- 1、[LG] Information-theoretic bounds on quantum advantage in machine learning
- 2、[CV] TrackFormer: Multi-Object Tracking with Transformers
- 3、[CV] GAN-Control: Explicitly Controllable GANs
- 4、[SI] Disentangling homophily, community structure and triadic closure in networks
- 5、[CV] PVA: Pixel-aligned Volumetric Avatars
- [CV] Self-Attention Based Context-Aware 3D Object Detection
- [IR] Towards Meaningful Statements in IR Evaluation. Mapping Evaluation Measures to Interval Scales
- [LG] Distribution-Free, Risk-Controlling Prediction Sets
- [CV] L2PF — Learning to Prune Faster
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Information-theoretic bounds on quantum advantage in machine learning
H Huang, R Kueng, J Preskill
[Institute for Quantum Information and Matter, Caltech & Johannes Kepler University Linz]
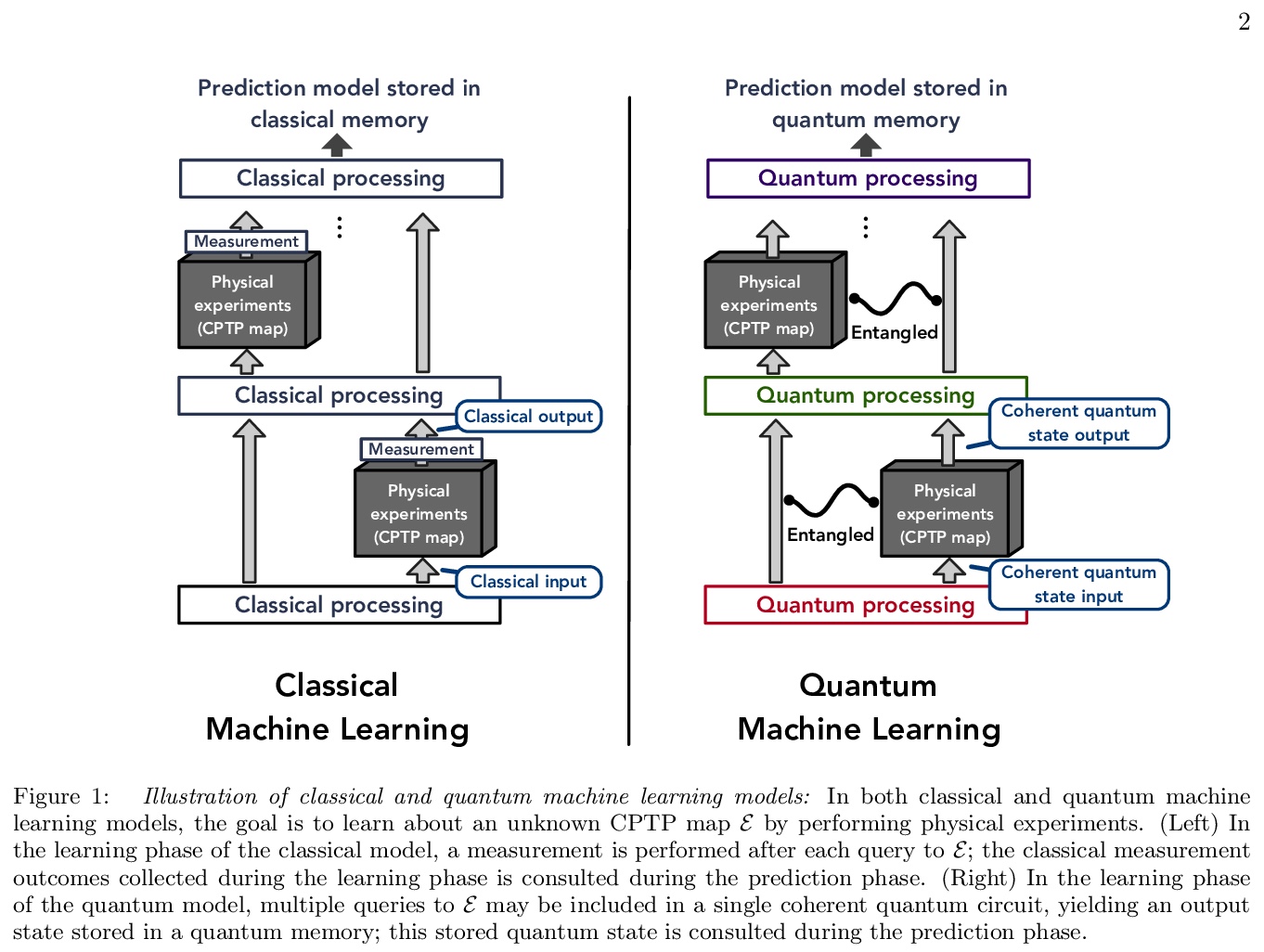
机器学习中量子计算优越性(量子霸权)的信息论约束。比较了量子机器学习和经典机器学习在预测量子实验结果方面的优劣。量子机器学习在训练期间获取量子数据,用量子计算机进行预测,而经典机器学习用训练期间获得的经典测量数据进行预测。文中表明,如果用训练期间的运行次数作为度量指标,量子机器学习并不比经典机器学习有太大优势。经典机器学习模型每次运行后,都会执行一次测量并记录经典结果,而量子机器学习模型可以连续访问以获取量子数据,用经典数据或量子数据来预测未来量子实验的结果。对于任意输入分布,经典机器学习模型通过与最优量子机器学习模型相当的访问次数,也能提供准确的预测,用量子测量数据训练的经典机器学习可以出人意料地强大。在经典机器学习的协助下,最新的实验平台可以很有效地解决物理、化学和材料科学中具有挑战性的量子问题;对于某些问题,如果目标是实现指定的最坏情况预测误差,量子机器学习可以比经典机器学习具有指数级的优势。
https://weibo.com/1402400261/JCjJMzZa2
2、[CV] TrackFormer: Multi-Object Tracking with Transformers
T Meinhardt, A Kirillov, L Leal-Taixe, C Feichtenhofer
[Technical University of Munich & Facebook AI Research (FAIR)]
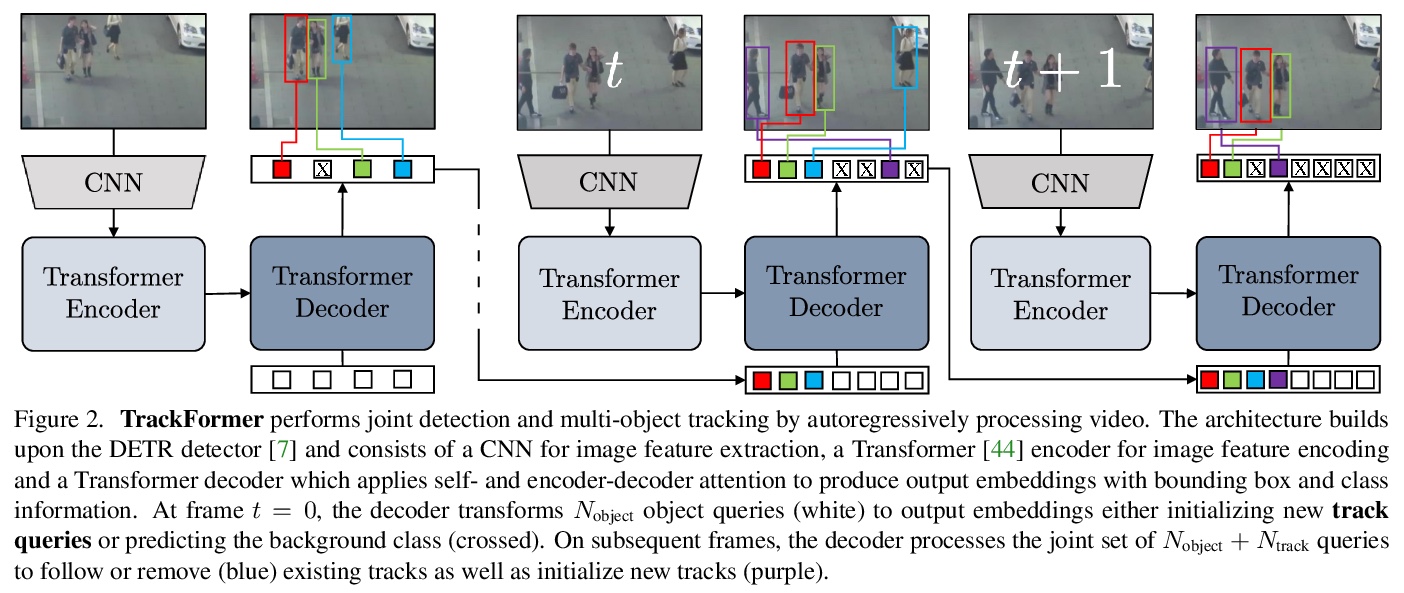
TrackFormer: 基于Transformer的多目标追踪。提出一种基于编码器-解码器Transformer架构实现的端到端多目标追踪和分割模型TrackFormer,引入了追踪查询嵌入,以自回归方式在序列上追踪目标。Transformer编码器-解码器架构在新的注意力追踪范式中,实现了帧之间的无缝数据关联,通过自注意力和编码器-解码器注意力机制,同时推理位置、遮挡和目标身份;将每个轨迹查询转换为其对应目标的位置变化,仅通过注意力操作来关联时变轨迹,而不依赖于其他额外的匹配、图优化、运动或外观建模。TrackFormer在多目标追踪及分割方面取得了最先进结果。
We present TrackFormer, an end-to-end multi-object tracking and segmentation model based on an encoder-decoder Transformer architecture. Our approach introduces track query embeddings which follow objects through a video sequence in an autoregressive fashion. New track queries are spawned by the DETR object detector and embed the position of their corresponding object over time. The Transformer decoder adjusts track query embeddings from frame to frame, thereby following the changing object positions. TrackFormer achieves a seamless data association between frames in a new tracking-by-attention paradigm by self- and encoder-decoder attention mechanisms which simultaneously reason about location, occlusion, and object identity. TrackFormer yields state-of-the-art performance on the tasks of multi-object tracking (MOT17) and segmentation (MOTS20). We hope our unified way of performing detection and tracking will foster future research in multi-object tracking and video understanding. Code will be made publicly available.
https://weibo.com/1402400261/JCjXHqgqu

3、[CV] GAN-Control: Explicitly Controllable GANs
A Shoshan, N Bhonker, I Kviatkovsky, G Medioni
[Amazon One]
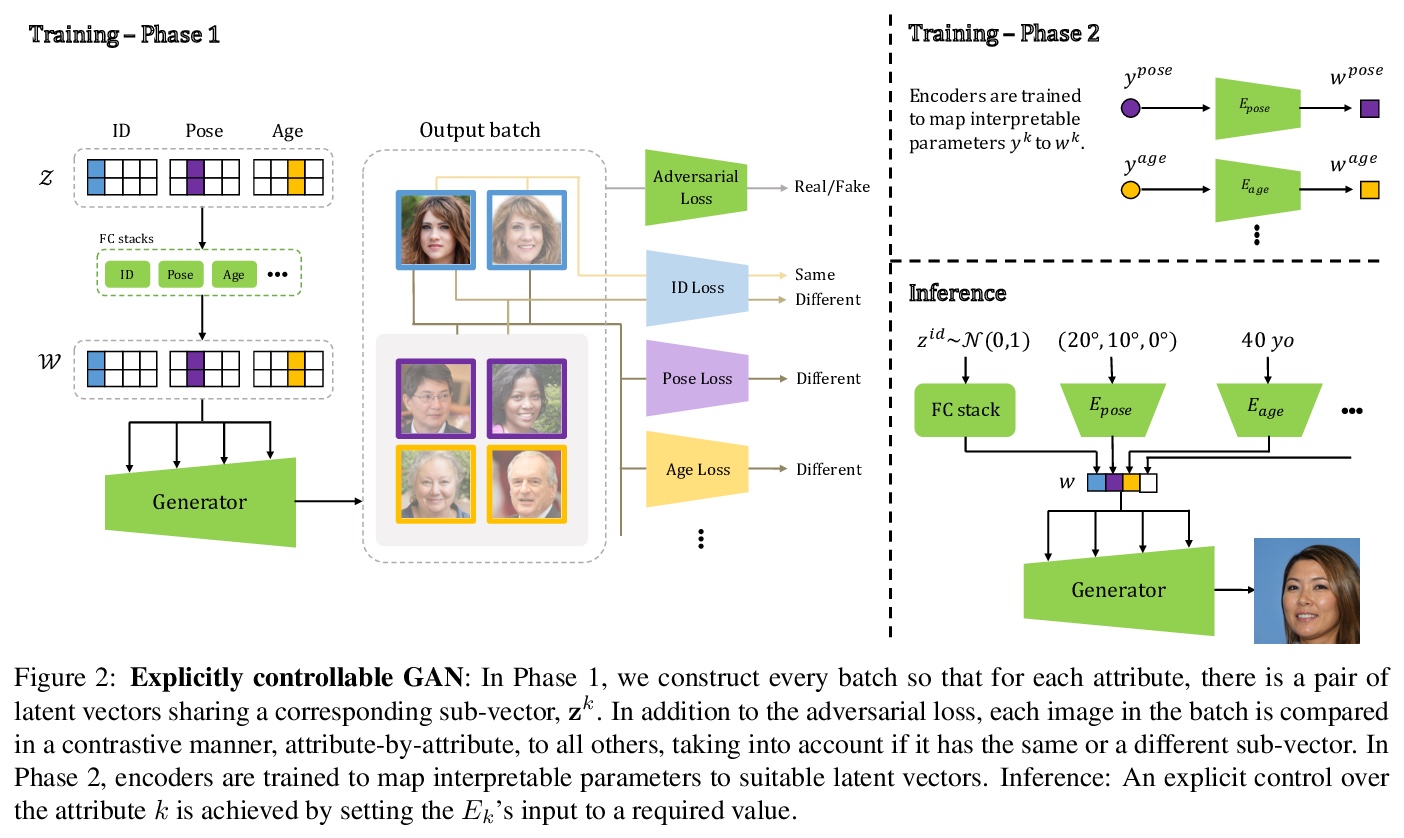
GAN-Control:显式可控GAN。提出能显式控制生成图像的GAN解缠式训练框架,可通过显式设置属性来控制生成图像,如年龄、姿势、表情等。通过对比学习,获得具有显式解缠潜空间的GAN,该解缠被用来训练控制编码器,将人工可解释的输入映射到合适的潜向量,从而实现显式控制。将可显式控制GAN的适用性扩展到了人脸以外的其他领域,在质量和数量上都达到了最先进的性能。
We present a framework for training GANs with explicit control over generated images. We are able to control the generated image by settings exact attributes such as age, pose, expression, etc. Most approaches for editing GAN-generated images achieve partial control by leveraging the latent space disentanglement properties, obtained implicitly after standard GAN training. Such methods are able to change the relative intensity of certain attributes, but not explicitly set their values. Recently proposed methods, designed for explicit control over human faces, harness morphable 3D face models to allow fine-grained control capabilities in GANs. Unlike these methods, our control is not constrained to morphable 3D face model parameters and is extendable beyond the domain of human faces. Using contrastive learning, we obtain GANs with an explicitly disentangled latent space. This disentanglement is utilized to train control-encoders mapping human-interpretable inputs to suitable latent vectors, thus allowing explicit control. In the domain of human faces we demonstrate control over identity, age, pose, expression, hair color and illumination. We also demonstrate control capabilities of our framework in the domains of painted portraits and dog image generation. We demonstrate that our approach achieves state-of-the-art performance both qualitatively and quantitatively.
https://weibo.com/1402400261/JCk4xawbf

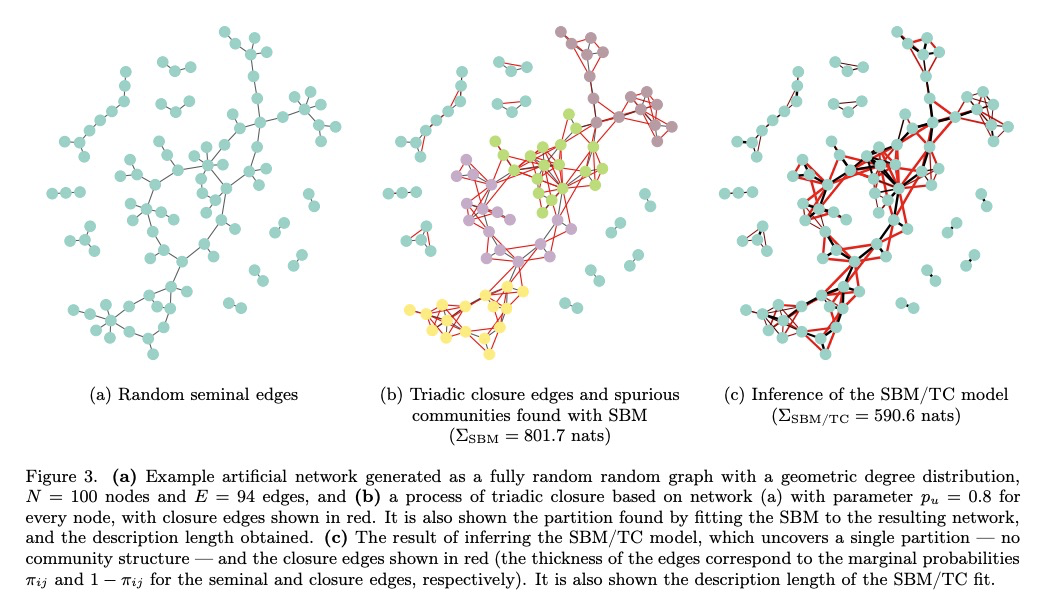
4、[SI] Disentangling homophily, community structure and triadic closure in networks
T P. Peixoto
[Central European University]
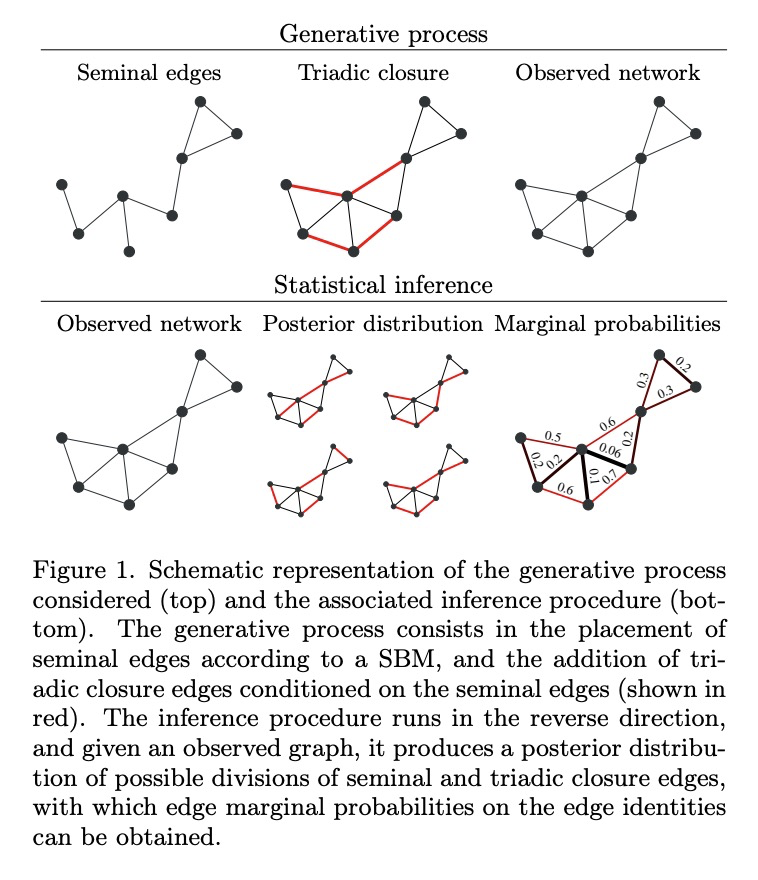
网络中同质性、社群结构和三元闭合的解离。提出一种生成模型和相应的推理方案,可区分经验网络中的社群结构和三元闭合,基于随机块模型(SBM)变体,增加了三元闭合边,其推理可识别出除底层社群结构本身之外,导致网络中每条边存在的最合理机制,能明显提高链路预测性能。
Network homophily, the tendency of similar nodes to be connected, and transitivity, the tendency of two nodes being connected if they share a common neighbor, are conflated properties in network analysis, since one mechanism can drive the other. Here we present a generative model and corresponding inference procedure that is capable of distinguishing between both mechanisms. Our approach is based on a variation of the stochastic block model (SBM) with the addition of triadic closure edges, and its inference can identify the most plausible mechanism responsible for the existence of every edge in the network, in addition to the underlying community structure itself. We show how the method can evade the detection of spurious communities caused solely by the formation of triangles in the network, and how it can improve the performance of link prediction when compared to the pure version of the SBM without triadic closure.
https://weibo.com/1402400261/JCkdK56t5

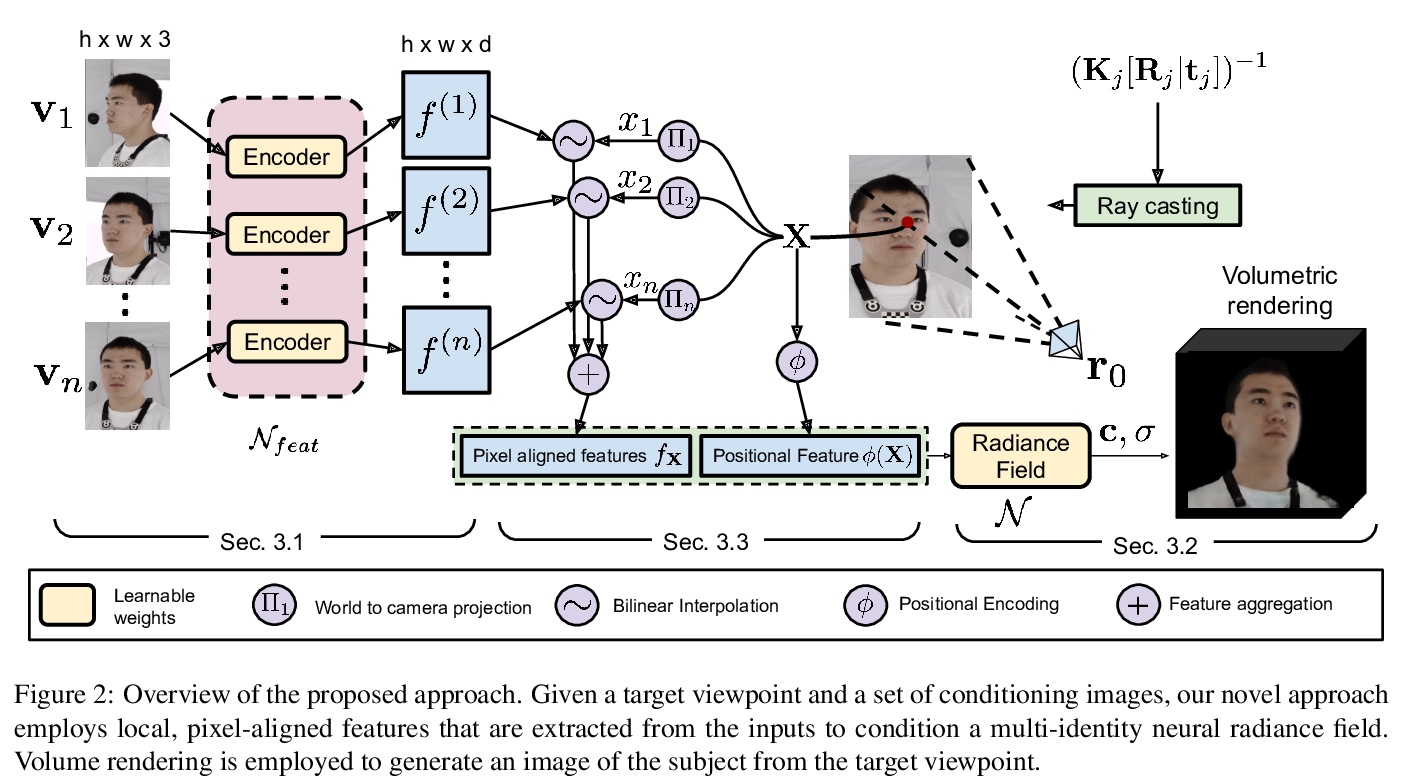
5、[CV] PVA: Pixel-aligned Volumetric Avatars
A Raj, M Zollhoefer, T Simon, J Saragih, S Saito, J Hays, S Lombardi
[Georgia Institute of Technology & Facebook Reality Labs]
PVA:像素对齐体头像。为解决采集和渲染逼真头部的问题,提出了用于仅给定少量输入预测体头像的PVA方法,通过一种新的参数化,将神经辐射场与直接从输入中提取的局部、像素对齐特征相结合,实现了跨身份泛化,避免了对非常深或复杂网络的需求。PVA以端到端方式进行训练,完全基于光重渲染损失,不需要显式的3D监督。
Acquisition and rendering of photo-realistic human heads is a highly challenging research problem of particular importance for virtual telepresence. Currently, the highest quality is achieved by volumetric approaches trained in a person specific manner on multi-view data. These models better represent fine structure, such as hair, compared to simpler mesh-based models. Volumetric models typically employ a global code to represent facial expressions, such that they can be driven by a small set of animation parameters. While such architectures achieve impressive rendering quality, they can not easily be extended to the multi-identity setting. In this paper, we devise a novel approach for predicting volumetric avatars of the human head given just a small number of inputs. We enable generalization across identities by a novel parameterization that combines neural radiance fields with local, pixel-aligned features extracted directly from the inputs, thus sidestepping the need for very deep or complex networks. Our approach is trained in an end-to-end manner solely based on a photometric re-rendering loss without requiring explicit 3D supervision.We demonstrate that our approach outperforms the existing state of the art in terms of quality and is able to generate faithful facial expressions in a multi-identity setting.
https://weibo.com/1402400261/JCklJ0YBp

另外几篇值得俄关注的论文:
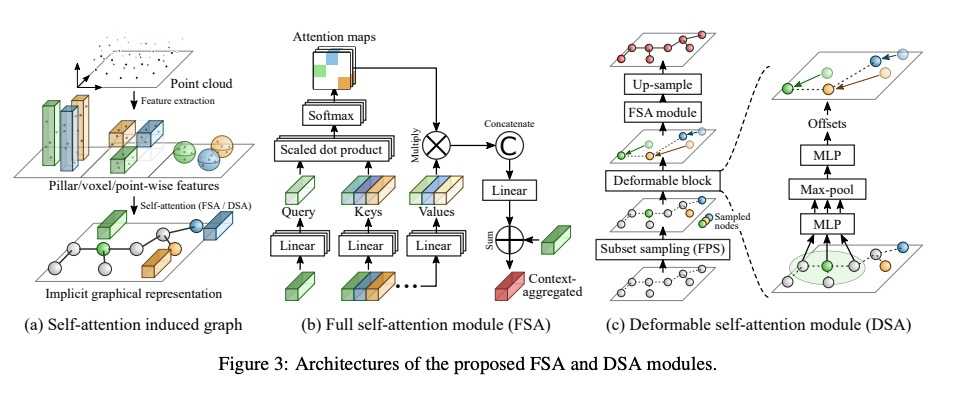
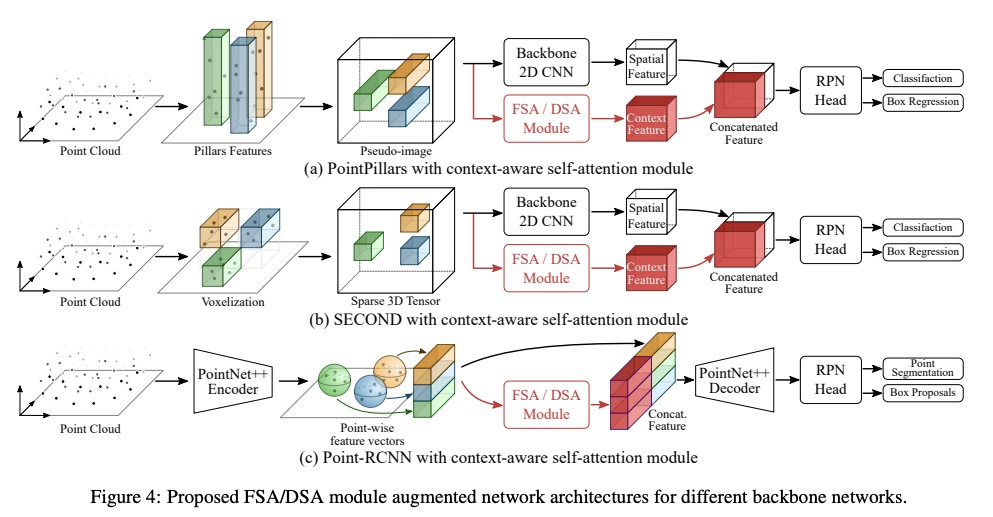
[CV] Self-Attention Based Context-Aware 3D Object Detection
自注意力上下文感知3D目标检测
P Bhattacharyya, C Huang, K Czarnecki
[University of Waterloo]
https://weibo.com/1402400261/JCkz1p4Za
[IR] Towards Meaningful Statements in IR Evaluation. Mapping Evaluation Measures to Interval Scales
信息检索有意义评价探索:评价指标到区间尺度的映射
M Ferrante, N Ferro, N Fuhr
[University of Padua & University of Duisburg-Essen]
https://weibo.com/1402400261/JCkGFqwY3

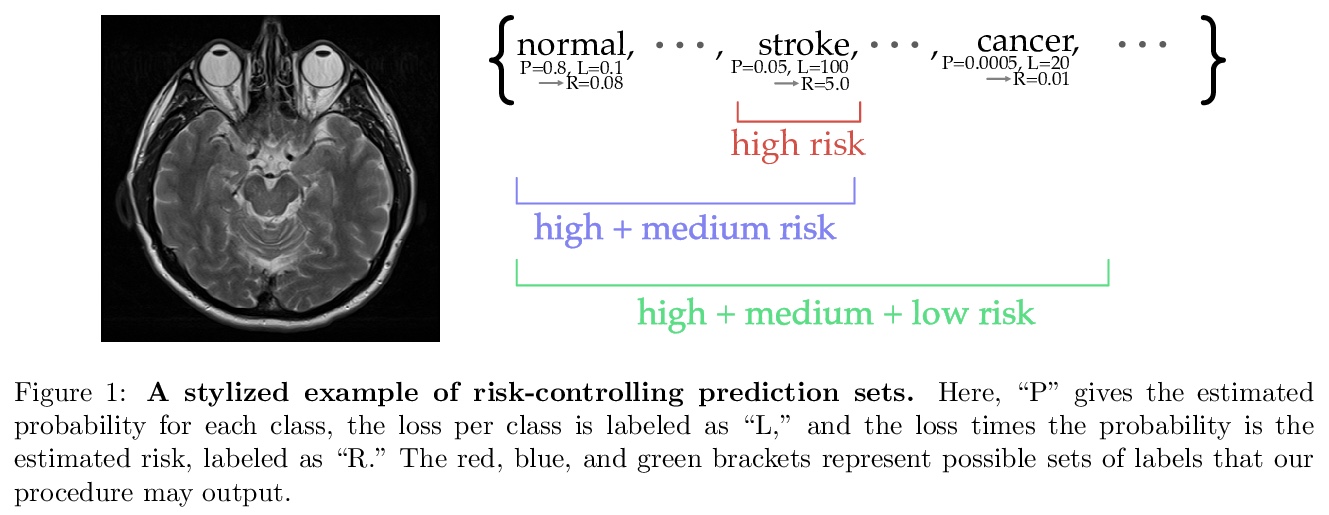
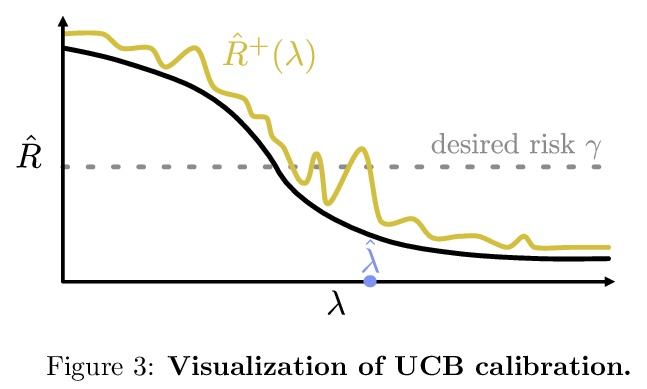
[LG] Distribution-Free, Risk-Controlling Prediction Sets
无分布风险控制预测集
S Bates, A Angelopoulos, L Lei, J Malik, M I. Jordan
https://weibo.com/1402400261/JCkPP6cMJ
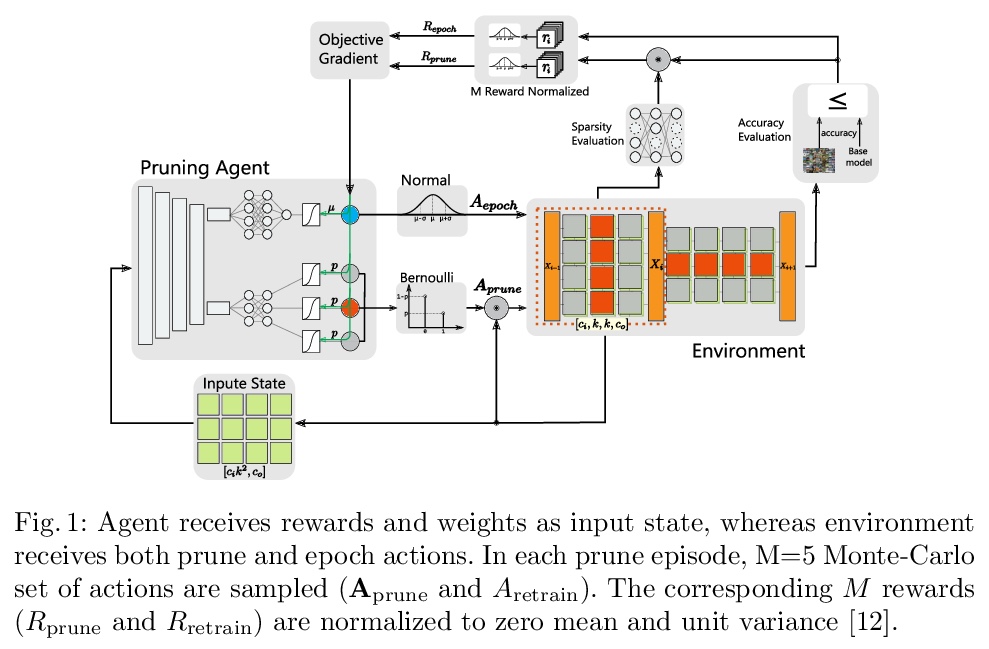
[CV] L2PF — Learning to Prune Faster
L2PF:学习更快的CNN修剪
M Vemparala, N Fasfous, A Frickenstein, M A Moraly, A Jamal, L Frickenstein, C Unger, N Nagaraja, W Stechele
[BMW Autonomous Driving & Technical University of Munich]
https://weibo.com/1402400261/JCkU43ixi

若有收获,就点个赞吧
0 人点赞
