炼丹笔记干货
作者:九羽
在互联网行业,无论是构建搜索推荐系统,还是智能营销等场景,都是围绕用户进行不同的实验,从各项指标上观察用户对不同交互、流程、策略、算法等反馈,进而对产品、营销策略、搜索推荐算法等进行迭代改进。
在之前的文章《流量为王:收益最大化的混排机制》探讨了如何在原始的运营流量或者推荐流量中,增加广告流量、带货流量后,将不同内容类型如何呈现给不同的用户,同时根据不同的业务不同的目标导向,兼顾各方需求的混排机制,在流量为王的时代,对于实现流量的价值转化。
在本篇文章中,主要讨论在进行了模型的线下迭代并且有了提升之后,怎么线上进行实验,怎么决定对哪些用户进行新策略、算法A的尝试,对哪些用户保持原有算法B进行对照。
什么是ABTest?

ABTest的概念来源于生物医学的双盲测试,双盲测试中病人被随机分成两组,在不知情的情况下分别给予安慰剂和测试用药,经过一段时间的实验后再来比较这两组病人的表现是否具有显著的差异,从而决定测试用药是否有效?
ABTest强调的是同一时间维度对相似属性分组用户的测试,时间的统一性有效的规避了因为时间、季节等因素带来的影响;而属性的相似性则使得地域、性别、年龄等等其他因素对效果统计的影响降至最低。
所有AB测试实验的奠基石是Goolge在KDD2010发表的论文《Overlapping Experiment Infrastructure More, Better, Faster Experimentation》,千禧年Google的工程师第一次将AB测试用于测试搜索结果页展示多少搜索结果更合适,虽然那次的AB测试因为搜索结果加载速度的问题失败了,但是这次的AB测试可以认为是Google的第一次AB测试。
怎么做ABTest?
目前业界应用最多的,是可重叠分层分桶方法。具体来说,就是将流量分成可重叠的多个层或桶。因为很多类实验从修改的实验参数到观察的产品指标都是不相关的,完全可以将实验分成互相独立的多个层。例如推荐算法召回层、推荐算法排序层、打散层,或者首页、业务页、详情页等。
**
模型分发(Model Distribution)
模型分发的目标是把在线流量分配给不同的实验模型,具体而言要实现三个功能:
- 为模型迭代提供在线流量,负责线上效果收集、验证等。
- A/B测试,确保不同模型之间流量的稳定、独立和互斥、确保效果归属唯一。
- 确保与其他层的实验流量的正交性。
流量的定义是模型分发的一个基础问题。如何让一个流量稳定地映射到特定模型上面,流量之间是否有级别呢,这些是模型分发需要重点解决的问题,这部分在后续进行深入的讲解。
流量分桶原理
采用如下步骤将流量分配到具体模型上面去:
- 把所有流量分成N个桶。
- 每个具体的流量Hash到某个桶里面去。
- 给每个模型一定的配额,也就是每个策略模型占据对应比例的流量桶。
- 所有策略模型流量配额总和为100%。
- 当流量和模型落到同一个桶的时候,该模型拥有该流量。

举个栗子来说,所有流量分为32个桶,A、B、C三个模型分别拥有37.5%、25%和37.5%的配额。对应的,A、B、C应该占据12、8和12个桶。为了确保模型和流量的正交性,模型和流量的Hash Key采用不同的前缀。
流量分级
每个团队的模型分级策略并不相同,这里只给出一个建议模型流量分级:
- 基线流量。本流量用于与其他流量进行对比,以确定新模型的效果是否高于基准线,低于基准线的模型要快速下线。另外,主力流量相对基线流量的效果提升也是衡量算法团队贡献的重要指标。
- 主力流量。主力流量只有一个,即稳定运行效果最好的流量。如果某个潜力流量长期好于其他潜力流量和主力流量,就可以考虑把这个潜力流量升级为主力流量。
- 实验流量。该流量主要用于新实验模型。该流量大小设计要注意两点:第一不能太大而伤害线上效果;第二不能太小,流量太小会导致方差太大,不利于做正确的效果判断。
- 潜力流量。如果实验流量在一定周期内效果比较好,可以升级到潜力流量。潜力流量主要是要解决实验流量方差大带来的问题。
做实验的过程中,需要避免新实验流量对老模型流量的冲击。流量群体对于新模型会有一定的适应期,而适应期相对于稳定期的效果一般会差一点。如果因为新实验的上线而导致整个流量群体的模型都更改了,从统计学的角度讲,模型之间的对比关系没有变化。但这可能会影响整个大盘的效果,成本很高。
为了解决这个问题,流量分桶模型优先为模型列表前面的模型分配流量,实验模型尽量放在列表尾端。这样实验模型的频繁上下线不影响主力和潜力流量的用户群体。当然当发生模型流量升级的时候,很多流量用户的服务模型都会更改。这种情况并不是问题,因为一方面我们在尝试让更多用户使用更好的模型,另一方面固定让一部分用户长期使用实验流量也是不公平的事情。
ABTest结果是否可信?

在实际业务中,我们会思考一个很现实的问题,ABTest得到的结论是否可信?如果不可信,那需要多少样本才能说明一组ABTest实验是具有显著性的呢?

**假设检验
在适当的条件下,中心极限定理告诉我们,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布,AB测试采用双样本对照的z检验公式。显著性上,根据z检验算出p值,通常我们会用p值和0.05比较,如果p<0.05,我们认为AB没有显著差异。置信问题上,对一个概率样本的总体参数进行区间估计的样本均值范围,它展现了这个均值范围包含总体参数的概率,这个概率称为置信水平。
从另一个角度来说,AB两个实验组之间即使有差异,也不一定能被观测出来,必须保证一定的条件才能使你能观测出统计量之间的差异;否则,结果也是不置信的。而这个条件就是开头提到的问题,样本数量问题。

样本量级
那么问题来了,一次ABTest需要多少样本(用户)呢?假设AB两组实验的用户具有相同的标准差 ,根据公式,带入n1,同时根据假设p值和a值,推导出需要的最低用户数。
,根据公式,带入n1,同时根据假设p值和a值,推导出需要的最低用户数。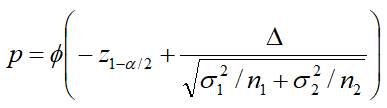
工业界的ABTest
这是字节ABTest实验系统的基本原理:
- 冷启动推荐:通过审核后,抖音会对实时在线用户进行流量分桶,每桶按照总用户量10%分配进行实验推送,第一步叫冷启动流量池曝光,比如你今天上传一个视频,通过双重审核的作品,系统将会分配给你一个初始流量池:200-300在线用户。不论你是不是大号,只要你有能力产出优质内容,就有机会跟大号竞争。
- 标签积累:分配的视频流量再进行分配实验组,每个实验组按照5%比例分配,并为用户贴上相近标签。
- 加权推荐:把作品送量测试给首个实验组用户,根据用户反馈的转、评、赞、完播率等计算作品基数,决定是否进行第二轮推荐及推荐力度。即播放量=A完播率+B 点赞率+C 评论率+D 转发率。
- 加大流量推荐:达到通过推荐基数,继续把作品推送下一个分配实验组进行测试;
- 顶流推荐:进入精品推荐池,大规模曝光,一旦进入精品推荐后,人群标签就被弱化了,几乎每个抖音用户都会刷到。
参考资料
1.KDD2010, Overlapping experiment infrastructure: more, better, faster experimentationOverlapping experiment infrastructure: more, better, faster experimentation
2.https://www.abtasty.com/sample-size-calculator/
3.https://www.jianshu.com/p/eac8ba730d58
4.https://zhuanlan.zhihu.com/p/36384858
5.https://zhuanlan.zhihu.com/p/159605797
6.https://signalvnoise.com/posts/3004-ab-testing-tech-note-determining-sample-size
记得看参考资料!!!

若有收获,就点个赞吧
0 人点赞
