一、联邦学习简介
1.1 联邦学习概述
在进行机器学习过程中,各参与方可借助其他方数据进行联合建模,但这种模式下,各参与方需要交出自己的数据。
联邦学习是各方无需共享数据资源,即在数据不出本地的情况下,进行数据联合训练,建立共享的机器学习模型。
举个简单的例子,假设有两个不同的企业A和企业B,企业A拥有用户特征数据,企业B拥有产品特征数据和标签数据。按照GDPR准则是不可以粗暴地将双方的数据加以合并的,假设双方各自建立一个任务模型(可以是分类或预测),但由于数据的不完整(A缺少B的标签数据,B缺少A的特征数据),那么在各自建立的模型可能效果并不理想。
联邦学习是要解决这个问题:它希望做到各个企业的自有数据不出本地,而联邦系统可以通过加密机制下的参数交换方式,建立一个虚拟共有模型。这个虚拟模型就好像大家把数据聚合在一起建立最优模型一样,但是在建立虚拟模型的时候,数据本身不移动,也不泄露隐私和影响数据合规。这样,建好的模型在各自的区域仅为本地的目标服务。在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助搭建建立了“共同富裕”的策略。
1.2 联邦学习分类
考虑有多个数据拥有方,每个数据拥有方各自所持有的数据集可以用一个矩阵来表示。矩阵的每一行代表一个用户,每一列代表一种用户特征。同时,某些数据集可能还有标签(如果要做预测模型,就必须要有标签数据)。把用户特征叫做X,标签特征叫做Y。用户特征加上标签特征构成了完整的训练数据(X,Y)。但现实中,往往会发现各个数据集用户不完全相同,或用户特征不完全相同,因此数据分布可以分为以下三种情况:
- 两个数据集的用户特征重叠部分较大,而用户重叠部分较小;
- 两个数据集的用户重叠部分较大,而用户特征重叠部分较小;
- 两个数据集的用户与用户特征重叠部分都比较小
由此,将联邦学习分为横向联邦学习、纵向联邦学习以及联邦迁移学习。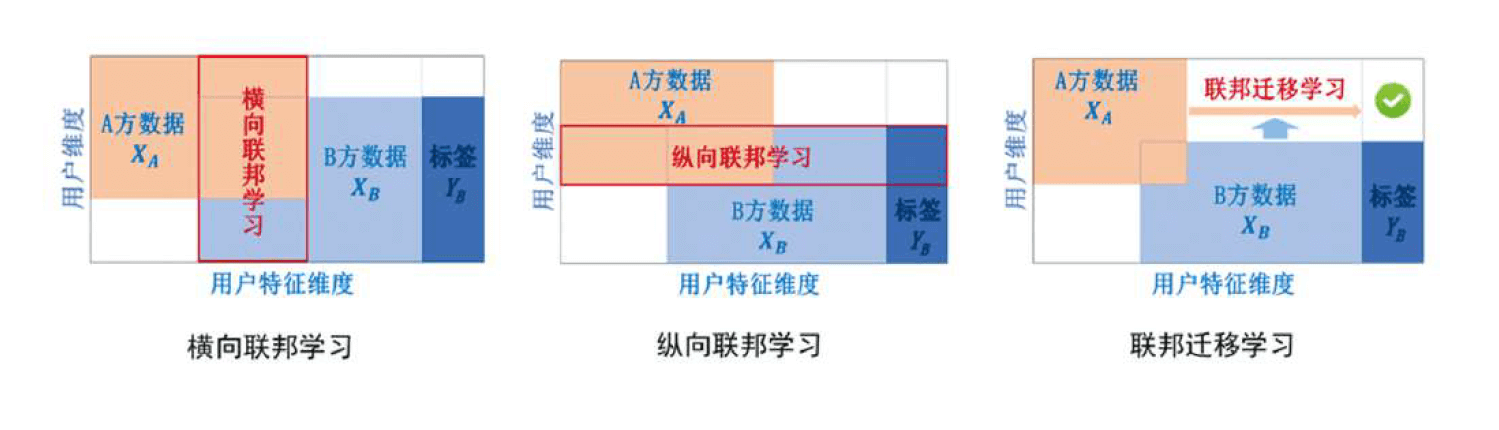
1.2.1 横向联邦学习
适用场景:
横向联邦学习的本质是样本的联合,适用于参与者间业务相似但客户不同,即特征重叠多,用户重叠少时的场景,比如不同地区的银行间,他们的业务相似(特征相似),但用户不同(样本不同)
学习过程: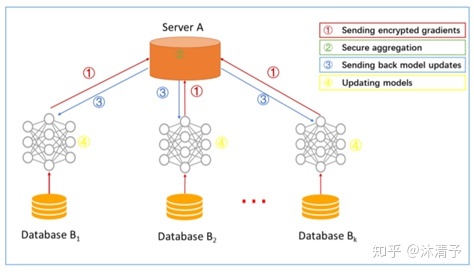
- step1:参与方各自从服务器A下载最新模型;
- step2:每个参与方利用本地数据训练模型,加密梯度上传给服务器A,服务器A聚合各用户的梯度更新模型参数;
- step3:服务器A返回更新后的模型给各参与方;
- step4:各参与方更新各自模型。
步骤解读:
在传统的机器学习建模中,通常是把模型训练需要的数据集合到一个数据中心然后再训练模型,之后预测。在横向联邦学习中,可以看作是基于样本的分布式模型训练,分发全部数据到不同的机器,每台机器从服务器下载模型,然后利用本地数据训练模型,之后返回给服务器需要更新的参数;服务器聚合各机器上的返回的参数,更新模型,再把最新的模型反馈到每台机器。
在这个过程中,每台机器下都是相同且完整的模型,且机器之间不交流不依赖,在预测时每台机器也可以独立预测,可以把这个过程看作成基于样本的分布式模型训练。谷歌最初就是采用横向联邦的方式解决安卓手机终端用户在本地更新模型的问题的。
1.2.2 纵向联邦学习
适用场景:
纵向联邦学习的本质是特征的联合,适用于用户重叠多,特征重叠少的场景,比如同一地区的商超和银行,他们的用户都为该地区的居民(样本相同),但业务不同(特征不同)。
学习过程: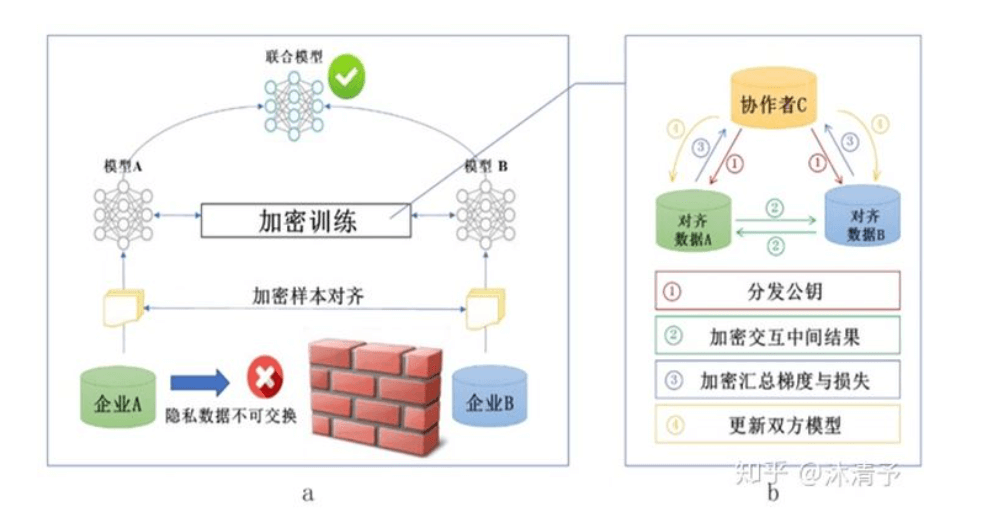
纵向联邦学习的本质是交叉用户在不同业务下的特征联合,比如商场A和银行B,在传统的机器学习建模过程中,需要将两部分数据集中到一个数据中心,然后再将每个用户的特征join成一条数据用来训练模型,所以就需要双方有用户交集(基于join结果建模),并有一方存在label。其学习步骤如上图所示,分为两大步:
第一步:加密样本对齐。是在系统级做这件事,因此在企业感知层面不会暴露非交叉用户。
第二步:对齐样本进行模型加密训练:
- step1:由第三方C向A和B发送公钥,用来加密需要传输的数据;
- step2:A和B分别计算和自己相关的特征中间结果,并加密交互,用来求得各自梯度和损失;
- step3:A和B分别计算各自加密后的梯度并添加掩码发送给C,同时B计算加密后的损失发送给C;
- step4:C解密梯度和损失后回传给A和B,A、B去除掩码并更新模型。
步骤解读:
以线性回归为例具体说明其训练过程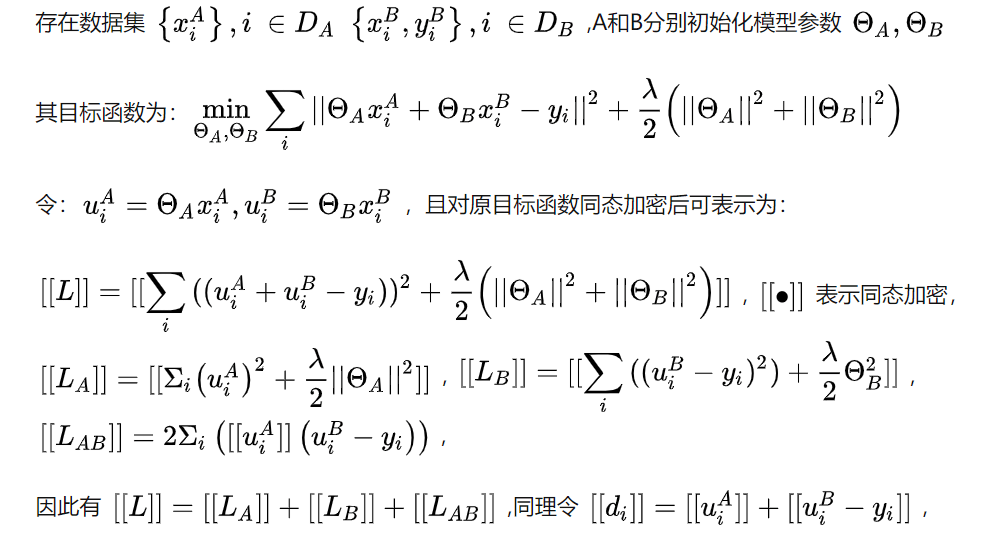
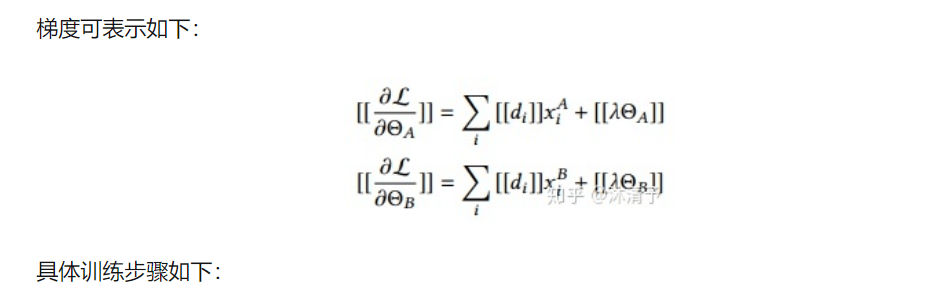
具体训练步骤如下: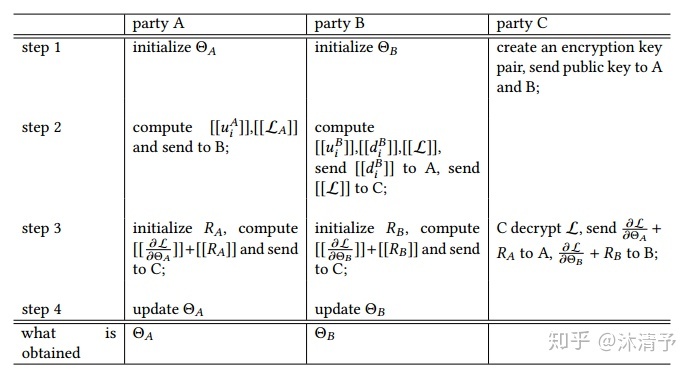
在整个过程中参与方都不知道另一方的数据和特征,且训练结束后参与方只得到自己侧的模型参数,即半模型。
预测过程:
由于各参与方只能得到与自己相关的模型参数,预测时需要双方协作完成,如下图所示: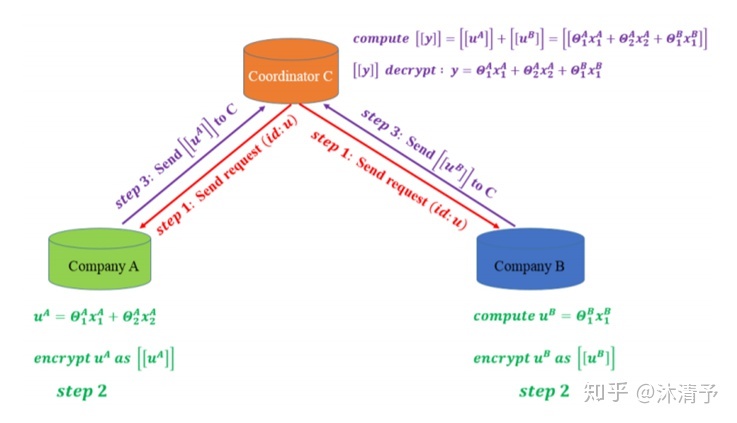
共同建模的结果:
- 双方均获得数据保护
- 共同提升模型效果
- 模型无损失
1.2.3 联邦迁移学习
适用场景:
当参与者间特征和样本重叠都很少时可以考虑使用联邦迁移学习,如不同地区的银行和商超间的联合。主要适用于以深度神经网络为基模型的场景。
迁移学习介绍:
迁移学习,是指利用数据、任务、或模型之间的相似性,将在源领域学习过的模型,应用于 目标领域的一种学习过程。
其实我们人类对于迁移学习这种能力,是与生俱来的。比如,我们如果已经会打乒乓球,就可以类比着学习打网球。再比如,我们如果已经会下中国象棋,就可以类比着下国际象棋。因为这些活动之间,往往有着极高的相似性。生活中常用的“举一反三”、“照猫画虎”就很好地体现了迁移学习的思想。
迁移学习的核心是,找到源领域和目标领域之间的相似性,举一个杨强教授经常举的例子来说明:我们都知道在中国大陆开车时,驾驶员坐在左边,靠马路右侧行驶。这是基本的规则。然而,如果在英国、香港等地区开车,驾驶员是坐在右边,需要靠马路左侧行驶。那么,如果我们从中国大陆到了香港,应该如何快速地适应 他们的开车方式呢?诀窍就是找到这里的不变量:不论在哪个地区,驾驶员都是紧靠马路中间。这就是我们这个开车问题中的不变量。找到相似性 (不变量),是进行迁移学习的核心。
学习过程:
联邦迁移学习的步骤与纵向联邦学习相似,只是中间传递结果不同(实际上每个模型的中间传递结果都不同)。这里重点讲一下联邦迁移的思想: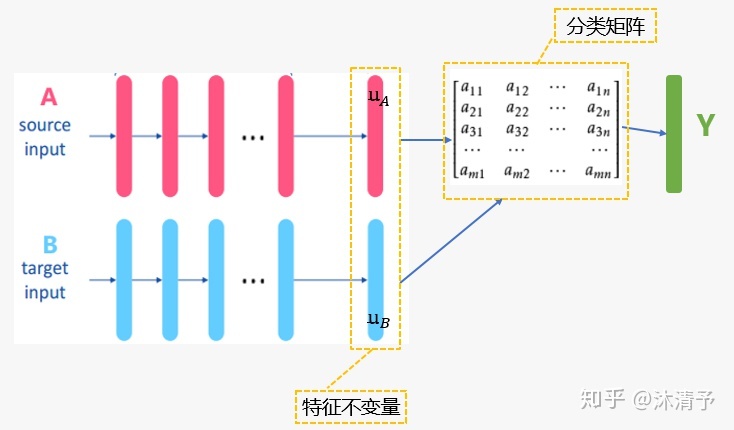


1.3 联邦学习优势
(1)数据隔离,数据不会泄露到外部,满足用户隐私保护和数据安全的需求;
(2)能够保证模型质量无损,不会出现负迁移,保证联邦模型比割裂的独立模型效果好;
(3)参与者地位对等,能够实现公平合作;
(4)能够保证参与各方在保持独立性的情况下,进行信息与模型参数的加密交换,并同时获得成长1.4 联邦学习开源框架介绍
目前业界主要的联邦学习框架有FATE、TensorFlow Federated、PaddleFL、Pysyft等。
微众银行开源的FATE开源项目,覆盖横向联邦学习,纵向联邦学习以及迁移联邦学习,同时FATE提供20多个联邦学习算法组件,涵盖了LR、GBDT、DNN等主流算法,FATE也提供了一站式联邦模型服务解决方案,涵盖联邦特征工程、联邦机器学习模型训练、联邦模型评估、联邦在线推理。相较于其他开源框架,在工业应用上有显著的优势
OpenMinded开源的Pysyft框架,较好地支持横向联邦学习。该框架同时支持Tensorflow,Keras,Pytorch,为使用人员快速上手提供了较多的选择。Pysyft提供了安全加密算法,数值运算算子,以及联邦学习算法,用户也可以自己高效的搭建自己的联邦学习算法。相较于Fate,OpenMinded尚未提供高效的部署方案及serving端解决方案。相比工业应用,更适合作为高效的学术研究,原型开发。
谷歌开源的Tensorflow Federated框架,较好的支持横向联邦学习。其中,可以通过Federated Learning API 与Tensorflow/Keras交互,完成分类、回归等任务。目前Tensorflow Federated在安全加密算子上缺少开放实现,同时缺少对线上生产的完善支撑。
2019年11月,百度开源了其联邦学习框架PaddleFL。PaddleFL开源框架中包含了DiffieHellman等安全算子,及LR等机器学习算法。由于其开源时间较短,算子丰富程度逊于上述三个框架,但其可以与百度机器学习开源框架PaddlePaddle进行交互。
| 开源框架 | FATE | Tensorflow Federated | PaddleFL | Pysyft |
|---|---|---|---|---|
| 受众定位 | 工业产品 学术研究 |
学术研究 | 学术研究 | 学术研究 |
| 牵头公司 | 微众银行 | 百度 | OpenMined | |
| 联邦学习类型 | 横向联邦学习 纵向联邦学习 联邦迁移学习 |
横向联邦学习 | 横向联邦学习 纵向联邦学习 |
横向联邦学习 |
| 联邦特征工程 | 特征分箱 特征选择 特征相关性 支持 |
不支持 | 不支持 | 不支持 |
| 机器学习算法 | LR,GNDT,DNN等 | LR,DNN等 | LR,DNN等 | LR,DNN等 |
| 安全协议 | 同态加密 SecretShare RSA DiffieHellman |
DP | DP | 同态加密 SecretShare |
| 联邦在线推理 | 支持 | 不支持 | 不支持 | 不支持 |
| Kubernetes | 支持 | 不支持 | 不支持 | 不支持 |
二、FATE框架及相关文档
FATE (Federated AI Technology Enabler) 是微众银行AI部门发起的开源项目,为联邦学习生态系统提供了可靠的安全计算框架。FATE项目使用多方安全计算(MPC)以及同态加密 (HE) 技术构建底层安全计算协议,以此支持不同种类的机器学习的安全计算,包括逻辑回归、基于树的算法、深度学习和迁移学习等。
2.1 FederatedML
一个实用的、可扩展的联邦机器学习库。包括许多常见机器学习算法联邦化实现,所有模型均采用模块化解耦的方式进行开发,从而增强可扩展性。
主要功能:
- 联邦样本对齐:纵向样本ID对齐,包括基于RSA+哈希等对齐方式。
- 联邦特征工程:联邦采样,联邦特征分箱,联邦特征选择,联邦相关性,联邦统计等
- 联邦机器学习:联邦LogisticRegression,LinerRegression,PossionRegression,联邦SecureBoost,联邦DNN,联邦迁移学习等。
多方安全计算协议:提供多种安全协议,包括同态加密,SecretShare,RSA,DiffieHellman等。
2.2 FATEFlow
FATEFlow是联邦学习建模Pipeline调度和生命周期管理工具,为用户构建端到端的联邦学习pipeline生产服务。FATEFlow实现了pipeline的状态管理及运行的协同调度,同时自动追踪任务中产生的数据、模型、指标、日志等便于建模人员分析。另外,FATEFlow还提供了联邦机制下的模型一致性管理以及生产发布功能。
FATEFlow调度流程:
主要功能:联邦建模Pipeline DAG Parser
- 联邦建模任务生命周期管理
- 联邦建模任务多方协同调度
- 联邦多方模型管理、模型版本管理
-
2.3 FATEBoard
FATEBoard是联邦学习建模的可视化工具,为终端用户可视化和度量模型训练的全过程,帮助用户更简单而高效地进行模型探索和模型理解。
FATEBoard由任务仪表盘、任务可视化、任务管理与日志管理等模块组成,支持模型训练过程全流程的跟踪、统计和监控等,并为模型运行状态、模型输出、日志追踪等提供了丰富的可视化呈现。FATEBoard可大大增强联邦建模的操作体验,让联邦建模更易于理解与实施,有利于建模人员持续对模型探索与优化。
主要功能: 联邦建模任务生命周期过程可视化
- 联邦模型可视化
-
2.4 FATE Serving
一个可扩展的、高性能的联邦学习模型服务系统。FATE-Serving是针对联合学习模型的高性能工业化服务系统,专为生产环境而设计。FATE-Serving现在支持:
高性能的在线联合学习算法。
- 联合学习在线推理管道。
- 动态加载联合学习模型。
- 可以服务于多个模型或同一模型的多个版本。
- 支持A / B测试实验模型。
- 使用联合学习模型进行实时推理。
- 支持多级缓存以获取远程方联合推断结果。
- 支持用于生产部署的预处理,后处理和数据访问适配器。
具体原理如下图所示: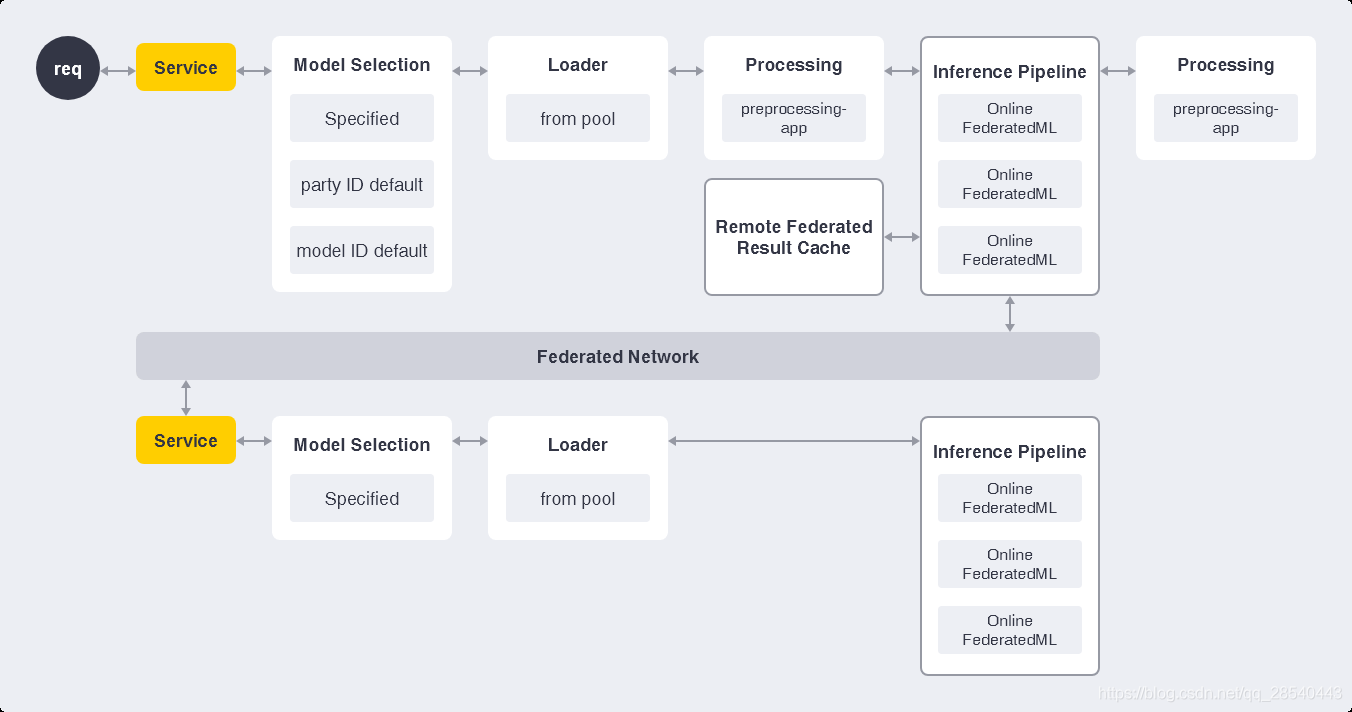
主要功能:
- 高性能在线联邦学习推理算法
- 在线联邦模型管理
-
2.5 Federated Network
联邦学习多方通信网络。
架构有:联邦学习方之间的跨站点通信、模组 MetaService:元数据管理者和持有者
- Proxy:应用程序层传输端点
- Federation :全局对象的抽象和实现,即各方之间要“联合”的数据
- Fate-Exchange: 负责通信
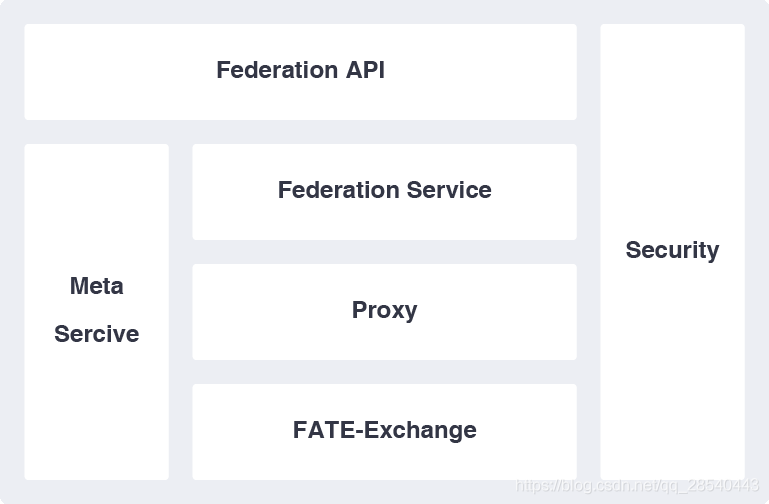
2.6 KubeFATE
通过把FATE的所有组件用容器的形式封装,实现了使用Docker Compose或者Kubernetes来部署。现代应用以DevOps方式开发,基于容器部署应用的优势相当明显,应用不仅可以无差别地运行在支持容器的平台上。
2.7 FATE文档
2.7.1 Supported Components
DataIO
对应模块名称DataIO,通常是建模任务的第一个组件,将用户上传数据转换为实例对象。
数据输入:DTable,值是原始数据。
数据输出:转换后的DTable,值是federatedml/feature/instance.py中定义的数据实例。
Intersect
对应模块名称Intersection计算两方的相交数据集,而不会泄漏差异集信息。主要用于异构方案任务。
数据输入:DTable数据。
数据输出:同时出现在两方DTable的键组成的DTable。
Federated Sampling
对应模块名称FederatedSample,联合采样数据,使分布在各方之间变得平衡。此模块支持federated版本和standalone版本。
数据输入:DTable数据。
数据输出:采样数据,支持随机采样和分层采样。
Feature Scale
对应模块名称FeatureScale,用于特征缩放和标准化的模块。
数据输入:DTable,其值为实例。
数据输出:转换后的DTable。
模型输出:变换系数,例如最小/最大,平均值/标准差。
Hetero Feature Binning
对应模块名称HeteroFeatureBinning,使用合并输入数据,计算每个列的iv和woe,并根据合并后的信息转换数据。
数据输入:DTable在guest中有标签y,在host中没有标签y。
数据输出:转换后的DTable。
模型输出:每列的iv /woe,分裂点,事件计数,非事件计数等。
OneHot Encoder
对应模块名称OneHotEncoder,将一列转换为OneHot格式。
数据输入:输入DTable。
数据输出:转换了带有新header的DTable。
模型输出:原始header和特征值到新header映射。
Hetero Feature Selection
对应模块名称HeteroFeatureSelection,提供5种类型的过滤器。每个过滤器都可以根据用户配置选择列。
数据输入:输入DTable。
模型输入:如果使用iv过滤器,则需要hetero_binning模型。
数据输出:转换的DTable具有新的header和已过滤的数据实例。
模型输出:每列是否留下。
Hetero-LR
对应模块名称HeteroLR,通过多方构建异质逻辑回归模块。
数据输入:输入DTable。
模型输出:Logistic回归模型。
Homo-LR
对应模块名称HomoLR,通过多方构建同质逻辑回归模块。
数据输入:输入DTable。
模型输出:Logistic回归模型。
Hetero Secure Boosting
对应模块名称HeteroSecureBoost,通过多方建立异构安全提升模型。
数据输入:DTable,值是实例。
模型输出:SecureBoost模型,由模型元和模型参数组成。
Evaluation
对应模块名称Evaluation,为用户输出模型评估指标。
2.7.2 DSL & Task Submit Runtime Conf Setting
首先简单介绍一下上传数据的方法,创建两个json文件:up_dt_guest.json和up_dt_host.json,并写入内容如下: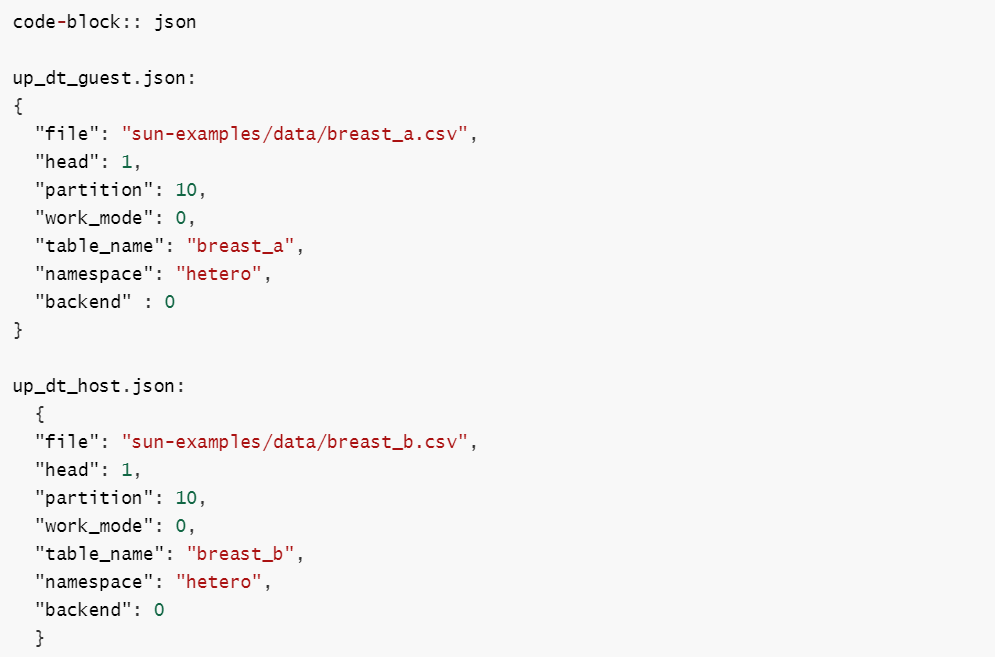
字段说明:
- file: 文件路径
- table_name&namespace: 存储数据表的标识符号
- head: 指定数据文件是否包含表头
- partition: 指定用于存储数据的分区数
- work_mode: 指定工作模式,0代表单机版,1代表集群版
- backend: 指定后端,0代表EGGROLL, 1代表SPARK
为了使建模任务更加灵活,目前,FATE使用其自己的领域特定语言(DSL,domain-specific language)来描述建模任务。通过使用这种DSL,可以将诸如数据输入,功能设计和分类/回归模块等建模组件组合为有向非循环图(DAG)。因此,用户可以根据需要灵活地组合算法组件。
此外,每个组件都有自己的参数要配置。此外,各方之间的配置可能会有所不同。为了方便起见,FATE使用在一个文件中配置所有各方和所有组件的所有参数。
DSL Configure File
使用json文件作为dsl配置文件,它实际上是一个字典。dict的第一级始终是“component”,显示您将在建模任务中添加组件。
然后,应在第二层中定义每个组件。以下设置组件的示例:
如示例所示,用户将组件名称定义为该模块的键。但是此模块应以“_num”结尾,其中num应以0开头。
Field Specification(字段说明)
1.模块:指定使用哪个组件。除.json后缀外,此字段应与federatedml / conf / setting_conf中的文件名严格相同。
2.输入:输入有两种类型,数据和模型。
- data(有三种可能的data_input形式)
a. data:通常用于data_io,feature_engineering模块和评估中。
b. train_data:用于homo_lr,hetero_lr和secure_boost。如果提供此字段,则任务将被解析为拟合任务。
c. eval_data:如果提供了train_data,则此字段为可选。在这种情况下,此数据将用作验证集。如果未提供train_data,则此任务将被解析为预测或迁移任务。
- model(有两种可能的模型输入类型)
a. model:这是由相同类型的组件输入的模型。例如,hetero_binning_0作为拟合组件运行,hetero_binning_1将hetero_binning_0的模型输出作为输入,因此可以用于迁移或预测。示例如下:
b. isometric_model:用于指定来自上游组件的模型输入。例如,特征选择将把特征分类作为上游模型,因为它将信息值用作特征的重要性。这是特征选择组件的示例:
3.输出:与输入相同,可能会出现两种类型的输出,即数据和模型。
- data:指定输出数据名称。
- model:指定输出模型名称。
Submit Runtime Conf
除了dsl conf外,用户还需要准备一个Submit runtime conf来设置每个组件的参数。
1.initiator(启动器):首先,应在此运行时配置文件中指定启动器。这是设置启动器的示例:
2.role(角色):应指定此建模任务中涉及的所有角色。角色中的每个元素都应包含角色名称及其角色ID。ID之所以采用列表形式,是因为一个角色可能存在多个参与方。
3.role_parameters:应当在各个参与方之间指定这些参数。请注意,每个参数都应具有列表的形式。
i.在role_parameters内部,使用参与者名称作为键,并且这些参与者的参数是值。以下结构为例:
如本示例所示,对于每一方,输入参数(例如train_data,eval_data等)应在args中列出。上面的名称和名称空间是上载数据的表指示符。
然后,用户可以为每个组件配置参数。 组件名称应与dsl配置文件中定义的名称匹配。 每个组件参数的内容都在federatedml / param中的Param类中定义。
4.algorithm_parameters:如果各方之间有一些相同的参数,则可以在algorithm_parameters中进行设置。示例如下:
与角色参数中的形式相同,参数的每个键都是在dsl配置文件中定义的组件的名称。
完成这些设置并提交任务后,fate-flow将结合角色参数中的参数列表和算法参数。 如果仍有一些字段未定义,则将使用默认运行时conf中的值。 然后,fate-flow将这些配置文件发送给它们的相应方,并启动联合建模任务。
三、FATE框架单机版部署
FATE支持Linux或者Mac操作系统,当前FATE支持:
(1)Native部署:单机部署和集群部署
运行环境:jdk1.8+、python3.6、python virtualenv、mysql5.6+
单机版:该版本支持两种方式:1)Docker;2)手动编译
集群版:从单机版部署迁移到集群版部署仅需要更改配置文件,不需要更改算法
(2)KubeFATE部署
目前使用的是单机版docker部署
单机版提供了三种部署方式,可以根据实际情况进行选择。
- 使用Docker镜像安装FATE(推荐)
- 在主机中安装FATE
- 使用Docker从源码构建FATE(需要40分钟或更长时间)
3.1 安装docker
注意这里的建议版本是18.09,所以需要安装18.09的docker版本
3.2 安装docker-compose
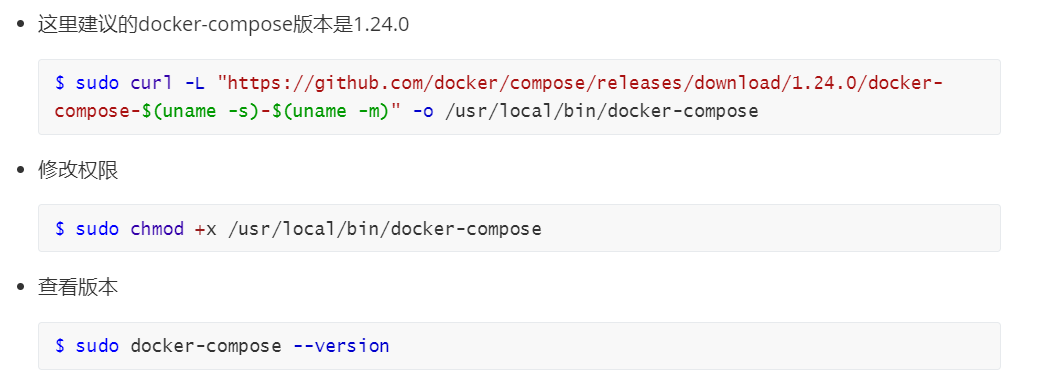
3.3 下载FATE项目

3.4 docker容器挂载
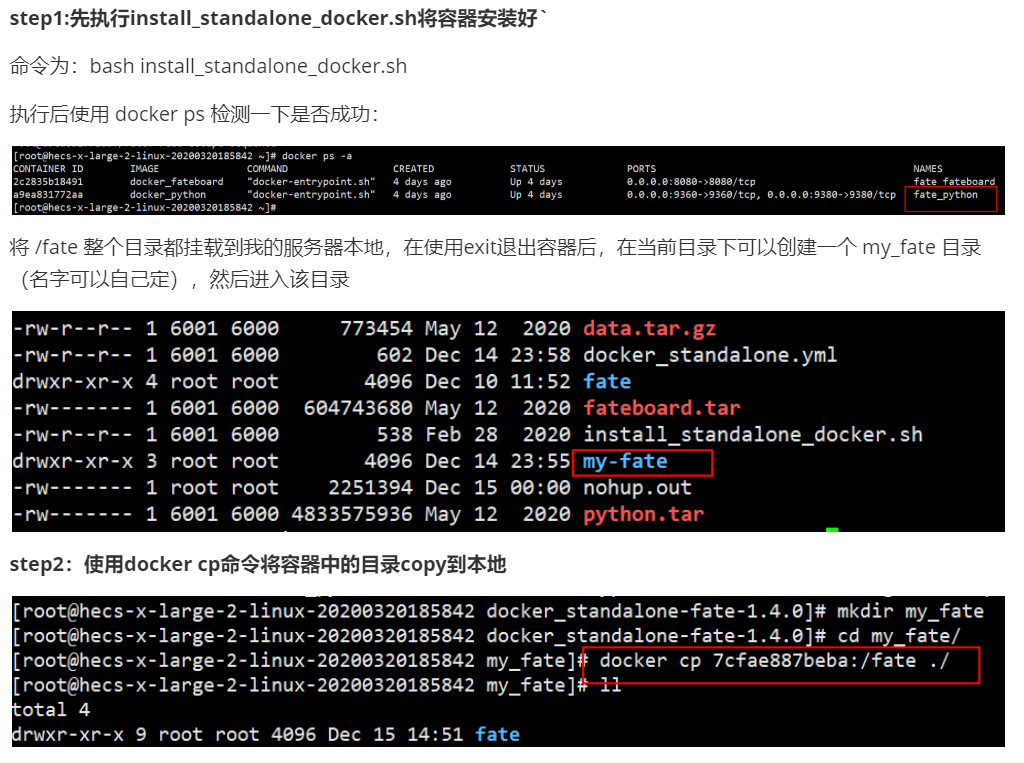
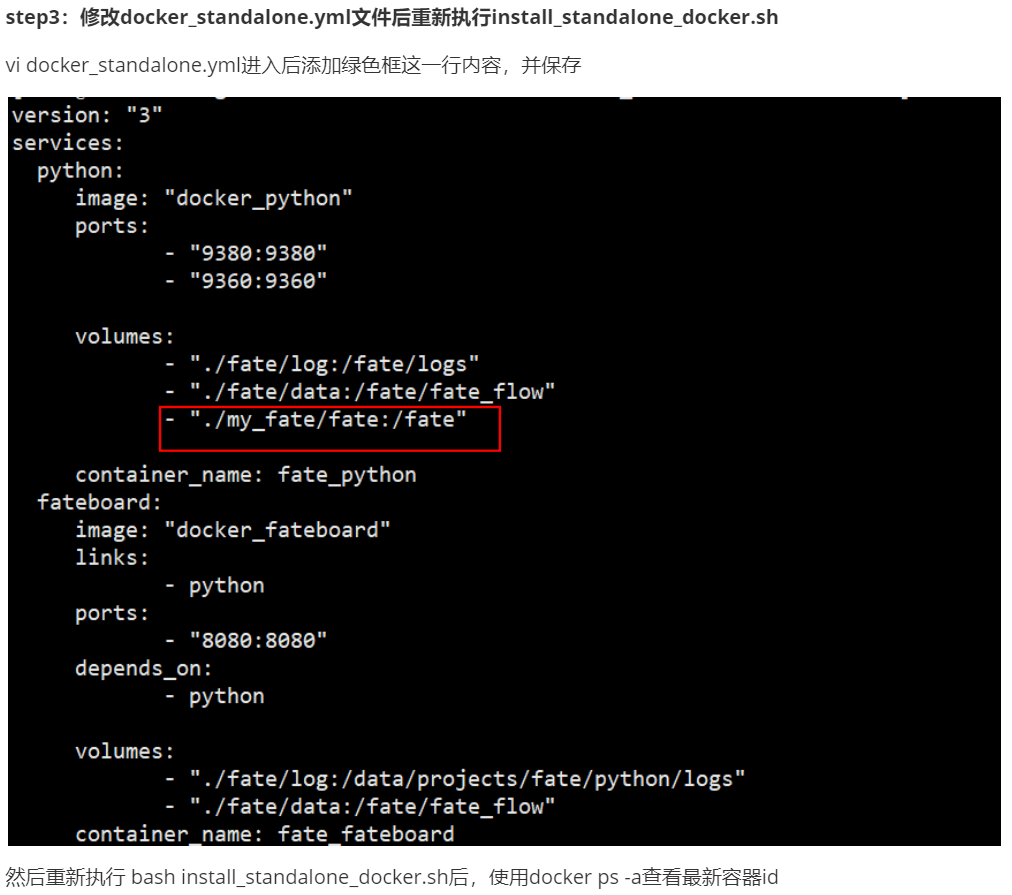
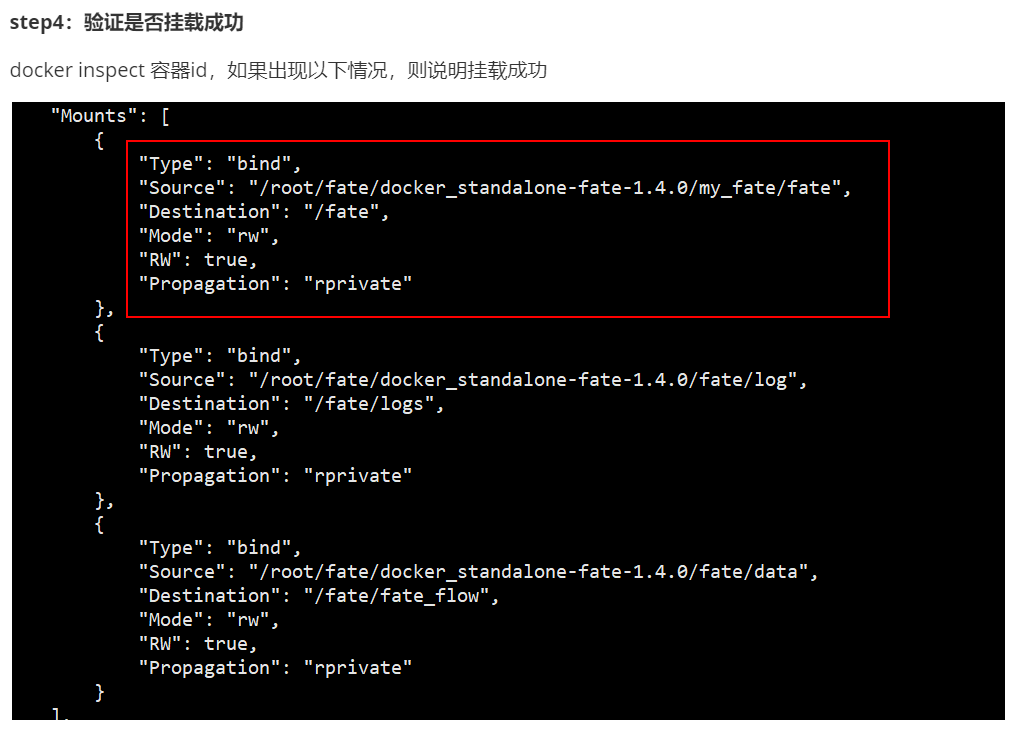
3.5 pycharm连接linux服务器
在windows本地连接刚刚的挂载路径,从而达到本地pycharm上直接修改容器中的代码,而不用再在黑黑的vi中编辑。
step1:下载一个专业版的pycharm
step2:创建新项目并连接服务器的指定目录(详细步骤如下)
(1)创建project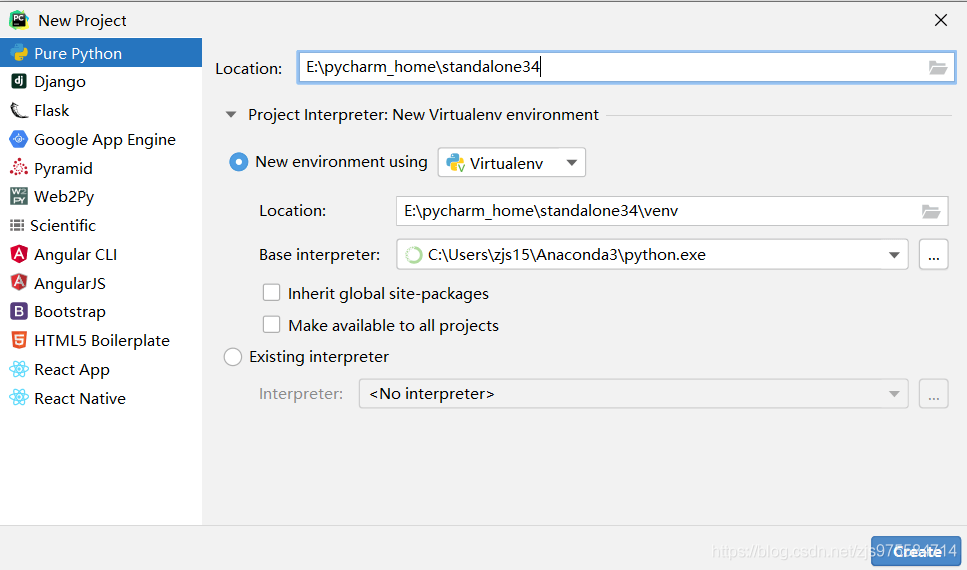
(2)设置interpreter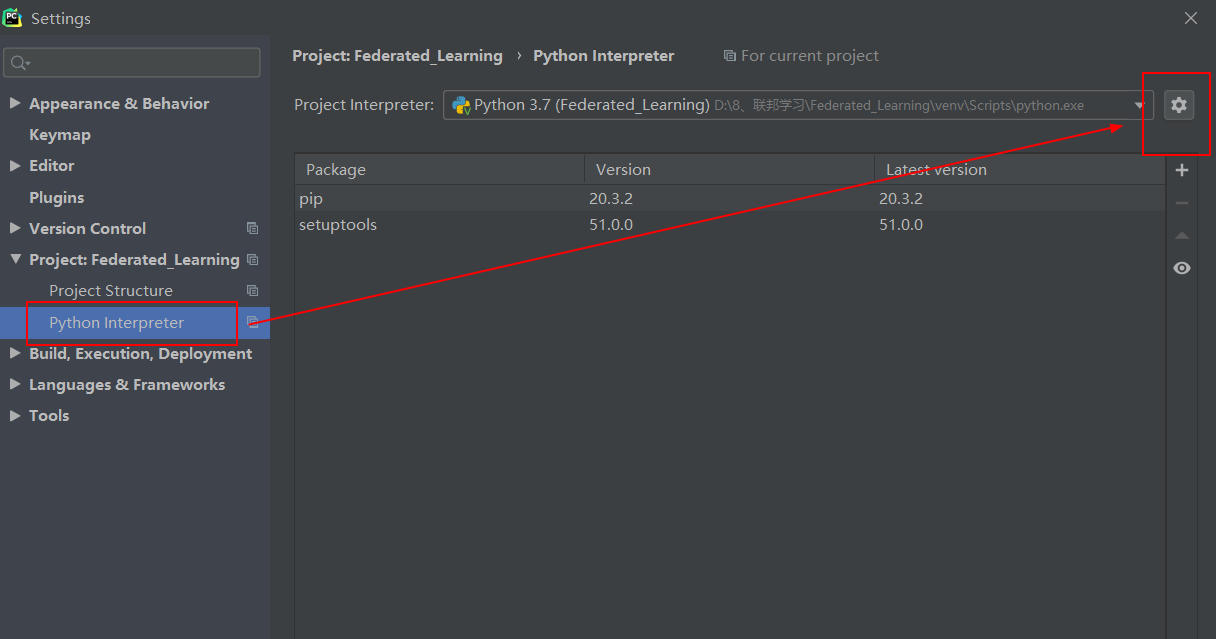
填好服务器配置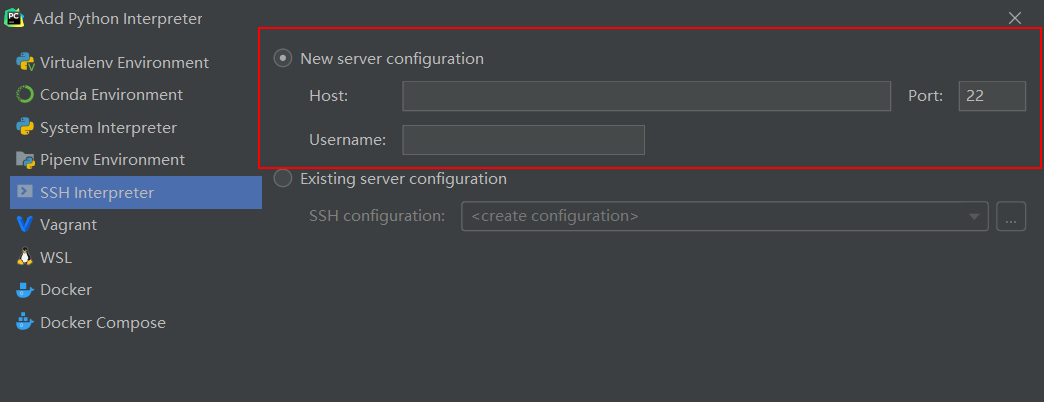
到这步时候,红色框里就是指配对服务器的哪个目录,我们选择刚刚配置的那个挂载目录即可
这个文件夹的图标你放上去才能显示出来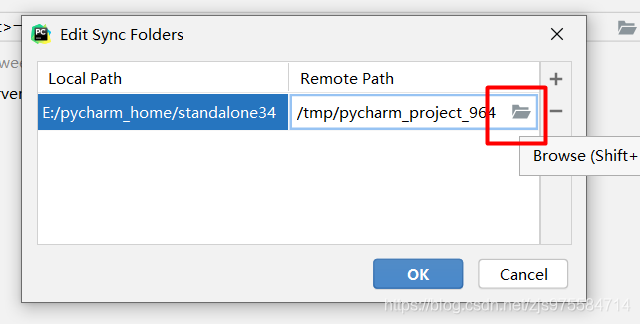
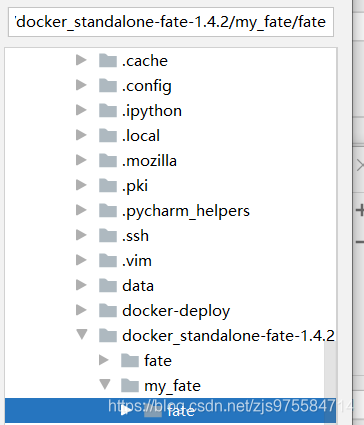
选择好刚刚创建的my_fate下的fate目录后确定,然后一路ok、finish就好了
step3:download和upload
无论是上传还是下载,我们都需要选中某个文件或文件夹才有效,比如我们现在项目中什么也没有时候,我们可以选择项目名后download即可。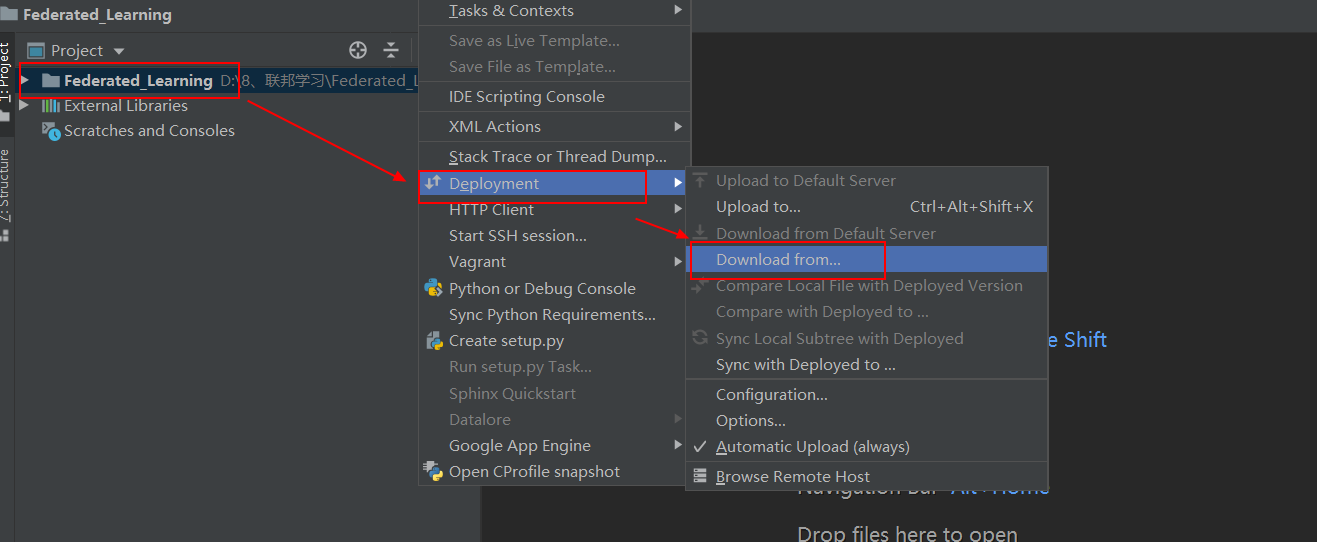
step4:友情提示区
(1)自动上传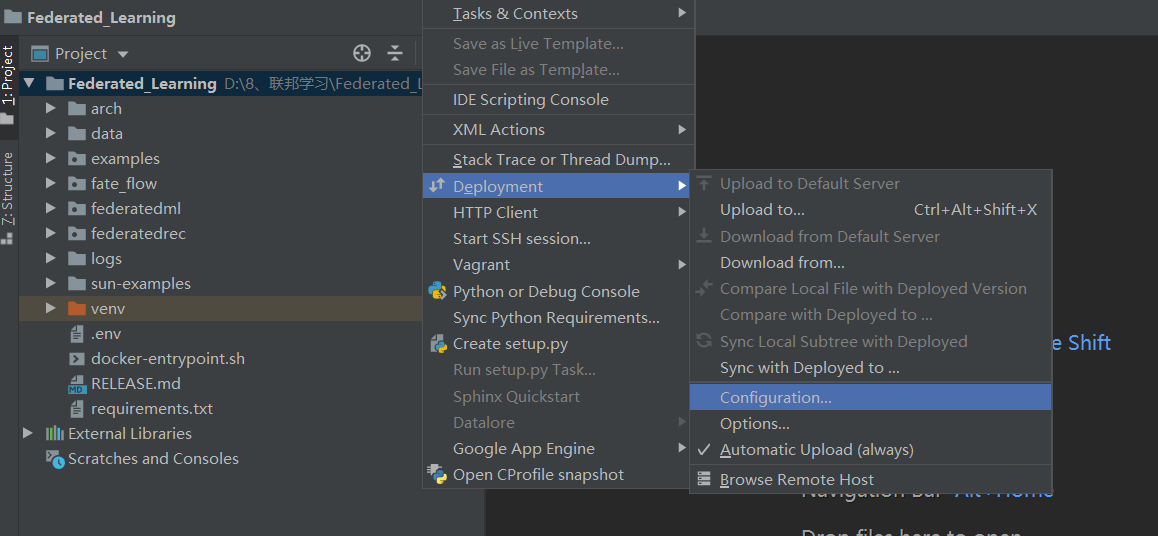
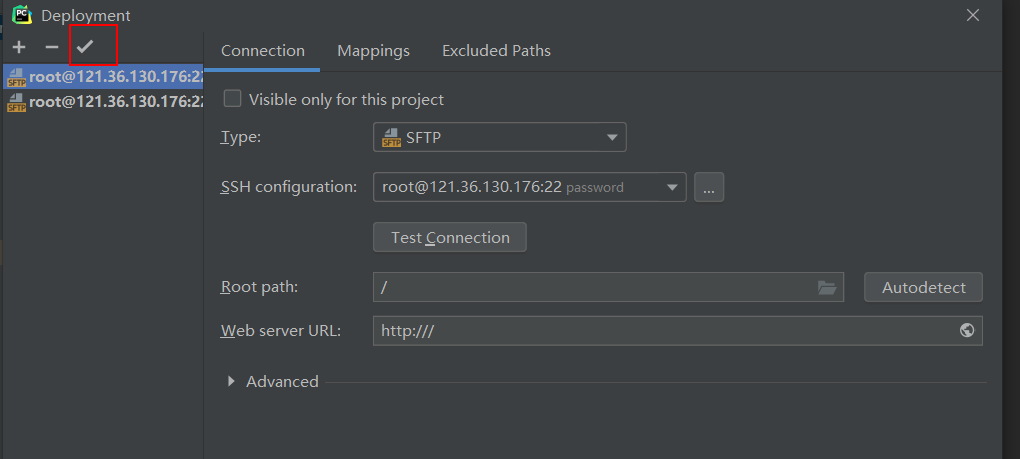
点进去后用这个小对勾选择你要选择的默认服务器
再把这个选上后,每次修改后使用ctrl+s保存即可自动上传,十分方便
(2)这个选项不取消有可能会报错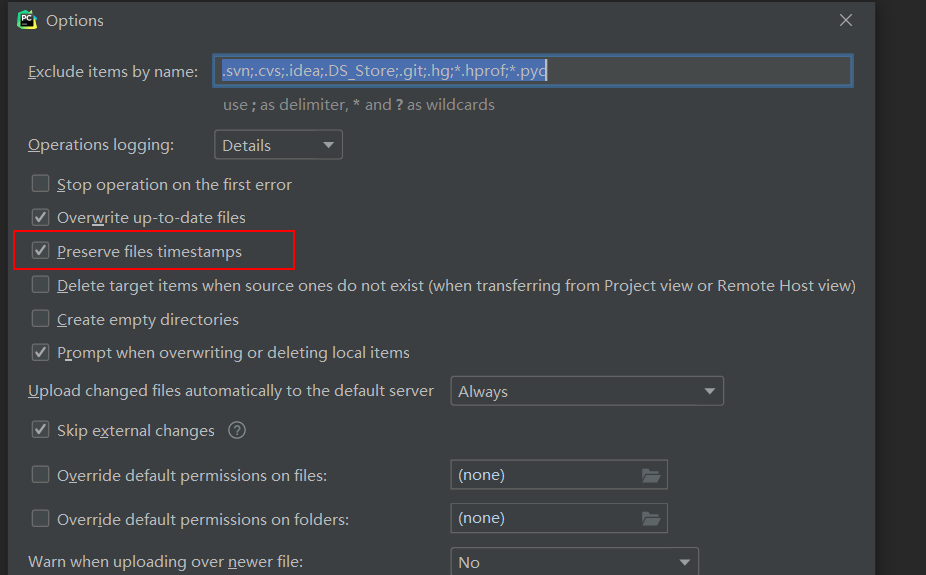
四、FATE纵向联邦建模分析
4.1 联邦建模过程信息交互
在纵向联邦学习的三方(arbiter,guest,host)架构中,涉及到数据相关的信息交互有以下几个环节:加密样本ID匹配对齐(RSA)或者加密样本ID匹配对齐(RAW)、特征工程-分箱标签加密、纵向模型训练过程。
(1)加密样本ID匹配对齐
RSA:
加密算法选择RSA和哈希,加密样本对齐后,guest和host只能得知对齐的样本ID,无法得知非对齐部分的对方样本ID信息;
RAW:
加密算法选择哈希,取交集的一方在过程中自方的ID没有出本地,提高和保障了安全性;
(2)特征工程-分箱标签加密环节交互的是模型的样本个数和标签信息
加密算法选择Paillier同态加密,双方之间不传输原始的业务数据,仅传输加密后的样本个数及标签;
(3)纵向模型训练过程
加密算法选择Paillier同态加密,由arbiter中立方生成秘钥对,将公钥发送给guest和host,私钥在arbiter方。信息交互中,guest和host将用公钥加密后的信息传输给arbiter,arbiter用私钥解密后,将聚合优化后的梯度分别传输给guest和host,guest和host更新模型参数后,继续模型训练。循环以上步骤,直至loss达到预期或者训练次数达到设置的最大值时完成模型训练。在训练的过程中,双方都不知道对方的数据结构,并且只能获得自己那一部分特征需要的参数。所以并没有直接传递数据相关的信息,它们间的通信也是安全的;
全程三方示例流程图: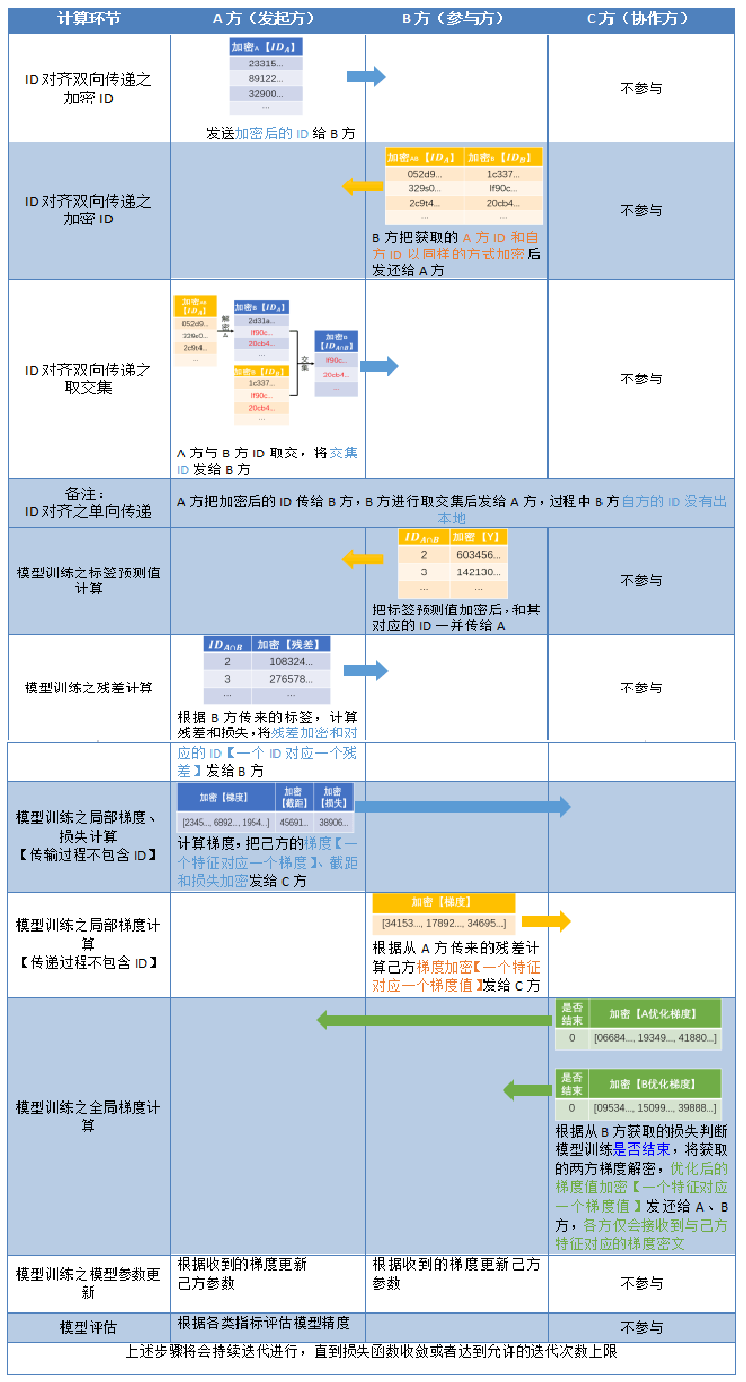
4.2 加密样本ID匹配对齐(RSA)

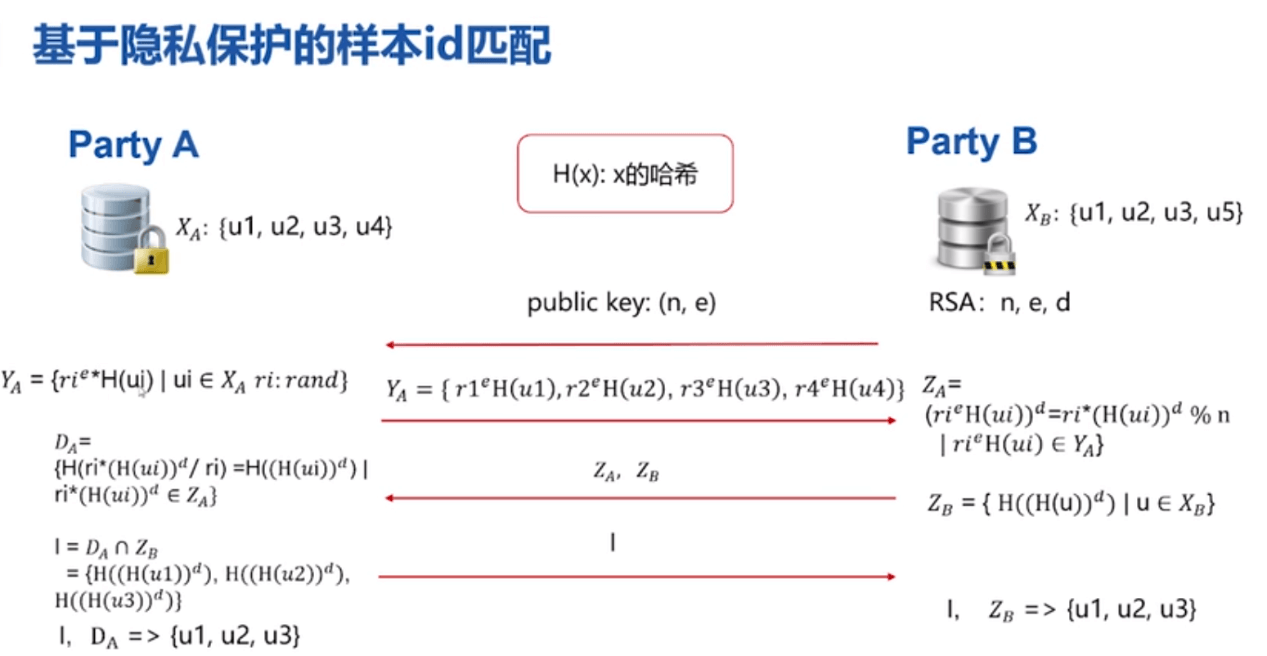
RSA+哈希【A方为GUEST,B方为HOST】:
选用哈希的原因:由于ID不一定是纯数字可能是字符串,需通过哈希将其转化为整数。
- B把n和e作为公钥发给A;
- A把e作为随机数的指数,乘上自己数据的哈希值。得到Ya返回给B。因为有随机数,所以B无法知晓A的原始数据;
- B用私钥d作为Ya的指数,根据费马小定理,用d加幂后就等于随机数乘上(A数据哈希值)的d次方。得到Za;
- B先对自己数据取哈希值,再用私钥d作为指数,再取一次哈希值,得到(B数据哈希值d次方)的哈希值,Zb,连同Za一起返回给A。由于A不知道B的私钥d,所以他无法解开Zb,无法知晓B的原始数据;
- A拿到Za后,先除以自己的随机数,得到(A数据哈希值)的d次方,再做一次哈希。得到(A数据哈希值d次方)的哈希值,Da;
- A将Da和Zb取交集。因为两者都是(数据哈希值d次方)的哈希值;
- A将交集返回给B,双方各自获得交集数据
4.3 加密样本ID匹配对齐(RAW)

A、B方可以根据算法参数设置哪方为取交集方和传输方
A:取交集方(ID不出库)、B:传输方(ID出库)
IDA:{X1、X2、X3、X4}和IDB:{X1、X2、X5、X6}
第一步:B方将ID取哈希值【MD5,SHA256等哈希方式】,将加密结果传给A
第二步:A方将己方ID取哈希值【MD5,SHA256等哈希方式】,和B方的加密结果取交集,后将对齐结果发还给B
全程A方为取交集的一方在过程中自方的ID没有出本地,提高和保障了安全性。A方将取交后的结果{X1、X2}同步发给B方。4.4 联邦特征分箱标签计算

A方为HOST、B方为GUEST
特征分箱的目的是计算IV值,IV值是用来衡量这个特征对标签y的贡献程度,辅助于特征选择;
在纵向中A侧(含有X),B侧(含X、Y)计算WOE和IV。由于A侧只有特征X,没有Y,计算WOE和IV得同时依赖X、Y,A侧不对B侧暴露X,B侧不对A暴露Y,最终只能让B侧获得所有特征的WOE&IV。
第一步:B侧对标签Y通过同态加密方式加密【Paillier加密具有混淆项,即同样的数字0经过加密后结果不一样,因此不能通过密文推出原来的标签为0还是1】
第二步:A侧有自己特征的分箱信息,即知道每个分箱中的ID信息,通过B侧传来的加密标签Y后获得0、1的个数,再将每个分箱中0,1的个数发给B侧
第三步:B侧解密后知道0、1个数,进而求得WOE和IV值。再反馈给host方列名【guest方获取的host方列名为匿名的形式例如Host_0这种,Host依次获知哪些特征是需要保留的。】4.5 纵向模型训练过程梯度传递
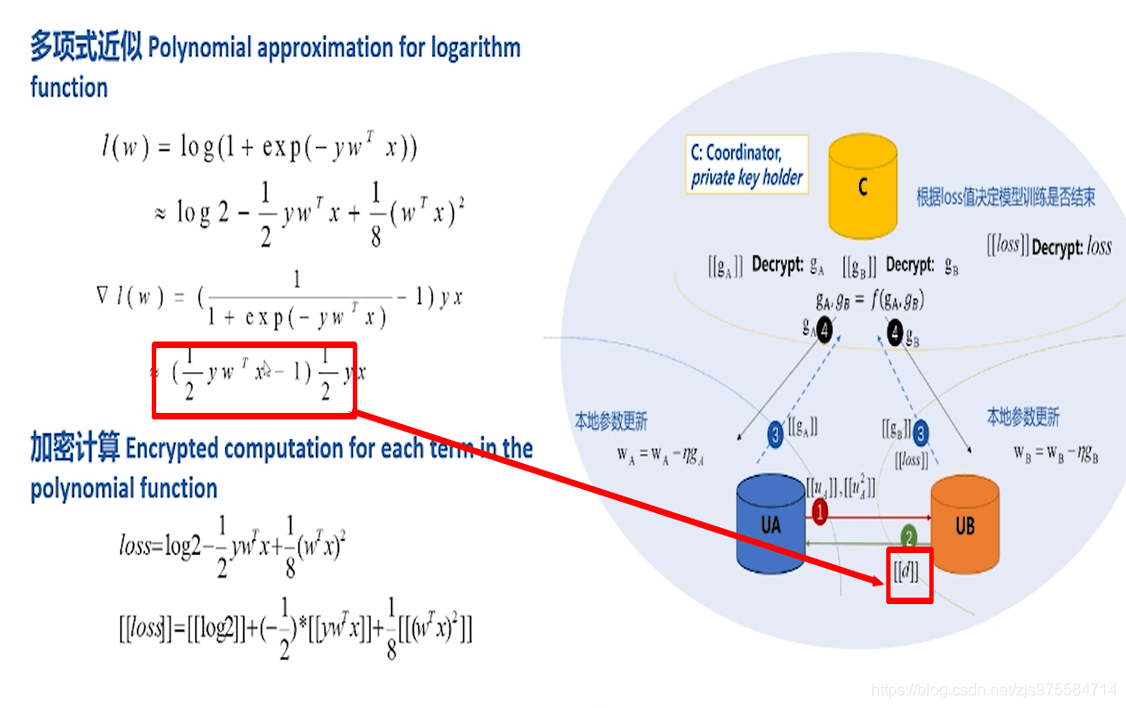
逻辑回归
总体上,加密训练过程从分发公钥到更新模型分为四步。【1,2步包含ID,3.4步不包含】
之所以要将损失函数通过泰勒展开式展开是由于加密算法目前支持加法和数乘同态,对Log不支持,故采用泰勒展开,式子变为只有加法和乘法。
推导过程中需要用的定义如下:[[]]:加密输出、l(w):loss
第一步A方发给B方的信息以一个array的形式发送,其中包括明文ID,一个ID对应一个中间聚合值。
第二步B方发给A方的残差也是以一个array的形式发送,其中包括明文ID,一个ID对应一个残差值。
第三步B方发给C方的损失以一个累加损失值的形式发送(对整份样本求得的一个累加损失值);五、简单案例操作
以经典的分类问题判断肿瘤良性恶性为例,使用联邦学习,基于逻辑回归进行训练。基于已经部署好的单机Fate进行实践。5.1 准备上传数据
我们直接使用Fate提供的案例数据目录在examples/data/breast_homo_guest.csv、examples/data/breast_homo_host.csv。这里上传数据需要准备host以及guest两方的上传数据,根据官方解释在Fate的概念中分成3种角色,Guest、Host、Arbiter。
5.2 编写上传数据配置upload_data_role.json
(1)编写host的上传配置文件upload_data_host.json:
(2)编写guest的上传配置文件upload_data_guest.json
(3)编写test上传配置文件upload_data_test.json
字段说明:
- file: 文件路径
- head: 指定数据文件是否包含表头
- partition: 指定用于存储数据的分区数
- work_mode: 指定工作模式,0代表单机版,1代表集群版
- table_name&namespace: 存储数据表的标识符号
backend: 指定后端,0代表EGGROLL,1代表SPARK
5.3 上传数据
上传数据命令:

${your_install_path}: fate的安装目录
- ${upload_data_json_path}:上传数据配置文件路径
注:每个提供数据的集群(即guest和host)都需执行此步骤 运行此命令后,如果成功,将显示以下信息:
docker exec -it fate_python bash进入fate节点内部
导入训练数据、测试数据以及评估数据输入以下命令
控制台显示以下提示表示上传成功: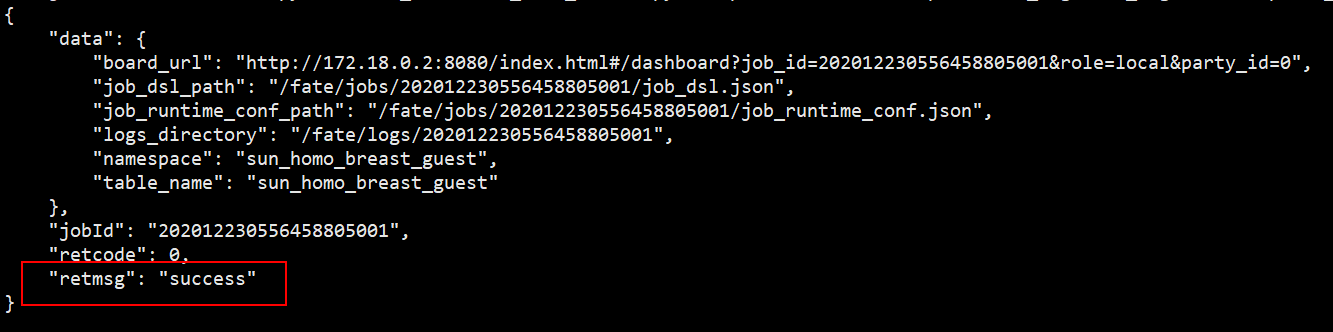
打开fate监控面板fate_board http://${boardhost}:8080,根据上传完之后的job_id查询得,刚刚上传的三个任务: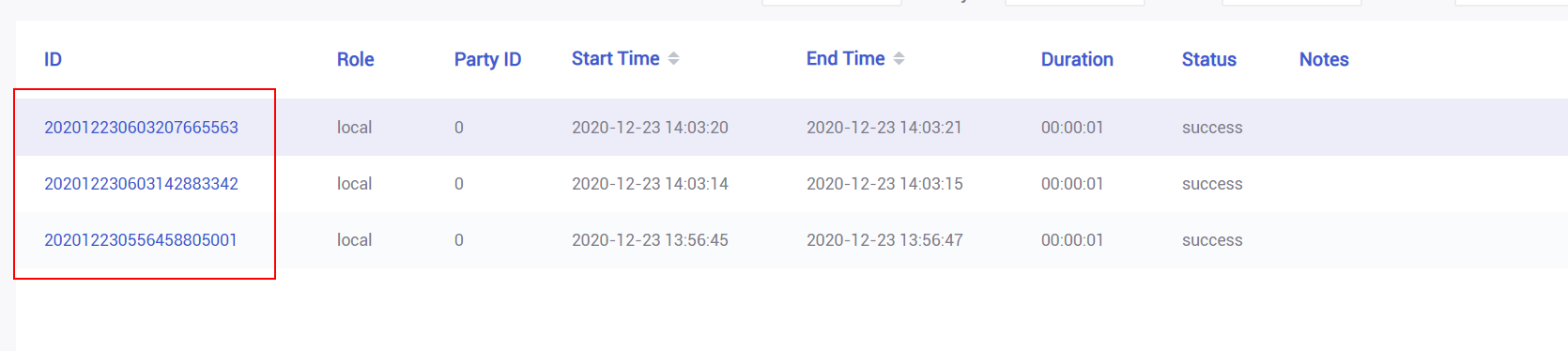
选择具体的任务查看详细信息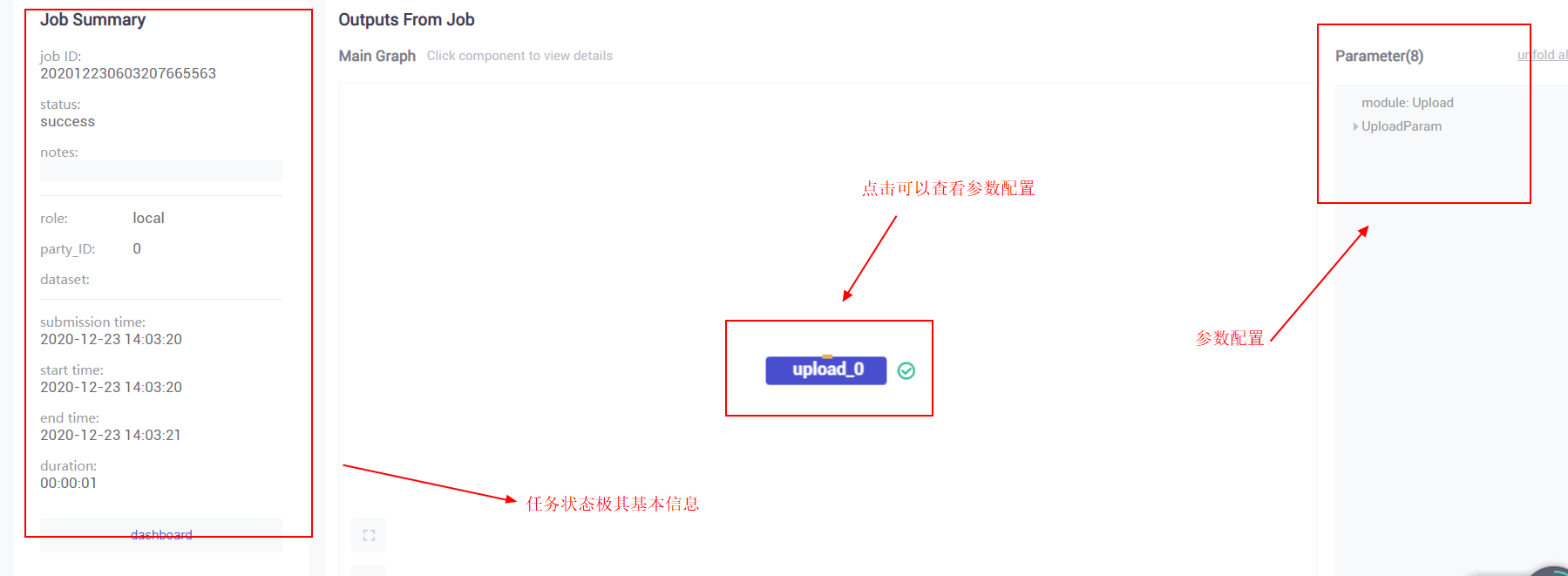
5.4 建模
5.4.1 编写dsl配置
为了让任务模型的构建更加灵活,目前 FATE 使用了一套自定的领域特定语言 (DSL) 来描述任务。在 DSL 中,各种模块(例如数据读写 data_io,特征工程 feature-engineering, 回归 regression,分类 classification)可以通向一个有向无环图 (DAG) 组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
为了尝试多一点的组件,我们的实践将涵盖训练以及评估模型。
(1)建模数据流定义
使用dataio组件,基于上一步上传好的数据定义建模数据输入/输出。这个例子里面定义了两个dataio,分别输出训练数据以及评估数据。
(2)训练输入输出定义
将dataio_0的输出对象作为训练的输入数据对象,输出横向联邦学习逻辑回归训练模型以及训练数据。
同理对评估数据进行训练定义,将dataio_1的输出对象以及homo_lr0的训练模型作为评估的输入数据对象,输出横向联邦学习逻辑回归训练模型以及评估数据。
(3)评估输入输出定义
对评估数据集基于homo_lr_0输出的模型进行训练并且输出预测结果以及模型。
5.4.2 编写运行配置
运行配置主要是用于指定guest、host、arbiter运行dsl任务相关配置,具体查看https://github.com/FederatedAI/FATE/doc/dsl_conf_setting_guide_zh.md
(1)定义建模角色以及运行模式
(2)定义角色参数
主要包括data数据结构定义以及组件配置按照角色区份。
guest角色参数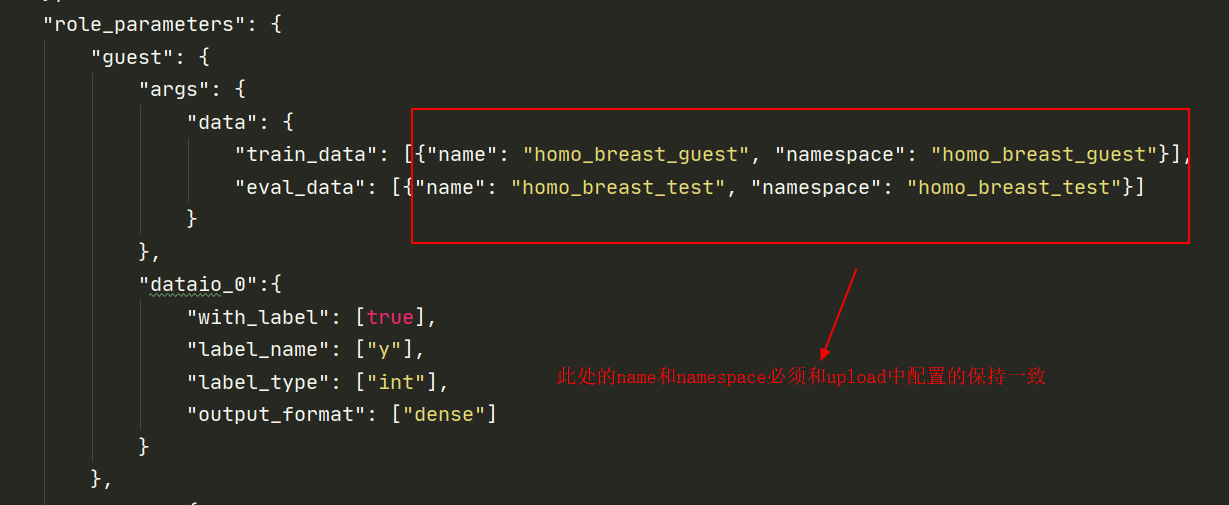
host角色参数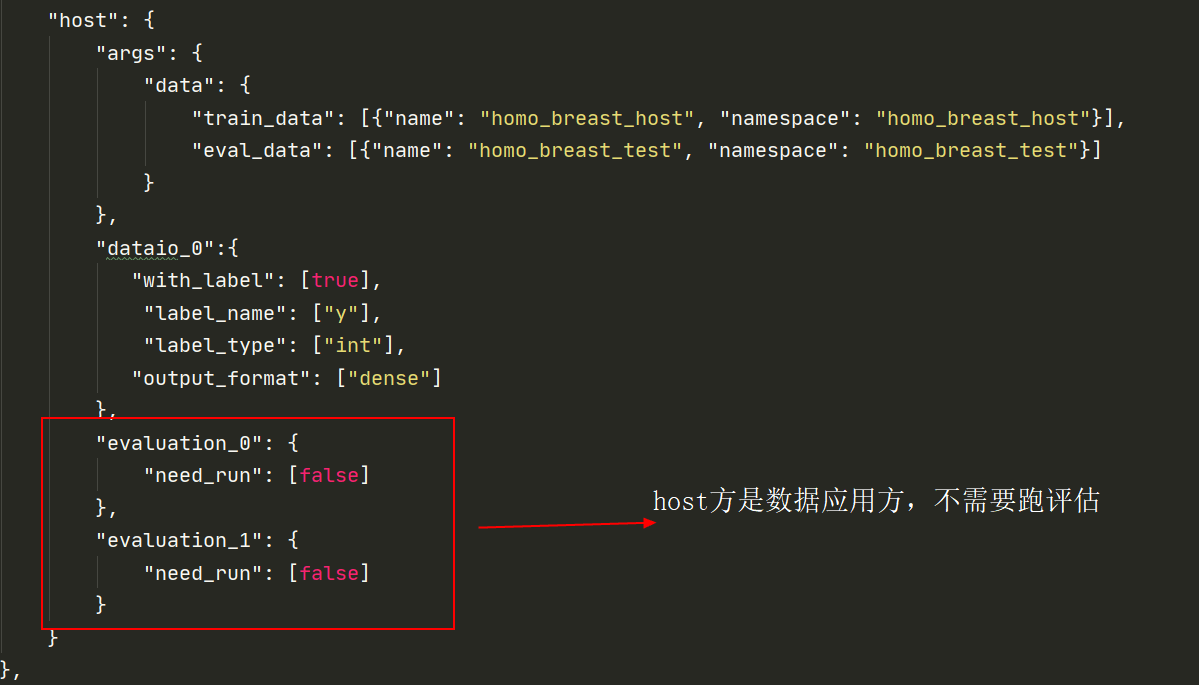
5.4.3 定义算法配置
具体查看算法参数https://github.com/FederatedAI/FATE/federatedml/param
5.5 开始训练评估任务
具体命令如下:
控制台输出命令:
控制台与监控面板显示如下信息
显示运行进度:
5.6 查看结果
通过监控面板查看job执行结果 ,通过job_id查询对应任务
可以看到建模的每个过程组成的DAG图
5.6.1 查看dataio_0执行结果
根据dsl定义的输出我们点击”view the outputs”查看结果如何
由于输出类型是data类型,可以在”data output”看到输入的数据列表项如上
点击”log”可以查看日志
5.6.2 查看dataio_1执行结果
5.6.3 查看分析训练结果
(1)homo_lr_0
homo_lr_0是分别在guest,host训练homo_breast_guest以及homo_breast_host得出最终模型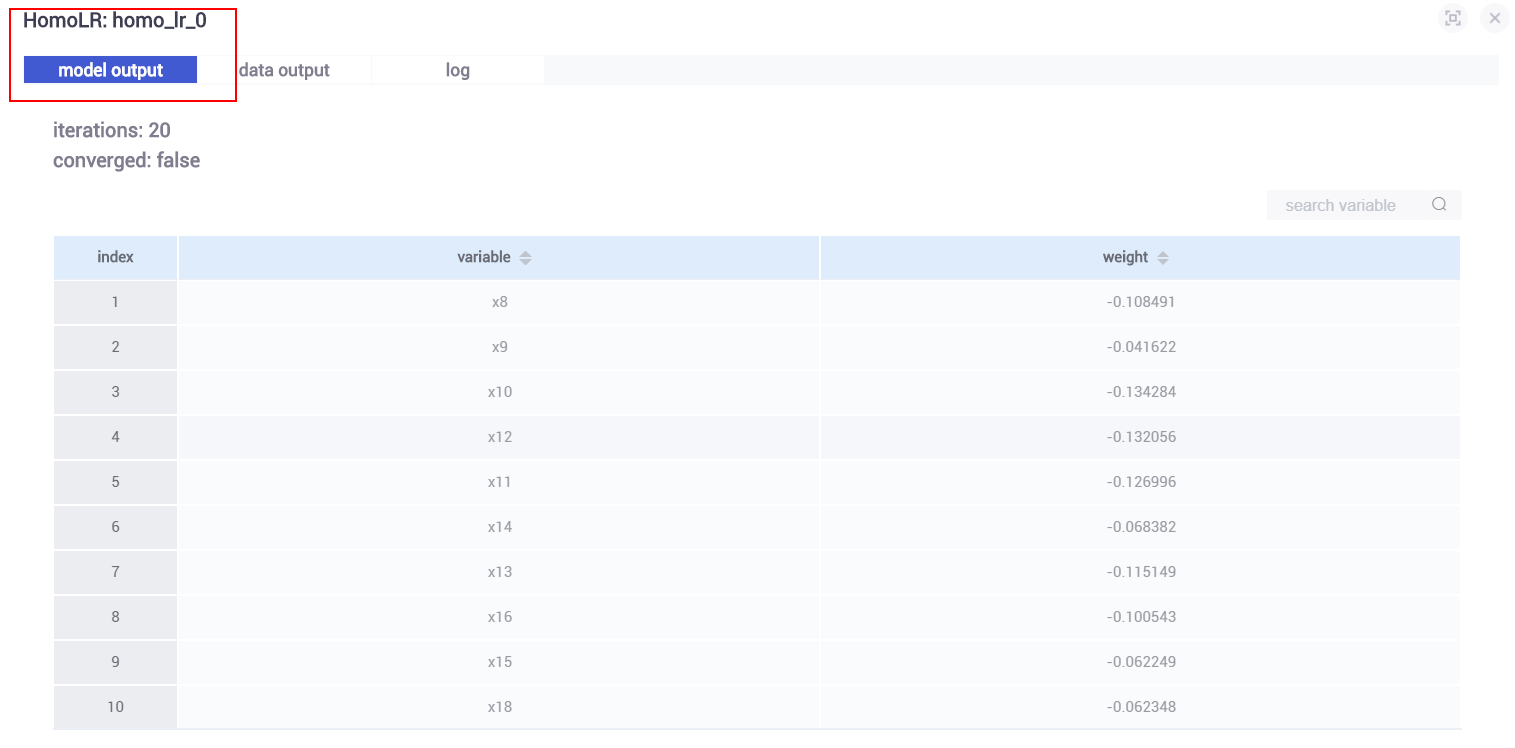
下面表格列出所有特征variable以及通过LR分类得出特征对应权值weight。下面还有一个曲线图,表示LR损失函数值随着迭代次数的变化。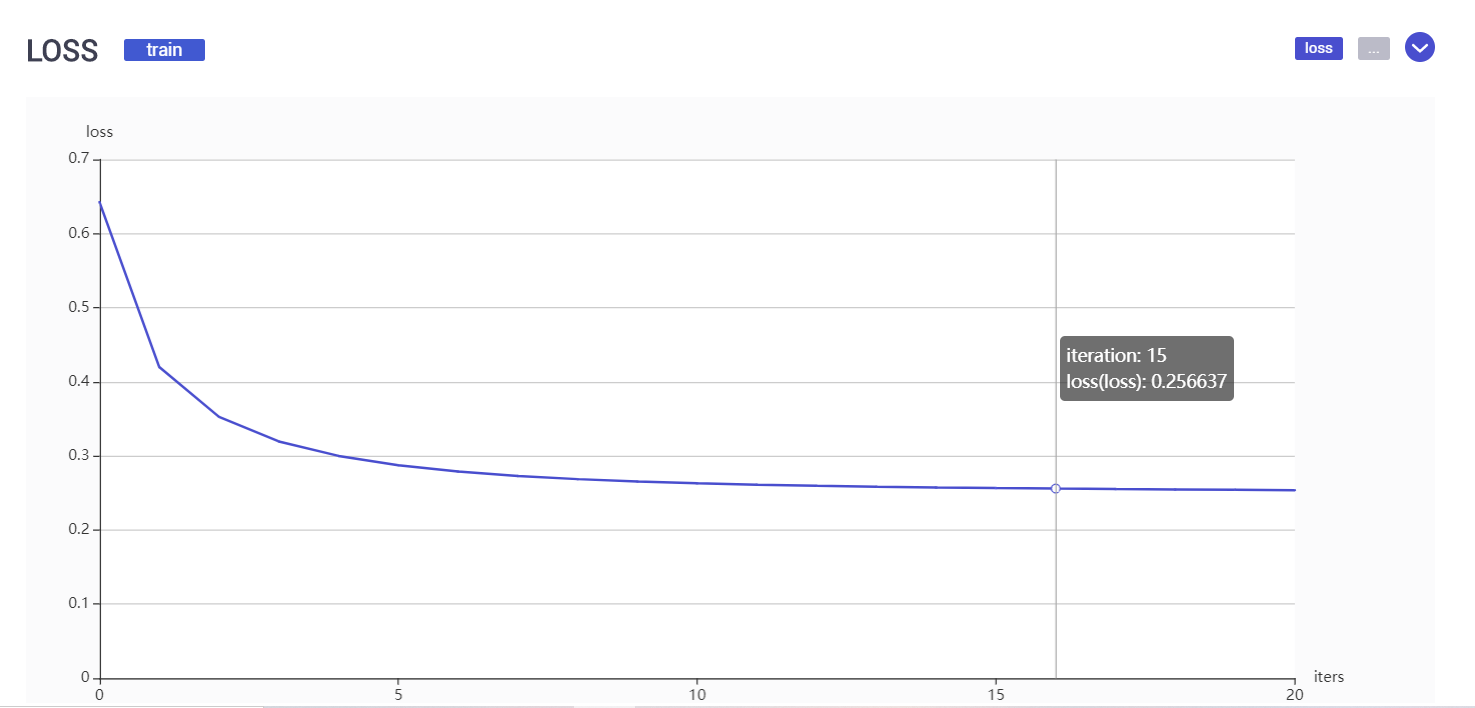
查看data output 训练结果如下: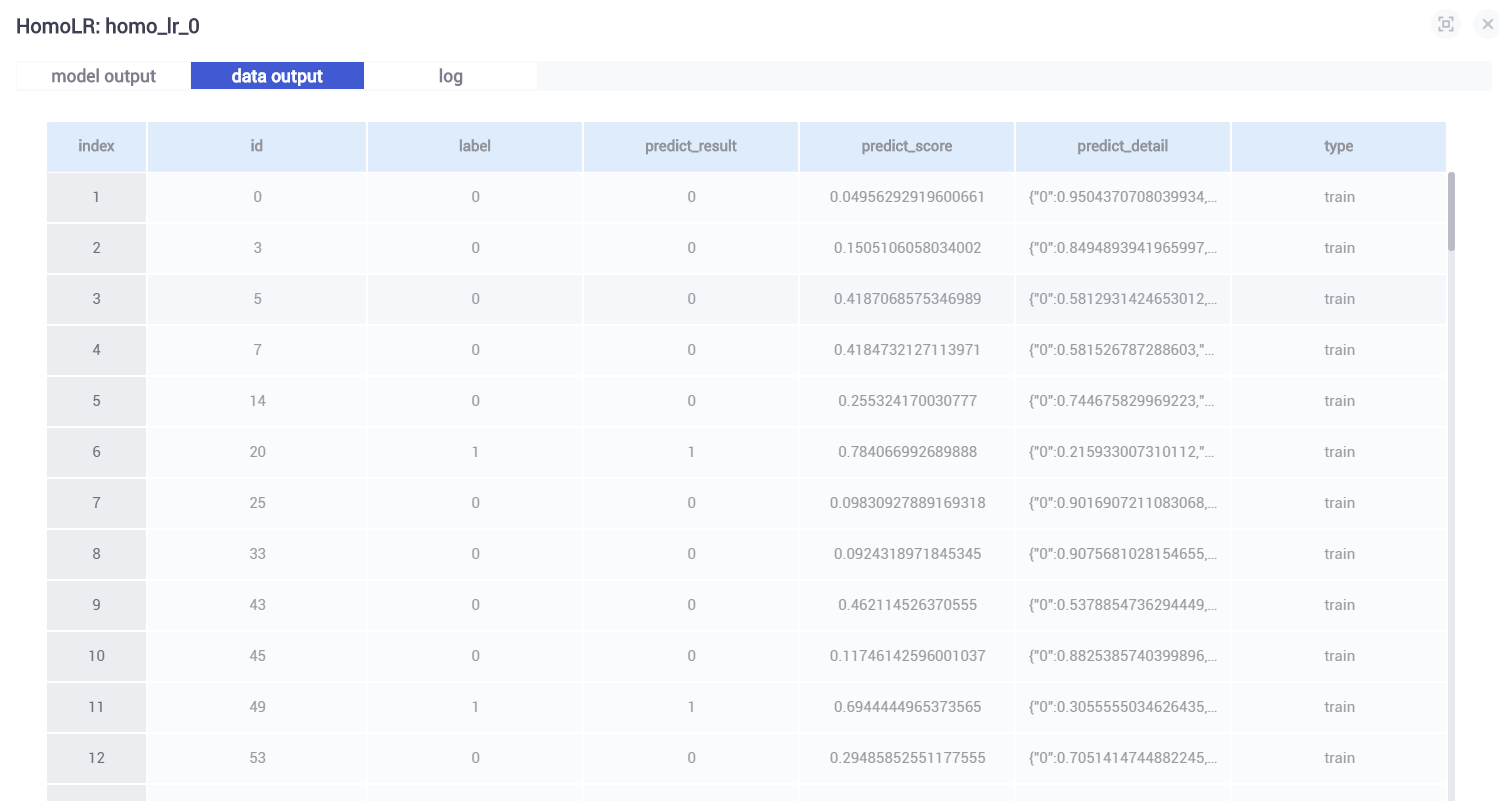
- id:id
- label: 标签值,真实结果
- predict_result: 预测结果
- predict_score: 预测得分
- predict_detail:预测结果的细节
(2)homo_lr_1
home_lr_1是基于homo_lr_0预测test数据集的结果。输出模型结果如下: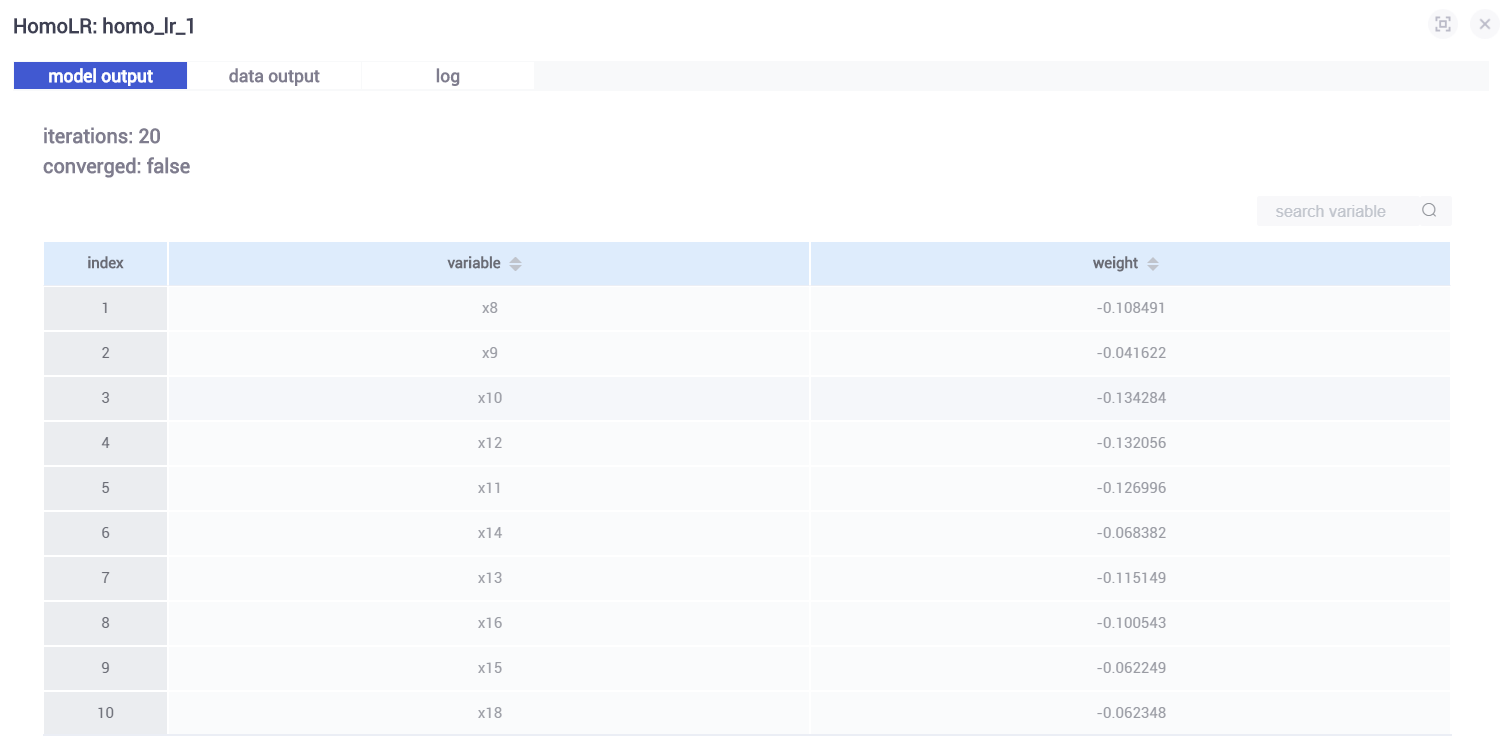
查看data output 训练结果如下: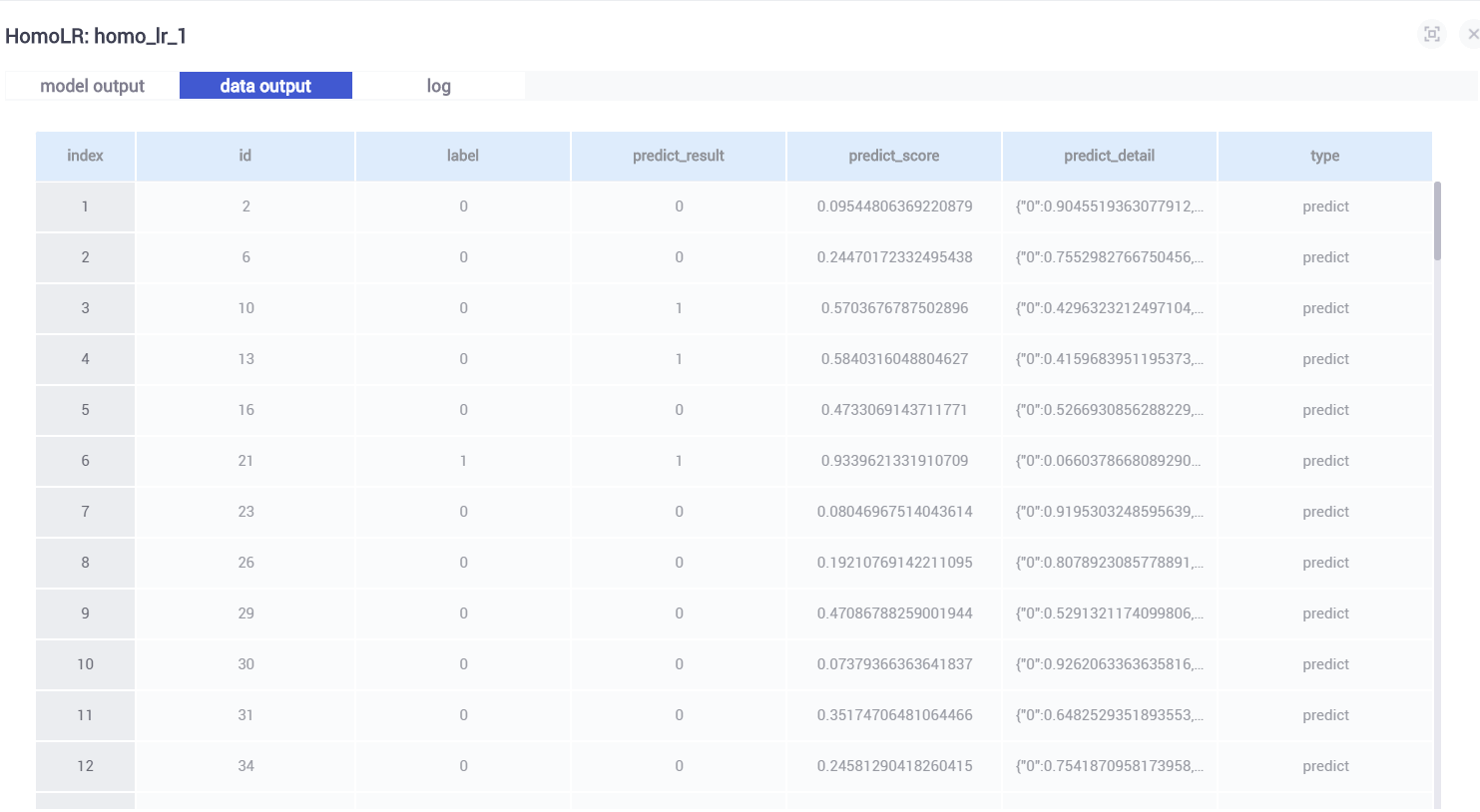
5.6.4 查看模型评估结果
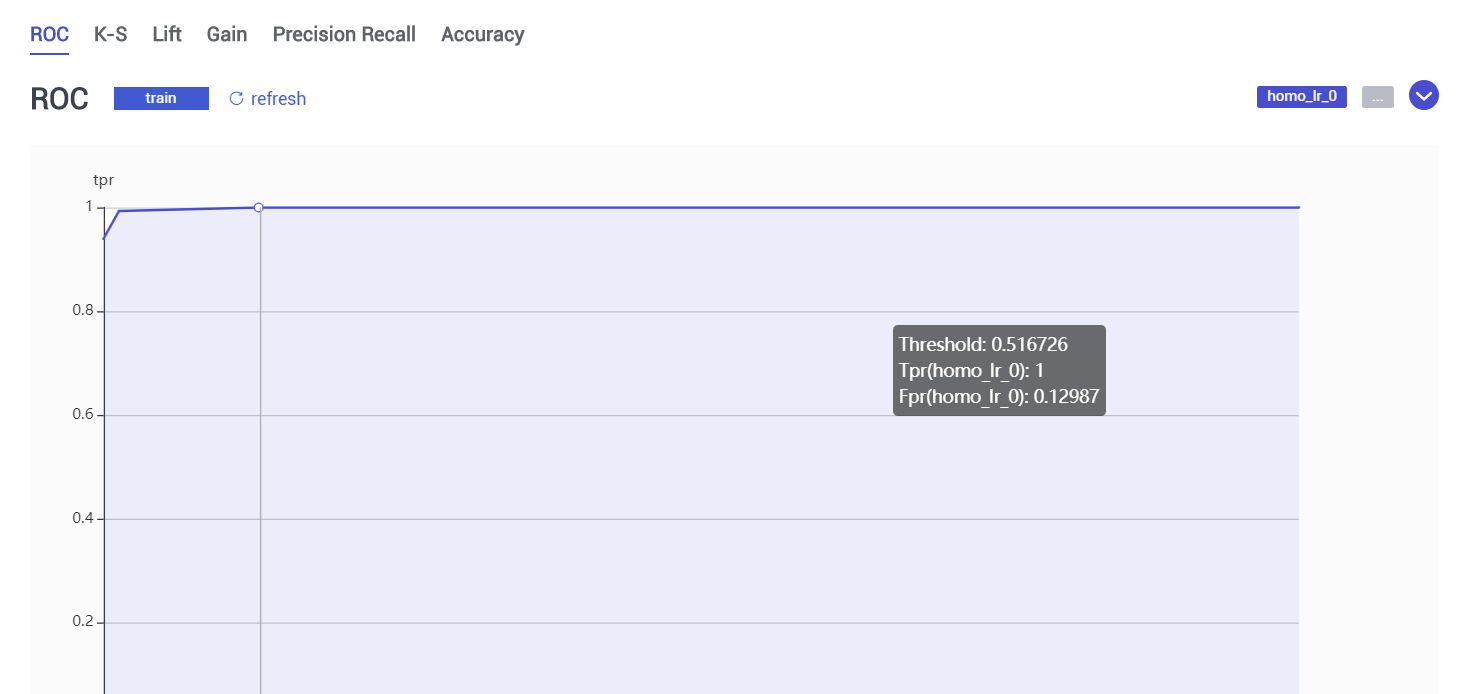
(1)homo_lr_0模型评估evalation_0 结果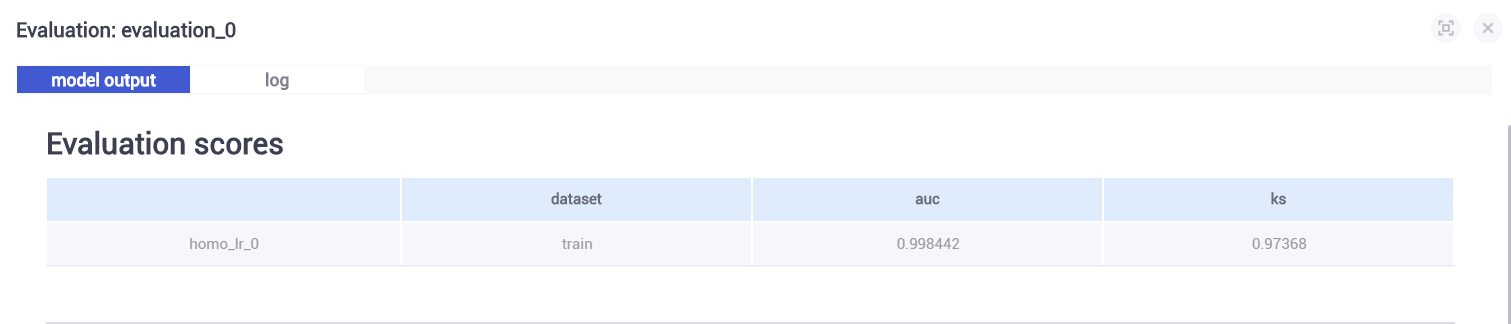
(2)homo_lr_1模型评估evalation_1 结果
homo_lr_1使用homo_lr_0训练的模型对test数据集进行预测,得出的结果如下图,相对evalation_0各部分指标略有下降。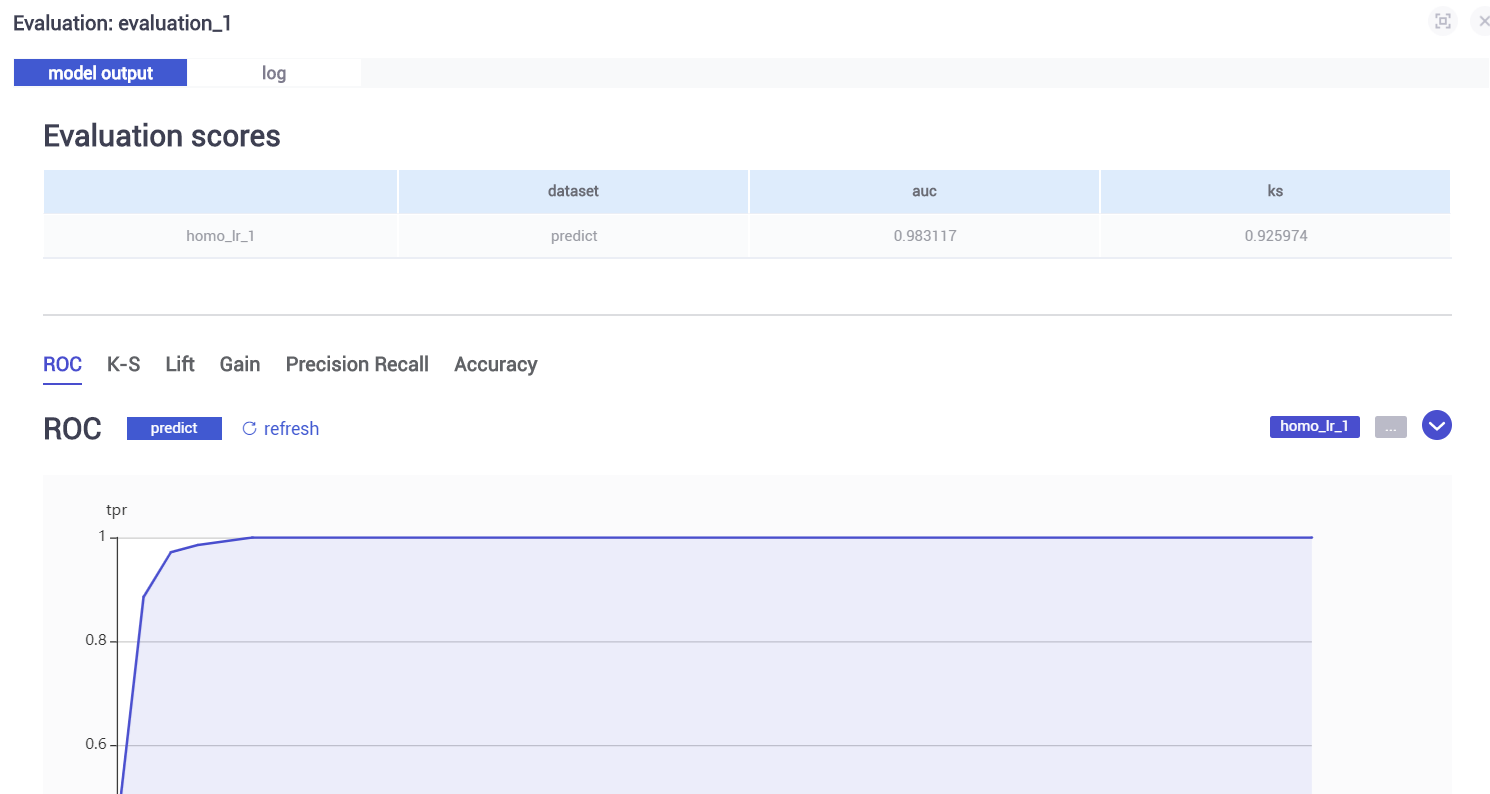
5.7 预测
上面通过训练得出模型home_lr_0,homo_lr_1,我们接下将基于此进行预测实践。
5.7.1 获取训练模型信息
因为后面需要用到model_id以及model_version,我们需要通过命令行的方式读取。具体命令模板如下: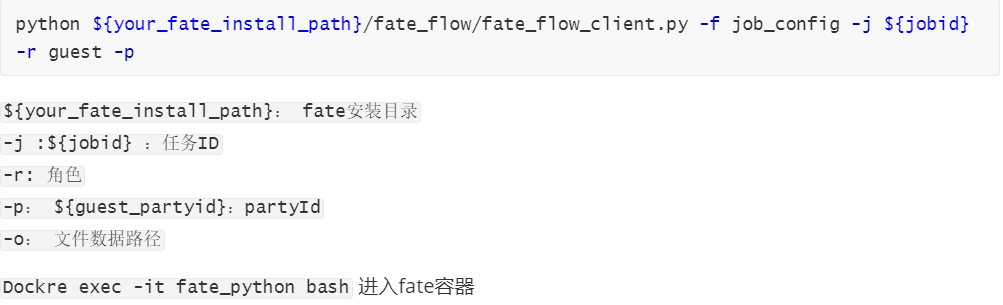
输入以下命令:
控制台输出相关信息如下: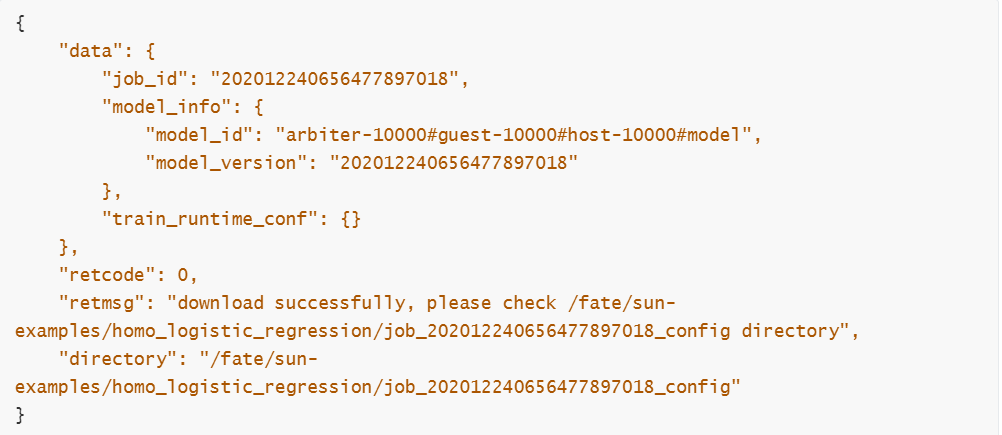
进入输出目录,可看到输出的文件

5.7.2 编写预测配置文件
使用文件sun-examples/homo_logistic_regression/sun_test_predict_conf.json

5.7.3 预测
预测的模板命令如下:
控制台输入以下命令:
输出以下结果表示成功: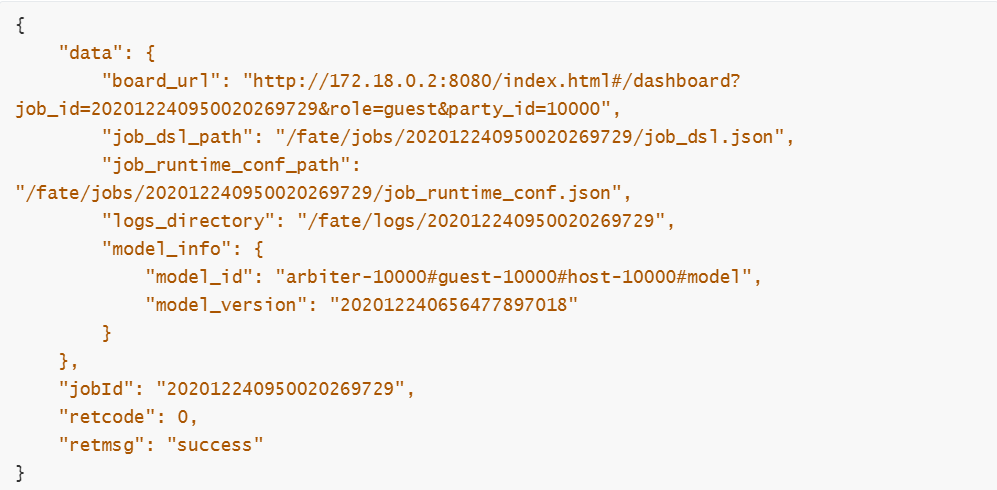
5.7.4 查看预测结果
通过监控平台以及job_id查看预测情况。总体情况如下:
点击”view the job” 查看具体情况。先看这个图,这个图我们无法得知各个组件之间的输入输出关系: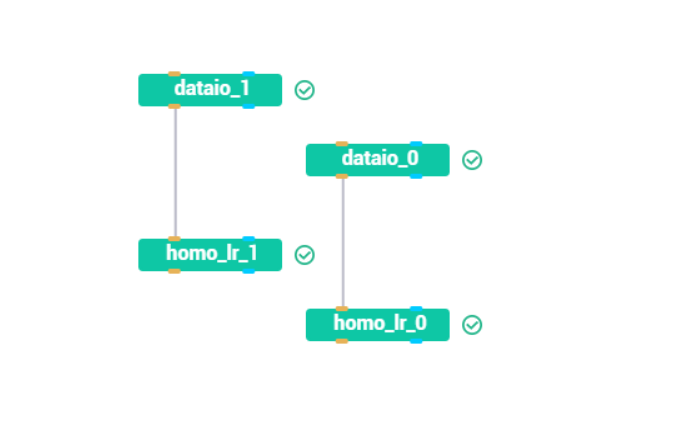
因此我们还是需要看他的dsl,继续5.7.1的查询命令
查看输出目录的dsl.json,找到对应配置如下(此处只展示部分):
查看data_output,对别label与predict_result: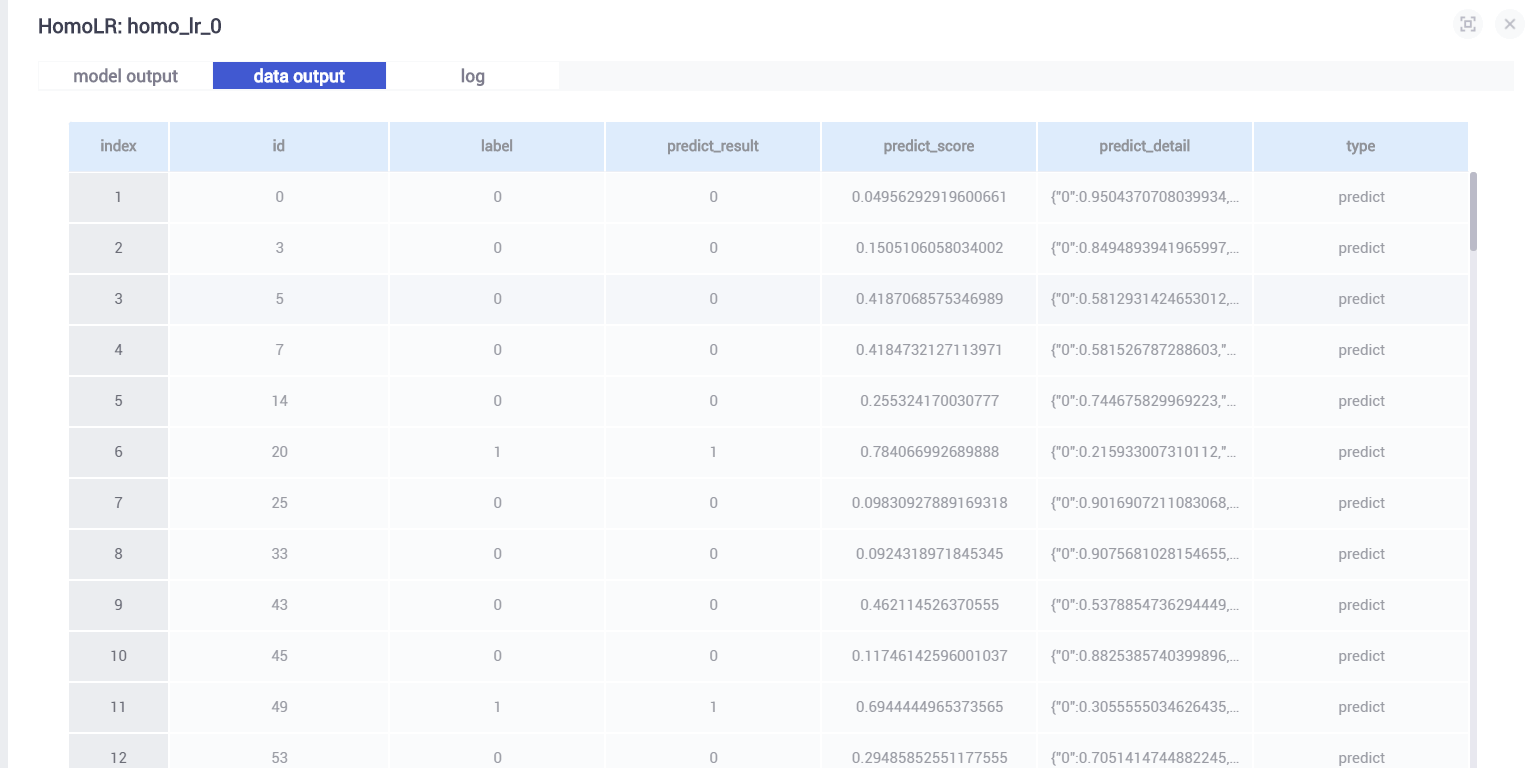
5.7.5 获取所有预测结果
Fate_board默认查看100条,我们想要获取全部数据可以通过命令行实现。模板命令如下: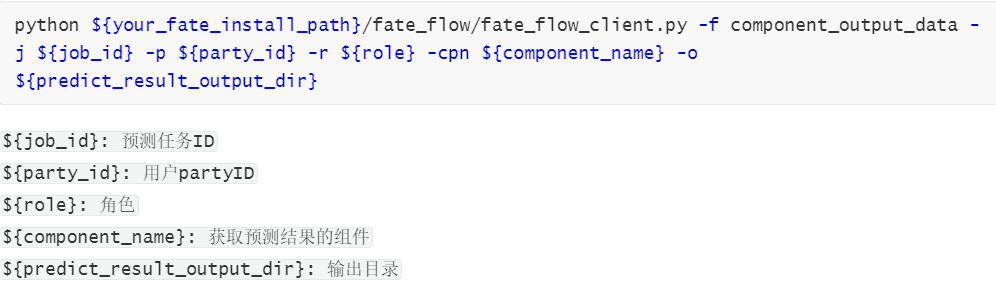
获取guest所有预测结果
控制台输入以下命令:
homo_lr_0预测结果:
homo_lr_1预测结果:
控制台输出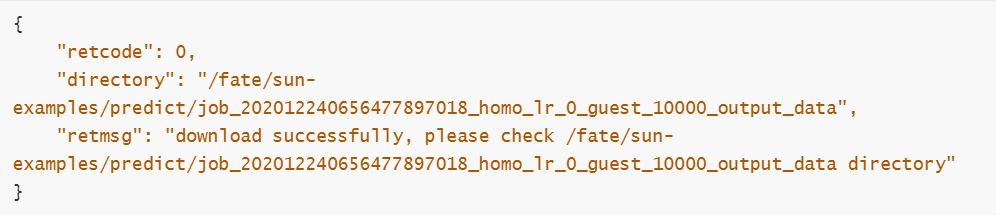
进入目录可以看到两个文件:
output_data.csv:输出csv的数据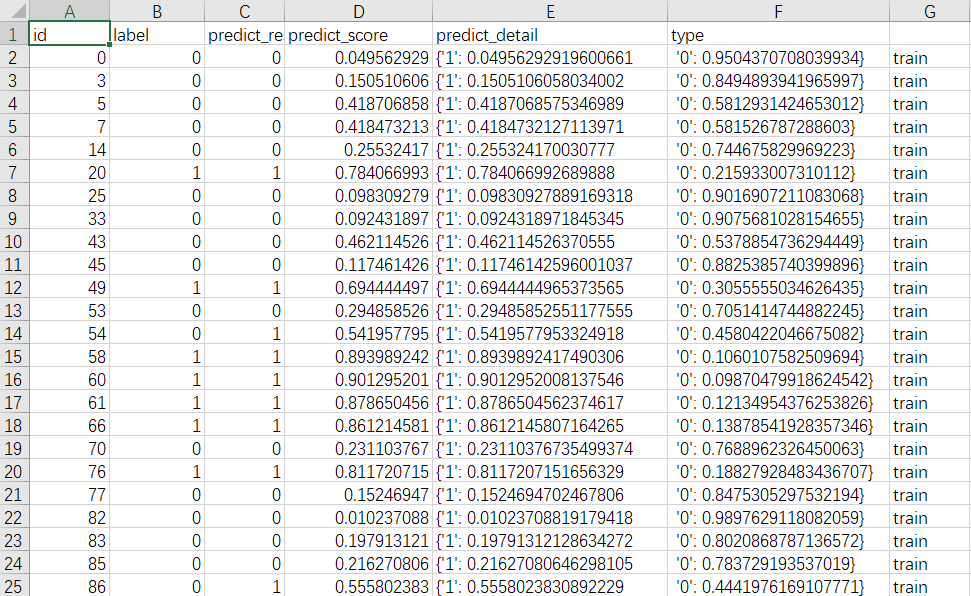
output_data_meta.json:输出数据的表头字段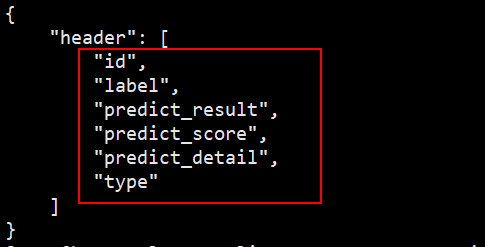
获取host所有预测结果
host的操作只需要修改role跟相对的partyid即可

若有收获,就点个赞吧
0 人点赞
