- 4.关于IV和WOE的进一步思考
- https://blog.csdn.net/weixin_38940048/article/details/82316900">-- coding:utf-8 --# Author:Bemyid
from numpy import log
from pandas import DataFrame as df
import pandas as pd
def createDateset():
dataSet=[
[0, 1, 0],
[0, 0, 0],
[0, 1, 0],
[1, 0, 1],
[1, 0, 0],
[1, 1, 1],
[0, 1, 1],
[1, 1, 1],
[1, 0, 1],
[1, 0, 1]]
return dataSet
def calcWOE(dataset,col,targe):
subdata=df(dataset.groupby(col)[col].count())
suby=df(dataset.groupby(col)[targe].sum())
data=df(pd.merge(subdata,suby,how=”left”,leftindex=True,rightindex=True))
btotal=data[targe].sum()
total=data[col].sum()
gtotal=total-b_total
data[“bad”]=data.apply(lambda x:round(x[targe]/b_total,3),axis=1)
data[“good”]=data.apply(lambda x:round((x[col]-x[targe])/g_total,3),axis=1)
data[“WOE”]=data.apply(lambda x:log(x.bad/x.good),axis=1)
return data.loc[:,[“bad”,”good”,”WOE”]]
def calcIV(dataset):
dataset[“IV”]=dataset.apply(lambda x:(x.bad-x.good)*x.WOE,axis=1)
IV=sum(dataset[“IV”])
return IV
if __name == ‘__main‘:
data=createDateset()
data=df(data,columns=[“x1”,”x2”,”y”])
data_WOE=calcWOE(data,”x1”,”y”)
print(data_WOE)
data_IV=calcIV(data_WOE)
print(data_IV)
————————————————
版权声明:本文为CSDN博主「bemyidd」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_38940048/article/details/82316900
4.关于IV和WOE的进一步思考

4.1 为什么用IV而不是直接用WOE

第一个原因,当我们衡量一个变量的预测能力时,我们所使用的指标值不应该是负数,否则,说一个变量的预测能力的指标是-2.3,听起来很别扭。从这个角度讲,乘以pyn这个系数,保证了变量每个分组的结果都是非负数,你可以验证一下,当一个分组的WOE是正数时,pyn也是正数,当一个分组的WOE是负数时,pyn也是负数,而当一个分组的WOE=0时,pyn也是0。
当然,上面的原因不是最主要的,因为其实我们上面提到的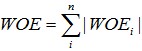 这个指标也可以完全避免负数的出现。
这个指标也可以完全避免负数的出现。
更主要的原因,也就是第二个原因是,乘以pyn后,体现出了变量当前分组中个体的数量占整体个体数量的比例,对变量预测能力的影响。怎么理解这句话呢?我们还是举个例子。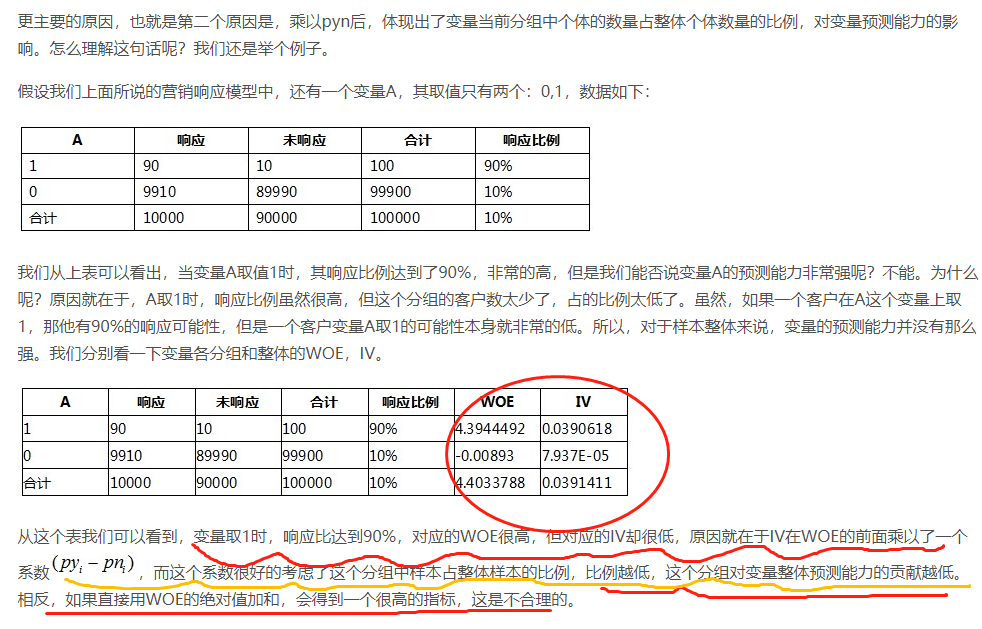

版权声明:本文为CSDN博主「kevin7561」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kevin7658/article/details/50780391
-- coding:utf-8 --# Author:Bemyid
from numpy import log
from pandas import DataFrame as df
import pandas as pd
def createDateset():
dataSet=[
[0, 1, 0],
[0, 0, 0],
[0, 1, 0],
[1, 0, 1],
[1, 0, 0],
[1, 1, 1],
[0, 1, 1],
[1, 1, 1],
[1, 0, 1],
[1, 0, 1]]
return dataSet
def calcWOE(dataset,col,targe):
subdata=df(dataset.groupby(col)[col].count())
suby=df(dataset.groupby(col)[targe].sum())
data=df(pd.merge(subdata,suby,how=”left”,leftindex=True,rightindex=True))
btotal=data[targe].sum()
total=data[col].sum()
gtotal=total-b_total
data[“bad”]=data.apply(lambda x:round(x[targe]/b_total,3),axis=1)
data[“good”]=data.apply(lambda x:round((x[col]-x[targe])/g_total,3),axis=1)
data[“WOE”]=data.apply(lambda x:log(x.bad/x.good),axis=1)
return data.loc[:,[“bad”,”good”,”WOE”]]
def calcIV(dataset):
dataset[“IV”]=dataset.apply(lambda x:(x.bad-x.good)*x.WOE,axis=1)
IV=sum(dataset[“IV”])
return IV
if __name == ‘__main‘:
data=createDateset()
data=df(data,columns=[“x1”,”x2”,”y”])
data_WOE=calcWOE(data,”x1”,”y”)
print(data_WOE)
data_IV=calcIV(data_WOE)
print(data_IV)
————————————————
版权声明:本文为CSDN博主「bemyidd」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_38940048/article/details/82316900

若有收获,就点个赞吧
0 人点赞
