来源:https://blog.csdn.net/baidu_39413110/article/details/104188957
引言
好坏标签定义完成并整理好数据集并不意味着建模工作可以马上开始,在建模之前我们还需要拟定好建模方案。比如根据不同客群、不同时段以及风控流程中不同的决策时点,我们都可以做出哪些不同的的建模方案选择?如何更合理地拆分出训练集和测试集?对于过采样过的样本如何还原真实比例?本篇就对这些问题做一个简要介绍。
一、是否需要分客群建模
在样本量足够的前提下,我们会面临两个选择,一个是把所有样本拿来建模,然后一个模型用在所有客群上;另一个是把客群分成多个子客群,分别在每个子客群上单独建模。常见的客群分割方式有:
- 按不同渠道分割
- 按不同产品类型分割
- 按照客户类型分割,比如新客老客
- 按数据覆盖度分割,比如全覆盖人群和部分覆盖人群
- 根据业务逻辑分割,比如地区、年龄段等
分客群建模能够取得更好的效果,取决于一个前提,即不同子客群上的特征存在明显差异。 如果每个子客群的特征差异很大,自然分客群建模能够更好地拟合每个子客群的不同特征,从而达到比整体建模更好的效果。那不同客群特征差异大具体表现为什么样呢,这里举一个例子: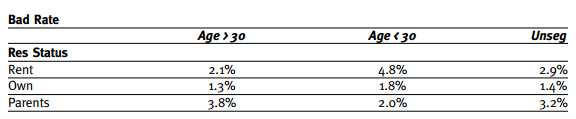
图中展示的是把两个特征(年龄、居住状态)交叉计算坏账率的结果,年龄以30岁为切点做了分割,居住状态分为租住、自有住房和与父母同住,最后一列(Unseg)表示不做分割时的坏账率。可以看到,在30岁以下客群中,和父母同住的人坏账率更高,而在30岁以上人群中,租房的人群相对更坏;这在业务逻辑上也是可解释的:30岁以上的人还和父母同住,一般自身的经济条件都比较差,自然还款能力和意愿也得不到保证,更易产生逾期,而年纪太小就租房的人群很可能属于非正常家庭,也就更倾向于逾期。
如果我们不以年龄分客群来看,租住状态这个变量就没有很强的区分度了,所以这个时候,以年龄分客群建模会有更好的区分度,能够达到更好的效果。
当然,在实际业务中,面对多种分割方案,上千个特征,我们有时候很难从特征层面把握分客群建模是否能够有更好的效果。此时最高效的方式还是做快速建模尝试,整体建模然后在不同客群上打分,和不同子客群分别建模的效果进行对比,可以直接看到分客群建模的增益。但同时我们也应该考虑开发和维护成本,多个模型肯定比一个模型成本高很多,所以还是要在效果和成本之间做一个权衡。
二、全时段建模一定更好吗
当我们有足够长时间跨度的建模样本时,选择哪个时段建模才是最优方案呢?一般我们会认为,建模样本包含所有时段,能够让模型最充分地学习到所有特征,应该会让模型泛化性更强,比分时段建模有更好的效果。但实际业务中如果我们都做一下尝试,可能会得到相悖的结论。
这里分享一个实际案例。在一次模型迭代过程中,我们积累了充分的建模样本,依照线上老评分卡的决策时点将建模样本分了两段:5-8月和9-11月,此时我们就有三种建模方案可选,5-8月、9-11月和5-11月。当我们固定了入模变量,分别尝试了这三种建模方案后发现,5-8月建模效果竟然是最优的,AUC甚至比5-11月的模型在各个时段上都高出0.5个点左右。这和我们最初预期的全时段建模效果最好并不一致。
如果分析原因的话,应该和9月份整个互金行业动荡,数据失效有关,直接导致了9月后的一段时间内通过人群的特征和之前产生了较大差异。所以加入9-11月这部分人群非但没能提升模型的整体效果,反而像噪音一样影响了模型的判断。
当然,这里对原因的分析并不透彻,这个个例也并不具备普适性。但有一点无疑,就是实践出真知,面对多种方案多做尝试一定没错,只靠想当然也许会让我们错过一个较大的模型提升点。
三、进件vs规则过件vs放款件
有时候,或许因为产品设计的原因,或许因为做了拒绝推断,我们可以看到拒绝样本的风险表现了,这时候我们可选择的建模方案就更加广阔了。根据风控流程的时点切割,我们可以选择的建模人群就有三种:整个进件人群,前置策略规则通过后的进件人群,以及最终的表现人群。从业务角度讲,用规则通过后的人群建模最贴合业务需求,因为这部分人就是模型上线决策真正要面对的人群。通常来讲,在哪个人群上建模,模型效果也会在哪个人群上最好。但实际业务中还是要根据拒绝样本标签的可信度、最终的业务需求以及模型效果来权衡最优的建模方案。
四、怎么选训练集
如何划分训练(train)、测试(test)、时间外(oot)样本也需要在建模前做慎重考虑。当我们拿到多个月的数据后,首先要考虑的是拿出哪一部分做oot,一般我们会把最新的一段时间,比如最新一个月拆分出来做时间外验证,这样做的好处是能一定程度模拟模型上线后的效果;但缺点是不能学习到最新这部分人的特征(在策略快速迭代或人群快速变化的时候,这一点影响会比较大)。面对这个问题,有一个折中的方案可以选择:建模时把最新的数据放在训练集中,然后用更短周期的标签在更新的时段上做验证(比如建模时我们选择的标签是3T20,建模最新到5月;我们可以用6月份的2T20标签对模型效果进行验证。)
第二个问题是如何划分训练集和测试集,这个问题在训练机器学习模型时更为重要,因为训练集和测试集上的效果差异直接反映了模型的过拟合程度。对于多个月的数据集,有两种分割方案,一是按时间段分,前2个月做test,后3个月做train;也可以把所有数据整体3/7分做test和train。这里更推荐第二种方案,因为前一种分割方案会包含时间变化的因素,具体而言,如果train和test效果有明显差异,这种差异有可能是模型过拟合导致的,也有可能是train和test上人群产生了较大的变化导致的。所以,如果我们整体做3/7分,可以基本保证train和test上的人群分布是一样的,也就排除了时间变化因素。
另外一个需要注意的问题是:训练集最好要包含线上评分卡决策之前的数据。 如果我们此次建模是为了替换线上的老评分卡,那把线上评分卡决策前的数据包含进来做训练是有必要的,因为我们建模用的样本都是通过的客群,而评分卡在实际使用中面对的是整个进件的人群,所以我们建模的样本其实是有偏人群。在线上老评分卡决策前的数据,会包含部分线上评分卡本会拒绝掉的样本,把这部分数据拿来训练,一定程度上会对建模样本的偏移做修正。当然,偏移校正最好的方式还是开一小部分测试人群,让这部分人不过任何策略,直接放款。建模时把这部分人群加进来建模可以更好地校正建模样本的偏移,但这种方式需要慎重考虑业务对坏账的承受能力。
五、还原真实好坏比例
我们拿到的建模样本,很多时候是对好坏样本重新采样的,尤其是在预测小概率事件时,通常会把响应样本做过采样。此时,我们建模样本的坏账率便不能反映真实客群的坏账情况,需要考虑权重的问题。
在模型拟合中,不论是拟合逻辑回归模型还是XGB模型,都可以在fit方法中通过sample_weight参数来指定好坏样本的权重。
如果评分卡已经在未调整权重的情况下训练完成了,则可以通过如下公式对输出的概率进行调整,使得输出的概率值反映真实的坏账水平:
在实际操作中,有一种更直接简单的方法来解决好坏样本重新采样的问题,即把欠采样的样本复制n倍再建模。比如真实的好坏比例如果为10:1,而我们拿到的建模样本好坏比例为2:1,简单地把好样本复制5倍,然后拿来建模,这样后续模型效果,LIFT以及坏账水平的评估,都是可以反映真实业务情况的。
————————————————
版权声明:本文为CSDN博主「白白的一团团」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/baidu_39413110/article/details/104188957

若有收获,就点个赞吧
0 人点赞
