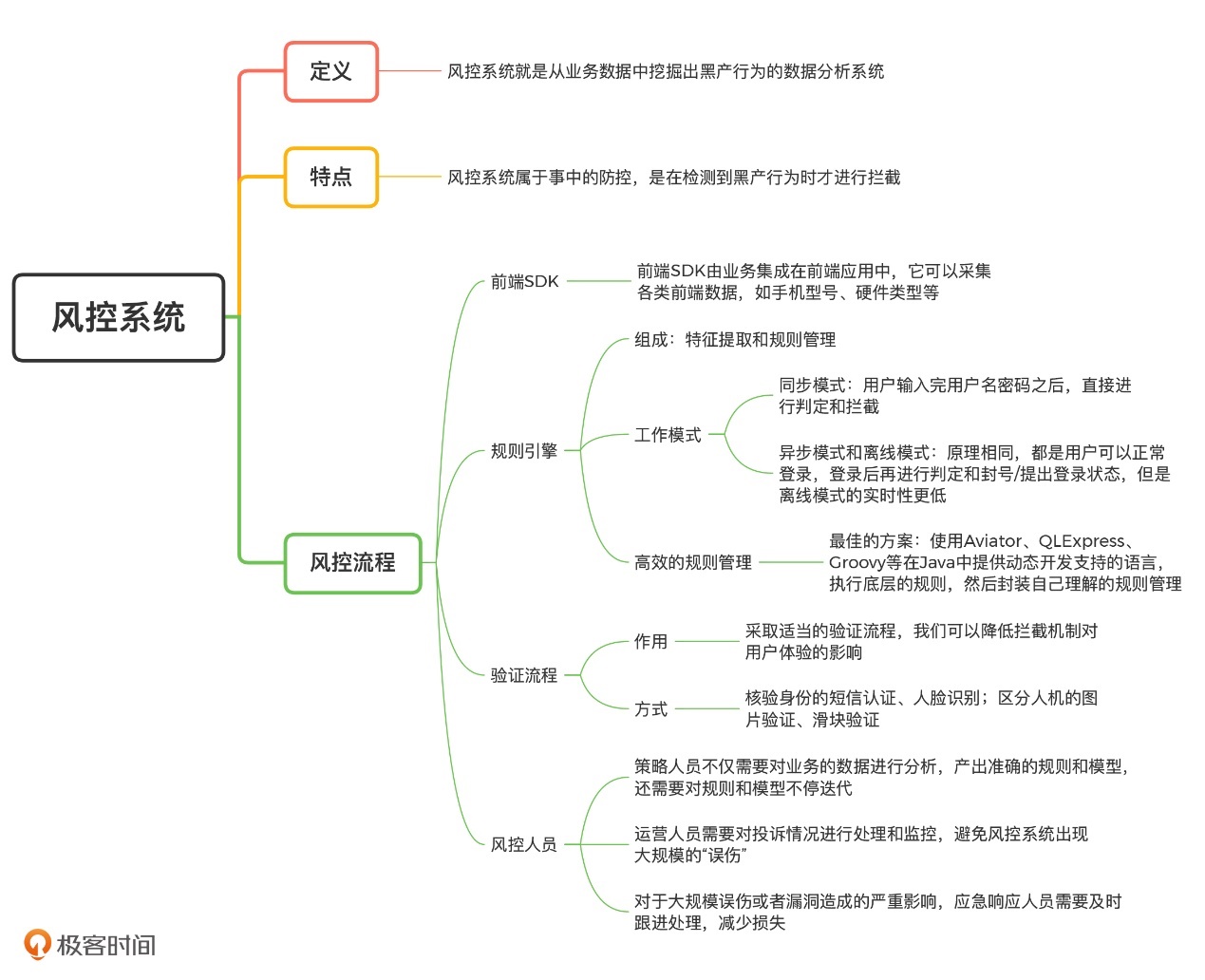
总结来说,规则引擎是风控系统的核心。想要做好一个规则引擎,我们需要思考清楚两件事情:第一,规则引擎以什么样的模式接入业务;第二,如何进行规则管理。
风控模型有哪些:
• 获客阶段:用户响应模型,风险预筛选模型。
• 授信阶段:申请评分模型,反欺诈模型,风险定价模型,收益评分模型。
• 贷后阶段:行为评分模型,交易欺诈模型,客户流失模型。
• 催收阶段:早期催收模型,晚期催收模型。
Q:简单描述一下风控建模的流程?
- 前期准备工作:不同的模型针对不同的业务场景,在建模项目开始前需要对业务的逻辑和需求有清晰的理解,明确好模型的作用,项目周期时间和安排进度,以及模型效果的要求。
- 模型设计:包括模型的选择(评分卡还是集成模型),单个模型还是做模型的细分,是否需要做拒绝推论,观察期,表现期的定义,好坏用户的定义,数据的获取途径等都要确定好。
- 数据拉取及清洗:根据观察期和表现期的定义从数据池中取数,并进行前期的数据清洗和稳定性验证工作,数据清洗包括用户唯一性检查,缺失值检查,异常值检查等。稳定性验证主要考察变量在时间序列上的稳定性,衡量的指标有PSI,平均值/方差,IV等。
- 特征工程:主要做特征的预处理和筛选,如果是评分卡,需要对特征进行离散化,归一化等处理,再对特征进行降维,降维的方法有IV筛选,相关性筛选,显著性筛选等。另外会基于对业务的深入理解做特征构造工作,包括特征交叉,特征转换,对特征进行四则运算等。
- 模型建立和评估:选择合适的模型,像评分卡用逻辑回归,只需要做出二分类预测可以选择xgboost等集成模型,模型建好后需要做模型评估,计算AUC,KS,并对模型做交叉验证来评估泛化能力及模型的稳定性。
- 模型上线部署:在风控后台上配置模型规则,对于一些复杂的模型还得需要将模型文件进行转换,并封装成一个类,用Java等其他形式来调用。
- 模型监控:前期主要监控模型整体及变量的稳定性,衡量标准主要是PSI,并每日观察模型规则的拒绝率与线下的差异。后期积累一定线上用户后可评估线上模型的AUC,KS,与线下进行比较,衡量模型的线上的实际效果。
Q:对于金融场景,稳定胜于一切,那在建模过程中如何保证模型的稳定性?
- 在数据预处理阶段可以验证变量在时间序列上的稳定性,通过这个方法筛掉稳定性不好的变量,也能达到降维的目的。筛选的手段主要有:计算月IV的差异,观察变量覆盖率的变化,两个时间点的PSI差异等。
- 异常值的检查,剔除噪声,尤其对于逻辑回归这种对于噪声比较敏感的模型。
- 在变量筛选阶段剔除与业务理解相悖的变量,如果是评分卡,可以剔除区分度过强的变量,这种变量一般不适合放入模型中,否则会造成整个模型被这个变量所左右,造成模型的稳定性下降,过拟合的风险也会增加。
- 做交叉验证,一种是时间序列上的交叉验证,考察模型在时间上的稳定性,另一种是K折随机交叉验证,考察模型的随机稳定性。
- 选择稳定性较好的模型,例如随机森林或xgboost这类泛化能力较好的模型。
Q:模型转化为规则后决策点(cutoff点)怎么设定?
- 规则只是判断用户好坏,而不会像模型会输出违约概率,所以设定决策点时需要考虑到规则的评估指标(精准率,查全率,误伤率,拒绝率),一般模型开发前会设定一个预期的拒绝率,在这个拒绝率下再考量精确率,查全率和误伤率的取舍,找到最佳的平衡点。
- 好的模型能接受更多的好用户,拒绝掉更多的坏用户,也就是提高好坏件比例,所以可事先设定一个预期目标的好坏件比例来选择最佳的决策点。
依据事先设定的策略目标(如核准率/核准数/好坏件比率/好坏件数等),并参考信用评分模型评分分布表,对预期目标(事先设定)与实际数据(由评分分布表取得)的评分等级,制订适当决策点。常用的策略目标有以下四种。
好坏件比率(Good/Bad Odds)
核准率(Approval Rate)
核准件中好客户数(Good Accounts)
核准件中坏客户数(Bad Accounts)
Q:怎么做风控模型的冷启动?
风控模型的冷启动是指产品刚上线时,没有积累的用户数据,或者用户还没有表现出好坏,此时需要做模型就是一个棘手的问题,常用的方法如下:
- 不做模型,只做规则。凭借自己的业务经验,做一些硬性规则,比如设定用户的准入门槛,考量用户的信用历史和多头风险,而且可以接入第三方提供的反欺诈服务和数据产品的规则。另外可以结合人审来对用户的申请资料做风险评估。
- 借助相同模式产品的数据来建模。如果两个产品的获客渠道,风控逻辑,用户特征都差不多的话,可以选择之前已上线那个产品所积累的用户来建模,不过在模型上线后需要比较线上用户的特征是否与建模用户有较大的差异,如果差异较大,需要对模型对一些调整。
- 无监督模型+评分卡。这种方法适用于产品上线一段时间后,表现出好坏的用户比较少,但需要做一个模型出来,此时可用线上的申请用户做无监督模型,找出一部分坏样本和好样本,用这些数据来做评分卡模型,当然这种模型准确性是存疑的,需要后续对模型不断迭代优化。
- TrAdaboost(目标场景也就是新业务场景有少量标签)、JDA模型(目标场景也就是新业务场景无标签)
Q:如何衡量一个风控模型的效果?
本人在工作中写过一个评分卡模型的评估方法,这里贴出来可以做个参考:
1.评分卡建模之前的评估:
主要评估建模样本的稳定性,根据评分卡的目的不同,比较对象为总体或者近段时间的样本。
2.分箱过程的评估
变量分箱的同时会计算WOE,这里是对WOE进行可解释性上的评估,包括变化趋势,箱体之间WOE差异,WOE绝对值大小等。
3.对逻辑回归模型的评估
- 将数据集随机划分为训练集和测试集,计算AUC, KS及Gini系数
- 通过交叉验证的方法,评估模型的泛化能力,评判指标选择AUC。
- 绘制学习曲线,评估模型是否有过拟合的风险,评判指标为准确率(Accuracy)。
4.转化评分之后的评估
- 对score进行可解释上的评估,评估原则与WOE评估大致相同。
- 绘制评分分布图,观察分布的形状及好坏用户分布的重叠程度。
- 绘制提升图和洛伦兹曲线,评估评分卡的可解释性和好坏用户区分效果。
- 评估准确性,根据对精确率和查全率的重视程度绘制PR曲线,并根据业务目标设定cutoff点。
5.评分卡上线后的评估
- 绘制评分分布表和评分分布图,计算评分的PSI,评估其稳定性。
- 评估每个入模变量的稳定性。
Q:对于成千上万维的特征你是怎么做特征筛选的,如何保证其模型的可解释性和稳定性?
- 可先做特征的粗筛选,例如缺失率高,方差为0,非常稀疏的特征可以先剔除。
- 根据变量的稳定性再次进行粗筛,衡量指标有月IV差异,两个时间点的PSI差异等。
- 根据IV值的高低筛选变量,或者直接用集成模型的特征重要性进行筛选。
- 为了保证模型的可解释性,需要将共线性的特征剔除。
- 最后考察各个特征与目标变量的关系,要求在业务上有良好的可解释能力,并且特征与目标变量的关系最好是呈单调线性变化的,这样也能保证模型的稳定性。
Q:风控流程中不同环节的评分卡是怎么设计的?
- 申请评分A卡用在贷前审核阶段,主要的作用是决定用户是否准入和对用户进行风险定价(确定额度和利率),用到的数据是用户以往的信用历史,多头借贷,消费记录等信息,并且做A卡一般需要做拒绝推断。A卡一般预测用户的首笔借款是否逾期,或者预测一段时间内是否会逾期,设计的方式也多种多样,有风险差异化评分卡,群体差异化评分卡,或者做交叉评分卡等。
- 行为B卡主要用在借贷周期较长的产品上,例如手机分期。作用一是防控贷中风险,二是对用户的额度做一个调整。用到的数据主要是用户在本平台的登录,浏览,消费行为数据,还有借还款,逾期等借贷表现数据。
- 催收C卡主要是对逾期用户做一个画像分析,通过深度挖掘用户特征,对逾期用户进行分群,做智能催收策略等。

若有收获,就点个赞吧
0 人点赞
