- 1、[CL] GPT-2’s activations predict the degree of semantic comprehension in the human brain
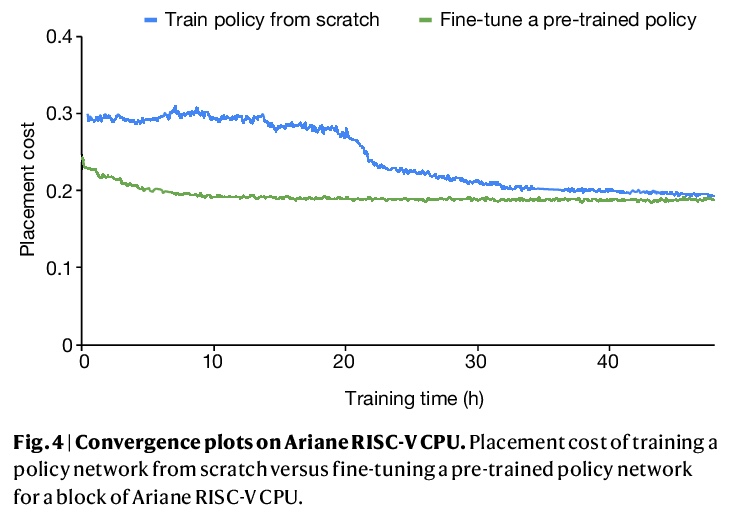
- 2、[LG] A graph placement methodology for fast chip design
- 3、[CV] Knowledge distillation: A good teacher is patient and consistent
- 4、[LG] Pretrained Encoders are All You Need
- 5、[CV] NeRF in detail: Learning to sample for view synthesis
- [CV] Generative Models as a Data Source for Multiview Representation Learning
- [CL] FastSeq: Make Sequence Generation Faster
- [LG] Vector Quantized Models for Planning
- [CV] Geometry-Consistent Neural Shape Representation with Implicit Displacement Fields
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CL] GPT-2’s activations predict the degree of semantic comprehension in the human brain
C Caucheteux, A Gramfort, J King
[Facebook AI Research & Université Paris-Saclay]
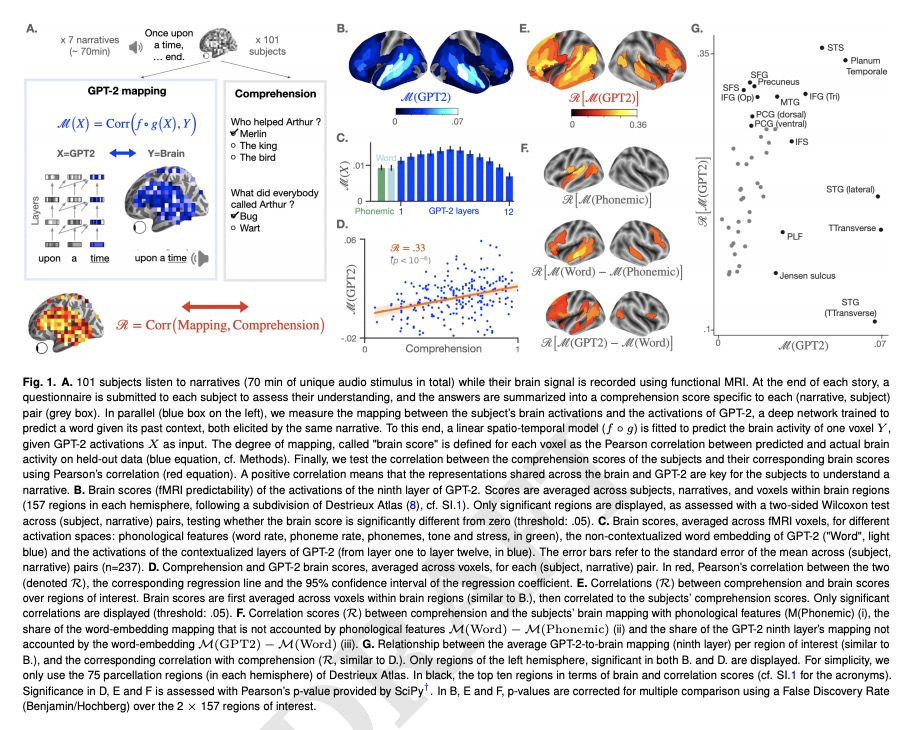
用GPT-2激活预测大脑语义理解度。像GPT-2这样的自然语言transformer,已经显示出处理文本的显著能力,成为深度翻译、摘要和对话算法的骨干。然而,这些模型是否真的能理解语言,是非常有争议的。本文表明,GPT-2表征不仅映射到大脑对口述故事的反应上,还能预测受试者对叙述的理解程度。分析了101名受试者在听70分钟的短篇故事时,用功能性磁共振成像(fMRI)记录的数据,拟合了一个线性模型,来预测GPT-2激活的大脑活动,将这种映射与受试者对每个故事的理解分数相关联。结果显示,GPT-2的大脑预测与语义理解能力明显相关。这些影响在语言网络中呈双侧分布,在额内和颞中回及额上皮层、颞平面和楔前的相关性达到峰值,超过30%。总的来说,这项研究提供了一个实证框架,来探测和剖析大脑和深度学习算法中的语义理解能力。
Language transformers, like GPT-2, have demonstrated remarkable abilities to process text, and now constitute the backbone of deep translation, summarization and dialogue algorithms. However, whether these models actually understand language is highly controversial. Here, we show that the representations of GPT-2 not only map onto the brain responses to spoken stories, but also predict the extent to which subjects understand the narratives. To this end, we analyze 101 subjects recorded with functional Magnetic Resonance Imaging while listening to 70 min of short stories. We then fit a linear model to predict brain activity from GPT-2 activations, and correlate this mapping with subjects’ comprehension scores as assessed for each story. The results show that GPT-2’s brain predictions significantly correlate with semantic comprehension. These effects are bilaterally distributed in the language network and peak with a correlation above 30% in the infero-frontal and medio-temporal gyri as well as in the superior frontal cortex, the planum temporale and the precuneus. Overall, this study provides an empirical framework to probe and dissect semantic comprehension in brains and deep learning algorithms.
https://weibo.com/1402400261/KjCLzp6TB
2、[LG] A graph placement methodology for fast chip design
A Mirhoseini, A Goldie, M Yazgan…
[Google Research]
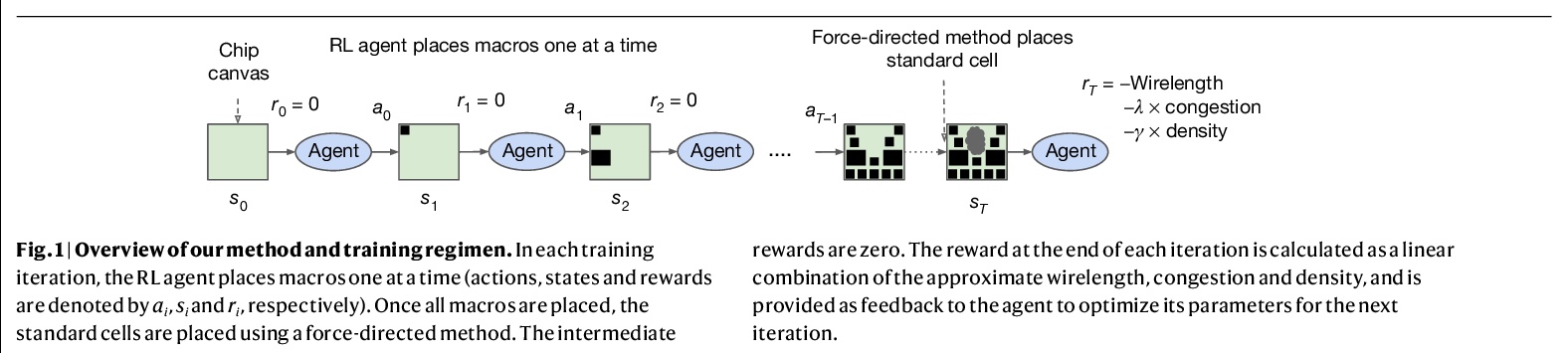
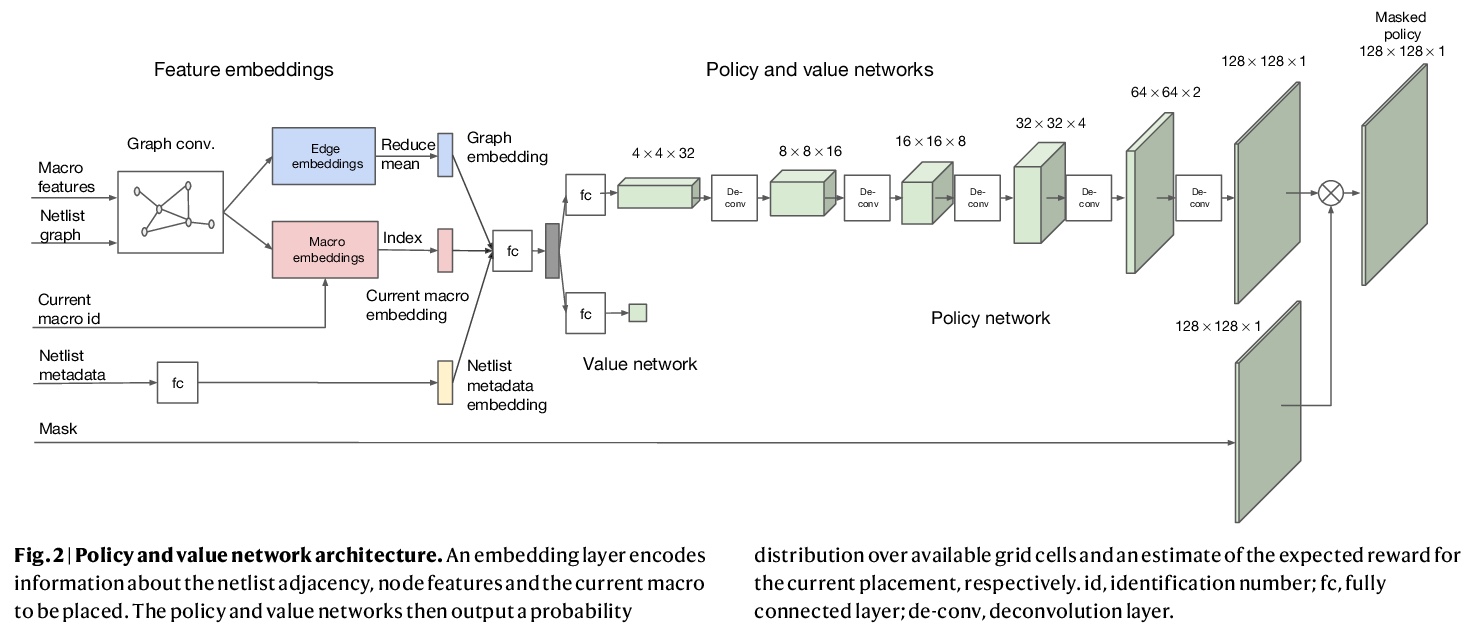
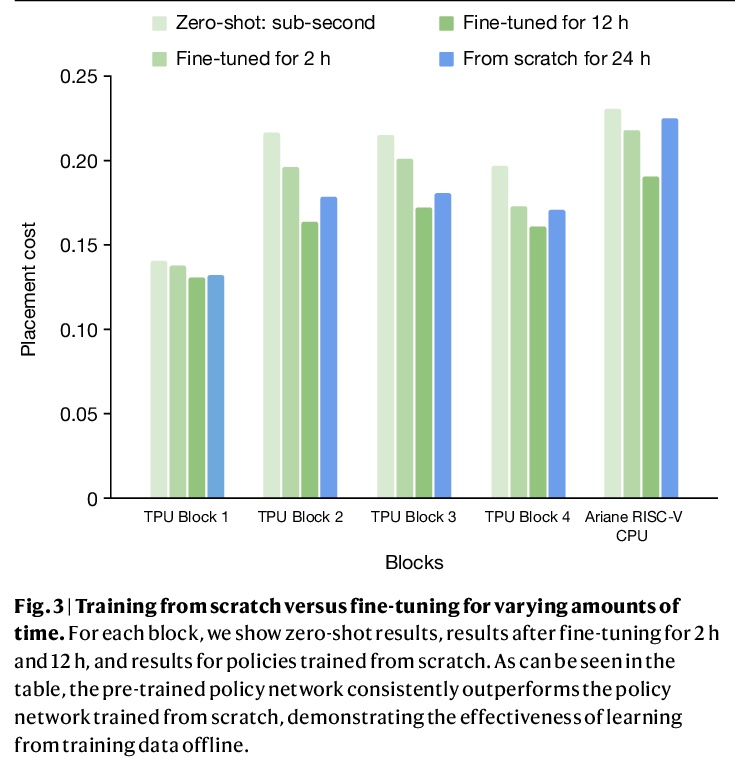
基于深度强化学习的快速芯片设计图规划方法。芯片布局规划是设计计算机芯片物理布局的工程任务。尽管经过五十年的研究,芯片布局规划仍然无法实现自动化,需要物理设计工程师花费数月的精力来制作可量产的布局。本文提出一种基于深度强化学习的芯片布局规划方法,在不到六个小时的时间里,自动生成了芯片布局规划图,这些布局规划图在所有关键指标上都优于或可与人类生成的布局规划图相媲美,包括功耗、性能和芯片面积。为实现这一目标,将芯片布局规划作为一个强化学习问题,开发了一种基于边缘的图卷积神经网络架构,能学习丰富的可迁移的芯片表示。利用过去的经验,在解决新的问题实例时变得更好、更快,使芯片设计可以由比任何人类设计师更有经验的智能体来完成。该方法被用来设计Google的下一代人工智能(AI)加速器,并有可能为每一代新产品节省数千小时的人工努力。更强大的人工智能设计的硬件将推动人工智能的进步,在这两个领域之间创造一种共生关系。
Chip floorplanning is the engineering task of designing the physical layout of a computer chip. Despite five decades of research, chip floorplanning has defied automation, requiring months of intense effort by physical design engineers to produce manufacturable layouts. Here we present a deep reinforcement learning approach to chip floorplanning. In under six hours, our method automatically generates chip floorplans that are superior or comparable to those produced by humans in all key metrics, including power consumption, performance and chip area. To achieve this, we pose chip floorplanning as a reinforcement learning problem, and develop an edge-based graph convolutional neural network architecture capable of learning rich and transferable representations of the chip. As a result, our method utilizes past experience to become better and faster at solving new instances of the problem, allowing chip design to be performed by artificial agents with more experience than any human designer. Our method was used to design the next generation of Google’s artificial intelligence (AI) accelerators, and has the potential to save thousands of hours of human effort for each new generation. Finally, we believe that more powerful AI-designed hardware will fuel advances in AI, creating a symbiotic relationship between the two fields.
https://weibo.com/1402400261/KjCRCaGvp
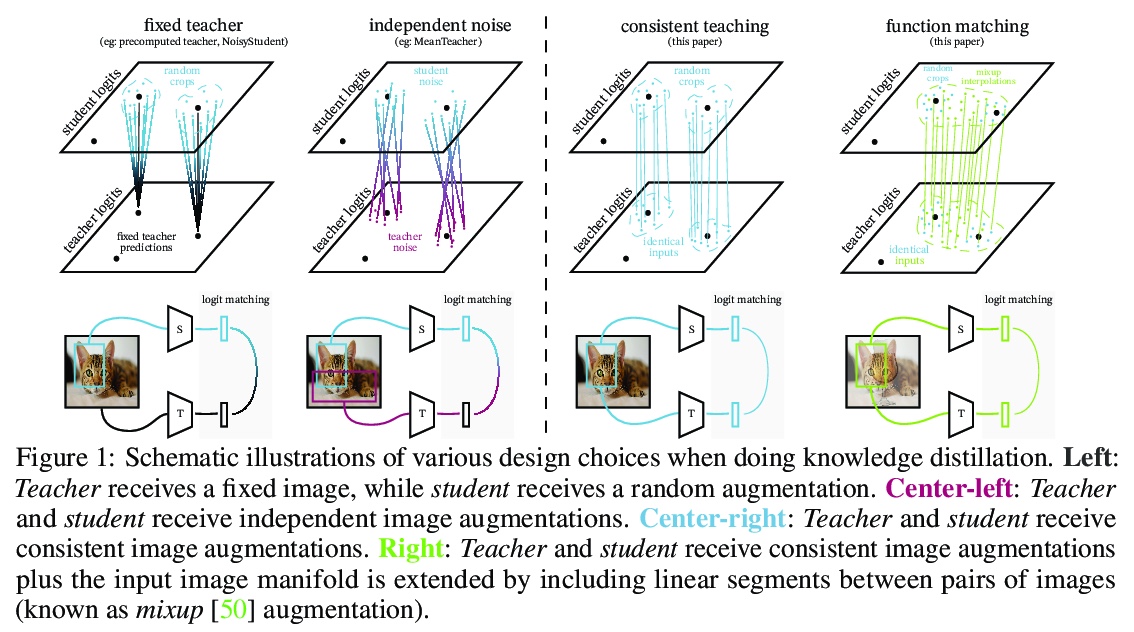
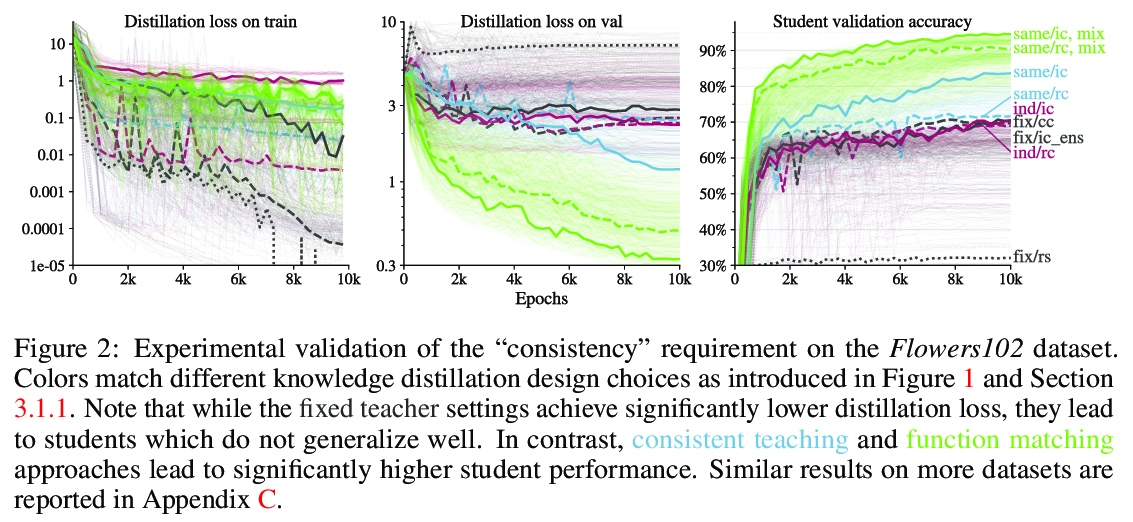
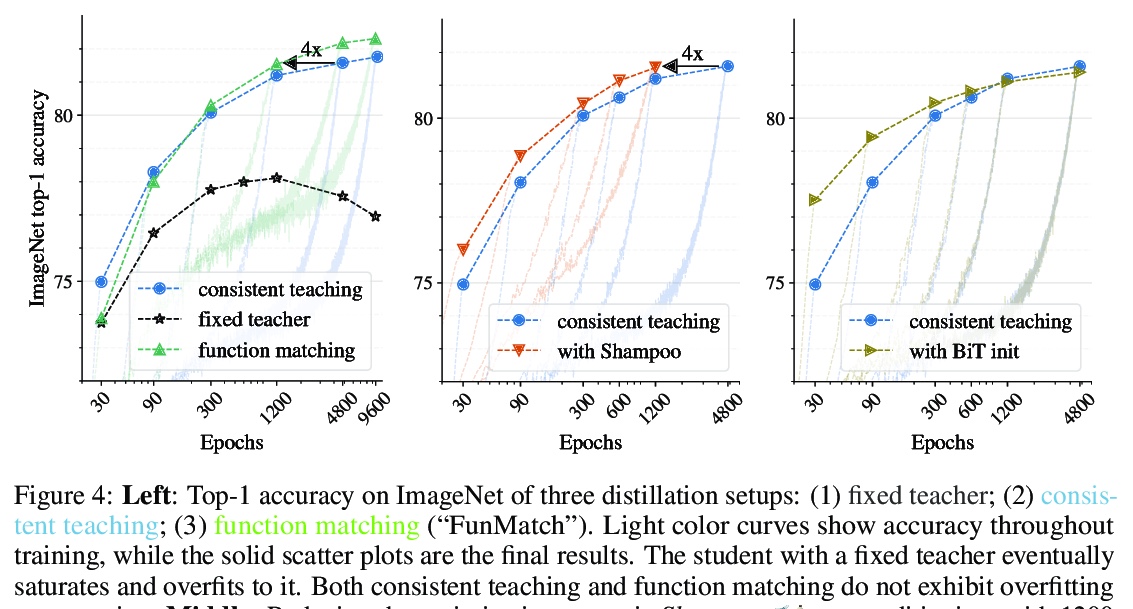
3、[CV] Knowledge distillation: A good teacher is patient and consistent
L Beyer, X Zhai, A Royer, L Markeeva, R Anil, A Kolesnikov
[Google Research]
知识蒸馏:好老师要有耐心和恒心。在计算机视觉领域,实现最先进性能的大规模模型,和实际应用中负担得起的模型之间的差距越来越大。本文解决了这个问题,并大大缩小了这两类模型之间的差距。在整个实证调查过程中,目的并不是要提出一种新的方法,而是要努力找出一种鲁棒有效的方法,使最先进的大规模模型在实践中能负担得起。实验证明,如果执行得当,知识蒸馏可以成为减少大型模型规模而不影响其性能的有力工具。特别是,发现有一些隐含的设计选择,可能会极大影响蒸馏的有效性。本文的主要贡献是明确识别了这些设计选项,这在之前的文献中是没有阐述的。通过全面的实证研究来支持这些发现,在广泛的视觉数据集上展示了令人信服的结果,特别是为ImageNet获得了最先进的ResNet-50模型,达到了82.8%的最高精度。
There is a growing discrepancy in computer vision between large-scale models that achieve state-of-the-art performance and models that are affordable in practical applications. In this paper we address this issue and significantly bridge the gap between these two types of models. Throughout our empirical investigation we do not aim to necessarily propose a new method, but strive to identify a robust and effective recipe for making state-of-the-art large scale models affordable in practice. We demonstrate that, when performed correctly, knowledge distillation can be a powerful tool for reducing the size of large models without compromising their performance. In particular, we uncover that there are certain implicit design choices, which may drastically affect the effectiveness of distillation. Our key contribution is the explicit identification of these design choices, which were not previously articulated in the literature. We back up our findings by a comprehensive empirical study, demonstrate compelling results on a wide range of vision datasets and, in particular, obtain a state-of-the-art ResNet-50 model for ImageNet, which achieves 82.8% top-1 accuracy.
https://weibo.com/1402400261/KjCWknYx6

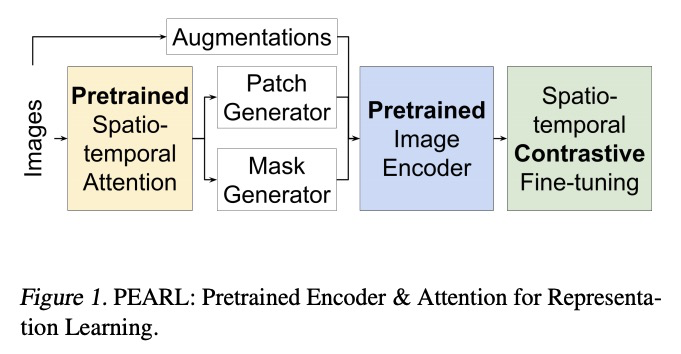
4、[LG] Pretrained Encoders are All You Need
M Khan, P Srivatsa, A Rane, S Chenniappa, R Anand, S Ozair, P Maes
[MIT & Berla Institute of Technology & Deepmind]
预训练编码器就够了。数据效率和泛化,是深度学习和深度强化学习的关键挑战,因为许多模型是在大规模、特定领域的、昂贵标记数据集上训练的。在大规模、未经整理的数据集上训练的自监督模型,已经显示出对不同环境的成功迁移。本文研究了在Atari中用预训练的图像表征和时空注意力进行状态表示学习,探索了用自监督技术对预训练表示进行微调,即对比预测编码、时空对比学习和增强。结果表明,预训练表征与在特定领域数据上训练的最先进的自监督方法相当。预训练表示产生了数据和计算效率高的状态表示。
Data-efficiency and generalization are key challenges in deep learning and deep reinforcement learning as many models are trained on largescale, domain-specific, and expensive-to-label datasets. Self-supervised models trained on largescale uncurated datasets have shown successful transfer to diverse settings. We investigate using pretrained image representations and spatiotemporal attention for state representation learning in Atari. We also explore fine-tuning pretrained representations with self-supervised techniques, i.e., contrastive predictive coding, spatiotemporal contrastive learning, and augmentations. Our results show that pretrained representations are at par with state-of-the-art self-supervised methods trained on domain-specific data. Pretrained representations, thus, yield data and compute-efficient state representations.
https://weibo.com/1402400261/KjCZg7KNQ

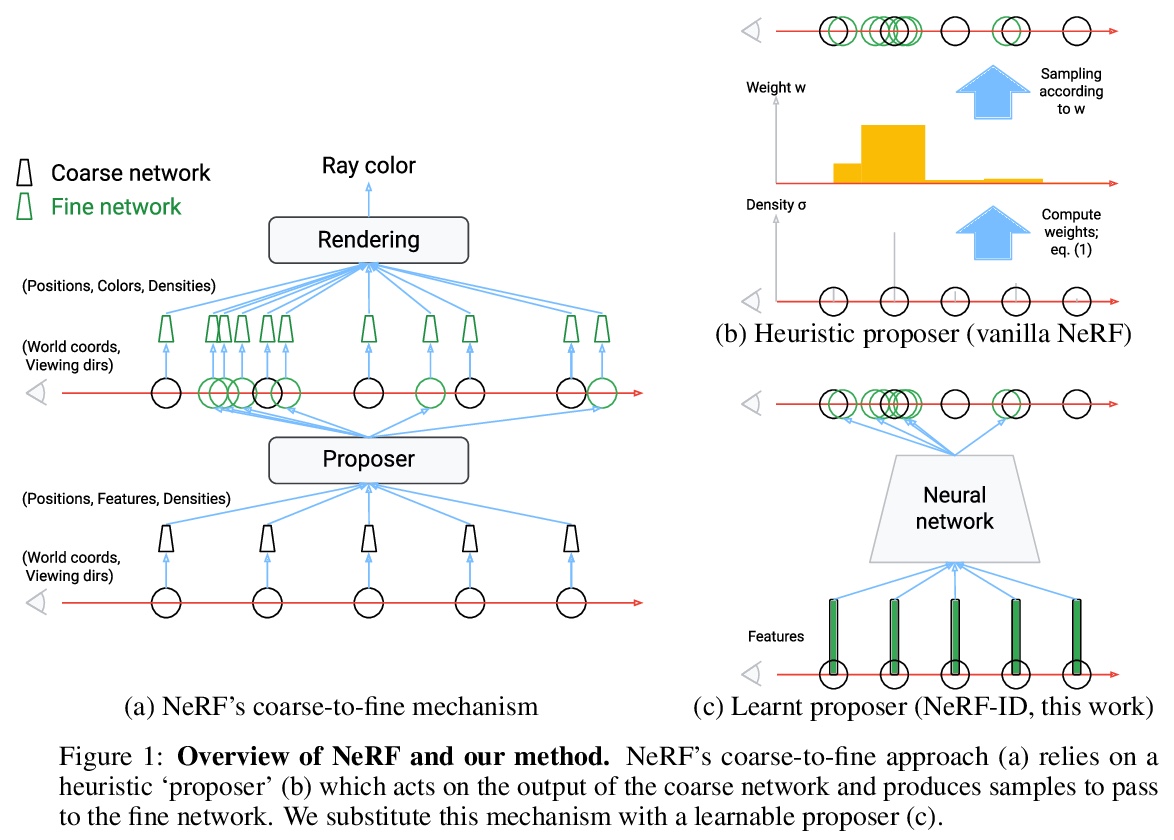
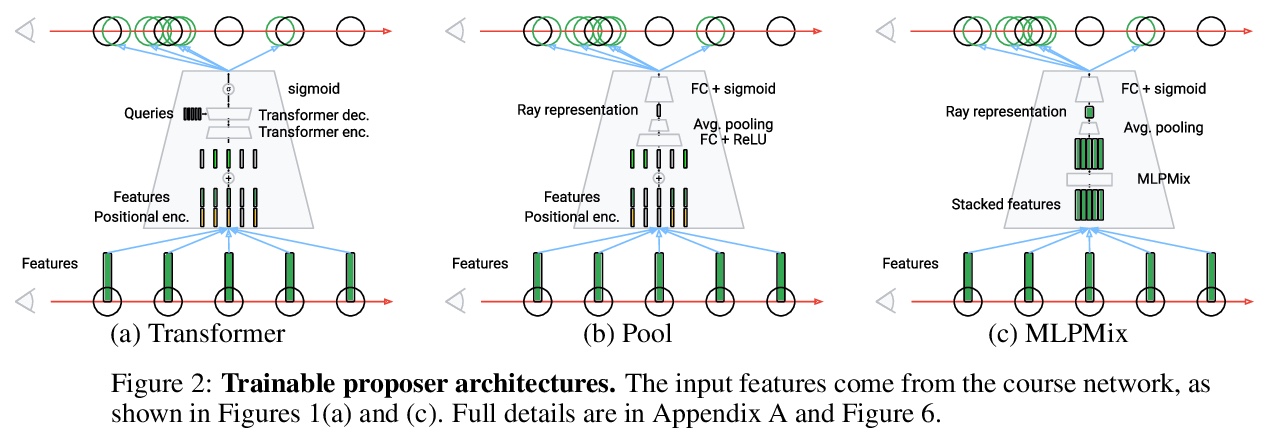
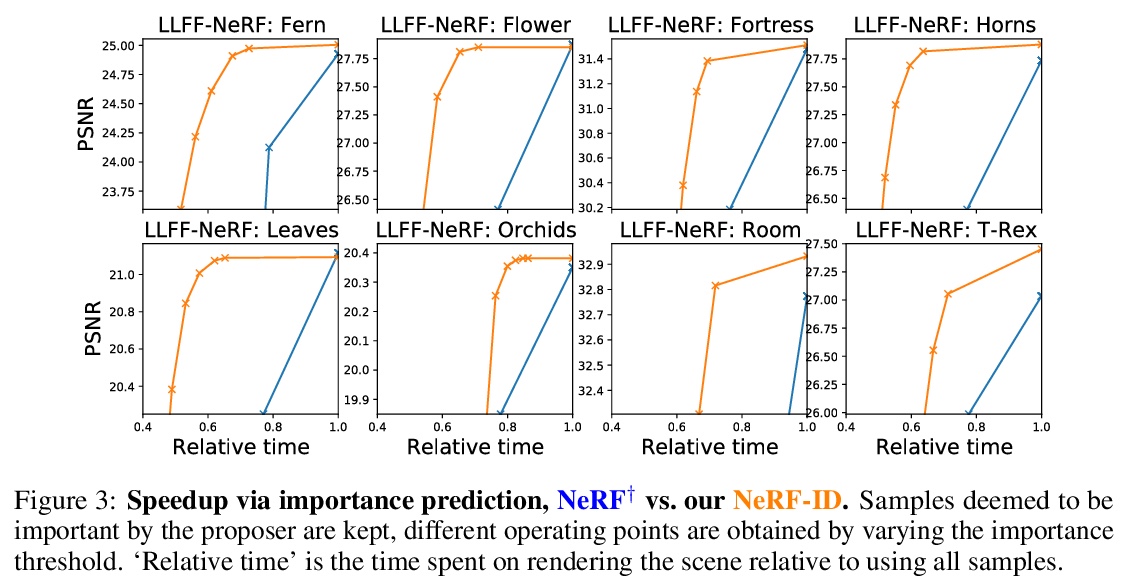
5、[CV] NeRF in detail: Learning to sample for view synthesis
R Arandjelović, A Zisserman
[DeepMind]
NeRF in detail:视图合成采样学习。神经辐射场(NeRF)方法已经展示了令人印象深刻的新视图合成性能。其核心是通过查询沿射线采样点的神经网络来渲染单条射线,以获得采样点的密度和颜色,并利用渲染方程整合这些信息。由于密集采样计算量很大,一种常见的解决方案是进行粗到细的采样。本文解决了普通的从粗到细的方法的一个明显的局限性——它是基于启发式的,没有为特定任务进行端到端的训练。本文引入一个可微模块,可学习提出样本及其对精细网络的重要性,并考虑和比较其神经结构的多种选择。由于缺乏监督,从头开始训练建议模块可能是不稳定的,因此也提出了一种有效的预训练策略,该方法被命名为”NeRF in detail”(NeRF-ID),在合成Blender基准上取得了优于NeRF和最先进的视图合成质量,在真实的LLFF-NeRF场景上取得了相同或更好的性能。此外,通过利用预测的样本重要性,在不明显牺牲渲染质量的情况下,可节省25%的计算量。
Neural radiance fields (NeRF) methods have demonstrated impressive novel view synthesis performance. The core approach is to render individual rays by querying a neural network at points sampled along the ray to obtain the density and colour of the sampled points, and integrating this information using the rendering equation. Since dense sampling is computationally prohibitive, a common solution is to perform coarse-to-fine sampling. In this work we address a clear limitation of the vanilla coarse-to-fine approach — that it is based on a heuristic and not trained end-to-end for the task at hand. We introduce a differentiable module that learns to propose samples and their importance for the fine network, and consider and compare multiple alternatives for its neural architecture. Training the proposal module from scratch can be unstable due to lack of supervision, so an effective pre-training strategy is also put forward. The approach, named `NeRF in detail’ (NeRF-ID), achieves superior view synthesis quality over NeRF and the state-of-the-art on the synthetic Blender benchmark and on par or better performance on the real LLFF-NeRF scenes. Furthermore, by leveraging the predicted sample importance, a 25% saving in computation can be achieved without significantly sacrificing the rendering quality.
https://weibo.com/1402400261/KjD2gySCJ

另外几篇值得关注的论文:
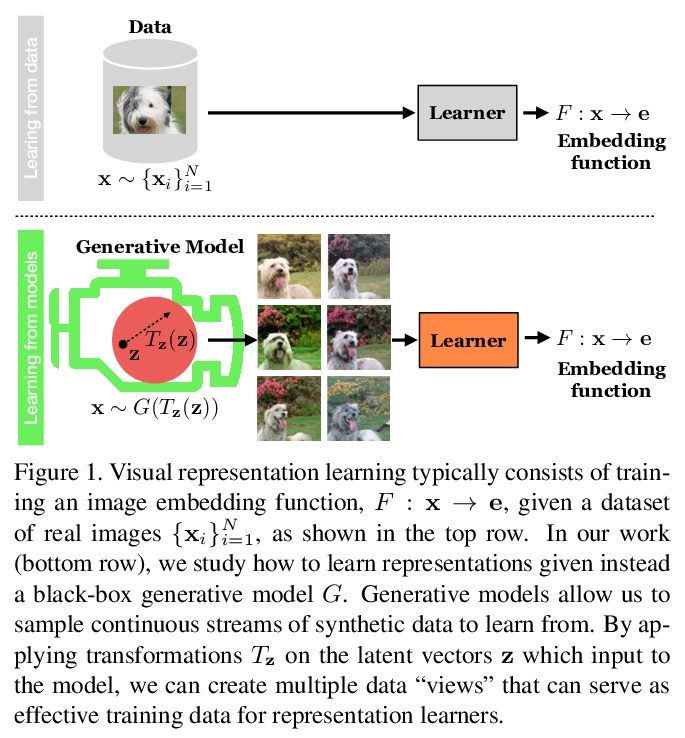
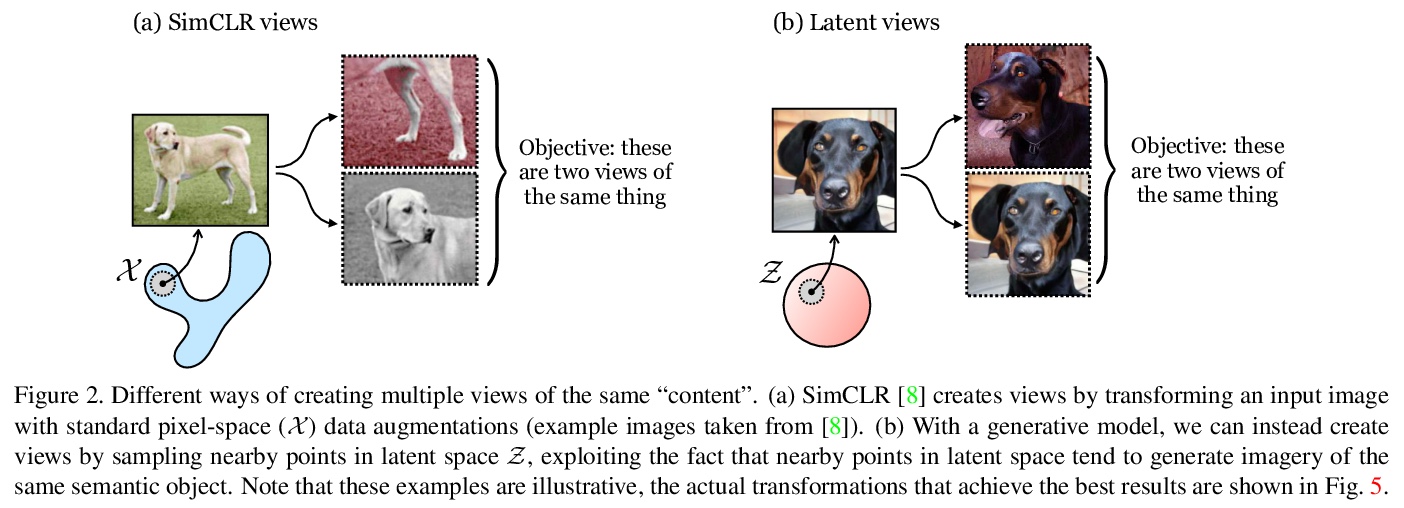
[CV] Generative Models as a Data Source for Multiview Representation Learning
生成模型作为多视图表示学习数据源
A Jahanian, X Puig, Y Tian, P Isola
[MIT]
https://weibo.com/1402400261/KjD5BqInj
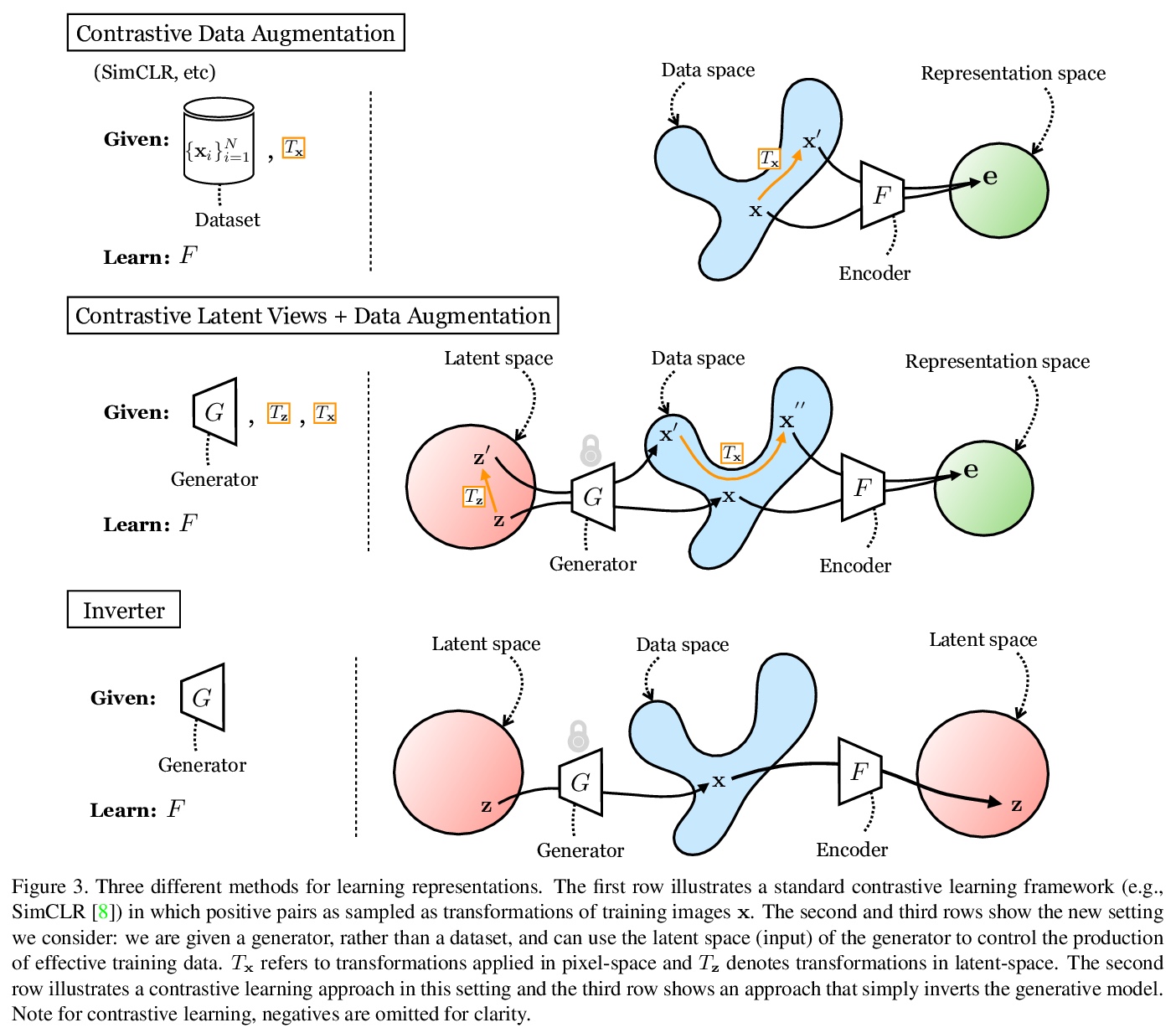

[CL] FastSeq: Make Sequence Generation Faster
FastSeq:更快的序列生成
Y Yan, F Hu, J Chen, N Bhendawade, T Ye, Y Gong, N Duan, D Cui, B Chi, R Zhang
[Microsoft & Microsoft Research Asia]
https://weibo.com/1402400261/KjD6Icgbb
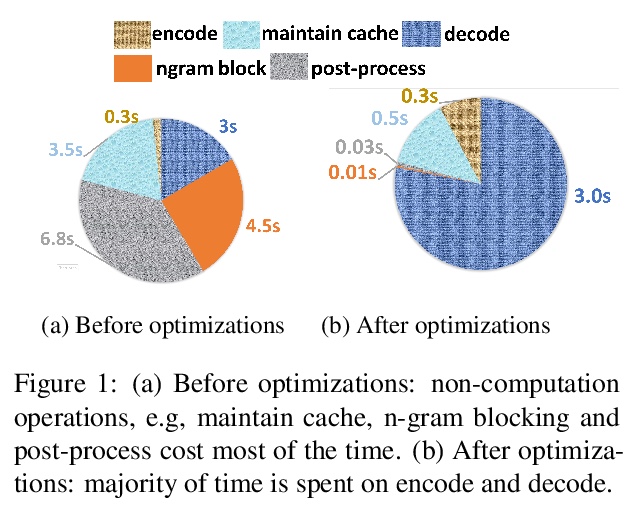
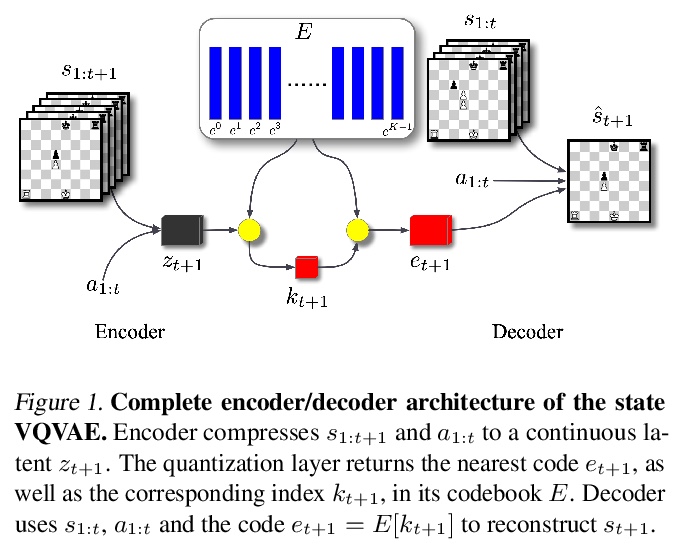
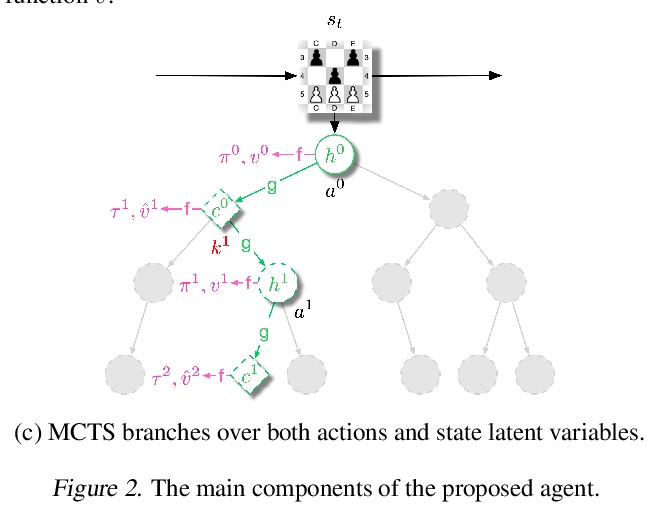
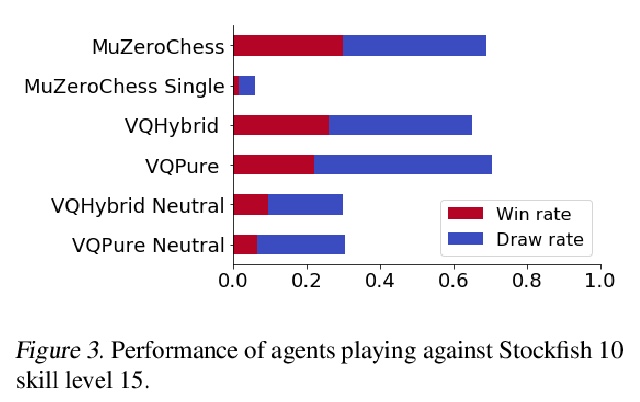
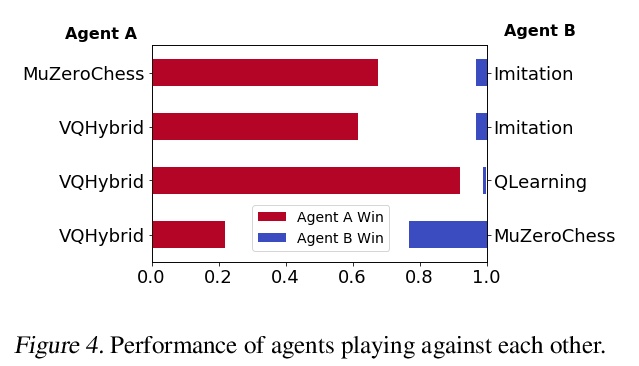
[LG] Vector Quantized Models for Planning
(强化学习中)规划的矢量量化模型
S Ozair, Y Li, A Razavi, I Antonoglou, A v d Oord, O Vinyals
[DeepMind]
https://weibo.com/1402400261/KjD80j7WH
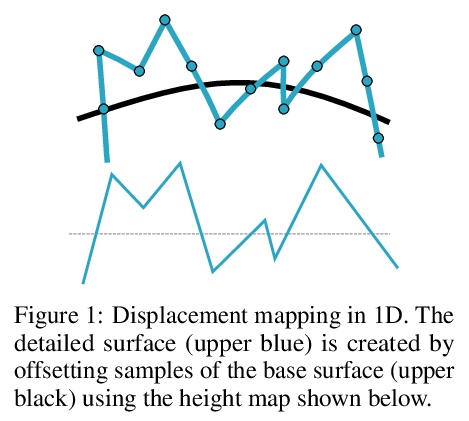
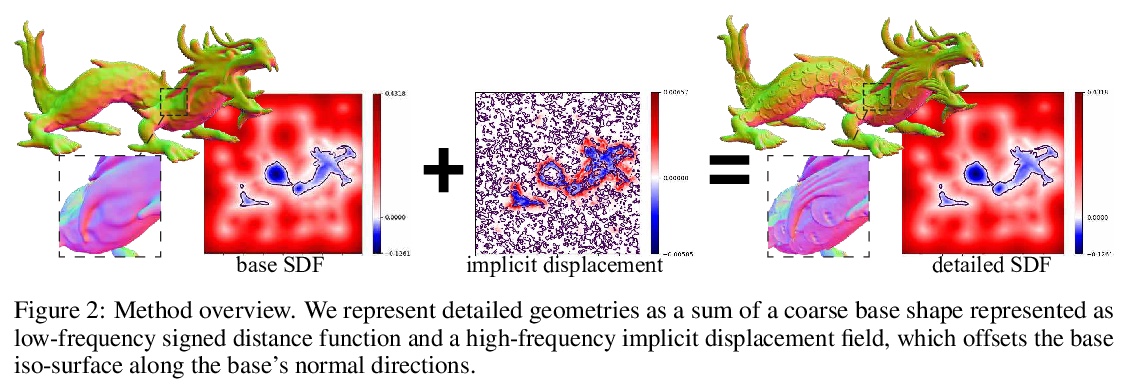
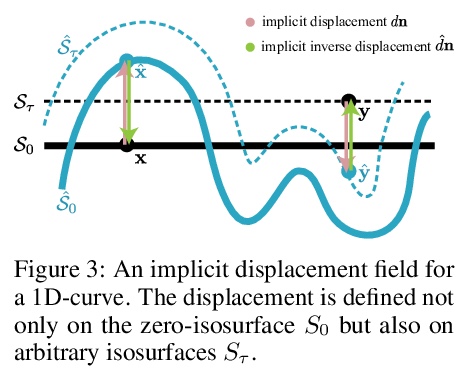
[CV] Geometry-Consistent Neural Shape Representation with Implicit Displacement Fields
隐位移场几何一致神经网络形状表示
W Yifan, L Rahmann, O Sorkine-Hornung
[ETH Zurich]
https://weibo.com/1402400261/KjD9mc9oC

若有收获,就点个赞吧
0 人点赞
