目录
- 3. 代码实现GRU
-
1. 什么是GRU
在循环神经⽹络中的梯度计算⽅法中,我们发现,当时间步数较⼤或者时间步较小时,循环神经⽹络的梯度较容易出现衰减或爆炸。虽然裁剪梯度可以应对梯度爆炸,但⽆法解决梯度衰减的问题。通常由于这个原因,循环神经⽹络在实际中较难捕捉时间序列中时间步距离较⼤的依赖关系。
门控循环神经⽹络(gated recurrent neural network)的提出,正是为了更好地捕捉时间序列中时间步距离较⼤的依赖关系。它通过可以学习的⻔来控制信息的流动。其中,门控循环单元(gatedrecurrent unit,GRU)是⼀种常⽤的门控循环神经⽹络。2. ⻔控循环单元
2.1 重置门和更新门
GRU它引⼊了重置⻔(reset gate)和更新⻔(update gate)的概念,从而修改了循环神经⽹络中隐藏状态的计算⽅式。
门控循环单元中的重置⻔和更新⻔的输⼊均为当前时间步输⼊与上⼀时间步隐藏状态
,输出由激活函数为sigmoid函数的全连接层计算得到。 如下图所示:
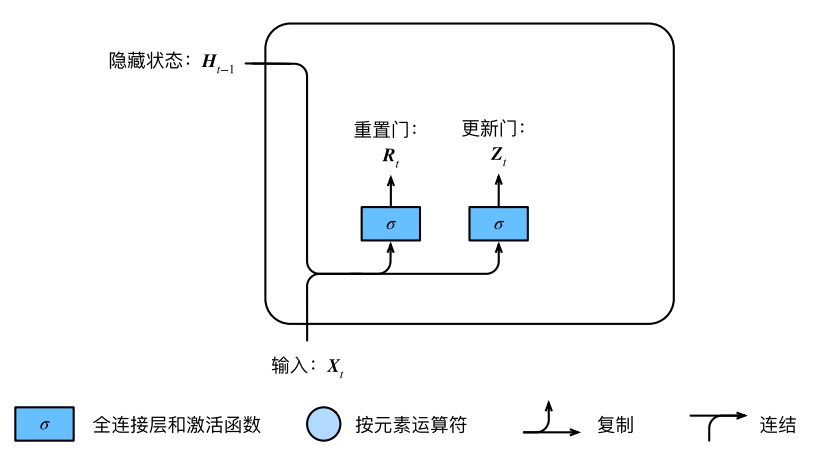
具体来说,假设隐藏单元个数为 h,给定时间步 t 的小批量输⼊(样本数为n,输⼊个数为d)和上⼀时间步隐藏状态
。重置⻔
和更新⻔
的计算如下:
)
)
sigmoid函数可以将元素的值变换到0和1之间。因此,重置⻔和更新⻔
中每个元素的值域都是[0, 1]。
2.2 候选隐藏状态
接下来,⻔控循环单元将计算候选隐藏状态来辅助稍后的隐藏状态计算。我们将当前时间步重置⻔的输出与上⼀时间步隐藏状态做按元素乘法(符号为⊙)。如果重置⻔中元素值接近0,那么意味着重置对应隐藏状态元素为0,即丢弃上⼀时间步的隐藏状态。如果元素值接近1,那么表⽰保留上⼀时间步的隐藏状态。然后,将按元素乘法的结果与当前时间步的输⼊连结,再通过含激活函数tanh的全连接层计算出候选隐藏状态,其所有元素的值域为[-1,1]。
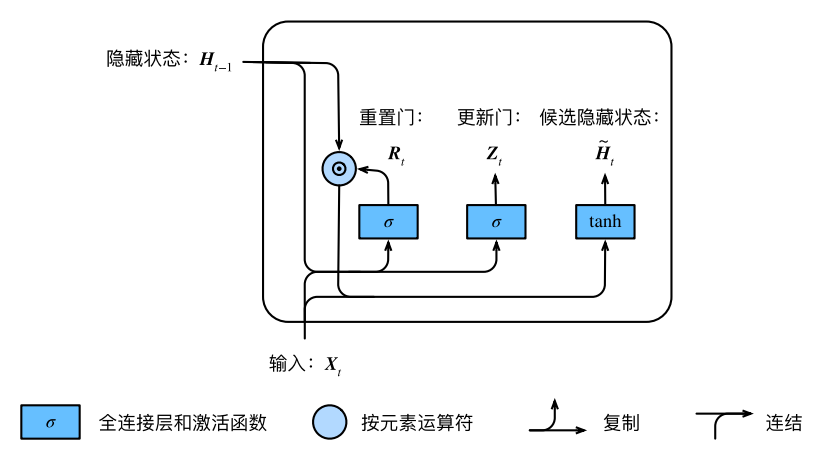
具体来说,时间步 t 的候选隐藏状态的计算为:
W_%7Bhh%7D+b_h))
从上⾯这个公式可以看出,重置⻔控制了上⼀时间步的隐藏状态如何流⼊当前时间步的候选隐藏状态。而上⼀时间步的隐藏状态可能包含了时间序列截⾄上⼀时间步的全部历史信息。因此,重置⻔可以⽤来丢弃与预测⽆关的历史信息。2.3 隐藏状态
最后,时间步t的隐藏状态
做组合:
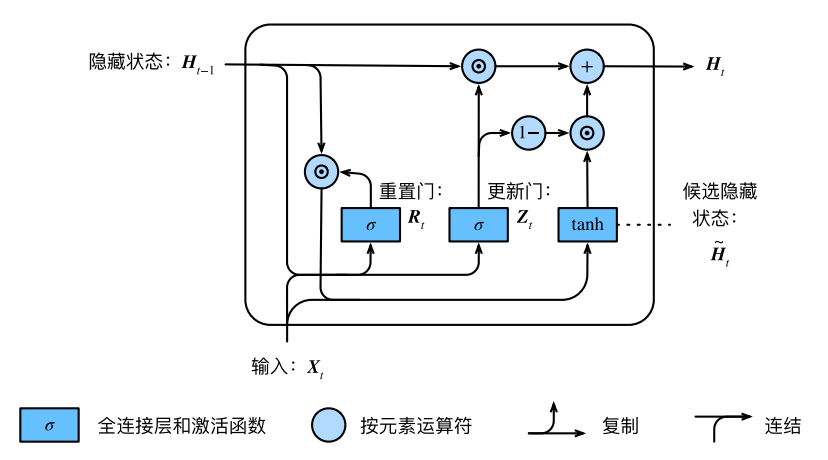
值得注意的是,更新⻔可以控制隐藏状态应该如何被包含当前时间步信息的候选隐藏状态所更新,如上图所⽰。假设更新⻔在时间步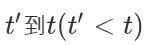 之间⼀直近似1。那么,在时间步
之间⼀直近似1。那么,在时间步 间的输⼊信息⼏乎没有流⼊时间步 t 的隐藏状态
间的输⼊信息⼏乎没有流⼊时间步 t 的隐藏状态 实际上,这可以看作是较早时刻的隐藏状态
直通过时间保存并传递⾄当前时间步 t。这个设计可以应对循环神经⽹络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较⼤的依赖关系。
我们对⻔控循环单元的设计稍作总结: 重置⻔有助于捕捉时间序列⾥短期的依赖关系;
- 更新⻔有助于捕捉时间序列⾥⻓期的依赖关系。
3. 代码实现GRU
MNIST—GRU实现4. 参考文献
《动手学—深度学习》
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
欢迎大家加入讨论!共同完善此项目!群号:【541954936】


若有收获,就点个赞吧
0 人点赞
