大家好,我是小伍哥,今天给大家分享的是一个基于密度的欺诈检测算法,思想非常牛逼,大家可以试试,先给出论文地址和代码
论文地址:http://pengcui.thumedialab.com/papers/lockinfer-kais15.pdf
代码地址:https://github.com/mjiang89/LockInfer
注意:上面论文是英文的,如果英文不是很好的同学,我找到了中文版本的,没有网址,需后台回复【论文】获取
一、LockInfer算法概述
互联网上泛滥着形形色色的欺诈行为,特别是社交网络诞生以来,许多职业黑客和黑色产业链便通过欺诈行为谋生,淘宝的刷单、微博刷粉、抖音刷赞等都成了众所周知的事情。这种拥有批量账户为用户提供作弊的行为,叫做lockstep行为,如何检测这些作弊用户,成为一个非常大的课题。
给定社交网络、专利引用网络和电话网络等多种大规模应用的网络拓扑结构,如何能抓住可疑的用户行为?
如何能找到惊人的、难以预知的连接模式?有很多工作已经研究了通信商的欺诈行为、Ebay 中的虚假评价和 Facebook 上虚假的页面 “喜欢”,而这里所研究的是常见的异常行为模式,并尝试开发一种通用的有效方法从不同的应用中检测出这类行为,一种基于密集行为的检测方法。
1、密集行为的案例
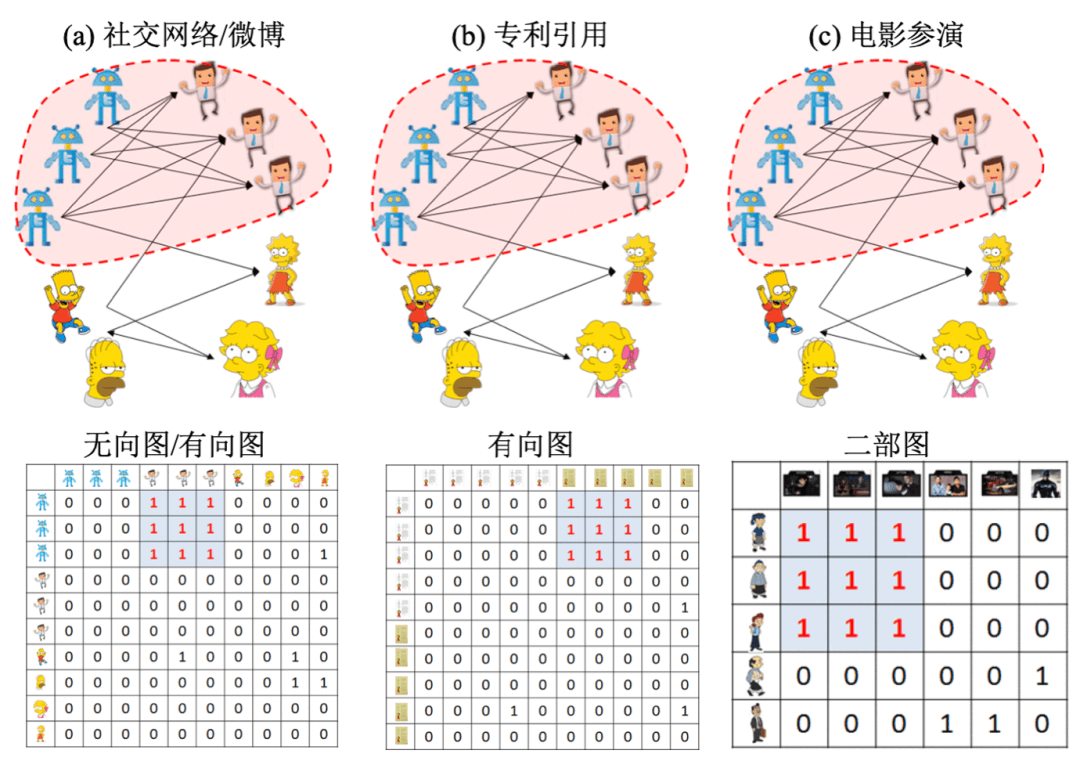
在这里我们先展示出密集行为的三个案例 :
a) 在Facebook或是Twitter 的类似的可以被表示为无向图/有向图的社交网络中,许多售粉公司都设置了百万级的僵尸粉一起行动,共同关注同一群人(顾客)来提升他们的市场价值。所以,虽然这些 被关注的人并不知名,但是他们会最终有很多粉丝。这些粉丝是花钱雇佣来的,或者是用脚本创造出来的。这种密集行为会在图对应的邻接矩阵中形成大的、密集的块。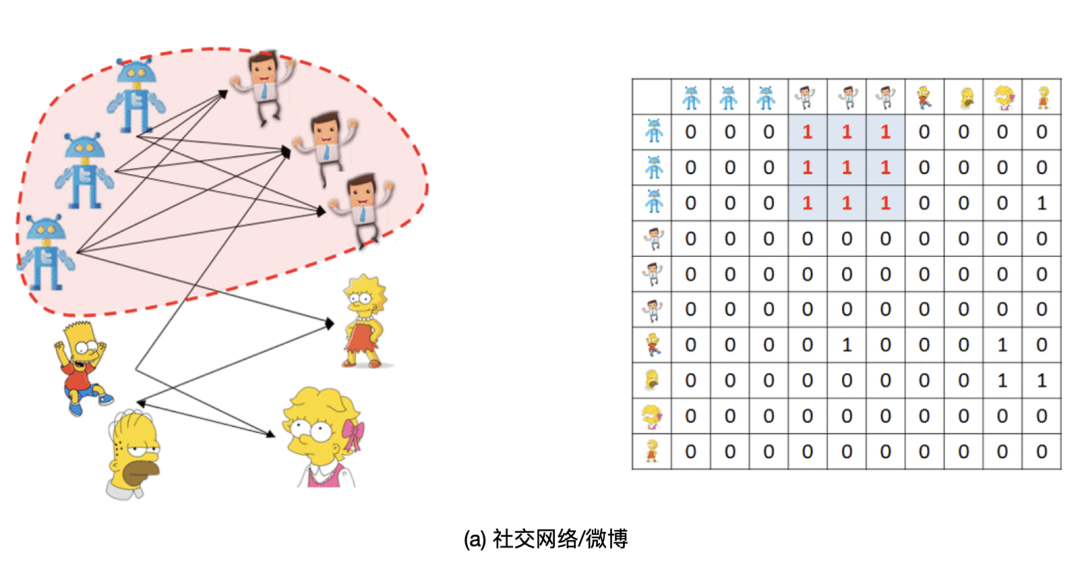
b) 在论文引用的网络中,在同一个研究问题或者是同一个项目里的研究 者们往往会互相引用对方的文章,即使这些文章与他们的工作毫不相关。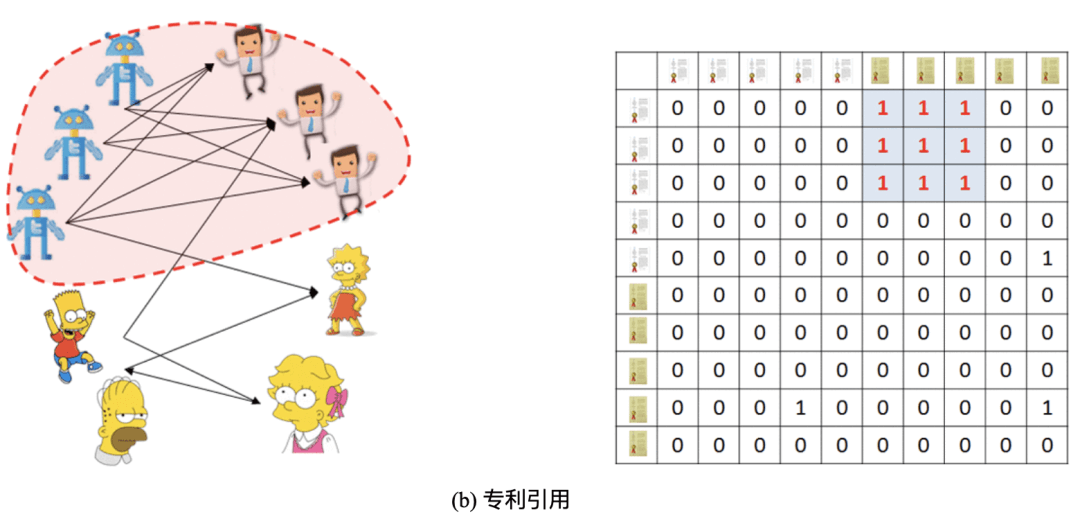
c) 在诸 如IMDb,MovieLens和Netflix 等电影参演的网络中,男演员/女演员/导演经常与关系已经很好的朋友一起合作参演电影,这样会更容易在工作中交流,更容易理解电影中演员的形象。这些网络是可以用二部图来描述的。要注意的是密集行为是说一组演员/导演与一组电影之间的交互,并最终在理解矩阵里面形成个密集子矩阵(块状)。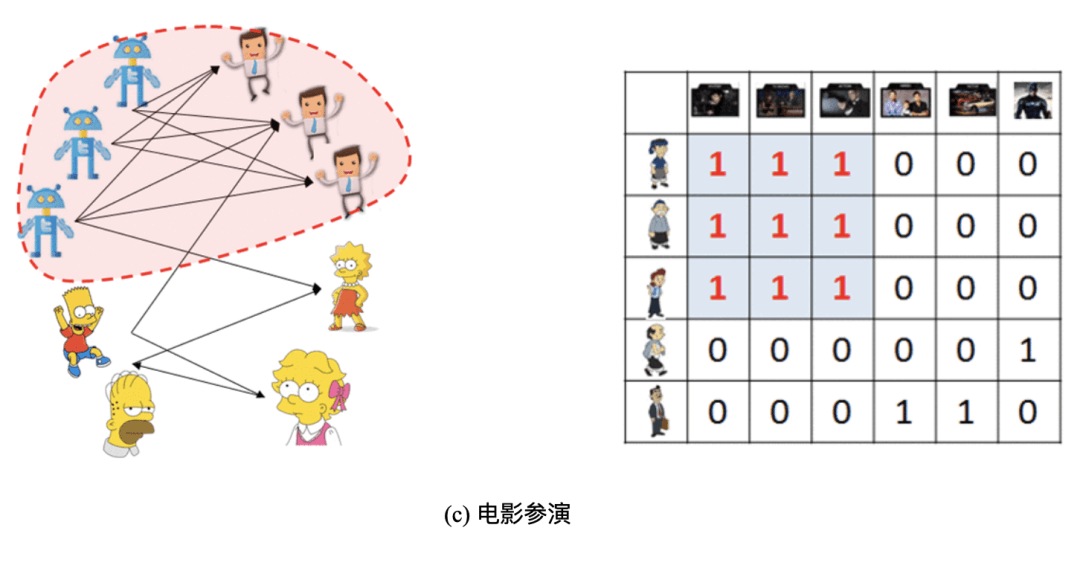
2、低密度密集连接
在基于图的应用中,密集行为模式是非常常见的,所以一个很重要又很有趣的问题是:如何来找到几乎满员的密集块状子矩阵,也就是如何找到密集行为的链接?
这个问题做起来并不那么容易,就社交网络为例,其中有很多帮助顾客提粉丝数的僵尸粉公司存在,这类行为扭曲社交媒体的网络结果,导致正常用户体验受到严重伤害,僵尸粉公司会开发出各种办法来绕开检测,一种方法是形成密度较低的块。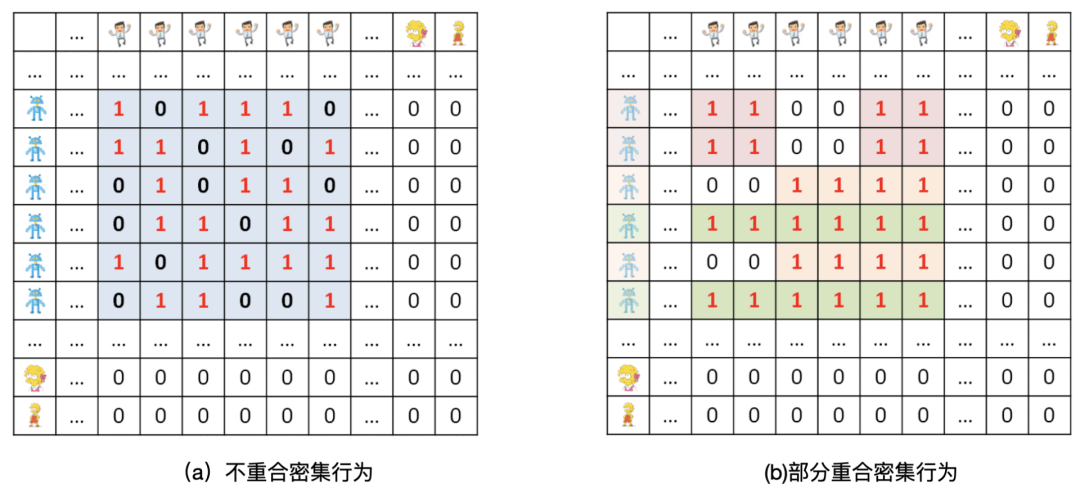
比如上图(a) 中就提出了一个更难的问题:如何检测到密集却不是100% 密集的块状结构?
什么情况下一个块过于大过于密集,以至于在图中很难出现?
图(b) 中给出了多组僵尸粉与顾客相连接的案例,僵尸粉群往往很分享顾客,而他们形成的密集行为会产生部分重合,如何检测部分重合的密集行为?
二、密集行为的类型
近年来的一些研究把社交图数据转为连接模式来研究社区结构以及聚类属性。然而,并没有任何分析能够指出如何检测出特殊行为的方式方法。本文在腾讯微博的完整有向图数据上做研究。这份数据是 2011年1月爬取得 到,含有1.17亿的用户和33.3亿的社交关系。在微博图中研究用户的关注行为时讨论了不同种类的密集行为。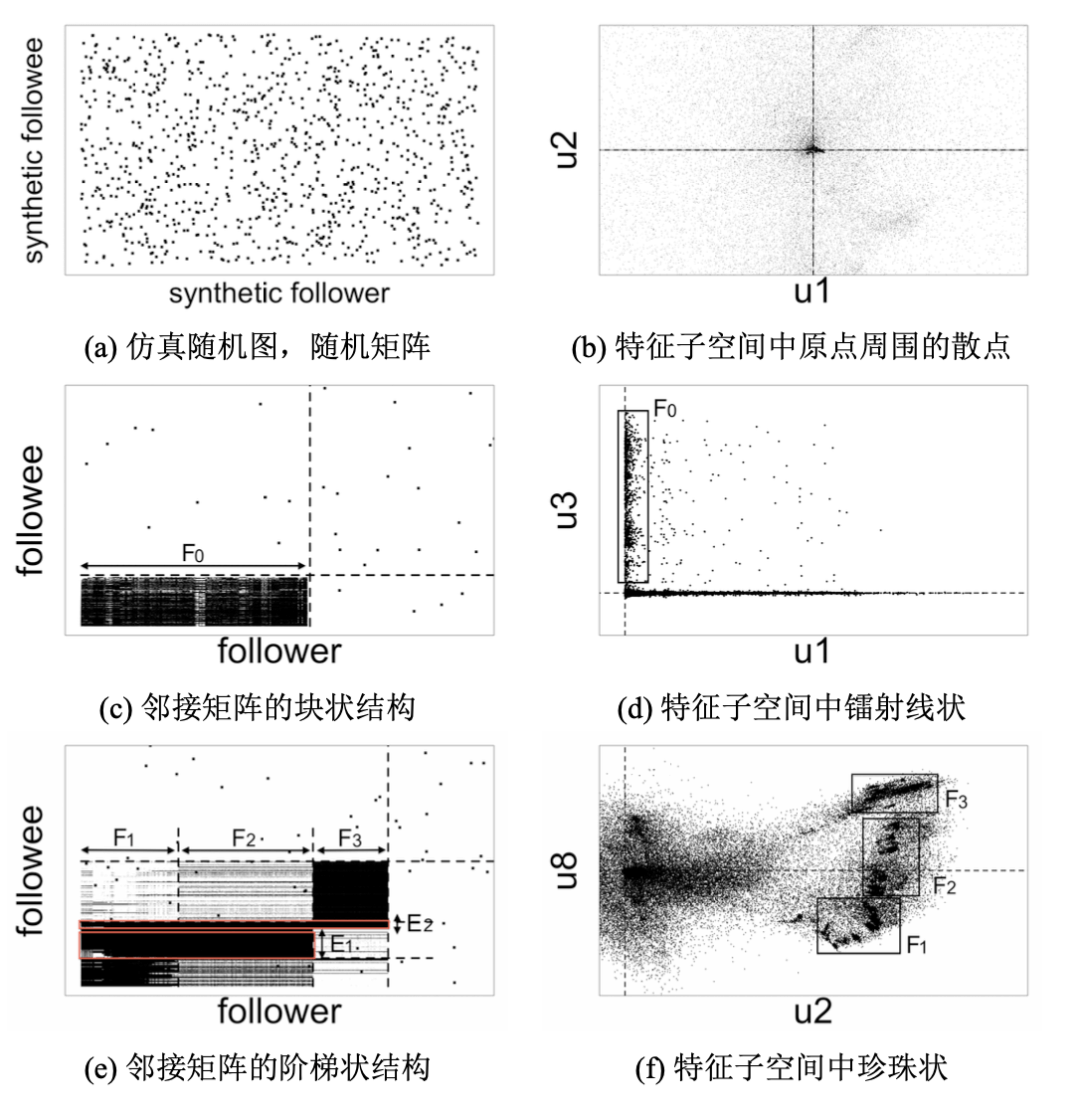
图5.5
比如图5.5(a-b) 中的无密集行为,图5.5(c-d) 中的不重合密集行为,图5.5(e-f) 中的部分重合密集行为。在邻接矩阵中寻找连接模式并 检查特征子空间中对应的形态。
图5.5(a)、5.5(c) 和 5.5(e) 中展现了链接关系,也就是用黑点描述邻接矩阵中的非零值,所在 X 轴是粉丝编号,所在Y轴是被关注人的编号。密集行为形成的 密集黑块用虚线高亮出来。
图5.5(b),5.5(d),5.5(f) 中画出了粉丝节点的一对矩阵 的左奇异向量值。这些图能够可视化特征子空间,虚线分别是 X 轴和Y轴。借助 表5.5中的名词表征复杂模式可以讨论如下: 
不含密集行为:根据Chung-Lu模型[260] 仿真了不含密集行为的随机幂律图。图5.5(a) 中的邻接矩阵并不含有大的、密集的块。本工作研究了每一对二维 的特征子空间,看到在图5.5(b) 中原点周围的粉丝。
不重合的密集行为:在腾讯微博中存在一组僵尸粉 F0 关注同一组人。那么图5.5(c) 所示,邻接矩阵中就会有一个大的密集的块(83,208 个粉丝,密度 为 81.3%)。图5.5(d) 画出了第 1 个和第 3 个左奇异向量形成的特征子空间。粉丝组 F0 在 Y 轴一侧形成镭射形状的点簇。
部分重合的密集行为:在邻接矩阵中会看到更惊奇的连接模式,也就是如 图5.5(e) 中的阶梯状(10,052 个粉丝,密度为 43.1%)。僵尸粉组 F1-F3 的密 集行为分别形成三个密度超过 89% 的密集块。然而不同于不重合密集行为, F1 和 F2 有同样的关注人群 E1,而 F1 和 F3 有同样的关注人群 E2。重合的密集行为的邻接矩阵的第2个和第 8 个左奇异向量形成了特征子空间,如 图5.5(f) 所示,含有多个微小的簇以同样的半径围绕着原点。如同不完整的 球状,又像珍珠项链,称之为 “珍珠状” 模式。
三、不同密集行为特征子空间可视化
根据不同类型的仿真密集行为在奇异向量中留下的痕迹,总结 出一系列的诊断方法。这些方法能够让数据科学家和实践者能够从奇特的连 接行为中发现可疑的用户行为。
首先要了解一个概念,特征空间,也就是邻接矩阵经过SVD分解后任取两个左奇异向量构成的二维分布空间。
通过领接矩阵特征空间的可视化可以量化lockstep行为:密集行为会在邻接矩阵中形成特定的连接模式和奇特的特征子空间的形状
- 在模拟的随机仿真图中,在特征子空间中粉丝都在原点周围分散。
- 在微博数据中,粉丝组 F0 的不重合密 集行为会在邻接矩阵中形成密集块,在特征子空间中形成镭射线。
- 粉丝组 F1-F3 的重合 密集行为会形成阶梯状结构和珍珠状的子空间分布。
接下来我们将仔细的对比一下不同密集图的邻接矩阵和特征空间的可视化结果,如下所示。
1、不含密集行为的随机图
在节点之间随机产生边的仿真图中,在特征子空间中粉丝都在原点周围分散。(左图是邻接矩阵可视化,右图是谱子空间可视化,下同) 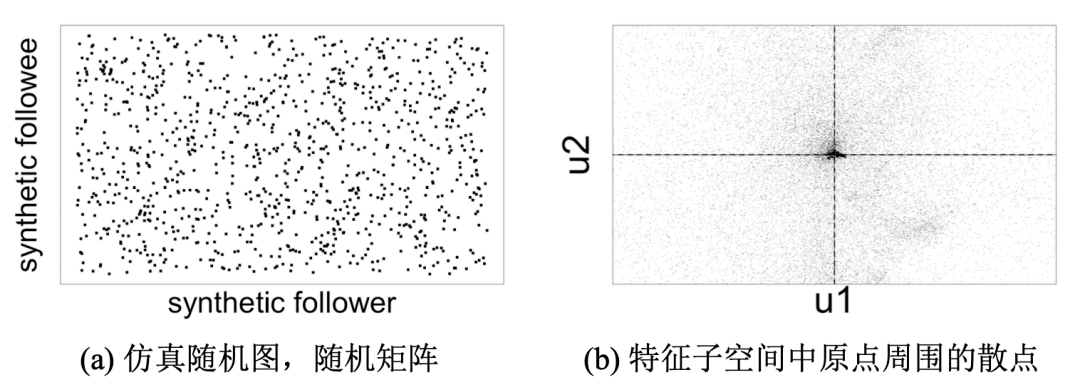
2、存在不重合密集行为的图
在微博数据中,粉丝组 F0 的不重合密 集行为会在邻接矩阵中形成密集块,在特征子空间中形成镭射线。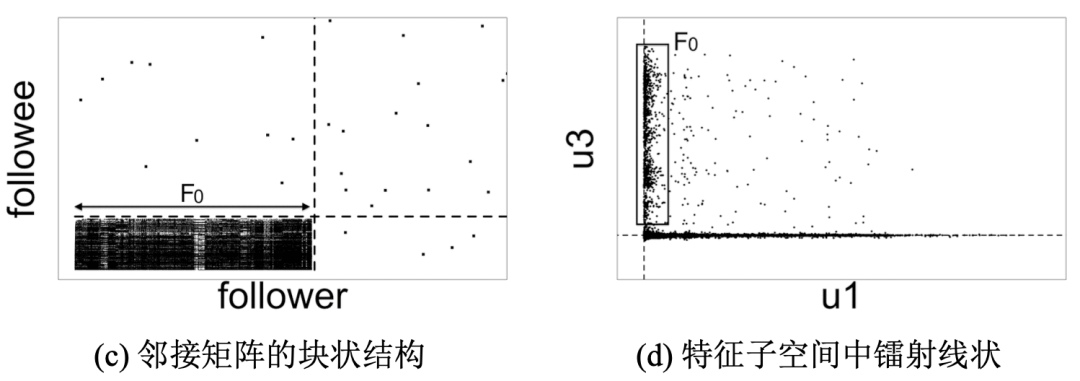
3、存在部分重合密集行为的图
粉丝组 F1-F3 的重合 密集行为会形成阶梯状结构和珍珠状的子空间分布。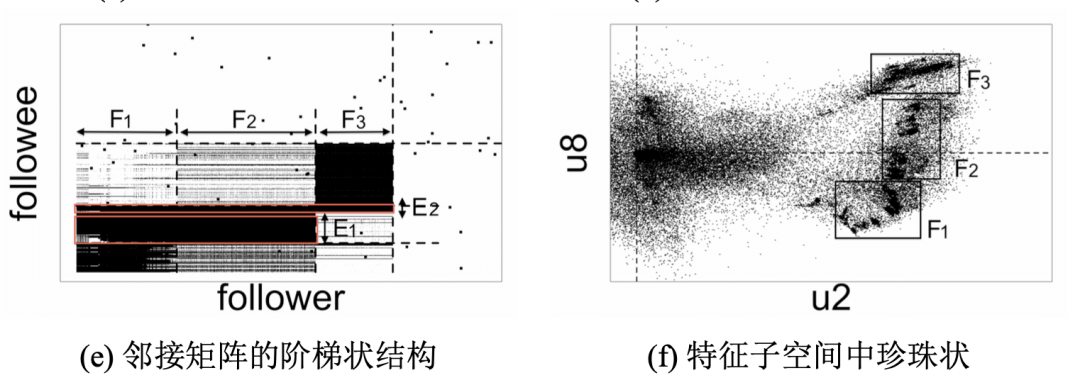
下面是针对不同lockstep分类的可视化分析结论:
四、密集行为的特征子空间的进一步分析
在这一小节,首先介绍 “密集块” 的定义和理论上的密度阈值,然后介绍如何 绘制特征子空间。通过讨论不同类密集行为,给出行为形成的密集块性质,并给出一系列从特征子空间的模式和连接模式来判断密集行为类型的规则。
1、密集块定义
用 (S , T ) 表示源节点集合 S 与目标节点 T 形成的子图。通过节点重排序之后, 邻接矩阵中就会出现 “块” 的形状。用 d(S , T ) 表示块密度即非零值比例。那么密 集块可疑定义为实际密度比均一假设下要高的块。正式的定义如下:
密集块:在邻接矩阵 A(大小为 M×N,密度为 D),一个大小为 m×n 的块 (S , T ) 可以被叫做 “密集块”,当且仅当密度 d(S , T ) 比均一密度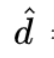 要高,即d (S,T)>=
要高,即d (S,T)>= 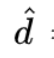
直觉上理解这个定义是说,大又密集的块表示了密集行为,所以看上去非常可疑。密度阈值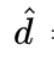 可以被如下估计。
可以被如下估计。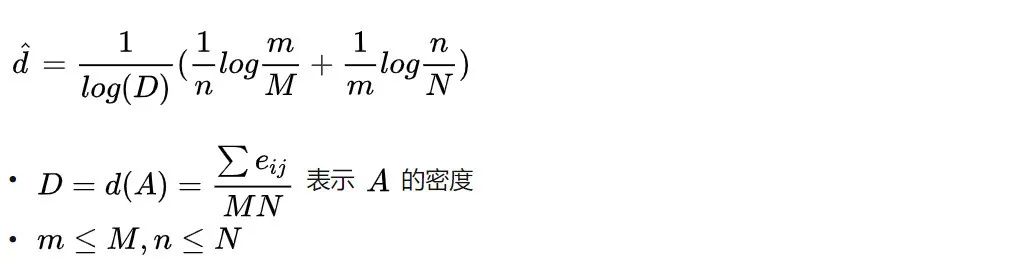
特征子空间图尝试通过可视化的方法展现出可疑的行为模式。用A来表示大小为 N × N 的社交网络邻接矩阵。每一个用户都可以被表示成一个N维的数据点,特征子空间图就是把这些在N维度的点在合适的二维子空间中展现出来。准确来说,子空间是由两个奇异值向量组成的。
k维度的奇异值分解(SVD)是把形式为 A = UΣVT 的矩阵因子化,其中 Σ 是由前 k 大的奇异值组成的、大小为 k × k 的对角矩阵,U 和 V 是大小为 N × k 的 正交矩阵,其中分别包含左奇异向量和右奇异向量。un,i 是矩阵 U 的第 (n,i) 个元 素,相似的,vn,i 是矩阵 V 的元素。un,i 是第 n 个粉丝在第 i 个左奇异向量中的值。定义 (i, j)-左特征子空间图为点集 (un,i, un, j) 形成的散点图,这就是 N 个粉丝的第 i 和第 j 个左奇异向量的映射。可以同样定义 N 个用户作为被关注人的情况,所以 (i, j)-右特征子空间图就是点集 (vn,i, vn, j) 的散点图。这个图能够可视化所有点,如果恰当使用,是可以解释很多邻接矩阵的内在性质的。
如同在图5.5(a-b) 中介绍的,给定一个随机幂律分布图,特征空间会是在原点周围的一些云一样的点集合。然而,在腾讯微博数据中看到了如镭射线状和珍珠 状的特别形状。
是什么样的用户行为导致了这些特别形状在特征子空间中出现?
简短的答案是不同种类的密集行为。
接下来会详细介 绍密集行为类型和这些特征形状之间的关系。在枚举所有密集行为的类型,首先要给出 “伪装” 和 “伪知名” 的概念。
如果粉丝集合F存在着密集关注偶像集合E的利益驱动的动机,那么他们也可以进行 “伪装”,也就是关注额外的一些不在集合E中的用户;
那些E中的用户也可能会 “伪知名”,也就是被一些额外的不在集合F中的粉丝关注。
2、构造仿真数据
根据这些概念可以构造仿真数据研究密集行为,首先产生一个大小为1M×1M 的随机幂律分布图,然后注入两组不同的存在密集行为的粉丝集合。细节上说, 注入集合 F1(50个新的粉丝)一起关注集合 E1(50个新的被关注的人)。相似地,注入另一组集合F2一起关注集合E2。下图中左侧用黑点画出邻接矩阵中的非零元素,能看到两个大小为 50 × 50 的非重合密集块,不重合的密集行为的属性设置如下:
规则 1-3 (“镭射线”):邻接矩阵中不重合的密集块。
规则 1 (短 “镭射线”): 两个密集块,90% 的高密度,不含 “伪装”,不含 “伪知名” 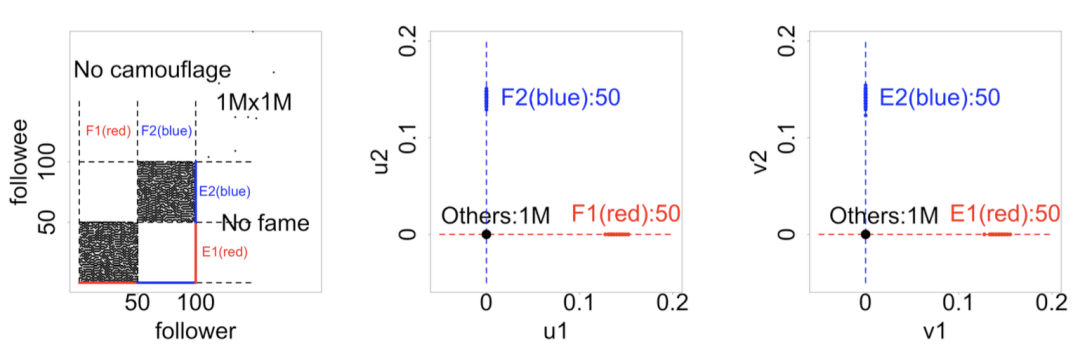
规则 2 (长 “镭射线”): 两个密集块,50% 的低密度,不含 “伪装”,不含 “伪知名” 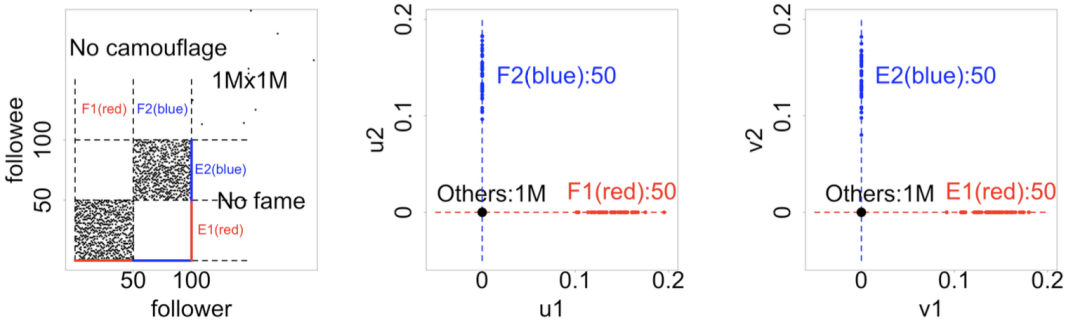
规则 3 (旋转的 “镭射线”): 两个密集块,含有 “伪装”, 不含 “伪知名” 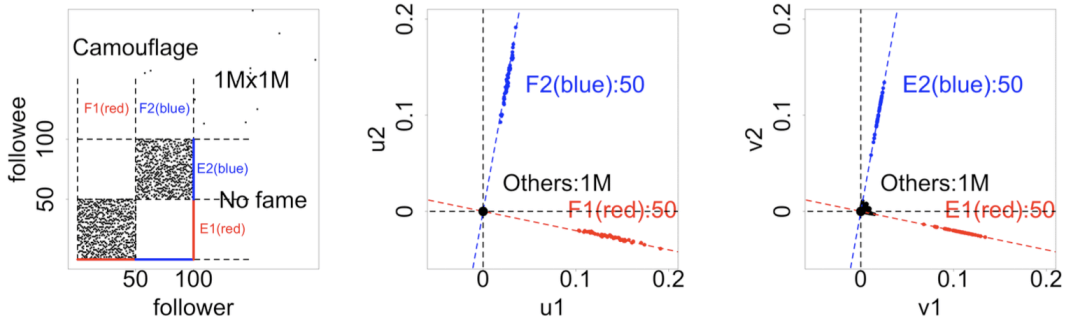
规则 3 (旋转的 “镭射线”): 两个密集块,含有 “伪知名”, 不含 “伪装” 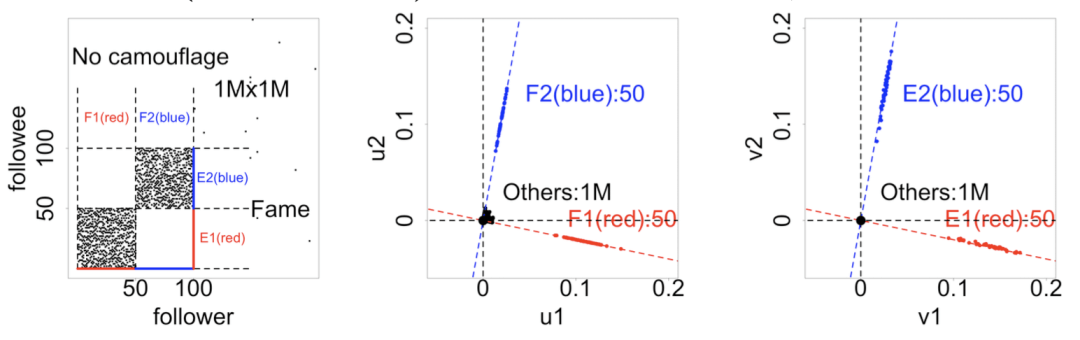
密 度:高密度是指新注入的粉丝关注90%的对应的注入的偶像;低密度是指比例为50%。
伪 装:伪装是让注入的粉丝关注0.1% 额外的偶像;如果没有伪装,那么它只关注对应的偶像。
伪知名:伪知名是让注入的偶像还会被0.1%额外的粉丝关注;如果没有伪知名,那么它只被新注入的粉丝关注。
在上图的中间和右侧分别给出了左奇异向量和右奇异向量构成的特征子空间。于是能看到不同类型的非重合密集行为存在下述的可疑踪迹:
规则 1 (短 “镭射线”):如果注入粉丝的密集行为非常紧密,邻接矩阵中会有一个或者多个密度高达90%的不重合块。特征子空间图会展现出短 “镭射 线”:向原点延伸过去的贴近轴的线状密集点集。
规则 2 (长 “镭射线”):如果注入的粉丝行为密集,但较为松散,邻接矩阵中有若干个密度为 50%的不重合块。特征子空间图展现出长 “镭射线”:镭射线会贴近轴,并且向原点伸长。
规则 3 (旋转的 “镭射线”):如果注入的粉丝有 “伪装” 或者是注入的偶像有 “伪知名” 的问题,邻接矩阵会在密集块以外形成稀疏的额外链接。和规则 1、 2 不同的是,向原点延伸的镭射线会以某个角度旋转,叫做旋转的 “镭射线”。
另一方面,如果注入的粉丝密集地关注对应的偶像集合,这些偶像集合存在 部分的重合,称之为部分重合的密集行为。仿真数据是在随机图中注入3个粉丝集合Fi (i = 1,…,3)和5个偶像集合Ei (i = 1,…,5)。每一个粉丝集合都含有1000个粉丝,每一个偶像集合都含有10个偶像。F1 的粉丝集合关注集合 E1 到 E3 的偶像;F2 的粉丝集合关注集合 E2 到 E4 的偶像;F3 的粉丝集合关注集合 E3 到 E5 的偶像。图5.8中可以看到邻接矩阵和特征子空间之间的关系。
规则 4 (“珍珠状”):重合的密集行为在邻接矩阵中形成 “阶梯状” 块,因为粉 丝集合会连接若干个偶像集合,多个密集块之间是存在重合的。特征子空间 中显示出离原点距离相近的球状,或者叫 “珍珠状” 的点簇。
图5.8(b) 给出 3 组 F1 到 F3 的粉丝集合在特征子空间中形成的3个点簇构成的珍珠状。图5.8(c) 给出 5 组 E1 到 E5 的偶像集合在特征子空间中形成的5个点簇构成的珍珠状。具有相近的或者是重合的偶像的注入粉丝会在特征子空间中靠近。
规则 4 (“珍珠状”): 三个部分重合的密集块形成的 “阶梯状” 块。 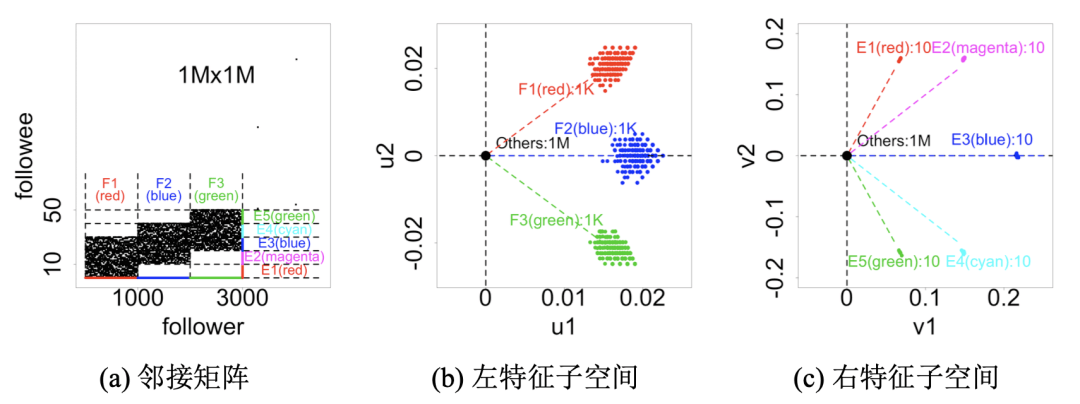
图5.8
五、基于特征子空间的密集行为检测算法实现
本工作中所给出密集行为的检测算法 LockInfer 有下面两个步骤:
种子选取: 根据上一个小节给出的规则1到4,选择具有密集行为的粉丝节点,并叫做 “有密集行为” 的粉丝。
密集值传递: 在粉丝集合和偶像集合之间传递 “有密集行为” 的值,简称密集值。每次用高于密度阈值定理给出的密度阈值 d选取有密集行为的粉丝用户,去掉并不足够密集的用户,接下来是对偶像集合做同样的处理。
算法 7中还给出了每一步骤的细节 
LockInfer可以从任意种子节点集合出发,甚至随机选取的节点。然而认真选取种子节点能加快检测速度。如下线索指出如何找到合适的种子:选择出度在尖峰处的粉丝,但出度在尖峰处的节点大多数实际上正常。用之前所给出的规则集合来选取粉丝,后续会证实这是非常有效的。
当然,如果采用额外信息,比如 IP地址、个人信息等内容,可以用这些额外 信息来选择可疑节点,例如,大量的可疑粉丝会设置自己的生日为同一年的第一 天,都是男性,都来自同样的城市。然而,如果没有额外信息,LockInfer 还是能 够从规则中有效选取种子。
图5.9给出找到种子的步骤方法。种子选取的算法有三 个步骤,如下:
首先,生成一系列的特征子空间图,计算最大的 k 个左奇异向量 u1, . . . , uk,并 画出所有粉丝节点在每一对奇异向量张成的子空间中的分布,如图5.9(a) 所示。在高维度的情况下,例如 U19 vs U20,常见的特征子空间图中原点附近有一大簇云 状点集。然而,从 U1 vs U3 中可以看到构成直角的镭射线,从 U1 vs U2 中可以看 到旋转的镭射线,从 U2 vs U8 中可以看到珍珠状分布,这些都是非常奇怪的。
正常情况下特征子空间的散点图会给出正常的 θ 和 r 频度分布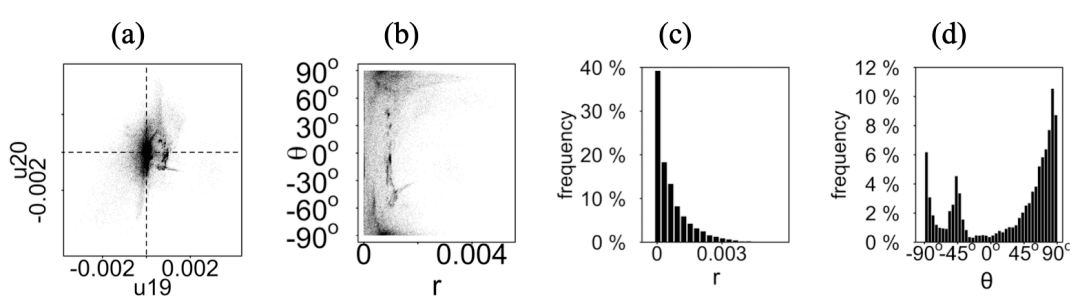
“镭射线” 会在 θ 的频度图上形成两个尖峰,出现在 0o 和 90o 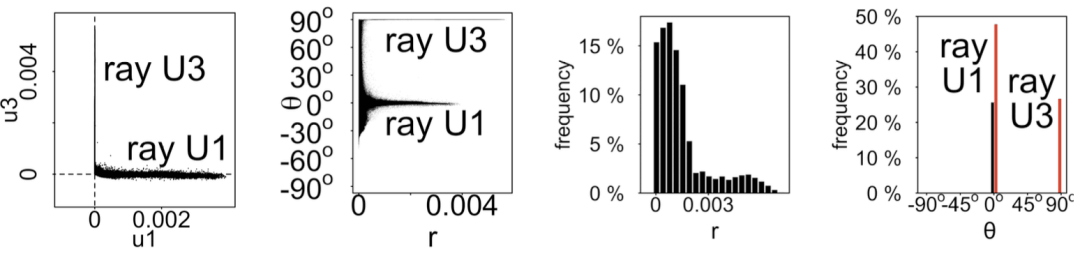
“镭射线” 会在 θ 的频度图上形成两个尖峰,出现在 0o 和 90o 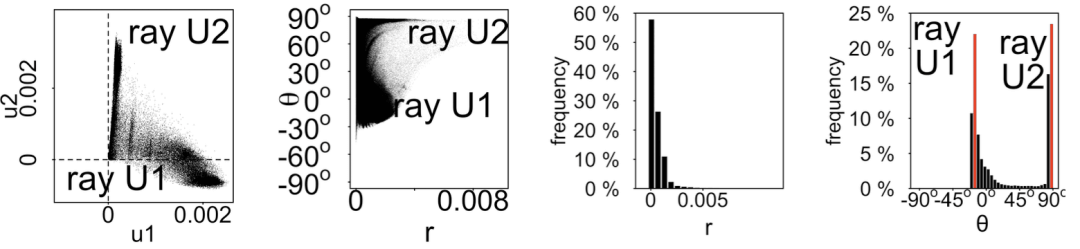
“珍珠状” 在 r 的频度图上形成一个离原点很远的尖峰 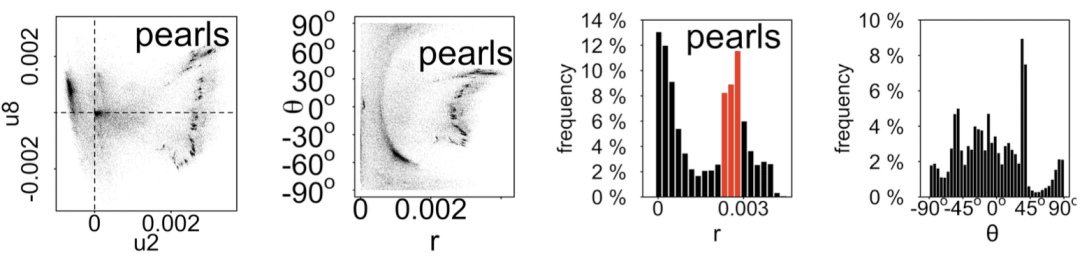
图5.9
第二,用极坐标变换把所有的点画成 (r,θ),其中 r 是点离原点的距离,θ 是旋 转的角度。如图5.9(b) 所示,镭射线会形成在 θ = 0o 和 θ = 90o 处的两个团簇,珍 珠状会形成在较大的 r 处的一些微小的点簇。
第三,可以把距离 (r) 和角度 (θ) 的轴分割为若干个部分,并且把 r 和 θ 的频度画在柱状图中。镭射线构成的角度分布图会在 0°和 90° 形成尖峰,但是在其他部位并没有尖峰;珍珠状构成的距离分布图会形成单个尖峰,而其他图中频度会 随着距离增大而慢慢减小。用中位数过滤法[278] 可以检测尖峰,并且把尖峰处的 节点放入种子集合中。
要注意的是,如果不存在密集行为,邻接矩阵中没有密集块,特征子空间图会在原点周围形成云状节点。角度 θ 的频度会几乎是一个常数,而 r 的节点频度 会随着 r 的增大而减小。
设定参数时,密集块的最小规模是 mmin×nmin (mmin = 100, nmin = 10),最小的密度是 d。同时可以设置 k = 20 来权衡特征子空间图的数量和 SVD 的运算时间。通 过阅读极坐标图,画出距离和角度的频度分布图,切割距离的轴为Kr =20个柱 子,切割角度的轴为Kθ =2 Kr =40个柱子,因为θ可能为正也可能为负。 
下面是进行 “密集值” 的传递来找到所有有密集行为的粉丝和偶像节点。定 义粉丝节点的密集值为其对应的有密集行为的偶像节点的百分比,定义偶像节点 的密集值为对应的有密集行为的粉丝节点百分比,由此每一次用一个密度阈值来 选择新的具有密集行为的粉丝节点和偶像节点集合。Scoop 函数如信任传递算法, 迭代地从粉丝到偶像,从偶像到粉丝传递密集值。下面来解释其中每一个步骤。 


从源节点(粉丝)到目标节点(偶像): 图5.10(a) 的有向图中上面是粉丝集 合,下面是偶像集合。如果从 5 个密集的粉丝出发,对每一个偶像,计算他 们粉丝在种子集合中的比例。选取有比例高的偶像作为有密集行为的偶像。函数 S2T 给出如何从源节点传递密集值到目标节点。
从目标节点(偶像)到源节点(粉丝):接着是对每一个粉丝,计算他有多 少比例的偶像是有密集行为的。图5.10(b) 给出了如何选取新的密集行为粉 丝,并去除无辜的不关注或者只关注 1 个的偶像。函数 T 2S 给出了如何从 目标节点传递密集值到源节点。
重复到收敛:当收敛的时候如果密集块并不为空,报告有密集行为的粉丝和偶像集合。 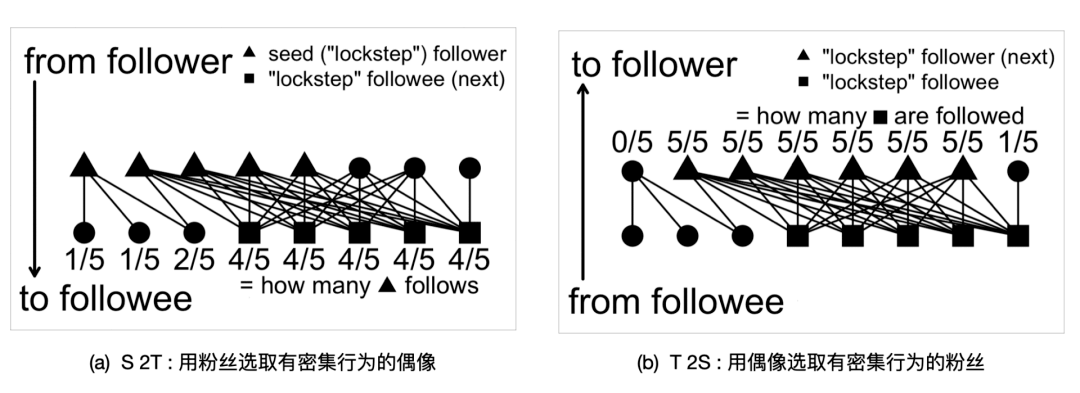
图5.10
LockInfer 的时间复杂度为 O(E),算法是随着边数呈线性关系。在仿真的呈 对角块状的邻接矩阵中运用该算法,每一个块都有 10,000 个节点和 40,000 个随机 边,重复块结构得到含有 1,300,000 个节点和 5,100,000 个边的仿真图。图5.11展示 了随着仿真图数据的大小(边数)变化的运行时间。注意到的是时间曲线与社交 图的规模呈线性关系,LockInfer 算法是可扩展的,可被用于真实应用中。 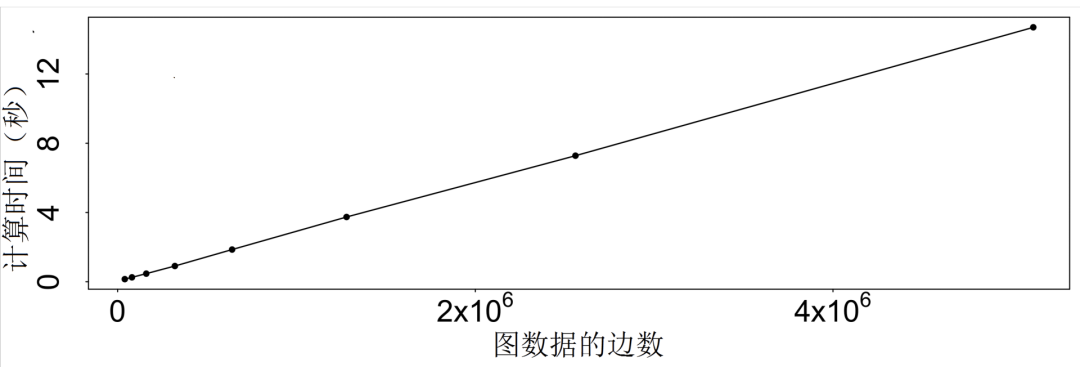
六、与其他算法的对比
下表给出本工作的 LockInfer 算法与采用特征向量和特征子空间的传统图挖掘方法相比,既有效、又有可解释性,还兼具可扩展性。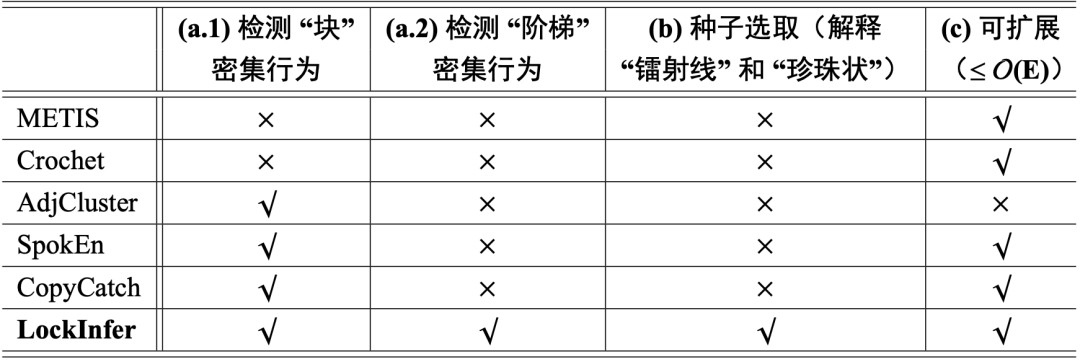
先写到这里吧,眼见看花了,需要跟多细节的,回复【论文】,获取中文论文。

若有收获,就点个赞吧
0 人点赞
