本文主要介绍Scrapy爬虫框架用于爬取360图片,顺带提下之前说的碰到Ajax如何处理,先提下目前的爬虫技术如下图。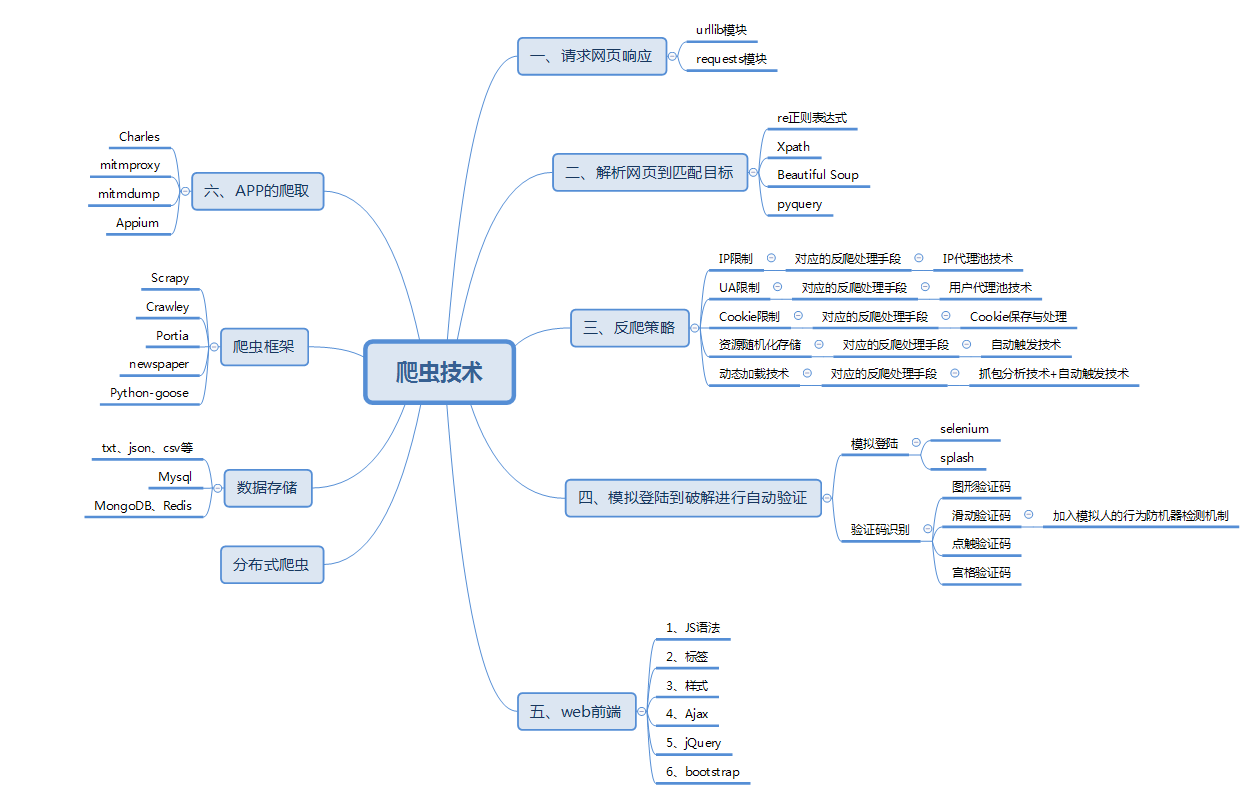
初步介绍下Scrapy是一个基于Twisted的异步处理框架,是纯python实现的爬虫框架,而且结构清晰,模块之前耦合度低,非常灵活。
了解Twisted见:https://www.cnblogs.com/silence-cho/p/9898984.html
百度上copy张图: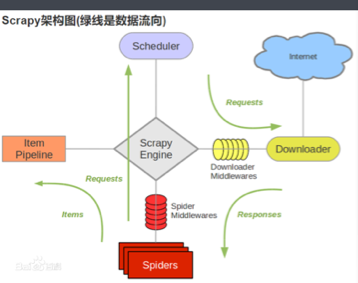
项目结构:
Scrapy框架和pyspider不同,它是通过命令行来创建项目的,代码的编写还是需要IDE的。
项目文件结构:
Scrapy.cfg #scrapy项目配置文件,其内定义了项目的配置文件路径、部署相关信息等内容
Project/
init.py
Items.py #它定义Item数据结构(可以当成字典)
Pipelines.py #它定义Item Pipeline的实现
Settings.py #它定义项目的全局配置
Middlewares.py #它定义Spider Middlewares和Downloader Middlewares的实现
Spiders/
init.py
Spider1.py #spider的实现
Spider2.py
…
1. 创建项目
在命令行:
scrapy startproject images360 #images360为项目文件夹
2. 创建Spiders
cd images360
scrapy genspider images images.so.com #利用genspider生成一个name为images的spider
3. 对项目类其余文件编写配置
4. 运行
scrapy crawl images
那具体怎么实现呢?
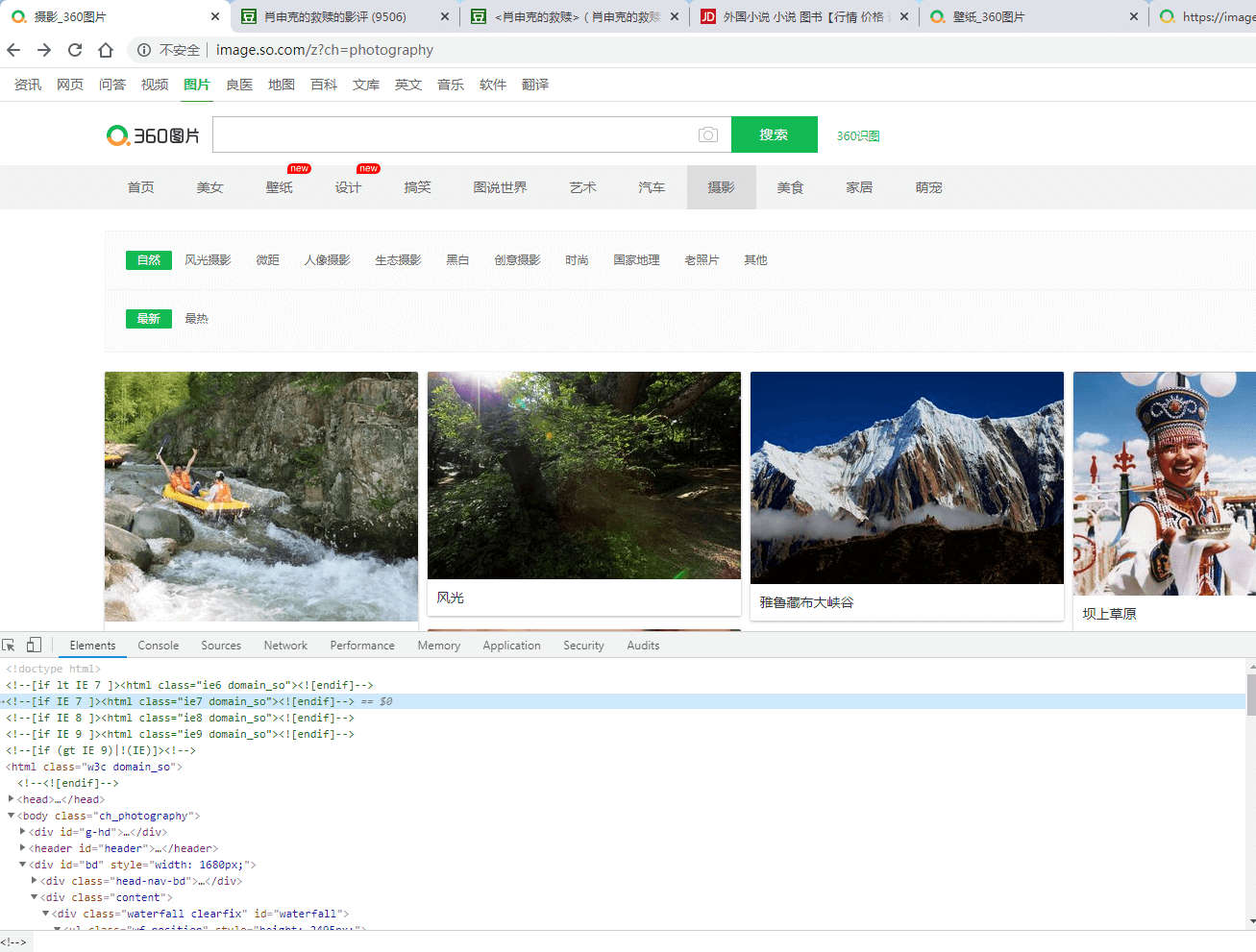
先打开要爬的摄影图片网站
https://image.so.com/z?ch=photography
然后对图片点击右键检查
接着点下面这个network,看下数据是怎么传输的,现在可以往下滑动,加载更多的图片处来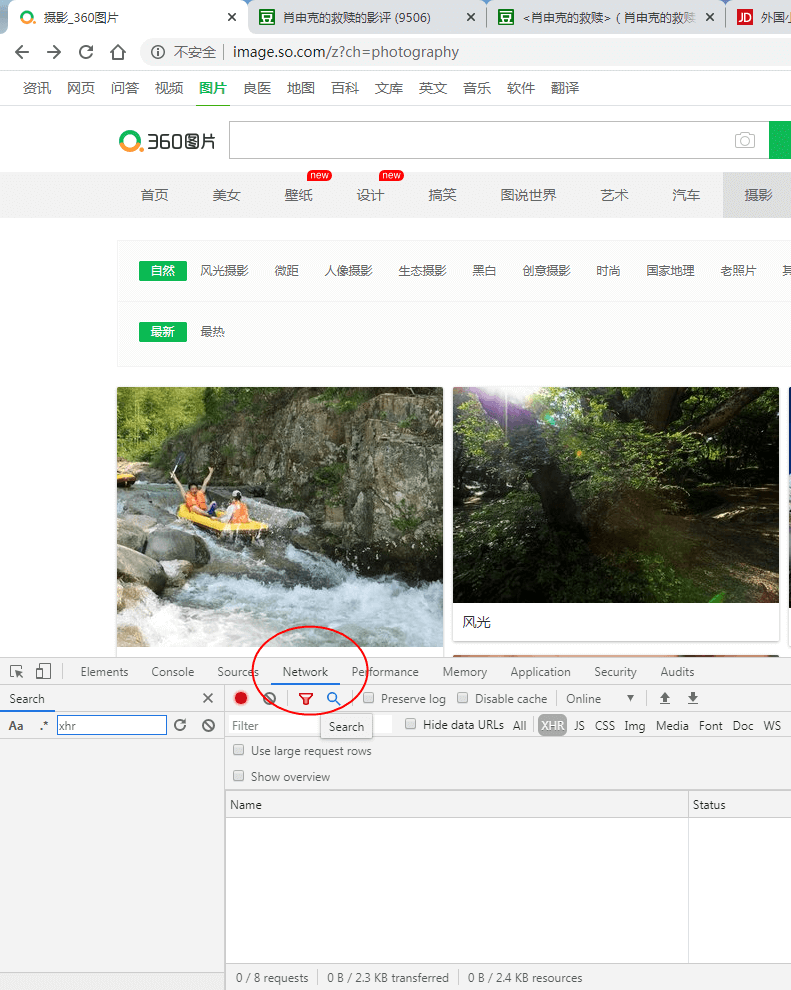
这个时候选择下面的XHR文件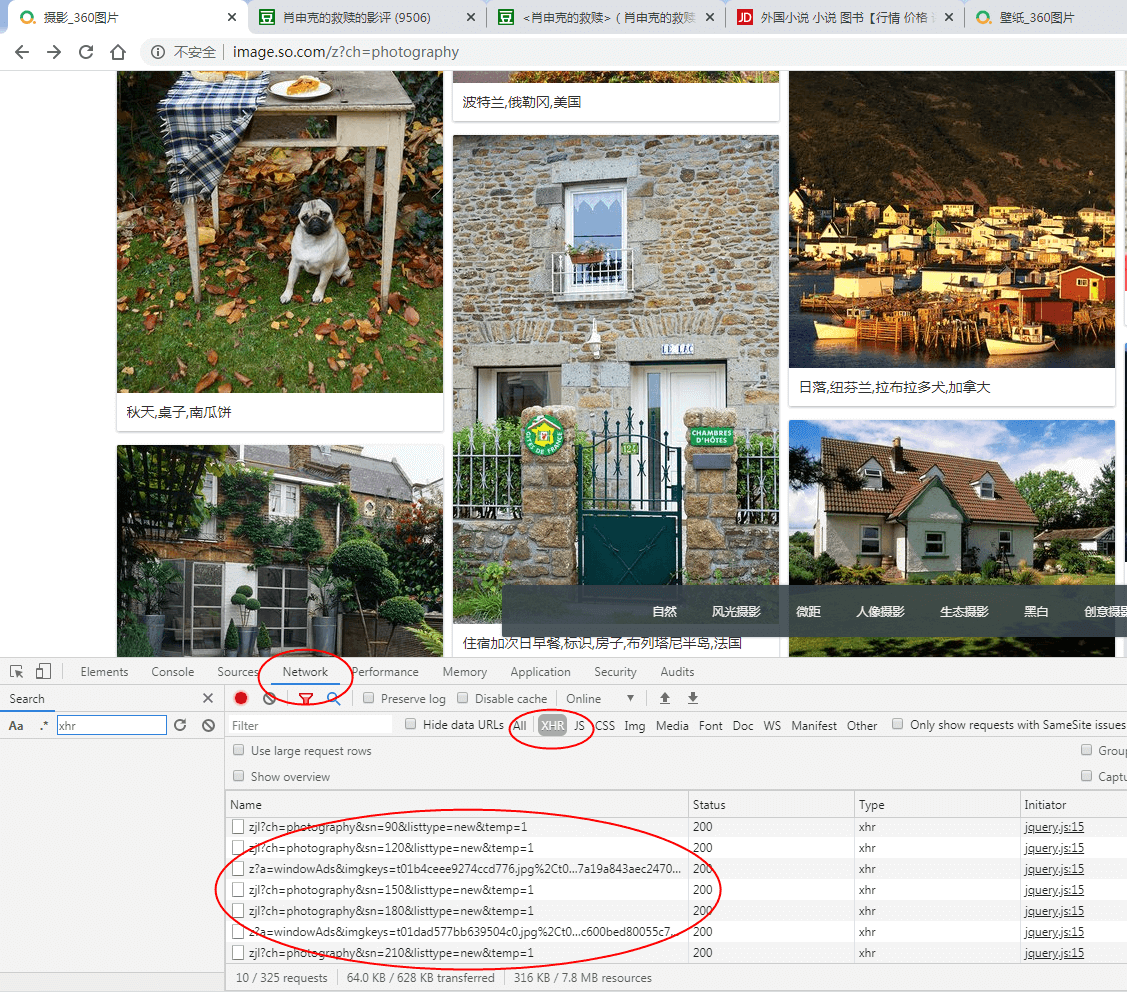
这些就是找Ajax的规律,因为它不像传统page直接加1页就翻页走了,它是通过ajax请求到网页更新这样的,如何去发现,通过xhr类型(Ajax的请求类型就是xhr)
我把这些圈中的链接copy如下:
https://image.so.com/zjl?ch=photography&sn=30&listtype=new&temp=1
https://image.so.com/zjl?ch=photography&sn=60&listtype=new&temp=1
https://image.so.com/zjl?ch=photography&sn=90&listtype=new&temp=1
发现规律了吧,虽然不像之前的urlpage+1那样简单,不过这个稍微找下也能找到规律
Ok,构造url已经解决,接下来就是提取信息,我们可以先访问下这个网页:
https://image.so.com/zjl?ch=photography&sn=30&listtype=new&temp=1
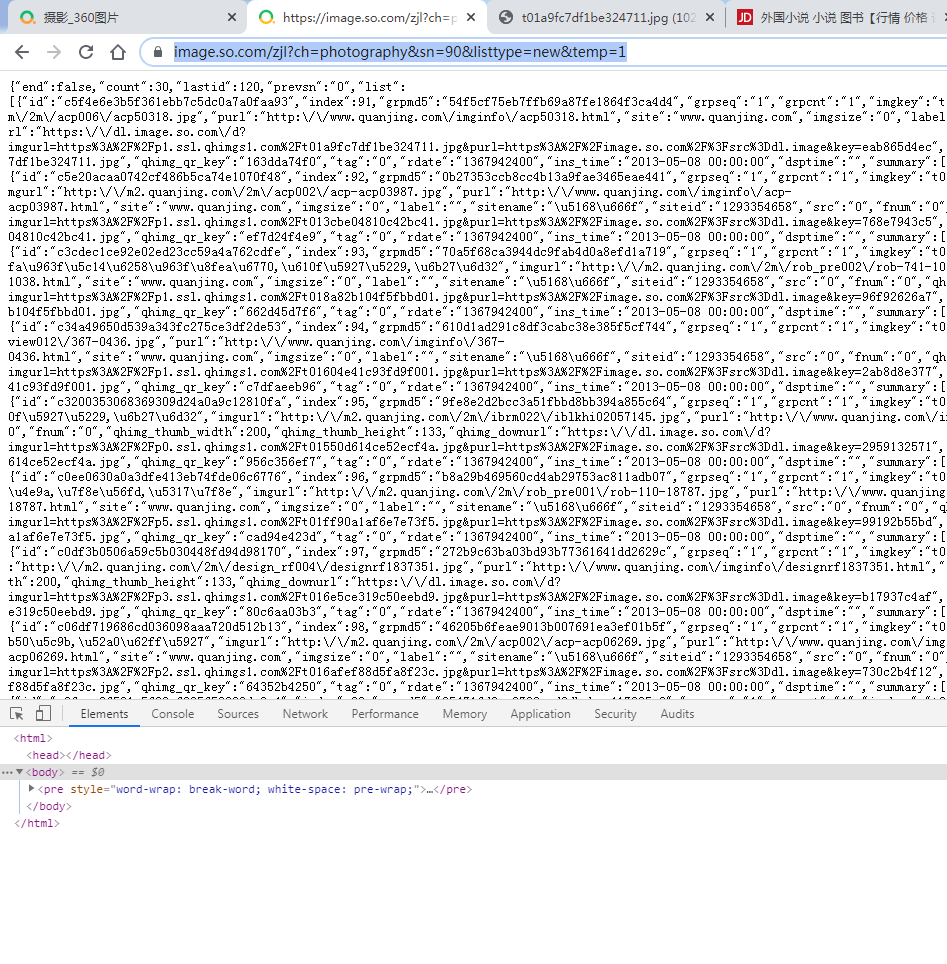
打开发现是密密麻麻的json格式,这就好办了,看看有哪些字段:
{“id”:”c5f4e6e3b5f361ebb7c5dc0a7a0faa93”,”index”:91,”grpmd5”:”54f5cf75eb7ffb69a87fe1864f3ca4d4”,”grpseq”:”1”,”grpcnt”:”1”,”imgkey”:”t01a9fc7df1be324711.jpg”,”width”:”1024”,”height”:”683”,”title”:”\u9b41\u5317\u514b,\u52a0\u62ff\u5927”,”imgurl”:”http:\/\/m2.quanjing.com\/2m\/acp006\/acp50318.jpg”,”purl”:”http:\/\/www.quanjing.com\/imginfo\/acp50318.html”,”site”:”www.quanjing.com”,”imgsize”:”0”,”label”:””,”sitename”:”\u5168\u666f”,”siteid”:”1293354658”,”src”:”0”,”fnum”:”0”,”qhimg_thumb_width”:200,”qhimg_thumb_height”:133,”qhimg_downurl”:”https:\/\/dl.image.so.com\/d?imgurl=https%3A%2F%2Fp1.ssl.qhimgs1.com%2Ft01a9fc7df1be324711.jpg&purl=https%3A%2F%2Fimage.so.com%2F%3Fsrc%3Ddl.image&key=eab865d4ec”,”qhimg_url”:”https:\/\/p1.ssl.qhimgs1.com\/t01a9fc7df1be324711.jpg”,”qhimg_thumb”:”https:\/\/p1.ssl.qhimgs1.com\/sdr\/200_200\/t01a9fc7df1be324711.jpg”,”qhimg_qr_key”:”163dda74f0”,”tag”:”0”,”rdate”:”1367942400”,”ins_time”:”2013-05-08 00:00:00”,”dsptime”:””,”summary”:[],”pic_desc”:” \u7530\u56ed”},
Spiders文件夹中iamges.py函数就写好了: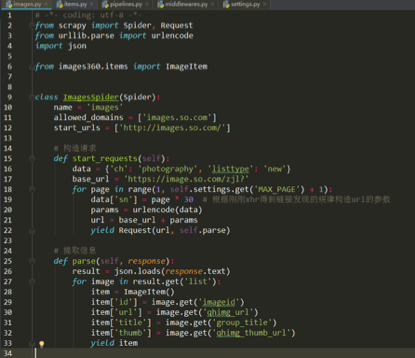
别忘了在item.py对提取字段进行定义:
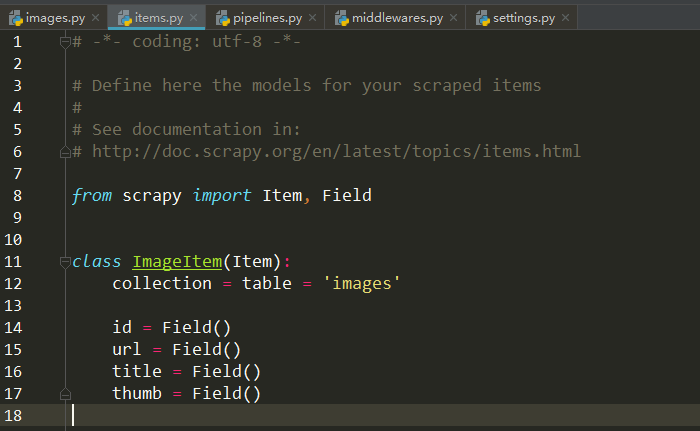
接下来如果想把数据存在数据库中,还需要进行相应的配置,这里选择用mysql介绍,用MongoDB也是类似的操作。
这个存储过程需要在pipelines.py文件中实现:
主要是用python中pymysql连接上你的mysql数据库,中间主要是参数传递,方法很简单。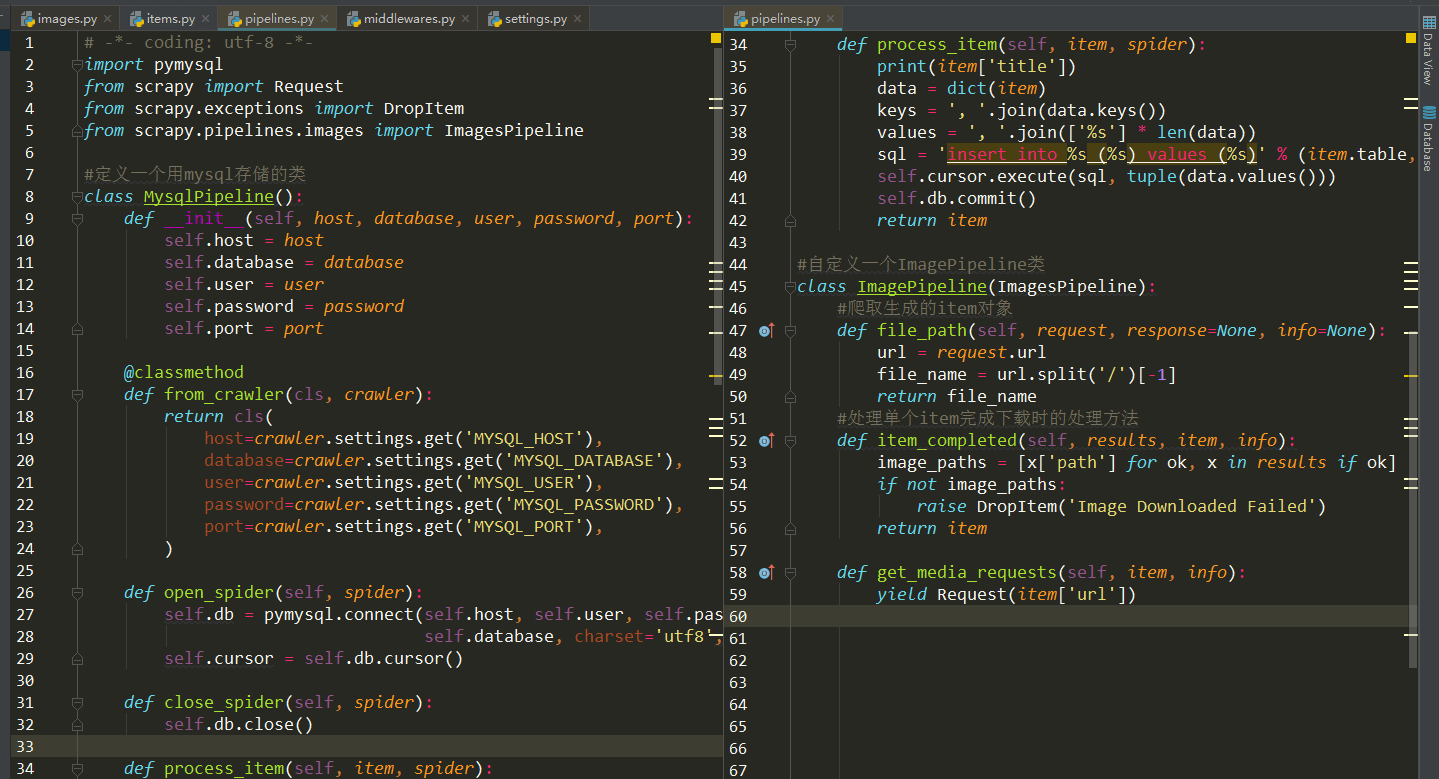
最后就是在配置文件中添加上存数据以及爬取页数的设置就行了,不过要注意images360.pipelines.ImagePipelin、MysqlPipeline调用的顺序,先ImagePipelin对item下载进行筛选后,才用MysqlPipeline存储。
最后第四步运行咯!
得到结果如下: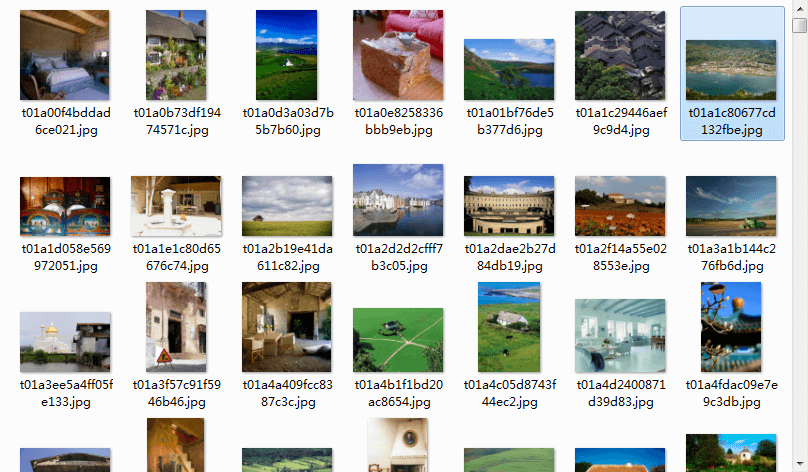
在mysql中: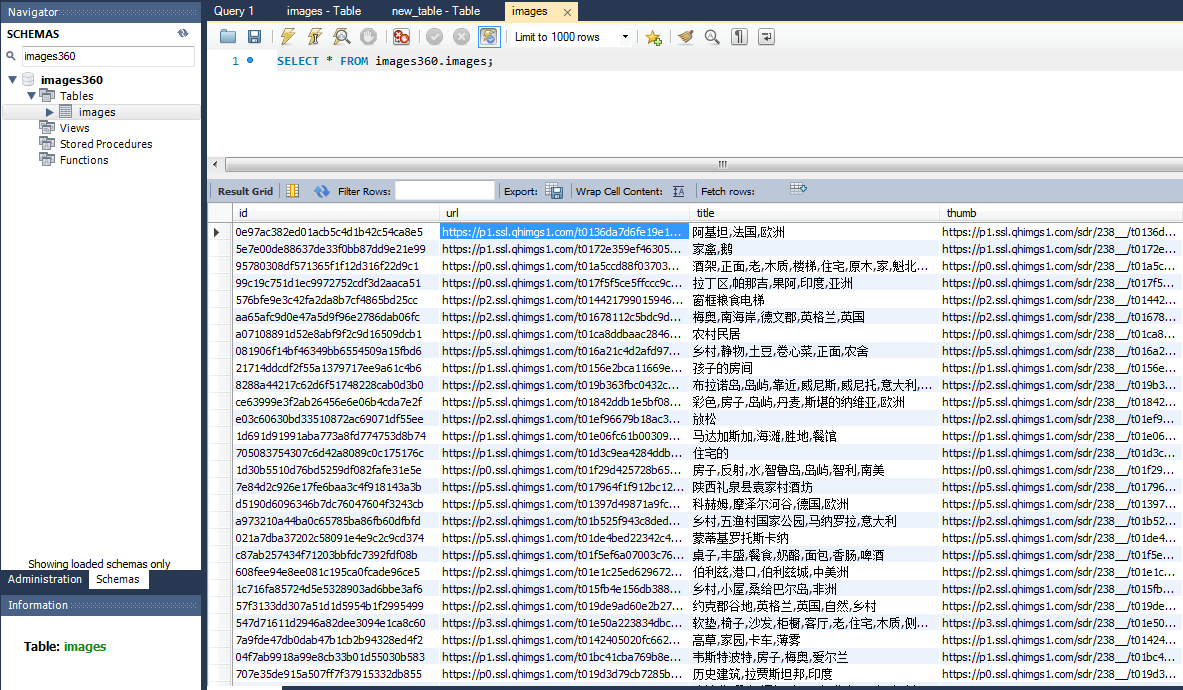
Scrapy下载速度是很快的: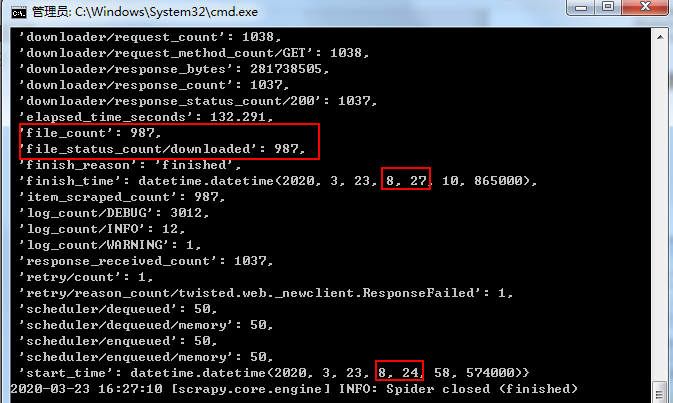
近1000张图片,3分钟搞定。想想上次爬妹子图片3w多张,爬了好几个小时…
爬虫就写到这把,本来还有微博评论、豆瓣影评…
理解不深,望见谅。
Reference:
1.《python3 网络爬虫开发实战》崔庆才

若有收获,就点个赞吧
0 人点赞
