能包括提供基础监控、报警、预警服务,如图1所示。

图1 Hubble全景监控服务核心功能
**
整体架构
**
Hubble 平台的整体架构如图2所示。
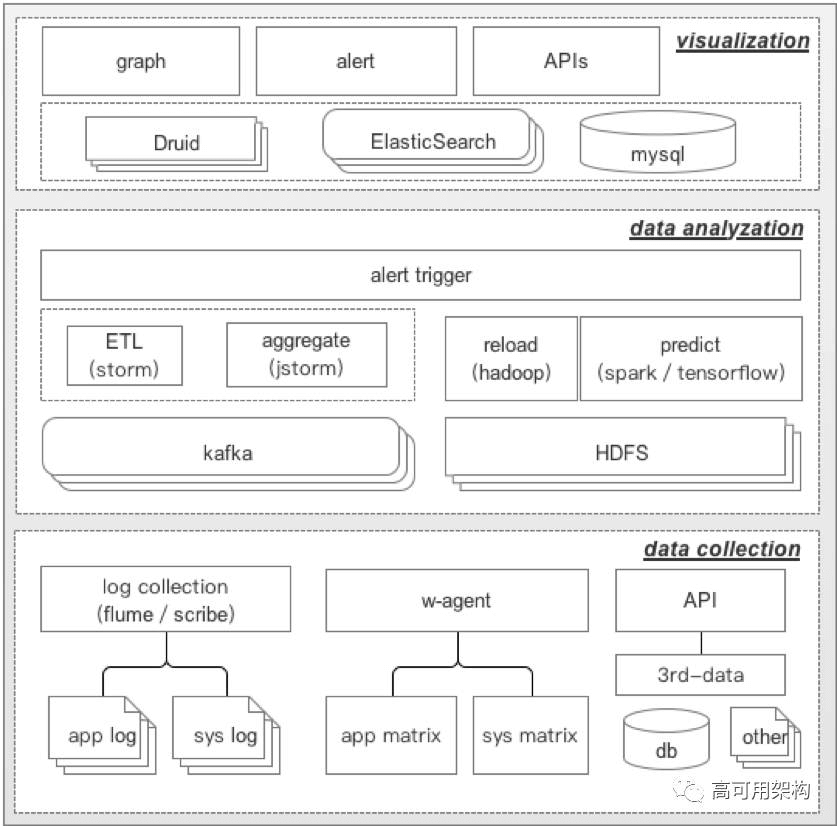
图2 Hubble平台整体架构图
如图2,Hubble 整体设计包含三个层次
数据采集层(data collection layer)
数据采集层负责将系统日志、系统指标、业务日志、业务指标等数据进行实时采集。对于日志数据,支持 flume、scribe 等日志搜集工具,也支持 filebeat、metricbeat 等文件及指标搜集工具。
对于系统及业务指标,可以通过我们开发的 w-agent 客户端进行数据搜集,w-agent 是 Hubble 的轻量级、低资源消耗的数据采集工具,它作为微博广告标准基础工具集里的一部分,在服务器初始化时进行安装配置,通过 zookeeper 进行配置管理,支持远程更新数据采集配置和配置变更实时生效。同时,数据采集层支持通过 API 的方式直接提交数据,方便数据个性化定制以适应不同的业务需求。
数据分析层(data analyzation layer)
数据分析层负责将采集到的数据进行 ETL、预处理、分析和聚合。为了提高可用性,采集到的数据同时将写入 HDFS 进行持久化,数据分析层可以根据需要,从 HDFS 中 reload 并重新计算。另外,离线部分的监控预估模块会定时进行模型训练,并将训练后的模型存储在 HDFS 中。alert trigger 模块负责根据报警规则进行报警触发监测。
_
可视化层(visualization layer)
_
经过分析处理的数据写入到可视化层的存储系统中(Druid、ElasticSearch 和 MySQL),可视化层负责根据业务方需求,进行监控图表的展示、配置和管理,以及报警信息及规则的管理。另外,可视化层提供 APIs,允许第三方通过 API 的方式获取聚合分析后的数据以及对报警的管理。
三层各个模块相互协作,完成从数据搜集到可视化整个流程。
**
核心功能
**
监控指标
**
经常听到同学说系统处理百万级别的监控指标,以此来形容监控平台的处理能力,当然,这个数据在一定程度上可以反映监控平台的复杂度和能力,但是我们业务真的需要这么庞大的监控指标么?实际上,很大一部分的监控指标是毫无价值或多余的,这些指标要么根本无法真实反应系统或者业务的状态,要么可以直接被其他指标取代,要么是需要结合更多的信息来分析。
抽象出来,监控指标应该有以下几个分类。
**
机器(系统)指标
**
这部分指标,从机器资源角度,尤其是从硬件瓶颈相关的早期迹象并捕获硬件故障信号进行监控。抽象概括起来包括机器 CPU、Memory、Disk IO Space、Net IO。
系统指标监测的目的是:
- 发现机器故障
- 限流与扩容
应用指标
应用指标分为基础应用指标和非基础应用指标。基础应用指标是指能被标准化和常见应用的监控,比如 Nginx Apache 服务器的请求状态和 access 日志及端口、MySQL 数据库端口、Hadoop 集群运行状态等。非基础应用指标,指针对基础应用指标以外的应用指标,比如某个服务的端口号指标、进程个数等。另外,对于应用的日志抽取出来的指标,也可以归类于非基础应用指标。
业务指标
业务指标关注具体业务、产品的指标,如日收入走势、订单数、广告计划数等业务层面的。
**
智能化全景监控实践
**
基础监控
基础监控要求实时反应真实的指标波动情况,其中关键技术之一是对时序数据进行聚合,其聚合的粒度根据业务不同而有一定差异,当然也会因指标及数据处理量等因素制约。目前 Twitter、Facebook 等国外公司一般做的 30 秒甚至分钟级别聚合,大部分公司做到 10 秒级聚合已经满足业务需求。微博广告监控根据业务需求,对部分指标聚合粒度为 1 秒级。
基础监控底层使用 D+(Data Plus)平台提供实时的数据服务,其中 D+ 平台是微博广告商业数据基础设施,负责数据搜集、存储、监测、聚合及管理,提供高可用的实时流和离线数据服务,在 D+ 上可以对不同数据源及实时数据与离线数据的关联,关于 D+ 技术架构细节,后续文章会进一步分享。
D+ 的整体架构如图3所示。
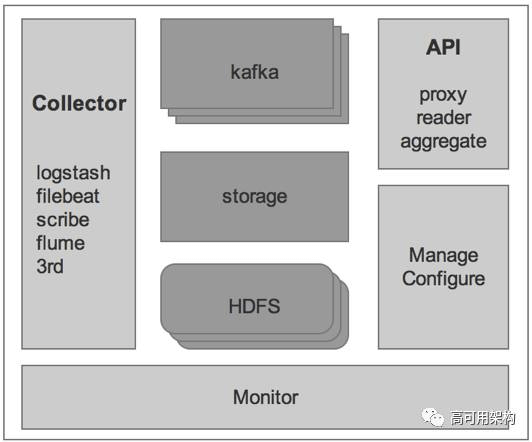
图3 D+系统架构图
基础指标数据、日志数据会从 D+ 流出到 ETL 部分进行数据处理,然后输入到 Druid 提供上层 Graph 展示,同时输出一部分数据(日志)进入 ElasticSearch,以便后续查询,D+ 位于 Hubble 整体架构的 data collection layer 和 data analyzation layer,具体可结合参考图2。
趋势预测
目前很多企业都在尝试通过趋势预测的方式,提前预测系统或者业务的未来发展,以期望未雨绸缪,业内普遍的做法是通过统计学的方法,如 Holt Winter,ARIMA,3Sigma 等。
此类方法的特点是简单,能结合部分历史数据进行趋势预测,然而也有很多不足,如 ARIMA 算法的一个技术难点就是时间序列的平稳化,平稳化的时间序列对于预测结果的好坏起着至关重要的作用。另一个问题是滑动平均操作带来的结果如波动锯齿明显,容易造成误报干扰的化,则加大监控监测周期。
微博广告团队率先尝试通过机器学习的方法来预测系统指标的变化趋势,取得了一定的效果,目前已经应用于广告曝光量、互动量的趋势预测。
_
趋势预测的架构图4如下:
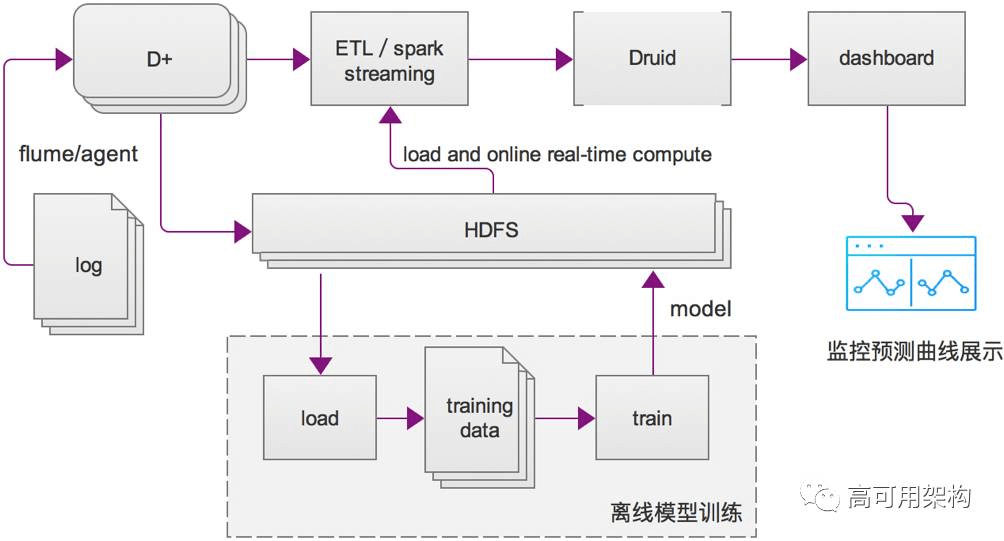
图4 基于机器学习的趋势预测架构图
主要分两部分:离线模型训练和在线计算。离线部分的数据来源是 HDFS 存储的历史指标数据,输出为模型;在线部分根据模型进行计算后导入到 Druid 进行存储和部分聚合,通过 dashboard 可以实时展示。
由于 LSTM(长短时记忆网络,RNN 变体)能很好抓住时间序列上下文可能存在的联系的特性,因此模型训练方面,我们选择了 LSTM 模型,Python 中有不少包可以直接调用来构建 LSTM 模型,比如 Keras,Tensorflow,Theano 等,我们选用 Keras 作为本文模型定义与算法实现的机器学习框架,选择 backend 为 TensorFlow,同时使用均方误差(mean squared error)作为误差的计算方式,并采用 RMSprop 算法作为权重参数的迭代更新方案。
图5展示了微博广告某产品曝光量(pv)趋势预测效果图。

图5 趋势预测曲线效果图
注:红色为训练数据;蓝色为实际值;绿色为测试输出
图6展示了微博某广告产品曝光量预测值与实际值偏差的占比分布。
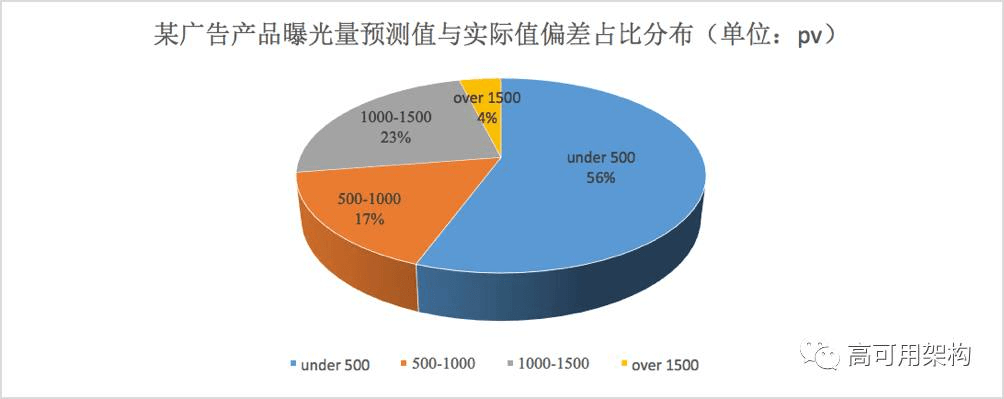
图6 趋势预测效果图
可以看到,对于 pv 预测值与实际值小于 1000 的大概占比为 73%,小于 1500pv 的占比约为 96%,按照 1000 次曝光(pv量)转化为广告计量单位为 1CPM,1.5CPM 内的误差占比 96%。
然而,基于机器学习的趋势预测目前还不能很好支持对精度要求非常高的指标,如按点击收费的广告互动数指标。
动态阈值
系统报警往往结合监控来做,是指对于某个指标触发某一个设定阈值后向相关人员发送消息提醒。目前大部分的做法是固定阈值,这个阈值是根据经验设定,其优点是简单直接、操控性强,其缺点是经验值不准,设定的 GAP 太小,报警会增加,导致误报率增加,GAP 设置过大,又会导致漏报。另外,很多数据指标的波动成周期性变化,通过经验或者人工很难设定一个合适的 GAP。
对此,我们在趋势预测的基础上增加动态阈值,比如报警条件为趋势预测曲线上下10%,这个百分比可以根据业务进行调整。
服务全景图——两个维度
假设对监控平台的要求是只允许一到两个视图,来清楚的展现服务监控状态,把所有的需求和指标进行优先级排序,可以抽取出两个关键维度,即机器维度和服务维度。
机器维度
这个视图下,我们的核心是要清楚确定所有机器的基本状态,可以简化为:健康、亚健康和病态三种。健康的状态表示,机器资源使用(cpu、memory、netio、band、load 等)一切正常,可能未来一段时间(如 7 天)也会正常,机器使用者可以完全不用担心这部分机器;亚健康状态表示,机器资源存在一定风险,如高峰期网络 IO 太高,但仍然未达到影响机器正常运行的程度,机器使用者需要考虑机器 IO 类型或者扩容,以便应对短期可能产生的压力;病态是指机器已经出现某个资源的消耗上限,如磁盘满,需要机器使用者立即处理。
根据这样的需求,我们需要设计的是这样一个视图,如图7所示:

图7 服务全景图:机器维度
当某个机器有异常,能展示当前机器异常级别、时间及具体异常信息。
服务维度
在这个视图下,我们关心的核心问题是,业务应用运行是否正常,整个链路是否通畅,是否有异常和告警,影响了多少节点。能够查看命名空间下的所有关联服务上下游整体健康状态,针对异常节点可以展示异常原因和监控报表。
同时,结合自动化平台,将服务之间的上下游关系(拓扑图)进行展示,如图8所示。
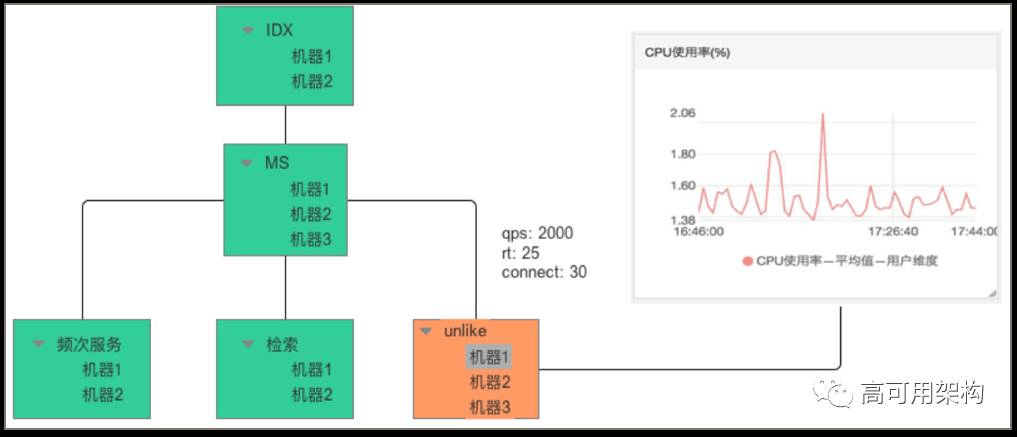
图8 服务全景图:服务维度
**
智能恢复触发器
恢复触发器的功能是在某条报警被触发时,由系统来进行一定程度的维护工作,比如降级或者迁移。其设定目标一定是要可扩展的,而且要能支持用户自定义触发器。
目前 Hubble 系统设计上只是简单支持了类似服务 restart、reload、stop 等标准触发器,还有不少的路要走。
后记
监控系统首要解决的问题是指标覆盖率,大而全,在此基础上做深耕,提高准确性,最后是精简和抽象,发现数据后面最本质的东西。微博广告基础架构团队在监控方面有一定的积累,并率先在监控中利用机器学习技术进行了一部分尝试,未来将在智能预测和服务自动化处理(降级、恢复等)方面进行更深入的尝试。
作者介绍
彭冬 Andrew(微博 @AndrewPD ,微信 justAstriver)
新浪微博商业产品部架构师,目前负责广告核心引擎基础架构、Hubble 系统、D+ 商业基础数据平台建设及相关管理工作。关注于计算广告、大数据、人工智能、高可用系统架构设计。
IOTEP - 开放创新,崇尚技术,追求极致 Innovation and Open, Technical, Extremely Perfect

若有收获,就点个赞吧
0 人点赞
