tf.keras 和 keras有什么区别?
作者:蔡善清
链接:https://www.zhihu.com/question/313111229/answer/606660552
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
要回答这个问题,首先需要简单谈一下keras的历史。keras是François Chollet于2014-2015年开始编写的开源高层深度学习API。所谓“高层”,是相对于“底层”运算而言(例如add,matmul,transpose,conv2d)。keras把这些底层运算封装成一些常用的神经网络模块类型(例如Dense, Conv2D, LSTM等),再加上像Model、Optimizer等的一些的抽象,来增强API的易用性和代码的可读性,提高深度学习开发者编写模型的效率。keras本身并不具备底层运算的能力,所以它需要和一个具备这种底层运算能力的backend(后端)协同工作。keras的特性之一就是可以互换的后端,你在所有后端上写的keras代码都是一样的。从一个后端训练并存储的模型,可以用别的后端加载并运行。
keras最初发行的时候,tensorflow还没有开源(fchollet开始写keras的时候还未加入Google)。那时的keras主要使用的是Theano后端。2015年底TensorFlow开源后,keras才开始搭建TensorFlow后端。今天TensorFlow是keras最常用的后端。
2016-2017年间,Google Brain组根据开源用户对TensorFlow易用性的反馈,决定采纳keras为首推、并内置支持的高层API。当时TensorFlow已经有tf.estimator、slim、sonnet、TensorLayers等诸多高层次API,选择keras主要是考虑它的优秀性以及在用户群中的受欢迎程度,不过那个是另一个故事线就不展开说了。
所以,keras的代码被逐渐吸收进入tensorflow的代码库,那时fchollet也加入了Google Brain组。所以就产生了tf.keras:一个不强调后端可互换性、和tensorflow更紧密整合、得到tensorflow其他组建更好支持、且符合keras标准的高层次API。
那keras和tf.keras到底有什么异同呢?下面我们先看一下共同点,再看一下不同点。
keras和tf.keras的主要共同点:
- 基于同一个API:如果不使用tf.keras的特有特性(见下文)的话,模型搭建、训练、和推断的代码应该是可以互换的。把import keras 换成from tensorflow import keras,所有功能都应该可以工作。反之则未必,因为tf.keras有一些keras不支持的特性,见下文。Google Brain组负责两个代码库之间的同步,每个代码库的重要bug fix和新特性,只要是后端无关的,都会被同步到另一个代码库。
- 相同的JSON和HDF5模型序列化格式和语义。从一方用model.to_json() 或model.save()保存的模型,可以在另一方加载并以同一语义运行。TensorFlow的生态里面那些支持HDF5或JSON格式的其他库,比如TensorFlow.js,也同等支持keras和tf.keras保存的模型。
keras和tf.keras的主要差别:
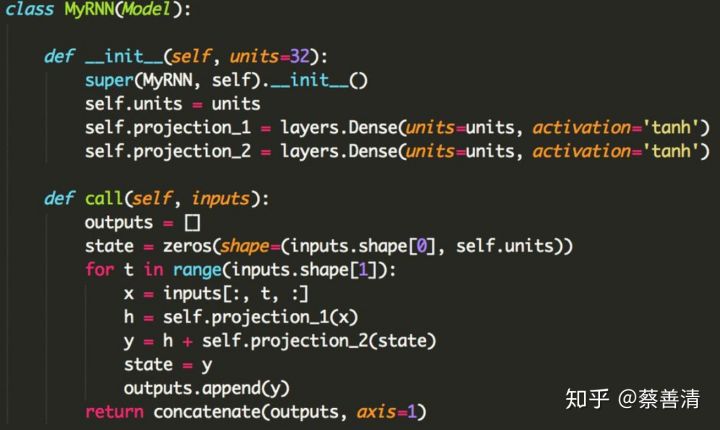
- tf.keras全面支持tensorflow的eager execution模式。eager execution是TensorFlow未来首推的另一个主要特性,也和易用性有关。但是这个对于tf.keras的用户有什么影响呢?如果你只是使用keras.Sequential()或keras.Model()的“乐高式”模型搭建API的话,这个没有影响。Eager execution相对于graph mode的性能劣势,通过tf.function的imperative-to-graph变换来弥补。但是你如果是要自己编写模型内部的运算逻辑的话,结合eager execution和tf.keras.Model方便动态模型的编写。下图里的代码实例展示了如何用这个API来编写一个动态RNN(图片来源:https://twitter.com/fchollet/status/1052228463300493312?lang=en)。这样写相对于仅仅使用tensorflow的底层API的好处,在于可以使用`tf.keras.Model`类型所提供的fit()、predict()等抽象。这个特性主要是面向做深度学习研究的用户。

2. tf.keras支持基于tf.data的模型训练。tf.data是TensorFlow自2017年初左右推出的新特性。由于基于lazy范式、使用了多线程数据输入管路,tf.data可以显著提高模型训练的效率,同时降低数据相关的代码的复杂性。tf.data带来的性能提高,对于TPU训练来说至关重要。tf.keras.Mode.fit()直接支持tf.data.Dataset 或iterator对象作为输入参数。比如这个MNIST训练例子:
https://gist.github.com/datlife/abfe263803691a8864b7a2d4f87c4ab8gist.github.com
tf.keras支持TPU训练。TPU是Google自己研发的深度学习模型训练加速硬件,现在在很多训练任务上持有State of the art的性能。用户可以用
tf.contrib.tpu.keras_to_tpu_model()将一个tf.keras.Model对象转换成一个可以在TPU上进行训练的模型对象。见以下例子:
https://colab.sandbox.google.com/github/tensorflow/tpu/blob/master/tools/colab/fashion_mnist.ipynbcolab.sandbox.google.comtf.keras支持tf.distribution里面的DistributionStrategy进行多GPU或多机分布式训练。tf.distribution是tensorflow里面比较新的API,提供一套易用的分布式训练的抽象,帮助用户实现多卡或多机模型训练。比如,keras用户应该知道,普通版的keras是不支持多GPU训练的。tf.keras可以克服这一局限,详见官方文档里面的例子:
https://www.tensorflow.org/guide/distribute_strategy#example_with_keras_apiwww.tensorflow.orgtf.keras的其他特有特性:
- tf.keras.models.model_to_estimator() :将模型转换成estimator对象 。见文档。
- tf.contrib.saved_model.save_keras_model():将模型保存为tensorflow的SavedModel格式。见文档。
那我应该选择keras还是tf.keras呢?
- 如果你需要任何一个上述tf.keras的特有特性的话,那当然应该选择tf.keras。
- 如果后端可互换性对你很重要的话,那选择keras。
- 如果以上两条对你都不重要的话,那选用哪个都可以。
希望以上有帮助。
————————
勘误和增补:
- 关于上面差异第4点:keras也支持多GPU训练,但是基于一个不同的API:keras.utils.multi_gpu_model

若有收获,就点个赞吧
0 人点赞
