为什么15.87%这个数字对你很重要?
原创: 万维钢
生活中总有那么一种人:他们学习效率极高,即使面对陌生知识,也能快速切入、高效掌握。
他们是怎么做到的?这和一个数字有关系——15.87%。
这是一个科学上的新发现,「得到」作者万维钢对此进行了详细分析,分享给你。
你好,我是万维钢。
今天咱们说一个特别熟悉的规律的新发现。这个发现是如此得重要,以至于我认为你应该永远记住它。
从三个熟悉的知识说起
1. 学习区
心理学家把我们可能面对的学习内容分成了三个区:舒适区、学习区和恐慌区。
舒适区的内容对你来说太容易,恐慌区的内容太难,刻意练习要求你始终在二者中间一个特别小的学习区里学习——这里的难度对你恰到好处。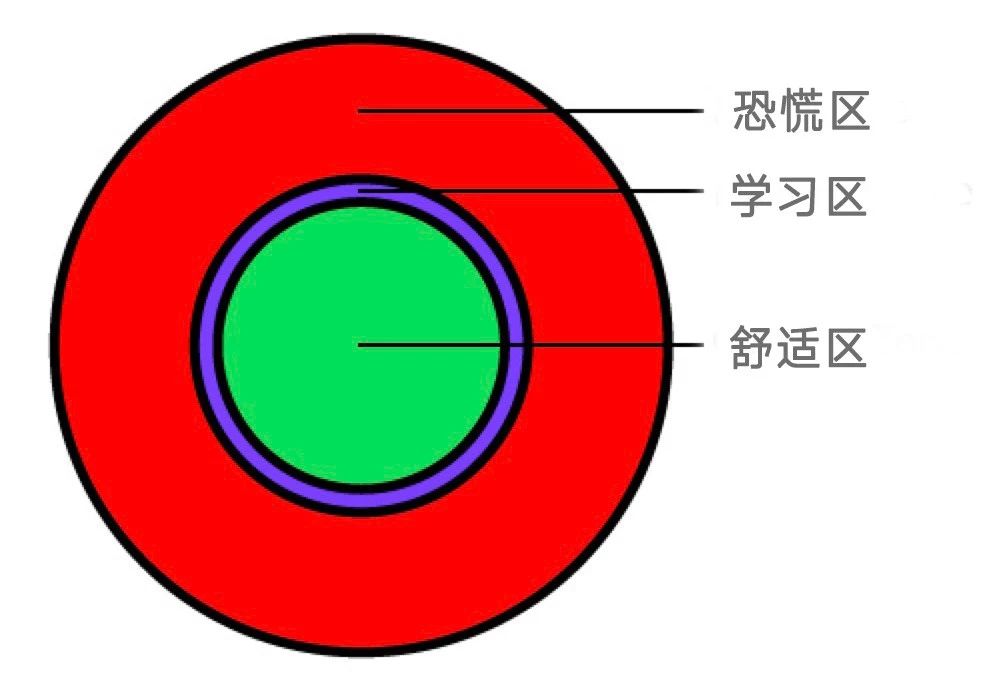
图片来自 http://sethsandler.com/productivity/3-zones/
这个理论不可能是错的。但是因为现在“跳出舒适区”已经成了一句口号,有些人就产生了逆反心理,说我好不容易找到一个舒适区发挥特长,为什么要跳出来呢?
关键在于这里说的是“学习”!也许你在舒适区赚钱最多,但那是另一回事——要想提高技艺,你就只能在学习区。
2. 心流
这个概念最早是米哈里·契克森米哈赖在《心流:最优体验心理学》这本书里提出来的。
契克森米哈赖说,要想在工作中达到心流状态,这项工作的挑战和你的技能必须形成平衡。他还专门用一张图说明这个道理——
图片来自 http://chickswagewar.blogspot.com/2013/06/skill-challenge-and-flow.html
如果工作的挑战大大低于你的技能,你会觉得这个工作很无聊。如果工作的挑战大大超出你的技能,你会感到焦虑。
而如果难度和技能正好匹配,你一上来并不知道该怎么做,但是调动自己最高水平的技能、再稍微突破一点,你正好能解决这个问题,那就是心流的体验。这是一个奇妙的感觉,你沉浸在工作之中忘记了时间的流动,甚至可能忘记自身的存在。
3. “喜欢 = 熟悉 + 意外”
一个文艺作品要想最大限度地吸引观众,必须既提供观众熟悉的东西,又制造意外。
好,现在你发现没有,这三个知识说的其实是一回事。学习区、心流、喜欢,说的是已知和未知、简单和困难、熟悉和意外的搭配——从信息论的角度来说,它们说的都是“旧信息”和“新信息”的配比。
那我现在问你一个问题,这个配比应该是多少呢?
意外应该有多少才合适
以前我们并没有量化这些理论,我们只是泛泛地说要加入一定的难度和意外。而我今天要讲的这个研究,恰恰告诉我们一个神奇的答案,说这个问题是有最优数值解的:这个数值是15.87%。
亚利桑那大学和布朗大学的研究者刚刚贴出一篇论文的预印本,叫《最优学习的85%规则》[1]。这篇论文还没有正式发表,《科学美国人》上的一个博客已经率先报道 [2],Twitter上也有好几个人讨论。
我仔细研读了这篇论文,感觉非常新颖而且非常重要,它将来会获得大量的引用。但是我认为一些讨论误解了这篇论文的意思。我先说说这篇论文到底说了什么。
我们知道现在人工智能本质上是机器学习。我们弄一个神经网络,用大量的数据去训练这个网络,让网络学会自己做判断。网络内部有大量参数随着训练不断变化,就相当于人脑在学习中提高技艺。
每一次训练,都是先让网络对数据做个自己的判断,然后数据再给它一个反馈。如果网络判断正确,它就会加深巩固现有的参数;如果判断错了,它就调整参数。这跟人脑的学习也很像:只有当你判断错误的时候,才说明这个知识对你是新知识,你才能学习提高。
研究者可以决定用什么难度的数据去“喂”这个网络。如果数据难度太低,网络每次都能猜对,那显然无法提高判断水平;如果数据难度太高,网络总是猜错,那它的参数就会东一下西一下变来变去,就会无所适从。这项研究问的问题是,每次训练中网络判断的错误率是多少,才是最优的呢?
研究者首先用了一个比较简单的数学模型做理论推导,又用了一个AI神经网络学习算法和一个模拟生物大脑的神经网络模型做模拟实验,结果得出一个精确解:15.87%。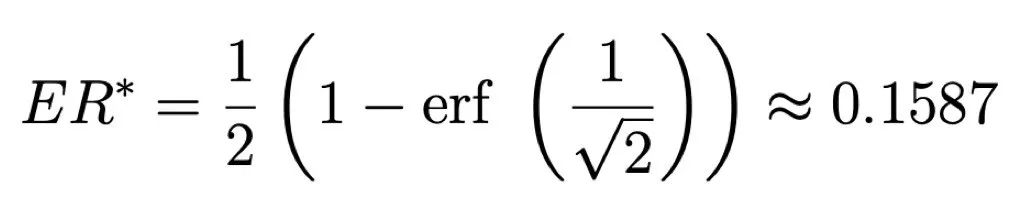
也就是说,当你训练一个东西的时候,你给它的内容中应该有大约85%是它熟悉的,有15%是它感到意外的。
研究者把这个结论称为“85%规则”,我们干脆就把15.87%叫做“最佳意外率”。这个数值就是学习的“甜蜜点”。
让你学得最快而且最爽
找到最佳意外率有两个好处:
1. 它让你的学习速度最快
我们来看看模拟实验的结果。下面这是一张等值曲线图,说的是判断出错率和AI训练效率的关系——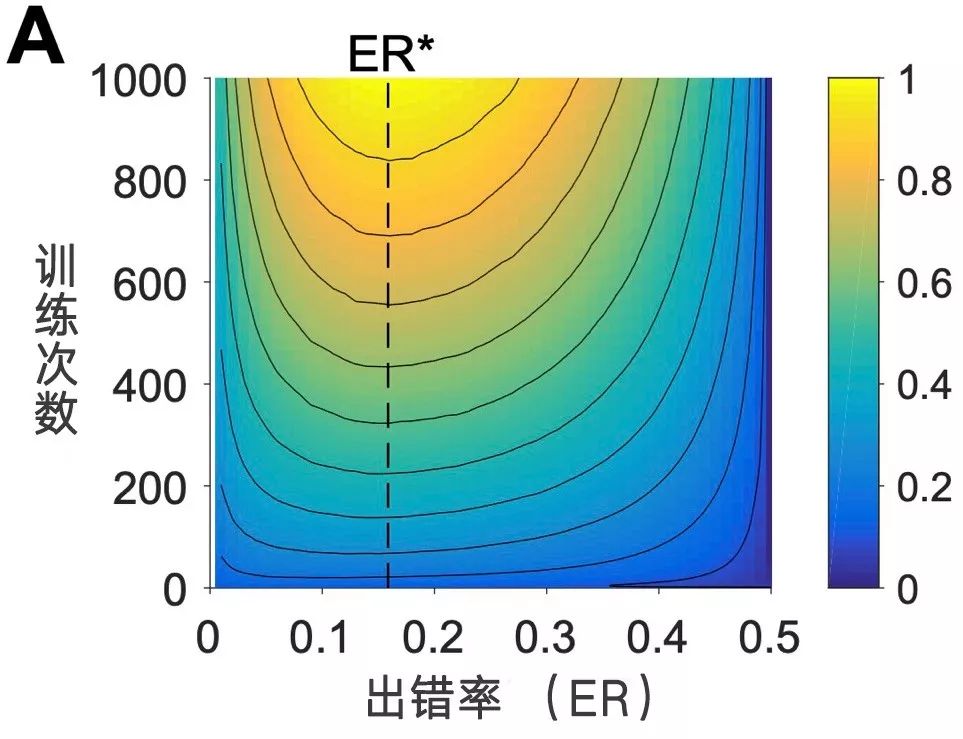
图中横坐标代表每次训练的出错率——也就是意外率,纵坐标代表训练的次数,图中颜色代表训练出来的网络的准确度,颜色越热(黄色)表示准确率越高。
我们看到,0.1587的训练出错率那个区域,随着训练次数的增长,它的准确度增加速度是最快的。比如说出错率是0.4,训练一千次能达到的准确率,大约相当于出错率是0.1587,训练350次的水平!
下面这张图中的三条曲线代表三个不同的训练出错率,横坐标是训练的总次数,纵坐标是准确度。我们看到,出错率在0.16的那条曲线,准确度增加的速度是最快的,可以说大大高于另外两条曲线。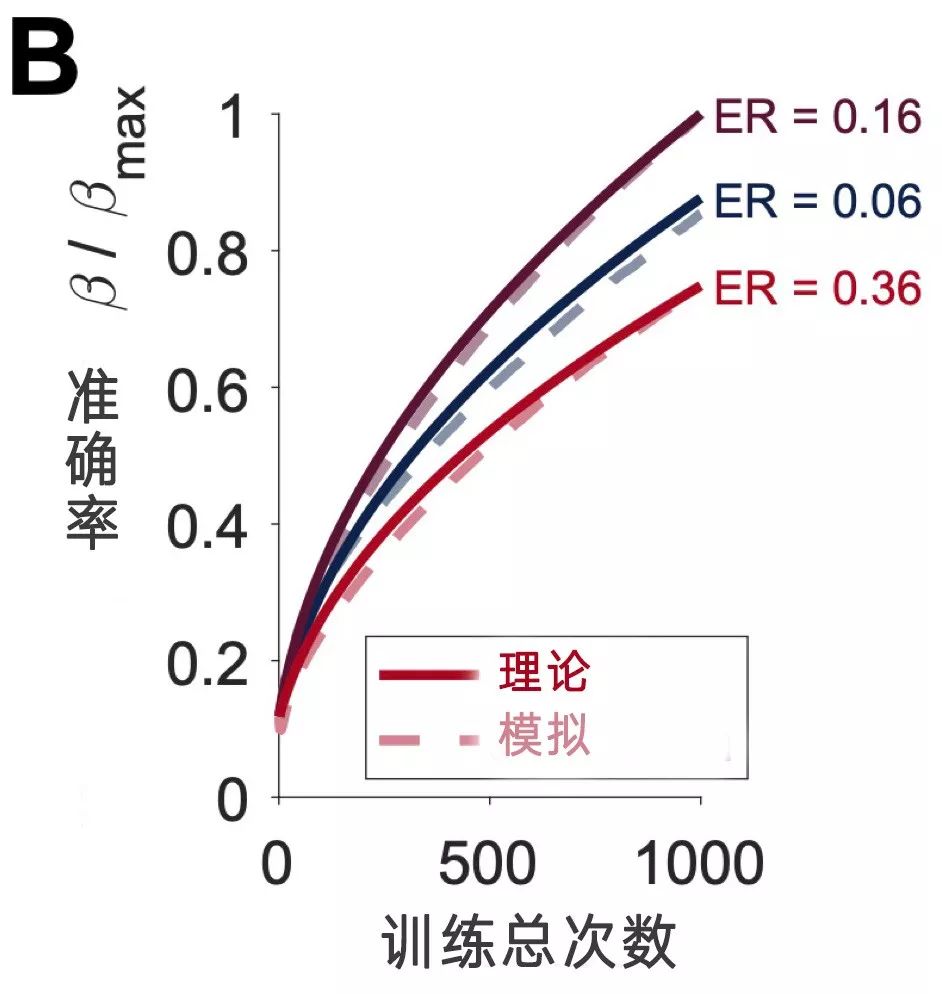
研究者理论推导的结果是,15.87%的意外率能让训练时间相对于其他数值以指数下降。
2. 它还能让你在学习中感觉最爽
这项研究使用的例子主要是机器学习,但是研究者也考察了在其他领域中的训练,包括对人的教学实验和对动物的训练,大家摸索出来的结果基本上都是要有15%的新内容。这些研究表明,在这个点上,人们对学习的投入度是最高的。
15.87%不但是学习中的最佳训练出错率,也是心流率,也是文艺作品最佳意外率。论文中还提到,电子游戏的设计者也得用这个比率。如果在这个游戏关卡中玩家都一点都不会犯错,轻松过关,那游戏就太简单了,玩家会感到无聊。如果让玩家频频犯错,那设置太难了,也玩不下去。15%左右的犯错率,是最好玩的游戏。
量化你的学习曲线
我为什么说《科学美国人》那篇博客文章的理解是错误呢?那个作者从这个研究悟出的道理是最好每次考试都考85分。如果你考100分,那这个考试对你来说太简单了,你应该挑战更高难度的内容。如果你的分数太低,那你应该降低难度。
但是你不想当一个考85分的学生,85分不能把你送进好大学。其实我们理解了这个研究之后就会明白,15.87%这个比率并不是学习之后再考试的出错率,而是在学习之前,你要学的这个内容的最佳意外率。这是先测验,后学习的训练方法中测验出来的出错率。
能让你判断错误的东西才是你需要学习的东西。不是说我们对一个什么知识掌握85%就行了,我们关注的恰恰是那15%的事先不会的东西。
所以最科学的安排不是说期末考试应该得85分,而是在每次学习之前,安排学习内容的时候,确保有15%的新东西。
比如说学英语。最理想的一篇课文,应该是其中85%的内容是你熟悉的,15%的内容——包括单词和语法——对你来说是新的。
学数学,每一个新知识都是建立在旧知识的基础之上。最好这一讲中85%的操作是你本来就会的,15%是新技巧。读书,最理想的情况是书中85%的内容让你有亲切感,另外15%是改造你的世界观。
我们从这项研究中至少可以有三个收获。
1. 熟悉很重要。
在学习中遇到熟悉的东西,可以巩固我们的知识,让我们再次确认以前学的是对的。这并不仅仅是心理上的安慰!人工智能神经网络不需要心理安慰,它是冷酷无情的,但是它也需要熟悉的内容。
所以“学习区”不是一个感情上的问题,而是大脑认知的问题。新信息重要,旧信息也很重要。
2. 15.87%这个数值是通用的吗?
研究者的理论推导用的是一个特殊的数学模型,但是他们的数值模拟,包括考察其他领域中的训练,结果差不多也都是这个数值。如果我们相信人脑本质上就是一个神经网络,那么这个研究就具有普遍的意义。我私下认为这个数值在任何一个领域中都不会太离谱。
3. 有一个值得专门强调的精神,就是你应该时刻追求效率最大化。
知道一个道理有用,和知道这个道理有多么有用,有本质区别。
每个人都知道要想学习好,你应该谦虚谨慎、博采众长、尊师重道、眼光放长远、有很大的格局。可是要谦虚到什么程度才好?格局最大要多大?这些都没有量化,不好操作。
但是15.87%这个最优意外率是可以操作的。15%和5%的进步速度有非常明显的差异。我们设想有两个爱学习的人 ——
A同学对什么都感兴趣,博览群书还选修了很多课程。他有时候觉得所学的内容很轻松,有时候感到吃力,但他总是那么用功。A同学热爱学习,他觉得自己学得很不错。
但是世界上还可能存在一个B同学。B同学有个教练,给他精心安排每次学习的内容,确保每次15%的意外率。B同学的学习效率达到了最大化。
我们知道那是一个特别理想的状态,没有人能确保这样的高效率。但是根据这一讲的理论,假以时日,B同学的学习成就将会远远超过A同学。你想想这是多么可怕的一个事实。
参考文献:
[1] Robert C. Wilson et al., The Eighty Five Percent Rule for Optimal Learning, doi: https://doi.org/10.1101/255182
[2] Cody Kommers, How Wrong Should You Be? blogs.scientificamerican.com, January 14, 2019.

若有收获,就点个赞吧
0 人点赞
