来源:https://blog.csdn.net/baidu_39413110/article/details/117606988
1、模型监控的目的及框架结构
实际业务中,对于一个正在线上使用的模型,能够实时把控模型的稳定及效用是至关重要的,所以,我们需要一套完善且及时的模型监控系统来帮助我们全面掌握模型的动态,及时定位模型问题。为达到这个目的,我们的模型监控系统大致可以分为两大部分:前端和后端。简单来说,前端监控系统实时监控模型分布的整体稳定性,后端监控系统实时了解模型效果的稳定性。下面我们来看一下前后端监控系统具体都需要把握哪些维度的信息。
2、前端监控
进件量与模型分稳定性
一套完善的监控系统中,我们首先要把握的就是样本量是否充足,毕竟我们所有的统计指标,都需要一个较大样本的前提,否则就不具备统计意义。而在指标方面,我们首先要把握的就是整体模型分分布的稳定性,因为这和我们的业务稳定直接相关,如果模型分整体的分布有很大变动,将直接导致整个客群通过率的大幅波动,客群质量就很难得到有效、稳定的把控。所以前端监控第一幅图我们选择如下,其中柱状图表示以天为单位,当日的进件客户数,红色线表示当日模型在所有人群上打分的均值,通过观测红色线走势的稳定性,我们就能整体把控当日的模型打分是否基本稳定,而进件人数的同步展示则很方便地说明,当模型均值出现较大波动时,不一定就是模型本身出了问题,而有可能是业务大幅收量或暂停所导致的。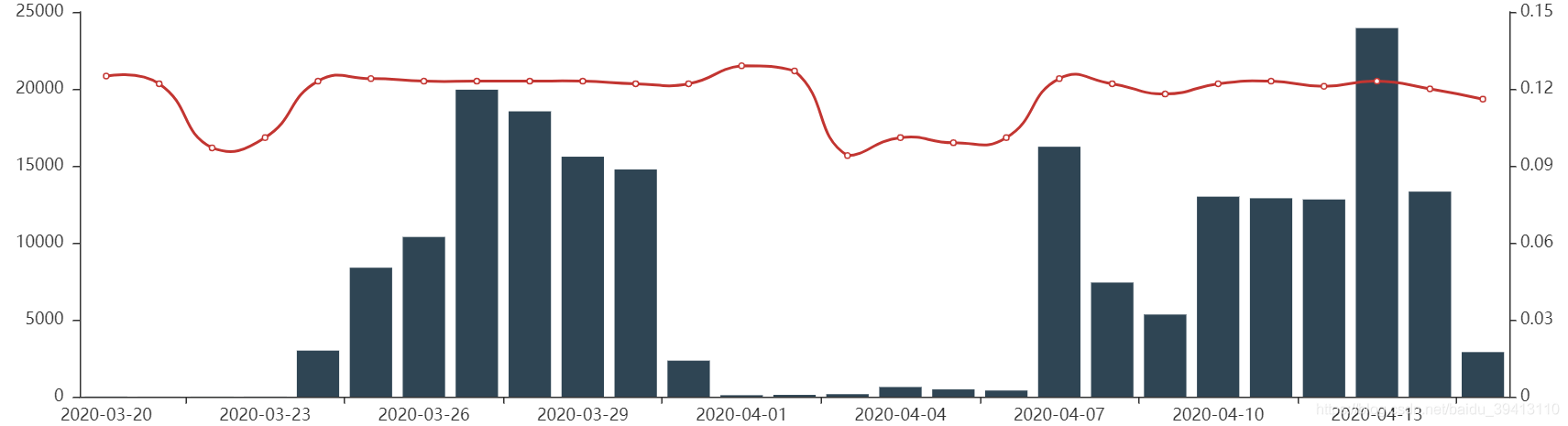
模型分分布稳定性:PSI
衡量模型打分稳定性,不仅仅可以通过均值来反映,我们有一个更专业,更常用的指标:PSI。所以,前端监控的第二幅图我们选择模型打分PSI监控图,图中出现的两条线,分别代表当日模型分与前一日模型分的PSI、当日模型分与基准日模型分的PSI。基准日可以选择模型上线的第一天,也可以选择模型训练样本的第一天,其最终的目的就是为了衡量当日模型与最开始相比,分布是否有很大差异。PSI这样一个量化指标,不仅仅可以用来展示,也可以作为稳定性的预警指标,比如在进件量充足的前提下,我们可以把时间粒度细化到小时,逐小时计算模型分与上一小时模型分的PSI,并设定0.2的阈值,一旦超出则发布预警信息,这样能让我们对模型稳定性有个更及时的把握。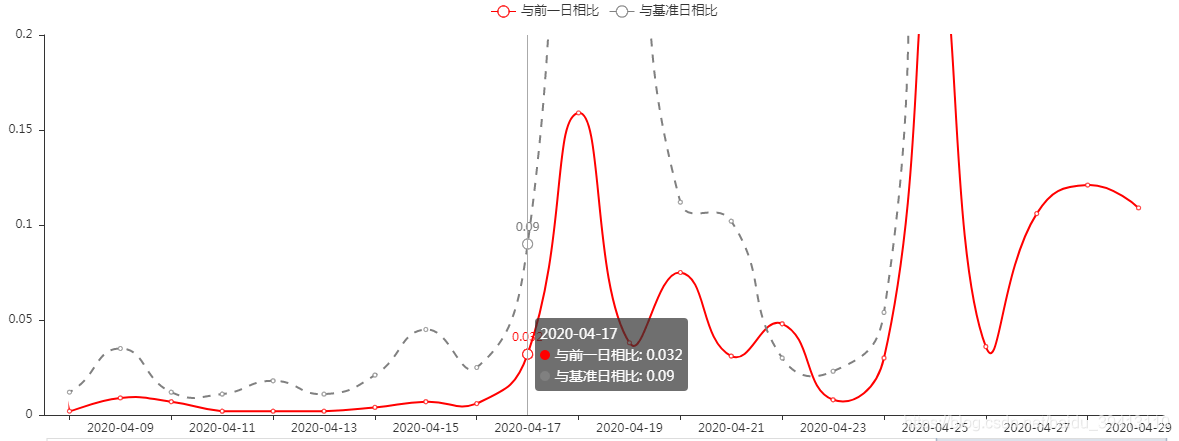
模型分分布稳定性:分bin图
PSI能够很好地衡量模型的稳定性,但正如我们在文章风控建模三:变量筛选原则中提到的,PSI的局限性在于它不能告诉我们模型分布具体是往哪个方向偏移的,以及每一个分组占比的具体变化情况。所以前端监控第三幅图,我们选择模型分分bin变化趋势图,通过这张图,我们就能清晰地看到模型每个bin相较于之前是变多了还是变少了,也就能帮我们快速定位出,模型到底是对头部优质客群筛选出问题了,还是对尾部劣质客群筛选有偏差了。这里模型分bin的切分点一般选取策略使用中制定的切分点,假如策略定在模型前三档通过,后七档拒绝,那么我们通过观测模型前三个bin的变化情况,也能对通过率的变化有一个很直观的了解。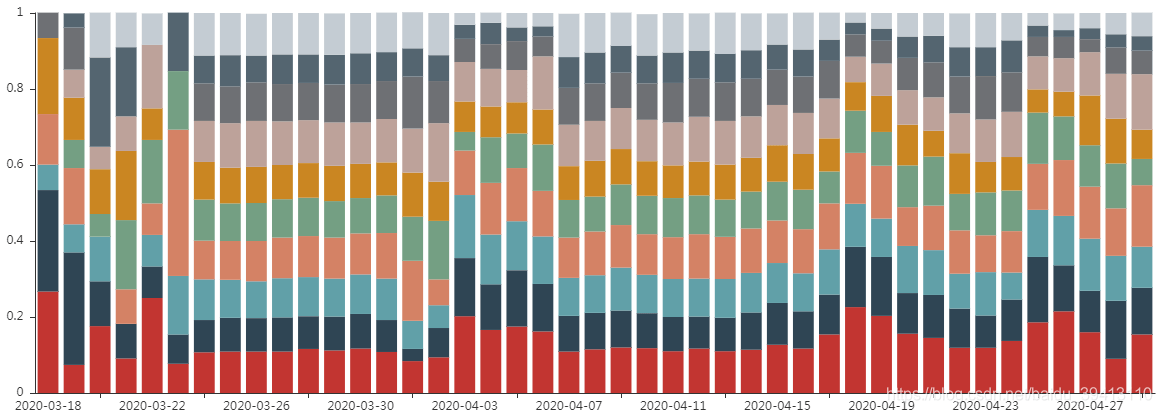
模型变量稳定性监控
我们搭建一套完整的监控体系的目的就在于要能快速发现问题并迅速定位出问题的原因。以上讲的三点模型分监控,都只是完成了第一步:发现问题。而要做到定位问题,就需要对模型的每个变量都监控起来。就前端监控来讲,变量的稳定性监控形式和模型的稳定性监控是一样的,主要包括每个变量的均值变化趋势、PSI变化趋势、分bin变化趋势的监控。稍有不同的一点就是,每个变量可以同时把其缺失率也监控起来,可以辅助我们判断到底是哪个变量,在哪里出了问题。比如如果发现某个变量缺失率突然变为100%,我们首先要排查的就是线上决策引擎取数是否出现了问题,如果取数没问题,其次再排查数据源出了什么问题。
3、后端监控
放款量与整体客群质量
模型后端监控主要监控的是模型效果,所以后端监控总是不可避免地具有延后性的,即便我们使用最短期的逾期指标,也要等到一个多月以后才能看到效果。同样,后端监控需要把握的第一点依然是数据量,其次是整体客群的质量。所以第一张后端监控图我们选择如下: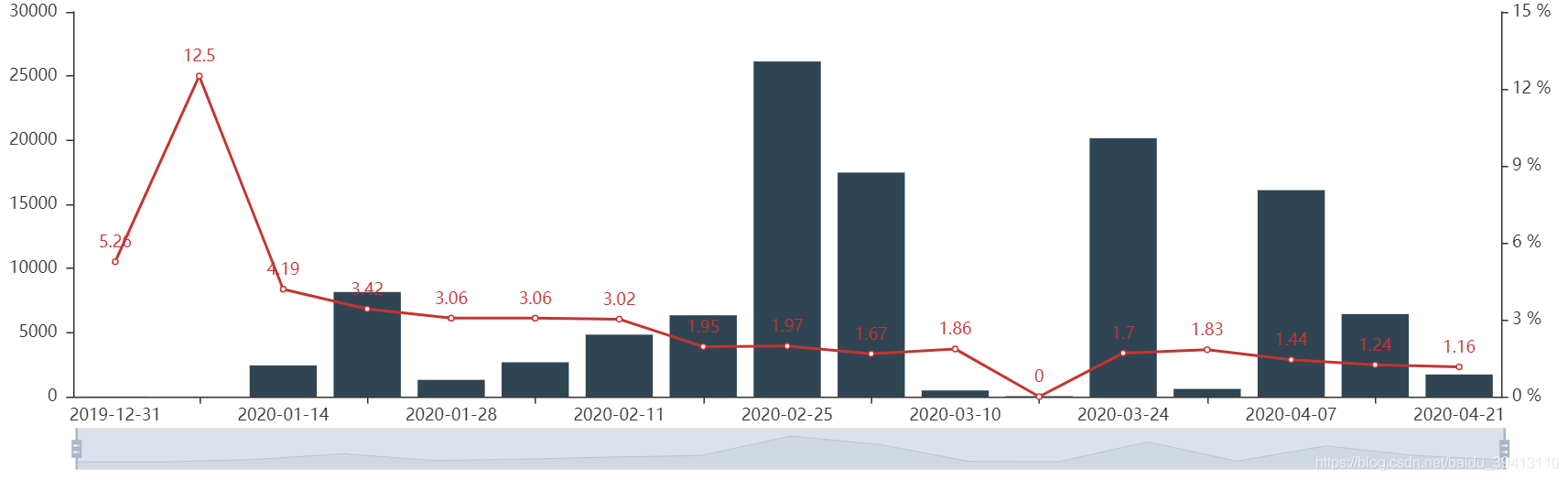
其中柱状图代表放款人群总数,线图表示当期整体客群的逾期率。首先,逾期指标我们往往选择最短期的首逾T7或首逾T15,主要是为了能及时看到最新的模型效果;其次,时间上我们往往选择以周为单位,主要是因为后端放款人群数量往往比进件人群要小一个量级,所以以周为单位才能保证足够的数据量使指标具有统计意义。
模型区分度效果监控
接下来就是模型的效果监控,模型效果最直观、最常用的指标当然是AUC和KS,所以与上图相对应,我们必然要把这两个指标监控起来,如下图: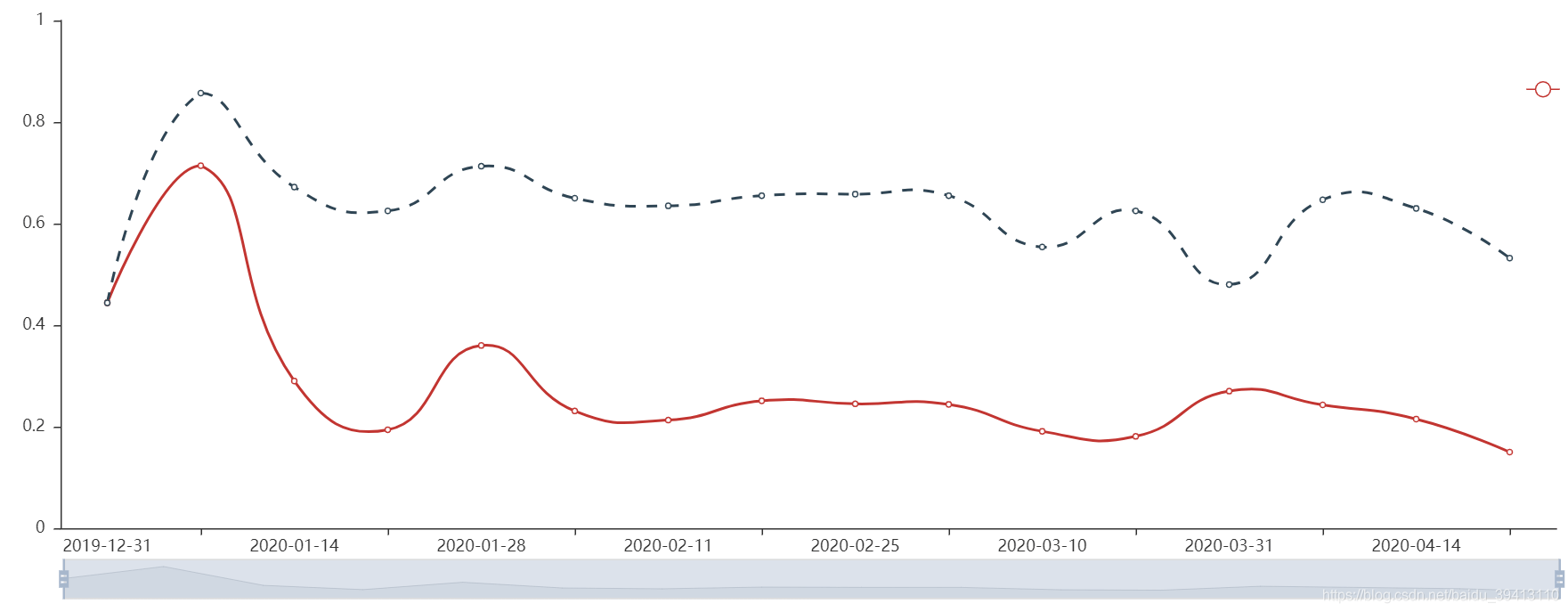
可以看到,模型的效果整体是平稳的,在19年底和20年初这段时间的剧烈波动主要是因为业务收量,基本没有放款客群导致的,而后期模型效果的缓慢下降则和后期整体客群的风险质量在一步步变好有关。客群质量不断被优化,模型区分度自然而然就会变弱。
AUC和KS只是一个评估模型好坏效果的整体性指标,只看AUC和KS是无法完整评估模型效果的,所以另一个需要把握的则是模型对具体每段客群的区分能力,这就需要我们把LIFT图也监控起来, 为了方便我们监控分析,并同时节省计算资源,我们可以选择只把最近期的几个时段的LIFT进行把控。LIFT的监控,可以帮我们快速定位出模型效果变动具体是变动在头部优质客群,还是尾部次级客群上,并具体地告诉我们,模型在哪个区间上出现了倒挂。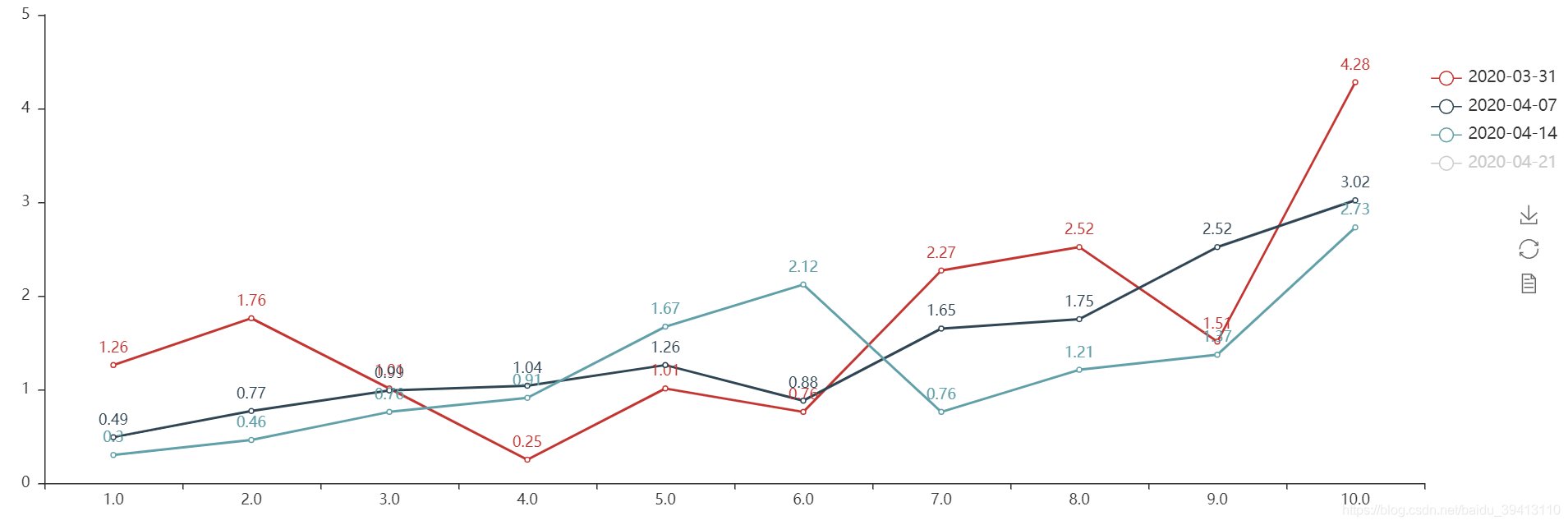
模型变量效果监控
同前端监控一样,要定位后端模型效果出现问题的原因,还是需要把后端效果监控细化到每个变量上。因为变量往往可以存在空值的情况,所以变量区分度效果的指标我们往往选取IV值,一般我们会把每个变量的IV值趋势变化图作为后端监控的一部分(如下图)。如果我们的模型是逻辑回归评分卡,那变量计算IV值时的分bin一般要和评分卡中变量的分bin保持一致。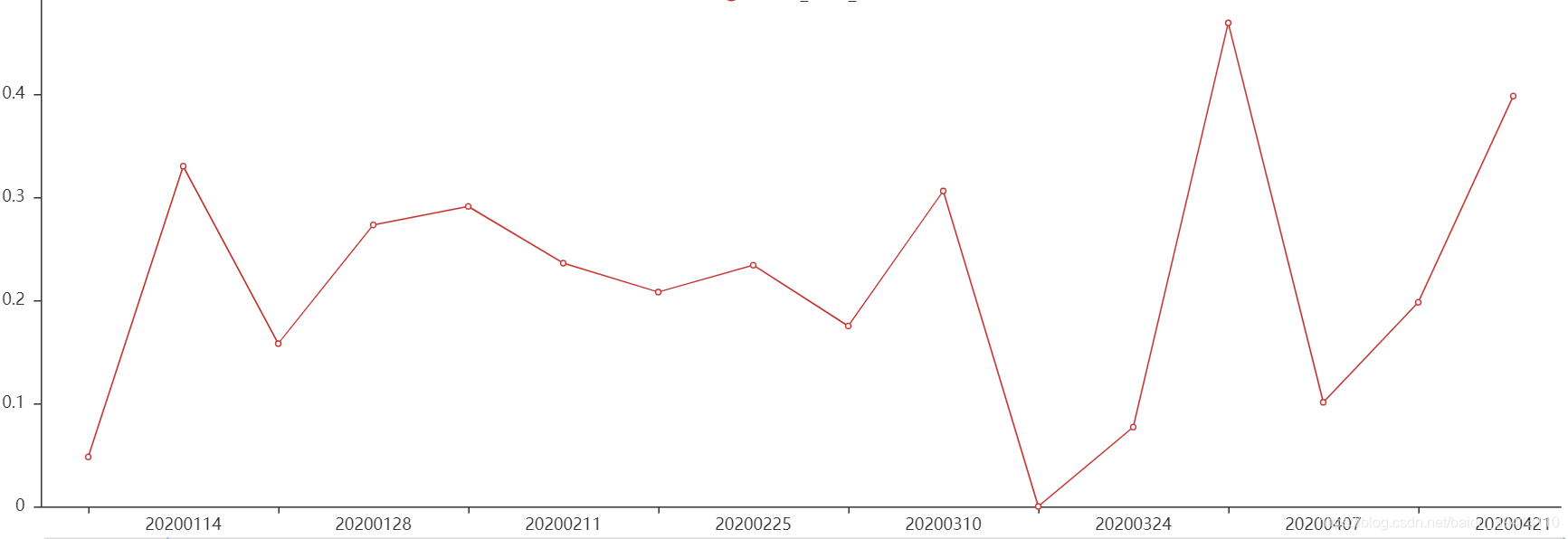
我们在文章风控建模三:变量筛选原则中提到过,仅仅看IV值不能完全把握变量区分度是否出现了问题,也有可能存在变量IV值基本不变,但区分效果却完全反掉的情况,所以,IV值往往不能单独监测,一定要配合另一张图一起使用才全面客观,即变量分区间坏账图。具体而言,通过变量分区间坏账图,我们可以把变量每个分段区间中的坏账率变化趋势监控起来。正常情况下,不同区间中的坏账率会随业务情况波动,但每条线都应该保持上下并行排列,不应该出现交错的情况,即区分度反掉的情况。当不同线直接出现交错或者间距突然变小时,都说明这个变量的区分度出现了明显的问题。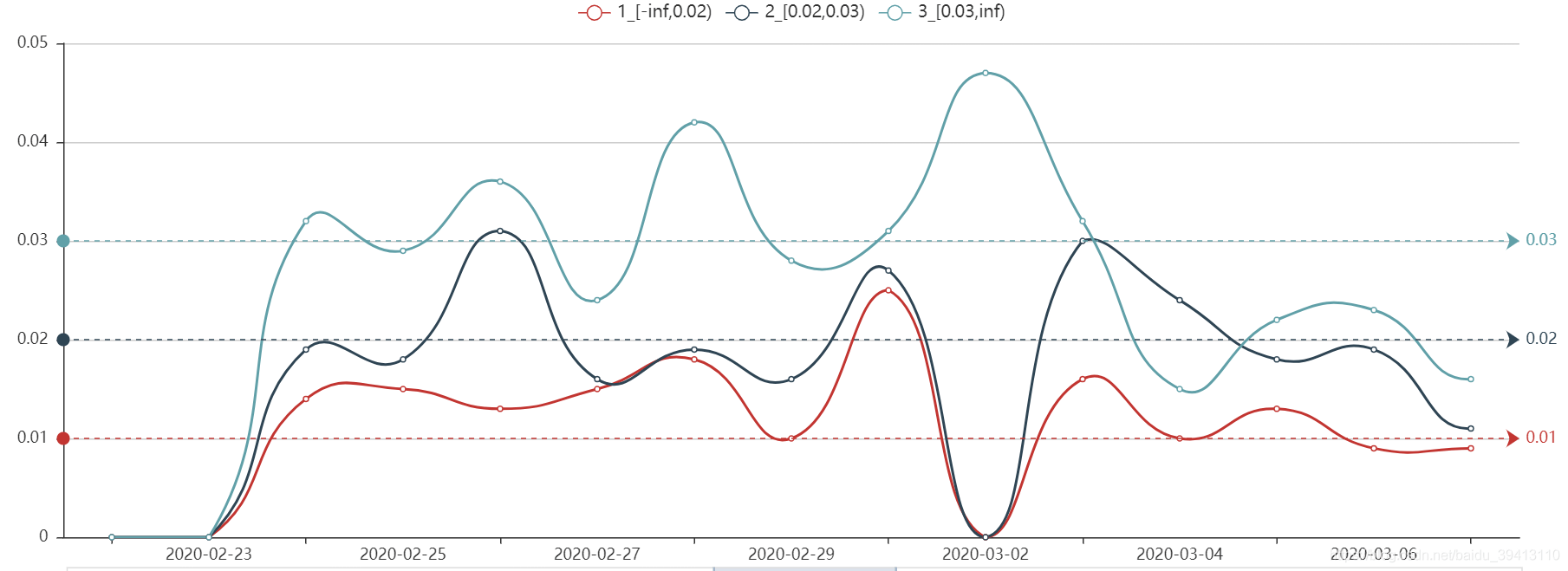
最后,变量的后端监控还可以补充一张每个分段区间内预测值(即模型分)vs坏账率的图。这张图能说明这样一个问题:如果我们发现某个变量在不同区间中是有倒挂现象的,或者坏账趋势呈现出U型或者N型,我们不着急下定论说这个变量就一定出了问题,如果我们观察到这个变量在不同区间中的预测值同样呈现出倒挂或者U型、N型的趋势,则说明这个变量在模型拟合中就是这样一种趋势,实际坏账则也应该是同样的趋势。总而言之,变量不同分段区间中预测值和真实坏账率趋势一致,才说明这个变量区分度没有问题的。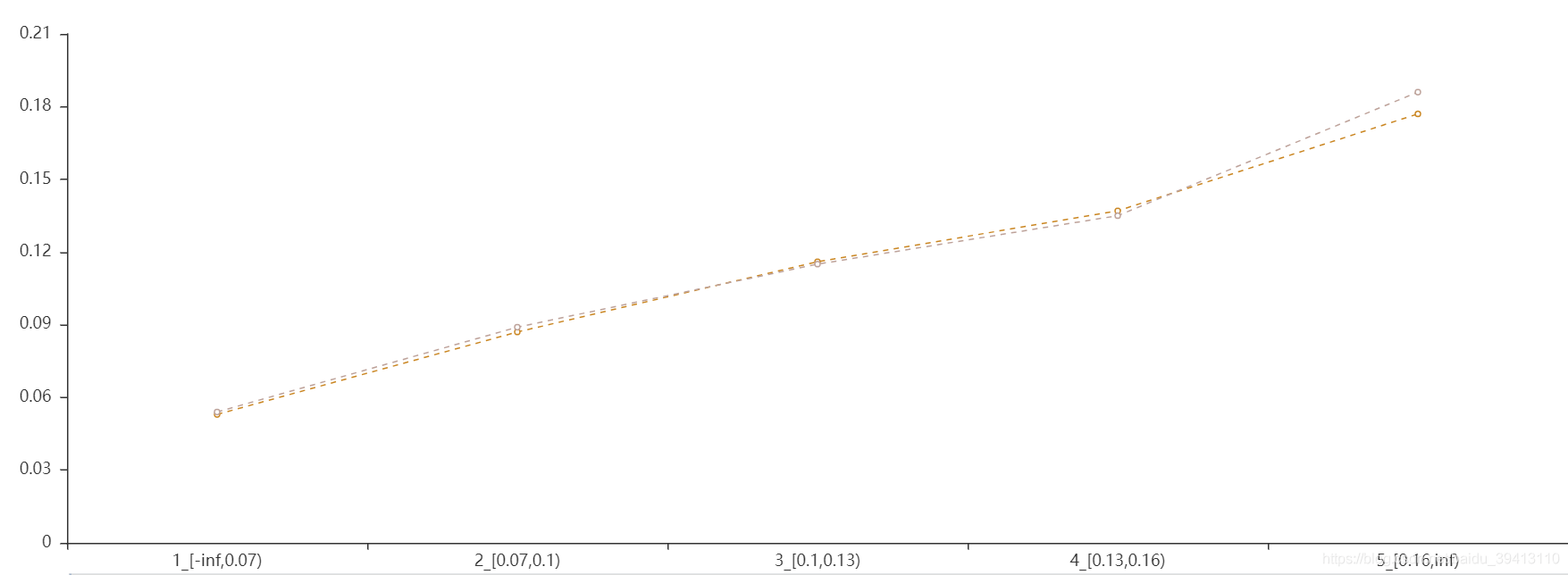
————————————————
版权声明:本文为CSDN博主「白白的一团团」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/baidu_39413110/article/details/117606988

若有收获,就点个赞吧
0 人点赞
