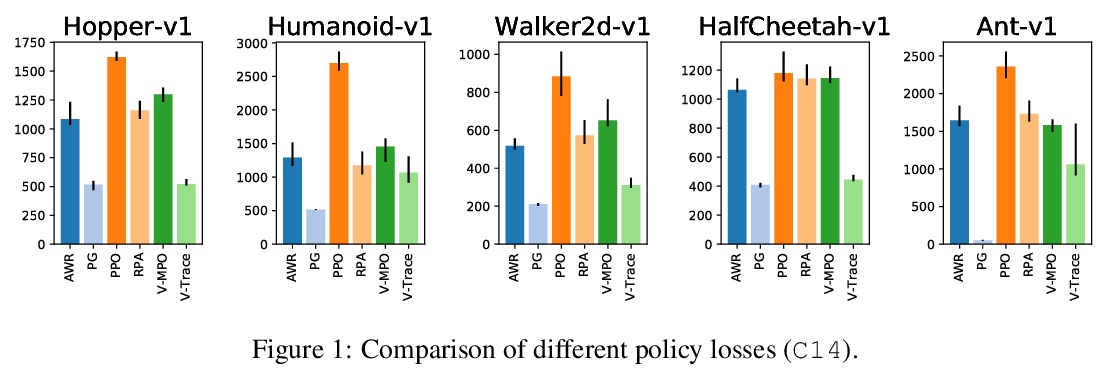
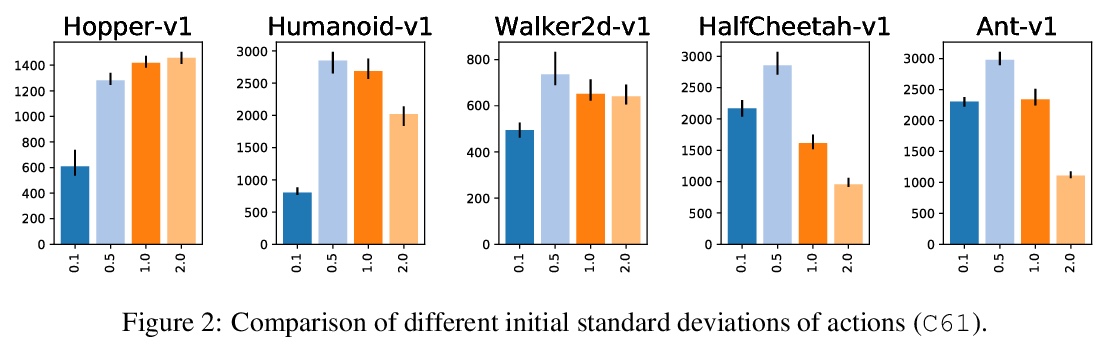
- 1、[LG] What Matters for On-Policy Deep Actor-Critic Methods? A Large-Scale Study
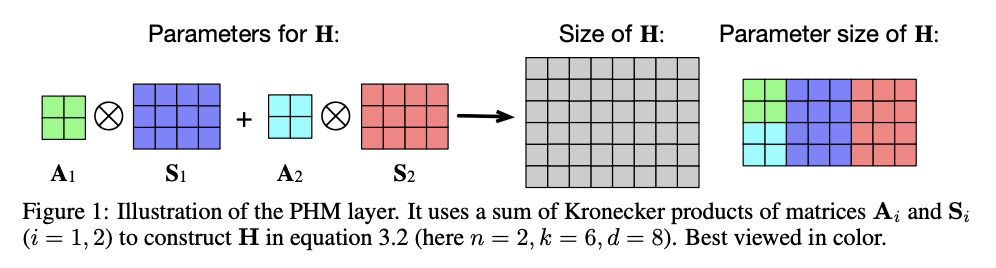
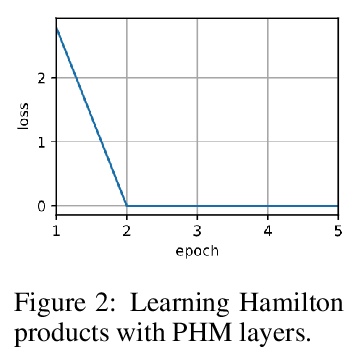
- 2、[LG] Parameterization of Hypercomplex Multiplications
- 3、[LG] Scalable Learning and MAP Inference for Nonsymmetric Determinantal Point Processes
- 4、[LG] Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients
- 5、[LG] On the mapping between Hopfield networks and Restricted Boltzmann Machines
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] What Matters for On-Policy Deep Actor-Critic Methods? A Large-Scale Study
M Andrychowicz, A Raichuk, P Stańczyk…
[OpenAI & Google]
On-Policy Deep Actor-Critic强化学习影响因素大规模研究。研究了在设计和实现On-Policy Deep Actor-Critic 强化学习算法时,需要做出的各个方面高级/低级设计决策的重要性。基于五个连续控制环境下、超过25万次的实验结果,评价了不同决策可能造成的影响,并提供了实用建议。其中一个令人惊讶的发现,是初始行为分布对智能体性能至关重要——当初始行为分布均值为零、标准差较低,且与观测值无关时,可显著提高训练速度。
In recent years, reinforcement learning (RL) has been successfully applied to many different continuous control tasks. While RL algorithms are often conceptually simple, their state-of-the-art implementations take numerous low- and high-level design decisions that strongly affect the performance of the resulting agents. Those choices are usually not extensively discussed in the literature, leading to discrepancy between published descriptions of algorithms and their implementations. This makes it hard to attribute progress in RL and slows down overall progress [Engstrom’20]. As a step towards filling that gap, we implement >50 such ``”choices” in a unified on-policy deep actor-critic framework, allowing us to investigate their impact in a large-scale empirical study. We train over 250’000 agents in five continuous control environments of different complexity and provide insights and practical recommendations for the training of on-policy deep actor-critic RL agents.
https://weibo.com/1402400261/JDGR0Bqlr
2、[LG] Parameterization of Hypercomplex Multiplications
A Zhang, Y Tay, S Zhang, A Chan, A Tuan Luu, S Hui, J Fu
[Amazon & Google & Swiss Federal Institute of Technology & Nanyang Technological University]
超复数乘法的参数化。提出了参数化的超复数乘法(PHM)层,可学习和泛化超复数乘法。汉密尔顿乘积(4D超复数乘法)可用来学习有效表示,同时节省高达75%的参数,但是其超复数空间只存在于极少数预定义维度上,限制了利用超复数乘法的模型的灵活性。参数化超复数乘法允许模型从数据中学习乘法规则,而不管这种规则是否是预定义的,可学习在任意的n维超复数空间上进行操作,提供更多的架构灵活性。用LSTM和Transformer在自然语言推理、机器翻译、文本风格转换和主语动词一致性方面的应用实验,证明了所提出方法的架构灵活性和有效性。
Recent works have demonstrated reasonable success of representation learning in hypercomplex space. Specifically, the Hamilton product (4D hypercomplex multiplication) enables learning effective representations while saving up to 75% parameters. However, one key caveat is that hypercomplex space only exists at very few predefined dimensions. This restricts the flexibility of models that leverage hypercomplex multiplications. To this end, we propose parameterizing hypercomplex multiplications, allowing models to learn multiplication rules from data regardless of whether such rules are predefined. As a result, our method not only subsumes the Hamilton product, but also learns to operate on any arbitrary nD hypercomplex space, providing more architectural flexibility. Experiments of applications to LSTM and Transformer on natural language inference, machine translation, text style transfer, and subject verb agreement demonstrate architectural flexibility and effectiveness of the proposed approach.
https://weibo.com/1402400261/JDGZEDS5K
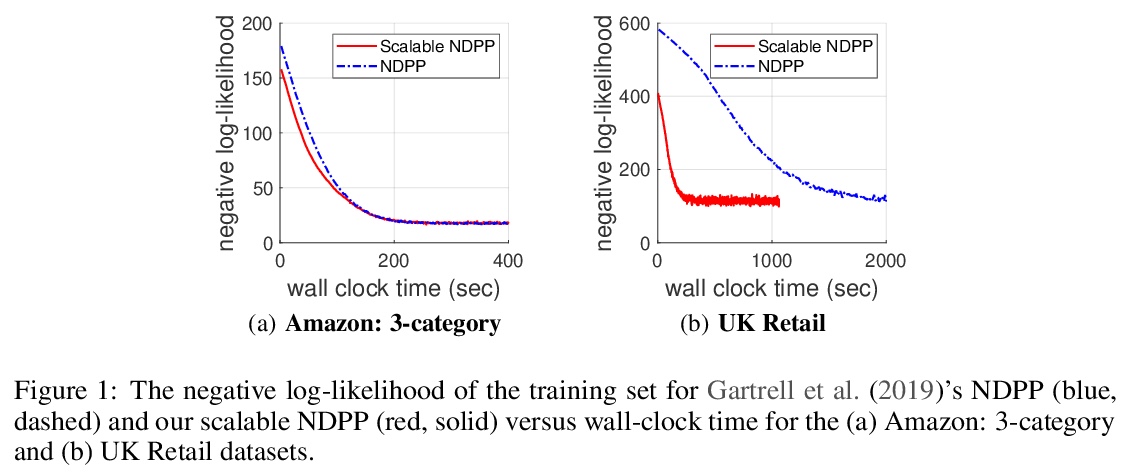
3、[LG] Scalable Learning and MAP Inference for Nonsymmetric Determinantal Point Processes
M Gartrell, I Han, E Dohmatob, J Gillenwater, VE Brunel
[Criteo AI Lab & Korea Advanced Institute of Science and Technology & Google Research & ENSAE ParisTech]
非对称行列式点过程可扩展学习和MAP推断。行列式点过程(DPP)被证明对许多机器学习任务是有效的,包括摘要、推荐系统、神经网络压缩等。本文提出了针对非对称DPP的可扩展学习和最大后验(MAP)推理算法。提出一种新的非对称DPP核分解方法,可在数据集规模的线性时间内学习,相比之前工作复杂度有很大改进。实证结果表明,该分解保持了之前分解的预测性能。推导出线性复杂度的NDPP最大后验推理算法,不仅适用于新核,也适用于之前的核。通过在真实世界数据集上的实验,表明所提出算法扩展性明显更好,可与之前工作的预测性能相比较,复杂度大大下降。
Determinantal point processes (DPPs) have attracted significant attention in machine learning for their ability to model subsets drawn from a large item collection. Recent work shows that nonsymmetric DPP (NDPP) kernels have significant advantages over symmetric kernels in terms of modeling power and predictive performance. However, for an item collection of size , existing NDPP learning and inference algorithms require memory quadratic in and runtime cubic (for learning) or quadratic (for inference) in , making them impractical for many typical subset selection tasks. In this work, we develop a learning algorithm with space and time requirements linear in by introducing a new NDPP kernel decomposition. We also derive a linear-complexity NDPP maximum a posteriori (MAP) inference algorithm that applies not only to our new kernel but also to that of prior work. Through evaluation on real-world datasets, we show that our algorithms scale significantly better, and can match the predictive performance of prior work.
https://weibo.com/1402400261/JDHaXylo6
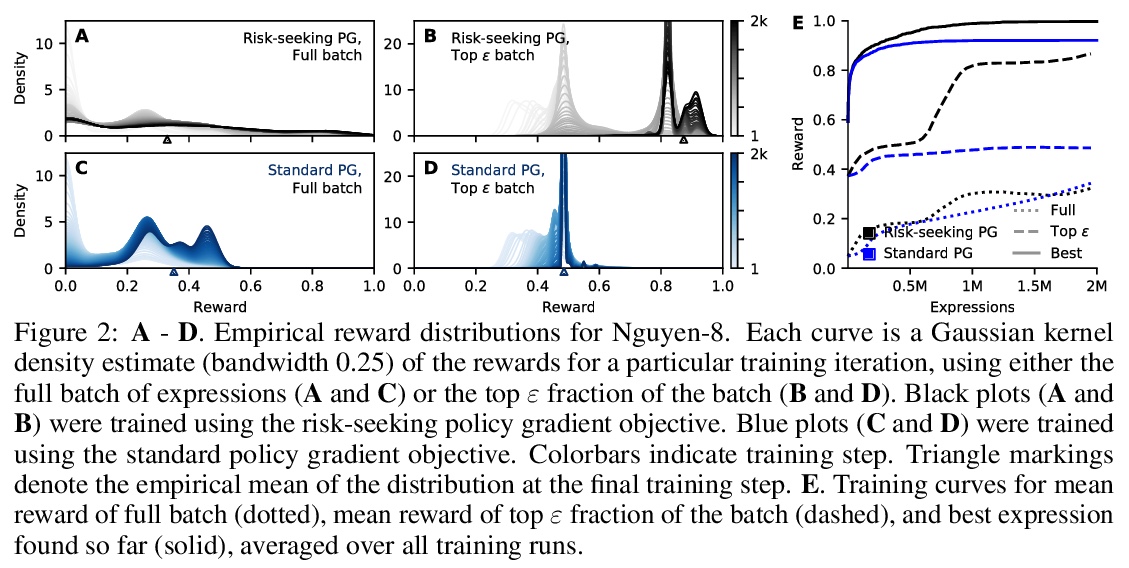
4、[LG] Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients
B K Petersen, M Landajuela Larma, T N. Mundhenk…
[Lawrence Livermore National Laboratory]
深度符号回归:通过风险寻求策略梯度从数据中恢复数学表达式。发现描述数据集的基本数学表达式是人工智能的一个核心挑战。本文提出一个框架,将深度学习和符号回归联系在起来,用大模型(即神经网络)来搜索小模型(即符号表达式)的空间,利用神经网络的表示能力,生成可解释的表达式。提出深度符号回归(DSR),一种基于强化学习的符号回归梯度方法,用循环神经网络(RNN)生成一个数学表达式的分布,用新的风险寻求策略梯度来训练网络,以产生更好的拟合表达式,可优化最佳情况下的性能而不是预期性能。
Discovering the underlying mathematical expressions describing a dataset is a core challenge for artificial intelligence. This is the problem of symbolic regression. Despite recent advances in training neural networks to solve complex tasks, deep learning approaches to symbolic regression are underexplored. We propose a framework that leverages deep learning for symbolic regression via a simple idea: use a large model to search the space of small models. Specifically, we use a recurrent neural network to emit a distribution over tractable mathematical expressions and employ a novel risk-seeking policy gradient to train the network to generate better-fitting expressions. Our algorithm outperforms several baseline methods (including Eureqa, the gold standard for symbolic regression) in its ability to exactly recover symbolic expressions on a series of benchmark problems, both with and without added noise. More broadly, our contributions include a framework that can be applied to optimize hierarchical, variable-length objects under a black-box performance metric, with the ability to incorporate constraints in situ, and a risk-seeking policy gradient formulation that optimizes for best-case performance instead of expected performance.
https://weibo.com/1402400261/JDHkM0Njs

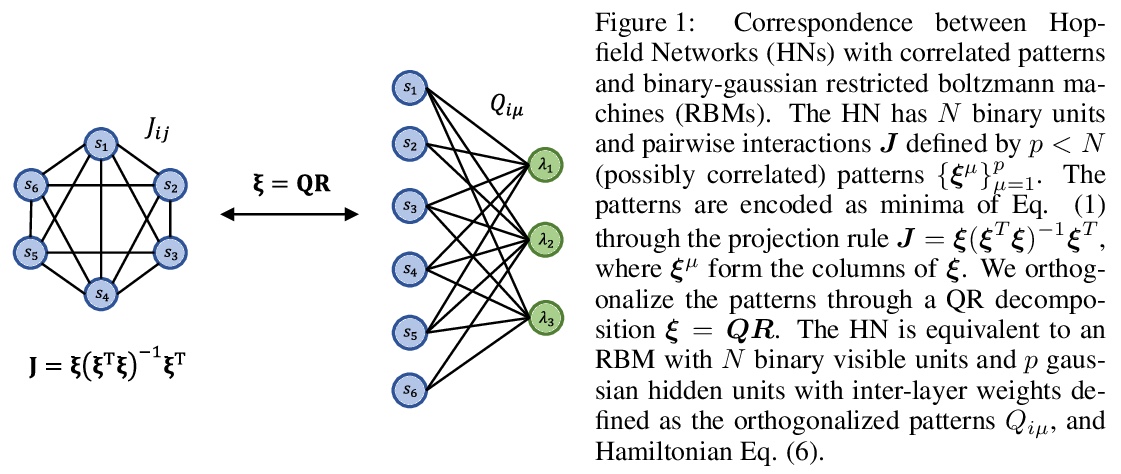
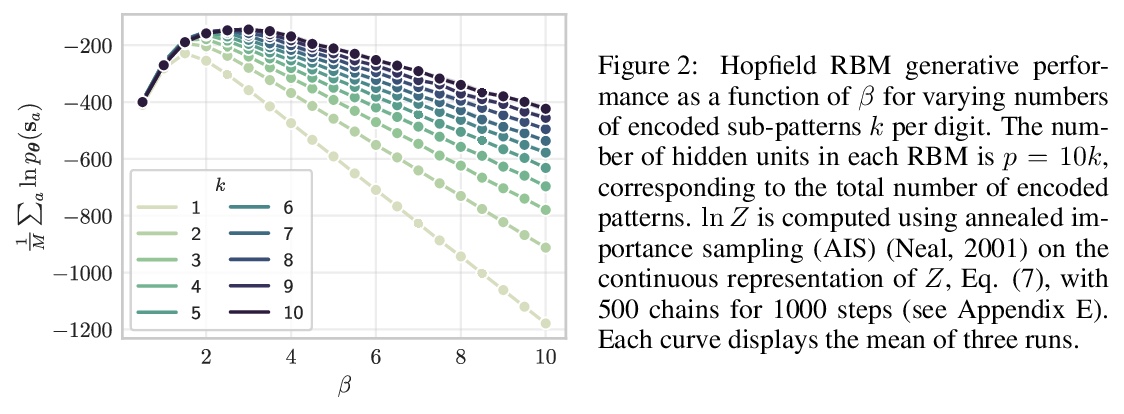
5、[LG] On the mapping between Hopfield networks and Restricted Boltzmann Machines
M Smart, A Zilman
[University of Toronto]
Hopfield网络与受限玻尔兹曼机之间的映射关系。具有相关模式的Hopfield网络(HN)可以映射到具有正交权重的受限玻尔兹曼机(RBM),任何具有二元变量和潜在相关二元模式的HN都可转化为具有二元可见变量和高斯隐变量的RBM。概述了反向映射存在的条件,并在MNIST数据集上进行了实验,表明该映射有助于RBM权重的初始化。
Hopfield networks (HNs) and Restricted Boltzmann Machines (RBMs) are two important models at the interface of statistical physics, machine learning, and neuroscience. Recently, there has been interest in the relationship between HNs and RBMs, due to their similarity under the statistical mechanics formalism. An exact mapping between HNs and RBMs has been previously noted for the special case of orthogonal (“uncorrelated”) encoded patterns. We present here an exact mapping in the general case of correlated pattern HNs, which are more broadly applicable to existing datasets. Specifically, we show that any HN with binary variables and potentially correlated binary patterns can be transformed into an RBM with binary visible variables and gaussian hidden variables. We outline the conditions under which the reverse mapping exists, and conduct experiments on the MNIST dataset which suggest the mapping provides a useful initialization to the RBM weights. We discuss extensions, the potential importance of this correspondence for the training of RBMs, and for understanding the performance of feature extraction methods which utilize RBMs.
https://weibo.com/1402400261/JDHre5qCn


若有收获,就点个赞吧
0 人点赞
