来源: https://blog.csdn.net/baidu_39413110/article/details/125208483
风控建模十一:利用外部数据联合建模时,如何选择样本
一、掺入验证样本
1.1 验证数据覆盖度、准确度
1.2 验证数据近期稳定性
二、分布尽量均匀
三、考虑样本偏差
四、针对数据覆盖范围选择样本
五、考虑特殊社会事件
所谓数字化风控,精细化运营,就是期望通过大数据的手段,尽可能丰富、全面地掌握客群的全貌画像,但现实状况中,数据孤岛问题一直都是制约金融科技发展的一大瓶颈。任何一家企业即便数据维度再丰富,也看不到客户的特征全貌。为了让业务中的模型能够尽可能维度丰富,尽可能贴近客户全貌特征,我们往往会通过外部数据联合建模的方式来解决内部数据单一、片面、区分度不高的问题。在大数据个人隐私保护日益趋严的趋势下,联合建模越来越多地采用联邦学习的方式,虽然安全,但也极大限制了我们对外部数据的理解与洞察。好在现在还有迂回的空间,驻场建模也是一种安全的方式,而且还能看到数据全貌,并定制化地进行特征加工。本篇文章就简单分享一下在能看到外部数据的情况下,应该如何选择建模的样本,关注哪些问题,才能让我们尽可能全面地了解外部数据并避免建模中的各种问题。
一、掺入验证样本
1.1 验证数据覆盖度、准确度
在我们对外部数据生态了解不深入的情况下,我们对外部数据反映哪些客群信息、反映的准不准都很难有一个确切的把握。除了与数据方人员深入沟通外,我们也可以通过掺入部分验证样本的方式来全面了解外部数据的获取机制、覆盖范围和准确性。比如,我们给样本的时候,可以把自己的信息加密后掺在里面,还可以在征得同意后,找一批同事的数据掺进去。自己和身边人的一些特征我们最清楚,刚好可以给数据来个反向验证。比如我们在测试一家企业的工作地址置信度的时候,把单位的地址填上去,看同事的数据情况,就能知道他这个置信度到底高不高。再比如,在测试一家企业的银行卡流水信息时,把自己的信息拿去匹配,拿自己的银行卡账单和数据相比对,就能确切地知道这家企业能获取到那些交易,这些交易一般都属于什么类型,大概能占到客户总交易笔数的百分之多少。
另外一个值得注意的是,我们给出去联合建模的样本都是信贷人群,信贷人群和大众人群还是有一些区别的。比如我们在测试一家交易数据的时候,发现这家数据在信贷客户样本上覆盖度高达90%,但在我们找的一批同事的测试样本上覆盖度只有30%。更奇怪的是,在信贷客户上面,我们发现没有被覆盖的这10%的人群风险表现明显要更好,且数据越丰富的客户,风险表现越差。后来我们通过深入了解发现,这家企业获取数据来源的很大一部分,来自于他们对多家信贷机构提供的代收代付服务,说明他们的数据覆盖的大多都是信贷人群,这就解释了为什么同事数据的覆盖度低,因为他们很少会去借纯信用贷款;这同时也解释了为什么数据覆盖越丰富的客户风险越差,因为数据越丰富,代表多头倾向越严重。正是有了这一小批同事样本的测试结果,才让我们更全面地了解了这家外部数据。如果没有这组样本的对比,我们可能就单纯地认为这家数据覆盖度就是能高达90%,也想不通为什么数据越丰富反而客户越坏。
1.2 验证数据近期稳定性
第二个问题就是数据稳定性的问题。我们选取的建模样本一般都是一段时间以前的申请客户样本,因为需要等待客户有充分的风险表现,而且所需的样本量越大,样本时间就越老,样本越老,就越面临着和当前样本不一致的风险。为了解决这个问题,我们可以在选择建模样本的时候,掺一批时间最近的申请样本,这样可以帮助我们验证模型在近期样本的稳定性,虽然这批样本没有风险表现,但可以通过看分布稳定性来帮我们筛选分布稳定的变量进行建模。这样做能够一定程度上保证模型在实际使用时,能够和建模时效果尽量一致。
二、分布尽量均匀
分布均匀,指的是在选取建模样本的时候,尽量在不同时间上、渠道上、产品上都能够有相同的坏账分布,这样一来可以掩盖自己企业坏账情况这样的敏感信息,二来也是避免建模出现问题。那分布不均匀会出现什么建模问题呢,我们看一个实际业务中碰到的状况。
两种情况会导致客户坏账率随时间不断降低:一是在定义坏样本的时候,不做固定时间窗口的限制;二是业务越来越收紧,这都会导致客户坏账率在时间上分布不均匀。如果我们选择建模样本的时候对这种情况不做处理,就有可能会有问题。比如一次联合建模,我们就在类似这样分布的样本进行了特征衍生和建模,后面发现,我们衍生的“最早交易日期距申请日天数”这一类变量,区分效果明显很好,比一些解释性更强,我们觉得应该更有区分度的变量还要好,这就引起了我们的怀疑。在通过更具体的分析后,我们发现这类变量有这样的分布特征,在该变量坏账率最高的第一箱(235-314天)中,其月份分布明显有偏,4,5月份的数据占比高过了60%;而在该变量坏账分布最低的最后一箱(682-842天)中,分布反之,7、8月份占比很大,也就是说,这个变量之所以区分度高,是因为它拟合了我们取样样本中坏账的时间分布状态,并不是特征本身的区分能力。这样的变量也只在我们选取的这部分样本上有这么高的区分度,应用在实际状况中一定会有大幅度的效果衰减。而这种状况是我们取样样本分布不均导致的,时间分布不均匀的样本状况导致了我们衍生的这一系列距今时长类变量都不能用。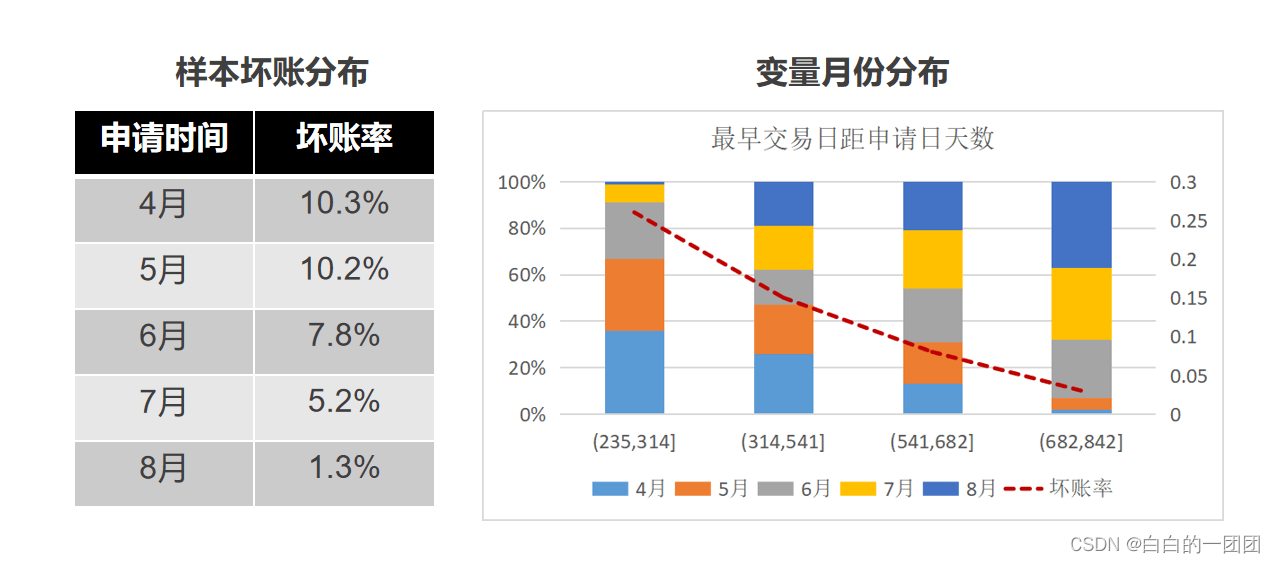
为了避免这种情况,我们在选取建模样本的时候就应该让坏样本尽量均匀地分布在每个月份上,同样的道理,在不同渠道、不同产品的样本上,也应该让坏样本尽量均匀分布,让其呈现出最随机的状态,这样就可以避免在做衍生变量的时候,一些变量错误地拟合了样本分布不均的状态,从而掩盖了其本质的区分能力。
三、考虑样本偏差
考虑样本偏差的问题,即拒绝推断的问题。关于这个问题,我们已经在博客风控建模七:拒绝推断中进行了比较详述的论断,这里我们举例再来说明一下这个问题。
我们选取的有风险表现的样本,相对于整个客群,其实都是有偏样本,其偏就偏在这部分有表现的样本都是经过了策略、模型层层筛选之后的样本,各种维度的变量分布和整体客群相比都有很大差异。比如一般多头类变量在整体客群上都会呈现出轻微的U型分布状态:当多头数为0时,我们称之为白户,一般风险表现要差一点,当多头数比较少的时候,呈现出的是一个用款客户的良性借贷状态,一般风险表现最好,后面随着多头数不断增加,客户的风险表现就会越来越差。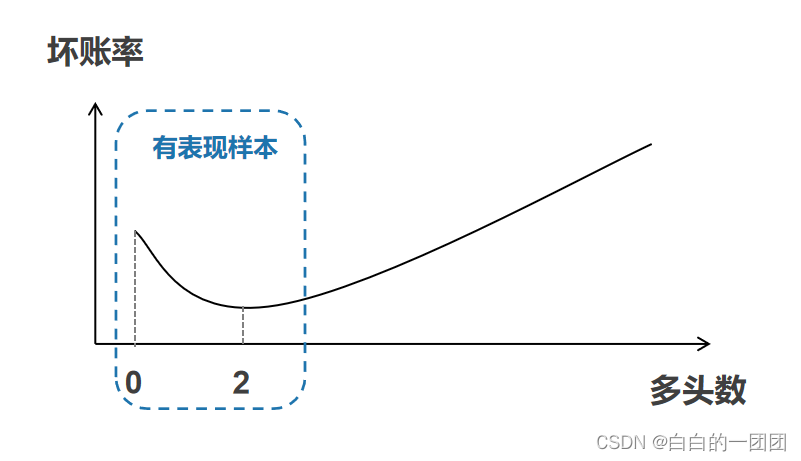
这种趋势不是我们主观臆断的,在我们联合建模的一些数据源中就能看出这种趋势,比如有家数据源的两个多头变量呈现的坏账趋势如下: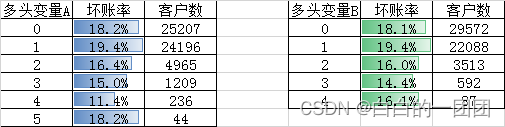
这种趋势就刚好契合我们上面所讲的,在策略筛选过的样本上,多头变量的U型的特征。
我们选取的用款客户,一般都是经过严格的多头指标筛选过的,比如可能所有用款客户,多头数没有超过5的。如果我们用这样一批样本建模,那模型拟合的结果就会认为,客户的多头数越多,风险就越好。如果我们做的这个模型是用来在决策引擎靠后的节点做补充决策的,那模型拟合的这个趋势就问题不大,因为它应用的场景已经不会出现多头过高的客户了。如果我们做的这个模型是用来做前置客群筛选的,那问题就大了,这个模型可能会让我们把所有多头数过高的客户都当成好客户筛选进来。因为我们用有风险表现的样本做模型相当于优中选优,而让这样的模型去做前置筛选,去面对整个良莠不齐的客群,就一定会出问题。
如果要用模型做前置筛选,应该如何避免这样的问题呢?可以在选择样本的时候掺一些拒绝样本,尤其是拒绝原因比较严重的拒绝样本进去,也当成坏样本进行建模。或者可以直接选取通过、拒绝样本做好、坏样本建模,都可以很大程度上避免样本偏差问题。
四、针对数据覆盖范围选择样本
每家数据服务商都存在数据覆盖度不全的问题,或者只覆盖部分客群,或者只覆盖部分维度,大多数据商二者兼有。因而,每家数据商只有在其主要覆盖的客群和维度上,才最具数据优势。我们选择样本进行联合建模就要有针对性地最大化这种优势。
举例来说,很多做SDK服务,或者手机功能嵌入服务(比如语音服务、推送服务)的数据商,其主要数据优势一般都只在安卓设备上。这里的数据优势就指数据维度丰富、准确性高。而在IOS设备上,大多没有数据,或数据稀疏。为了能最大发挥这些数据商的数据优势,比较好的办法就是只把数据应用在安卓人群上,因而选择建模样本的时候,可以针对性地只挑选安卓设备客户样本。如果我们不加选择地选择所有设备的样本,虽然样本看起来大而全了,但也只是徒增了样本的空值率而已。
另一个例子,就是一些地方性运营商数据,比如浙江移动,这时联合建模的样本选取就要从两个维度进行筛选,一是手机归属地为浙江,二是运营商选择移动;这样才能保证建模样本的高覆盖、不浪费。
虽然这样的样本选择方式只能解决部分问题,但现实情况就是每家数据商只能够提供解决部分问题的数据,所以外部数据联合建模是一个长期的过程,只能通过一点点地解决每个客群,每个维度的问题,才能最终形成一个比较完善的数字化解决方案。
五、考虑特殊社会事件
消费金融也是社会生产、发展的一个环节,自然逃脱不了突发性社会事件的冲击和影响,尤其是对于行业有直接影响社会性事件最值得我们关注,并结合这些情况,调整我们的业务逻辑和处理方式。
举一个较为久远的例子,19年对三方数据的突发整治,直接冲击了同盾等多家多头数据机构的数据服务,包括很多以爬虫为主要手段的三方数据商。虽然自事件以来,很多机构仍然正常提供数据服务,但我们从业务上可以直接监控到,很多数据商的数据分布出现了很大的突变,可以说事件前后像是两家完全不同的数据商。自此,我们选择建模样本也陡然增加了一条时间界线,事件以前的样本,多少都不能够代表新的环境,所以在选择样本时,我们也尽量不做选取。
第二个例子要说到22年初的上海疫情封城,这次疫情情况严重,时间长久,直接导致了很大一批人的工作停滞,收入断档。相应地,很多借贷客户就不得不出现了逾期的情况。虽然给很多客户做了延期和资产重组,但也只是局部地,暂时地延缓了问题。考虑到这种情况,我们在做建模样本选择的时候,就不得不针对性地对这段时间、上海地区的逾期客户做特殊考虑,因为这部分逾期客户是突发状况导致,并不能代表一般意义的坏客户。
当然,除了以上五点问题,其它一些细节问题也应该在样本选择的时候就尽可能地解决掉,比如以下几点:
1、样本省份分布,可以考虑去掉一些偏远省份的样本;
2、一些和总体客群有明显差异的渠道、产品上的样本,也应该尽可能地不选,以此来避免噪音信号形成的干扰;
3、逾期标签可以选择多种口径,比如长期信用逾期,短期欺诈逾期,多种标签可以多方面分析外部数据具体适用于哪种业务场景;
4、携带必要信息,比如渠道号、产品号,可以在建模时做分渠道、分产品分析和建模;
总之,选择建模样本绝不是简简单单地随便选,纷繁复杂的细节是需要特别注意的,总结来说就是要尽可能全面、详细地了解样本的情况、了解外部数据的情况,并真正做到具体情况,具体分析,以使联合建模时能够尽可能少地出现问题,尽可能大地发挥数据价值。
————————————————
版权声明:本文为CSDN博主「白白的一团团」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/baidu_39413110/article/details/125208483

若有收获,就点个赞吧
0 人点赞
