来源:https://zhuanlan.zhihu.com/p/141287611/
风控业务背景
模型构建固然重要,但最终是为了将模型应用于实际业务中,创造价值。从这个角度而言,完全不懂策略的风控建模师是不合格的。在交付模型时,建议与策略同学多加沟通,不仅是给出模型的技术指标,说明正确的使用方法(应用不当就会产生模型风险),更需要学一点策略知识。这不仅让你拥有更宏观的业务视野,也会更明确自身价值。☀️
本文从模型视角介绍一些策略规则发现的常见做法,希望能对初学者有所启迪。
目录
Part 1. 模型与策略之间的边界和联系
Part 2. 基于画格子的规则生成方法
Part 3. 基于决策树的规则生成方法
Part 4. 总结
致谢
版权声明
参考资料
Part 1. 模型与策略之间的边界和联系
在平时工作中,我们会发现策略组类似模型组的“甲方“,向模型组提需求。而模型组则在开发完模型后,交付相应的模型分和开发文档。这是因为:
模型是策略的工具,策略往往包含了模型,是模型的延伸。(摘自参考资料1)
如图1所示,策略规则生成中需要综合多种来源的变量,大致可分为3个来源:
- 模型分数:对于一些弱(金融属性)数据源,难以提取有效的强单变量,此时就需要借助模型来提取合成一个强变量分数。模型的好处很明显,一是可以提高单变量排序性,二是变量降维,三是综合多个维度。
- 客群标签:风控策略决策对象归根结底是人,那就可以利用用户画像标签,比如性别、收入、学历、地域、年龄、职业等。这些标签的业务可解释性非常强,适合对人群不断细分,分而治之。
- 其他变量:指一些区分度本身就比较强的变量,如多头借贷变量、征信、黑白名单等。这些变量可能本身就很强,可以挑选一些直接用于规则,而不需要再通过模型来融合。
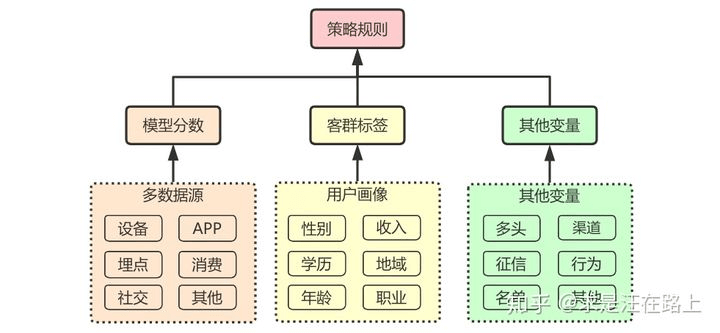
图 1 - 策略规则生成的多维度变量来源
广义上来说,策略也是一种模型。但仍存在一些侧重点差异,体现在:
- 复杂度:模型常采用一些机器学习/深度学习算法(如NLP、Graph Embedding),挖掘各类数据来构造特征。同时,利用一些回归、分类算法(如逻辑回归、XGBoost)学习输入(特征X)与输出(目标Y)之间的统计规律;策略则需要结合具体业务场景,主要依赖于人工业务经验对客群细分,一般用简单的多变量交叉切分(画格子)或使用决策树分群,这是为了保证足够的解释性,便于感知业务影响。
- 迭代周期:模型重,策略轻。模型往往会经过长时间窗的稳定性验证,保证上线后持续较长时间都保持稳定,只有当模型出现明显衰减(排序性变弱)时才会迭代;而策略则可以根据近期样本快速调整,上线下线都更为灵活。例如,若近期发现某个地区发现大面积欺诈行为,那就直接上线地域拦截规则。
业务影响:模型退居二线,如违约预测(PD)模型可输出人群的违约概率,但这并不能直接产生业务贡献;策略站在业务第一线,更为关注对不同细分人群的决策结果,比如:是否准入?授信额度多少?利率定价多少?
Part 2. 基于画格子的规则生成方法
风控策略本质是若干变量通过AND、 OR等逻辑运算组成的规则集,目标是为了降低坏账率、提高通过率、提升利润率等。典型的风控策略格式如下所示:
如果: AND 最近1个月多头申请机构数 >= 5 AND 模型信用分 < 500 OR 历史最大逾期天数 > 10 那么: 选项 予以拒绝(RJ)
很多时候,我们都在思考如何自动从大量变量(高维空间)里找到较少变量(低维空间)组成的规则集合,即规则发现。
一种常见策略规则的做法,即笛卡尔积法,俗称“格子大法”。可分为以下几个步骤:获取变量: 定义bad,取最近完全进入表现期的样本,关联潜在可用的特征变量集X。
- 变量筛选:通过IV快速筛选。对IV靠前的一些变量,记录相应的分箱边界供后续使用。
- 指标统计:对多个单变量分箱后分组,统计申请量、放款量、坏账量等数量指标。
- 透视呈现:分多个维度,统计每个格子内的申请率、放款率、坏账率等比率指标。
- 规则提取:结合坏账率目标和样本量,圈出满足要求的格子,提取相应的规则逻辑。
- 规则评估:评估跨期稳定性,分析在不同时间窗圈定订单的通过率、逾期率等指标。
- 策略上线:在决策引擎(如SMG3)上配置规则,设置作用的订单尾号和其他参数。
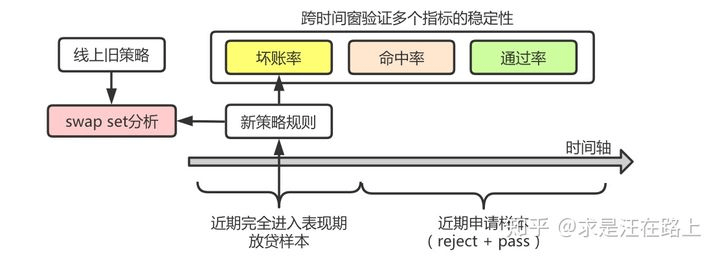
图 2 - 策略生成逻辑与验证
在明确上述基本步骤后,我们以  和
和  两个变量来制定规则,统计代码如下:
两个变量来制定规则,统计代码如下:
select applymonth, x1_bin, x2_bin ,count(1) as appl_cnt — 申请量 ,count(case when is_loan = 1 then order_id else null end) as loan_cnt — 放贷量 ,count(case when is_del = 1 then order_id else null end) as del_cnt — 逾期量 from ( select order_id ,apply_month — 申请月份 ,apply_time — 申请时间 ,is_loan — 是否放贷 ,is_del — 是否逾期 _ ,case when x1 < 600 then ‘0.(-inf,600)’ when x1 >= 600 and x1 < 620 then ‘1.[600,620)’ when x1 >= 620 and x1 < 660 then ‘2.[620,660)’ when x1 >= 660 and x1 < 700 then ‘3.[660,700)’ when x1 >= 700 then ‘4.[700,inf)’ else ‘null’ end as x1_bin ,case when x2 >= 0 and x2 < 3 then ‘0.[0,3)’ when x2 >= 3 and x2 < 5 then ‘1.[3,5)’ when x2 >= 5 and x2 < 7 then ‘2.[5,7)’ when x2 >= 7 and x2 < 9 then ‘3.[7,9)’ when x2 >= 9 then ‘4.[9,inf)’ else ‘null’ end as x2_bin from vdm_risk.fhj_sample ) a group by apply_month, x1_bin, x2_bin; 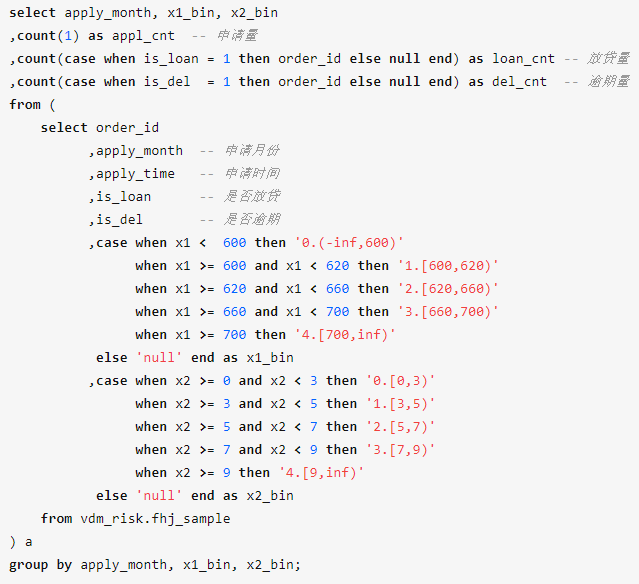
为了便于后续分析策略规则的跨期稳定性,我们加入时间维度进行统计。固定时间点,可统计 和
和  两个变量组成的二维格子里的(订单口径)申请量、放贷量、坏账量、放贷率、坏账率等,如图3所示。
两个变量组成的二维格子里的(订单口径)申请量、放贷量、坏账量、放贷率、坏账率等,如图3所示。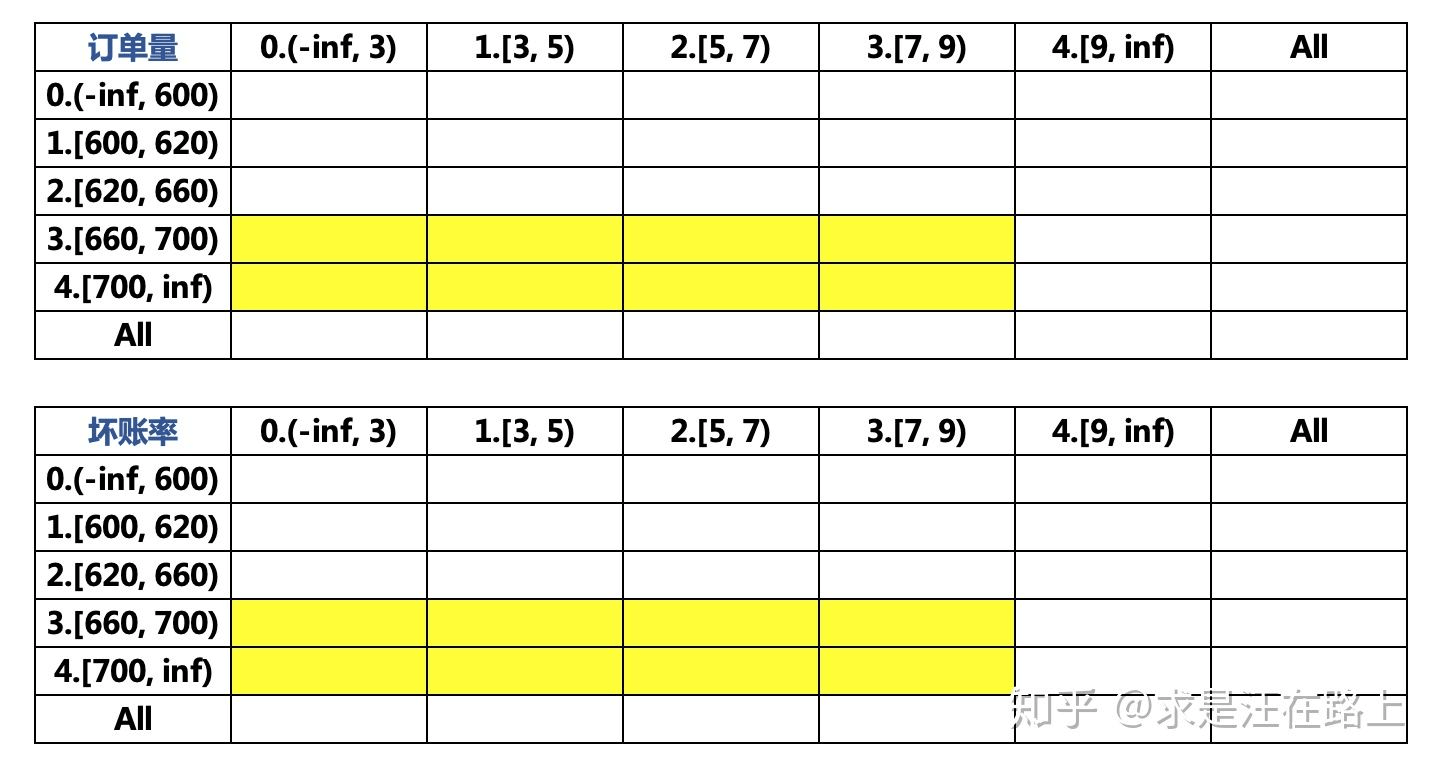
图 3 - 双变量交叉组成的决策矩阵
风控策略中常遇到的两个问题是:
- 降低坏账率,此时就需要将高于目标坏账率的格子里的客户拒绝。
- 提升通过率,即拒绝回捞。这就需要推断被拒绝的人群的贷后表现,将部分误拒人群捞回。
在图3中,我们希望拒绝回捞,那就可以考虑将黄色部分的格子(坏账率均低于2%)予以回捞。如果继续增加更多维度,我们发现格子数量会增加。相应地,落到每个格子里的样本量也就会减少,此时可能会失去统计意义。尤其在计算比例类指标时,对样本量有基本要求(1K+)。因此,我们可以考虑:先看大格子,再看小格子。
如图2所示,按此方法,从放贷样本中提取满足要求的规则后,我们需要在近期申请样本上评估规则的稳定性,包括:
- 对通过率的影响:若通过率持续升高,这就可能引起我们的担忧,毕竟通过率与坏账率是正相关的;若通过率持续走低,那么就可能引起客户的不满,毕竟交易一直被拒可能导致客户流失。因此,通过率要保持一定的稳定,才是我们乐于见到的现象。
- 对坏账率的影响:由于逾期风险总是滞后的,我们无法预料,一般只能在最近放贷进入表现期的样本上分析,但可以用早期表现(early performance)来估算。例如,生成规则时参考FPD30+风险,在评估稳定性时可以用FPD7+,以此获得更长的评估窗口。
同时,考虑到与线上策略的重合度,我们还需要评估新策略与旧策略之间的效果差异。如果新策略的增量很小,可能就不考虑上线替换。可参考《利用Swap Set分析风控模型更替的影响》一文。
Part 3. 基于决策树的规则生成方法
格子大法是策略同学平时用到最多的方法,其易于解释、控制调整;但缺点在于,当变量维度增加时,难以从大量小格子里筛选满足业务目标的规则,这会给策略同学带来极大的工作量。
此时,我们可借助一种常见算法——决策树 ,例如CART回归树。
from sklearn import tree # 初始化树结构参数 dtree = tree.DecisionTreeRegressor( ccp_alpha=0.0, criterion=‘mse’, max_depth=3, max_features=None, max_leaf_nodes=6, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=20, min_samples_split=100, min_weight_fraction_leaf=0.0, presort=‘deprecated’, random_state=None, splitter=‘best’)
决策树的好处在于,其可根据信息增益、信息增益率等指标,自动进行人群细分。通常,我们可以利用下列几个参数来控制分群数量:
- max_depth:最大树深。树深越大,模型越复杂,分裂产生的叶子节点(子客群)也越多。
- min_samples_leaf:叶子节点最小样本量。
- min_samples_split:父节点在分裂前需要的最少的样本量。
# 拟合数据 dtree.fit(X=df[featcols].fillna(-999999), y=df[‘del_30’], sample_weight=None, check_input=True, X_idx_sorted=None)
为了便于观察各子客群的样本量、坏账率等指标,我们将其可视化:
from sklearn.externals.six import StringIO dot_data = StringIO() tree.export_graphviz( decision_tree=dtree, # 拟合完毕的CART树 out_file=dot_data, # 输出数据 max_depth=None, feature_names=feat_cols, # 入模特征列表 class_names=[‘del_30’], # y变量 label=‘all’, filled=False, leaves_parallel=False, impurity=True, node_ids=False, proportion=False, rotate=False, rounded=False, special_characters=False, precision=3, ) # 读取树结构数据 import pydotplus graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) # 可视化展示树_ from IPython.display import Image Image(graph.create_png())
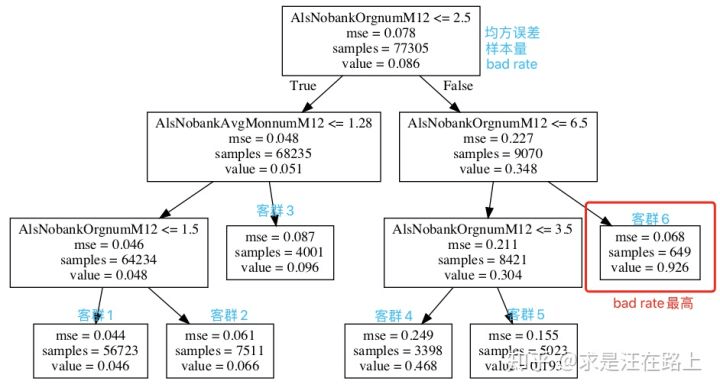
图 4 - 二叉决策树可视化
如图4所示,决策树共分支产生6个叶子节点客群。根节点(大盘)的坏账率为8.6%,而客群6的坏账率达到92.6%,远高于大盘,可考虑作为欺诈规则予以拒绝。从决策路径上看,这个客群的多头指数在7以上,符合业务sense。
值得指出的是,决策树存在以下缺点:
- 业务合理性:分裂时完全依赖于Gini系数等指标,有时缺乏业务意义。例如,在图4中,决策分界点都非整数,结合变量含义,需要人工调整为整数相对更为合理。
- 过拟合现象:需要跨期验证稳定性,避免只是在当前数据集上效果明显,但跨期并不稳定。
- 不容易控制:与格子大法有所差异的是,决策树是有监督自动学习,无需人工介入,这就不容易调整。
Part 4. 总结
本文较为系统地探讨了模型与策略之间的关系,以及介绍了两种常见的策略规则生成方法。当然,一个合格的策略需要接受各类业务场景的锤炼,基本方法论仍不足以覆盖一切。我们需要多加实践,培养宏观的业务视野。
笔者认为,先从风控模型做起,打好基础(包括对底层数据源的熟悉程度、算法工具的掌握、模型设计分析的思维全面性等)后,再转去做策略是比较合适的发展路线。理由是,要想让你的模型真正产生价值,你就需要不满足模型的边界,勇于站到业务第一线,推动业务的前进
美国模型风险监管体系介绍以及同盾的建议
https://mp.weixin.qq.com/s/95MVhXgyG9h5KqRphP14cA
参考资料
美国模型风险监管体系介绍以及同盾的建议mp.weixin.qq.comDataFunTalk:信贷业务风控策略简介zhuanlan.zhihu.comZain Mei:一种基于卡方分箱和回归树的策略挖掘方法zhuanlan.zhihu.com
关于作者:
在某互联网金融公司从事风控建模、反欺诈、数据挖掘等方面工作,目前致力于将实践经验固化分享,量化成长轨迹。欢迎交流

若有收获,就点个赞吧
0 人点赞
