- 1、[CL] PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them
- 2、[LG] GradInit: Learning to Initialize Neural Networks for Stable and Efficient Training
- 3、[LG] TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models
- 4、[LG] Training Larger Networks for Deep Reinforcement Learning
- 5、[LG] Rethinking Co-design of Neural Architectures and Hardware Accelerators
- [CV] K-Hairstyle: A Large-scale Korean hairstyle dataset for virtual hair editing and hairstyle classification
- [LG] Graph Convolution for Semi-Supervised Classification: Improved Linear Separability and Out-of-Distribution Generalization
- [LG] A Deep Learning Approach for Characterizing Major Galaxy Mergers
- [LG] Geometric feature performance under downsampling for EEG classification tasks
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them
P Lewis, Y Wu, L Liu, P Minervini, H Küttler, A Piktus, P Stenetorp, S Riedel
[Facebook AI Research & University College London]
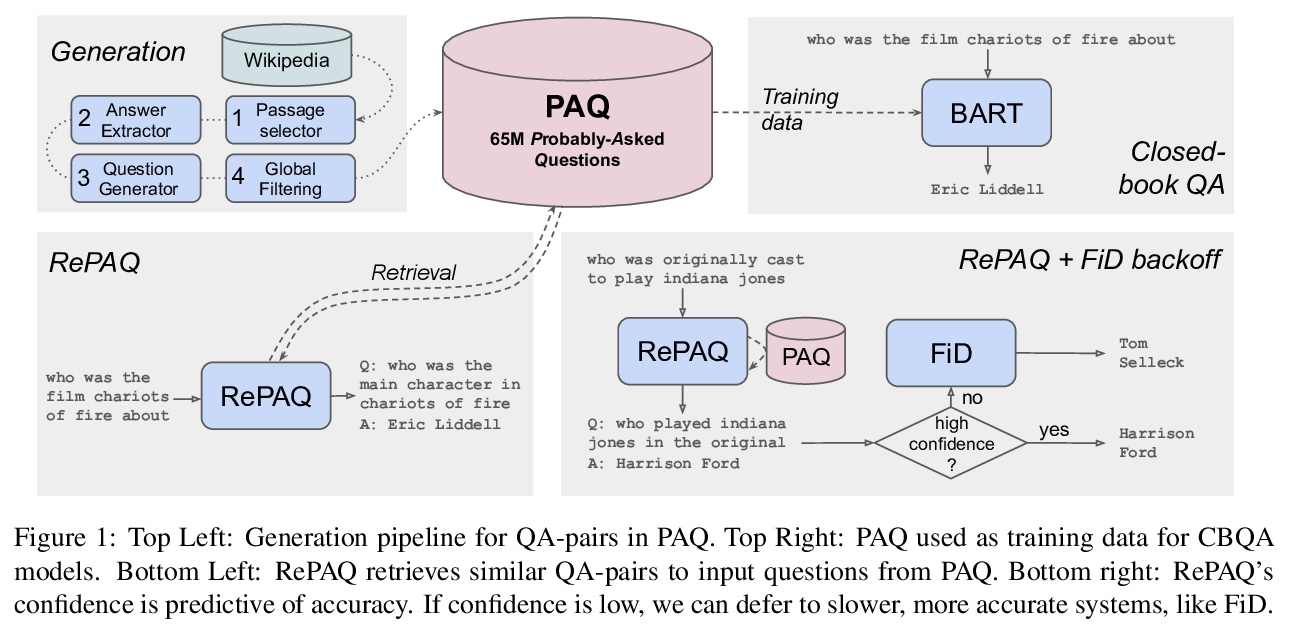
PAQ:6500万个可能被问到的问题能用来做什么?为便于改进QA对模型,引入Probably Asked Questions(PAQ),包含6500万规模的QA对,采用全局过滤,从维基百科中自动生成,探索如何利用其改进ODQA模型。鉴于其规模,生成PAQ是计算密集型的,但对于更准确,更小,更快的QA模型来说是有用且可复用资源。引入了一个新的QA对检索器RePAQ,展示了其在准确性、速度、空间效率和选择性QA方面的有效性。PAQ预置和缓存测试问题,使RePAQ能够与最近的检索和读取模型的准确性相匹配,同时速度明显更快。用PAQ训练的CBQA模型比同类基线的表现好5%,但比RePAQ落后15%以上,表明了显式检索的有效性。RePAQ可以根据大小(500MB以下)或速度(每秒超过1K个问题)进行配置,同时保持高准确度。证明了RePAQ在选择性QA方面的优势,在可能不正确的情况下放弃回答。
Open-domain Question Answering models which directly leverage question-answer (QA) pairs, such as closed-book QA (CBQA) models and QA-pair retrievers, show promise in terms of speed and memory compared to conventional models which retrieve and read from text corpora. QA-pair retrievers also offer interpretable answers, a high degree of control, and are trivial to update at test time with new knowledge. However, these models lack the accuracy of retrieve-and-read systems, as substantially less knowledge is covered by the available QA-pairs relative to text corpora like Wikipedia. To facilitate improved QA-pair models, we introduce Probably Asked Questions (PAQ), a very large resource of 65M automatically-generated QA-pairs. We introduce a new QA-pair retriever, RePAQ, to complement PAQ. We find that PAQ preempts and caches test questions, enabling RePAQ to match the accuracy of recent retrieve-and-read models, whilst being significantly faster. Using PAQ, we train CBQA models which outperform comparable baselines by 5%, but trail RePAQ by over 15%, indicating the effectiveness of explicit retrieval. RePAQ can be configured for size (under 500MB) or speed (over 1K questions per second) whilst retaining high accuracy. Lastly, we demonstrate RePAQ’s strength at selective QA, abstaining from answering when it is likely to be incorrect. This enables RePAQ to ``back-off” to a more expensive state-of-the-art model, leading to a combined system which is both more accurate and 2x faster than the state-of-the-art model alone.
https://weibo.com/1402400261/K33fY1NUh
2、[LG] GradInit: Learning to Initialize Neural Networks for Stable and Efficient Training
C Zhu, R Ni, Z Xu, K Kong, W. R Huang, T Goldstein
[University of Maryland & Google Research]
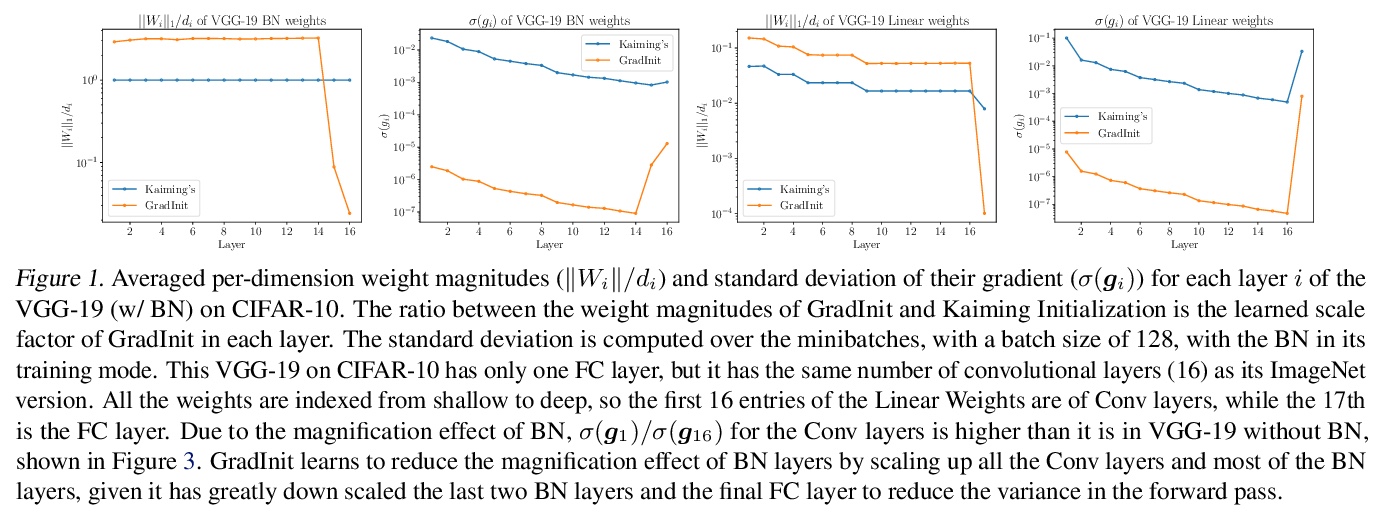
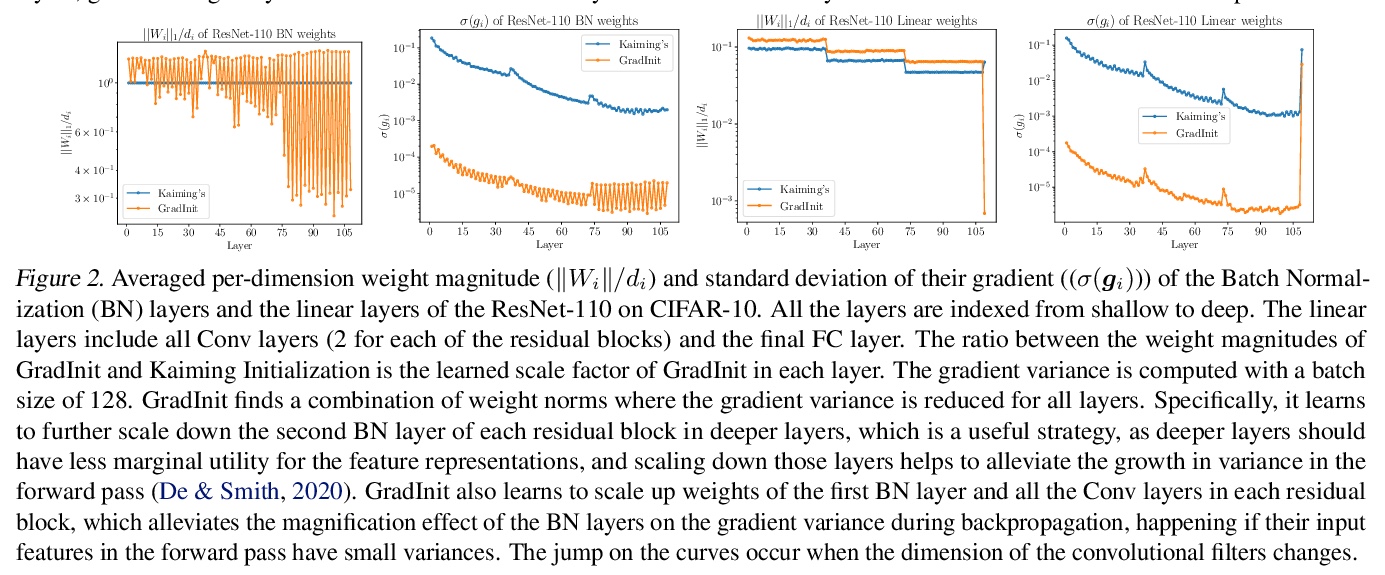
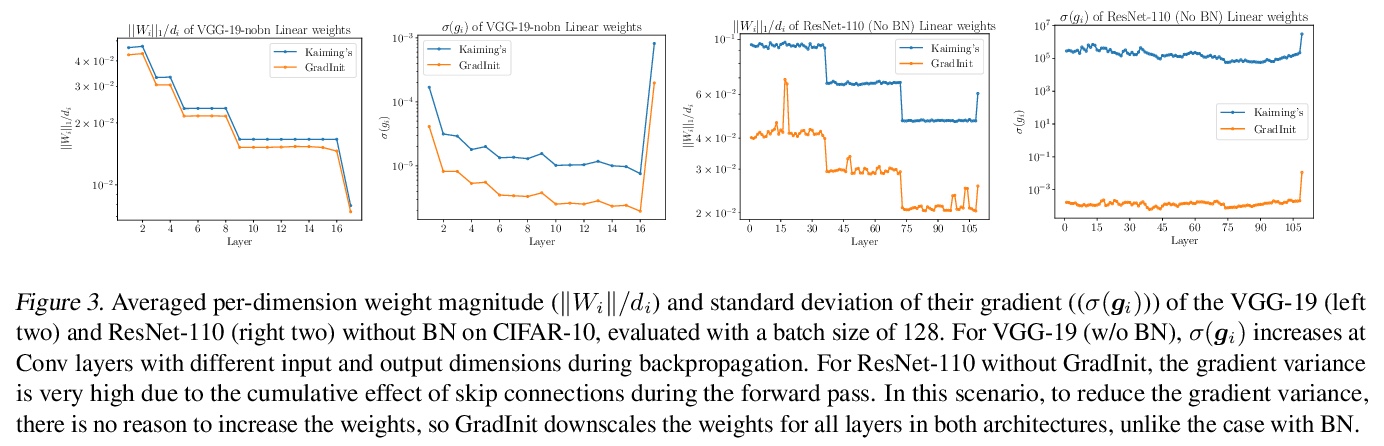
GradInit: 面向稳定高效训练的神经网络初始化学习。提出一种用于初始化神经网络的自动化和架构不可知方法GradInit,基于一个简单的启发式方法;调整每个网络层的方差,使SGD或Adam的单步导致的损失值尽可能小。这种调整是通过在每个参数块前引入一个标量乘法器变量来完成的,用简单的数值方案来优化变量。通过为网络的每个随机初始化参数块学习一个尺度因子重新初始化网络,使特定随机优化器的一个梯度步骤后,在不同小批量上评价的训练损失最小化,考虑随机性、学习率和优化器的方向,能找到更好的为优化器量身定做的初始化。GradInit加快了收敛速度,提高了各种架构对图像分类的测试性能,无论有无跳接或归一化层。
Changes in neural architectures have fostered significant breakthroughs in language modeling and computer vision. Unfortunately, novel architectures often require re-thinking the choice of hyperparameters (e.g., learning rate, warmup schedule, and momentum coefficients) to maintain stability of the optimizer. This optimizer instability is often the result of poor parameter initialization, and can be avoided by architecture-specific initialization schemes. In this paper, we present GradInit, an automated and architecture agnostic method for initializing neural networks. GradInit is based on a simple heuristic; the variance of each network layer is adjusted so that a single step of SGD or Adam results in the smallest possible loss value. This adjustment is done by introducing a scalar multiplier variable in front of each parameter block, and then optimizing these variables using a simple numerical scheme. GradInit accelerates the convergence and test performance of many convolutional architectures, both with or without skip connections, and even without normalization layers. It also enables training the original Post-LN Transformer for machine translation without learning rate warmup under a wide range of learning rates and momentum coefficients. Code is available at > this https URL.
https://weibo.com/1402400261/K33qS9731
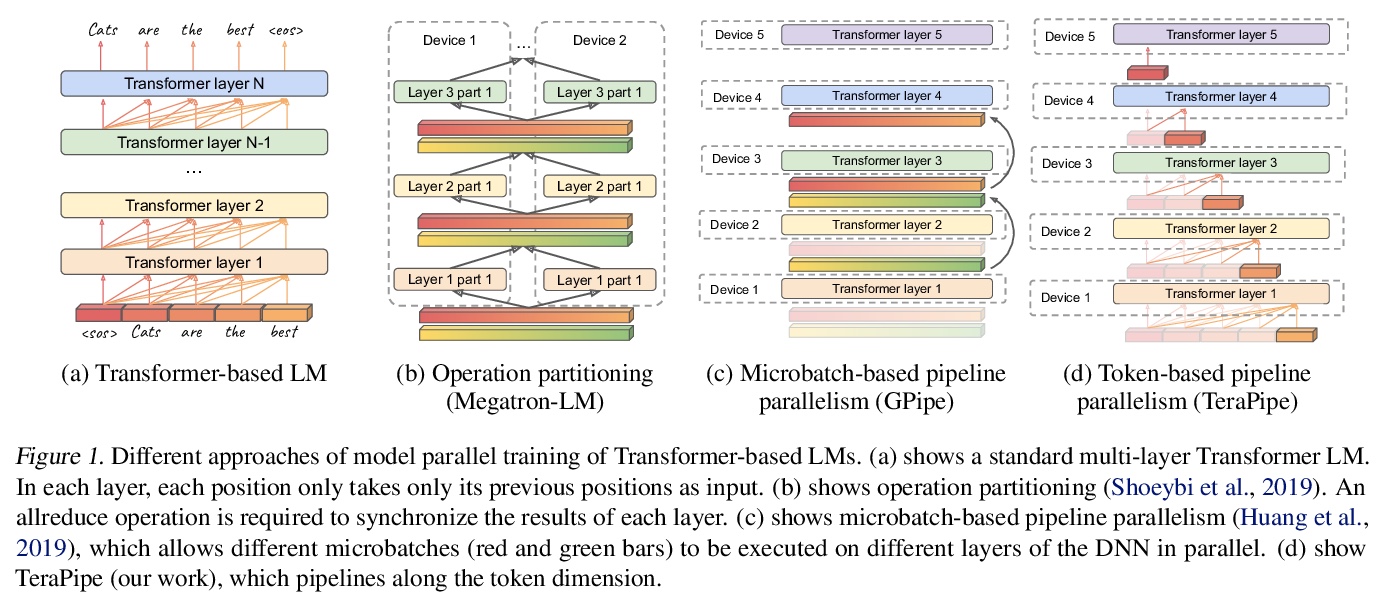
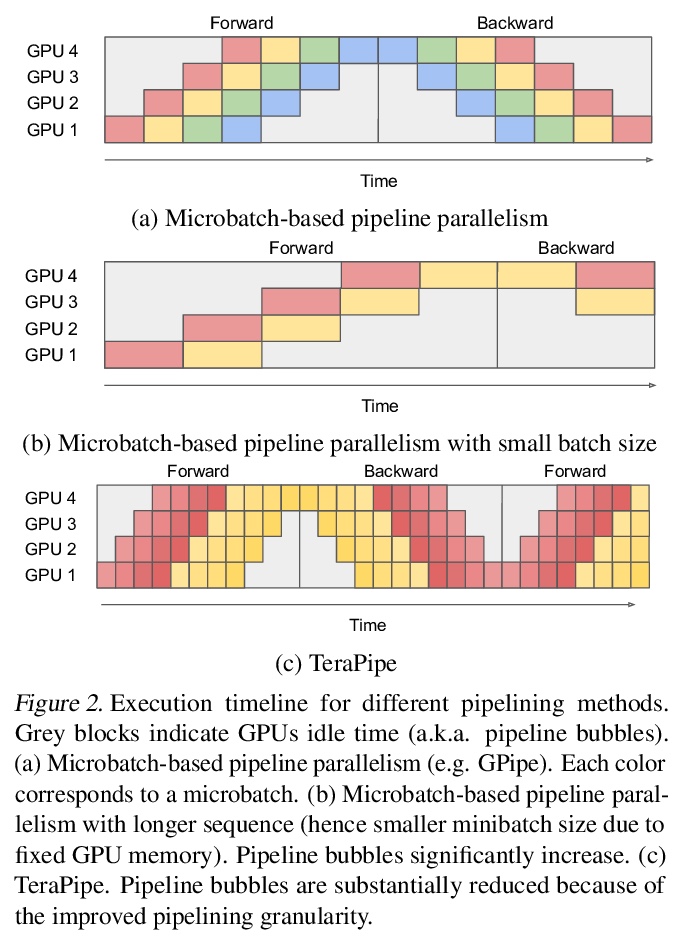
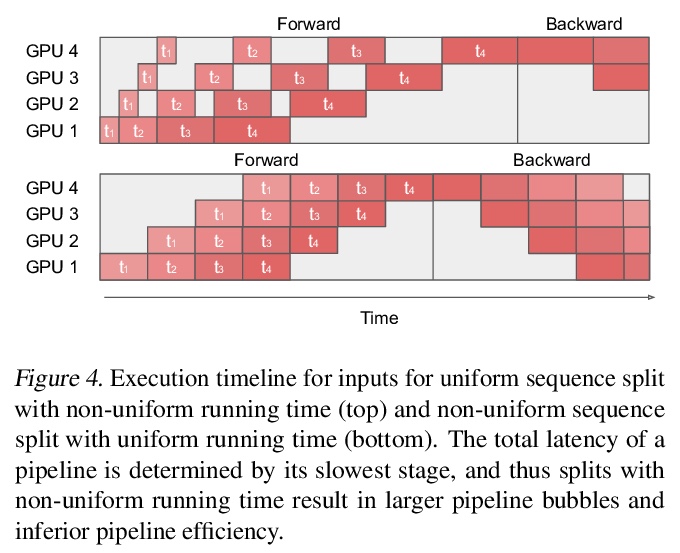
3、[LG] TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models
Z Li, S Zhuang, S Guo, D Zhuo, H Zhang, D Song, I Stoica
[UC Berkeley & Duke University]
TeraPipe:基于Token级管线并行化的大规模语言模型训练。从现有模型并行方法中找出一个新的正交维度:由于Transformer的自回归属性,可在单个训练序列内对基于Transformer的语言模型进行管线并行化。提出了TeraPipe,一个高性能的Token级管线并行算法,用于基于Transformer语言模型的同步模型并行训练。开发了一种新的基于动态规划的算法,以计算给定特定模型和集群配置的最佳管线执行方案。与最先进的模型并行方法相比,TeraPipe可在具有48个P3.16xlarge实例的AWS集群上,将1750亿参数的最大GPT-3模型的训练速度提高5倍。
Model parallelism has become a necessity for training modern large-scale deep language models. In this work, we identify a new and orthogonal dimension from existing model parallel approaches: it is possible to perform pipeline parallelism within a single training sequence for Transformer-based language models thanks to its autoregressive property. This enables a more fine-grained pipeline compared with previous work. With this key idea, we design TeraPipe, a high-performance token-level pipeline parallel algorithm for synchronous model-parallel training of Transformer-based language models. We develop a novel dynamic programming-based algorithm to calculate the optimal pipelining execution scheme given a specific model and cluster configuration. We show that TeraPipe can speed up the training by 5.0x for the largest GPT-3 model with 175 billion parameters on an AWS cluster with 48 p3.16xlarge instances compared with state-of-the-art model-parallel methods.
https://weibo.com/1402400261/K33uXncRr
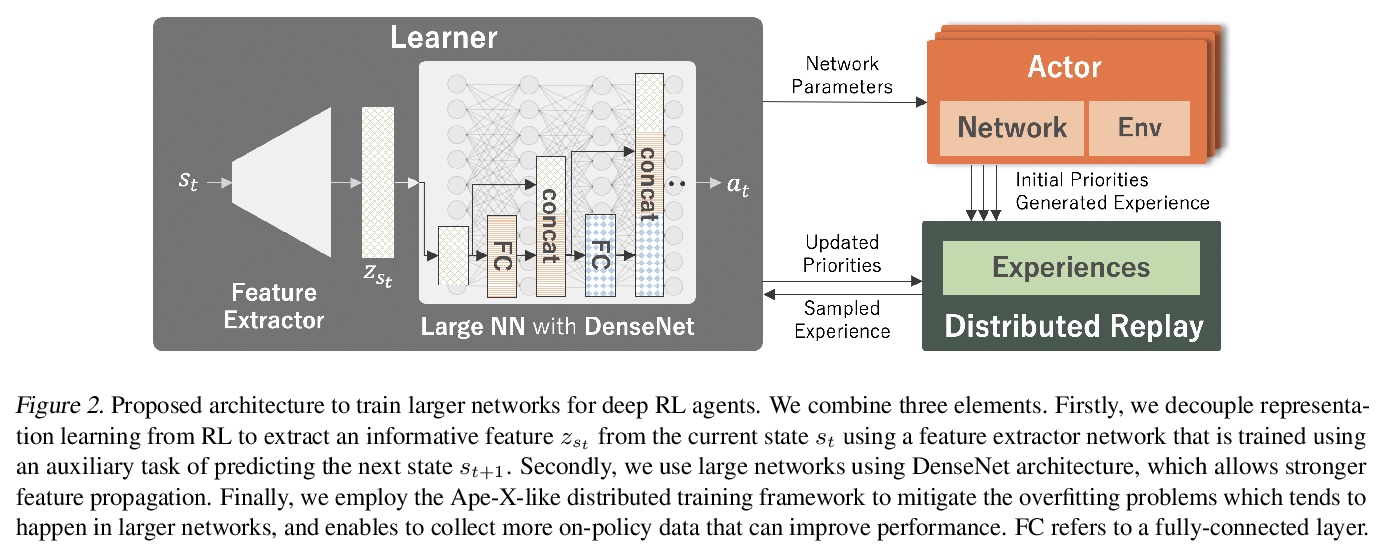
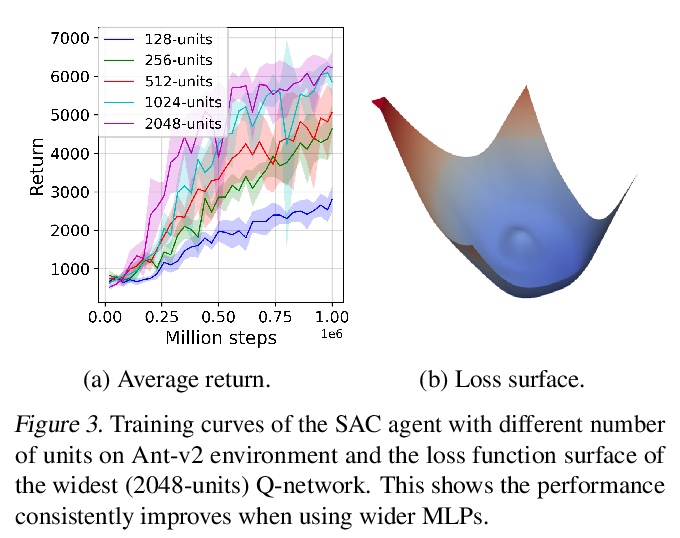
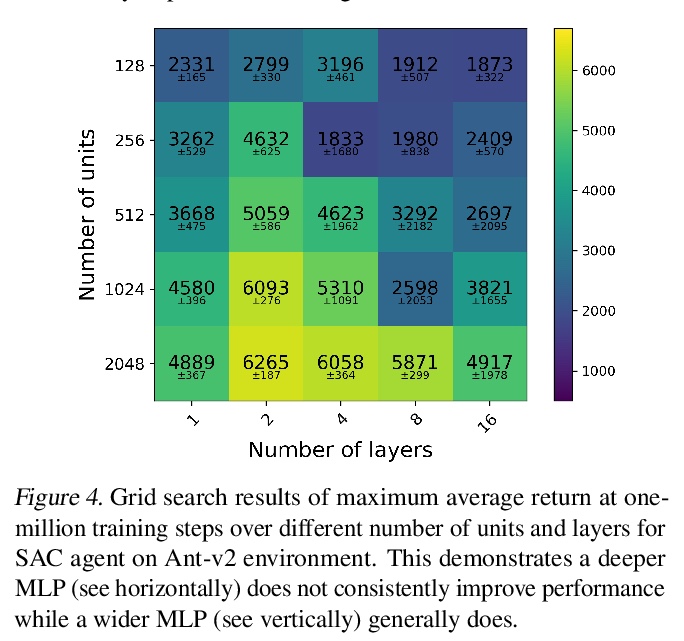
4、[LG] Training Larger Networks for Deep Reinforcement Learning
K Ota, D K. Jha, A Kanezaki
[Mitsubishi Electric & Tokyo Institute of Technology]
深度强化学习更大规模网络训练。对深度强化学习智能体采用更大规模网络进行深入研究,经验表明,单纯增加网络容量并不能提高性能,相比更深的网络,更宽的网络更能提高性能。提出一种用于训练更大规模网络的深度强化学习智能体的新方法,同时反思了使用这种网络时必须做出的一些重要设计选择。所提出的方法包括三个要素:1)采用非常宽的网络组成的DenseNet架构,2)使用预测下一个状态的辅助损失,将表示学习与强化学习的训练解耦,3)一种分布式训练方法来缓解过拟合问题,并增强对新场景的泛化。使用这三方面的技术,可以训练非常大的网络,带来显著的性能提升。
The success of deep learning in the computer vision and natural language processing communities can be attributed to training of very deep neural networks with millions or billions of parameters which can then be trained with massive amounts of data. However, similar trend has largely eluded training of deep reinforcement learning (RL) algorithms where larger networks do not lead to performance improvement. Previous work has shown that this is mostly due to instability during training of deep RL agents when using larger networks. In this paper, we make an attempt to understand and address training of larger networks for deep RL. We first show that naively increasing network capacity does not improve performance. Then, we propose a novel method that consists of 1) wider networks with DenseNet connection, 2) decoupling representation learning from training of RL, 3) a distributed training method to mitigate overfitting problems. Using this three-fold technique, we show that we can train very large networks that result in significant performance gains. We present several ablation studies to demonstrate the efficacy of the proposed method and some intuitive understanding of the reasons for performance gain. We show that our proposed method outperforms other baseline algorithms on several challenging locomotion tasks.
https://weibo.com/1402400261/K33zYxqwv
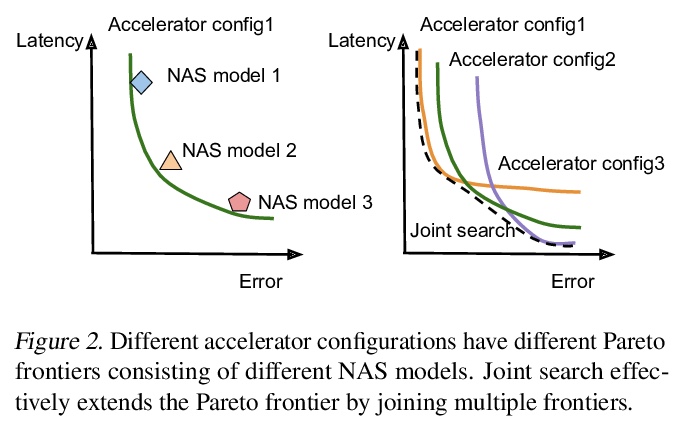
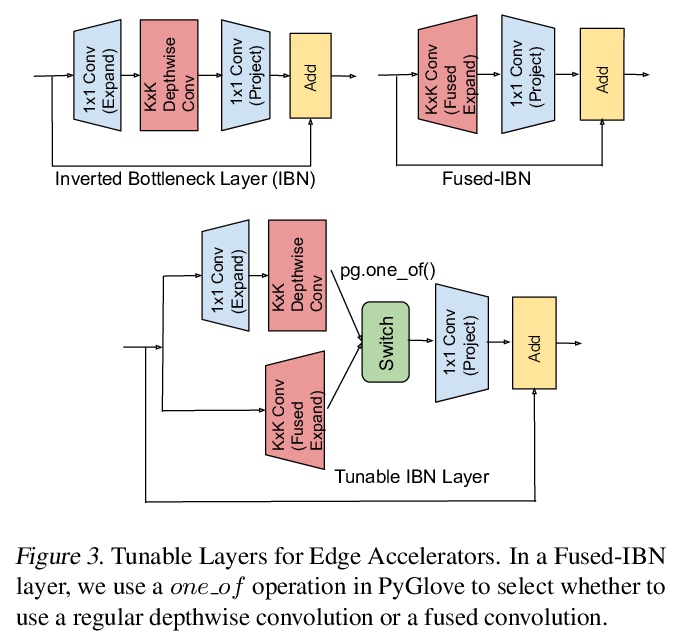
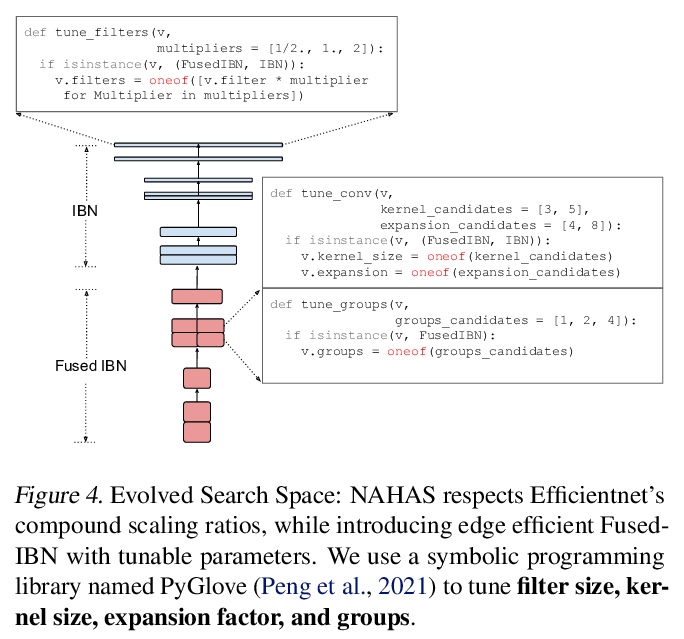
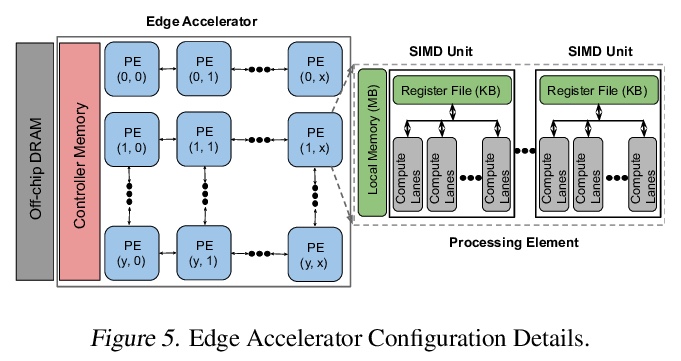
5、[LG] Rethinking Co-design of Neural Architectures and Hardware Accelerators
Y Zhou, X Dong, B Akin, M Tan, D Peng, T Meng, A Yazdanbakhsh, D Huang, R Narayanaswami, J Laudon
[Google]
神经网络架构与硬件加速器协同设计的反思。系统研究了神经网络架构和硬件加速器协同设计的重要性和策略。提出三个观点:1)软件搜索空间必须定制化,以充分利用目标硬件架构;2)模型架构和硬件架构的搜索应该联合进行,以达到齐头并进的效果;3)不同的用例会导致非常不同的搜索结果。开发了一个全自动框架,可以联合优化神经网络架构和硬件加速器,展示了联合优化神经网络架构搜索与高度优化的工业标准边缘加速器参数化的有效性。提出一种延迟驱动的与硬件无关的搜索方法,优于之前的平台感知神经网络架构搜索、人工制作模型和最先进的EfficientNet。在相同精度约束下,该方法同时调整模型架构和硬件加速器配置,可将边缘加速器的能耗降低2倍。
Neural architectures and hardware accelerators have been two driving forces for the progress in deep learning. Previous works typically attempt to optimize hardware given a fixed model architecture or model architecture given fixed hardware. And the dominant hardware architecture explored in this prior work is FPGAs. In our work, we target the optimization of hardware and software configurations on an industry-standard edge accelerator. We systematically study the importance and strategies of co-designing neural architectures and hardware accelerators. We make three observations: 1) the software search space has to be customized to fully leverage the targeted hardware architecture, 2) the search for the model architecture and hardware architecture should be done jointly to achieve the best of both worlds, and 3) different use cases lead to very different search outcomes. Our experiments show that the joint search method consistently outperforms previous platform-aware neural architecture search, manually crafted models, and the state-of-the-art EfficientNet on all latency targets by around 1% on ImageNet top-1 accuracy. Our method can reduce energy consumption of an edge accelerator by up to 2x under the same accuracy constraint, when co-adapting the model architecture and hardware accelerator configurations.
https://weibo.com/1402400261/K33I9kL9X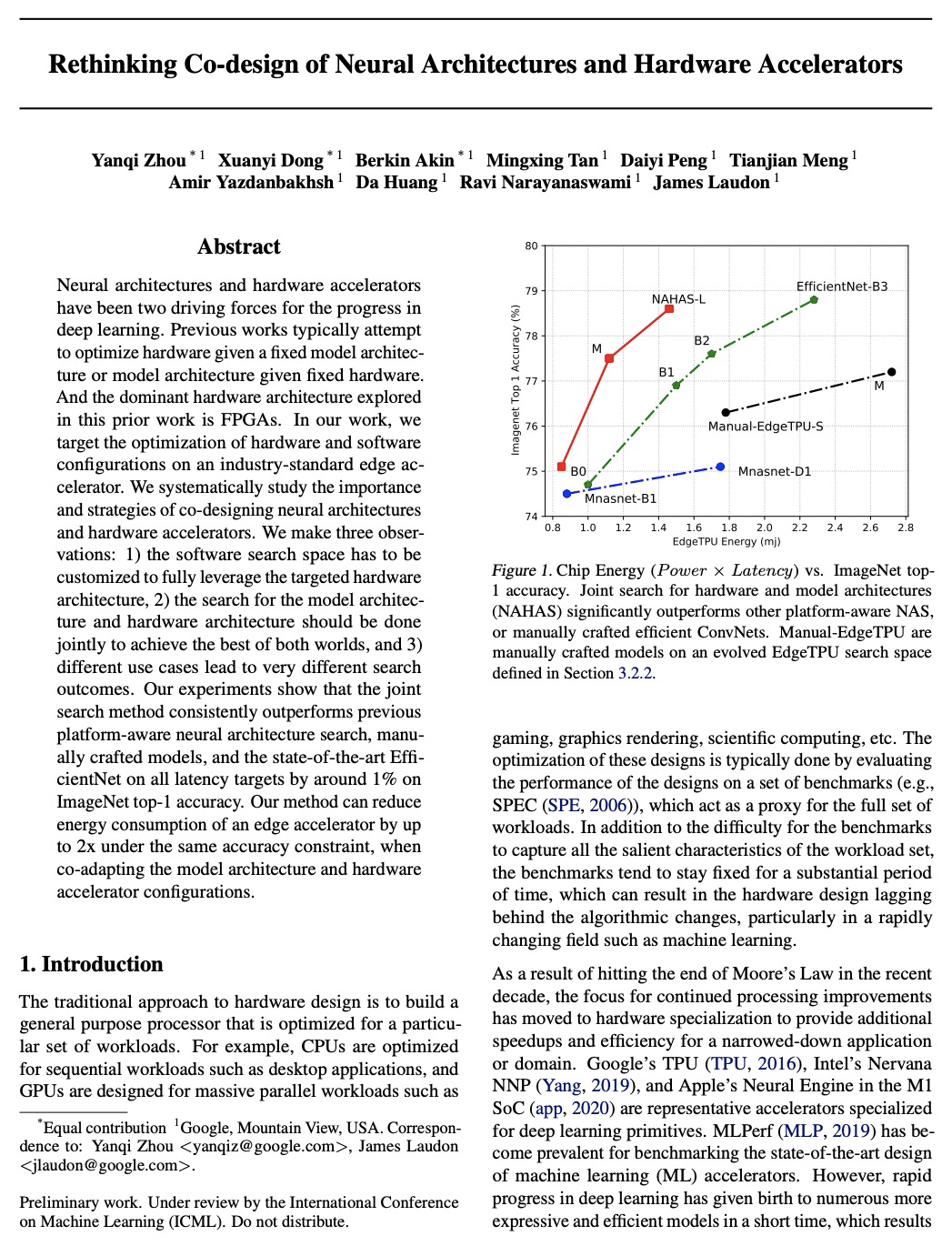
另外几篇值得关注的论文:
[CV] K-Hairstyle: A Large-scale Korean hairstyle dataset for virtual hair editing and hairstyle classification
K-Hairstyle:用于虚拟发型编辑和发型分类的大规模韩式发型数据集
T Kim, C Chung, S Park, G Gu, K Nam, W Choe, J Lee, J Choo
[KAIST & Nestyle & Smilegate AI & Aiinplanet]
https://weibo.com/1402400261/K33FxlEqu

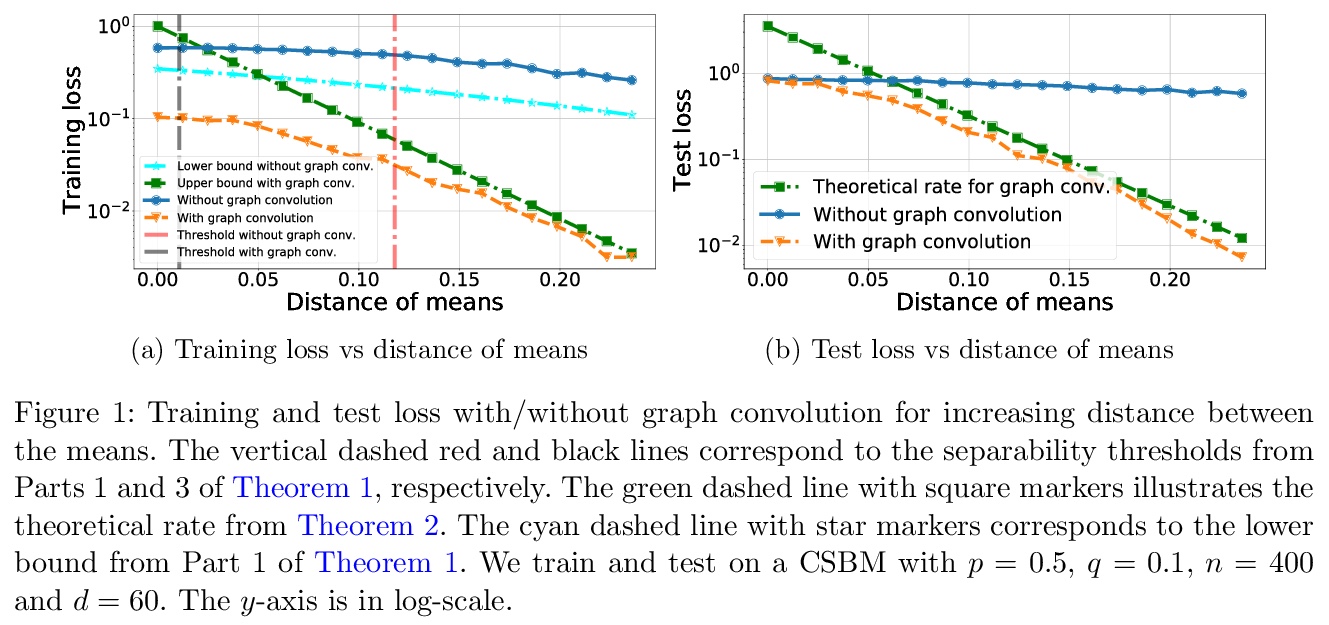
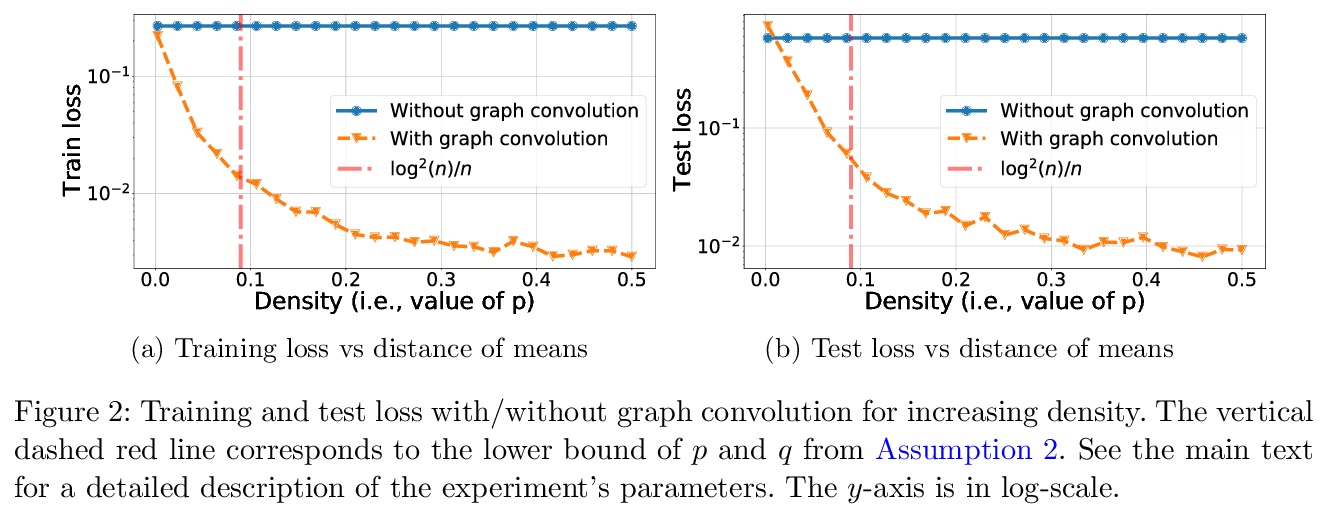
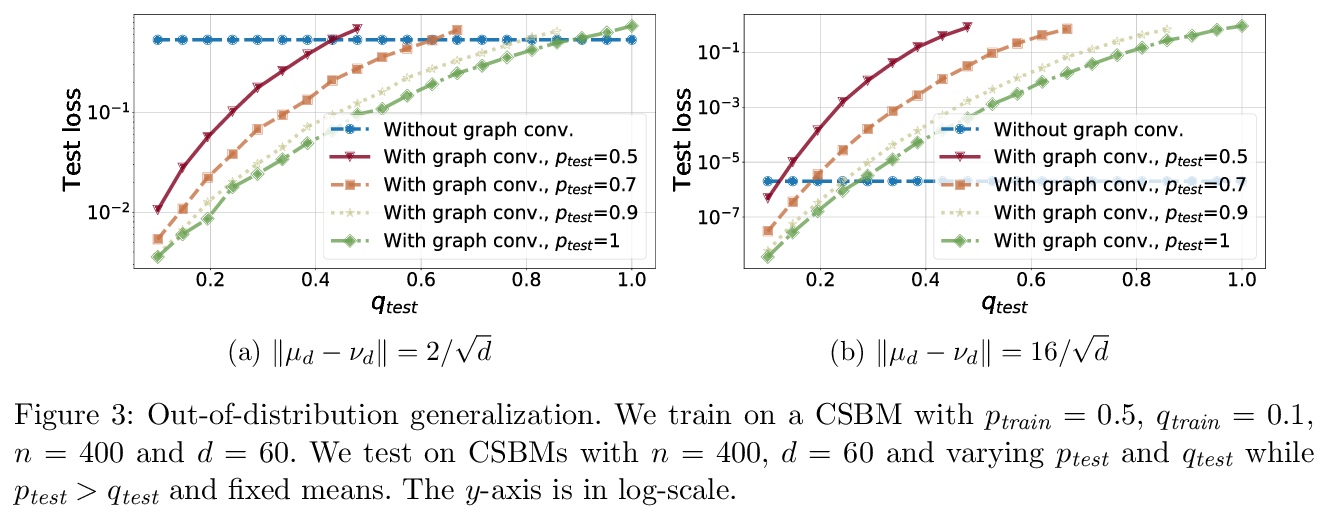
[LG] Graph Convolution for Semi-Supervised Classification: Improved Linear Separability and Out-of-Distribution Generalization
图卷积半监督分类:改进线性可分性和分布外泛化
A Baranwal, K Fountoulakis, A Jagannath
[University of Waterloo]
https://weibo.com/1402400261/K33LQxf8C
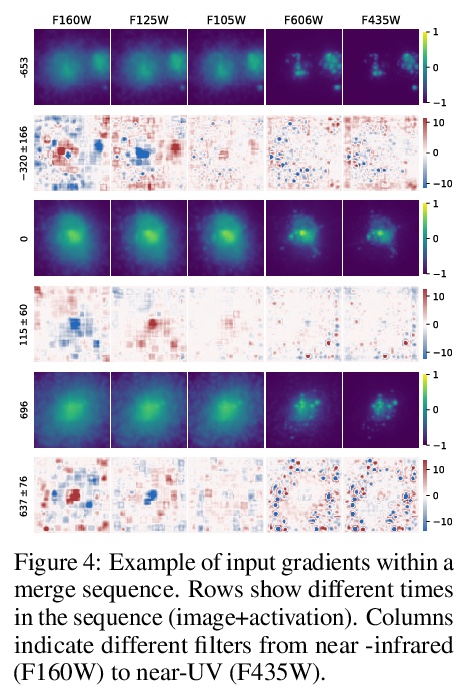
[LG] A Deep Learning Approach for Characterizing Major Galaxy Mergers
大星系合并阶段预测的深度学习方法
S Koppula, V Bapst, M Huertas-Company, S Blackwell, A Grabska-Barwinska, S Dieleman, A Huber, N Antropova, M Binkowski, H Openshaw, A Recasens, F Caro, A Deke, Y Dubois, J V Ferrero, D C. Koo, J R. Primack, T Back
[DeepMind & PSL Research University]
https://weibo.com/1402400261/K33NlC0KN



[LG] Geometric feature performance under downsampling for EEG classification tasks
下采样脑电分类任务几何特征性能
B Bischof, E Bunch
[Stitch Fix Algorithms & American Family Insurance]
https://weibo.com/1402400261/K33VcDzTA


若有收获,就点个赞吧
0 人点赞
