- -- coding: utf-8 --
import pandas as pd - 用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i])) - 拉格朗日插值代码
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数 - 自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果 - 逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j) - 参数初始化
inputfile= ‘../data/leleccum.mat’ #提取自Matlab的信号文件 - 参数初始化
inputfile = ‘../data/sales_data.xls’
data = pd.read_excel(inputfile, index_col = u’序号’) #导入数据 - 数据是类别标签,要将它转换为数据
#用1来表示“好”、“是”、“高”这三个属性,用0来表示“坏”、“否”、“低”
data[data == u’好’] = 1
data[data == u’是’] = 1
data[data == u’高’] = 1
data[data != 1] = 0
x = data.iloc[:,:3].values.astype(int)
y = data.iloc[:,3].values.astype(int) - 修改后
model = Sequential() #建立模型
#model.add(Dense(input_dim = 3, output_dim = 10))
model.add(Dense(units=10, input_dim=3)) - model.add(Dense(input_dim = 10, output_dim = 1))
model.add(Dense(input_dim=10, units=1)) - model.fit(x, y, nb_epoch = 1000, batch_size = 10) #训练模型,学习一千次
model.fit(x, y, epochs=1000, batch_size=10)
Python 数据挖掘实战小结 v1.0
一、异常值发现——箱线图
-- coding: utf-8 --
import pandas as pd
catering_sale = ‘../data/catering_sale.xls’ #餐饮数据
data = pd.read_excel(catering_sale, index_col = u’日期’) #读取数据,指定“日期”列为索引列
import matplotlib.pyplot as plt #导入图像库
plt.rcParams[‘font.sans-serif’] = [‘SimHei’] #用来正常显示中文标签
plt.rcParams[‘axes.unicode_minus’] = False #用来正常显示负号
plt.figure() #建立图像
p = data.boxplot(return_type=’dict’) #画箱线图,直接使用DataFrame的方法
x = p[‘fliers’][0].get_xdata() # ‘flies’即为异常值的标签
y = p[‘fliers’][0].get_ydata()
y.sort() #从小到大排序,该方法直接改变原对象
用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱线图
二、缺失值处理
拉格朗日插值代码
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = ‘../data/catering_sale.xls’ #销量数据路径
outputfile = ‘../tmp/sales.xls’ #输出数据路径
data = pd.read_excel(inputfile) #读入数据
data[u’销量’][(data[u’销量’] < 400) | (data[u’销量’] > 5000)] = None #过滤异常值,将其变为空值
自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果
逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile) #输出结果,写入文件
小波变换>>特征提取
#-- coding: utf-8 --
#利用小波分析进行特征分析
参数初始化
inputfile= ‘../data/leleccum.mat’ #提取自Matlab的信号文件
from scipy.io import loadmat #mat是MATLAB专用格式,需要用loadmat读取它
mat = loadmat(inputfile)
signal = mat[‘leleccum’][0]
import pywt #导入PyWavelets
coeffs = pywt.wavedec(signal, ‘bior3.7’, level = 5)
#返回结果为level+1个数字,第一个数组为逼近系数数组,后面的依次是细节系数数组
三、降维
PCA主成分分析
from sklearn.decomposition import PCA
pca = PCA(ncomponents=4) #降维到4维
pca.fit(data)
pca.components #返回模型的各个特征向量
pca.explainedvariance_ratio #返回各个成分各自的方差百分比
四、分类与预测
回归分析
决策树
神经网络
贝叶斯网络
支持向量机

岭回归适用于自变量间有多重共线性
决策树
ID3算法基于信息熵来选择最佳测试属性。
它选择当前样本集中具有最大信息增益值的属性作为测试属性

神经网络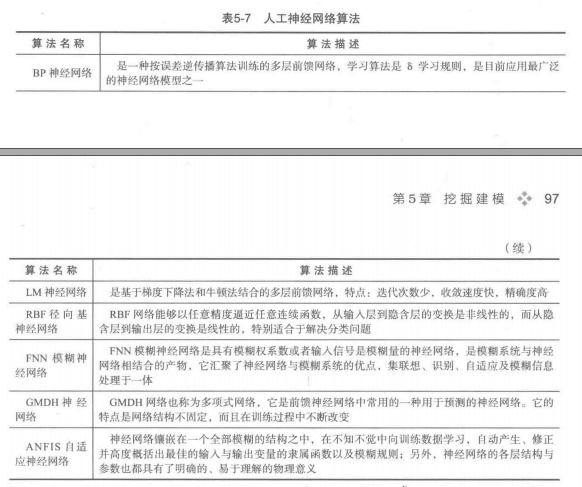
BP神经网络代码
#-- coding: utf-8 --
#使用神经网络算法预测销量高低
import pandas as pd
参数初始化
inputfile = ‘../data/sales_data.xls’
data = pd.read_excel(inputfile, index_col = u’序号’) #导入数据
数据是类别标签,要将它转换为数据
#用1来表示“好”、“是”、“高”这三个属性,用0来表示“坏”、“否”、“低”
data[data == u’好’] = 1
data[data == u’是’] = 1
data[data == u’高’] = 1
data[data != 1] = 0
x = data.iloc[:,:3].values.astype(int)
y = data.iloc[:,3].values.astype(int)
from keras.models import Sequential
from keras.layers.core import Dense, Activation
“””
model = Sequential() #建立模型
model.add(Dense(input_dim = 3, output_dim = 10))
model.add(Activation(‘relu’)) #用relu函数作为激活函数,能够大幅提供准确度
model.add(Dense(input_dim = 10, output_dim = 1))
model.add(Activation(‘sigmoid’)) #由于是0-1输出,用sigmoid函数作为激活函数
“””
修改后
model = Sequential() #建立模型
#model.add(Dense(input_dim = 3, output_dim = 10))
model.add(Dense(units=10, input_dim=3))
model.add(Activation(‘relu’)) #用relu函数作为激活函数,能够大幅提供准确度
model.add(Dense(input_dim = 10, output_dim = 1))
model.add(Dense(input_dim=10, units=1))
model.add(Activation(‘sigmoid’)) #由于是0-1输出,用sigmoid函数作为激活函数
model.compile(loss = ‘binary_crossentropy’, optimizer = ‘adam’)
#编译模型。由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy,以及模式为binary
#另外常见的损失函数还有mean_squared_error、categorical_crossentropy等,请阅读帮助文件。
#求解方法我们指定用adam,还有sgd、rmsprop等可选
model.fit(x, y, nb_epoch = 1000, batch_size = 10) #训练模型,学习一千次
model.fit(x, y, epochs=1000, batch_size=10)
yp = model.predict_classes(x).reshape(len(y)) #分类预测
from cm_plot import * #导入自行编写的混淆矩阵可视化函数
cm_plot(y,yp).show() #显示混淆矩阵可视化结果


聚类分析
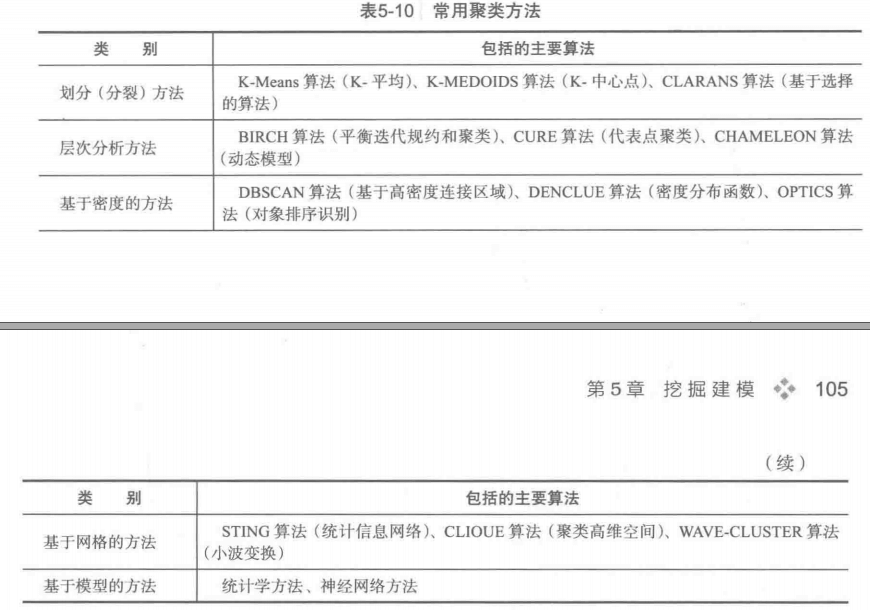
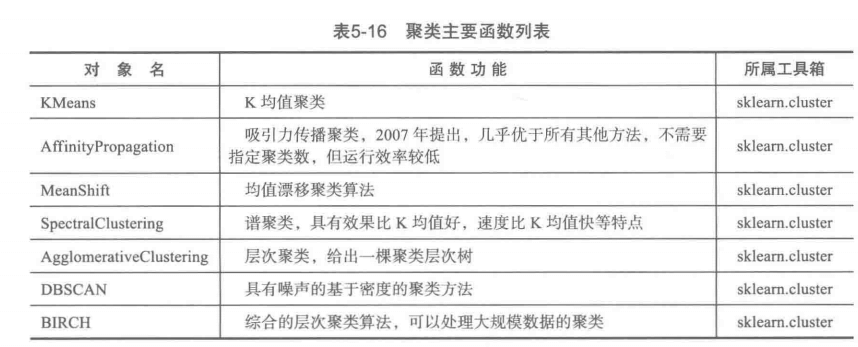

关联规则
时序模型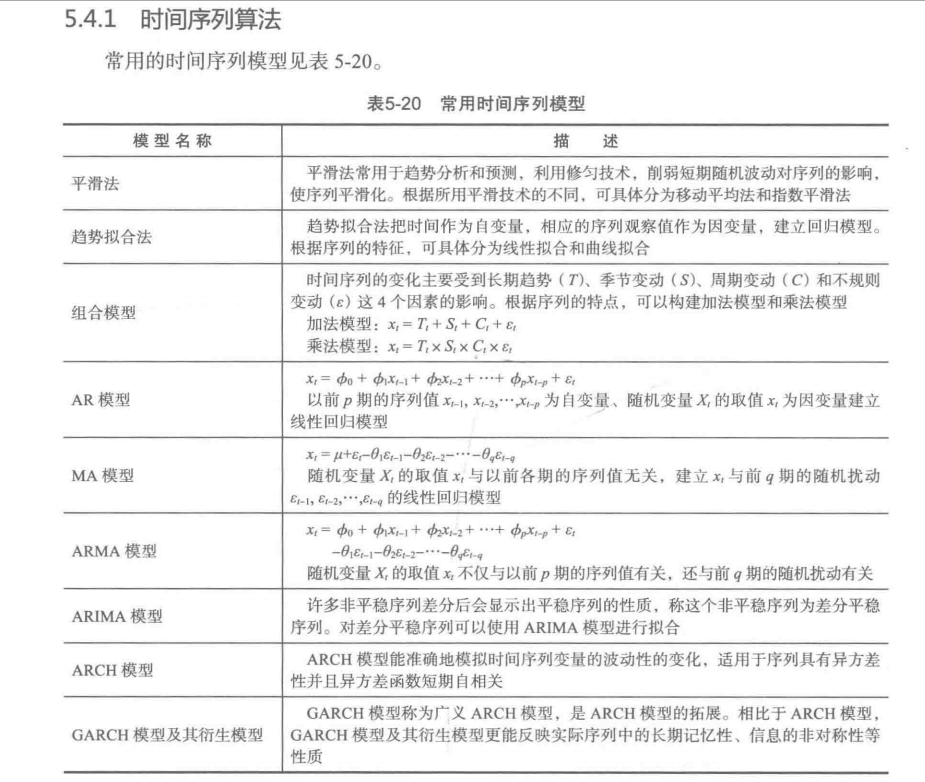
离群点检测

若有收获,就点个赞吧
0 人点赞
