大家进行了线下交流。现将讨论内容整理成这篇文章。
一、数据分析转到风控难度大吗
数据分析和风控有相通的地方,比如技能(SQL/Excel)、思路方面,风控其实是特定业务场景下的数据分析。学好工具,了解业务。
二、风控策略分析师的日常
策略分析的核心是策略框架的搭建,比如授信策略、动支策略(动支:指提款,提用,动用)等,日常工作包括变量挖掘、报表分析、指标监控,此外还需要关注整体的风险与收益的平衡,相较于模型关注的东西更多一点。
三、产品设计与风险的关系
产品设计中的三个主要问题:
1.产品的风险高吗
2.产品的风险成本是多少
3.定价多少才能赚钱**
产品风险高低可以通过过往数据分析或者预估产品的预期违约概率;风险成本受还款方式、违约及回收情况影响。
等本等息产品: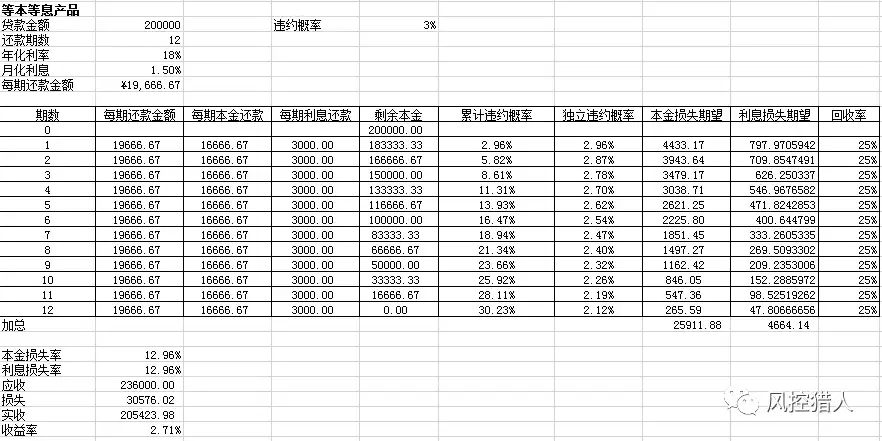
关键点在于独立违约概率/累计违约概率的设定、违约回收率两个地方需要预估。
损失周期转化:主要讲如何计算年化资金占用、年化坏账。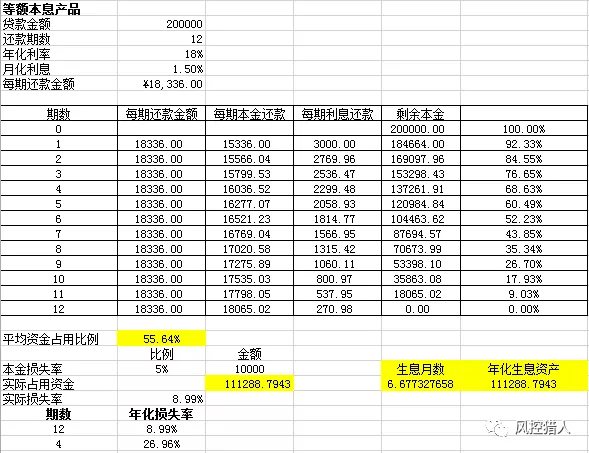
**
四、产品收益损失预测计算,预警指标的设定
收益损失率财务上有P&L测算,将各项成本进行年化后进行测算。
损失公式:EL(预期损失)=PDEADLGD
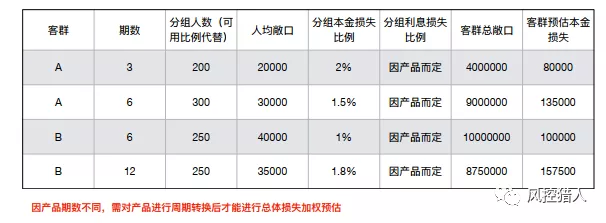
图片摘自FAL
_
五、风控成本与收益如何平衡
一个信贷金融产品的利润来源于剔除各项成本之后的净利息收入。其中资金成本、数据成本较为固定,不确定的因素为坏账成本与催收成本,这两个因素也是高度相关的。风控做得好坏与否,直接决定了产品的单体收益有多少。因此,后面需要计算的就是各分数段下的坏账以及对应的催收成本。
可以参考:互联网消费金融业务的简版盈利测算
https://zhuanlan.zhihu.com/p/384429125
六、常用的风险指标有哪些
通过率、首逾/次逾、Vintage、迁徙率、回收率、不良率、逾期率。
七、FSTPD1指标与M4+不良关系
可以通过对比已有资产的表现大致推断出什么水平下首逾指标会对应多少的坏账。
八、市面上常用的决策引擎有哪些?
国外的有FICO的Blaze、明策SparklingLogic、益博睿的SMG3、开源的有Drools,价格较贵。
国内的有同盾、蚁盾、第四范式、天阳,价格比较便宜。
采购决策引擎中常关注的几个地方:
1.性能与功能 2.部署的便捷性 3.高并发低延迟
4.ABtest的版本发布 5.灰度发布 6.价格。
九、收入与负债的推算方式
线上:社保、公积金、税务、三方、征信。
线下:工资流水、收入证明。
收入模型主要变量:社保推收入、全国城市人均收入、最大信用卡额度、消费类变量、杠杆率(征信净资产/征信信用负债)、征信抵押类净资产、房贷月还款额等。对于不同的客群,采用不同收入模型变量。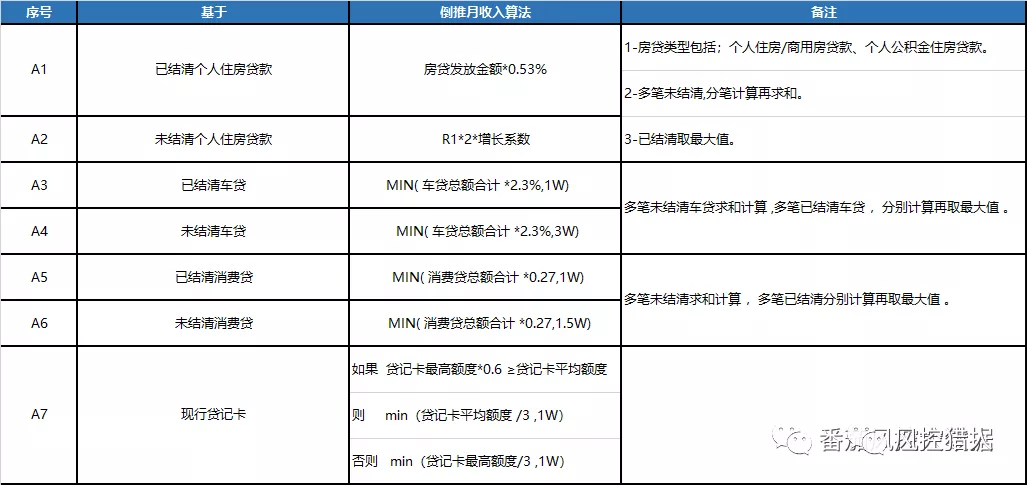
图片摘自番茄风控大数据
收入与还款能力的预测可以参考https://zhuanlan.zhihu.com/p/146461086
十、新接入三方数据如何和现有模型结合投入应用
已入模数据源实际是如何做数据源备用的
新接入三方数据看对模型的增益,此外还需要看数据的缺失情况。有些数据源缺失多但是效果好,这类可以用作规则;有些则是缺失少效果一般,这种可以作为入模的变量。还有,有一些分数对全量客户有用,比如社交分,适合入模;而有一些分数只对部分客群有识别效果,这种就用策略去框住。
新上线数据源一般会单独做一个模型,切一部分流量看表现情况之后看效果,不会一次性对全部流量使用。
还需要注意的一点是,新接三方回溯的是最新时点的数据,不是历史时点表现,会有穿越特征。
谈到的几个数据源:
1.中科金的捷益分(不知道是不是这么写)底层是同盾、冰鉴和马上的数据。
2.算话、腾讯天御、同盾生态分。
十一、模型分数cutoff在不同渠道的设定
同一套模型分针对不同渠道切割的时候,可以根据通过率或者坏账率的要求来切,如果渠道太多,可以将渠道分为几个等级,针对不同等级的渠道进行相应的切分。
十二、客户分群的常见做法
客户分群主要考虑三点:
1.分出来的客群是否有显著差异
2.分出来的每个客群量是否足够
3.分出来每个客群的数据源是否稳定
可以考虑的分群变量:渠道(比如房贷客户与工资卡客户)、是否人行户、是否有公积金和社保。也可以理解成从重要数据的缺失度来考虑分群。
客户分群有两种方法,一种是分群单独建模,还有一种是加入分群变量。
举例:某银行消费贷,反欺诈信用策略跑完,先跑人行征信评分卡,直接拒绝低分客户。然后再结合三方数据跑综合评分卡,观察分布,拒绝低分,然后再细分客群,针对细分客群挖掘新变量,做分群模型。举个例子,跑完第一个人行征信模型并cutoff后,我们引入三方数据,首先针对上班客群推测收入模型、个体户人群收入模型,然后做分别做还款能力变量、消费能力变量等。所以这里就有了模型串行后的并行——上班族、个体户模型并行(由于变量开发不一样),最后我们再引入各种新的数据源(如运营商数据评分FICO)变量,来更加提升模型效果深入细分客群,同时最后是分别的额度模型。
摘自知乎:https://zhuanlan.zhihu.com/p/369834815
十三、联邦学习
介绍了用过的联邦学习平台富数和神谱),使用体验是效果较慢,一次只能筛选1000个x变量。
关于联邦学习,上次讨论活动提及过:
市面上一共有四本书,微众两本,《联邦学习》和《联邦学习实战》;其余两本是《深入浅出联邦学习:原理与实践》、《联邦学习技术及实战》(京东数科)的。核心步骤是梯度的传递,更新梯度之后将梯度分布式发布。主要内容是同态加密以及工程上的实现,比如消息传递过程中的多方协作、通讯机制以及恶意参与问题。
目前联邦学习中的问题:
1.恶意参与,比如有参与方数据恶意造假。
2.激励机制,是指数据共享的动机。
3.通信协同,比如一台机器突然没响应了怎么办。
十四、拒贷回捞的做法
首先,主策略的风控能力决定了回捞的空间。如果主策略筛选过后的客户都无差异的坏,则无回捞价值;回捞之所以有价值,是因为拒绝的人的坏还是有排序性。
常用的一种拒贷回捞的方法:对拒量客户查三方数据,利用三方数据中互金企业有逾期情况作为Y重新训练模型,然后再和原来的评分模型作交叉矩阵。
拒贷回捞推荐两篇文章:https://www.zhihu.com/people/flash-36-76/posts
十五、ABtest在实际工作中的设计
最近模型团队新开发违约模型,为了验证新模型效果,将人群随机分配进行AB测试,实验组A使用新模型,对照组B使用旧模型。观察了一段时间的结果后,得到如下观测结果:实验组A样本量10000人,逾期量300人;对照组B样本量10000人,逾期量400人。请从假设检验的统计学方法说明在降低逾期率上新模型效果是否优于旧模型?
该问题摘自https://zhuanlan.zhihu.com/p/144924899,感兴趣的可以去深入研究一下AB测试背后的原理和操作方法。
后面还有一些问题没来得及讨论完,后续还会组织类似的交流活动。个人觉得无论是风控技能还是业务理解,再或者是行业认知,如果想要各方面获得提升的话,都需要多与业内人士交流和讨论,多去了解行业内大家都是如何在做这件事情,然后再结合自己的经验去思考和总结,这样才能真正获得成长。组织活动是一件略微耗费心力也不是我所擅长的事情,谢谢大家的参与和支持,我也会尽力将这件有意义的事情做好。

若有收获,就点个赞吧
0 人点赞
