- LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
- 1、[LG] Graph-Based Deep Learning for Medical Diagnosis and Analysis: Past, Present and Future
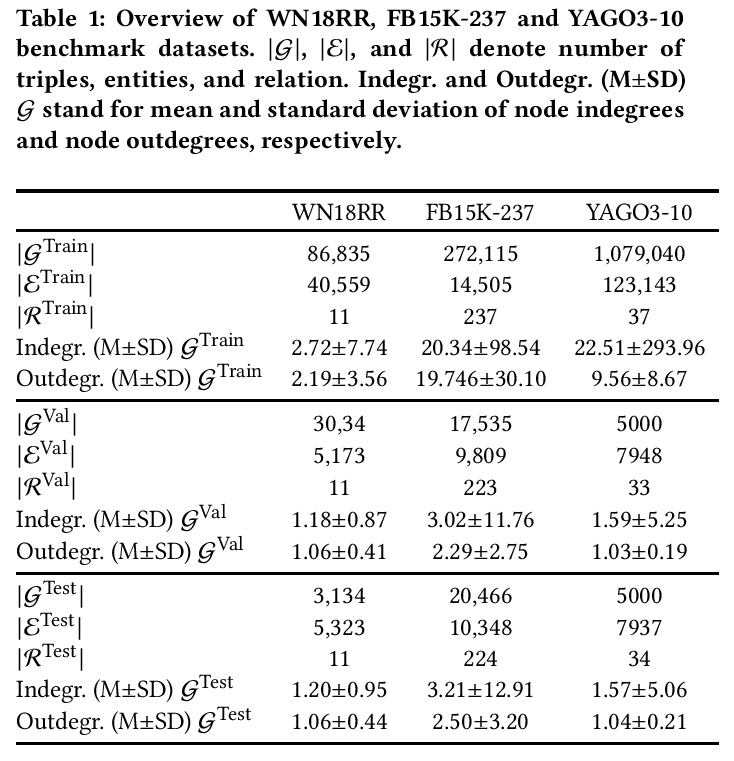
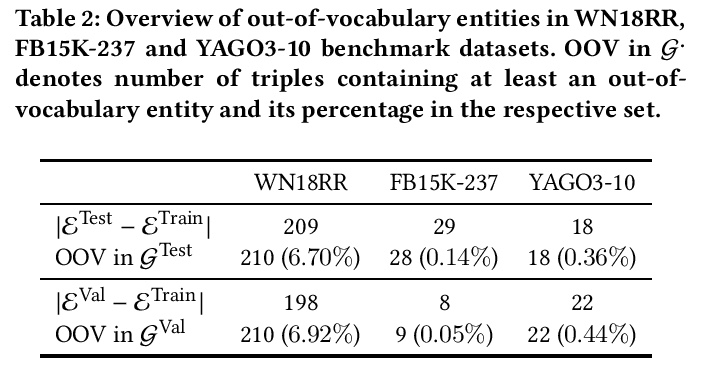
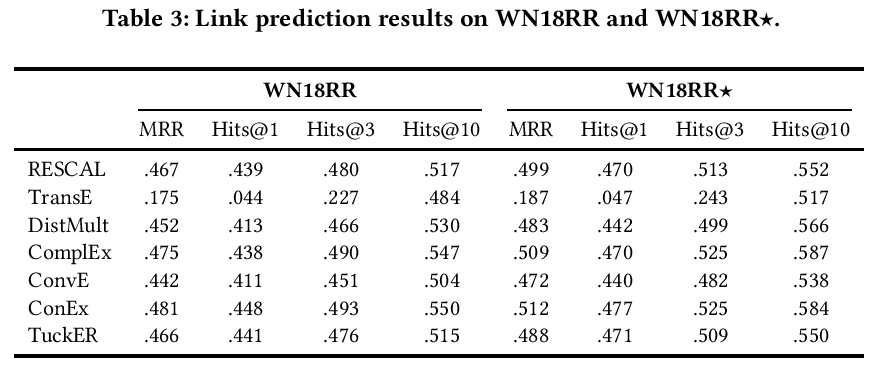
- 2、[LG] Out-of-Vocabulary Entities in Link Prediction
- 3、[CV] VS-Net: Voting with Segmentation for Visual Localization
- 4、[CL] Context-Sensitive Visualization of Deep Learning Natural Language Processing Models
- 5、[CV] Visual representation of negation: Real world data analysis on comic image design
- [CV] Act the Part: Learning Interaction Strategies for Articulated Object Part Discovery
- [CL] GraphFormers: GNN-nested Language Models for Linked Text Representation
- [CV] Few-Shot Video Object Detection
- [CV] Universal Weakly Supervised Segmentation by Pixel-to-Segment Contrastive Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] Graph-Based Deep Learning for Medical Diagnosis and Analysis: Past, Present and Future
D Ahmedt-Aristizabal, M A Armin, S Denman, C Fookes, L Petersson
[CSIRO & Queensland University of Technology]
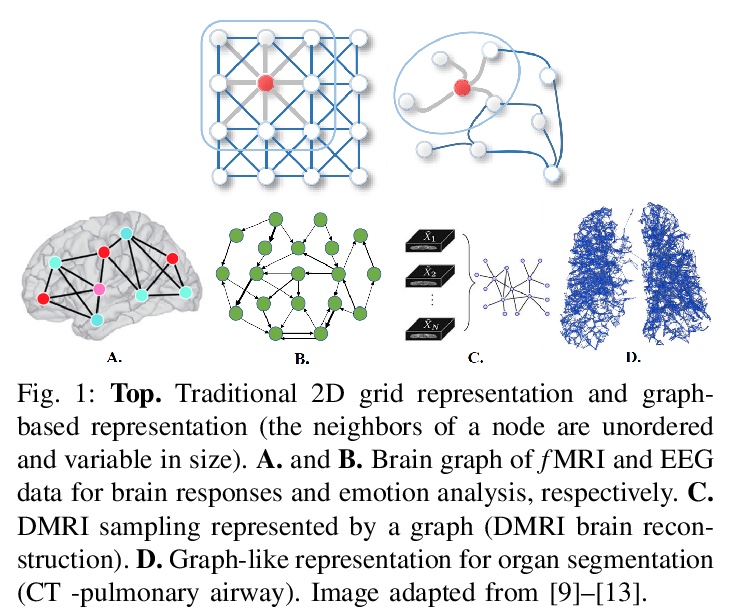
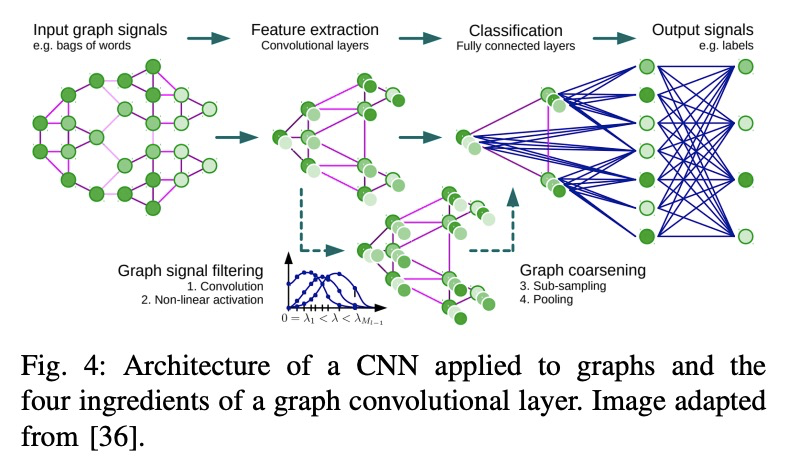
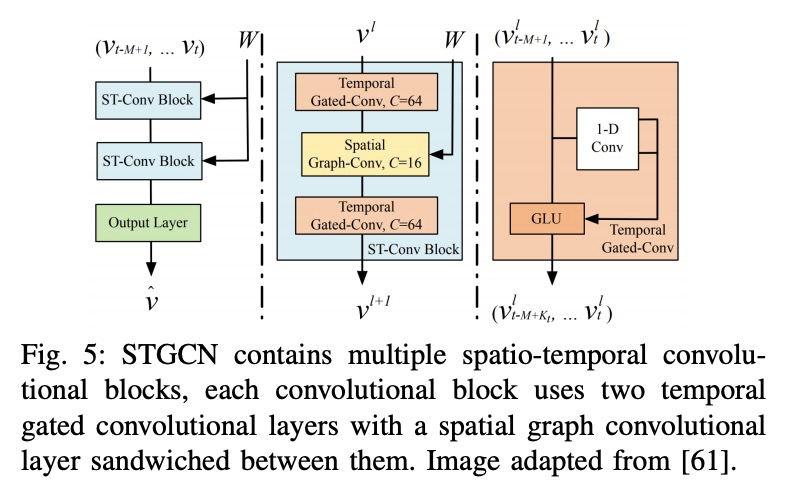
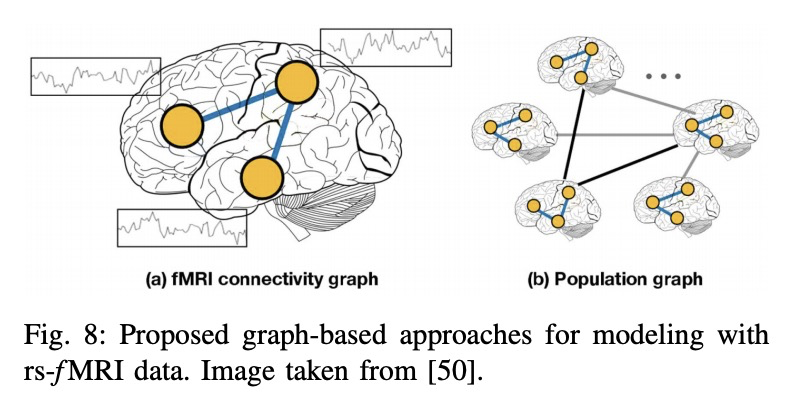
基于图深度学习的医学诊断与分析:过去、现在和未来。随着数据驱动的机器学习研究的进展,各种各样的预测问题被解决了。探索如何利用机器学习,特别是深度学习方法来分析医疗数据已成为关键。现有方法的一个主要限制,是对网格状数据的关注,而生理记录的结构往往是不规则和无序的,很难概念化为矩阵。图神经网络可利用生物系统中的隐含信息,引起了人们的极大关注,互动节点由边连接,权重可以是时间关联或解剖学连接。本综述彻底回顾了不同类型的图结构及其在医疗中的应用。以系统方式对这些方法进行了概述,并按其应用领域进行了组织,包括功能连接、解剖结构和电分析。还概述了现有技术的局限性并讨论了未来研究的潜在方向。
With the advances of data-driven machine learning research, a wide variety of prediction problems have been tackled. It has become critical to explore how machine learning and specifically deep learning methods can be exploited to analyse healthcare data. A major limitation of existing methods has been the focus on grid-like data; however, the structure of physiological recordings are often irregular and unordered which makes it difficult to conceptualise them as a matrix. As such, graph neural networks have attracted significant attention by exploiting implicit information that resides in a biological system, with interactive nodes connected by edges whose weights can be either temporal associations or anatomical junctions. In this survey, we thoroughly review the different types of graph architectures and their applications in healthcare. We provide an overview of these methods in a systematic manner, organized by their domain of application including functional connectivity, anatomical structure and electrical-based analysis. We also outline the limitations of existing techniques and discuss potential directions for future research.
https://weibo.com/1402400261/KhX01qHSQ
2、[LG] Out-of-Vocabulary Entities in Link Prediction
C Demir, A N Ngomo
[Paderborn University]
链接预测基准的词表外实体。知识图谱嵌入技术,是使知识图谱适用于基于向量表示的大量机器学习方法的关键。链接预测经常被用来作为评估这些嵌入质量的代理。鉴于创建链接预测基准是一项耗时的工作,关于这一主题的大多数工作只使用了少部分基准。由于基准对算法的公平比较至关重要,确保其质量就等于为开发更好的链接预测和嵌入知识图谱的解决方案提供了坚实的基础。之前的研究指出了与一些基准数据集的开发到测试片段的信息泄露有关的限制。本文发现了通常用于评估链接预测方法的三个基准的另一个共同限制:测试和验证集中的词表外实体,提供了一个发现和删除这些实体的方法的实现,并提供了数据集WN18RR、FB15K-237和YAGO310的修正版本。在WN18RR、FB15K237和YAGO3-10的修正版本上的实验表明,最先进的方法的测量性能发生了显著变化,P值分别为<1%、<1.4%和<1%。总的来说,最先进的方法在WN18RR的所有指标中平均获得了3.29±0.24%的绝对值。这意味着之前的工作中取得的一些结论可能需要重新审视。
Knowledge graph embedding techniques are key to making knowledge graphs amenable to the plethora of machine learning approaches based on vector representations. Link prediction is often used as a proxy to evaluate the quality of these embeddings. Given that the creation of benchmarks for link prediction is a time-consuming endeavor, most work on the subject matter uses only a few benchmarks. As benchmarks are crucial for the fair comparison of algorithms, ensuring their quality is tantamount to providing a solid ground for developing better solutions to link prediction and ipso facto embedding knowledge graphs. First studies of benchmarks pointed to limitations pertaining to information leaking from the development to the test fragments of some benchmark datasets. We spotted a further common limitation of three of the benchmarks commonly used for evaluating link prediction approaches: out-of-vocabulary entities in the test and validation sets. We provide an implementation of an approach for spotting and removing such entities and provide corrected versions of the datasets WN18RR, FB15K-237, and YAGO310. Our experiments on the corrected versions of WN18RR, FB15K237, and YAGO3-10 suggest that the measured performance of state-of-the-art approaches is altered significantly with p-values < 1%, < 1.4%, and < 1%, respectively. Overall, state-of-the-art approaches gain on average absolute 3.29 ± 0.24% in all metrics on WN18RR. This means that some of the conclusions achieved in previous works might need to be revisited. We provide an opensource implementation of our experiments and corrected datasets at https://github.com/dice-group/OOV-In-Link-Prediction.
https://weibo.com/1402400261/KhX2I8vAy
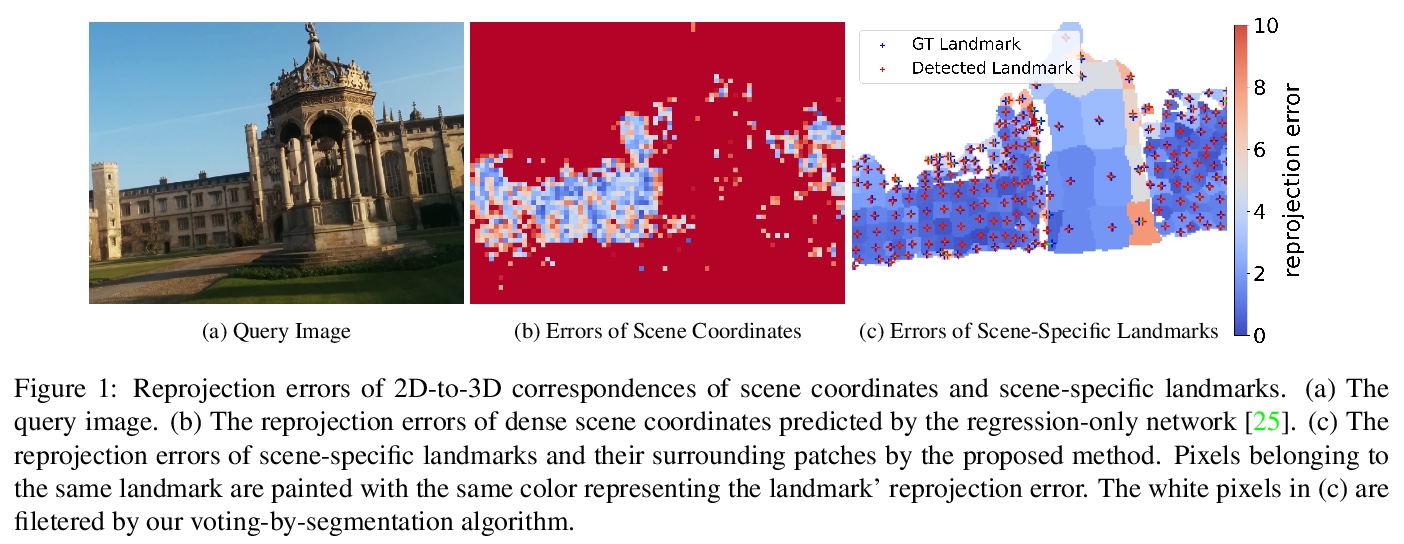
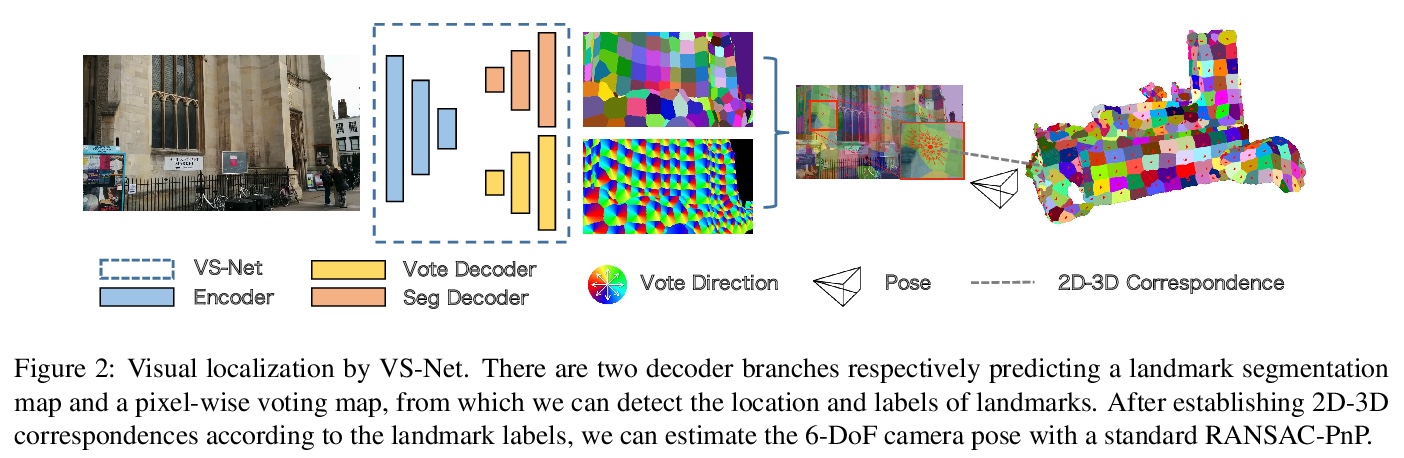
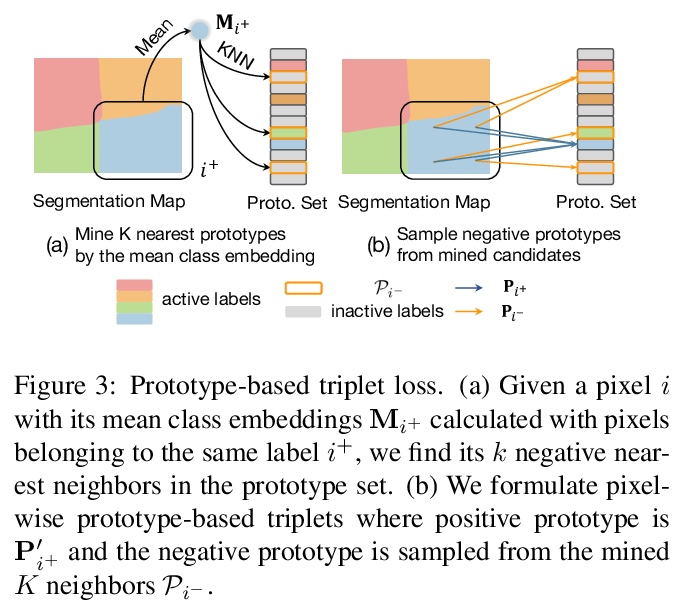
3、[CV] VS-Net: Voting with Segmentation for Visual Localization
Z Huang, H Zhou, Y Li, B Yang, Y Xu, X Zhou, H Bao, G Zhang, H Li
[Zhejiang University & The Chinese University of Hong Kong]
VS-Net: 面向视觉定位的分割投票。视觉定位对机器人和计算机视觉具有重要意义。最近,基于场景坐标回归的方法,在小型静态场景的视觉定位中表现出良好性能,但仍然从许多低质量场景坐标中估计摄像机的位置。为解决该问题,本文提出一种新的视觉定位框架,通过一系列可学习的场景特定地标,在查询图像和3D图之间建立2D到3D对应关系。在地标生成阶段,目标场景的3D表面叠加成马赛克块,其中心作为场景特定地标。为了鲁棒而准确地恢复场景特定地标,提出了分割网络投票法(VS-Net),用分割分支将像素分割成不同的地标块,用地标位置投票分支估计各块中地标位置。由于场景中的地标数量可能达到5000个,对于常用的交叉熵损失来说,用这么大数量的类来训练分割网络,既费计算又费内存,本文提出一种新的基于原型的三重损失与硬负挖掘,能有效地训练具有大量标签的语义分割网络。所提出的VS-Net在多个公共基准上进行了广泛的测试,其性能超越了目前最先进的视觉定位方法。
Visual localization is of great importance in robotics and computer vision. Recently, scene coordinate regression based methods have shown good performance in visual localization in small static scenes. However, it still estimates camera poses from many inferior scene coordinates. To address this problem, we propose a novel visual localization framework that establishes 2D-to-3D correspondences between the query image and the 3D map with a series of learnable scene-specific landmarks. In the landmark generation stage, the 3D surfaces of the target scene are oversegmented into mosaic patches whose centers are regarded as the scene-specific landmarks. To robustly and accurately recover the scene-specific landmarks, we propose the Voting with Segmentation Network (VS-Net) to segment the pixels into different landmark patches with a segmentation branch and estimate the landmark locations within each patch with a landmark location voting branch. Since the number of landmarks in a scene may reach up to 5000, training a segmentation network with such a large number of classes is both computation and memory costly for the commonly used cross-entropy loss. We propose a novel prototype-based triplet loss with hard negative mining, which is able to train semantic segmentation networks with a large number of labels efficiently. Our proposed VS-Net is extensively tested on multiple public benchmarks and can outperform stateof-the-art visual localization methods.
https://weibo.com/1402400261/KhX6zpYaO

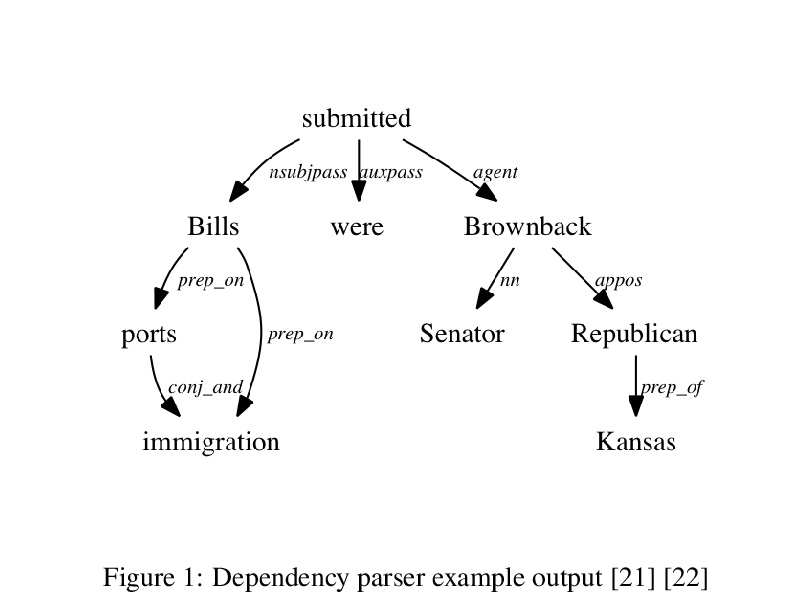
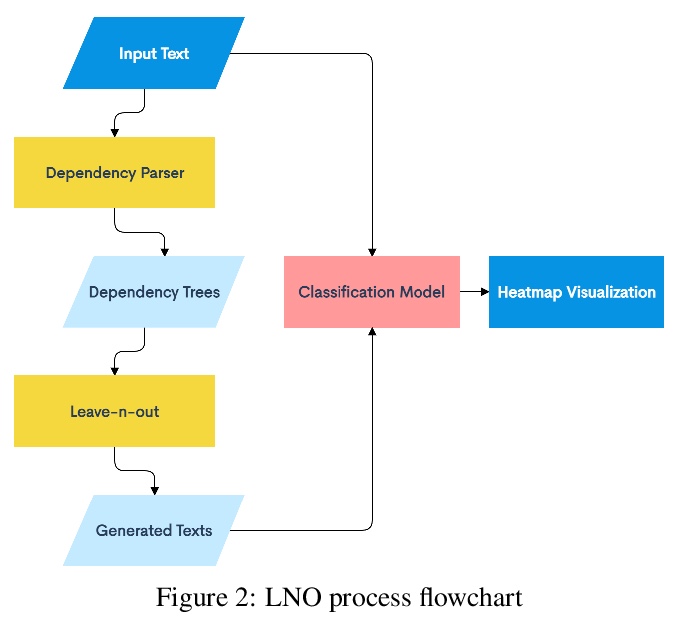
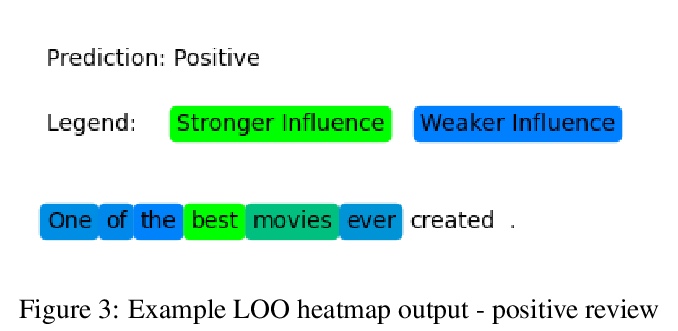
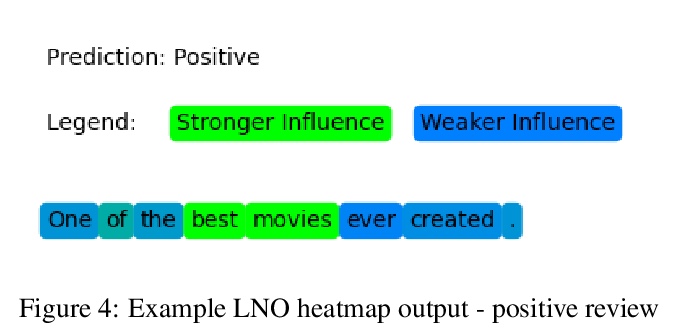
4、[CL] Context-Sensitive Visualization of Deep Learning Natural Language Processing Models
A Dunn, D Inkpen, R Andonie
[Central Washington University & University of Ottawa]
深度学习自然语言处理模型的上下文敏感可视化。过去几年,Transformer神经网络的引入,改变了自然语言处理(NLP)的面貌。到目前为止,还没有一种可视化系统,能检查Transformer的各个方面。本文提出一种新的面向NLP的Transformer上下文敏感可视化方法,利用现有的NLP工具,找到对输出影响最大的最重要的标记(词)组,从而保留原始文本的一些背景。首先,用一个句子级的依赖性分析器来突出有希望的词组。依赖性分析器在句子中的单词之间建立了一个关系树。接下来,系统地从输入文本中删除相邻和不相邻的n个标记组,产生几个缺少这些标记的新文本。将产生的文本传递给一个预训练的BERT模型。分类输出与完整文本的输出相比较,并记录激活强度的差异。选择在目标分类输出神经元中产生最大差异的修改后文本,然后认为被删除的单词组合对模型的输出影响最大。最后,最具影响力的单词组合被可视化为热图。
The introduction of Transformer neural networks has changed the landscape of Natural Language Processing (NLP) during the last years. So far, none of the visualization systems has yet managed to examine all the facets of the Transformers. This gave us the motivation of the current work. We propose a new NLP Transformer context-sensitive visualization method that leverages existing NLP tools to find the most significant groups of tokens (words) that have the greatest effect on the output, thus preserving some context from the original text. First, we use a sentence-level dependency parser to highlight promising word groups. The dependency parser creates a tree of relationships between the words in the sentence. Next, we systematically remove adjacent and non-adjacent tuples of n tokens from the input text, producing several new texts with those tokens missing. The resulting texts are then passed to a pre-trained BERT model. The classification output is compared with that of the full text, and the difference in the activation strength is recorded. The modified texts that produce the largest difference in the target classification output neuron are selected, and the combination of removed words are then considered to be the most influential on the model’s output. Finally, the most influential word combinations are visualized in a heatmap.
https://weibo.com/1402400261/KhXbb9r07
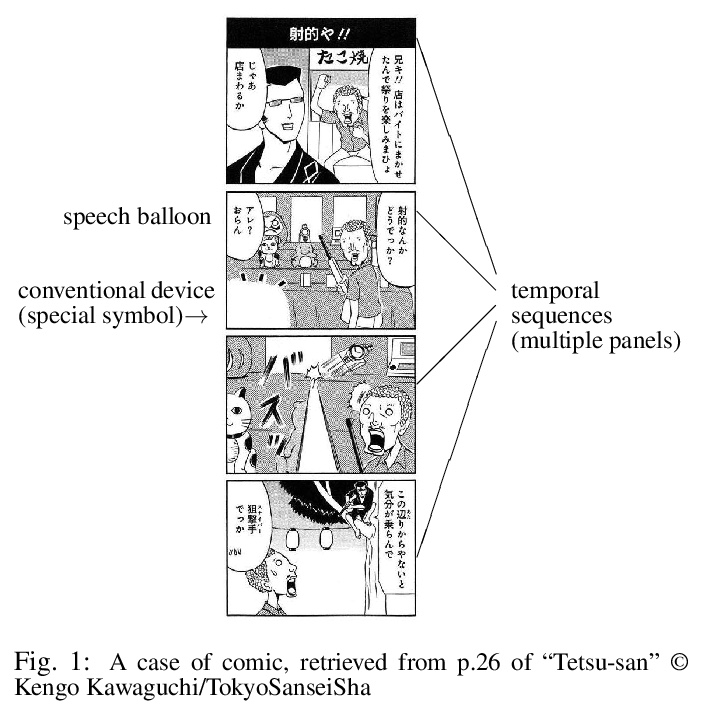
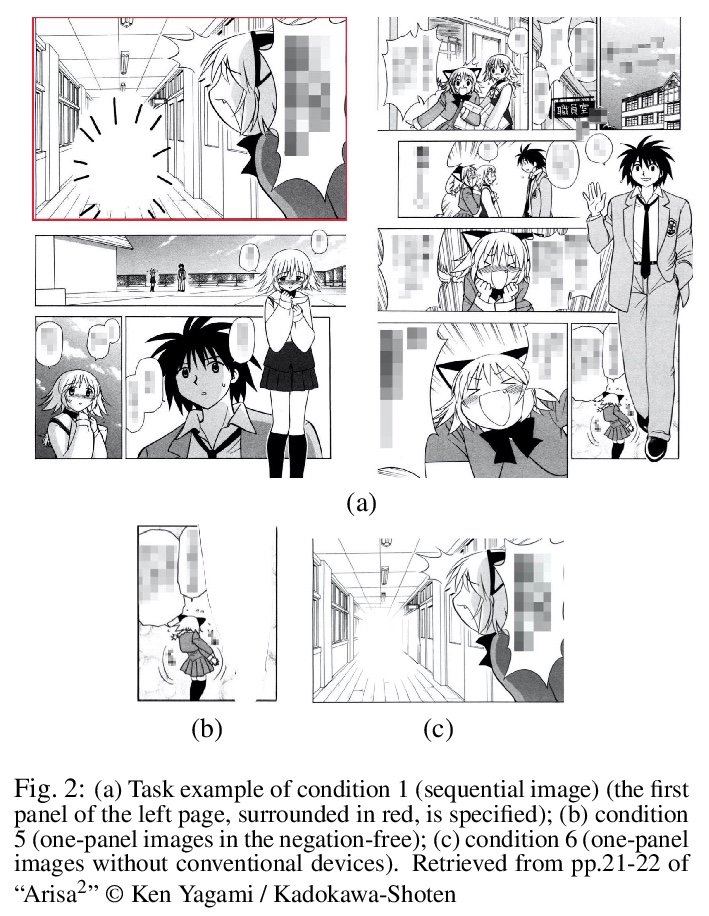
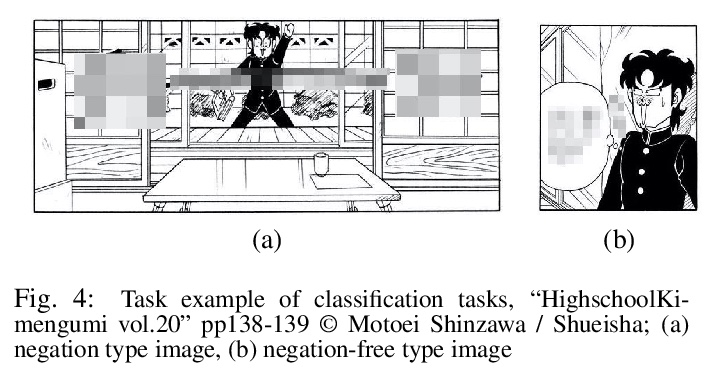
5、[CV] Visual representation of negation: Real world data analysis on comic image design
Y Sato, K Mineshima, K Ueda
[The University of Tokyo & Keio University]
否定的视觉表示:漫画图像设计的真实世界数据分析。一直以来,人们普遍认为视觉表征(如照片和插图)并不描述否定,这一观点通过分析现实世界的视觉表征的漫画(manga)插图受到了经验上的挑战。在使用图像说明任务的实验中,给人们提供漫画插图,并要求他们解释能从中读出什么。收集到的数据显示,一些漫画插图可以在没有任何序列(多板块)或常规设备(特殊符号)的帮助下描绘出否定句。对这种类型的漫画插图进行了进一步的实验,将图像分为含有否定词和不含否定词的图像。虽然这种图像分类对人类来说很容易,但对数据驱动的机器,即深度学习模型(CNN)来说,却很难达到同样高的性能。鉴于这些发现,本文认为一些漫画插图能唤起背景知识,因此可以用纯粹的视觉元素来描绘否定句。
There has been a widely held view that visual representations (e.g., photographs and illustrations) do not depict negation, for example, one that can be expressed by a sentence “the train is not coming”. This view is empirically challenged by analyzing the real-world visual representations of comic (manga) illustrations. In the experiment using image captioning tasks, we gave people comic illustrations and asked them to explain what they could read from them. The collected data showed that some comic illustrations could depict negation without any aid of sequences (multiple panels) or conventional devices (special symbols). This type of comic illustrations was subjected to further experiments, classifying images into those containing negation and those not containing negation. While this image classification was easy for humans, it was difficult for data-driven machines, i.e., deep learning models (CNN), to achieve the same high performance. Given the findings, we argue that some comic illustrations evoke background knowledge and thus can depict negation with purely visual elements.
https://weibo.com/1402400261/KhXdztvqK

另外几篇值得关注的论文:
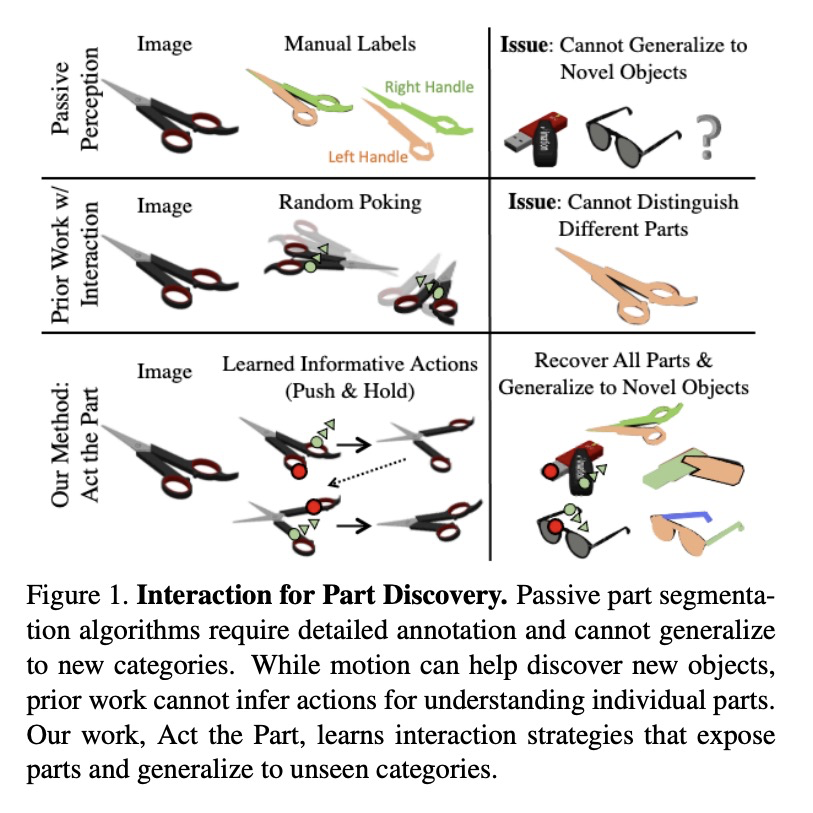
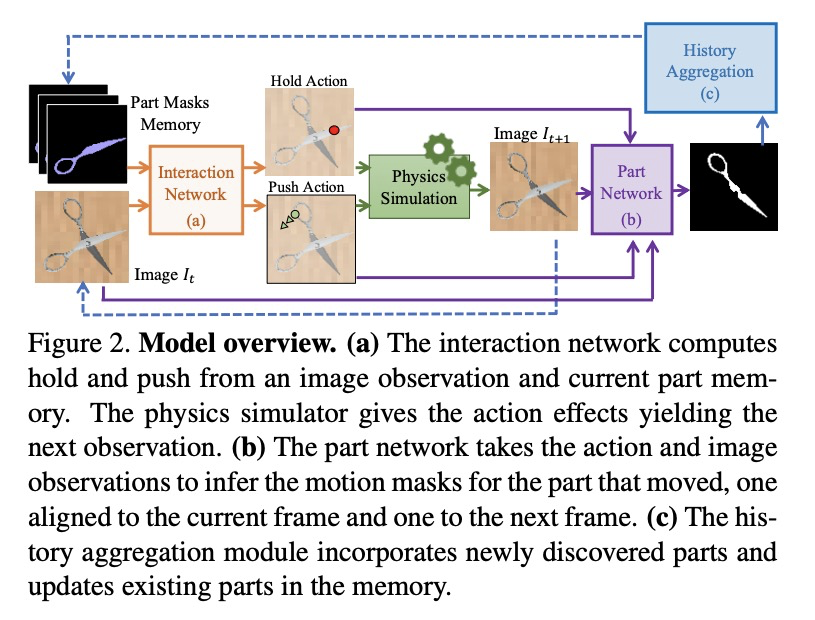
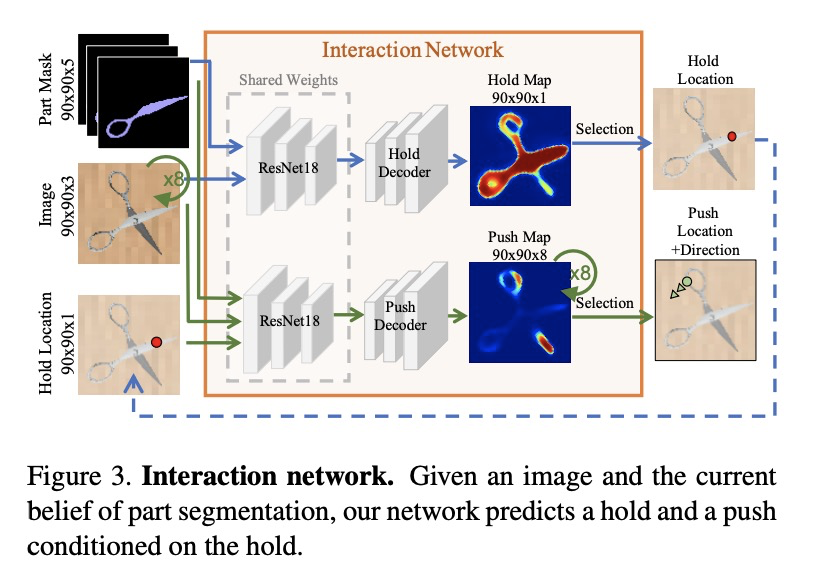
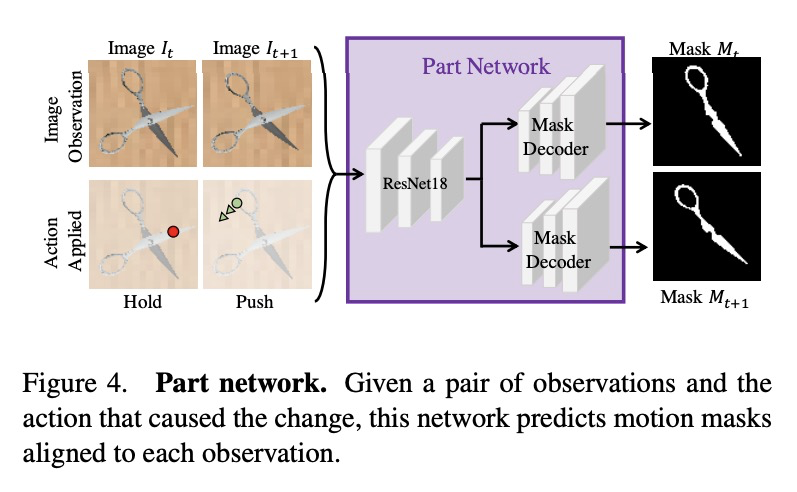
[CV] Act the Part: Learning Interaction Strategies for Articulated Object Part Discovery
Act the Part:关节式对象部件发现的交互策略学习
S Y Gadre, K Ehsani, S Song
[Columbia University & Allen Institute for AI]
https://weibo.com/1402400261/KhXh7pQ7w
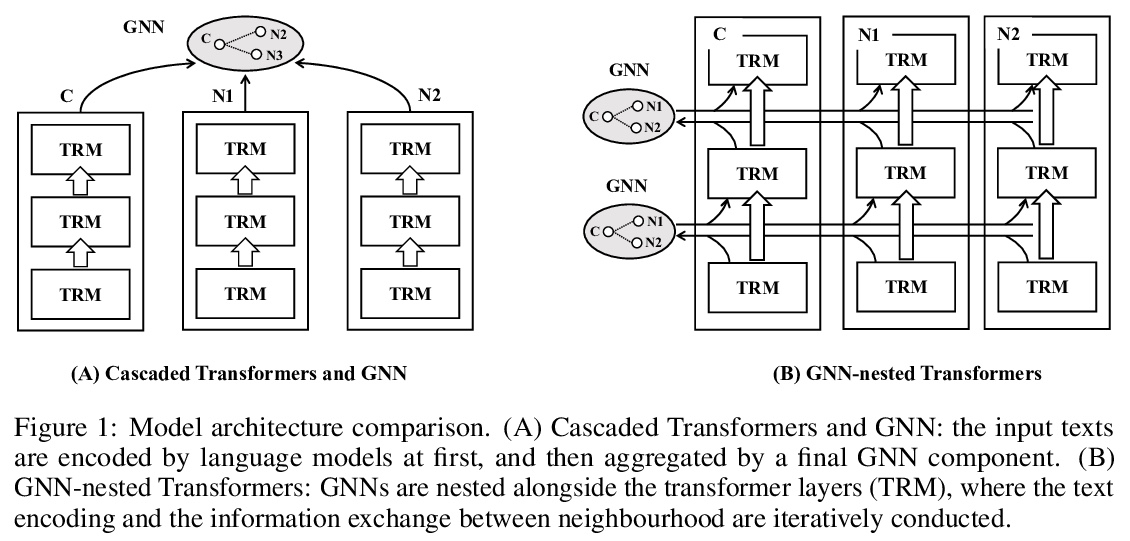
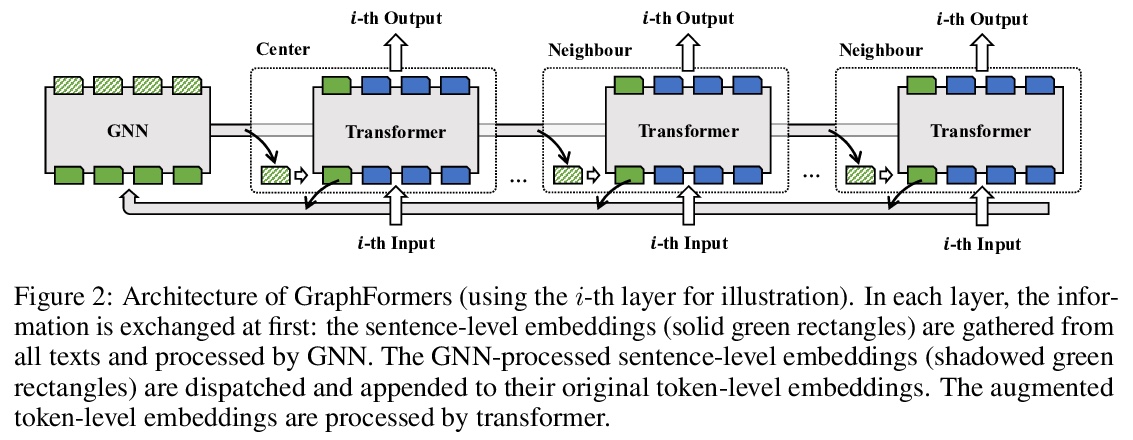
[CL] GraphFormers: GNN-nested Language Models for Linked Text Representation
GraphFormers:面向链接文本表示的GNN嵌套语言模型
J Yang, Z Liu, S Xiao, C Li, G Sun, X Xie
[Microsoft Research Asia & University of Science and Technology of China]
https://weibo.com/1402400261/KhXiYEfgz
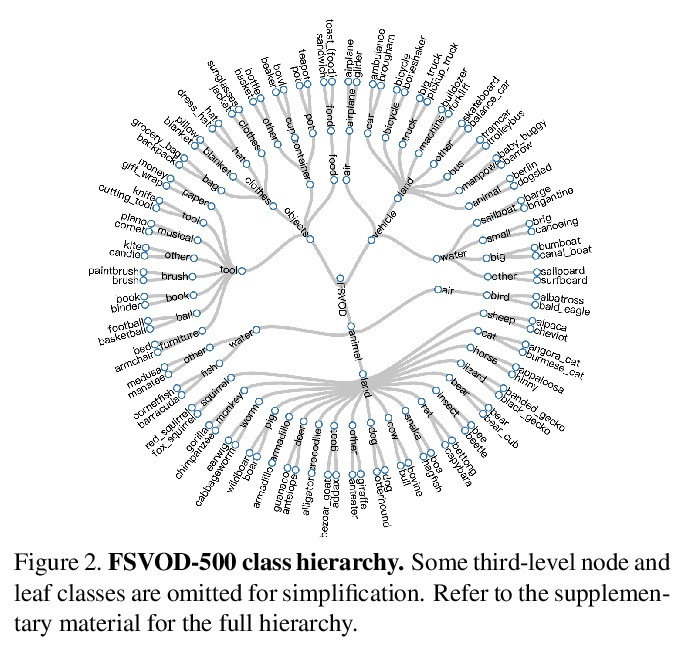
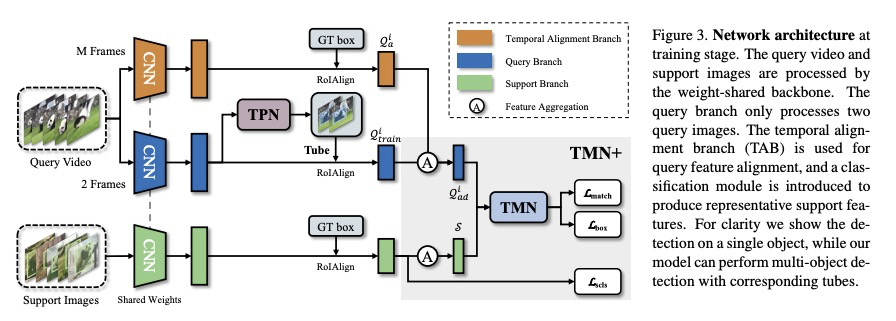
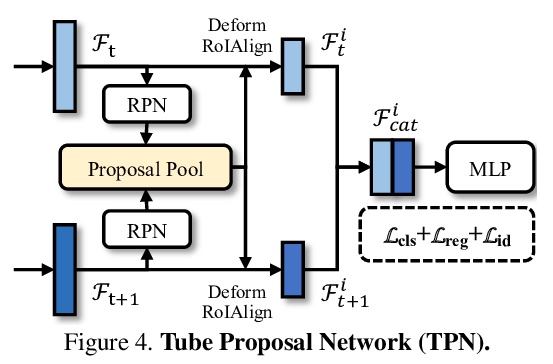
[CV] Few-Shot Video Object Detection
少样本视频目标检测
Q Fan, C Tang, Y Tai
[HKUST]
https://weibo.com/1402400261/KhXko41i3

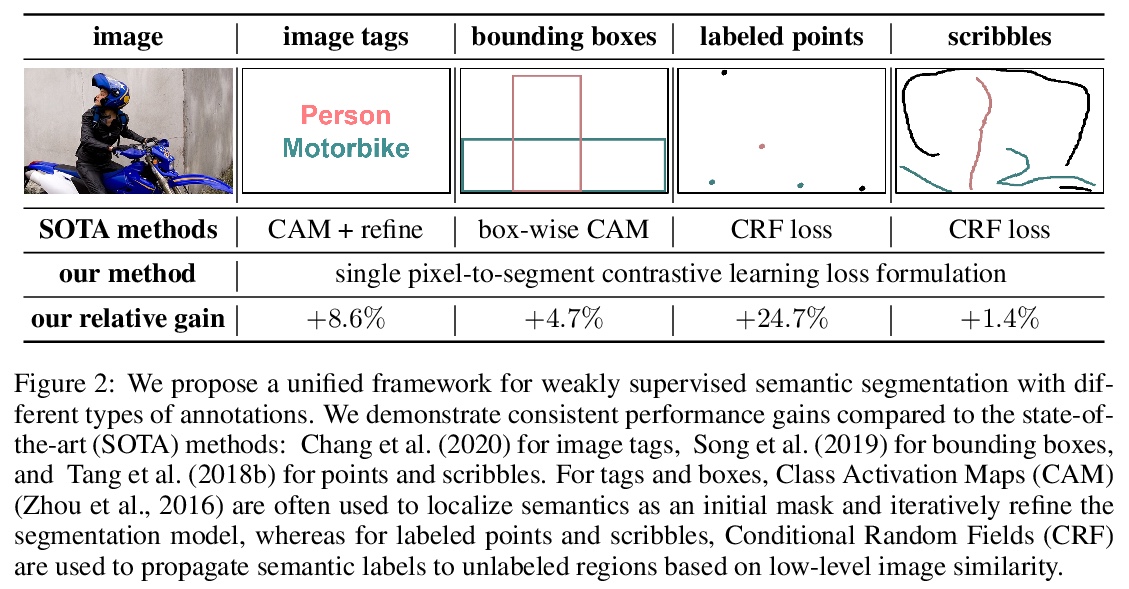
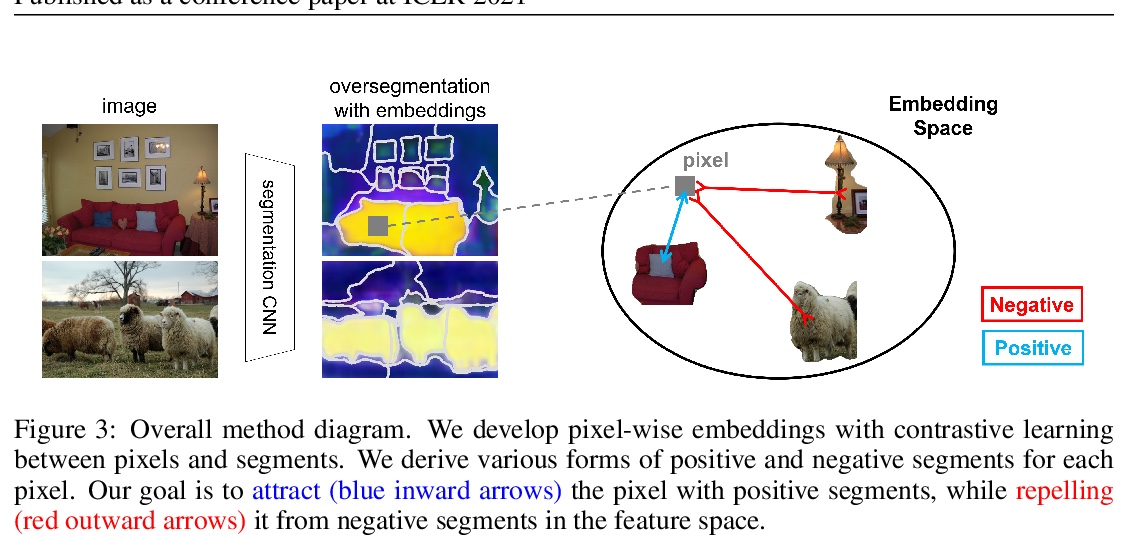
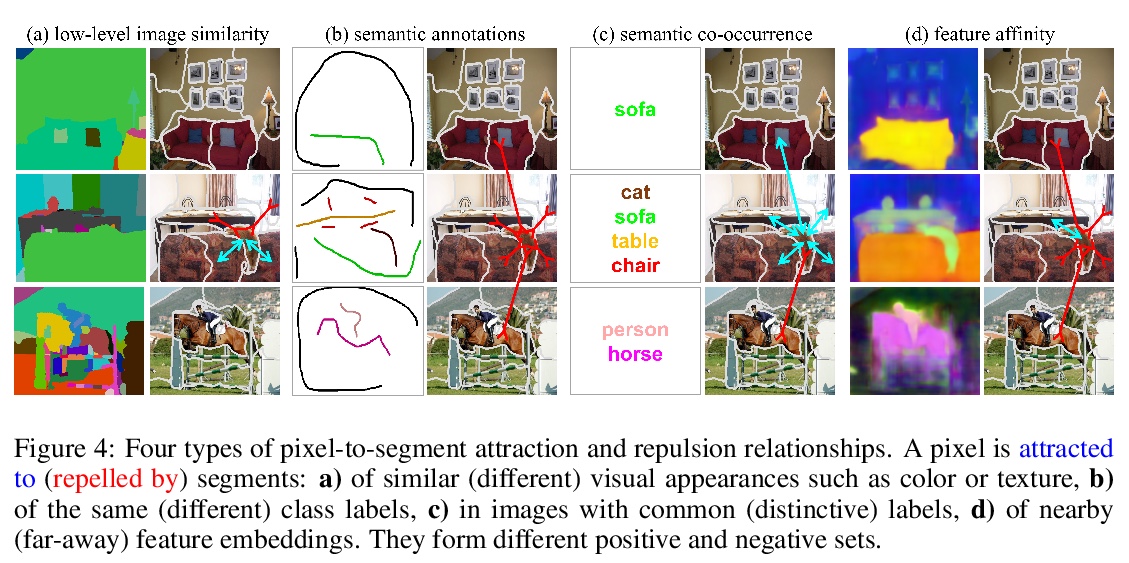
[CV] Universal Weakly Supervised Segmentation by Pixel-to-Segment Contrastive Learning
基于像素-片段对比学习的通用弱监督分割
T Ke, J Hwang, S X. Yu
[UC Berkeley]
https://weibo.com/1402400261/KhXmjuYW4


若有收获,就点个赞吧
0 人点赞
