一、聚合函数
1.grouping sets 组合多个分组的结果(一次group by就能满足多种组合维度)——hive优化
grouping sets后面跟的组合可以不用全部组合了,可以根据个人需求组合
注:GROUPING SETS会把在单个GROUP BY逻辑中没有参与GROUP BY的那一列置为NULL值
看传统的group by 列1,列2 都是列1+列2的维度组合统计,不能得到列1的单独维度统计,也不能得到列2的单独维度统计
select color,axle_cnt,status,count(distinct uid) from tmp.test_0130
where color in (‘0’,’1’) and axle_cnt in (‘2’,’6’)
group by color,axle_cnt,status
select color,count(distinct uid) from tmp.test_0130
where color in (‘0’,’1’) and axle_cnt in (‘2’,’6’)
group by color
grouping sets 可以组合多个分组的结果,因为group by 的维度是单一的,他只能计算某个维度信息,而不能计算多个维度,在grouping sets查询中可以根据不同的单维度组合进行聚合,等价于将不同维度的group by结果进行union all
select color,axle_cnt,status,count(distinct uid) from tmp.test_0130
where color in (‘0’,’1’) and axle_cnt in (‘2’,’6’)
group by color,axle_cnt,status
grouping sets
(
(color),
(color,axle_cnt),
(color,status)
)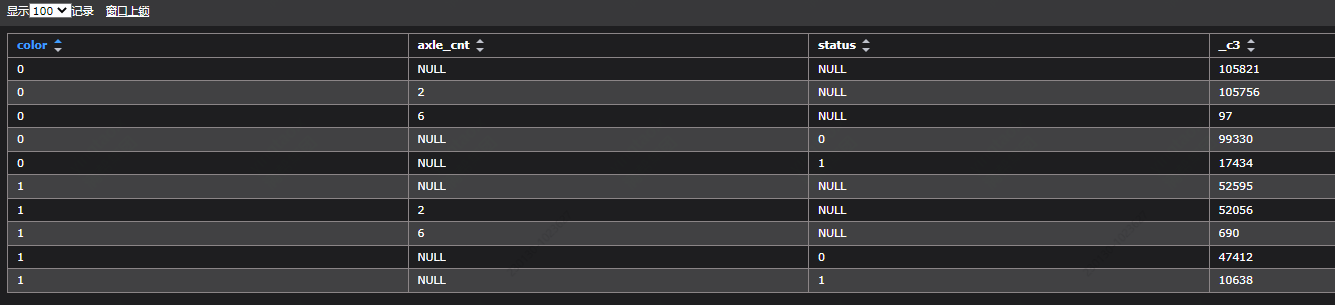
为什么说是group by结果的union all
(color) group by有2种结果
(color,axle_cnt) group by有4种结果
(color,status) group by有4种结果
都加起来正好10种 !
grouping sets不需要把所有的列名进行组合,把需要的进行组合就可以了;
(color),
(color,axle_cnt),
(color,status)
这里加了三种情况,分别表示的是颜色维度,颜色+车轴维度,颜色+状态维度
写的时候先考虑清楚,是需要将哪几种维度的放在一起。
SELECT month, day,COUNT(DISTINCT cookieid) AS uv,GROUPING__IDFROM cookie5GROUP BY month,dayGROUPING SETS (month,day,(month,day))ORDER BY GROUPING__ID;-- 等价于SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__IDFROM cookie5 GROUP BY monthUNION ALLSELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__IDFROM cookie5 GROUP BY dayUNION ALLSELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__IDFROM cookie5 GROUP BY month,day
2.cube 汇总和交叉
CUBE的工作方式:先全部汇总,然后再分类按从从右到左一次去掉最后一个字段,常用于做交叉表
select color,count(distinct uid) from tmp.test_0130
where color in (‘0’,’1’) and axle_cnt in (2,6)
group by color
with cube
select color,count(distinct uid),avg(guaranty) from tmp.test_0130
where color in (‘0’,’1’) and axle_cnt in (2,6)
group by color
with cube
select color,axle_cnt,count(distinct uid),avg(guaranty) from tmp.test_0130
where color in (‘0’,’1’) and axle_cnt in (2,6)
group by color,axle_cnt
with cube
新增了5种
SELECT month, day,COUNT(DISTINCT cookieid) AS uv,GROUPING__IDFROM cookie5GROUP BY month,dayWITH CUBEORDER BY GROUPING__ID;--等价于SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__IDFROM cookie5UNION ALLSELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__IDFROM cookie5 GROUP BY monthUNION ALLSELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__IDFROM cookie5 GROUP BY dayUNION ALLSELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__IDFROM cookie5 GROUP BY month,day
3.rollup 汇总和交叉(会少一种组合方式)
rollup 的工作方式:在完成了基本额数据汇总后,按照从右到左的顺序,每次去掉字段列表中的最后一个字段,再对剩余的字段进行分组统计,并将获得的小计结果插入返回表中,别去掉的字段位置使用null 填充,最后,再对全部进行一次统计,所以字段位置均使用null 填充。(sql 和oracle 均可使用)
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__IDFROM cookie5GROUP BY month,day WITH ROLLUP ORDER BY GROUPING__ID;--等价于SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__IDFROM cookie5 GROUP BY month,dayUNION ALLSELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__IDFROM cookie5 GROUP BY monthUNION ALLSELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__IDFROM cookie5
二、子查询
1.wiht as 子查询部分
定义一个SQL片断后,该SQL片断可以被整个SQL语句所用到。有的时候,with as是为了提高SQL语句的可读性,减少嵌套冗余
标准的数据库中,如hive,Oracle,DB2,SQL SERVER,PostgreSQL都是支持WITH AS 语句进行递归查询。只有MySQL是不支持的
- 使用子查询嵌套查询
- select*
- from emp
- where salary > (
- select salary
- from emp
- where id =2
2.with as的优点
增加了sql的易读性,如果构造了多个子查询,结构会更清晰;
更重要的是:“一次分析,多次使用”,这也是为什么会提供性能的地方,达到了“少读”的目标
“一次分析,多次使用”,这也是为什么会提供性能的地方,达到了“少读”的目标
with as ( select from user ) A select from student customer where customer.userid = a.user.id
这个sql语句的意思是:先执行select * from user把结果放到一个临时表A中,作为全局使用。
with as的用法可以通俗点讲是,讲需要频繁执行的slq片段加个别名放到全局中,后面直接调用就可以,这样减少调用次数,优化执行效率。
三、联接查询
SQL 支持的连接查询包括内连接、外连接、交叉连接、自然连接以及自连接等。其中,外连接又可以分为左外连接、右外连接以及全外连接。
1.内连接
内连接(Inner Join)返回两个表中满足连接条件的数据;使用关键字 INNER JOIN 表示,也可以简写成 JOIN。内连接的原理如下图所示(基于两个表的 id 进行等值连接):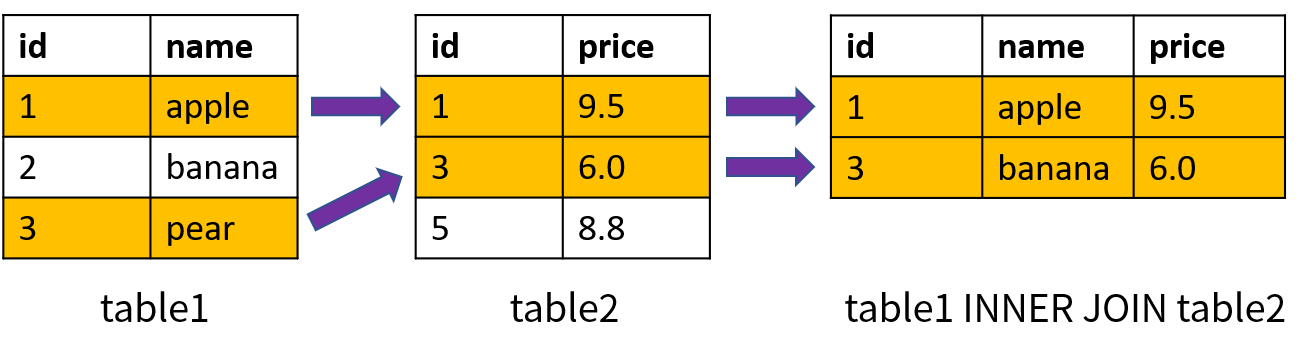
其中,id = 1 和 id = 3 是两个表中匹配的数据,因此内连接返回了这 2 行记录。上一节已经给出了内连接的示例,不再重复。
2.左外连接
左外连接(Left Outer Join)首先返回左表中所有的数据;对于右表,返回满足连接条件的数据;如果没有相应的数据就返回空值。左外连接使用关键字 LEFT OUTER JOIN 表示,也可以简写成 LEFT JOIN。左外连接的原理如下图所示(基于两个表的 id 进行连接):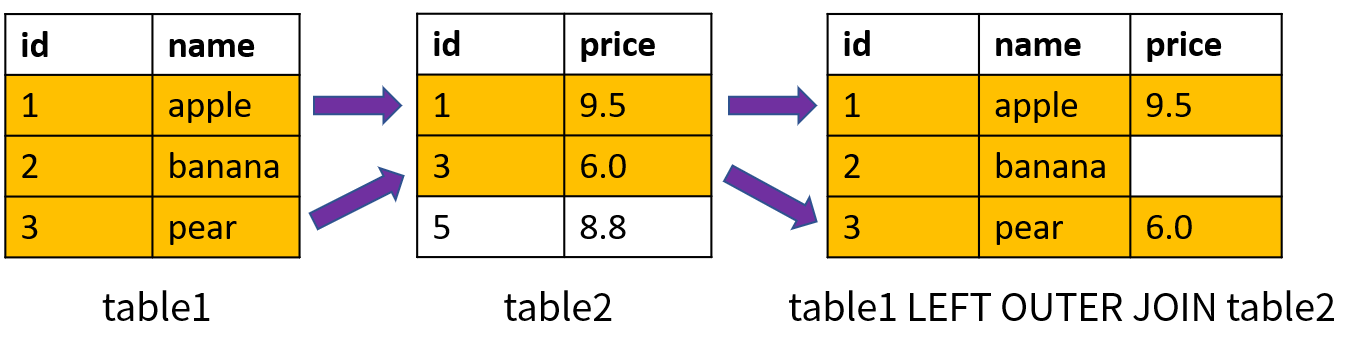
其中,id = 2 的数据在 table1 中存在,在 table2 中不存在;左外连接仍然会返回左表中的该记录,而对于 table2 中的价格(price),返回的是空值。
cross join 实现两个表联接
3.右外连接
右外连接(Right Outer Join)首先返回右表中所有的数据;对于左表,返回满足连接条件的数据,如果没有相应的数据就返回空值。右外连接使用关键字 RIGHT OUTER JOIN 表示,也可以简写成 RIGHT JOIN。右外连接的原理如下图所示(基于两个表的 id 进行连接):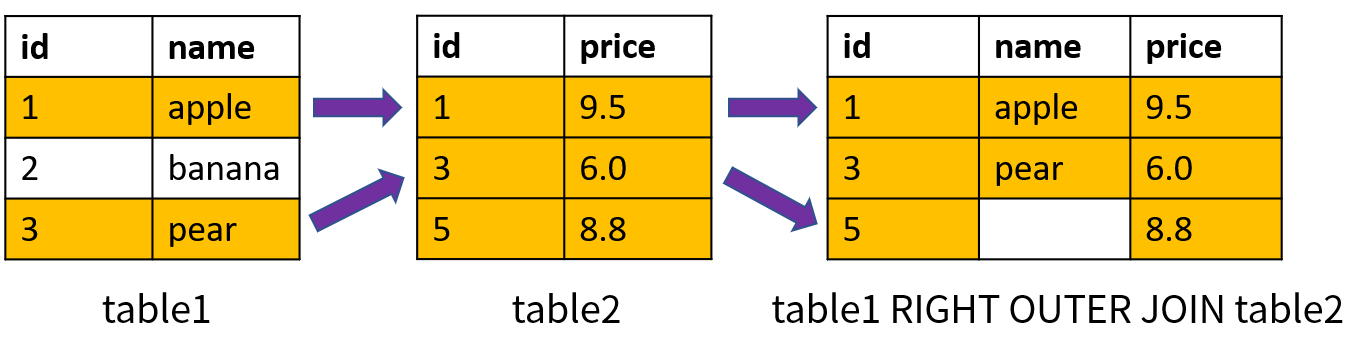
其中,id = 5 的数据在 table2 中存在,在 table1 中不存在;右外连接仍然会返回右表中的该记录,而对于 table1 中的名称(name),返回的是空值。
4.全外连接
全外连接(Full Outer Join)等价于左外连接加上右外连接,同时返回左表和右表中所有的数据;对于两个表中不满足连接条件的数据返回空值。全外连接使用关键字 FULL OUTER JOIN 表示,也可以简写成 FULL JOIN 。全外连接的原理如下图所示(基于两个表的 id 进行连接):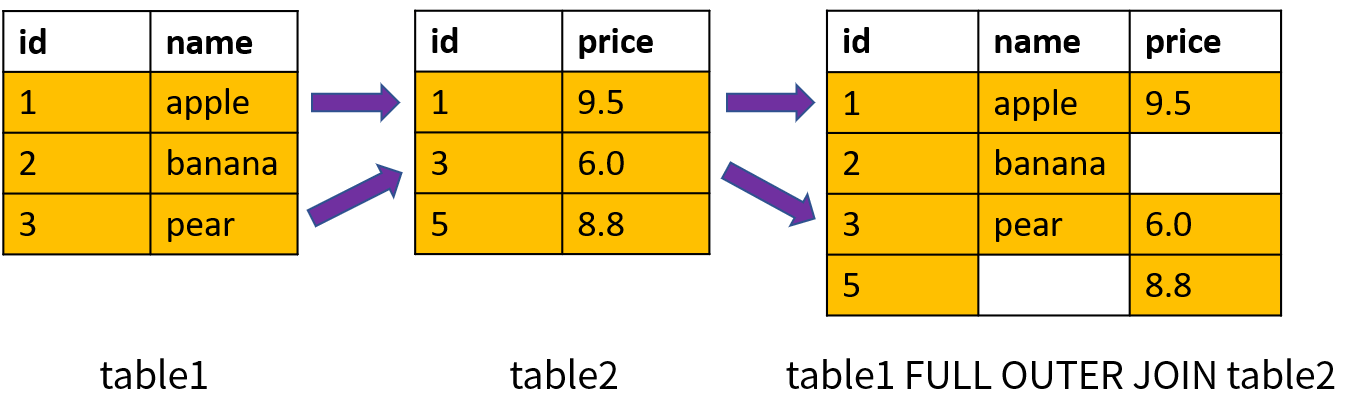
结果中包含了所有的 id,然后对于两个表中不满足连接条件的数据(id = 2 和 id = 5),分别在相应的字段中返回了空值。
5.交叉连接
交叉连接也称为笛卡尔积(Cartesian Product),使用关键字 CROSS JOIN 表示。两个表的交叉连接相当于一个表的所有行和另一个表的所有行两两组合,结果的数量为两个表的行数相乘。如果第一个表有 1000 行,第二个表有 2000 行,它们的交叉连接将会产生 2000000 行数据。
交叉连接可能会导致查询结果的数量急剧增长,从而引起性能问题;通常应该使用连接条件进行过滤,避免产生交叉连接。
交叉连接的原理如下图所示(基于两个表的 id 进行连接):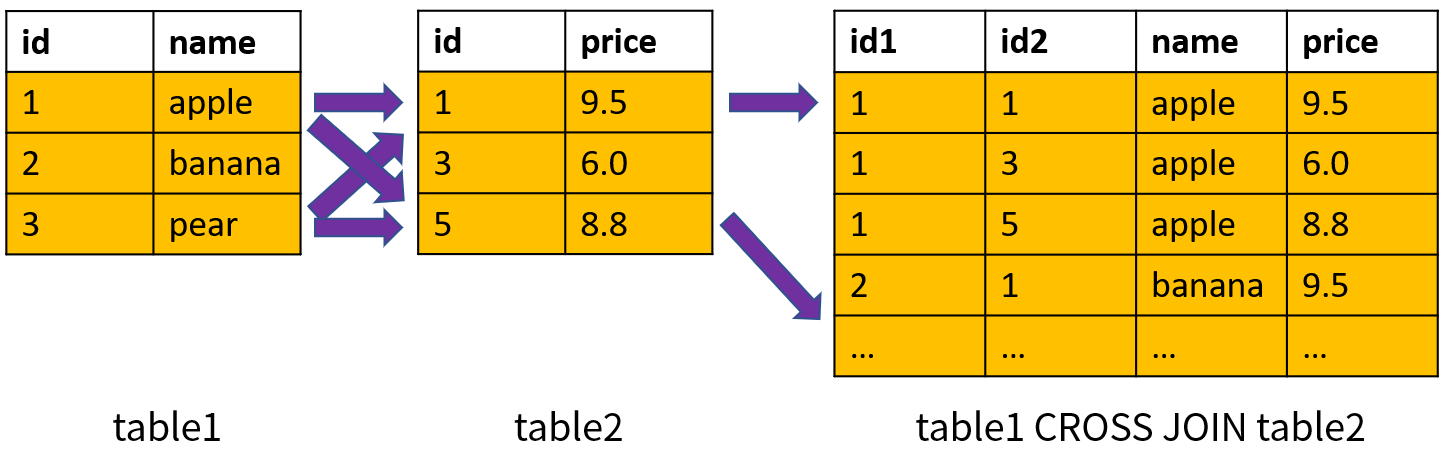
结果总共包含 9 条记录。交叉连接一般使用较少。对于 ANSI SQL/86 标准的语法,交叉连接就是不指定表的连接条件。
除了上面介绍的几种连接类型,SQL 中还存在一些特殊形式的连接查询。
6.自然连接
对于连接查询,如果满足以下条件,可以使用 USING 替代 ON 简化连接条件的输入:
- 连接条件是等值连接;
- 两个表中的连接字段必须名称相同,类型也相同。
针对上文中的内连接查询示例,可以使用 USING 简化如下:
— Oracle、MySQL 以及 PostgreSQL 实现 SELECT dept_id, d.dept_name, e.emp_name FROM employee e JOIN department d USING (dept_id);
其中,USING 表示使用两个表中的公共字段(dept_id)进行等值连接。查询语句中的公共字段不需要添加表名限定。该语句的结果与上文中的内连接查询示例相同。
四、窗口函数
--< 窗口函数 > OVER ([ PARTITION BY < 列清单 >] ORDER BY < 排序用列清单 >)--OVER 子句中的 ORDER BY 只是用来决定 窗口函数按照什么样的顺序进行计算的--窗口函数是对 WHERE 子句或者 GROUP BY 子句处理后的“结果”进行的操作,因此只在select中--能够在窗口函数中使用的函数--1. 聚合函数SUM、AVG、MAX、MIN、COUNT--2. RANK、DENSE_RANK、ROW_NUMBER等专用窗口函数--3. ASC正序、DESC降序--RANK 和 DENSE_RANK及ROW_NUMBER 区别:RANK(1,1,3 跳过相同排名的) DENSE_RANK(1,1,2不跳过相同排名的) ROW_NUMBER(1,2,3唯一连续位次)。--<窗口函数>的位置,可以放以下两种函数:-- 1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。-- 2) 聚合函数,如sum. avg, count, max, min等--特殊窗口函数用法--1.移动计算,可用来计算小计、累计、移动计算附近几组数据等--ROWS 2 PRECEDING 截止到之前两行 FOLLOWING就是之后SELECT rn,sum (rn) OVER (ORDER BY rn ROWS UNBOUNDED PRECEDING) --小计的使用from tmp.a1023578_0122_666;--2 ntile() 函数 分组切片函数ntile(10) over (partition by XX order by YY desc) --数据以XX维度十等分,按照YY降序排序,取1就是XX维度分组下YY降序排序前10%
—OVER 子句中的 ORDER BY 只是用来决定 窗口函数按照什么样的顺序进行计算的
select , rank() over (partition by 班级 order by 成绩 desc) as ranking from 班级表
*ranking 就是新的列名,由rank()函数生成
— 对其排序累计求和、排序给出排名、
我们来解释下这个sql语句里的select子句。rank是排序的函数。要求是“每个班级内按成绩排名”,这句话可以分为两部分:
1)每个班级内:按班级分组
partition by用来对表分组。在这个例子中,所以我们指定了按“班级”分组(partition by 班级)
2)按成绩排名
order by子句的功能是对分组后的结果进行排序,默认是按照升序(asc)排列。在本例中(order by 成绩 desc)是按成绩这一列排序,加了desc关键词表示降序排列。
select ,
sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min
from 班级表
*partition子句可是省略,省略就是不指定分组,这样就得到一列数据累计求和、累计平均、累计判断最大…
五、其他
1.计算字符串中出现某个的次数
select ( length(‘apple’)-length(replace(‘apple’,’p’,’’)) ) from tmp.test_0130 —HIVE SQL (函数len)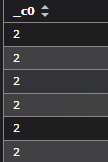
2.大小写转换
select upper(‘apple’),lower(‘AppLE’) from tmp.test_0130 —upper转换为大写,lower转换为小写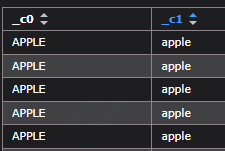
select card_type,lower(card_type) from tmp.test_0130
select card_type,lower(card_type) from tmp.test_0130 group by card_type —还可以group by

若有收获,就点个赞吧
0 人点赞
