来源:https://blog.csdn.net/baidu_39413110/article/details/103675096
GBM模型因其收敛快、精度高、数据预处理简单、方便部署等优势已经被金融风控领域所广泛使用。金融业务中常用的GBM模型有两种,XGBoost和LightGBM,两者算法原理基本一致,LightGBM不过是在XGB的基础上进行了些小调整,优化了空间和速度。很多时候在实际业务中,面对同一个模型需求,我们会在同一数据集上尝试两种建模方法,GBM和传统评分卡方法。一般情况下,GBM模型AUC都会比评分卡略高一些,最差也基本持平,因此,在对模型可解释性要求不是特别高的时候,我们往往会选择部署GBM模型。
使用GBM很简单,高度封装的xgboost和lightGBM三方库可兼容各个主流计算机语言,但我们使用这个工具的前提应该是对这个工具有充分的了解,或者读过源码,或者自己动手实现一下XGB算法,这样对算法过程和每个参数在哪个环节起到什么作用都会有一个更清晰的认识,关于XGB算法过程的python实现,可参看这篇博客:
【机器学习与算法】python手写算法:xgboost算法
一、数据预处理
训练XGB模型相比于训练逻辑回归评分卡的优势就在于数据预处理简单,但业务上哪些预处理过程能够简化,哪些又不建议简化呢?那这些过程又为什么可以省略呢?
1、相关性
XGB本质上是树模型结果的一个加和运算,既然是树模型,在分裂构造树的时候就只看增益,选取增益最大的变量进行分裂,变量间即便有高相关性,也不会对最终模型的训练和预测有啥影响。所以理论上,不需要对变量做相关性筛选。
变量相关性理论上不影响模型的训练和使用就不需要做筛选吗?不是的,如果带高相关性变量入模训练,至少在以下两个方面会造成影响:一是变量重要性。对于每个变量对最终模型的贡献,我们往往会参考xgboost自带的featureimportances属性(三种计算方式可供选择:增益、覆盖度、频次;最新版本xgb默认为增益)。如果高相关变量在入模变量中,很多变量的重要性排序就不具备参考意义,一些变量重要性排序很低可能仅仅是因为有个与其高相关的变量排在前面。第二就是模型的稳健性,由于我们需要控制最终入模变量不能过多,那如果最终入模变量很多都是高相关的,说明模型衡量风险的维度并没有那么丰富,维度不丰富就会影响模型的稳健性,使模型很难长期保持稳定有效。实际业务中很容易出现一个维度多个变量同时失效的情况,最终对模型效果造成很大影响。
所以,虽然相关性理论上不影响XGB模型的训练和使用,但基于业务考量,还是强烈建议对入模变量做相关性筛选。
2、类别型变量怎么处理
XGB模型是不接受类别型变量直接入模训练的,XGB作者对于不给XGB做类别型变量处理接口给出的解释是没有必要,类别型可以直接做独热编码处理。独热编码我们之前提到过不推荐使用,主要因为以下三个原因:
- 一是造成特征维度爆炸;
- 二是人为拆解变量,容易造成信息丢失;
- 三是容易让XGB里面的树结构更加不平衡,而且需要更深的树深去完成拟合。
对于第一点问题倒不大,因为XGB可以训练稀疏矩阵来加快训练速度,只需要使用scipy.sparse.csc_matrix函数把训练数据变成稀疏矩阵即可:
from spicy import sparsex_train_sparse = sparse.csc_matrix(x_train)import xgboost as xgbdtrain = xgb.DMatrix(x_train_sparse,y_train)
对于第二点,业务上更希望入模的变量是有实际业务含义的;对于第三点,模型会变得更复杂,而且树深过深也不利于我们控制过拟合。所以我们不推荐类别变量独热编码后直接入模训练的方式。
那推荐的方式是什么呢?参照评分卡训练,类别型变量可以做分箱和WOE转换。如果我们有一套现成的分箱和WOE转换工具,那直接这么做没有问题,如果没有现成工具,其实也不用特意麻烦自己去寻找最优分箱点再计算WOE,直接把每个类别用其对应的坏账率来替换,然后放到XGB模型里让模型自己去寻找最优分割点也是一样的效果。
如果我们使用的是LightGBM模型的话,我们甚至都不需要耗费精力自己对类别型变量做坏账转换,LGBM提供了处理类别型变量的接口,直接在predict的时候指定下哪些是类别型变量,然后让模型自己处理就好了:
cat_features = [...]#lgbm要求最好把类别型变量的每个类别转换为从0开始编号的整数,负数编号将被lgbm当做缺失处理for item in cat_features:df[item] = df[item].astype('category').cat.codesfrom lightgbm.sklearn import LGBMRegressor as lgblgb.predict(X,Y,categorical_feature=cat_features)
lgbm对类别型变量具体怎么处理的呢?其实是把每个类别按照sum_gradient / sum_hessian指标进行排序,然后在排序后的histogram里寻找最优分裂点,sum_gradient / sum_hessian就是目标函数一阶导的加和除以二阶导的加和,具体请参看官方文档。
当然,如果你对类别型有更高的处理要求,以及还想看下特征组合能对整体模型效果提升多少,那还可以尝试下Catboost。
二、怎么调参
我们调参一般是为了解决两个问题:一是控制过拟合,二是想通过调参把模型效果再提升一些。但说句实话,调参在解决这两个问题上最多起到一个锦上添花的作用,不解决本质问题(前提是初始参数设置的不离谱)。
解决XGB模型过拟合问题,最重要的还是要看两点,一是样本量,给足训练样本是解决XGB过拟合最有效的手段,没有真实样本可以考虑采样样本。二是入模变量本身的稳定性,具体变量筛选原则可以参考风控建模三:变量筛选原则。
当然在最终入模变量确定后,我们还是需要在模型结构上再探索一下提升空间,虽然提升有限,但也还是要花点时间找到一套最优参数。
1、锚定调参目标
调参锚定什么目标,代表了我们要寻找哪个数据集上面的最优参数。一般做法是会把训练集分5折,4折训练然后1折拿来验证,如此搞5次,最后把5个验证集上的平均表现作为我们锚定的目标,即找到在5个验证集上平均最优的参数。这样做既考虑了泛化性又不至于泄露test和oot数据集上的信息。
那真的不能泄露test和oot数据集上的信息吗?尤其是我们选定了比较新的样本做test和oot的时候,为什么不能锚定test和oot呢?如果我们找到一套参数,它不一定是训练集上的最优参数,但在比较新的样本上表现最好,那不是更具有泛化性而且更符合我们的业务预期吗?个人认为是完全可以锚定test和oot去调参的,但有个前提是有更新更长的时段去做充分验证模型的有效性,如此也能保证模型在长时间段上是稳定的。
2、网格搜索调参
网格搜索是调参常用方法之一,即在一套经验参数的交叉组合中去寻找最优解,这个方法的缺点就是每增加一个要调的参数,花费的时间就指数级增长。所以网格搜索调参最好就只挑几个关键参数,依据经验也不要给太多可选项。比如XGB里面的树深max_depth参数,由于XGB本来就是弱分类器的不断增强,所以没必要把每棵树搞得特别复杂,所以一般树深控制在2-4足够了。实操上常用的做法是先给个大范围的参数选择,然后多搜索几轮,不断缩小参数范围。
from sklearn.grid_search import GridSearchCVfrom xgboost import XGBClassifierp_grid={'max_depth':list((2,3,4)),'n_estimators':list((200,300,400))grid=GridSearchCV(XGBClassifier(),param_grid=p_grid,cv=5)grid.fit(x,y)print(grid.grid_scores_,grid.best_params_,grid.best_score_)
3、贝叶斯调参
相比于网格搜索的暴力求解法,贝叶斯调参则转换了一种思路,其基本思想是把模型表现作为一个随超参数变化的函数,然后在域空间里面寻找一个使目标函数值最大的最优解。其采用了Tree-structured Parzen Estimator优化算法求解最优解,简单来讲就是采用高斯过程,考虑之前的参数信息,不断地更新先验,不断逼近最优解。具体算法过程可以参考这篇paper。一般我们使用python里面的Hyperopt三方库来实现贝叶斯调参过程:
首先,定义目标函数,这里我们把训练集X分5折,每次4折训练,1折验证,并把5次验证集上的auc平均值作为我们要优化的目标,这里我们通过定义一个aucscore函数来实现,函数的入参为一个dict,包含我们需要调的参数,函数返回auc均值的负数,因为hyperopt做的是最小化函数优化过程。
from hyperopt import fmin, tpe, hpimport lightgbm as lgbfrom sklearn.metrics import roc_curve,auckf = KFold(n_splits=5,random_state=100, shuffle=True)def aucscore(args):print(args)AUC = []for train_index, test_index in kf.split(X):x_train_kf, x_test_kf = X.iloc[train_index], X.iloc[test_index]y_train_kf, y_test_kf = Y.iloc[train_index], Y.iloc[test_index]lgbm_model = LGBMRegressor(learning_rate =args['learning_rate'],n_estimators=args['n_estimator'],max_depth=args['max_depth'],objective= 'binary',seed=100)lgbm_model.fit(x_train_kf,y_train_kf)y_pred_test = lgbm_model.predict(x_test_kf)false_positive_rate, recall, thresholds = roc_curve(y_test_kf, y_pred_test)AUC += [auc(false_positive_rate, recall)]score = np.mean(np.array(AUC))return -score
然后,定义域空间,即我们要搜索的参数范围:
para_space_mlp={'learning_rate':hp.quniform('learning_rate',0.05,0.1,0.001),'n_estimator':hp.quniform('n_estimator',300,500,20),'max_depth':hp.quniform('max_depth',2,4,1)}
最后,在定义域范围内,进行迭代优化,并返回最优解:
best = fmin(aucscore, para_space_mlp, algo=tpe.suggest, max_evals=100, rstate=np.random.RandomState(100))print(best['learning_rate'],best['n_estimator'],best['max_depth'])
理论上来讲,贝叶斯调参会比网格搜索调参快很多,但如果我们设置太多参数,范围过大的时候,即便使用贝叶斯调参,需要耗费的内存和时间也是相当大的。所以建议在设定域空间的时候,也要结合之前训练模型的经验,尽量缩小域空间范围。
三、解释性
机器学习模型常常被人诟病的一点就是解释性不强,不能够像逻辑回归评分卡一样,把每个样本的每个特征对最后得分的贡献给量化出来。虽然XGB或LGBM本身不能够做到这一点,但确实有一些工具能够帮助我们对机器学习的模型进行解释。
1、SHAP
SHAP全称SHapley Additive exPlanations,是一种基于博弈论构建的加性解释模型。其基本的思想就是考虑所有特征的所有可能组合,比如三个特征可以构建出8种可能组合(包括无变量、单变量、两两组合、三个变量),构建8个预测模型对结果进行预测,然后通过衡量各模型间增加每个单变量时对预测结果带来的边际贡献,来确定每个特征的作用。这里每个特征的贡献最终用SHAP值来量化,对于一个样本,我们把它每个变量的SHAP值相加,就能得到这个样本的预测结果与基模型结果(所有y的均值)的差异。对于SHAP的计算过程和原理,理解用于计算SHAP值的公式这篇文章写得非常清楚简洁。
下面我们来看下怎么应用。SHAP直接提供了python的可安装包,直接pip install shap就可以了。我们以波士顿房价预测数据来看下:
import shapimport xgboostshap.initjs()X,y = shap.datasets.boston()model = xgboost.train({"learning_rate": 0.01}, xgboost.DMatrix(X, label=y), 100)#初始化一个explainerexplainer = shap.TreeExplainer(model)#传入X数据进行SHAP值计算shap_values = explainer.shap_values(X)#直接可视化第一个样本的解释shap.force_plot(explainer.expected_value, shap_values[0,:], X.iloc[0,:])

图中对第一个样本每个变量的贡献给出了量化解释,其中红色的特征表示正向贡献的特征,即这个变量会在基本值(所有预测均值)的基础上,推高这个样本的预测值,这个变量在图中所占的宽度,表示了这个变量把预测值推高的幅度(也就是这个变量的SHAP值)。当然,蓝色的都是负向变量。
这个样本最终的预测为16.49,高于平均水平(平均值可以通过explainer.expected_value查看,为14.23),图中我们一眼就可以看到这个样本房价预测偏高的最主要原因就是LSTAT这个变量,这个变量表示人口中地位低下者的比例,均值为12.65,这个变量仅为4.98,明显低于平均水平,从业务逻辑上来讲,一个地区地位低下者占比越少,自然房价也越高。
再来看个负向变量,RM房间数,整个样本的RM均值为6.28,这个样本的RM为6.57,比平均还是高一些的,怎么成了负向变量了?我们刚刚分析了LSTAT这个变量了,其实这个时候就要看在同一LSTAT水平上,这个样本RM还是不是占优势,当计算了所有LSTAT小于5的样本的RM均值后,发现RM平均在7.23,果然,在同LSTAT水平下,这个样本还真算小房子,房价自然相对低一些,所以RM在这个样本上也就成了负向变量了。
SHAP还可以帮助我们计算每个特征在模型中的整体重要性,计算方式就是把每个样本的该特征的SHAP值的绝对值取平均,可以通过这个语句查看变量重要性:
shap.summary_plot(shap_values, X, plot_type=”bar”)
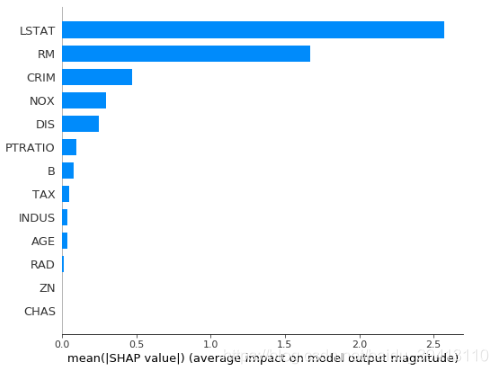
当然,SHAP还有很多其他功能,包括变量相互作用等等,具体可以参考官方介绍。
2、LIME
LIME是Local Interpretable Model-Agnostic Explanations的缩写,是一种对模型局部进行解释的方法。其基本思想就是不对模型内部结构做深入探究,对于要解释的样本点,我们通过在其附近邻域内取一些扰动点输入模型,观察模型输出的变动,并根据此在该样本点附近建立一个可解释模型(比如回归或树模型),来达到解释单个样本的效果。具体原理和计算过程可以参考模型解释-LIME的原理和实现
基于此原理的LIME可以解释任何模型,不论结构多复杂,适用性非常广,但是这种方法也有明显缺陷,一是需要确定邻域,选择的邻域范围不同可能导致最终解释结果大相径庭,二是结果并不十分稳定。
LIIME同样提供了直接供安装的python包(pip install lime),我们通过鸢尾花数据来看下LIME的实现方式:
import limeimport lime.lime_tabularfrom sklearn import datasetsfrom xgboost import XGBClassifier as xgbiris = datasets.load_iris()X,y = iris.data, iris.targetmodel = xgb(learning_rate=0.1,n_estimators=300)model.fit(X,y)#自定义一个函数,输入预测样本,输出预测概率predict_fn_xgb = lambda x: model.predict_proba(x).astype(float)#初始化一个LIME解释器,kernel_width控制模型线性度,宽度越大,线性越大explainer = lime.lime_tabular.LimeTabularExplainer(X ,feature_names = iris.feature_names,class_names=iris.target_names, kernel_width=3)#解释第60个样本并展示结果exp = explainer.explain_instance(X[60], predict_fn_xgb, num_features=5)exp.show_in_notebook(show_all=True)

如图,LIME给出了模型预测属于每个类别的概率,并量化出了导致这种预测结果的每个变量的贡献,对于此样本,模型给出了它属于versicolor的概率为98%,主要原因是因为petal length大于1.6,其中petal length和petal width两个变量都是使模型预测为versicolor的正向变量,而sepal width和sepal length都是负向变量,但是作用很小。
四、模型保存、打分及部署
想要我们训练定稿的模型最终能应用到决策引擎中去做实时决策,就需要我们把模型部署上线,这项工作通常由风控业务部门和技术开发团队共同完成,风控业务方一般会通过下面两种方式将模型做一个承接:
1、生成model文件
生成model文件是最常见的方式,不仅方便自己保存模型,用于后续的比较和打分,同时也可以让开发团队通过model文件转换为pmml文件做线上部署:
from lightgbm.sklearn import LGBMRegressorlgbm_model = LGBMRegressor()lgbm_model.fit(X, Y, eval_metric='auc')lgbm_model.booster_.save_model('./lgbm.model')
这里要重点强调一下,读取model文件打分是不会根据我们数据的变量名去挨个匹配变量的,它会自动按照我们训练时的变量顺序把变量重命名为f0到fn,所以下次读取model文件并打分的时候,一定要保证打分集变量的顺序和我们之前训练模型时的变量顺序完全一致,否则模型也是会正常打分的,但打分全是错的。
import lightgbm as lgblgbm_model = lgb.Booster(model_file='./lgbm.model')#注意这里的ordered_feature跟训练时的变量顺序一定要一致preds = lgbm_model.predict(oot[ordered_feature])
xgb其实也可以保存model文件,但要小心。如果我们使用的xgb版本在0.6以上,大家不妨亲自对比一下用训练好的模型直接打分,和保存model文件,再读取model文件对同一数据集打分,两者是不是完全一致。
2、生成pmml文件
既然模型上线最终是要转换为pmml文件的,那我们在训练模型的时候直接保存pmml文件,也就避免了来回转换,简化了流程,在训练xgb的时候,我们可以通过sklearn2pmml三方包直接生成pmml文件:
from xgboost import XGBClassifierfrom sklearn_pandas import DataFrameMapperimport picklefrom sklearn2pmml import sklearn2pmml, PMMLPipelinexgb_clf = XGBClassifier()#sklearn2pmml只支持对pipeline的一个pmml转换,所以我们先生成一个pipeline,第一步default_mapper啥都不做就可以default_mapper = DataFrameMapper([(i, None) for i in X.columns])pipeline = PMMLPipeline([("mapper", default_mapper), ("classifier", xgb_clf)])eval_set = [(X_valid, Y_valid)]params = {"classifier__eval_set":eval_set,"classifier__early_stopping_rounds": 50,"classifier__eval_metric":'auc'}pipeline.fit(pd.concat([X, y], axis=1), y, **params)#封装成pipeline不方便存储model文件,那我们可以存pickle文件,效果一样with open('./xgb.pkl', 'wb') as f:pickle.dump(pipeline, f)#最后生成pmml文件sklearn2pmml(pipeline, './xgb.pmml', with_repr = True)
这里为了生成pmml文件而强行把model封装到了一个pipeline里了,不方便留存model文件,但没关系,可以留存pickle文件,而且下次载入pickle文件并打分的时候,不像model文件,它是会自动根据变量名去匹配变量的,所以即便我们的打分集变量顺序乱了,只要变量名是对的,打分就没有问题。
五、建模注意小细节
数据分析和建模工作是个对细致和耐心需求很高的工作,数据处理中可谓处处都有坑,处处都可能出纰漏。这里总结几点平时工作中很容易出问题的地方:
- y标签要记得实时更新
我们建模前期往往会对各种建模方案进行各种尝试,以期找到效果最优结果(关于建模方案拟定可以参考风控建模二:建模方案拟定),这个过程总是要花费些时间的,当我们最终确定了建模方案后,在开始建模前,要记得更新一下最新的表现标签,可以把更多表现到期的人囊括进来,这在我们使用较新样本建模和数据量不大时尤为关键,搞不好数据能多一半。
整理数据的时候越全越好
在前期整理建模数据时候,最好不要只把好坏样本整理出来,而把灰样本全不管了。整理样本越全越好,灰样本放进来,如果空间允许最好把拒绝样本也整理出来。如此会给我们后面建模带来很多方便,比如更新y标签的时候我们只需要重新匹配一下y就可以得到最新的建模样本,不需要根据最新的y再从头整理数据;再比如看每个变量进件长期趋势的时候,就可以直接取数。
保存数据尽量使用tab分隔
- 很多时候我们整理好的数据存成csv后,再read_csv的时候发现读不进来了,报了个行数不一样的错误,这个时候往往是因为某个字符型变量中本身带逗号导致的(比如经纬度[120.34, 35]),这样就会混淆csv本身的逗号分隔符。所以建议存数据的时候使用sep=’\t’做分隔,可以避免这种问题。
当然读写数据往往非常耗时,这时候不妨试试read_feather这个函数,相比read_csv,速度绝对飞一般的感觉。
核对是否所有变量都用上了
在建模数据整理完成后,一定要核对下变量数,像业务中的数据动辄上千维,n个表,最后不核对一下,谁能保证所有可用变量都在数据集里了。别到了模型都定稿了发现有些重要变量漏了,不是很尴尬。
实时追踪模型效果,及时调整问题变量
- 模型定稿、提需、上线开发、核对总要花些时间的,尤其遇到复杂变量的开发更是耗费时间,这段时间记得实时更新表现数据,实时跟踪模型效果,可以及时发现失效变量,在模型真正决策前做出恰当调整。
————————————————
版权声明:本文为CSDN博主「白白的一团团」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/baidu_39413110/article/details/103675096

若有收获,就点个赞吧
0 人点赞
