目录 · · · · · ·
第1章 智能风控的发展/ 1
1.1 早期的风控技术/ 1
1.1.1 基于人工经验的风控/ 1
1.1.2 传统统计量化的风控/ 2
1.2 初识智能风控/ 2
1.2.1 智能风控的定义/ 3
1.2.2 智能风控的发展/ 3
1.2.3 与传统风控对比/ 4
1.3 智能风控主要应用/ 5
1.3.1 应用于营销环节/ 6
1.3.2 应用于贷前环节/ 6
1.3.3 应用于贷中环节/ 7
1.3.4 应用于贷后环节/ 8
1.4 本章小结/ 9
第2章 搭建智能风控模型体系/ 10
2.1 模型概述/ 11
2.2 模型开发方法论——构建好样本/ 13
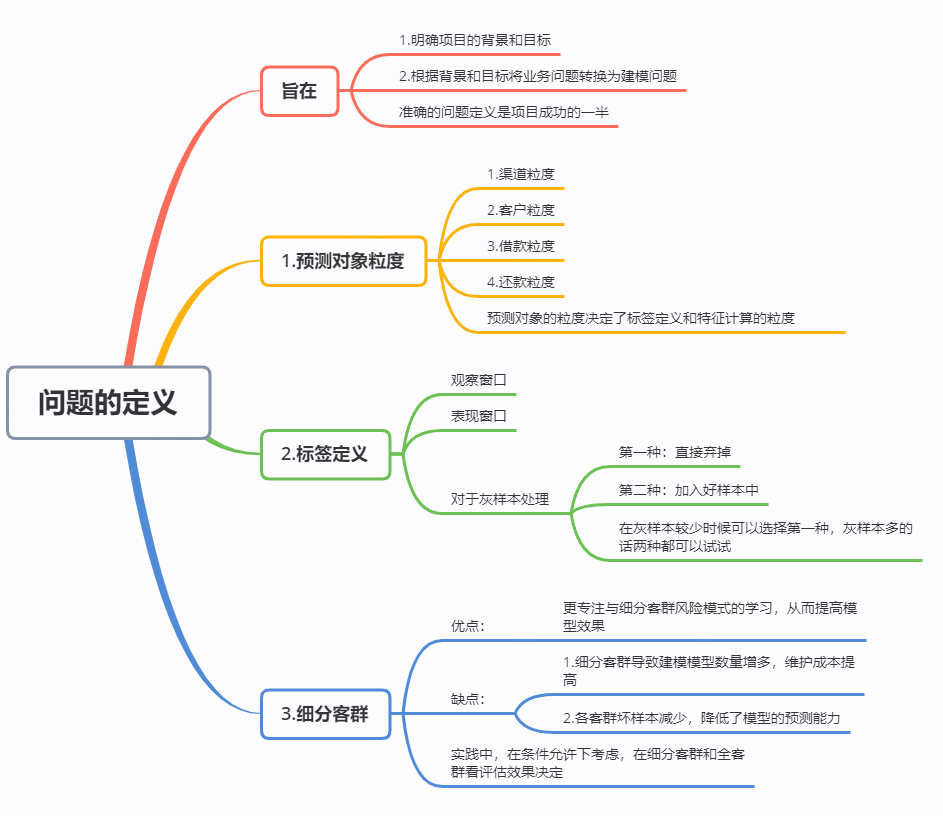
2.2.1 问题定义/ 14
2.2.2 样本的选择和划分/ 18
2.2.3 模型架构设计/ 20
2.2.4 数据准备和数据描述/ 21
2.2.5 数据预处理/ 24
2.3 模型开发方法论——构建好模型/ 33
2.3.1 特征选择/ 33
2.3.2 特征提取/ 44
2.3.3 模型训练、概率转化和效果评估/ 46
2.3.4 模型部署及上线验证/ 54
2.4 常用风控建模智能算法/ 56
2.4.1 基础学习算法/ 56
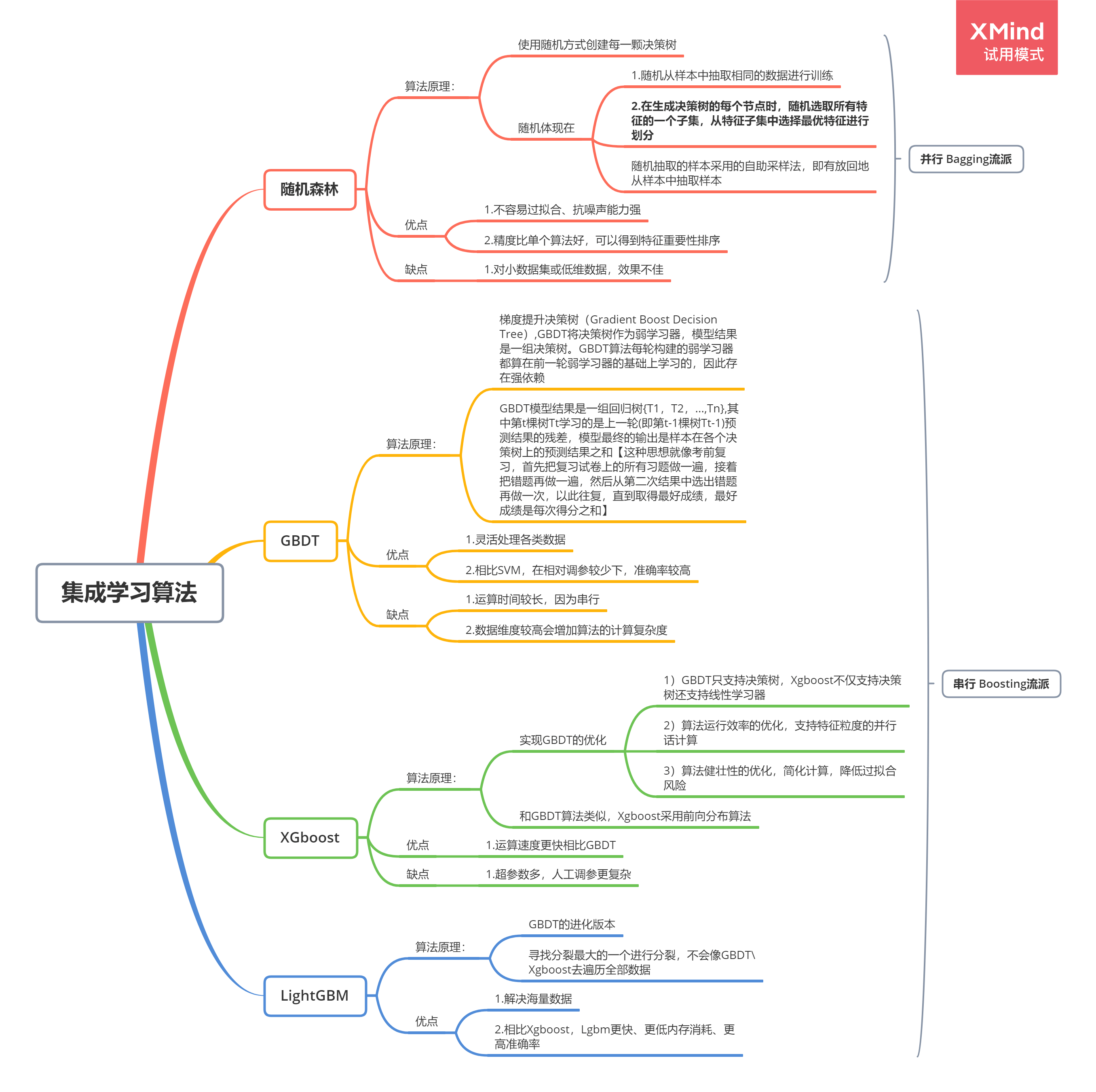
2.4.2 集成学习算法/ 65
2.4.3 深度学习算法/ 74
2.5 模型迭代优化/ 81
2.5.1 模型融合角度/ 82
2.5.2 建模时效角度/ 85
2.5.3 拒绝推断角度/ 86
2.6 风控模型体系搭建/ 92
2.6.1 营销阶段的模型/ 92
2.6.2 贷前阶段的模型/ 93
2.6.3 贷中阶段的模型/ 94
2.6.4 贷后阶段的模型/ 95
2.7 模型监控和异常处理/ 96
2.7.1 模型监控和预警/ 96
2.7.2 模型异常处理/ 100
2.8 本章小结/ 100
第3章 搭建风控特征画像体系/ 102
3.1 特征挖掘概述/ 102
3.2 特征挖掘方法论/ 103
3.2.1 原始数据分析/ 103
3.2.2 数据清洗/ 104
3.2.3 中间数据集构建/ 109
3.2.4 特征的设计和生成/ 115
3.2.5 特征评估/ 124
3.2.6 特征上下线/ 126
3.3 特征挖掘智能算法/ 127
3.3.1 特征衍生/ 127
3.3.2 文本特征挖掘/ 132
3.3.3 图特征挖掘/ 142
3.4 风控特征画像体系的搭建/ 148
3.4.1 营销特征画像/ 148
3.4.2 贷前特征画像/ 149
3.4.3 贷中特征画像/ 153
3.4.4 贷后特征画像/ 155
3.5 特征监控和特征异常处理/ 155
3.5.1 特征监控/ 155
3.5.2 特征异常处理/ 156
3.6 本章小结/ 157
第4章 搭建智能风控策略体系/ 158
4.1 风控策略概述/ 158
4.2 风控策略方法论/ 159
4.2.1 规则分析方法/ 159
4.2.2 模型策略分析方法/ 169
4.2.3 额度策略分析方法/ 178
4.2.4 A/B测试/ 183
4.3 风控策略智能算法/ 185
4.3.1 规则挖掘智能算法/ 185
4.3.2 决策优化智能算法/ 189
4.4 风控策略体系的搭建/ 195
4.4.1 营销策略/ 195
4.4.2 贷前策略/ 196
4.4.3 贷中策略/ 201
4.4.4 贷后策略/ 202
4.5 风控策略的监控、预警和异常处置/ 203
4.5.1 风控策略的监控与预警/ 203
4.5.2 风控策略异常处置/ 207
4.6 本章小结/ 208
第5章 智能风控与人工的结合/ 209
5.1 机器学习的局限性/ 209
5.1.1 数据不足/ 209
5.1.2 可解释性低/ 210
5.1.3 因果难区分/ 210
5.1.4 模型自身的风险/ 212
5.2 发挥人的价值/ 212
5.2.1 异常识别/ 212
5.2.2 案例研究/ 213
5.2.3 黑产对抗/ 213
5.3 决策方案的选择/ 214
5.3.1 完全智能决策/ 214
5.3.2 部分智能决策/ 215
5.4 本章小结/ 216
第6章 智能风控管理/ 217
6.1 建立持续复盘机制/ 217
6.2 制订风险预防和应对措施/ 218
6.3 制订存档管理措施/ 218
6.4 建立透明的沟通渠道/ 219
6.5 建立工作体系标准/ 220
6.6 应用团队协作工具/ 220
6.7 本章小结/ 222
参考文献/ 223
本书代码:
practice_of_intelligent_risk_control-master.zip
序言
在判断一个风控人员是否可靠,以及能否达到资深水平时,我首先观察两点:
1.他有没有经历过一个完整的经济周期,是否能在任何经济环境下都能通过行之有效的风控模型与策略持续、稳健地发展业务;
2.他是否关注风控体系的建立,而不是单纯地搭建风控模型or策略;
——叶梦舟 融360
第1章 智能风控的发展
1.3 智能风控主要应用
应用于营销、贷前、贷中、贷后环节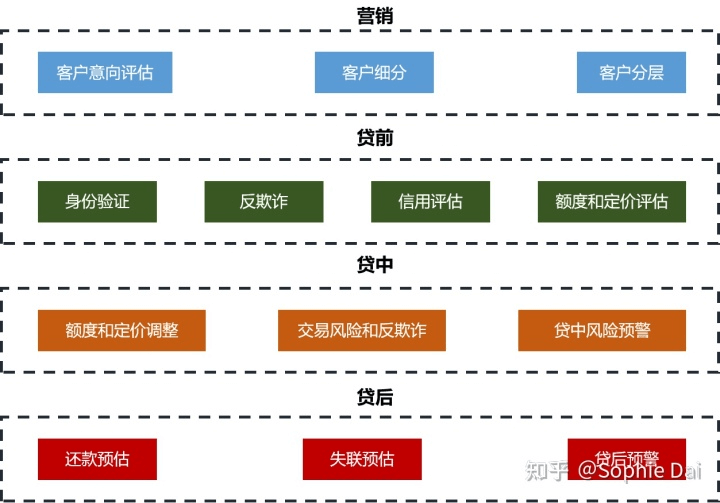
来源:https://www.zhihu.com/column/c_199236458
1.营销环节
营销,也就是获客。是信贷风控的第一个环节,营销环节决定了金融机构可以获得何种质量和偏好的客户。营销和风控的侧重点不同:营销是负责获取大量客户,风控端从获取到一大批客户中,筛选出好客户。当前被认可的广义的风控是从营销入口开始的,这使得营销和风控在更高层面可达成一致。营销的目标是获取符合期望的目标客户,而不仅仅是获得一定数量的客户。营销环节的智能风控主要应用包括:客户意向评估、客户细分和客户分层。
- 客户意愿评估:根据客户响应概率,可以分为高响应客户、中响应客户、和地响应客户。针对不同客户的响应级别,金融机构可以设置不同的营销策略,如高响应客户采取主动营销策略(如电话+短信营销),中响应客户采取次主动营销策略(如短信营销),对于低响应客户可暂时放弃,以降低营销成本。(预测模型,预测响应率:LR多变量回归预测、Xgboost、LGBM)
- 客群细分:在智能营销中,通过建立客户分群模型,可以将具有多个相似特征的客户划分到一个细分群体,进而分析细分客群的需求,提供相应的信贷产品。例如,在细分客户中,发现有车人群,可以设计针对车主的营销方案和定制产品。
- 客群分层:客群分层是指将潜在的信贷申请客户预先进行风险等级评定,从而在营销之前将一些高风险客户排除在外,为低风险客户提供更有吸引力的金融产品。在智能风控中,通过建立一系列客户筛选规则和预授信模型,对客户进行分层评估,从而有区别地进行营销。营销阶段的客群分层有利于降低整体客群的风险水平,提高转化率,降低营销成本。我们可以认为,客群分层是一种风控前置的方法。
2.贷前环节
贷前风控是一个在客户申请和放款之间对申请人进行风险评估的风控环节。智能风控通过收集大量数据,运用机器学习模型,预测客户的风险概率,自动评估信贷申请人的身份真实性、信用等级和风险等级,并给予相应的信用额度和定价。我们可以通过数据和技术消除信息不对称性,降低不确定性;通过自动化决策,降低成本,提高效率。贷前风控主要包括身份验证、反欺诈、信用评估、以及额度及定价评估。
- 身份验证:智能风控采用多种手段结合的方式进行身份验证,包括使用人脸识别,与官方人脸信息库比对,使用活体监测技术,判断操作人是否是真人操作,利用官方身份信息库,校验身份证等证件信息的准确性。
- 反欺诈:在智能风控中,我们已经通过身份认证技术解决了一部分身份欺诈问题,但是,还有更为隐蔽的欺诈方式,需要借助多元化的工具解决。例如:我们从关系网络数据、设备信息等多种高纬度数据中挖掘特征,构建一系列反欺诈规则和模型,提高欺诈案件识别库。
- 信用评估:信用评估是为了确认借款人的还款可信度等级(信用等级)。信用等级可以解构为两个维度:还款意愿和还款能力。还款意愿可以通过借款人的历史行为体现,如之前的借款是否按时偿还,还款能力可以从借款人的收入水平方面判断。在智能风控中,我们可以借助多维度大数据建立信用风险模型,对借款人的信用等级进行评估。这些数据维度包括中国人民银行征信数据、客户社交、司法、行为、搜索、电商、线上线下消费能力等,由于还款能力和还款意愿很难绝对区分,因此,通常将体现还款意愿或还款能力很难绝对区分,因此通常将体现还款意愿或者还款能力的各个维度特征综合作为模型的输入,通过模型学习,从历史有表现的数据中找到各个维度与信用等级的量化关系,从而进行综合信用等级评估。
- 额度和定价评估:信贷产品的关键要素包括授信额度、利率、期限。额度和定价的设计实际上比大多数人考虑的要复杂得多。这些要素需要参考市场上其他竞争对手、监管限制,并结合自身客群的还款能力和风险水平来确定。然而,当我们改变额度和定价时,会反过来影响客户的借款意愿、还款能力和还款意愿,从而影响产品转化、风险水平、最终影响盈利。在智能风控中,我们结合信用评估模型、还款能力预估模型、以及额度和定价对转化和风险的影响分析,综合确定额度和定价,并且采用大量A/B测试,采用最优方法需求合理的额度和定价策略。
3.贷中环节
贷中环节是指贷款申请成功到贷款结清阶段,一但客户逾期,就转入贷后环节(注意:其实这里风控部门和业务部门对于贷前、贷中和贷后的定义是有差异的。不同贷款类型和贷款品种对于贷前、贷中、贷后的起始和终止时间节点的换分也是不一样的,比如说:对于业务部门对贷后定义是:从信贷发放或其他信贷业务发生后直到本息收回或者信用结束的全过程。但是不影响各自工作开展,更多是主要风控部门和业务部门做好沟通)
- 额度和定价调整:在智能风控中,我们一般通过贷中风控模型对客户的信用等级进行重新评估,当客户信用等级比以前高(即信用更好)时,则给予更高的额度和更优惠的定价。金融机构可以主动、定期地运行贷中风险模型,对客户进行信用等级评估,从而给出更合理的产品方案,这将有利于留存客户,提高客户价值。
- 交易风险和反欺诈:在智能风控中,我们通过关联各类数据,寻找新出现的欺诈模式,运用机器学习、深度学习、图谱学习等技术,构建贷中反欺诈规则和模型,对风险进行拦截。
- 贷中风险预警:在客户借款之后,就可以通过客户的贷中行为对客户是否会入催进行预测,从而提前知道哪些客户有可能逾期。对于高风险客户,提前介入催收,往往取得良好的效果,因为信贷借款人往往存在从多个金融机构借款的情况,而当客户还款资金有限时,更早接入的金融机构更有可能收回贷款。在智能风控中,我们可以构建贷后风险预估模型和贷中逾期识别规则,提前预判入催可能性高的客户,并采取有效措施以降低借款人入催的比例,从而降低贷款逾期率,减少损失。
4.贷后环节
贷后是指借款客户逾期至催回的完整阶段。贷后管理的精细程度对客户的还款质量有相当大影响。利用机器学习、处理贷中和贷后行为数据,以及多维度内外部大大数据,可以精准预估逾期客户的早期还款概率、晚期还款概率、和失联还款概率等,从而对不同风险等级的客户采取不同的催收策略。贷后风险控制主要包括还款预估和失联预估。
- 还款预估:还款预估是指在借款人已经逾期的情况下,预测借款人还款的概率。针对不同的还款概率的客户,采用不同的催收方式,提高还款可能性。按照逾期时间的长短,还款预估可以分为早期还款预估和晚期还款预估。早期逾期的客户很可能是由于遗忘或者不方便还款而导致逾期,通过短信提醒等轻度催收方式即可回款。从策略上讲,我们应该将催收的重点放在还款概率低的客户上。晚期逾期的客户则相反,我们应该关注其中还款可能性高的客户,对于还款可能性低的客户,可以暂时有选择性地进行放弃,或者委托第三方机构进行催收。在智能风控中,我们可以建立各个阶段的催收模型,预估还款概率。我们通常可以将3类数据作为模型的输入:第一类是客户的个人基本信息,包括年龄、性别、学历、职业、主要收入、家庭情况和住房情况等等;第二类数据是信用历史数据,包括信用历史时间、逾期频率和严重性,以及内外部信用评分;第三类信息是催收信息记录,包括催收时间、催收通话时长、催收反馈等。
- 失联预估:在催收的后期,经常出现无法联系到借款人的情况,失联对催收会产生非常大的阻碍,尽早了解客户的是否失联对催收的价值很大,金融机构可以对失联概率高的客户进行尽早委外催收,或者尽早收集更多的联系人信息。在智能风控中,我们可以通过建立失联预估模型,利用金融机构内部的客户信息、交易信息和催收信息,逾期客户失联的可能性,从而有针对性地采取预防措施。
第2章 搭建智能风控模型体系
2.1 模型概述
在信贷风控建模领域,不论我们在建模中才有了何种算法,其整体流程步骤是类似的,如下图所示:一般包括问题定义、样本的选择与划分、模型框架设计、数据准备与描述分析、数据清洗、特征选择、模型训练与效果评估、部署上线、模型监控、模型调优。
简单也可分为三阶段:模型立项分析、模型训练与开发、和模型上线与维护。 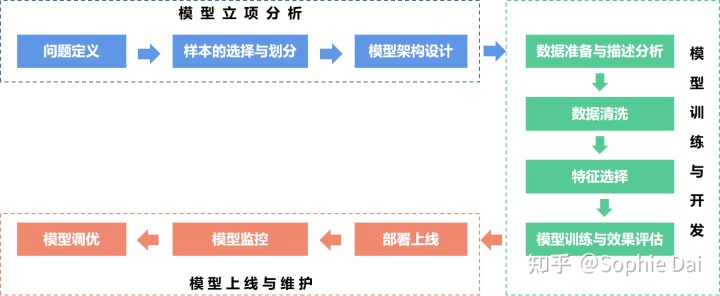
作者:Sophie Dai
链接:https://zhuanlan.zhihu.com/p/585745071
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2.3 模型开发方法论——构建好模型
风控领域特征选择方法分类: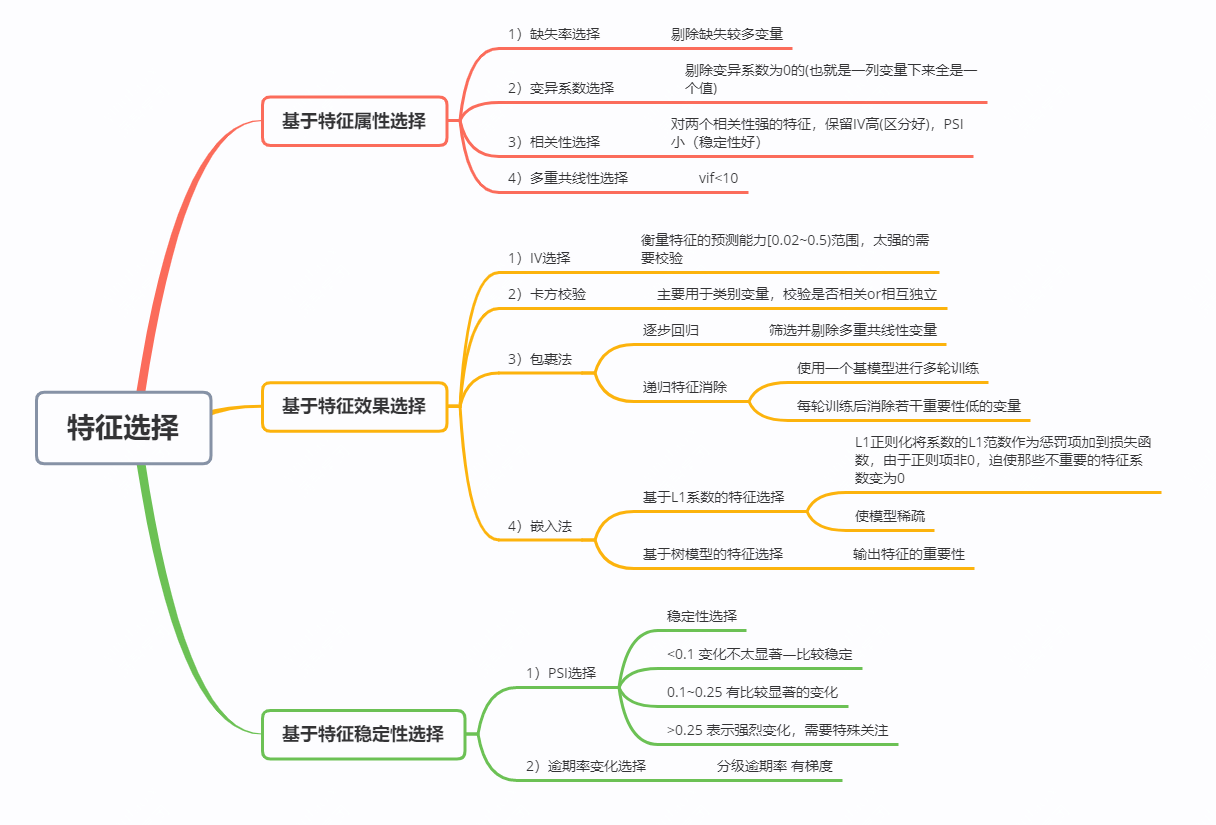
2.4 常用风控建模智能算法
2.6 风控模型体系搭建
2.6.1 营销阶段的模型
营销响应模型:预测客户响应的概率;基本信息+行为数据+外部
流量筛选模型:前筛模型,用来识别资质较差的客群;三要素+流量方提供的客户行为数据+外部
2.6.2 贷前阶段模型
反欺诈模型:识别欺诈风险高的客户;客户填写资料停留时长+设备特征+关系网络等
信用风险模型:评估预测其未来逾期的概率,申请评分卡,A卡
2.6.3 贷中阶段模型
贷中行为模型:贷中行为即行为评分卡,B卡
交易风险模型:用于拦截高风险交易,及时止损
2.6.4 贷后阶段模型
还款预估模型:催收评分卡,C卡,预测已逾期的客户在未来一段时间的还款概率的模型;催收
失联预估模型:预测用户失联的可能性
第3章 搭建风控特征画像体系
*第4章 搭建智能风控策略体系
4.1 风控策略概述
风控策略是指,根据不同业务场景和客群,通过一系列规则策略与模型策略的组合,对客户的风险进行判断,从而实现准入、反欺诈、授信、风险定价和催收等阶段目标,最终达到风险控制的目的。
风控策略的核心目标是将风险控制在合适的范围。
在遵守监管政策和满足客户利益的前提下,实现收益的最大化。
有效的风控策略是在保证业务稳步发展的前提下,寻求风险和收益的平衡。
利润=息费收入-运营成本-坏账损失
4.2 风控策略方法论
4.2.1规则分析方法
1.制订人工规则
1)寻找风险点
- 市场调研:撸贷、骗贷
- 信贷人员和催收人员反馈
- 关联图谱识别
- 黑产分析
- 实时数据监控
2.制订量化规则
*1)单规则制订-IV分析法:
# -*- coding: utf-8 -*-import syssys.path.append('..')sys.path.append('..')# ImportError: cannot import name 'data_utils' from 'utils' (C:\ProgramData\Anaconda3\lib\site-packages\utils\__init__.py)# 实在不行就把 utils 的函数py文件放到默认目录下面去# print(sys.path)import toadimport numpy as npimport pandas as pdfrom utils import data_utilsfrom toad.plot import bin_plotfrom matplotlib import pyplot as pltdef cal_iv(x, y):"""IV计算函数:param x: feature:param y: label:return:"""crtab = pd.crosstab(x, y, margins=True)crtab.columns = ['good', 'bad', 'total']crtab['factor_per'] = crtab['total'] / len(y)crtab['bad_per'] = crtab['bad'] / crtab['total']crtab['p'] = crtab['bad'] / crtab.loc['All', 'bad']crtab['q'] = crtab['good'] / crtab.loc['All', 'good']crtab['woe'] = np.log(crtab['p'] / crtab['q'])crtab2 = crtab[abs(crtab.woe) != np.inf]crtab['IV'] = sum((crtab2['p'] - crtab2['q']) * np.log(crtab2['p'] / crtab2['q']))crtab.reset_index(inplace=True)crtab['varname'] = crtab.columns[0]crtab.rename(columns={crtab.columns[0]: 'var_level'}, inplace=True)crtab.var_level = crtab.var_level.apply(str)return crtabgerman_credit_data = data_utils.get_data()# 生成分箱初始化对象bin_transformer = toad.transform.Combiner()# 采用等距分箱训练bin_transformer.fit(german_credit_data,y='creditability',n_bins=6,method='step',empty_separate=True)# 分箱数据trans_data = bin_transformer.transform(german_credit_data, labels=True)# 查看Credit amount分箱结果bin_plot(trans_data, x='credit.amount', target='creditability')plt.show()# 查看Credit amount分箱数据cal_iv(trans_data['credit.amount'], trans_data['creditability'])# 构建单规则german_credit_data['credit.amount.rule'] = np.where(german_credit_data['credit.amount'] > 12366.0, 1, 0)
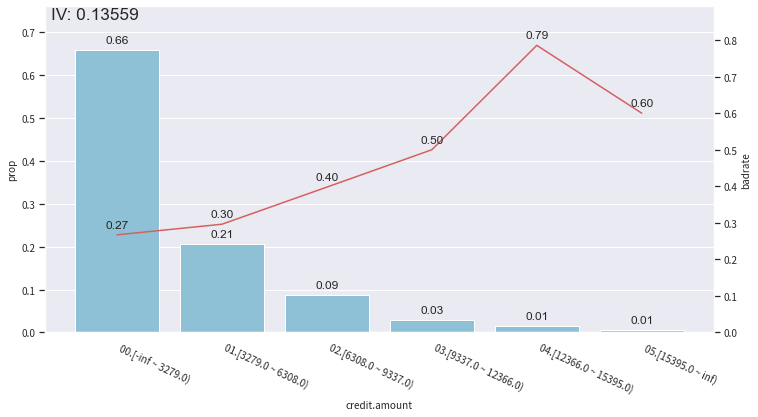
后两个箱体的逾期率明显高于前面的
2)极端值监测:
# -*- coding: utf-8 -*-import syssys.path.append("./")sys.path.append("../")import pandas as pdfrom utils import data_utilsdef rule_evaluate(selected_df, total_df, target, rate=0.15, amount=10000):""":param selected_df: 子特征列表:param total_df: 特征宽表:param target: 目标变量:param rate: 息费(%):param amount: 平均每笔借款金额:return:"""# 命中规则的子群体指标统计hit_size = selected_df.shape[0]hit_bad_size = selected_df[target].sum()hit_bad_rate = selected_df[target].mean()# 总体指标统计total_size = total_df.shape[0]total_bad_size = total_df[target].sum()total_bad_rate = total_df[target].mean()# 命中率hit_rate = hit_size / total_size# 提升度lift = hit_bad_rate / total_bad_rate# 收益profit = hit_bad_size * amount - (hit_size - hit_bad_size) * rate * amountres = [total_size, total_bad_size, total_bad_rate,hit_rate, hit_size, hit_bad_size, hit_bad_rate, lift, profit]return resdef rule_discover(data_df, var, target, rule_term, rate=0.15, amount=10000):""":param data_df: 特征宽表:param var: 特征名称:param target: 目标变量:param rule_term: 分位数列表或规则条件:param rate: 息费(%):param amount: 平均每笔借款金额:return:"""res_list = []if rule_term is None:rule_term = [0.005, 0.01, 0.02, 0.05, 0.95, 0.98, 0.99, 0.995]if isinstance(rule_term, list):for q in rule_term:threshold = data_df[var].quantile(q).round(2)if q < 0.5:temp = data_df.query("`{0}` <= @threshold".format(var))rule = "<= {0}".format(threshold)else:temp = data_df.query("`{0}` >= @threshold".format(var))rule = ">= {0}".format(threshold)res = rule_evaluate(temp, data_df, target, rate, amount)res_list.append([var, rule] + res)else:temp = data_df.query("`{0}` {1}".format(var, rule_term))rule = rule_termres = rule_evaluate(temp, data_df, target, rate, amount)res_list.append([var, rule] + res)columns = ['var', 'rule', 'total_size', 'total_bad_size', 'total_bad_rate','hit_rate', 'hit_size', 'hit_bad_size', 'hit_bad_rate', 'lift','profit']result_df = pd.DataFrame(res_list, columns=columns)return result_dfif __name__ == '__main__':# 数据读入german_credit_data = data_utils.get_data()german_credit_data.loc[german_credit_data.sample(frac=0.2, random_state=0).index, 'sample_set'] = 'Train'german_credit_data['sample_set'].fillna('OOT', inplace=True)# 使用分位数列表构建规则集rule_table = rule_discover(data_df=german_credit_data, var='credit.amount',target='creditability',rule_term=[0.005, 0.01, 0.02, 0.05, 0.95, 0.98, 0.99, 0.995])print(rule_table)# 规则效果评估rule_analyze = german_credit_data.groupby('sample_set').apply(lambda x: rule_discover(data_df=x, var='credit.amount',target='creditability', rule_term='>12366.0'))print(rule_analyze)
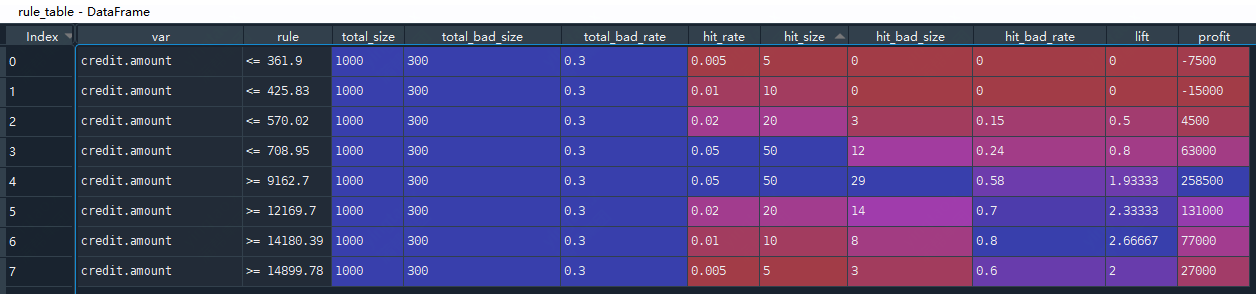

*3)规则的收益性评估

4.2.2模型策略分析方法
样本选取>>模型策略的制订>>模型策略评估>>模型策略的上线与验证>>模型策略回顾
1.单模型策略
1)基于模型的通过率和坏账率的决策点设定
2)基于lift的决策点制定
2.多模型组合策略
基于两个or两个以上模型分组合生成的模型应用方案。多模型组合策略的优势
①能够发挥多个模型性能进行互补
②内外部模型的组合能够有效降低数据成本
1)多模型融合准入(融合模型分)
2)多模型串行准入
3)多模型交叉准入
利用交叉生成的模型风险等级矩阵更能体现多模型优势,风险划分等级也更细,但要保证金每个格子的样本量有统计意义
3.模型策略评估
*1)交换集分析(swap set analysis)
预测:被新模型通过,老模型拒绝的坏账率
>>通过换入换出分析,得到新策略坏账率更低(在相同通过率下)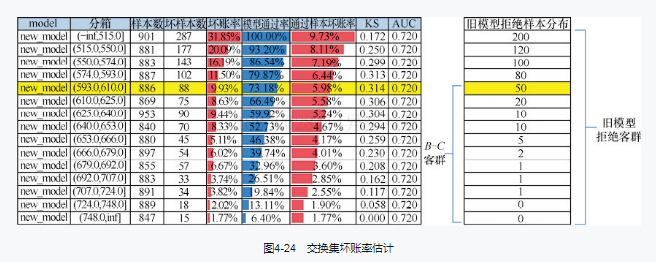
*2)拒绝推断
新模型优于旧模型的本质在于换入用户风险更好,换出用户风险更高
这里的拒绝推断就是把旧模型拒绝,被新模型通过的用户进行推断:
直接方式是利用新模型各分段有表现的坏账率来预估这部分被旧模型拒绝的用户坏账率
(注意:这里存在一个低估换入客群坏账率的问题,因为此时坏账率是在旧模型通过的条件下得到的坏账率,通常会乘以一个换入客群坏账率系数修正)
可以结合以下三种方式进行推断:
- Universe Test推断:设置一小部分拒绝推断的客户通过,获取较为准确的坏账率
- A/Btest组推断:两个组设置新旧策略执行
- 线性拟合推断:旧模型在线上决策的cut-off为478,则通过478以上分箱的客群的坏账率去建立一个多项式的线性回归模型,通过多项式线性回归模型去预测低于478的客群坏账率
4.2.3额度策略分析方法
额度策略的制订>>额度策略评估>>额度策略的上线与验证>>额度策略回顾
差异化额度策略可以在保持间均不变下,降低贷后金额损失率;或者,在贷后笔数损失率不变下,提升间均额度,从而提升收益
1.额度策略的制订
1)单一额度策略
业务开展初期,对首贷客户设置相同额度,随着贷款次数增加而提升额度
2)单因子额度策略
根据用户风险等级给额度
3)多因子额度策略
根据收入&风险等级给额度
2.额度策略评估
金笔系数:金额坏账率/笔数坏账率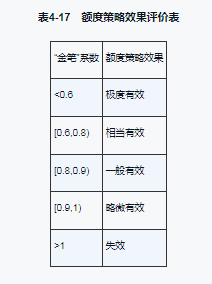
4.3 风控策略智能算法
4.3.1 规则挖掘智能算法
1.决策树
# -*- coding: utf-8 -*-import syssys.path.append("./")sys.path.append("../")import sklearn.tree as stimport graphvizfrom utils import data_utilsdef decision_tree_resolve(train_x, train_y, class_names=None, max_depth=3, fig_path=''):"""基于决策树可视化:param train_x: data of train:param train_y: data of y:param class_names: 标签名称:param max_depth: 树最大深度:param fig_path: 图片路径和名称:return:"""if class_names is None:class_names = ['good', 'bad']clf = st.DecisionTreeClassifier(max_depth=max_depth,min_samples_leaf=0.01,min_samples_split=0.01,criterion='gini',splitter='best',max_features=None)clf = clf.fit(train_x, train_y)# 比例图dot_data = st.export_graphviz(clf, out_file=None,feature_names=train_x.columns.tolist(),class_names=class_names,filled=True,rounded=True,node_ids=True,special_characters=True,proportion=True,leaves_parallel=True)graph = graphviz.Source(dot_data, filename=fig_path)return graph# 加载数据german_credit_data = data_utils.get_data()# 构造数据集X = german_credit_data[data_utils.numeric_cols].copy()y = german_credit_data['creditability']graph = decision_tree_resolve(X, y, fig_path='data/tree')graph.view()# 转化为规则X['node_5'] = X.apply(lambda x: 1 if x['duration.in.month'] <= 34.5 and x['credit.amount'] > 8630.5 else 0, axis=1)X['node_9'] = X.apply(lambda x: 1 if x['duration.in.month'] > 34.5 and x['age.in.years'] <= 29.5 and x['credit.amount'] > 4100.0 else 0,axis=1)X['node_12'] = X.apply(lambda x: 1 if x['duration.in.month'] > 34.5 and x['age.in.years'] > 56.5 else 0, axis=1)
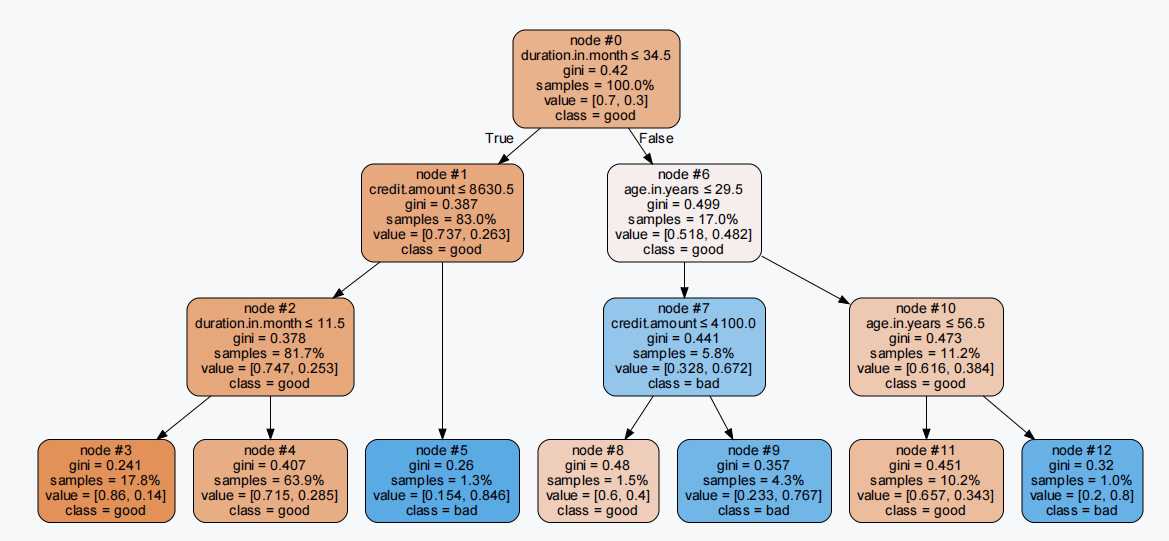
2.基于异常点监测
# -*- coding: utf-8 -*-import syssys.path.append("./")sys.path.append("../")import numpy as npfrom chapter4.ch4_01_rules_for_outliers import rule_discoverfrom pyod.models.iforest import IForestfrom utils import data_utils# 加载数据german_credit_data = data_utils.get_data()# 构造数据集X = german_credit_data[data_utils.numeric_cols]y = german_credit_data['creditability']# 初始化模型clf = IForest(behaviour='new', bootstrap=False, contamination=0.1, max_features=1.0, max_samples='auto', n_estimators=500, random_state=20, verbose=0)# 训练模型clf.fit(X)# 预测结果german_credit_data['out_pred'] = clf.predict_proba(X)[:, 1]# 将预测概率大于0.7以上的设为异常值german_credit_data['iforest_rule'] = np.where(german_credit_data['out_pred'] > 0.7, 1, 0)# 效果评估rule_iforest = rule_discover(data_df=german_credit_data, var='iforest_rule', target='creditability', rule_term='==1')print("孤立森林评估结果: \n", rule_iforest.T)
4.3.2 决策优化智能算法
1.最优化算法
# -*- coding: utf-8 -*-import syssys.path.append("./")sys.path.append("../")import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom numpy import polyfit, poly1dfrom sklearn.metrics import r2_scorefrom scipy.optimize import minimizedef calculate_pass_loss_decile(score_series, y_series):"""模型分取值变化时通过率与坏账率关系:param score_series: 模型分:param y_series: Y标签:return:"""decile_df = pd.crosstab(score_series, y_series).rename(columns={0: 'N_nonEvent', 1: 'N_Event'})decile_df.loc[:, 'N_sample'] = score_series.value_counts()decile_df.loc[:, 'EventRate'] = decile_df.N_Event * 1.0 / decile_df.N_sampledecile_df.loc[:, 'BadPct'] = decile_df.N_Event * 1.0 / sum(decile_df.N_Event)decile_df.loc[:, 'GoodPct'] = decile_df.N_nonEvent * 1.0 / sum(decile_df.N_nonEvent)decile_df.loc[:, 'CumBadPct'] = decile_df.BadPct.cumsum()decile_df.loc[:, 'CumGoodPct'] = decile_df.GoodPct.cumsum()decile_df = decile_df.sort_index(ascending=False)decile_df.loc[:, 'ApprovalRate'] = decile_df.N_sample.cumsum() / decile_df.N_sample.sum()decile_df.loc[:, 'ApprovedEventRate'] = decile_df.N_Event.cumsum() / decile_df.N_sample.cumsum()decile_df = decile_df.sort_index(ascending=True)return decile_dfdef poly_regression(x_series, y_series, degree, plot=True):"""多项式回归拟合:param x_series: x数据:param y_series: y数据:param degree: 指定多项式次数:param plot: 是否作图:return:"""coeff = polyfit(x_series, y_series, degree)f = poly1d(coeff)R2 = r2_score(y_series.values, f(x_series))print(f'coef:{coeff},R2: {R2}')if plot:# 用来正常显示中文标签plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = Falseplt.figure(figsize=(10, 5))plt.plot(x_series, y_series, 'rx')plt.plot(x_series, f(x_series))plt.xlabel('通过率', {'size': 15})plt.ylabel('坏账率', {'size': 15})plt.show()return coeffgerman_score = pd.read_csv('data/german_score.csv')german_score.head()decile_df = calculate_pass_loss_decile(german_score['score'],german_score['creditability'])print(decile_df.head())# 数据准备x = decile_df['ApprovalRate']# 逾期率折算为坏账率y = decile_df['ApprovedEventRate'] / 2.5poly_coef = poly_regression(x, y, 2, plot=True)# 坏账率L(x)与通过率x的关系l_x = poly1d(poly_coef)print(l_x)def find_best_approval_rate(x_to_loss_func, score_df):"""定义最优化函数坏账率L(x)与通过率x的关系函数:param x_to_loss_func: 坏账率与通过率的函数关系:param score_df: 模型分与通过率的对应关系,index为模型分,"ApprovalRate"列为对应的通过率:return:"""# 定义目标函数,求解最大值即为负的最小值def fun(x_array):# 其中x_list[0]为通过率x,x_array[1]为对应的坏账率L(x)return -10000 * (0.16 * (1 - x_array[1]) - x_array[1]- 30 / (x_array[0] * 0.6) / 10000)# eq表示 函数结果等于0 ; ineq 表示 表达式大于等于0, 下面式子1e-6项确保相应变量不等于0或1cons = ({'type': 'eq', 'fun': lambda x_array: x_to_loss_func(x_array[0]) - x_array[1]},{'type': 'ineq', 'fun': lambda x_array: x_array[0] - 1e-6},{'type': 'ineq', 'fun': lambda x_array: x_array[1] - 1e-6},{'type': 'ineq', 'fun': lambda x_array: 1 - x_array[0] - 1e-6},{'type': 'ineq', 'fun': lambda x_array: 1 - x_array[0] - 1e-6})# 设置初始值x_base = np.array((0.10, 0.10))# 采用SLSQP进行最优化求解res = minimize(fun, x_base, method='SLSQP', constraints=cons)print('利润最优:', "{:.2f}".format(-res.fun))print('最优解对应通过率:', "{:.2%}".format(res.x[0]), '坏账率:', "{:.2%}".format(res.x[1]))print("模型分阈值:", score_df[score_df['ApprovalRate'] >= res.x[0]].index.max())print('迭代终止是否成功:', res.success)print('迭代终止原因:', res.message)find_best_approval_rate(l_x, decile_df)
计算通过率&坏账率 达到的最优利润
4.5.2 风控策略异常处置
1.转化异常值处置
- 统计问题
- 产品异常
- 规则策略问题
- 模型策略问题
- 数据问题
- 客群变化
2.贷后逾期异常处置
第6章 智能风控管理

若有收获,就点个赞吧
1 人点赞
