来源:https://zhuanlan.zhihu.com/p/358102773
在数据分析实战训练中,我们将会回顾数据分析常见的分析方法,同时,每种方法,都会使用sql及训练数据集进行实战演练。以练代战,通过锻炼思维,加强工程实现能力,来模拟实际项目,获得实战经验的效果。
每篇开篇我都会放上如下数据分析(核心)思维框架: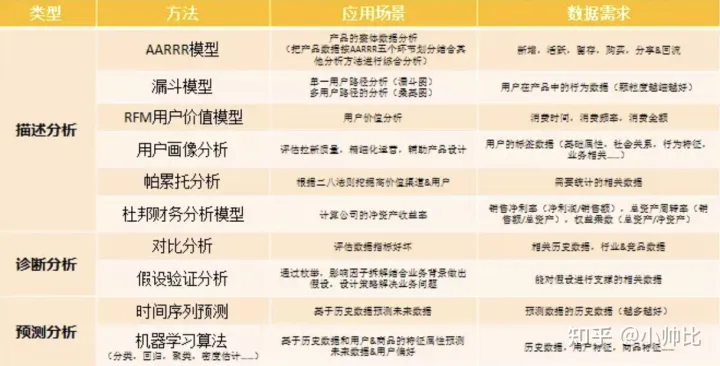

这些方法就是数据分析师手里应该掌握的武器,希望大家都能背过,倒背如流。
SQL基础参见专栏:SQL速学速练
这么干货的文章,不点点赞和收藏实在太对比起作者了。
本次将介绍如何对用户行为进行分析
用户行为分析可以按如何框架,以时间维度进行横向分析,按不同颗粒度,进行纵向分析。同时还可以结合用户画像、时间、不同颗粒度,进行更精细的交叉分析。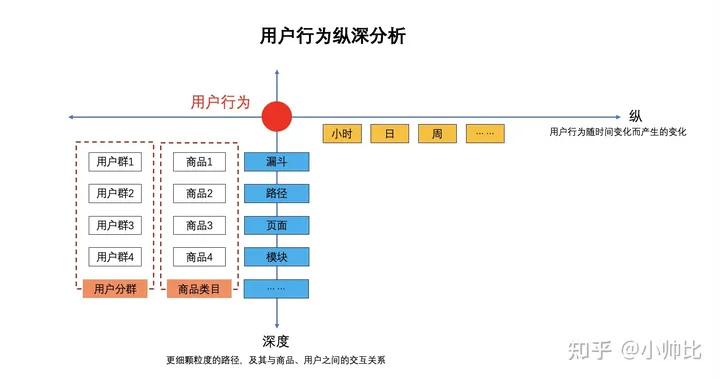
一、数据集介绍
淘宝用户行为数据集:数据集-阿里云天池
英国电商数据集:https://www.kaggle.com/carrie1/ecommerce-data
数据集中有两张表,分别为:用户行为数据集、商品数据集。本次分析我们只用到了用户行为数据,感兴趣的同学可以都下载下来,自己把玩把玩。
数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括四种:点击商品详情页、购买商品、将商品放入购物车、收藏商品)。数据集的每一行表示一条用户行为。
用户行为数据集字段详细描述:
| 字段 | 字段说明 | 数据类型 |
|---|---|---|
| userid | 用户ID | int |
| itemid | 商品ID | int |
| categoryid | 商品类目ID | int |
| behavior | 行为类型 | string: pv、buy、cart、fav |
| timestamps | 时间戳 | 时间错 |
行为描述说明:
- pv:商品详情页点击
- buy:商品购买
- cart:将商品加入购物车
- fav:收藏商品
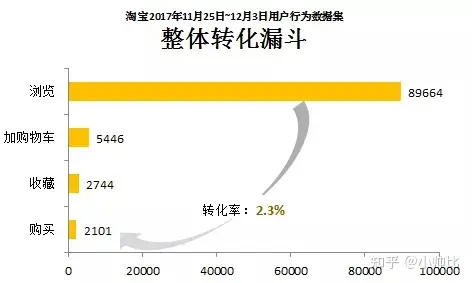
二、用户漏斗分析
根据业务理解,淘宝电商的漏斗为:浏览 -> 加购物车-> 收藏 -> 购买
接下来我们使用sql对数据集进行一系列操作,来得到我们想要的数据漏斗
-- 建一个视图-- 将行为都变成列,以便后续操作creat view action asselect userid,itemid,categoryid,case when bahavior=pv then 1 else 0 end as pv,case when bahavior=buy then 1 else 0 end as buy,case when bahavior=cart then 1 else 0 end as cart,case when bahavior=fav then 1 else 0 end as fav,timestampsfrom user_table;-- 计算整体转化率select from_unixtime(unix_timestamp(timestamps),'yyyymmdd') as imp_date,sum(pv) as pv,sum(buy) as buy,sum(cart) as cart,sum(fav) as favfrom actiongroup by from_unixtime(unix_timestamp(timestamps),'yyyymmdd');
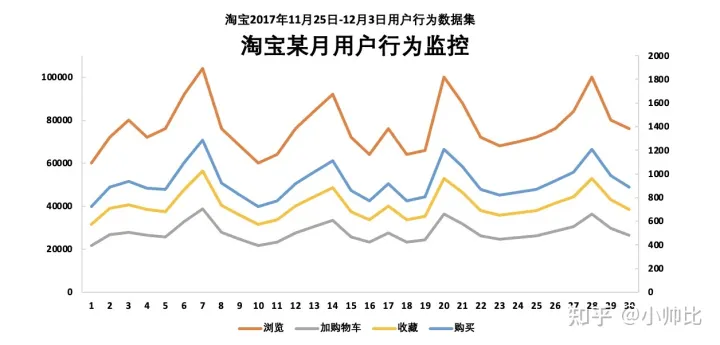
这样我们就可以得到以天为维度,每天的用户行为漏斗。我们可以用以下几种思路进行进一步分析:
- 以时间序列的方式,监控以天为维度,各行为的转化率变化情况,即时发现异常并进行根因分析
- 以针对某天或者某周,针对性的分析其总体转化率
- 聚焦某类用户或某类商品,对比其转化率与大盘用户的高低
三、用户路径分析
传统的路径分析,首先需要穷举所有重要的行为路径,根据业务逻辑进行抽象总结,并通过流程图的模式进行可视化。再使用sql计算漏斗间的漏斗关系。
本次案例中的行为只有浏览、添加购物车、收藏以及下单,逻辑较为简单,在真实的业务中,用户的关键行为可能有几十甚至上百,这时候我们就需要使用社区分析、关联规则、聚类等算法,筛选出关键用户的行为,降低归纳难度。
在这里因为我们已经将用户的行为变成了独立的列,所以计算起来很方便,只需要画出合理的逻辑分析图即可。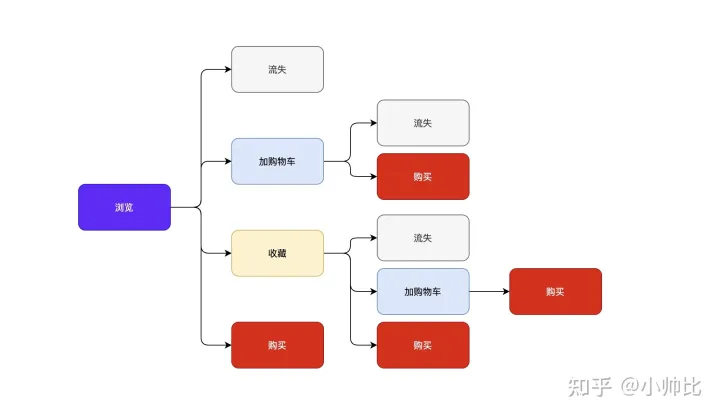
用户路径拆分逻辑图
select count(userid) as '点击-流失'from actionwhere pv=1and buy=0and cart=0and fav=0;select count(userid) as '点击-购买'from actionwhere pv=1and buy=1and cart=0and fav=0;select count(userid) as '点击-收藏'from actionwhere pv=1and buy=0and cart=0and fav=1;select count(userid) as '点击-收藏-购买'from actionwhere pv=1and buy=1and cart=1and fav=0;select count(userid) as '点击-收藏-购物车-购买'from actionwhere pv=1and buy=1and cart=1and fav=1;
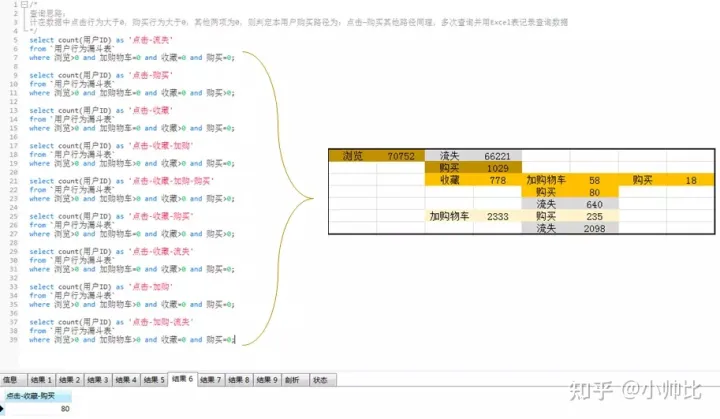
这里列出几种,剩下的大家自己补充,有问题可以在评论区留言。
在进行计算后,还可以通过桑吉图的形式,进行可视化展示。这里我们可以使用Tableau自带功能,或者结合python中的plotly可视化包,写脚本,进行更灵活的展示。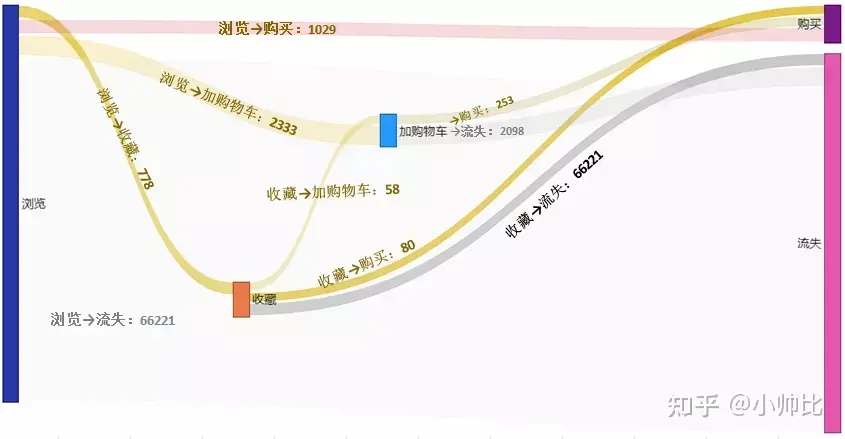
在面对复杂业务流程下的路径分析时,我们还可以通过另一种,通过将路径组合成路径串,写正则表达式进行提取的方式进行更灵活的拆分与归纳。
- 步骤1:将路径按时间拼接成路径串
- 步骤2:从路径串中拆分出特定路径组合
1、将路径按时间拼接成路径串
在这一步中,有两个需要注意的点。第一是需要明确定义出每一个用户,每一条路径的开始、结束。第二是,如何区分出同一用户的两条相邻路径。
这里没有什么约定俗成的规则,需要case by case,根据业务逻辑,同时结合实际数据表现,去制定一些规则。例如,在某一个页面退出超过10min,即认为该路径结束。一般路径id会在后端上报中记录。
原始数据:userid, sessionid, pgid, pg_stp, start_time
| userid | sessionid | pgid | pg_stp |
|---|---|---|---|
| 小王 | 1 | 首页 | 1 |
| 小王 | 1 | 搜索页 | 2 |
| 小王 | 1 | 播放页 | 3 |
期望结果:imp_date, userid, session_id, start_time, path_str
| imp_date | userid | session_id | start_time | path_str |
|---|---|---|---|---|
| 20210301 | 小王 | 1 | 10点10分 | 首页#搜索页#播放页#asc |
| 20210301 | 小王 | 2 | 15点10分 | 首页#asc |
| 20210302 | 小李 | 1 | 8点00 | 首页#搜索页#asc |
-- 在这里使用了collect_list作为核心拼接函数,它可以按顺序进行拼接-- 具体使用tutorial见参考资料select session_info,collect_list(pgid)from(select userid||session_id||start_time as session_info,pgid,pg_stpfrom (select userid,session_id,pgid,pg_stp,start_time,row_number() over(partition by userid,session_id order by pg_stp asc) as rankfrom raw_dta)order by userid,session_id,pgid,rank asc) bgroup bysession_info
2、使用正则表达式,按规则提取指定路径
比起之前案例中简单的页面逻辑组合,实际中路径的组合可能复杂的多,这时候我们可以通过正则表达式来实现。
例如:我们在电商环节中,想知道由历史记录驱动的购物行为,可以使用正则表达式这样表示
-- 根据规则,筛选出从首页直接滑动到热卖页的用户路径-- 假设首页的布局为:首页(精选页) -|- 首页(个人推荐页) -|- 首页(热卖页)-- 则经过精选页到达热卖页的路径可能为:-- 1. 精选页——>(点击)热卖页面-- 2. 精选页——> (滑动)推荐页 ——> (滑动)热卖页select case when (simple_path rlike '^(首页\\(精选\\)#)+(首页\\(热卖\\)#).*asc$'or(stay_time <3and simple_path rlike '^(首页\\(精选\\)#)+(首页\\(个人推荐\\)#)(首页频道页\\(热卖\\)#).*asc$'))then '横刷至热卖页'from table
rlike是like的升级版,能够满足我们在函数中写正则的需求。列出上述涉及到的正则符号的含义:
- ^:表明此处为字符串的起点
- \:转译符。因为很多符号在正则表达式中都有特定的功能,如果我们不想使用其功能,只想让他简简单单当个符号,那么就需要先转译一下。
- +:表示前面的组合可以出现多个
- .:任意字符或者字符串组合
- *:任意多个
- $:表明此处为字符串的结尾
参考
案例:如何用SQL分析电商用户行为数据 | 人人都是产品经理
Apache Software Foundation
Hive collect_set函数

若有收获,就点个赞吧
0 人点赞
