- 1、[CV] Barlow Twins: Self-Supervised Learning via Redundancy Reduction
- 2、[CV] Generating Images with Sparse Representations
- 3、[LG] Measuring Mathematical Problem Solving With the MATH Dataset
- 4、[CL] There Once Was a Really Bad Poet, It Was Automated but You Didn’t Know It
- 5、[CV] FisheyeSuperPoint: Keypoint Detection and Description Network for Fisheye Images
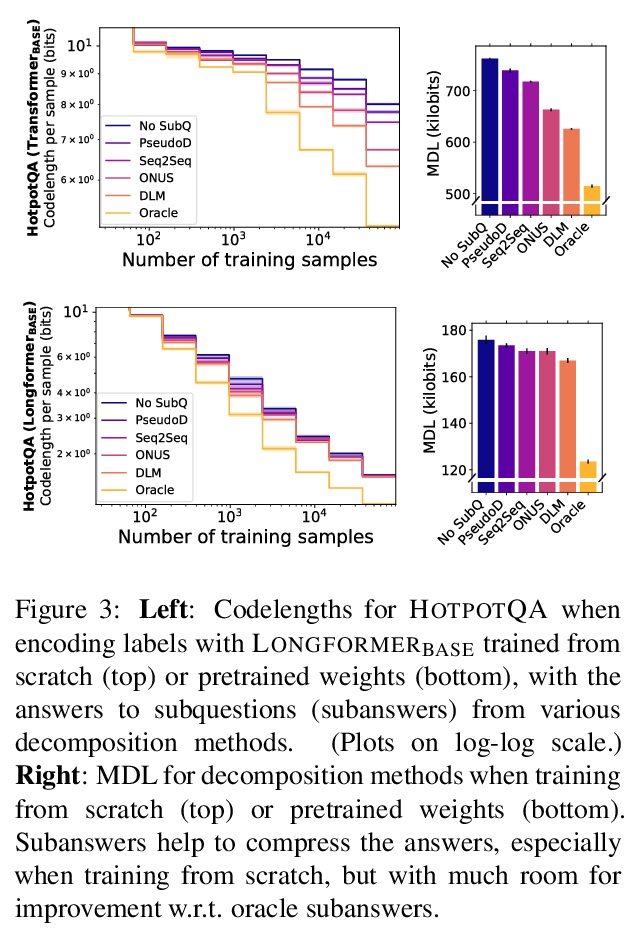
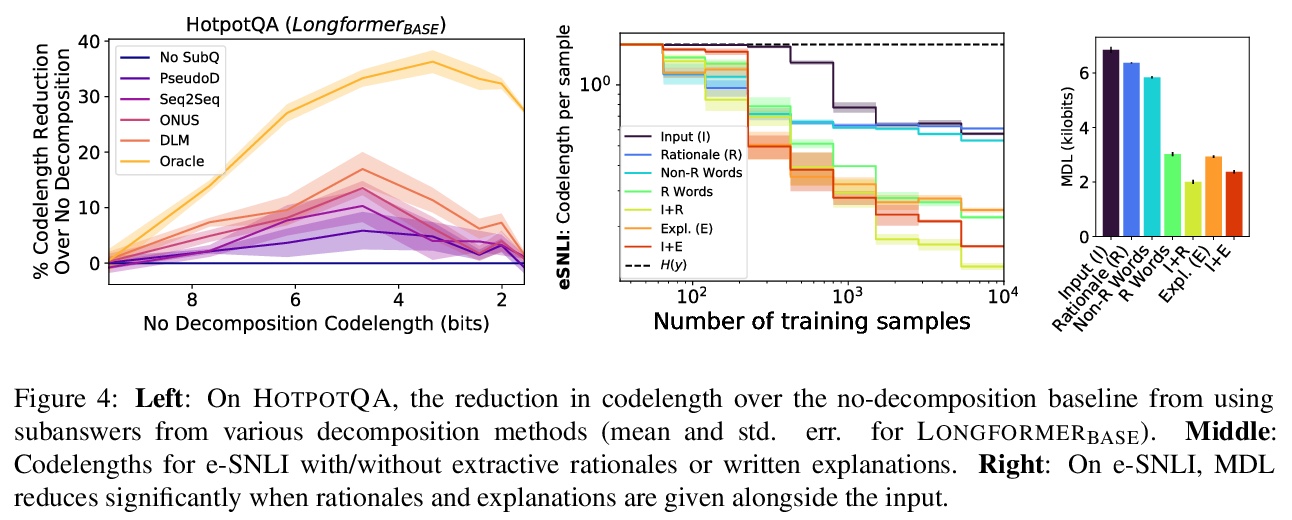
- [LG] Rissanen Data Analysis: Examining Dataset Characteristics via Description Length
- [CV] Coordinate Attention for Efficient Mobile Network Design
- [CL] IOT: Instance-wise Layer Reordering for Transformer Structures
- [LG] Golem: An algorithm for robust experiment and process optimization
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Barlow Twins: Self-Supervised Learning via Redundancy Reduction
J Zbontar, L Jing, I Misra, Y LeCun, S Deny
[Facebook AI Research]
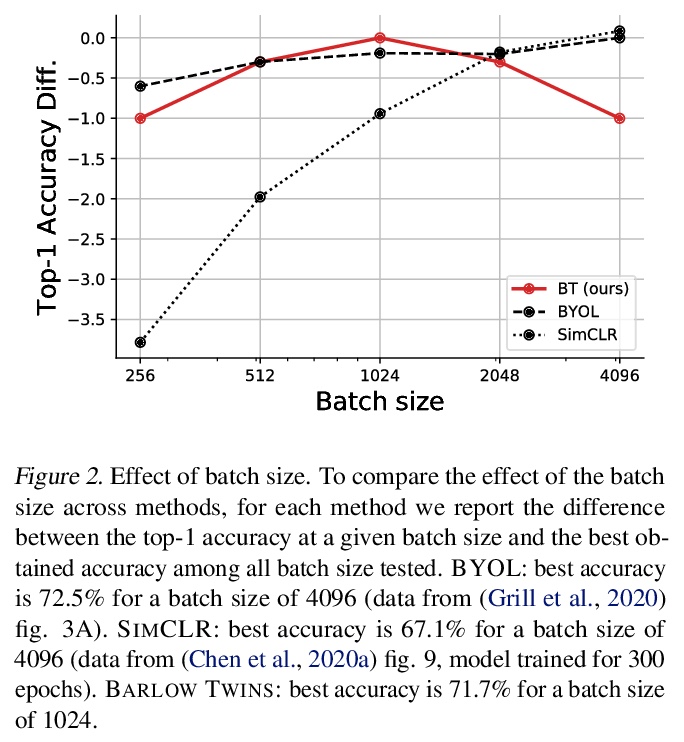
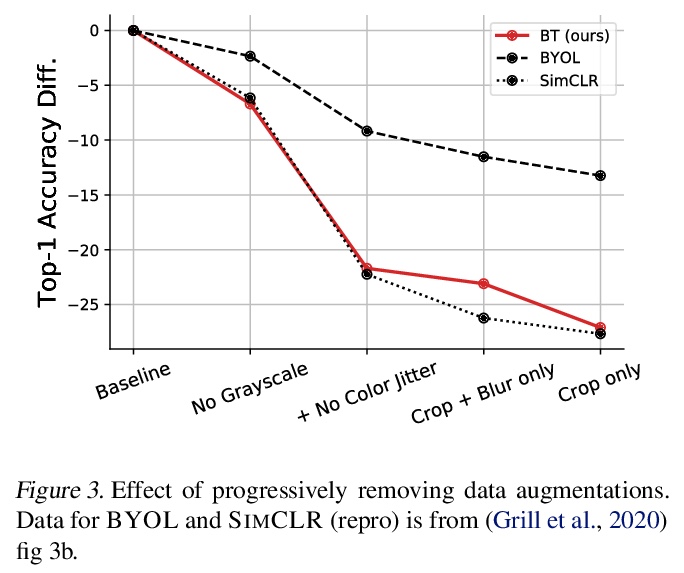
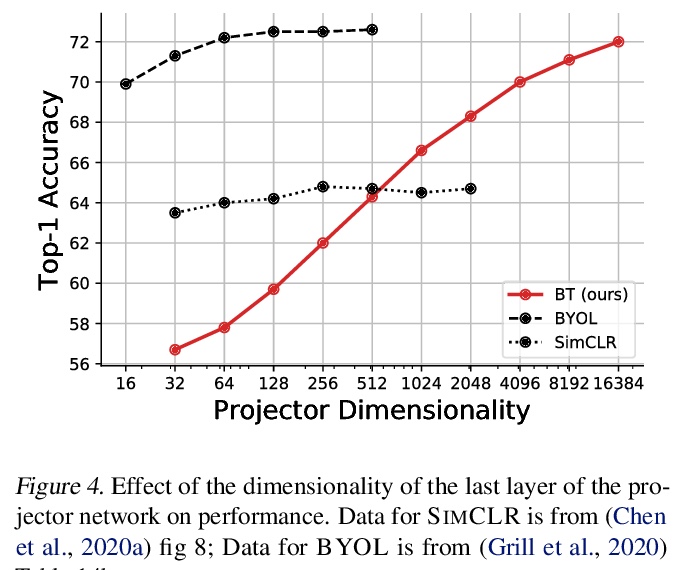
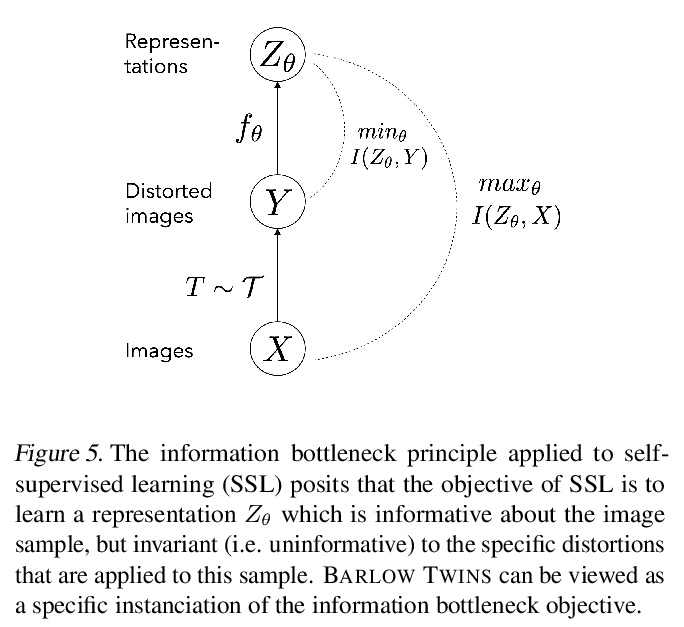
Barlow Twins: 冗余缩减自监督学习。提出一种目标函数,通过测量给定失真样本的两个恒等网络输出间的互相关矩阵,使其尽可能地接近单位矩阵,来自然地避免坍缩。这使得失真样本的表示向量是相似的,同时使这些向量的成分间的冗余度最小化。这种方法称为BARLOW TWINS,不需要大批量,也不需要网络孪生间的不对称性,如预测网络、梯度停止或权重更新的移动平均,可使用非常高维的输出向量。BARLOW TWINS在低数据场景下,在ImageNet上的半监督分类方面优于以前的方法,在使用线性分类器头的ImageNet分类方面,以及分类和物体检测的迁移任务方面,与目前的技术水平相当。
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn representations which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant representations. Most current methods avoid such collapsed solutions by careful implementation details. We propose an objective function that naturally avoids such collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the representation vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called Barlow Twins, owing to neuroscientist H. Barlow’s redundancy-reduction principle applied to a pair of identical networks. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. It allows the use of very high-dimensional output vectors. Barlow Twins outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the art for ImageNet classification with a linear classifier head, and for transfer tasks of classification and object detection.
https://weibo.com/1402400261/K5kzpB8Lo
2、[CV] Generating Images with Sparse Representations
C Nash, J Menick, S Dieleman, P W. Battaglia
[DeepMind]
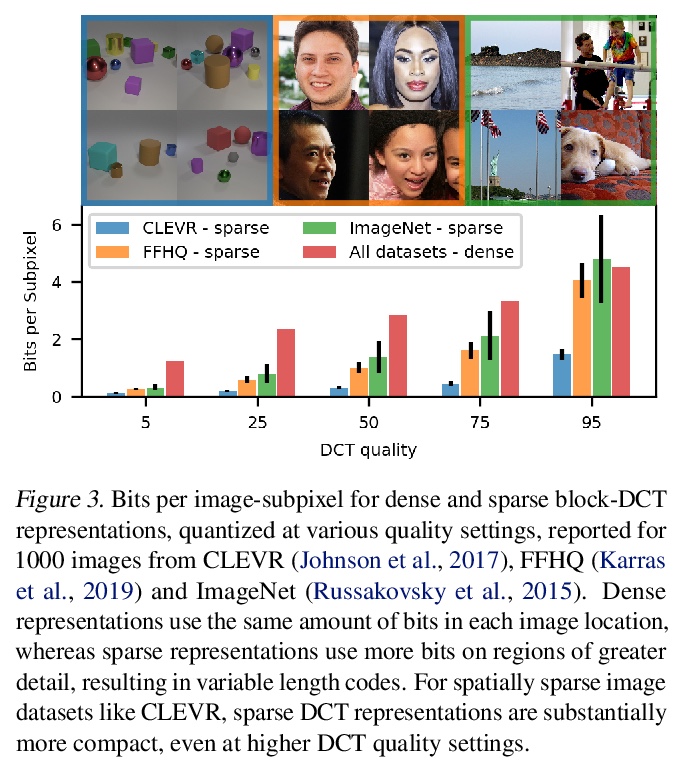
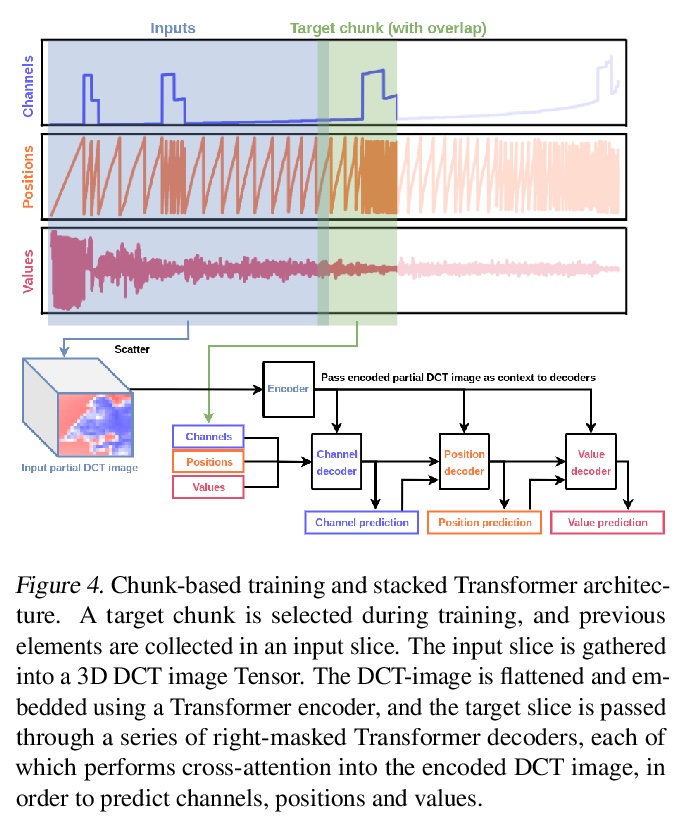
基于稀疏表示的图像生成。提出用基于稀疏DCT的图像表示法进行生成式建模,受JPEG等常见图像压缩方法的启发,将图像转换为量化的离散余弦变换(DCT)块,将其稀疏地表示为DCT通道、空间位置和DCT系数三组序列,提出基于Transformer的自回归架构,对稀疏图像序列进行建模,克服了用分块训练对长序列建模的挑战。DCTransformer在样本质量和多样性基准上,实现了强大性能,轻松支持超分辨率上采样,以及着色任务。
The high dimensionality of images presents architecture and sampling-efficiency challenges for likelihood-based generative models. Previous approaches such as VQ-VAE use deep autoencoders to obtain compact representations, which are more practical as inputs for likelihood-based models. We present an alternative approach, inspired by common image compression methods like JPEG, and convert images to quantized discrete cosine transform (DCT) blocks, which are represented sparsely as a sequence of DCT channel, spatial location, and DCT coefficient triples. We propose a Transformer-based autoregressive architecture, which is trained to sequentially predict the conditional distribution of the next element in such sequences, and which scales effectively to high resolution images. On a range of image datasets, we demonstrate that our approach can generate high quality, diverse images, with sample metric scores competitive with state of the art methods. We additionally show that simple modifications to our method yield effective image colorization and super-resolution models.
https://weibo.com/1402400261/K5kIt2nSH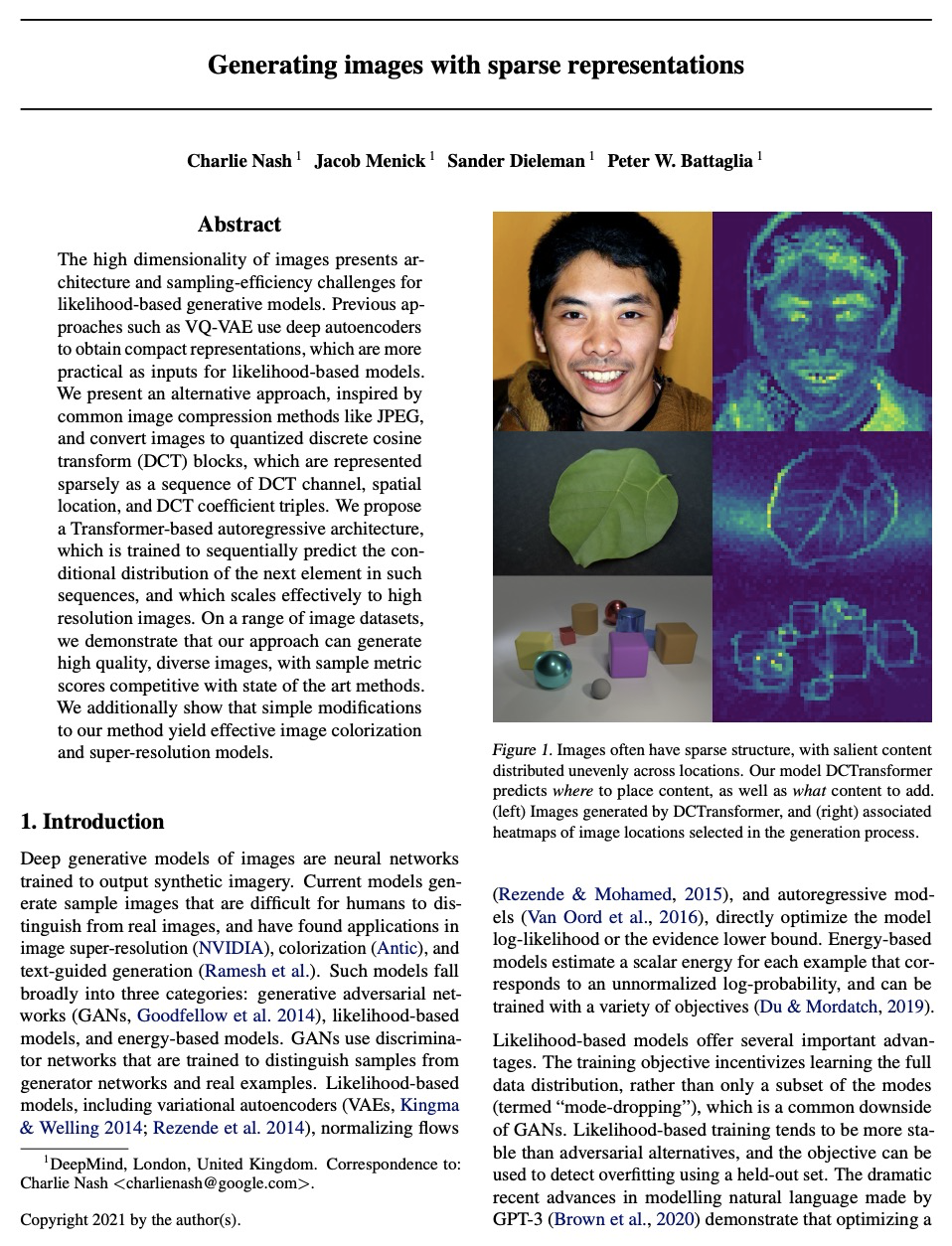

3、[LG] Measuring Mathematical Problem Solving With the MATH Dataset
D Hendrycks, C Burns, S Kadavath, A Arora, S Basart, E Tang, D Song, J Steinhardt
[UC Berkeley & UChicago]
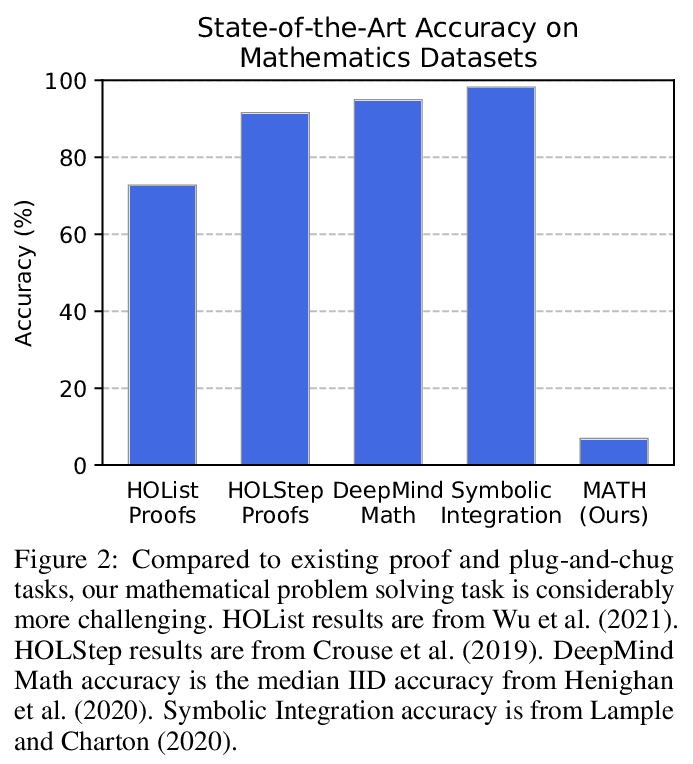
MATH数学题基准数据集。提出MATH数据集,包含12,500个具有挑战性的竞赛数学题。MATH中每个问题都有完整的步骤解法,可用来教模型生成答案推导和解释。为方便未来的研究,提高MATH的准确率,还提供了一个大型的辅助预训练数据集,帮助教模型学习数学基础知识。即使能提高MATH上的准确率,但实验结果显示,即使是大型Transformer模型,准确率仍然比较低。即使继续扩大规模,单纯增加预算和模型参数数,对于实现强大的数学推理是无能为力的。虽然规模化Transformers可自动解决大多数其他基于文本的任务,但规模化目前还不能解决MATH提出的挑战。
Many intellectual endeavors require mathematical problem solving, but this skill remains beyond the capabilities of computers. To measure this ability in machine learning models, we introduce MATH, a new dataset of 12,500 challenging competition mathematics problems. Each problem in MATH has a full step-by-step solution which can be used to teach models to generate answer derivations and explanations. To facilitate future research and increase accuracy on MATH, we also contribute a large auxiliary pretraining dataset which helps teach models the fundamentals of mathematics. Even though we are able to increase accuracy on MATH, our results show that accuracy remains relatively low, even with enormous Transformer models. Moreover, we find that simply increasing budgets and model parameter counts will be impractical for achieving strong mathematical reasoning if scaling trends continue. While scaling Transformers is automatically solving most other text-based tasks, scaling is not currently solving MATH. To have more traction on mathematical problem solving we will likely need new algorithmic advancements from the broader research community.
https://weibo.com/1402400261/K5kLMDDIz


4、[CL] There Once Was a Really Bad Poet, It Was Automated but You Didn’t Know It
J Wang, X Zhang, Y Zhou, C Suh, C Rudin
[Duke University]
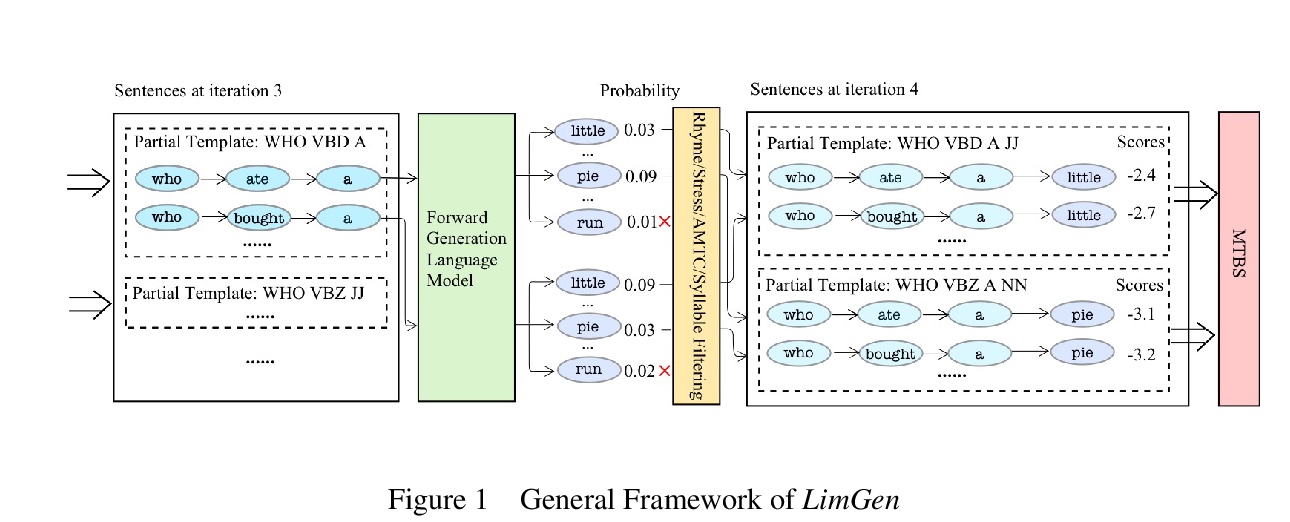
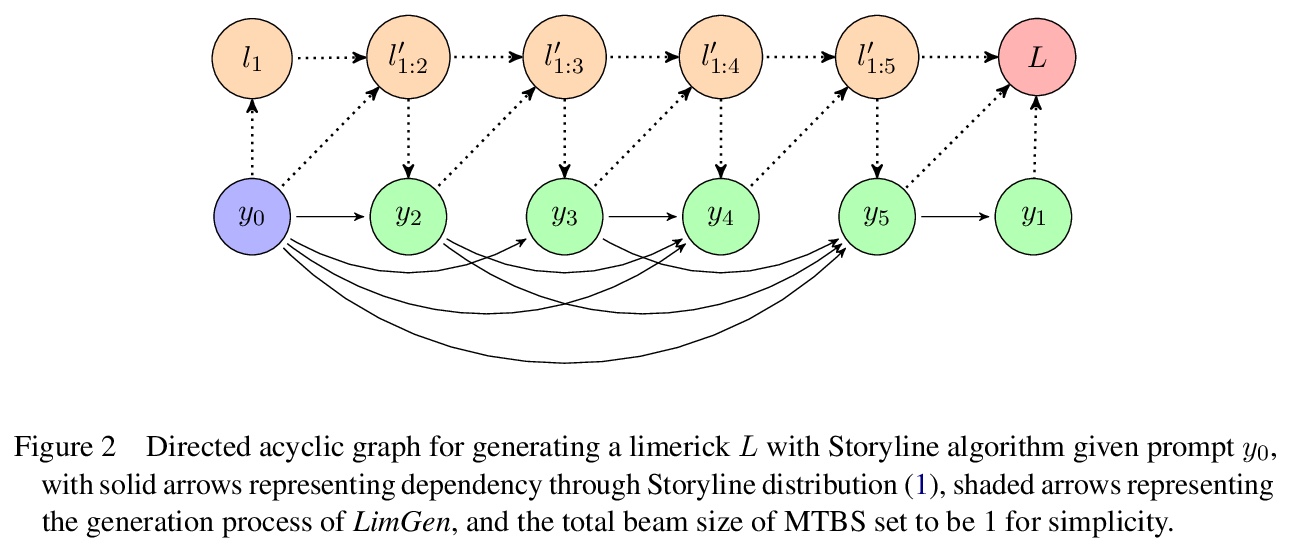
全自动打油诗生成系统。提出新的全自动打油诗生成系统LimGen,性能优于最先进的基于神经网络的诗歌模型,以及之前基于规则的诗歌模型。LimGen由三个重要部分组成:自适应多模板约束算法,搜索限制在真实诗歌空间,多模板波束搜索算法,以有效地在空间搜索,以及概率Storyline算法,提供与用户提供的提示词相关的连贯情节。由此产生的五行打油诗满足诗意约束,并具有主题上连贯的故事情节,有时甚至是有趣的(如果幸运的话)。
Limerick generation exemplifies some of the most difficult challenges faced in poetry generation, as the poems must tell a story in only five lines, with constraints on rhyme, stress, and meter. To address these challenges, we introduce LimGen, a novel and fully automated system for limerick generation that outperforms state-of-the-art neural network-based poetry models, as well as prior rule-based poetry models. LimGen consists of three important pieces: the Adaptive Multi-Templated Constraint algorithm that constrains our search to the space of realistic poems, the Multi-Templated Beam Search algorithm which searches efficiently through the space, and the probabilistic Storyline algorithm that provides coherent storylines related to a user-provided prompt word. The resulting limericks satisfy poetic constraints and have thematically coherent storylines, which are sometimes even funny (when we are lucky).
https://weibo.com/1402400261/K5kPZ1QzV

5、[CV] FisheyeSuperPoint: Keypoint Detection and Description Network for Fisheye Images
A Konrad, C Eising, G Sistu, J McDonald, R Villing, S Yogamani
[Maynooth University & University of Limerick]
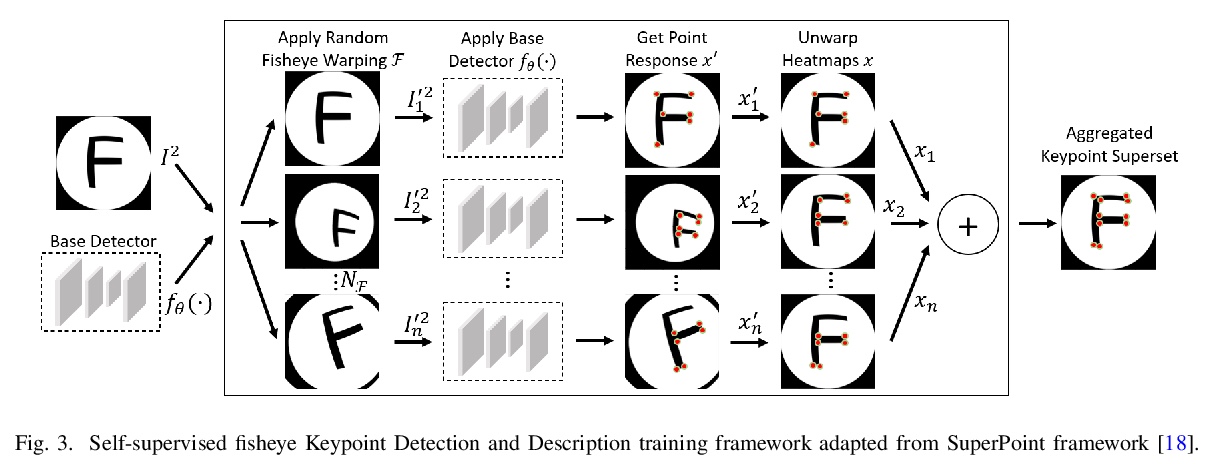
FisheyeSuperPoint:鱼眼相机图像关键点检测和描述网络。提出FisheyeSuperPoint关键点检测和描述网络,使用经过调整的训练流水线,可直接在鱼眼图像数据集上工作。FisheyeSuperPoint利用了鱼眼扭曲实现了对鱼眼图像的自监督训练,鱼眼图像通过投射到单位球体的中间步骤被映射到一个新的、扭曲的鱼眼图像上,相机的虚拟姿态在六个自由度内变化。这个过程被嵌入到现有的SuperPoint实现中,并在RobotCar数据集上进行训练。实验表明,在标准图像(HPatches)上的实验中,FisheyeSuperPoint性能始终优于SuperPoint,尤其是在同向正确性方面。
Keypoint detection and description is a commonly used building block in computer vision systems particularly for robotics and autonomous driving. Recently CNN based approaches have surpassed classical methods in a number of perception tasks. However, the majority of techniques to date have focused on standard cameras with little consideration given to fisheye cameras which are commonly used in autonomous driving. In this paper, we propose a novel training and evaluation pipeline for fisheye images. We make use of SuperPoint as our baseline which is a self-supervised keypoint detector and descriptor that has achieved state-of-the-art results on homography estimation. We introduce a fisheye adaptation pipeline to enable training on undistorted fisheye images. We evaluate the performance on the HPatches benchmark, and, by introducing a fisheye based evaluation methods for detection repeatability and descriptor matching correctness on the Oxford RobotCar datasets.
https://weibo.com/1402400261/K5kSweXMa


另外几篇值得关注的论文:
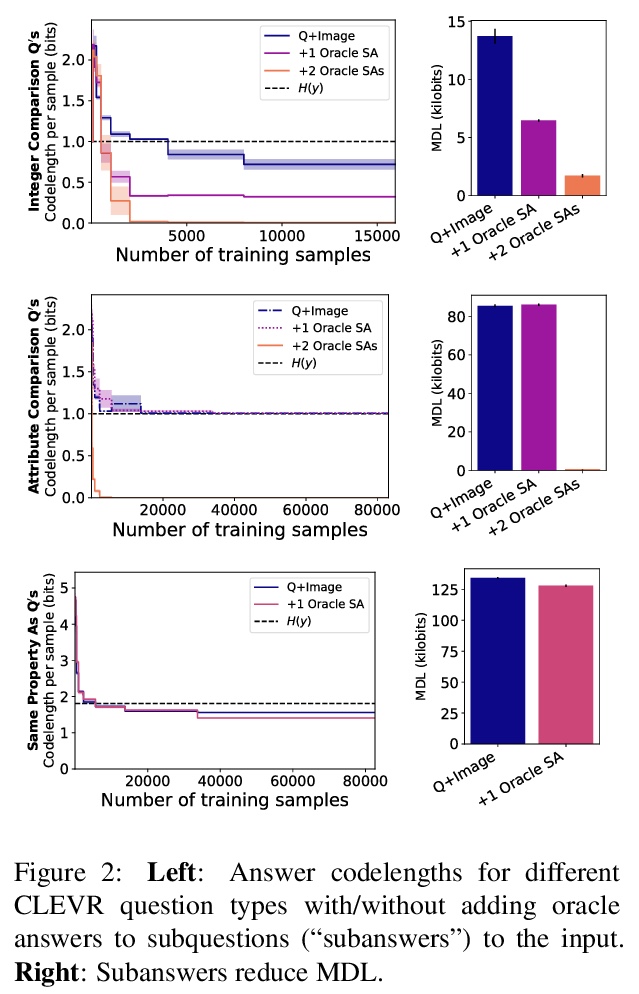
[LG] Rissanen Data Analysis: Examining Dataset Characteristics via Description Length
Rissanen数据分析(RDA):用描述长度检查数据集特征
E Perez, D Kiela, K Cho
[New York University & Facebook AI Research]
https://weibo.com/1402400261/K5kV7z8iJ
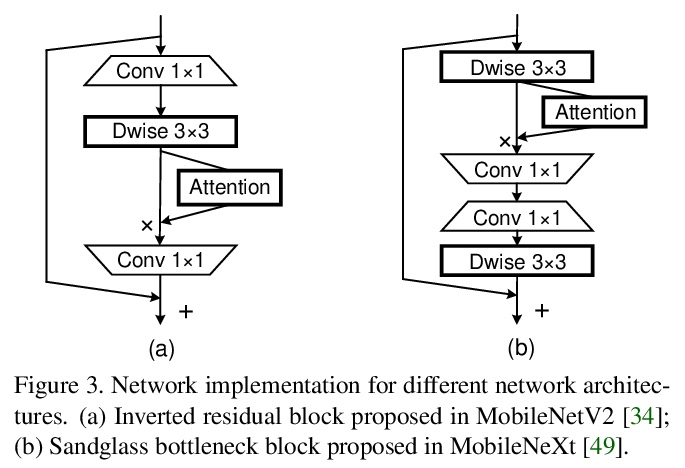
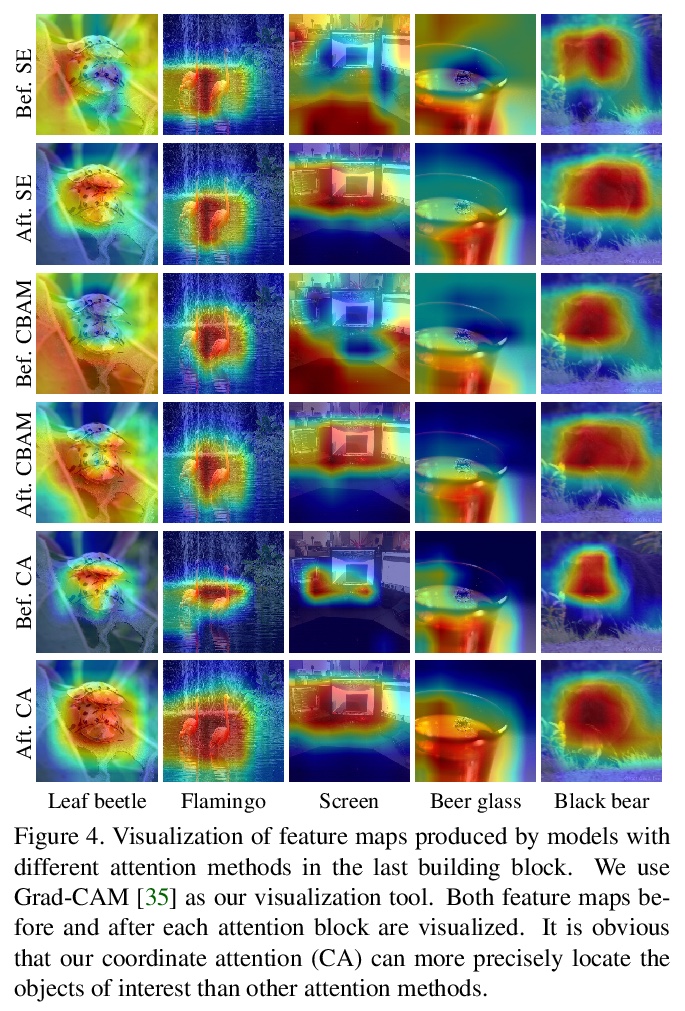
[CV] Coordinate Attention for Efficient Mobile Network Design
协调注意力高效移动网设计
Q Hou, D Zhou, J Feng
[National University of Singapore]
https://weibo.com/1402400261/K5kXcobcj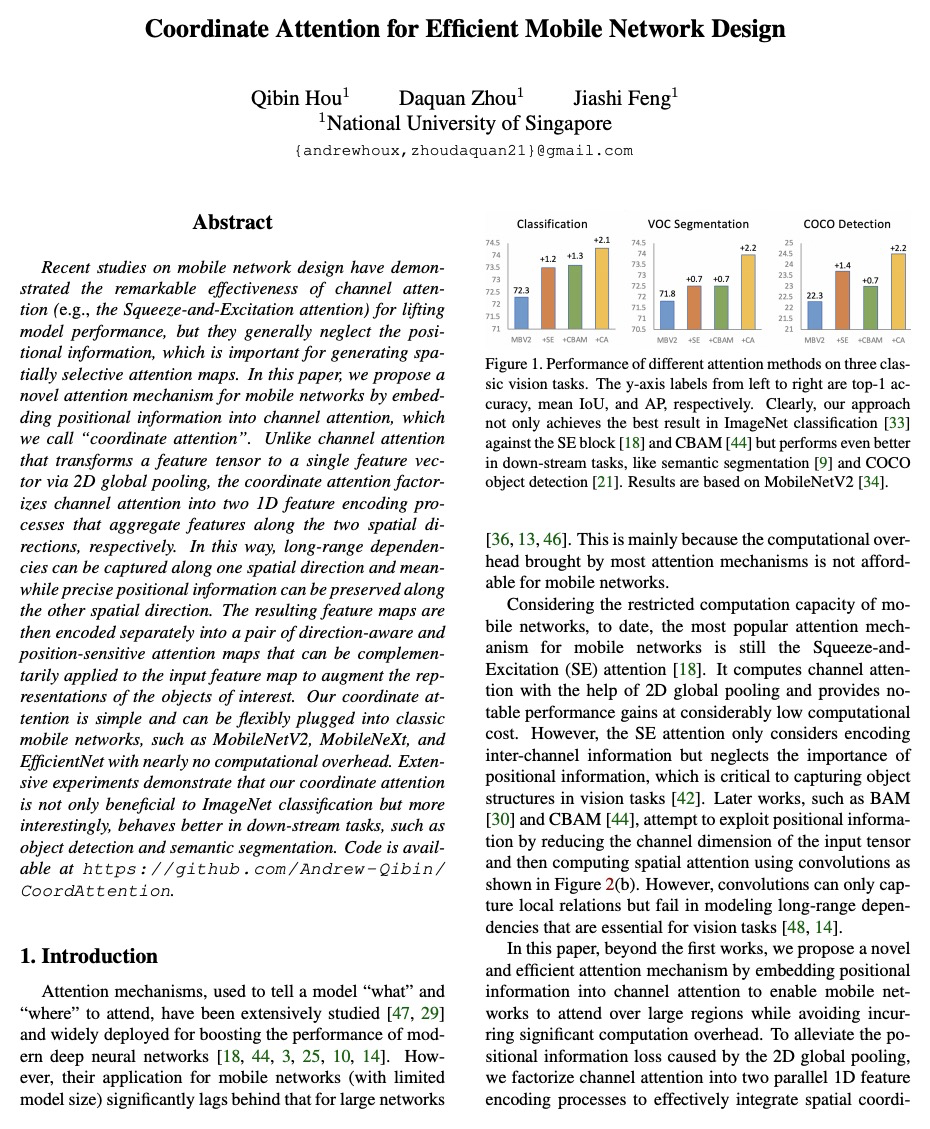

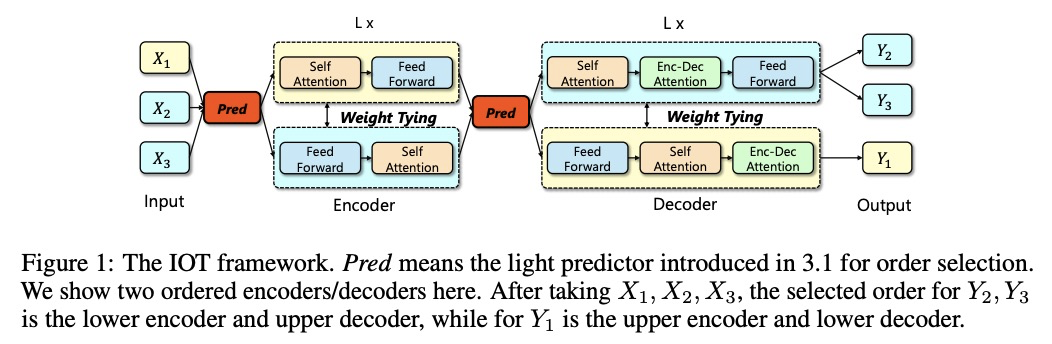
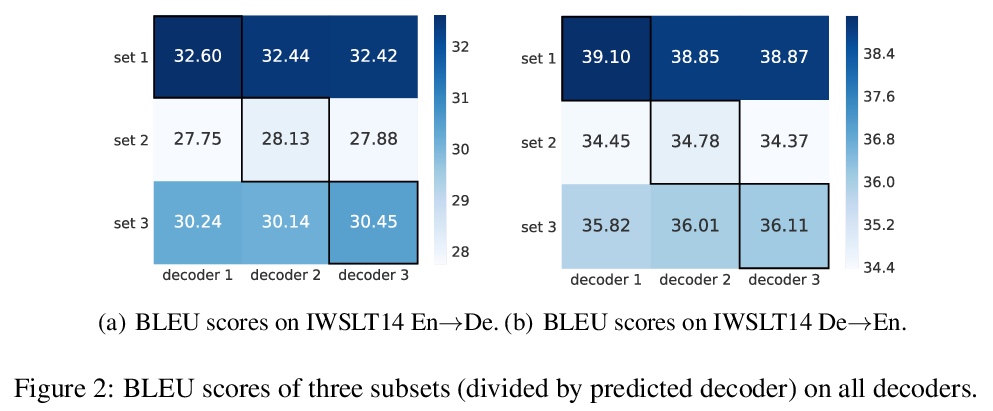
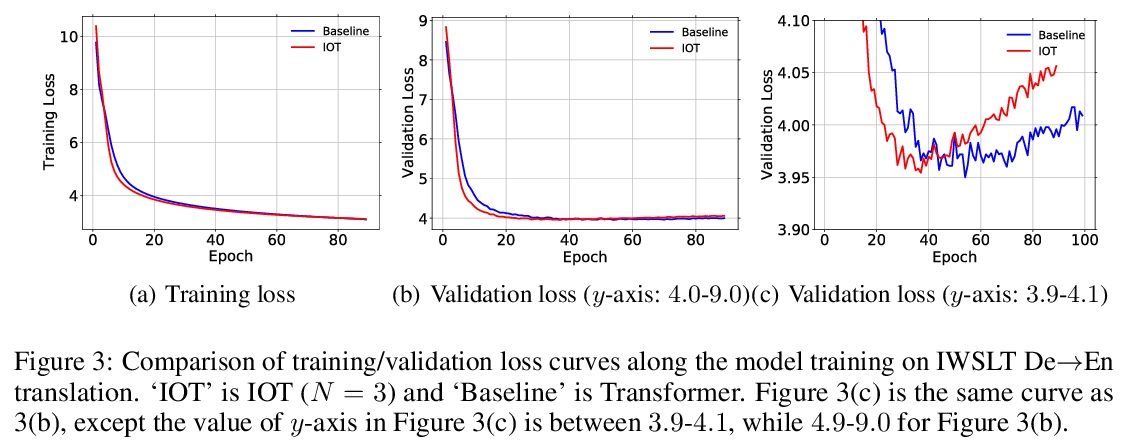
[CL] IOT: Instance-wise Layer Reordering for Transformer Structures
IOT:Transformer结构的实例级层重排
J Zhu, L Wu, Y Xia, S Xie, T Qin, W Zhou, H Li, T Liu
[University of Science and Technology of China & Microsoft Research]
https://weibo.com/1402400261/K5kYDjGYL
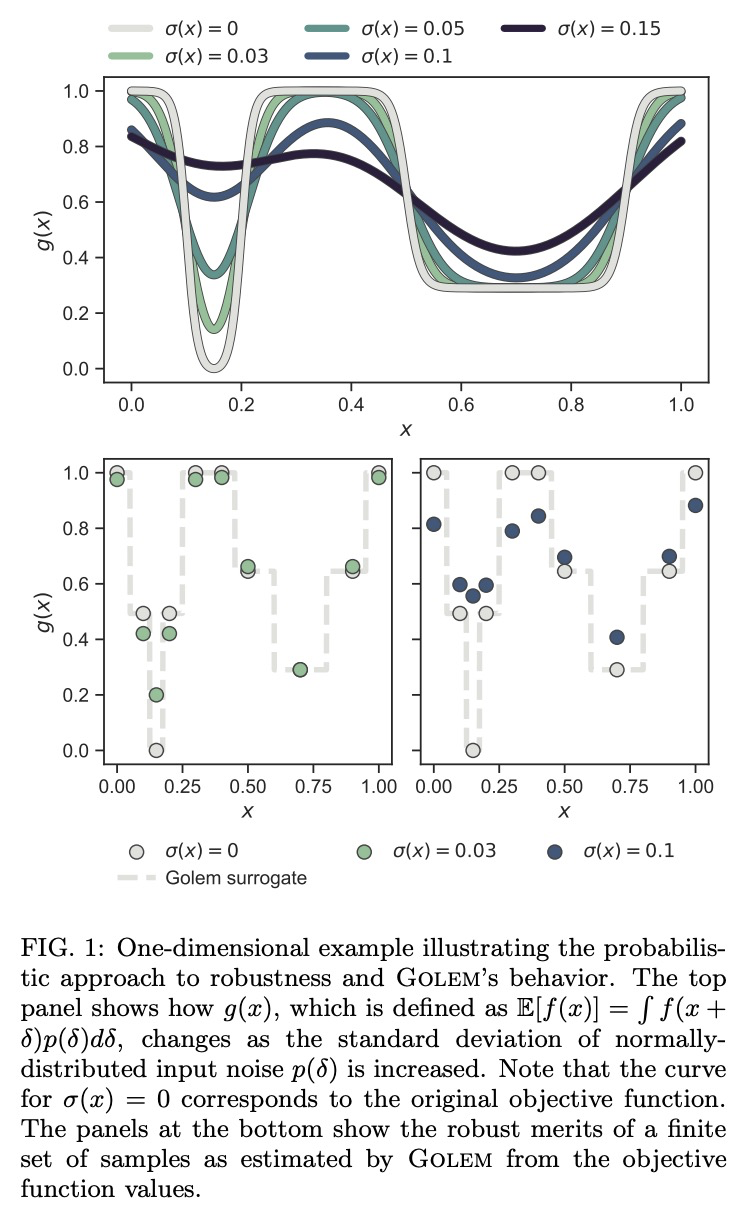
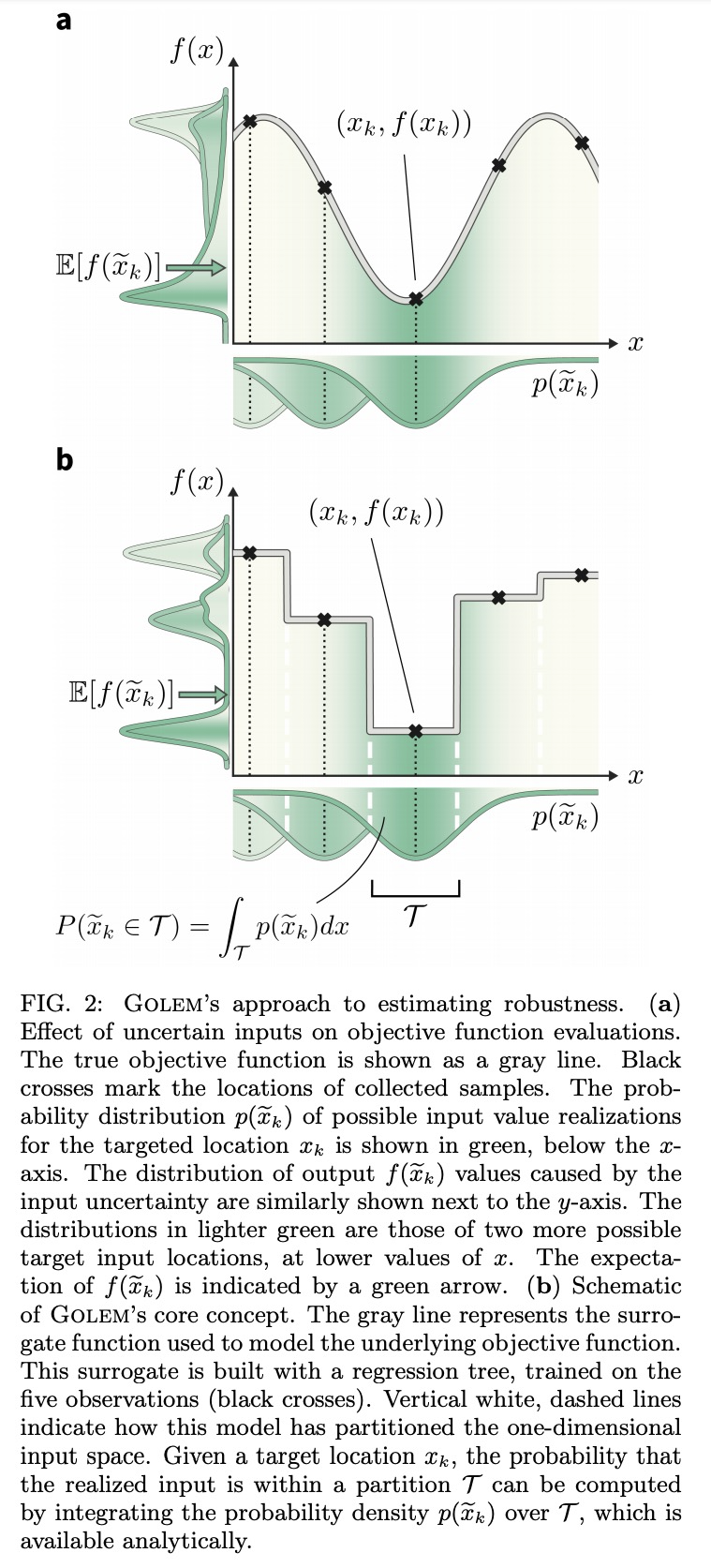
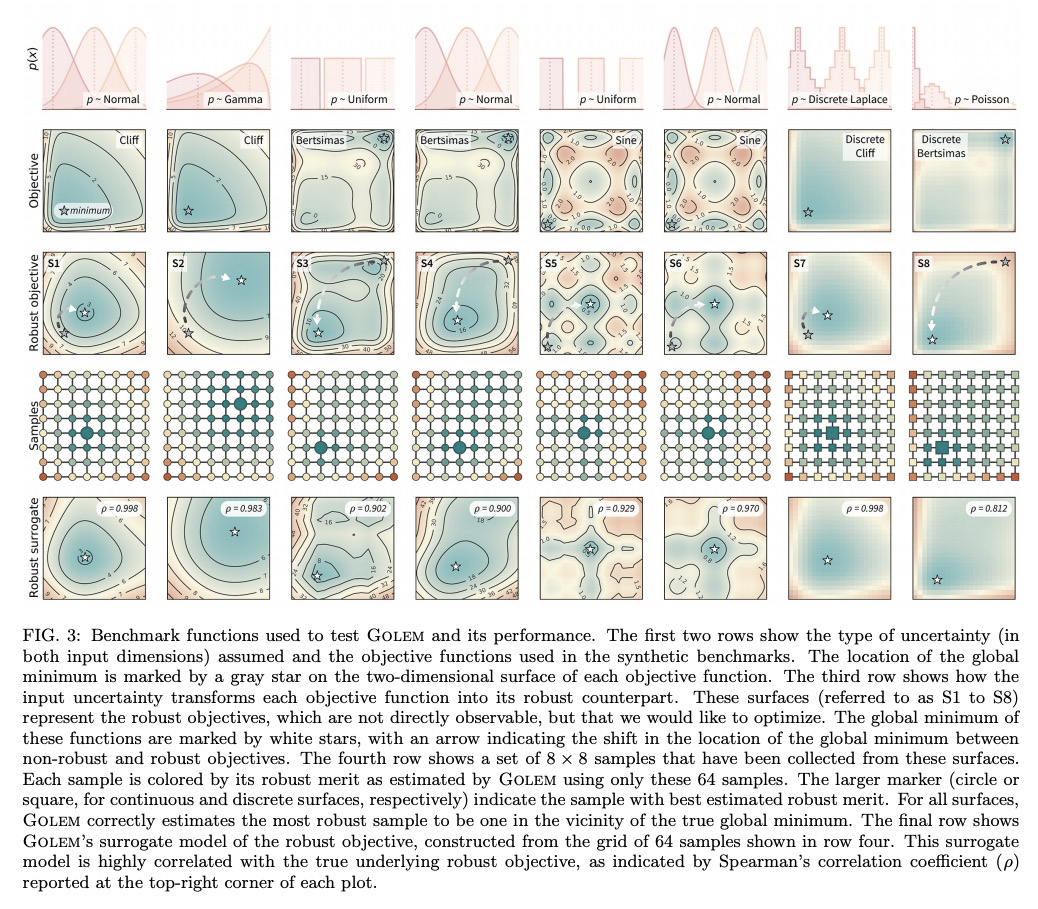
[LG] Golem: An algorithm for robust experiment and process optimization
Golem:鲁棒实验与过程优化算法
M Aldeghi, F Häse, R J. Hickman, I Tamblyn, A Aspuru-Guzik
[Vector Institute for Artificial Intelligence & University of Toronto & Harvard University]
https://weibo.com/1402400261/K5l1TpxiT

若有收获,就点个赞吧
0 人点赞
