数据库技术分享(进阶)
(Postgresql,Oracle,Hive和MySql)
Hive
简介
Hive是建立在 Hadoop 上的数据仓库基础构架,起源于Facebook(一个美国的社交服务网络)。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive体系结构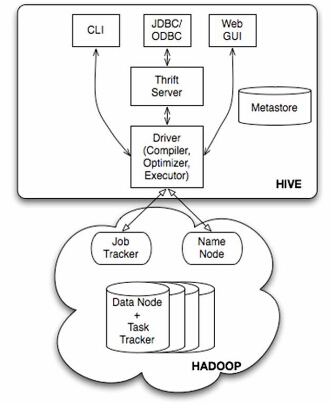
数据存储
Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
其次,Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
内部表:
•什么是内部表需要对比外部表来看
•删表时数据和表一起删除
外部表:
•数据已经存在于HDFS
•外部表只是走一个过程,加载数据和创建表同时完成,不会移动到数据仓库目录中,仅仅是和数据建立了一个连接
•删表表不会删除数据
内部表外部表区分:
在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而内部表表则不一样;在删除内部表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
分区表:
•在Hive Select查询中,一般会扫描整个表内容,会消耗很多时间做没必要的工作。 分区表指的是在创建表时,指定partition的分区空间。扫描时可以只扫描某一个分区的数据
•分区表存储时分局所设立的分区分别存储数据(分区字段就是一个文件夹的标识)
桶表:
•对于每一个表(table)或者分区,Hive可以进一步组织成桶,也就是说捅是更为细粒度的数据范困划分。
优缺点
优点:
- 可扩展:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统)
- 延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
- 容错:良好的容错性,节点出现问题SQL仍可完成执行
缺点:
- hive的效率比较低
- hive调优比较困难,粒度较粗
常用函数
| 数学函数 | | | —- | —- | | 函数名 | 作用 | | round(double d, int n) | 返回保留n位小数的近似d值 | | floor(double d) | 返回小于d的最大整值 | | ceil(double d) | 返回大于d的最小整值 | | rand(int seed) | 返回随机数,seed是随机因子 | | bin(int d) | 计算二进制值d的string值 |
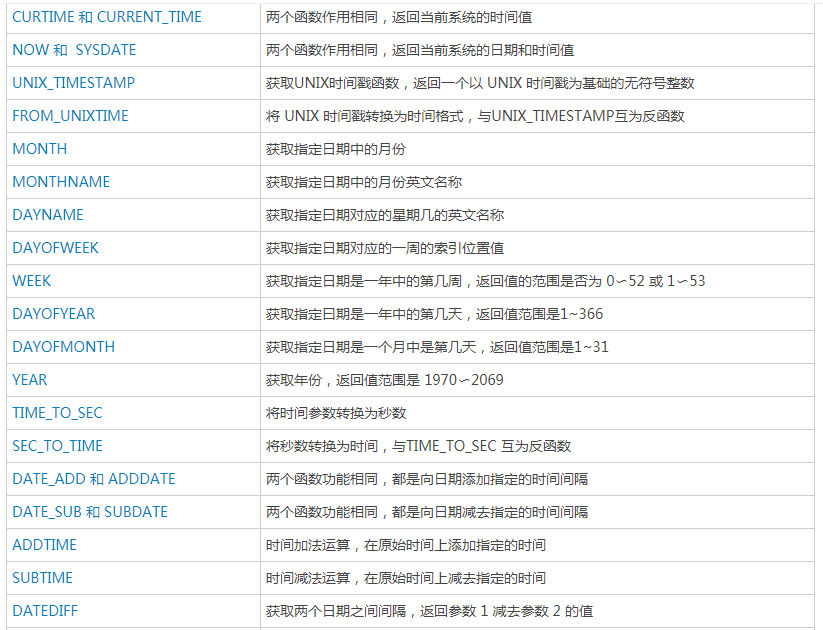
| 日期函数 | |
|---|---|
| 函数名 | 作用 |
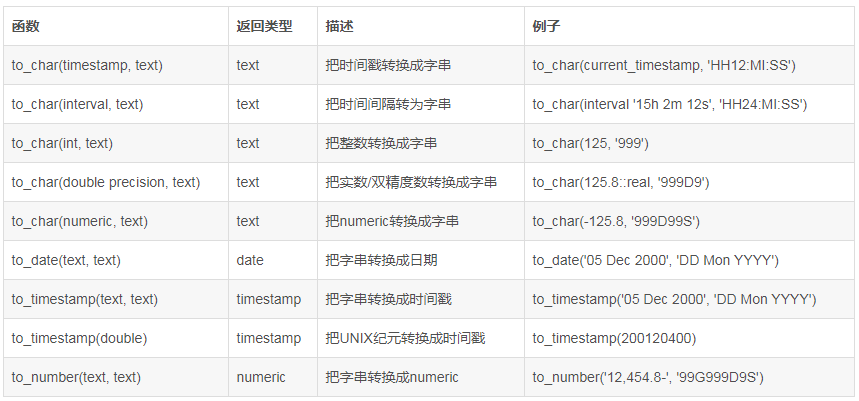
| to_date(string timestamp) | 返回时间字符串中的日期部分 |
| current_date | 返回当前日期 |
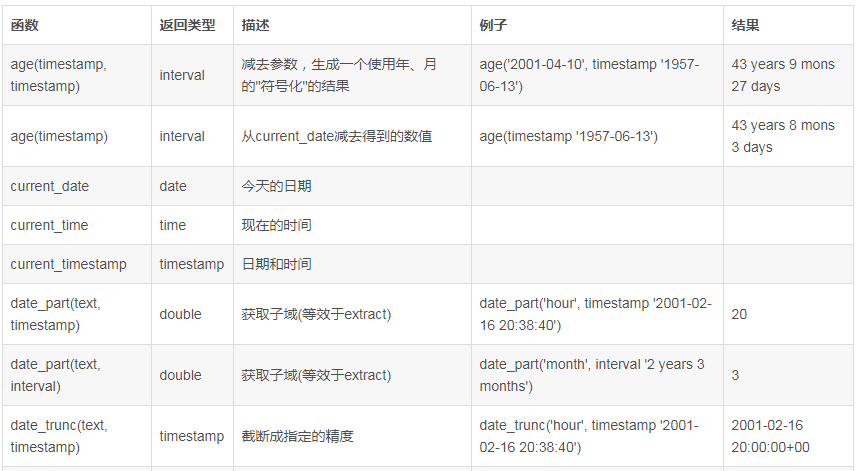
| year(date) | 返回日期date的年,类型为int |
| month(date) | 返回日期date的月,类型为int |
| day(date) | 返回日期date的天,类型为int |
| weekofyear(date1) | 返回日期date1位于该年第几周 |
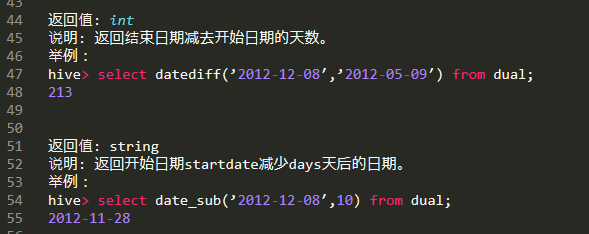
| datediff(date1,date2) | 返回日期date1与date2相差的天数 |
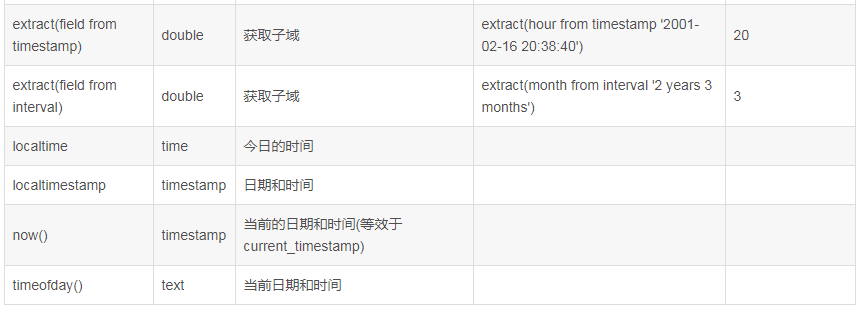
| date_add(date1,int1) | 返回日期date1加上int1的日期 |
| date_sub(date1,int1) | 返回日期date1减去int1的日期 |
| months_between(date1,date2) | 返回date1与date2相差月份 |
| add_months(date1,int1) | 返回date1加上int1个月的日期,int1可为负数 |
| last_day(date1) | 返回date1所在月份最后一天 |
| next_day(date1,day1) | 返回日期date1的下个星期day1的日期。day1为星期X的英文前两字母 |
| trunc(date1,string1) | 返回日期最开始年份或月份。string1可为年(YYYY/YY/YEAR)或月(MONTH/MON/MM)。 |
| unix_timestamp() | 返回当前时间的unix时间戳,可指定日期格式 |
| from_unixtime() | 返回unix时间戳的日期,可指定格式。 |
| 条件函数 | |
|---|---|
| 函数名 | 作用 |
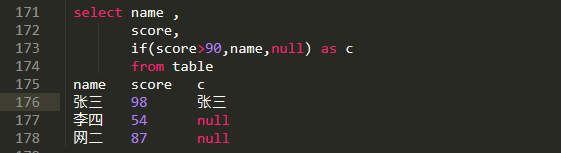
| if(boolean,t1,t2) | 若布尔值成立,则返回t1,反正返回t2 |
| case when boolean then t1 else t2 end | 若布尔值成立,则t1,否则t2,可加多重判断 |
| coalesce(v0,v1,v2) | 返回参数中的第一个非空值,若所有值均为null,则返回null |
| isnull(a) | 若a为null则返回true,否则返回false |
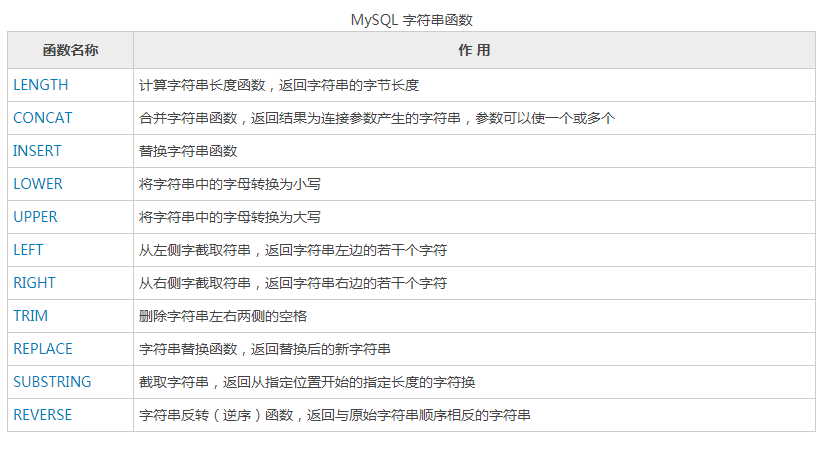
| 字符串函数 | |
|---|---|
| 函数名 | 作用 |
| length(string1) | 返回字符串长度 |
| concat(string1,string2) | 返回拼接string1及string2后的字符串 |
| concat_ws(sep,string1,string2) | 返回按指定分隔符拼接的字符串 |
| lower(string1) | 返回小写字符串,同lcase(string1)。upper()/ucase():返回大写字符串 |
| trim(string1) | 去字符串左右空格,ltrim(string1)去字符串左空格。 |
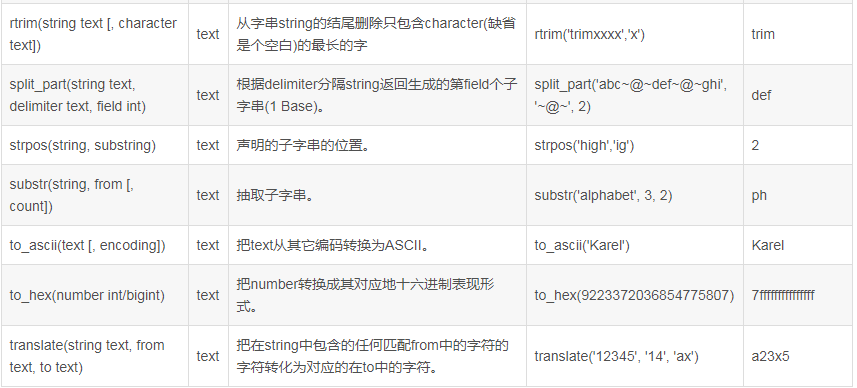
| rtrim(string1) | 去字符串右空格 |
| repeat(string1,int1) | 返回重复string1字符串int1次后的字符串 |
| reverse(string1) | 返回string1反转后的字符串 |
| rpad(string1,len1,pad1) | 以pad1字符右填充string1字符串,至len1长度以pat1正则分隔字符串string1,返回数组 |
| substr(string1,index1,int1) | 以index位置起截取int1个字符 |
| 聚合函数 | |
|---|---|
| 函数名 | 作用 |
| count() | 统计行数 |
| sum(col1) | 统计指定列和 |
| avg(col1) | 统计指定列平均值 |
| min(col1) | 返回指定列最小值 |
| max(col1) | 返回指定列最大值 |
| 表生成函数 | |
|---|---|
| 函数名 | 作用 |
| explode (array) | 返回多行array中对应的元素 |
| explode(map) | 返回多行map键值对对应元素 |
| 窗口函数 | |
|---|---|
| 函数名 | 作用 |
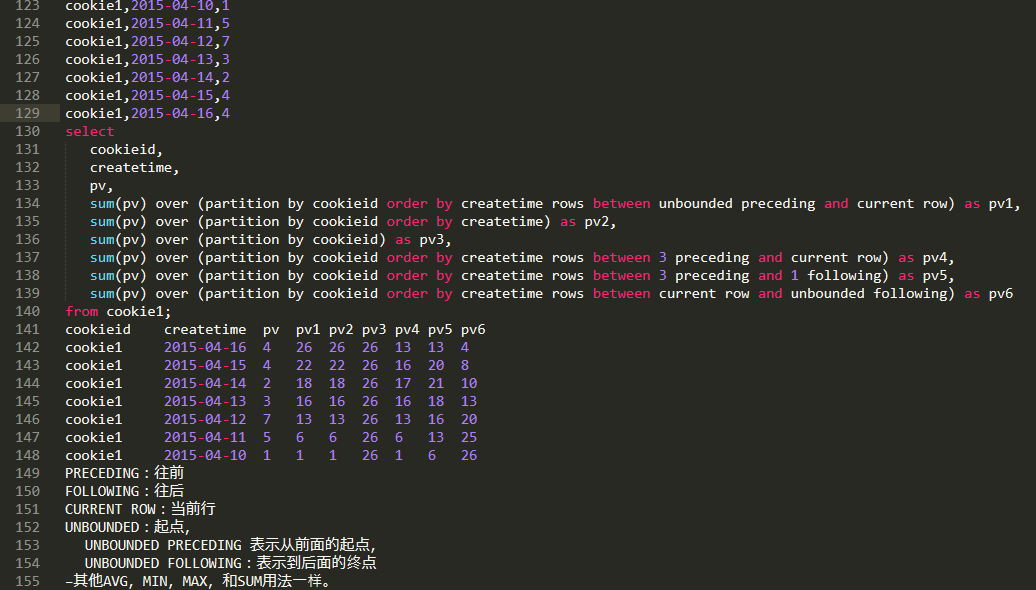
| row_number() over(partitiion by .. order by .. ) | 根据partition排序,相同值取不同序号,不存在序号跳跃 |
| rank() over(partition by .. order by .) | 根据partition排序,相同值取相同序号,存在序号跳跃 |
| dense_rank() over(partition by .. order by ..) | 根据partition排序,相同值取相同序号,不存在序号跳跃 |
| sum() over(partition by .. order by ..) | 根据partition排序,分组求和 |
| count() over(partition by .. order by ..) | 根据partition排序,分组计数 |
| lag(col,n) over(partition by .. order by ..) | 查看当前行的上第n行 |
| lead(col,n) over(partition by .. order by ..) | 查看当前行的下第n行 |
| first_value() over(partition by .. order by ..) | 满足partition及排序的第一个值 |
| last_value() over(partition by .. order by ..) | 满足partition及排序的最后值 |
| ntile(n) over(partition by .. order by ..) | 满足partition及排序的数据分成n份 |
| 行转列函数 | |
|---|---|
| 函数名 | 作用 |
| concat_ws(sep, collect_set(col1)) | 同组不同行合并成一列,以sep分隔符分隔。collect_set在无重复的情况下也可以collect_list()代替。collect_set()去重,collect_list()不去重 |
| lateral view explode(split(col1,’,’)) | 同组同列的数据拆分成多行,以sep分隔符区分 |
Postgresql
简介
PostgreSQL是以加州大学伯克利分校计算机系开发的 POSTGRES,现在已经更名为PostgreSQL,版本 4.2为基础的对象关系型数据库管理系统(ORDBMS)。PostgreSQL支持大部分 SQL标准并且提供了许多其他现代特性:复杂查询、外键、触发器、视图、事务完整性、MVCC。
PostgreSQL是一个功能强大的开源对象关系数据库管理系统(ORDBMS)。 用于安全地存储数据; 支持最佳做法,并允许在处理请求时检索它们。
PostgreSQL(也称为Post-gress-Q-L)由PostgreSQL全球开发集团(全球志愿者团队)开发。 它不受任何公司或其他私人实体控制。 它是开源的,其源代码是免费提供的。
PostgreSQL是跨平台的,可以在许多操作系统上运行,如Linux,OS X和Microsoft Windows等。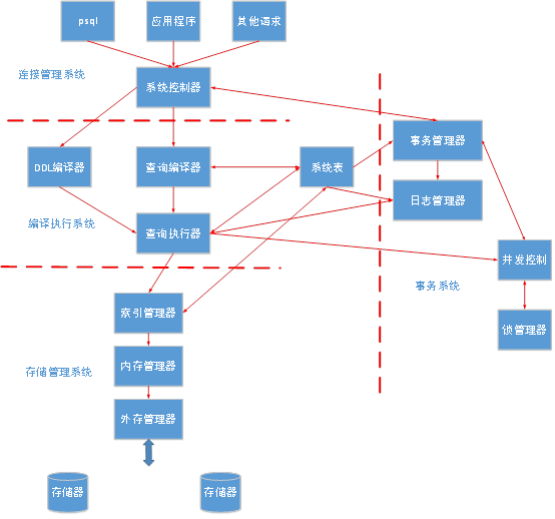
连接管理系统接受外部操作对系统的请求,对操作请求进行预处理和分发,起系统逻辑控制作用;
编译执行系统由查询编译器,查询执行器组成,完成操作请求在数据库中的分析处理和转化工作,最终实现物理存储介质中数据的操作;
存储管理系统由索引管理器,内存管理器,外存管理器组成,负责存储和管理物理数据,提供对编译查询系统的支持;
事务系统由事务管理器,日志管理器,并发控制,锁管理器组成,日志管理器和事务管理器完成对操作请求的事务一致性支持,锁管理器和并发控制提供对并发访问数据的一致性支持;
系统表是PostgreSQL数据库的元信息管理中心,包括数据库对象信息和数据库管理控制信息。系统表管理元数据信息,将PostgreSQL数据库的各个模块有机地连接在一起,形成一个高效的数据管理系统。
主要特点
从技术角度来讲,PostgreSQL 采用的是比较经典的C/S(client/server)结构,也就是一个客户端对应一个服务器端守护进程的模式,这个守护进程分析客户端来的查询请求,生成规划树,进行数据检索并最终把结果格式化输出后返回给客户端.同时也要指出的是,PostgreSQL 对接口的支持也是非常丰富的,几乎支持所有类型的数据库客户端接口。这一点也可以说是 PostgreSQL 一大优点。
典型应用场景
企业数据库
如 ERP、交易系统、财务系统涉及资金、客户等信息,数据不能丢失且业务逻辑复杂,选择 PostgreSQL 作为数据底层存储,一是可以帮助您在数据一致性前提下提供高可用性,二是可以用简单的编程实现复杂的业务逻辑。
含 LBS 的应用
大型游戏、O2O 等应用需要支持世界地图、附近的商家,两个点的距离等能力,PostGIS 增加了对地理对象的支持,允许您以 SQL 运行位置查询,而不需要复杂的编码,帮助您更轻松理顺逻辑,更便捷的实现 LBS,提高用户粘性。
数据仓库和大数据
PostgreSQL 更多数据类型和强大的计算能力,能够帮助您更简单搭建数据库仓库或大数据分析平台,为企业运营加分。
建站或 App
PostgreSQL 良好的性能和强大的功能,可以有效的提高网站性能,降低开发难度。
优缺点
优点:
- 稳定性极强, Innodb 等引擎在崩溃、断电之类的灾难场景下抗打击能力有了长足进步。
- PG 性能高速度快。任何系统都有它的性能极限,在高并发读写,负载逼近极限下,PG的性能指标仍可以维持双曲线甚至对数曲线,到顶峰之后不再下降
缺点:
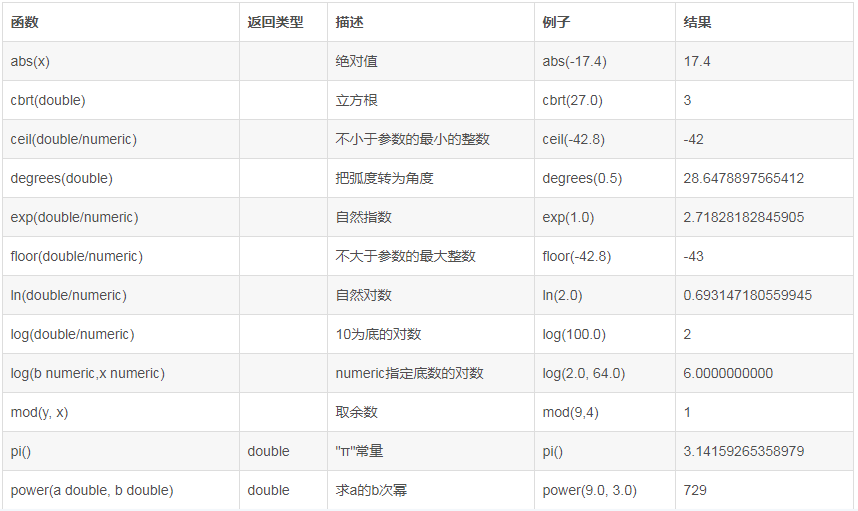
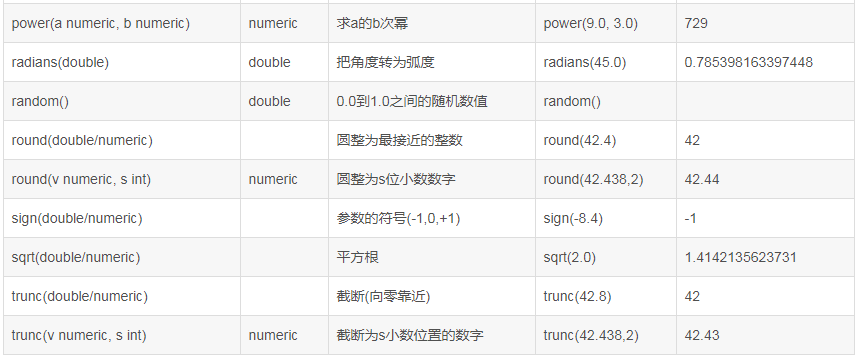
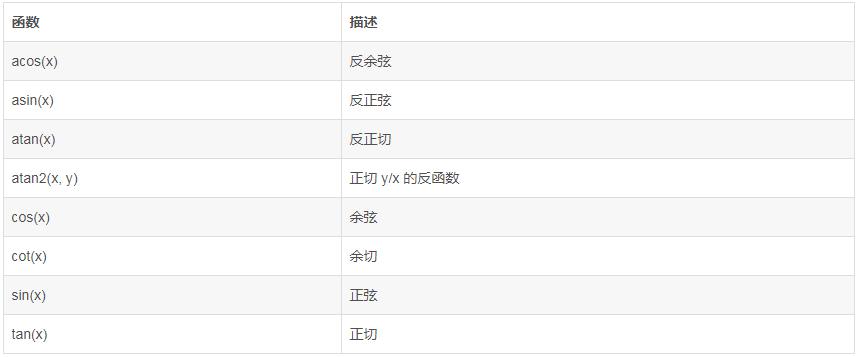
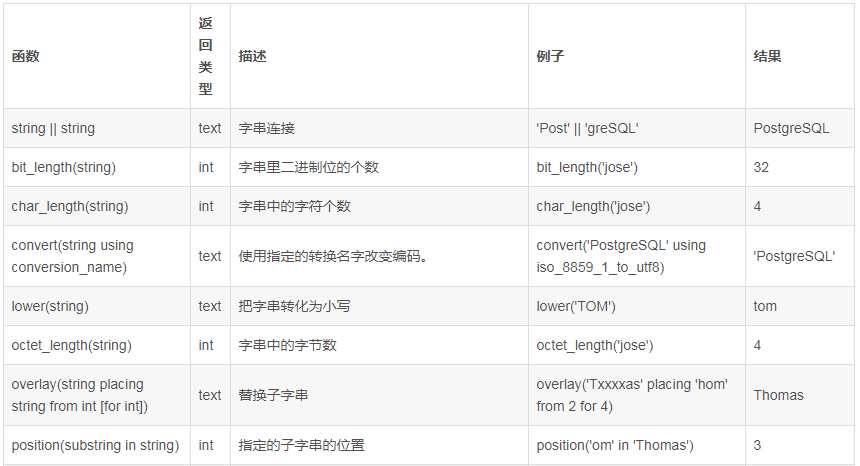
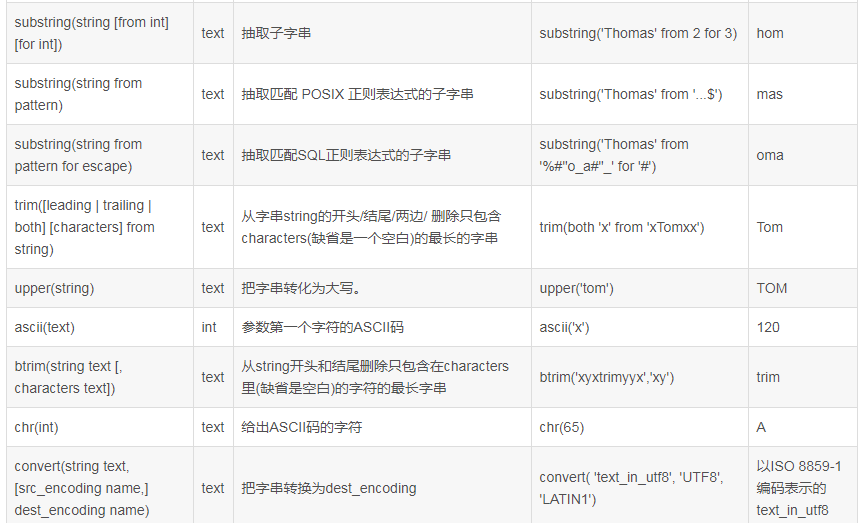
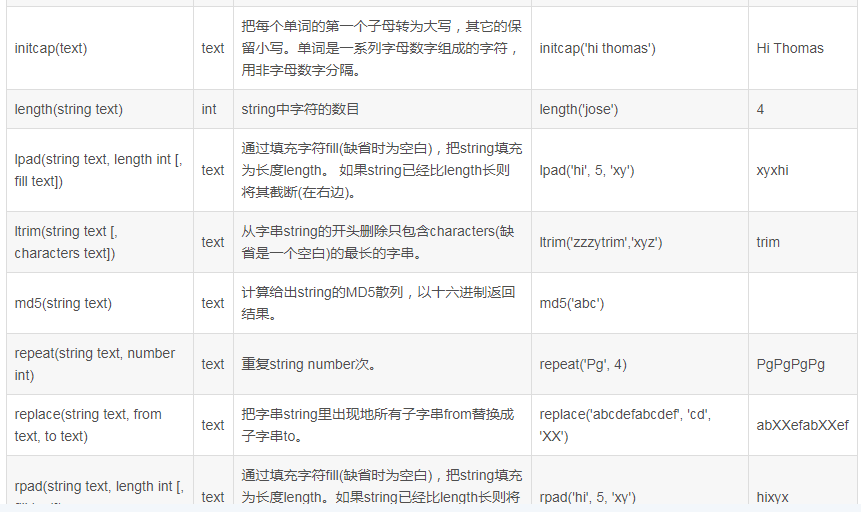

MySql
简介
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL数据库操作-思路图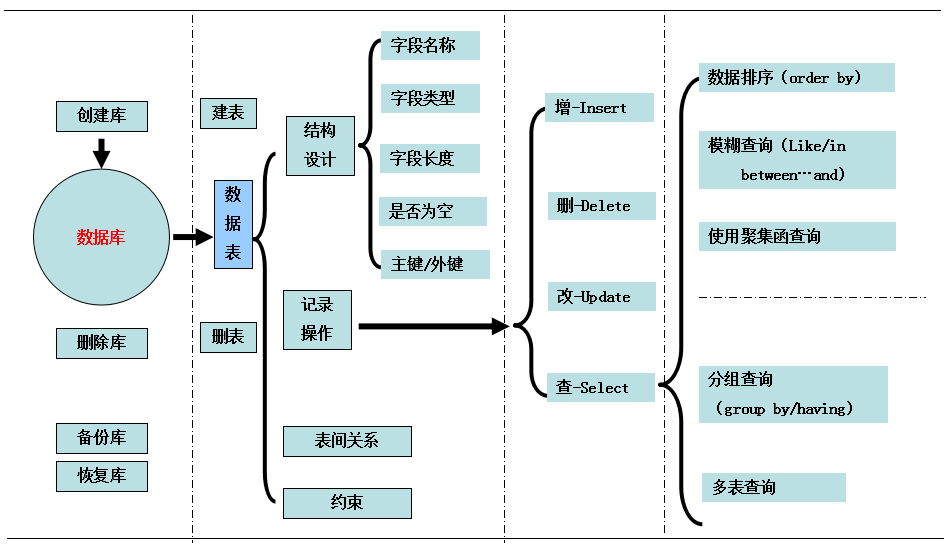
MySQL到底能支持多大的数据量?
MySQL 3.22 限制的表大小为4GB。由于在MySQL 3.23 中使用了MyISAM 存储引擎,最大表尺寸增加到了65536TB(2567 – 1字节)。由于允许的表尺寸更大,MySQL数据库的最大有效表尺寸通常是由操作系统对文件大小的限制决定的,而不是由MySQL内部限制决定的。事实上MySQL 能承受的数据量的多少主要和数据表的结构有关,并不是一个固定的数值。表的结构简单,则能承受的数据量相对比结构复杂时大些。
优缺点
常用函数
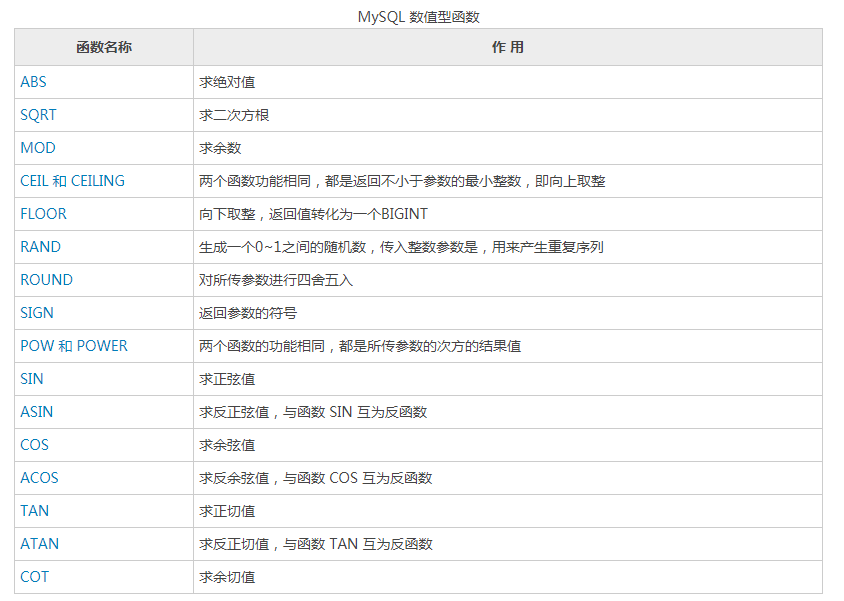
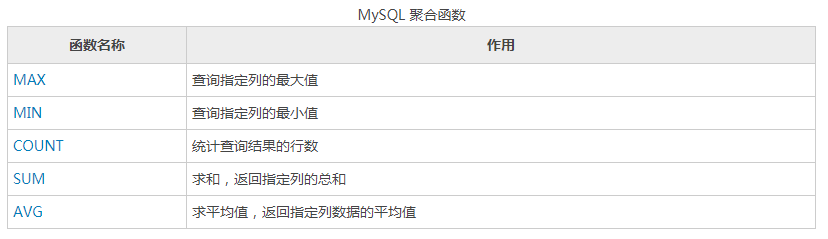
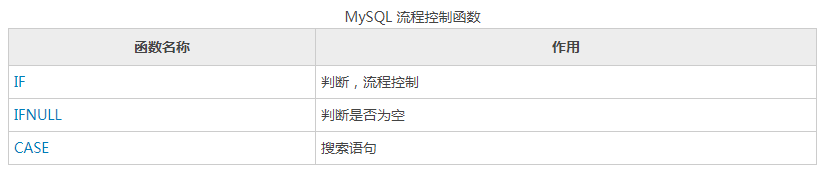


Oracle
简介
Oracle Database,又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的 适应高吞吐量的数据库解决方案。
世界上的所有行业几乎都在应用Oracle技术,《财富》100强中的98家公司都采用Oracle技术。Oracle是第一个跨整个产品线(数据库、业务应用软件和应用软件开发与决策支持工具)开发和部署100%基于互联网的企业软件的公司。Oracle是世界领先的信息管理软件供应商和世界第二大独立软件公司。
MySql、Hive、Postgresql对比
Hive PK MySql
| Hive | MySql | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | 磁盘上 |
| 数据格式 | 用户自定义 | 系统定义格式 |
| 数据更新 | 不支持更新、只可读,不可写 | 支持数据更新 |
| 执行 | MR | Excutor |
| 延迟 | 高(全量扫描整个表) | 低 |
| 处理规模 | 大 | 小 |
| 索引 | 0.8版本之后加入图索引,通过mapreduce暴力扫描整个数据 | 有复杂的索引 |
| 可扩展性 | 与Hadoop一致支持可扩展性 | ACID 语义的严格限制,扩展行非常有限 |
PostgreSQL PK MySQL
1、PostgreSQL相对于MySQL的优势
- 在SQL的标准实现上要比MySQL完善,而且功能实现比较严谨;
- 对表连接支持较完整,优化器的功能较完整,支持的索引类型很多,复杂查询能力较强;
- PG主表采用堆表存放,MySQL采用索引组织表,能够支持比MySQL更大的数据量。
- PG的主备复制属于物理复制,相对于MySQL基于binlog的逻辑复制,数据的一致性更加可靠,复制性能更高,对主机性能的影响也更小。
2、MySQL相对于PG的优势:
a. MySQL采用索引组织表,这种存储方式非常适合基于主键匹配的查询、删改操作,但是对表结构设计存在约束;
b. MySQL的优化器较简单,系统表、运算符、数据类型的实现都很精简,非常适合简单的查询操作;
c. MySQL分区表的实现要优于PG的基于继承表的分区实现,主要体现在分区个数达到上千上万后的处理性能差异较大。
总体上来说,开源数据库都不是很完善,商业数据库oracle在架构和功能方面都还是完善很多的。从应用场景来说,PG更加适合严格的企业应用场景(比如金融、电信、ERP、CRM),而MySQL更加适合业务逻辑相对简单、数据可靠性要求较低的互联网场景(比如google、facebook、alibaba)。
Sql调优
1.任何地方都不要使用 select from t ,用具体的字段列表代替“”,不要返回用不到的任何字段
2.考虑使用“临时表”暂存中间结果。将临时结果暂存在临时表,后面的查询就在tempdb中了,这可以避免程序中多次扫描主表
3.小表连接大表
4.慎用Count(Distinct) 去重统计,一般 COUNT DISTINCT 使用先 GROUP BY 再 COUNT 的方式替换。
Hive详解
创建表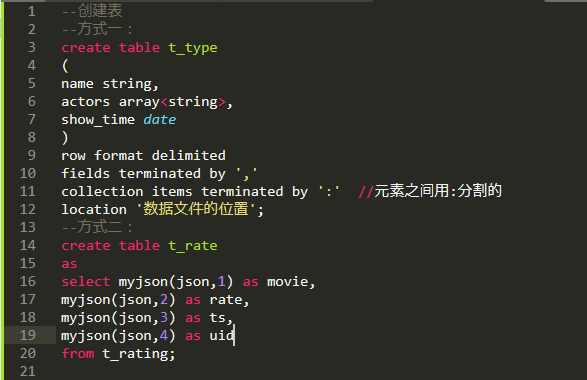
时间函数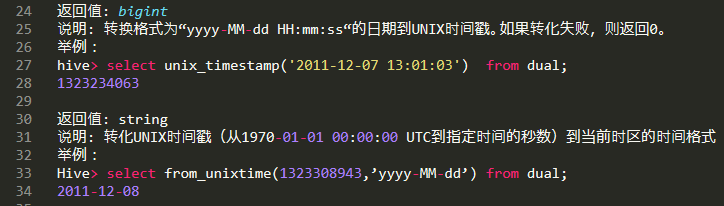

Json解析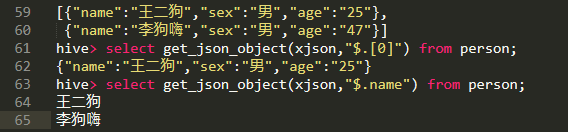
正则替换
窗口函数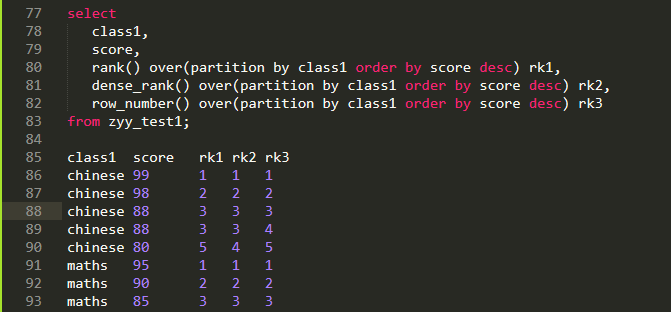
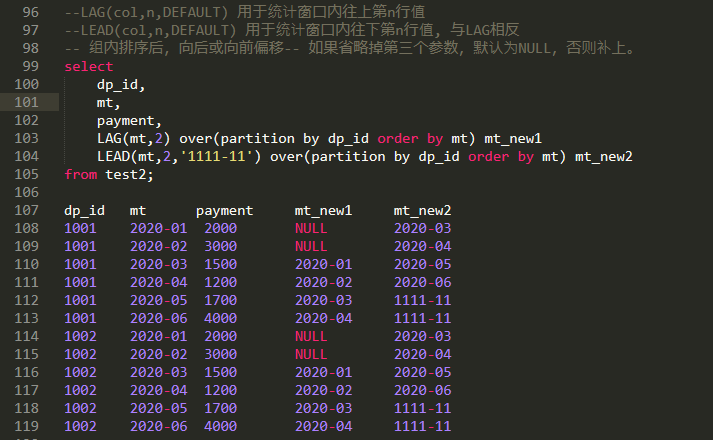
条件函数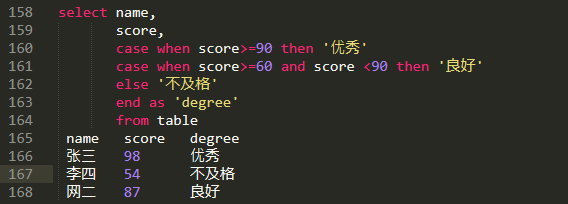

综合案例

若有收获,就点个赞吧
0 人点赞
