来源:
分 享 嘉 宾 : 严 澄 度 小 满 风 控 模 型 负 责 人
今天的介绍会围绕下面四点展开:
- 科学定义数据
- 科学应用数据
- 科学评估数据
- 科学解释数据
1. 金融风险管理
信贷业务本质是储蓄转化为投资的一种形式。类比于其他的互联网业务,电商平台的推荐系统
实现的是客户和商品需求之间的精准匹配,广告平台的投放系统实现的是客户和潜在兴趣之间
的精准匹配,互联网信贷业务的风险管理目标就是实现资金供给方和资金需求方的精准风险匹
配。在风险匹配的两端,资金供给方期望的风险目标是明确的,所以风险管理的核心是预测资
金需求方的风险,从而进行精准匹配。接下来我们讲讲风险定义以及如何科学地预测风险。
2. 科学定义数据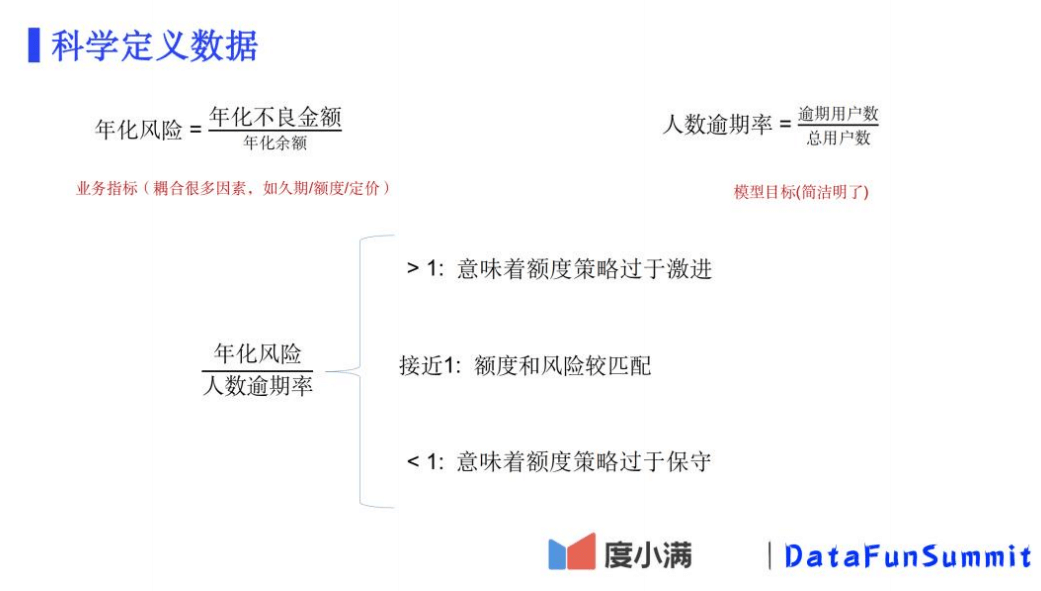
在信贷行业内,对风险最常见的定义是年化风险,即年化不良金额除以年化余额。 这是因为简
化收益大多是按照年化定价 - 年化风险 - 年化资金成本来计算的。一整包资产的年化风险受
很多因素影响:逾期的用户分布,逾期的金额分布,放款的久期分布。虽然年化风险从业务上
来看是个非常直观的指标,但如果要直接预测年化风险则是非常困难的。从更易实现的角度来
看,预测逾期的用户分布会更直接而简单。
3. 科学应用数据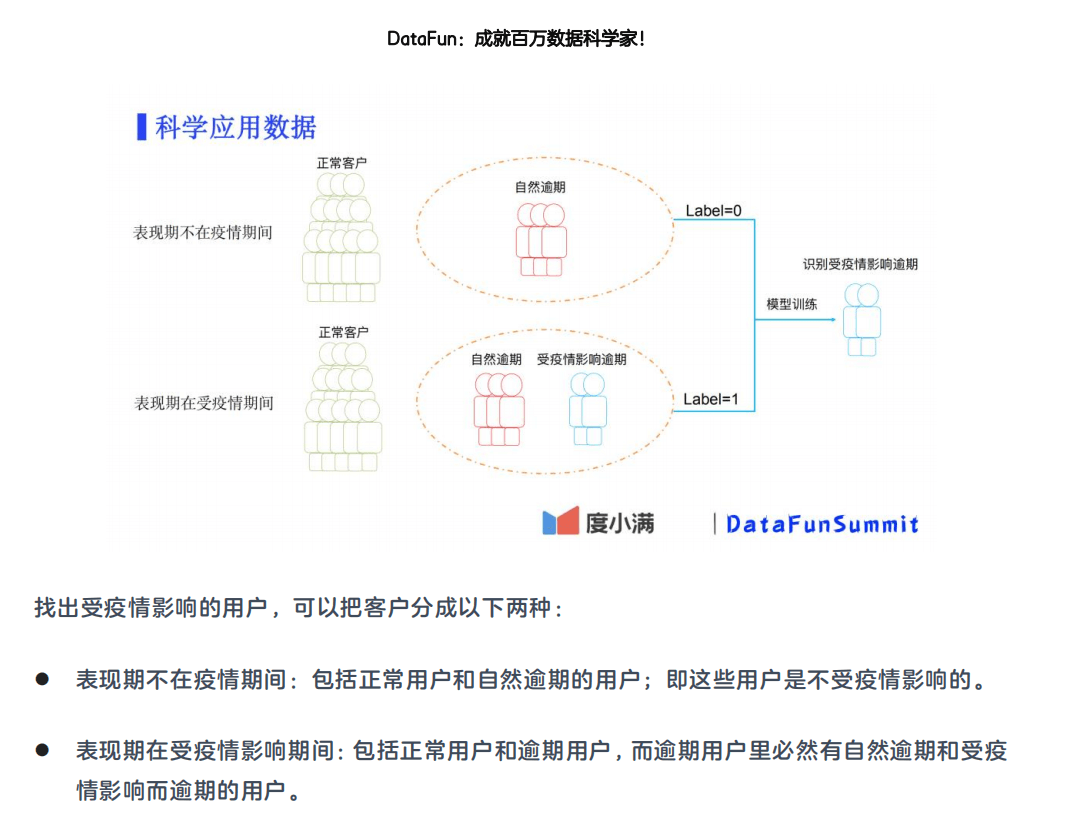
我们将表现期不在疫情期间逾期的用户标识为 0,将表现期在受疫情期间的逾期用户标识为 1,
基于二分类模型进行训练。经过模型训练以后,那些预测高概率为 1 的用户就是那些受疫情影
响而逾期的用户,而那些预测高概率为 0 的用户就是不管有没有疫情都大概率会逾期的客户。
这样,我们设定一个阈值,就可以将大部分受疫情影响而逾期的用户找出来
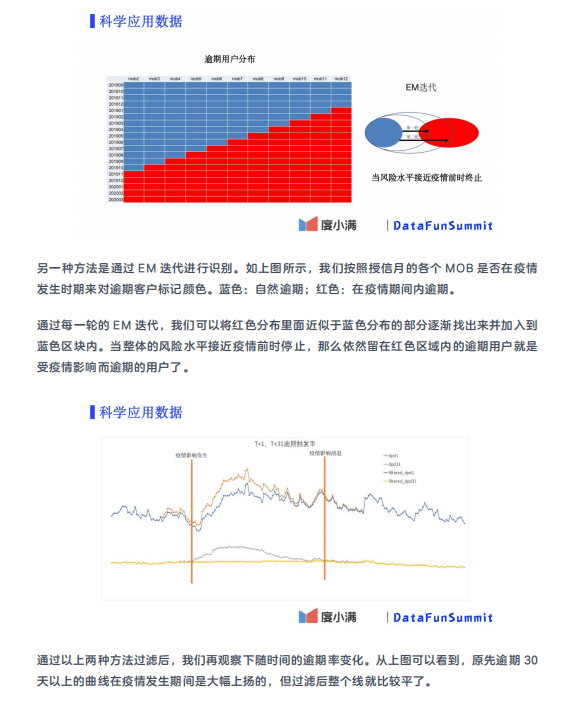
4. 科学评估数据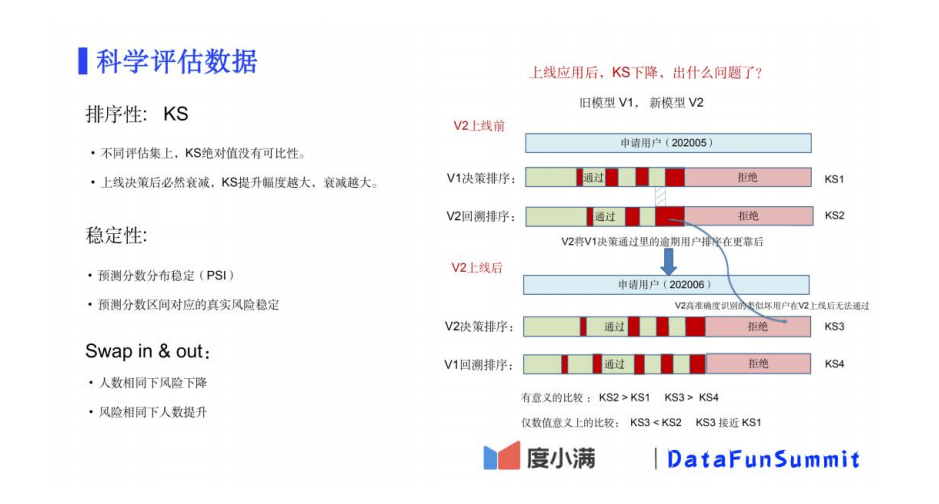
换入换出的考虑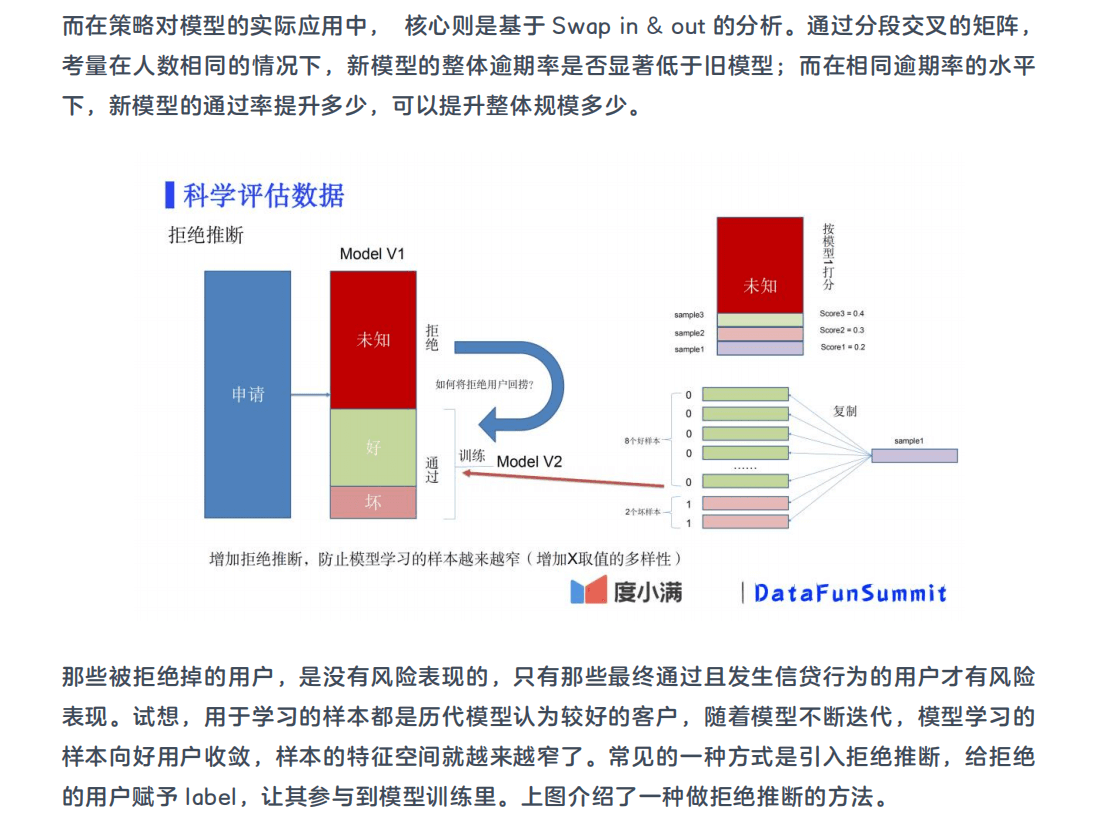
给拒绝的用户按照模型 1 给出的打分,比如某个用户模型 1 的分数是 0.2(逾期率 20%),那
么将这个用户的样本复制 10 份,其中 8 份样本的 label 设成 0,2 份设置成 1。这样 10 份样本
特征一样,但整体 label 为 1 的比例就是 20%。当然也可以不复制样本,很多模型都支持设置
样本权重。通过这种方式增加了 X 取值的多样性,可以一定程度提升模型的适用性。
这种情况下,细分客群建模,可以让每个模型充分
学习自身样本的信息,而不是从全局上平均化地去拟合。但是,如果寻找不到显著的差异,特
别是样本总量还不是很充足的时候,分客群不是一个好的选择
5. 科学解释数据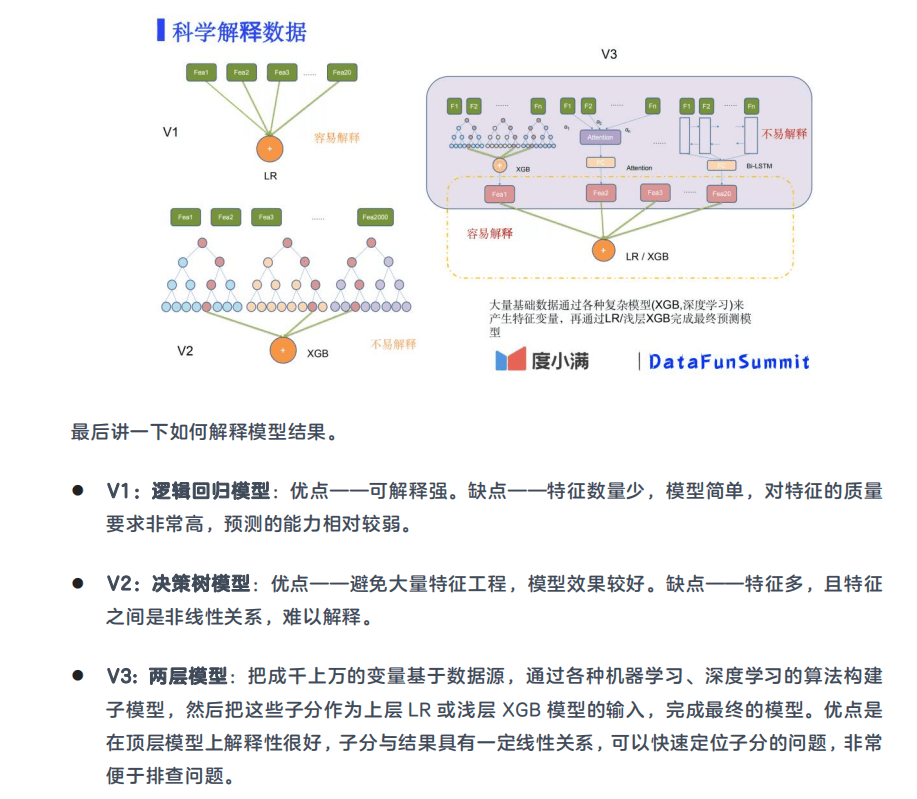

若有收获,就点个赞吧
0 人点赞
