practice_of_intelligent_risk_control-main.zip
一、模型开发中的样本粒度
有渠道粒度、客户粒度、借款粒度、还款粒度。在实际业务中需要根据业务模式和模型应用策略来选择合适的粒度进行建模。比如一次性借款产品,申请模型选择借款粒度;循环额度产品选择客户粒度;催收评分选择还款粒度。这个问题可以看下知乎求是汪在路上:贷中行为评分卡(B卡)模型的评论区。
二、标签定义
表现期定为近 6期是否发生30天以上逾期的情况下,对于超过6个月表现期且逾期发生在6个月之后的样本,也可以纳入建模样本中,属于“软表现窗口”。对于坏样本量较少的情况,可以选择不同的逾期状态,尽可能多覆盖坏样本。
三、特征选择中的稳定性
除了PSI之外,还要看各分箱坏账的稳定性。书中定义为“倒箱”,体现了特征对预测变量区分能力的稳定性,而PSI反映的是特征分布的稳定性。这个简单地说,就是分箱在分月的坏账不要交叉,开口越大越好。<br />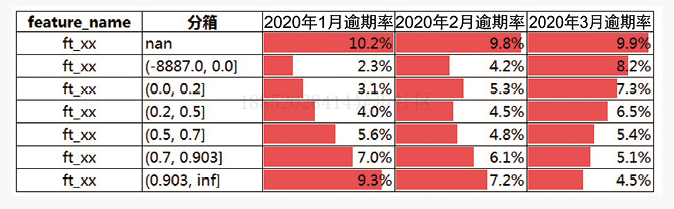
四、损失函数、代价函数和目标函数
损失函数:单个样本的误差
代价函数:所有样本误差的平均,所有损失函数的平均值
目标函数:在代价函数的基础上加了正则项,是最终需要优化的函数
五、模型融合方法
1、模型结果简单加权
2、模型结果再训练
3、集成学习:bagging和boosting,stacking和blending方法的原理图画得不错。
上面是有了不同的模型分之后怎么进行融合,此外还可以针对不同标签、不同样本、不同数据源来建立不同的子模型。<br />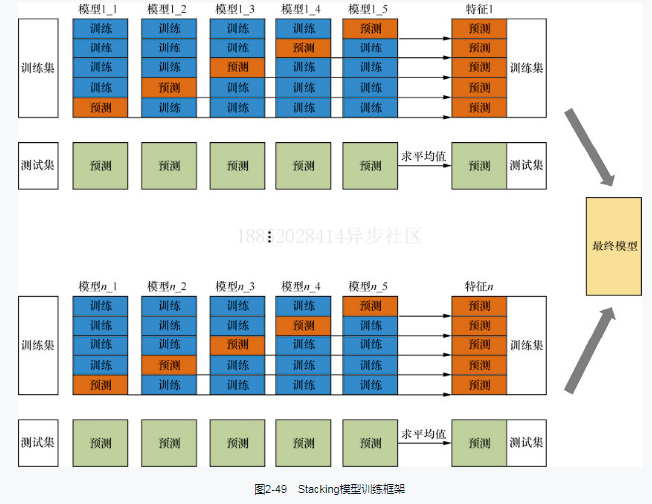
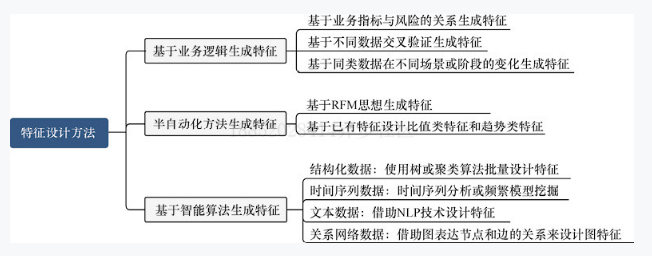
六、特征设计方法
基于业务逻辑生成特征、半自动化生成特征、基于智能算法生成特征,每一种都有代码和案例实践。
七、风控策略
规则评估里,有一部分对规则收益性进行评估,从利润最大化的角度,评估引入的规则是否能真正为业务带来利润。<br />规则上线,对于有强业务含义且评估后效果稳定的规则,直接全流量上线;对于有明确业务含义且评估中发现稳定性可能存在风险的规则,可通过分流测试进一步验证线上的实际效果;对于业务含义不明但评估效果较好的规则,可先线上陪跑,确认线上的实际效果后再全面应用。
八、交换集分析
对新模型通过旧模型拒绝的样本进行坏账预估,这里假设旧模型的样本在新模型打分时,同分数段坏账率一致,会存在低估换入客群坏账率的问题,需要做系数修正(有3种方法)。后面再详细写一篇笔记。<br />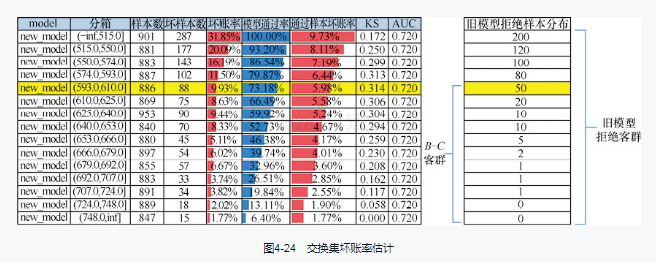
九、额度策略评估
金额坏账率与笔数坏账率的比值,叫作“金笔系数”。额度的A/B测试需要在平均额度不变的情况下,设计多种额度方案,从利润最大化的角度选择最优方案。
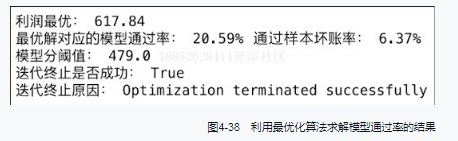
十、决策优化智能算法
风险策略在风险与收益之间做权衡,即寻找最优决策。最优化算法侧重单步收益最优化。用模型策略中决策点选择为例进行了介绍,后续再详细写一篇笔记实操下。额度策略中的最优额度选取可参考。
十一、因果关系
辛普森悖论的例子。机器学习模型从数据中学习的是相关关系。举例,模型训练发现借款人的申请额度越高,风险越高。申请额度高并不是客户风险高低的原因,而是结果。先识别出高风险的客户,给该类客户较低的额度,再给低风险的客户较高的授信额度,才能真正提高收益。<br />[<br />](https://blog.csdn.net/lc434699300/article/details/125921545)

若有收获,就点个赞吧
0 人点赞
