写文章也一年多了,这一年的时间里一直在学习、总结、思考不停地反复,逐渐从一个菜鸟到对这门技术慢慢有了自己的认知。但是即便如此,我内心还是深知自己不明白的东西有很多,依然有许多需要实践和积累的。最近又回头去看求是汪的文章,很多东西看一遍很容易遗忘,需要不停地反复阅读、思考和总结。所以突然就有了写这篇文章的想法,将评分卡中理论的东西整理一下,具体顺序全凭自己的记忆和思路。目的也是为了重新夯实一下基础,让自己的内心感到更加踏实和安全。
一、评分卡的映射逻辑
这个之前写过逻辑回归评分卡映射,具体细节不展开。一些重要的公式如下,这几个公式是评分卡映射中的核心公式,后面会重复提到。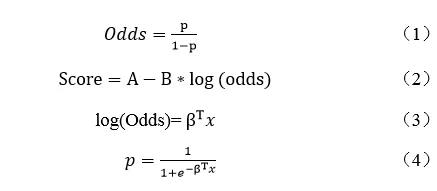
评分卡映射的逻辑中,需要对θ0(初始违约概率)、P0(初始分数)、PDO(翻番倍数)作出假设,这三个数值决定了评分转化中的A和B的值。由此衍生出几个问题:
1.逻辑回归输出的y为什么可以表示违约概率?
由上式4可以知道,逻辑回归输出的y就是p,这是表面上的原因。深层原因是,第4步的步骤其实是一个普拉托平滑,可以使输出概率的分布是正态分布,这在评分卡校准的时候会用到。而像xgb这些模型由于没有做相关性筛选,入模变量相关性比较高,因此输出概率分布一般服从长尾分布(各种因素对结果的影响不是相加,而是相乘,那么最终结果不是正态分布,而是对数正态分布)。
2.逻辑回归的系数的绝对值是否可以认为是特征的重要性?
逻辑回归系数的绝对值越大,说明对分类效果的影响越显著。但是因为改变变量的尺度就会改变系数的绝对值,而且如果特征之间是线性相关的,则系数可以从一个特征转移到另一个特征。特征间相关性越高,用系数解释变量的重要性就越不可靠。
3.不同客群的评分卡(逻辑回归)为什么不用进行校准?
评分卡背后的实质是score、ln(odds)、p之间的映射关系。如果同样一个score对应的p不一致时,则需要对评分进行校准。而由(2)式可知,确定score和ln(odds)关系的是A和B。因此只需要θ0(初始违约概率)、P0(初始分数)、PDO(翻番倍数)这三个值一致,那么评分卡分数的尺度则是一样的,无需进行任何校准。
如果两个逻辑回归的分数已经采用了不同的θ0、P0、PDO,则需要再对这两个分数分别再进行一次普拉托变换,则可以将分数校准至同一水平。
4.为什么逻辑回归拟合出来的截距等于ln(odds)?
这个问题在求是汪的文章中有给过推导: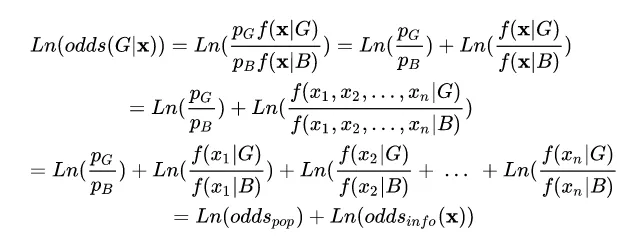
大致思路是ln(odds)是先验信息,随着观察信息的不断加入,引起后验信息的变化,最终对群体的好坏评价越来越客观。这种朴素贝叶斯的假设思想很重要,也就是上面第一步到第二步。为了解释第一步到第二步的变化,可以看下面的例子: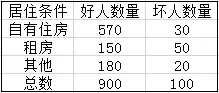
以x为自有住房为例,f(x|G)表示在好人情况下x为自有住房的概率,也被称为似然函数,描述属性向量有多大可能性落在好和坏的群体中。f(x|G)=570/900。
p(G|x)是条件概率,p(G|x)=570/600;
f(x)是x出现的概率,f(x)=600/1000;
p(G)是整体概率,p(G)=900/1000。
将上面四个值两两相乘,得到下式: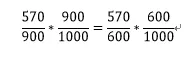
对应上面的公式则是:
f(x|G)p(G)=p(G|x)f(x)
f(x|B)p(B)=p(B|x)f(x)
两式相除得到: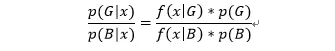
左边的式子就是ln(odds),也就是上式中第一步到第二步的由来。
二、WOE与IV值的理解
可以参看WOE与IV指标的深入理解应用。
WOE的两种写法可以对应两种理解: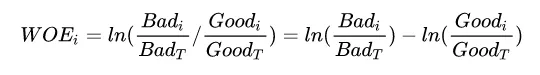
代表每个分箱里的坏人分布相对于好人分布之间的差异性;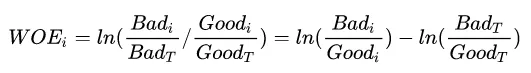
代表每个分箱里的坏好比(Odds)相对于总体的坏好比之间的差异性。
依然从朴素贝叶斯的角度来理解WOE,其中ln(BadT/GoodT)表示先验项,ln(Badi/Goodi)是后验项,WOE表示根据观测数据更新信息,这也是WOE叫作证据权重的原因,帮助修正先验知识的证据。
具体的推导过程如下: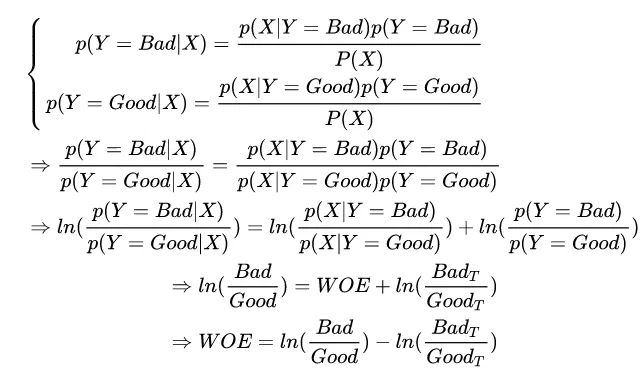
关于WOE可以思考两个问题:
1.WOE曲线越陡是否越好?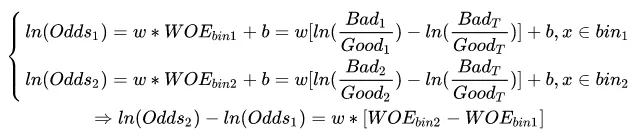
WOE曲线越陡,说明变量两箱之间的WOE差值越大。w是常数,因此两箱之间的ln(odds)之差也越大,相应的两箱之间的分差越大,也就是该变量的区分度很好。
2.WOE计算方法与逻辑回归系数一致性的关系?
先说结论:WOE用坏好比时,要求逻辑回归系数为正;WOE用好坏比时,逻辑回归系数为负。对逻辑回归系数正负性要求是为了保证坏账率与分数之间的单调性关系。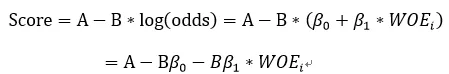
每个变量的分数为-BβWOE,当WOE用坏好比时,坏样本率越高,WOE值越大,而想要分数越低,需要保证β为正数;当WOE为好坏比时正好相反。
3.IV值为什么具有预测能力?
IV值的本质是K-L距离,衡量好人分布与坏人分布的差异,IV值越大说明好人分布与坏人分布的差异越大,因此IV值越大预测能力越强。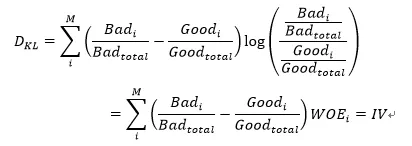
类似的PSI也是K-L距离,衡量的是预期分布与实际分布之间的差异,PSI越大说明实际分布与预期分布差异越大,变量越不稳定。具体内容可见相对熵与IV、PSI的关系
三、KS值的理解
KS的公式为max(累计坏样本比率-累计好样本比率),可以理解为好坏距离或区分度的上限。比如KS为30%,其含义是在误杀35%的好客户的情况下拦截住65%的坏客户。关于KS可以思考的问题如下:
1.KS越高说明模型越好吗?
不是,KS值的高低与建模样本中的坏样本浓占比相关,想提升KS的方法有很多,最直观的一个就是增大Y样本中的浓度,比如选取不同的Y,坏样本的浓度就会不一样。此外,KS的高低与策略的松紧有关,策略比较松,放进来的坏客户就较多,KS就会高。
2.在不同cutoff内取到max时,模型性能有什么差异?
假设KS值都为30%,也就是误杀35%的好客户的情况下拦截住65%的坏客户。不同的cutoff内取到max说明达到同样的拦截效果,通过率不同,通俗地说,一个可能在80%通过率的时候就达到拦截效果,而另一个在50%通过率才达到同样的效果。高通过率的说明模型低分段的浓度很高比低通过率时要高,即低分段的识别能力更强。
3.模型上线后的KS不断衰减的原因?
模型训练时的KS是基于全量通过样本的,上线后会切一刀,高于一定分数的样本才能进来,因此上线后的KS一般是会比训练时的KS低。此外,策略调整、客群变化都会导致KS的衰减。
关于评分卡中常用到的理论推导,大概就想到了这么多,理论终究是理论,还有很多东西需要在业务实践中去验证和领悟,继续坚持学习、积累、成长。

若有收获,就点个赞吧
0 人点赞
