目录
- 1. 什么是XLNet
- 2. 自回归语言模型(Autoregressive LM)
- 3. 自编码语言模型(Autoencoder LM)
- 4. XLNet模型
- 4.1 排列语言建模(Permutation Language Modeling)
- 4.2 Transformer XL
- 5. XLNet与BERT比较
- 6. 代码实现
- 7. 参考文献
1. 什么是XLNet
XLNet 是一个类似 BERT 的模型,而不是完全不同的模型。总之,XLNet是一种通用的自回归预训练方法。它是CMU和Google Brain团队在2019年6月份发布的模型,最终,XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序。
作者表示,BERT 这样基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于自回归语言模型的预训练方法。然而,由于需要 mask 一部分输入,BERT 忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)。
基于这些优缺点,该研究提出了一种泛化的自回归预训练模型 XLNet。XLNet 可以:
- 通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息;
- 用自回归本身的特点克服 BERT 的缺点;
此外,XLNet 还融合了当前最优自回归模型 Transformer-XL 的思路。
2. 自回归语言模型(Autoregressive LM)
在ELMO/BERT出来之前,大家通常讲的语言模型其实是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词,这种类型的LM被称为自回归语言模型。GPT 就是典型的自回归语言模型。ELMO尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归LM,这个跟模型具体怎么实现有关系。ELMO是做了两个方向(从左到右以及从右到左两个方向的语言模型),但是是分别有两个方向的自回归LM,然后把LSTM的两个方向的隐节点状态拼接到一起,来体现双向语言模型这个事情的。所以其实是两个自回归语言模型的拼接,本质上仍然是自回归语言模型。
自回归语言模型有优点有缺点:
缺点是只能利用上文或者下文的信息,不能同时利用上文和下文的信息,当然,貌似ELMO这种双向都做,然后拼接看上去能够解决这个问题,因为融合模式过于简单,所以效果其实并不是太好。
优点其实跟下游NLP任务有关,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而Bert这种DAE模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题,导致生成类的NLP任务到目前为止都做不太好。3. 自编码语言模型(Autoencoder LM)
自回归语言模型只能根据上文预测下一个单词,或者反过来,只能根据下文预测前面一个单词。相比而言,Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
这种DAE LM的优缺点正好和自回归LM反过来,它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,这是好处。缺点是啥呢?主要在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题,因为Fine-tuning阶段是看不到[Mask]标记的。DAE吗,就要引入噪音,[Mask] 标记就是引入噪音的手段,这个正常。
XLNet的出发点就是:能否融合自回归LM和DAE LM两者的优点。就是说如果站在自回归LM的角度,如何引入和双向语言模型等价的效果;如果站在DAE LM的角度看,它本身是融入双向语言模型的,如何抛掉表面的那个[Mask]标记,让预训练和Fine-tuning保持一致。当然,XLNet还讲到了一个Bert被Mask单词之间相互独立的问题。4. XLNet模型
4.1 排列语言建模(Permutation Language Modeling)
Bert的自编码语言模型也有对应的缺点,就是XLNet在文中指出的:
第一个预训练阶段因为采取引入[Mask]标记来Mask掉部分单词的训练模式,而Fine-tuning阶段是看不到这种被强行加入的Mask标记的,所以两个阶段存在使用模式不一致的情形,这可能会带来一定的性能损失;
- 另外一个是,Bert在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的。
上面两点是XLNet在第一个预训练阶段,相对Bert来说要解决的两个问题。
其实思路也比较简洁,可以这么思考:XLNet仍然遵循两阶段的过程,第一个阶段是语言模型预训练阶段;第二阶段是任务数据Fine-tuning阶段。它主要希望改动第一个阶段,就是说不像Bert那种带Mask符号的Denoising-autoencoder的模式,而是采用自回归LM的模式。就是说,看上去输入句子X仍然是自左向右的输入,看到Ti单词的上文Context_before,来预测Ti这个单词。但是又希望在Context_before里,不仅仅看到上文单词,也能看到Ti单词后面的下文Context_after里的下文单词,这样的话,Bert里面预训练阶段引入的Mask符号就不需要了,于是在预训练阶段,看上去是个标准的从左向右过程,Fine-tuning当然也是这个过程,于是两个环节就统一起来。当然,这是目标。剩下是怎么做到这一点的问题。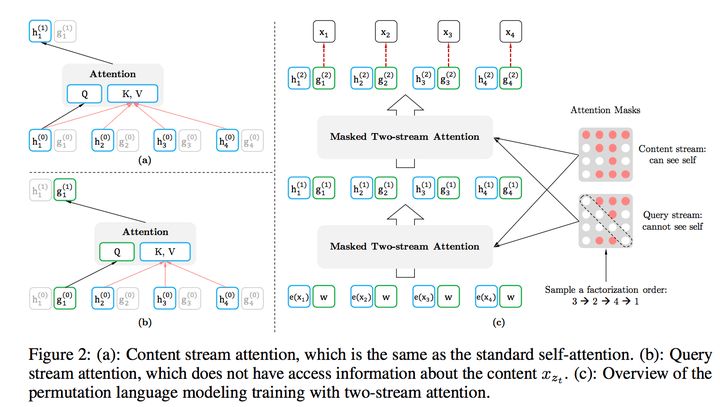
首先,需要强调一点,尽管上面讲的是把句子X的单词排列组合后,再随机抽取例子作为输入,但是,实际上你是不能这么做的,因为Fine-tuning阶段你不可能也去排列组合原始输入。所以,就必须让预训练阶段的输入部分,看上去仍然是x1,x2,x3,x4这个输入顺序,但是可以在Transformer部分做些工作,来达成我们希望的目标。
具体而言,XLNet采取了Attention掩码的机制,你可以理解为,当前的输入句子是X,要预测的单词Ti是第i个单词,前面1到i-1个单词,在输入部分观察,并没发生变化,该是谁还是谁。但是在Transformer内部,通过Attention掩码,从X的输入单词里面,也就是Ti的上文和下文单词中,随机选择i-1个,放到Ti的上文位置中,把其它单词的输入通过Attention掩码隐藏掉,于是就能够达成我们期望的目标(当然这个所谓放到Ti的上文位置,只是一种形象的说法,其实在内部,就是通过Attention Mask,把其它没有被选到的单词Mask掉,不让它们在预测单词Ti的时候发生作用,如此而已。看着就类似于把这些被选中的单词放到了上文Context_before的位置了)。
具体实现的时候,XLNet是用“双流自注意力模型”实现的,细节可以参考论文,但是基本思想就如上所述,双流自注意力机制只是实现这个思想的具体方式,理论上,你可以想出其它具体实现方式来实现这个基本思想,也能达成让Ti看到下文单词的目标。
这里简单说下“双流自注意力机制”,一个是内容流自注意力,其实就是标准的Transformer的计算过程;主要是引入了Query流自注意力,这个是干嘛的呢?其实就是用来代替Bert的那个[Mask]标记的,因为XLNet希望抛掉[Mask]标记符号,但是比如知道上文单词x1,x2,要预测单词x3,此时在x3对应位置的Transformer最高层去预测这个单词,但是输入侧不能看到要预测的单词x3,Bert其实是直接引入[Mask]标记来覆盖掉单词x3的内容的,等于说[Mask]是个通用的占位符号。而XLNet因为要抛掉[Mask]标记,但是又不能看到x3的输入,于是Query流,就直接忽略掉x3输入了,只保留这个位置信息,用参数w来代表位置的embedding编码。其实XLNet只是扔了表面的[Mask]占位符号,内部还是引入Query流来忽略掉被Mask的这个单词。和Bert比,只是实现方式不同而已。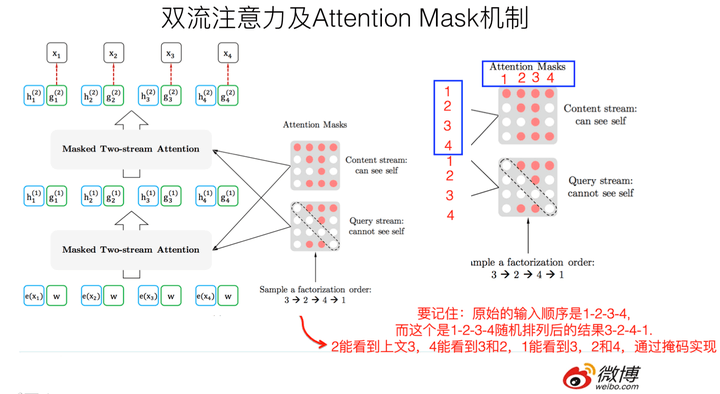
上面讲的Permutation Language Model是XLNet的主要理论创新,所以介绍的比较多,从模型角度讲,这个创新还是挺有意思的,因为它开启了自回归语言模型如何引入下文的一个思路,相信对于后续工作会有启发。当然,XLNet不仅仅做了这些,它还引入了其它的因素,也算是一个当前有效技术的集成体。感觉XLNet就是Bert、GPT 2.0和Transformer XL的综合体变身:
- 首先,它通过PLM(Permutation Language Model)预训练目标,吸收了Bert的双向语言模型;
- 然后,GPT2.0的核心其实是更多更高质量的预训练数据,这个明显也被XLNet吸收进来了;
- 再然后,Transformer XL的主要思想也被吸收进来,它的主要目标是解决Transformer对于长文档NLP应用不够友好的问题。
4.2 Transformer XL
目前在NLP领域中,处理语言建模问题有两种最先进的架构:RNN和Transformer。RNN按照序列顺序逐个学习输入的单词或字符之间的关系,而Transformer则接收一整段序列,然后使用self-attention机制来学习它们之间的依赖关系。这两种架构目前来看都取得了令人瞩目的成就,但它们都局限在捕捉长期依赖性上。
为了解决这一问题,CMU联合Google Brain在2019年1月推出的一篇新论文《Transformer-XL:Attentive Language Models beyond a Fixed-Length Context》同时结合了RNN序列建模和Transformer自注意力机制的优点,在输入数据的每个段上使用Transformer的注意力模块,并使用循环机制来学习连续段之间的依赖关系。4.2.1 vanilla Transformer
为何要提这个模型?因为Transformer-XL是基于这个模型进行的改进。
Al-Rfou等人基于Transformer提出了一种训练语言模型的方法,来根据之前的字符预测片段中的下一个字符。例如,它使用![[公式]](/uploads/projects/yingtaoxiang@hello/a057c08235584447a8013e3791bd483b.svg) 预测字符
预测字符 ![[公式]](/uploads/projects/yingtaoxiang@hello/c72b225d6f1295c73c3fa373cb65a783.svg) ,而在 之后的序列则被mask掉。论文中使用64层模型,并仅限于处理 512个字符这种相对较短的输入,因此它将输入分成段,并分别从每个段中进行学习,如下图所示。 在测试阶段如需处理较长的输入,该模型会在每一步中将输入向右移动一个字符,以此实现对单个字符的预测。
,而在 之后的序列则被mask掉。论文中使用64层模型,并仅限于处理 512个字符这种相对较短的输入,因此它将输入分成段,并分别从每个段中进行学习,如下图所示。 在测试阶段如需处理较长的输入,该模型会在每一步中将输入向右移动一个字符,以此实现对单个字符的预测。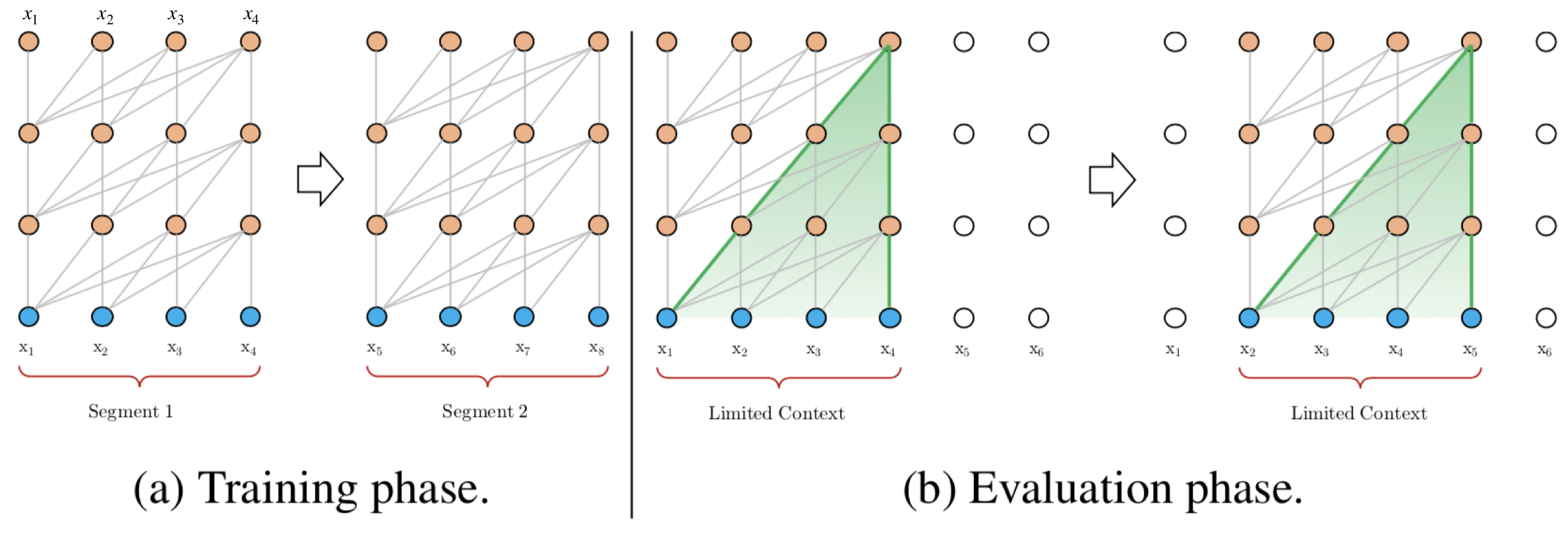
该模型在常用的数据集如enwik8和text8上的表现比RNN模型要好,但它仍有以下缺点:
- 上下文长度受限:字符之间的最大依赖距离受输入长度的限制,模型看不到出现在几个句子之前的单词。
- 上下文碎片:对于长度超过512个字符的文本,都是从头开始单独训练的。段与段之间没有上下文依赖性,会让训练效率低下,也会影响模型的性能。
- 推理速度慢:在测试阶段,每次预测下一个单词,都需要重新构建一遍上下文,并从头开始计算,这样的计算速度非常慢。
4.2.2 Transformer XL
Transformer-XL架构在vanilla Transformer的基础上引入了两点创新:循环机制(Recurrence Mechanism)和相对位置编码(Relative Positional Encoding),以克服vanilla Transformer的缺点。与vanilla Transformer相比,Transformer-XL的另一个优势是它可以被用于单词级和字符级的语言建模。
- 引入循环机制
与vanilla Transformer的基本思路一样,Transformer-XL仍然是使用分段的方式进行建模,但其与vanilla Transformer的本质不同是在于引入了段与段之间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。如下图所示:
在训练阶段,处理后面的段时,每个隐藏层都会接收两个输入:
- 该段的前面隐藏层的输出,与vanilla Transformer相同(上图的灰色线)。
- 前面段的隐藏层的输出(上图的绿色线),可以使模型创建长期依赖关系。
这两个输入会被拼接,然后用于计算当前段的Key和Value矩阵。
该方法可以利用前面更多段的信息,测试阶段也可以获得更长的依赖。在测试阶段,与vanilla Transformer相比,其速度也会更快。在vanilla Transformer中,一次只能前进一个step,并且需要重新构建段,并全部从头开始计算;而在Transformer-XL中,每次可以前进一整个段,并利用之前段的数据来预测当前段的输出。
- 相对位置编码
在Transformer中,一个重要的地方在于其考虑了序列的位置信息。在分段的情况下,如果仅仅对于每个段仍直接使用Transformer中的位置编码,即每个不同段在同一个位置上的表示使用相同的位置编码,就会出现问题。比如,第i−2i-2i−2段和第i−1i-1i−1段的第一个位置将具有相同的位置编码,但它们对于第iii段的建模重要性显然并不相同(例如第i−2i-2i−2段中的第一个位置重要性可能要低一些)。因此,需要对这种位置进行区分。
论文对于这个问题,提出了一种新的位置编码的方式,即会根据词之间的相对距离而非像Transformer中的绝对位置进行编码。从另一个角度来解读公式的话,可以将attention的计算分为如下四个部分:
- 基于内容的“寻址”,即没有添加原始位置编码的原始分数。
- 基于内容的位置偏置,即相对于当前内容的位置偏差。
- 全局的内容偏置,用于衡量key的重要性。
- 全局的位置偏置,根据query和key之间的距离调整重要性。
详细公式见:Transformer-XL解读(论文 + PyTorch源码)
5. XLNet与BERT比较
尽管看上去,XLNet在预训练机制引入的Permutation Language Model这种新的预训练目标,和Bert采用Mask标记这种方式,有很大不同。其实你深入思考一下,会发现,两者本质是类似的。
区别主要在于:
- Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词;
- 而XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单词在预测某个单词的时候不发生作用。
所以,本质上两者并没什么太大的不同,只是Mask的位置,Bert更表面化一些,XLNet则把这个过程隐藏在了Transformer内部而已。这样,就可以抛掉表面的[Mask]标记,解决它所说的预训练里带有[Mask]标记导致的和Fine-tuning过程不一致的问题。至于说XLNet说的,Bert里面被Mask掉单词的相互独立问题,也就是说,在预测某个被Mask单词的时候,其它被Mask单词不起作用,这个问题,你深入思考一下,其实是不重要的,因为XLNet在内部Attention Mask的时候,也会Mask掉一定比例的上下文单词,只要有一部分被Mask掉的单词,其实就面临这个问题。而如果训练数据足够大,其实不靠当前这个例子,靠其它例子,也能弥补被Mask单词直接的相互关系问题,因为总有其它例子能够学会这些单词的相互依赖关系。
当然,XLNet这种改造,维持了表面看上去的自回归语言模型的从左向右的模式,这个Bert做不到,这个有明显的好处,就是对于生成类的任务,能够在维持表面从左向右的生成过程前提下,模型里隐含了上下文的信息。所以看上去,XLNet貌似应该对于生成类型的NLP任务,会比Bert有明显优势。另外,因为XLNet还引入了Transformer XL的机制,所以对于长文档输入类型的NLP任务,也会比Bert有明显优势。
6. 代码实现
7. 参考文献
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
欢迎大家加入讨论!共同完善此项目!群号:【541954936】


若有收获,就点个赞吧
0 人点赞
