信贷业务风控策略简介

DataFunTalk
DataFun:大数据、人工智能领域的知识分享平台。
关注他
、等 113 人赞同了该文章
风控猎人
求是汪在路上
导读:大家好,今天分享的主题是信贷业务风控策略。风控业务主要经历了几个阶段:
- 规则:直接判断通过,或不通过。
数据:可以通过客户的资产,流水,来判断客户的资质优劣。
模型:通过数据分析、数据挖掘,找到相应的规律,识别出人工难以找到的部分人群。
但是,数据是有限的,成本很高,会限制风控的上限;同时,如何有效的结合数据、规则、模型,来实现业务目标,这就需要风控策略来完成。
本次分享,将介绍如何在信贷业务中利用数据、规则、模型等完善风控策略,包括原有风控流程及规则优化、定价策略、额度策略等内容。
▌背景
1.1 消费信贷行业背景
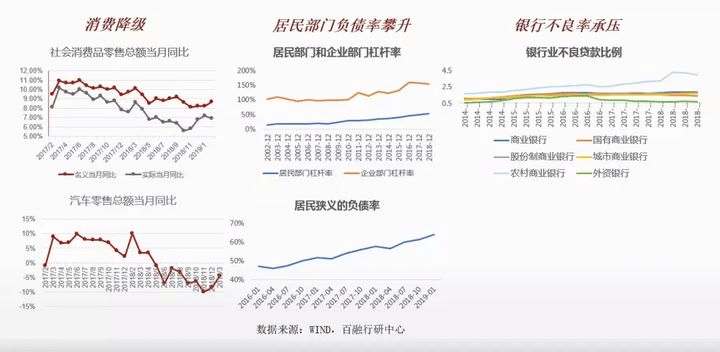
首先给大家普及下消费信贷行业的情况,目前的消费信贷市场和2年前的不太一样。2年甚至3年以前,它是一个蓬勃发展的阶段,但是现在出现了一个情况,就是消费降级,社会消费品零售总额、汽车零售总额增长放缓,居民狭义的负债率攀升,以及银行不良贷款率增长态势。信贷市场相较前几年的市场发生了变化,前几年属于资产红利,风控的价值本质上是资产获利的多少;目前而言,风控的价值是有效降低风险,减少亏损。因此,对于成本的控制,对于风控的效果,需要有更精细化的应用和实践。
1.2 消费信贷行业客户渗透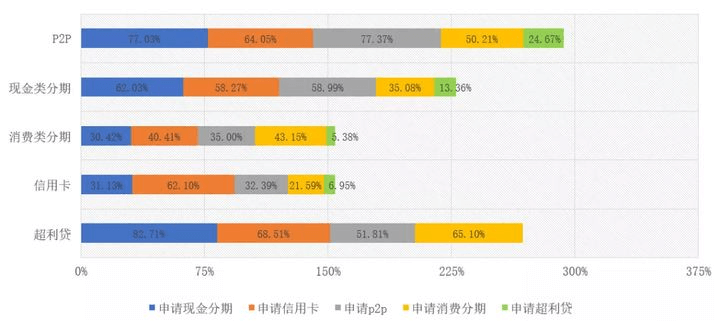
客户渗透率
横轴表示渗透占比,横轴越长,渗透率越高;单个颜色越长,表明用户群重合也越高。当某个产品受到监管,会导致其客户流失,随之带来金融风险问题。以 P2P 和超利贷为例,正常情况下,P2P 的客户应该比超利贷好,但是由于市场监管的变化,二者的客户质量已经差不多了。所以,当市场规则发生变化的时候,原来的规则和模型都失效,因此,风控策略就成为了最后一道关卡。
1.3 传统评分卡的开发流程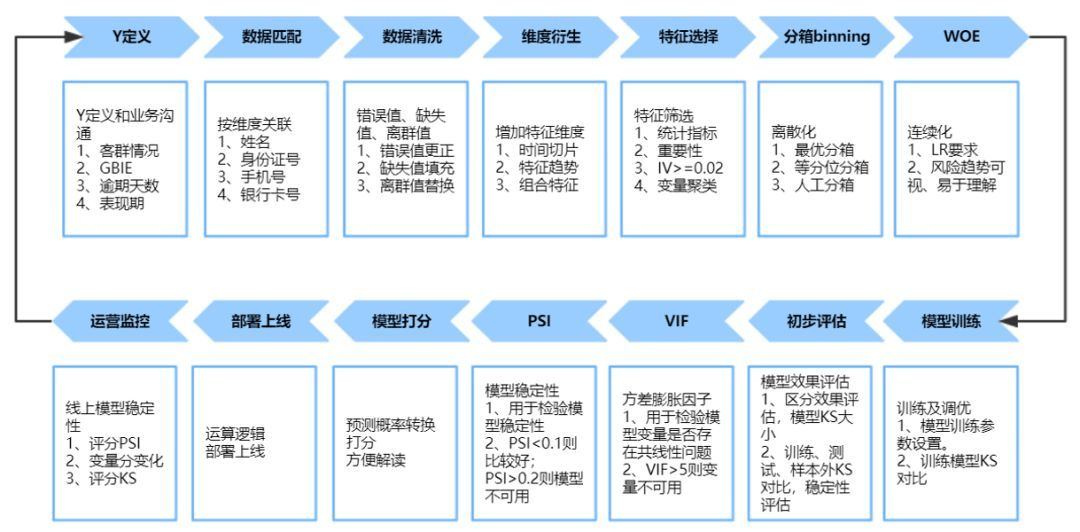
评分卡开发流程
① 目标定义
- 定义风控业务的目标,要求熟悉业务逻辑,好坏客户的定义。
② 数据的整合加工
- 数据:包括用户的姓名、身份证号、手机号、银行卡号,购物记录等
- 清洗:错误值、缺失值、离群值
- 衍生变量的处理:引入其它维度的数据,以及做特征组合
③ 特征选择、调优、效果评估
- 特征选择:利用统计显著性、变量重要度、IV 指标,变量聚类等算法来挑选重要的变量,通常还需要采用分箱的方式,将连续值离散化,增加变量的鲁棒性,增加了变量的整体稳定性。
- 模型调优:在训练集上调整模型参数,对比 KS 值的变化,选择 KS 最大的模型。
- 效果评估:对比训练集、测试集、样本外数据集的 KS 值,查看模型是否稳定。
- 共线性:此外,还需要检验模型变量之间是否存在共线性问题,一般计算 VIF 值,如果 VIF>5,表明存在共线性问题,该变量不可用。
- 模型稳定性:计算 PSI 值,如果 PSI<0.1,则模型稳定性较好,如果 PSI>0.2,则模型稳定性较差,不可用。
④ 模型打分、部署、监控
- 对变量每个分箱都打一个分值,形成一张评分卡(相较于机器学习,优点是可解释性强),最后上线部署。
1.4 机器学习模型开发流程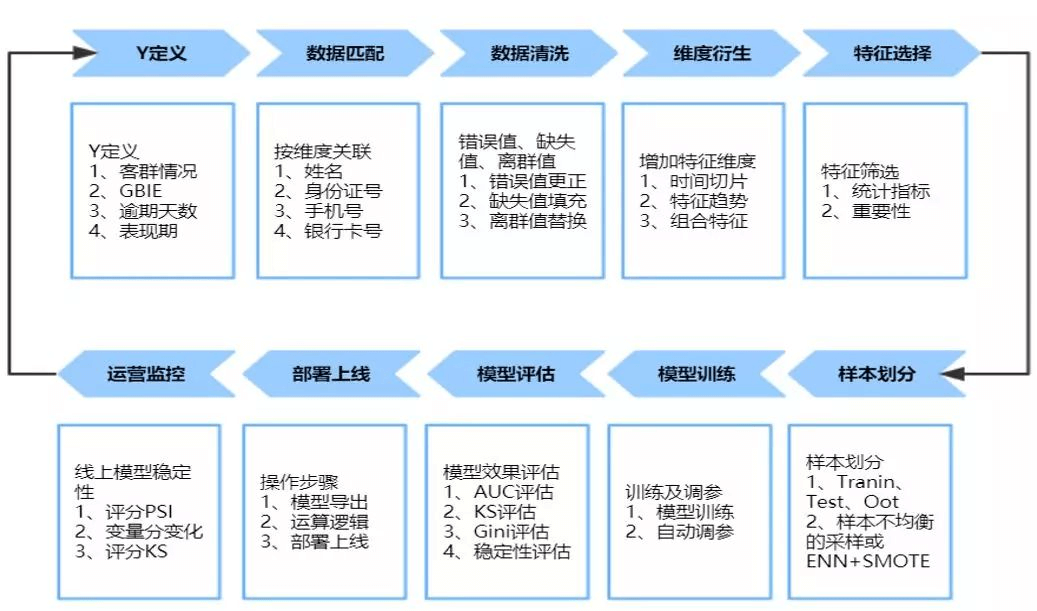
机器学习开发流程
相较于评分卡开发流程,差异如下:
① 机器学习中人工介入少;
② 可解释性差;
③ 重点是调整参数,避免模型过拟合。
▌贷前风控流程与策略
2.1 风控流程设计
目标是发现风险点(包括:信用卡欺诈、团伙窝案、高危用户等),降低风险;同时降低成本、提升效率。
银行的风控流程,以某四大行信用卡业务为例。
案例1:
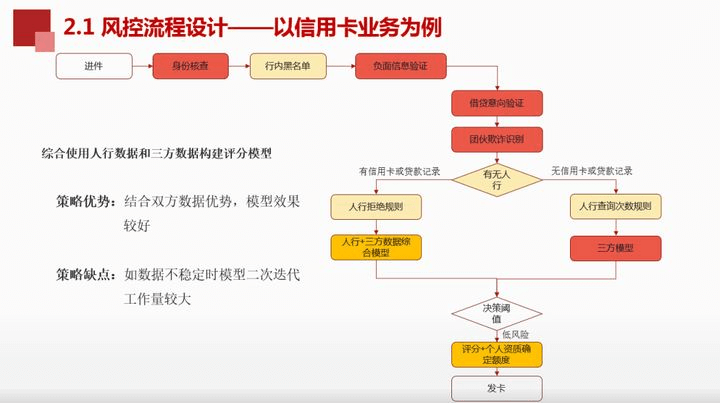
① 身份核查:验证身份的真实性,是否为本人、是否有欺诈等行为。
② 剔除其它点影响:行内黑名单、负面信息验证。
③ 将成本低的借贷意向验证放在成本高的团伙欺诈识别前面,达到节省成本的作用。
④ 结合人行拒绝规则、人行数据以及第三方数据建模,其优点是结合双方数据优势,模型效果会较好。但数据不稳定时,模型二次迭代工作量较大。
案例2:
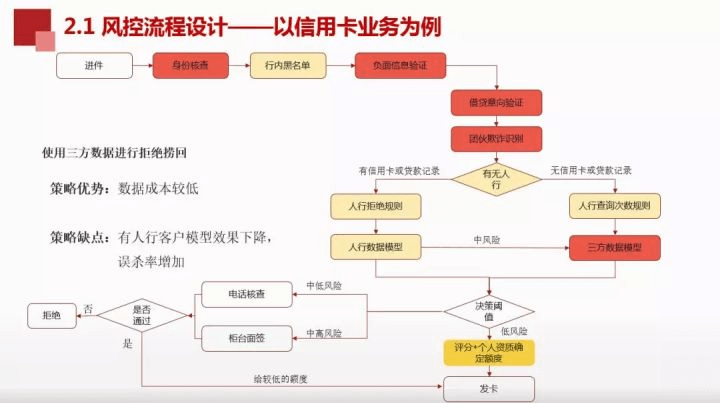
相较于案例1,案例2较为保守,没有将人行数据和三方数据结合起来做来模型,对于拒绝的用户再次做人工审核,将符合的用户再次捞起来。这样做数据成本低,但是有人行客户模型效果下降,误杀率增加。
案例3:
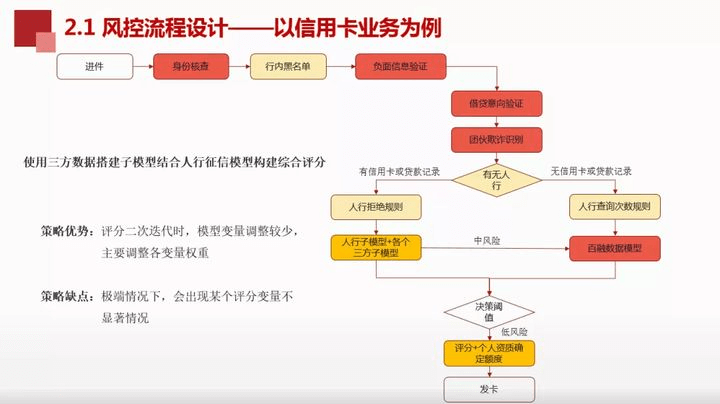
同案例1的区别:将各个数据构建子模型,然后整合为一个综合模型,如收入数据、支出数据建模。差异在于客群建模的差异,将不同的客群用户分开做模型。这样在评分二次迭代时,模型变量调整较少,主要调整各变量权重即可。但是在极端情况下,会出现某个评分变量不显著的情况。
综合上述三个案例,风控策略并不是完全依赖于成本,还要依赖于实际业务情况和业务目标。很多时候,风控流程是根据业务情况来进行的。
2.2 利率策略和额度策略
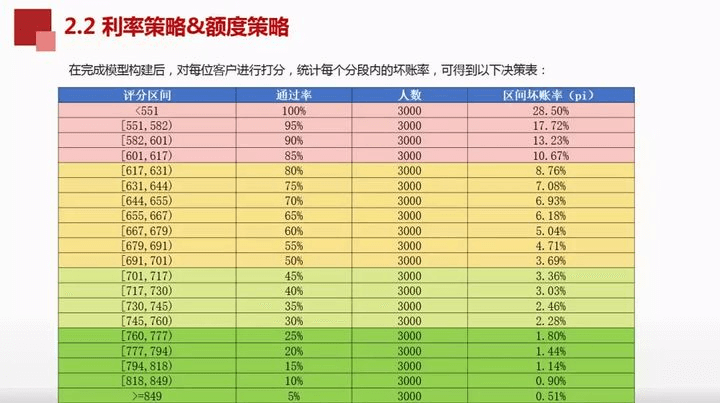
完成模型构建后,对每位客户打分,统计每个分段内的坏账率,以控制收益与成本。怎么给合适的利率和额度呢?
① 利率策略:
风险与利率计算公式
A 表示额度,r 表示预期收益率,p 表示坏账率,对每个评分段分别计算预期收益 ri,但通常情况下,利率是固定的,当分数在某个阈值时,就直接拒绝掉。
② 额度策略: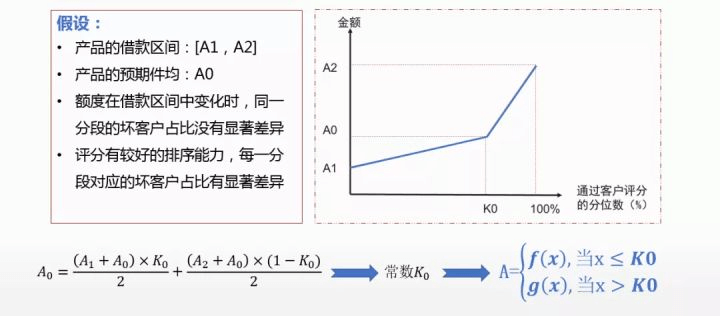
风险情况与平均每件额度
额度策略本身受限于产品设计、客户需求及竞品情况,结合自身成本和风险偏好,可初步确定产品的额度区间 [A1,A2] 和件均 A0。由于右图中俩个梯形的面积应该是相等的,因此,可以得到关于 A0 的计算表达式,由于 A0、A1、A2 都是已知的,因此我们能计算出 A0 对应的常数 K0,这样就可以把右图中蓝色的折线拟合出来,即相对最优的一个解。可以实现,根据不同的分位数,给不同的额度。那么,这么做合理吗?它是需要满足一定的假设条件的:
- 额度在借款区间中变化时,同一分段的坏客户占比没有明显差异;
- 评分有较好的排序能力,每一分段对应的坏客户占比有显著差异。
③ 额度策略优化: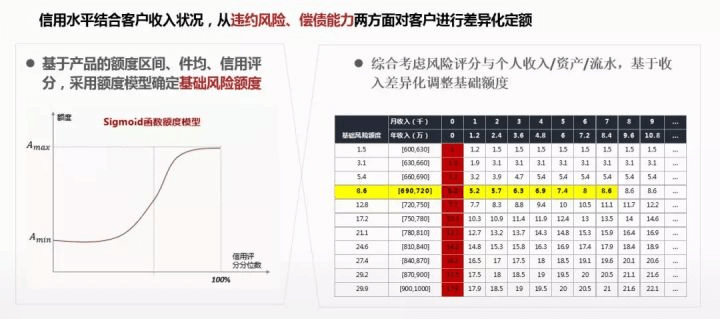
额度策略优化
采用 sigmoid 来替代分段函数,确定基础风险额度。对于大额借贷,还是考虑用户的偿债能力,即收入,资产,流水等指标,先算出基础风险额度,再结合收入等指标,差异化调整基础额度。
2.3 风控规则有效性诊断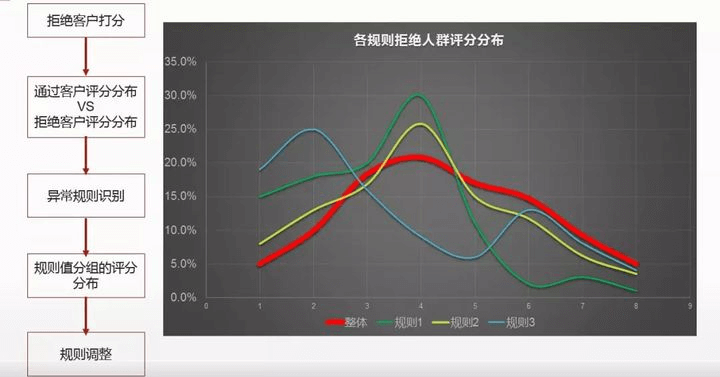
各规则拒绝人群评分分布
怎么确认规则的有效性和调整?
首先对拒绝客户进行打分,然后对比‘通过客户评分分布’和‘拒绝客户评分分布’,找出异常规则,再把各规则进行分组评分分布对比,最后进行规则调整。
如上图,对拒绝的客户重新打分,与整体样本中拒绝用户评分对比:
- 规则1,效果最好,最低分段的用户拒绝率高,高分段的用户拒绝率。
- 规则2,效果不明显,与整体数据的分布差异不大,效果不明显。
- 规则3,太过于波动,不稳定。
2.4 信用评估模型的构建与优化——模型优化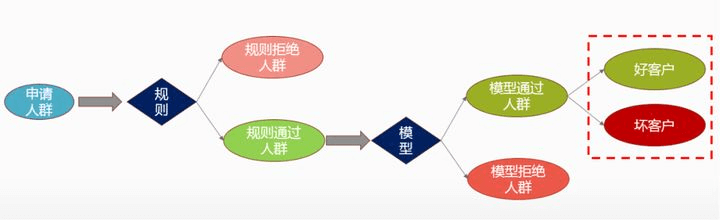
风控建模流程图
基础的风控建模流程如上。在进行模型迭代时,主要利用通过样本进行模型构建,被迭代的模型拒绝率较高;如不考虑模型拒绝人群,进行拒绝推断,则新模型的应用效果会有明显下滑,且多次迭代后,新模型的效果提升比例会越来越小。因此重要的一点在于,如何做拒绝推断,找到之前被规则淹没的特征。
解决样本淹没问题的三种方案
为了解决样本淹没问题,将规则拒绝的样本加入模型训练阶段,有三种方案:
① 比例分配:将拒绝对象随机划分为“好”和“差”的账户,再次带入评分流程中,构建一个模型;
② 简单增强法:对拒绝客户打分,并选取某个 cutoff 点进行区分,cutoff 点的两边分别为“好”和“坏”客户,代入模型中迭代;
③ Parcelling:是结合比例分配和简单增强法,对拒绝客户打分,对每个分段按照比例进行好坏客户划分,再次代入模型进行迭代。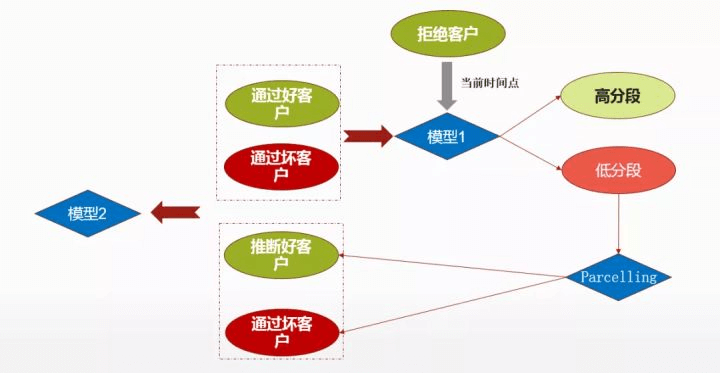
模型优化
我们的做法是使用通过的样本和通过的坏客户构建模型1,拿当前时间点跑客户评分,分为高分段和低分段,把原来拒绝客户跑完模型后高分段的样本剔除掉,对低分段特征做 parcelling,然后推断好客户和坏客户,合在一起再做模型2,然后不断的迭代这个模型,这时跑出来的模型,要比刚刚介绍的模型1方法要好。但是这种拒绝推断是没办法从样本上解决样本有偏的问题,只能从某种程度上解决。
以上就是今天要分享的内容,谢谢大家。

嘉宾介绍
韩士渊,百融云创金融科技部高级风控总监。负责百融云创非银风控业务,带领团队完成了众多金融机构的风控体系构建,包括金融产品设计、整体审批流程设计、风控模型建设、审批决策建议等,在贷前审批、贷中监控及贷后管理等不同业务阶段有丰富经验。

若有收获,就点个赞吧
0 人点赞
