- 1、[LG] GRAND: Graph Neural Diffusion
- 2、[CV] Efficient Self-supervised Vision Transformers for Representation Learning
- 3、[LG] Lossy Compression for Lossless Prediction
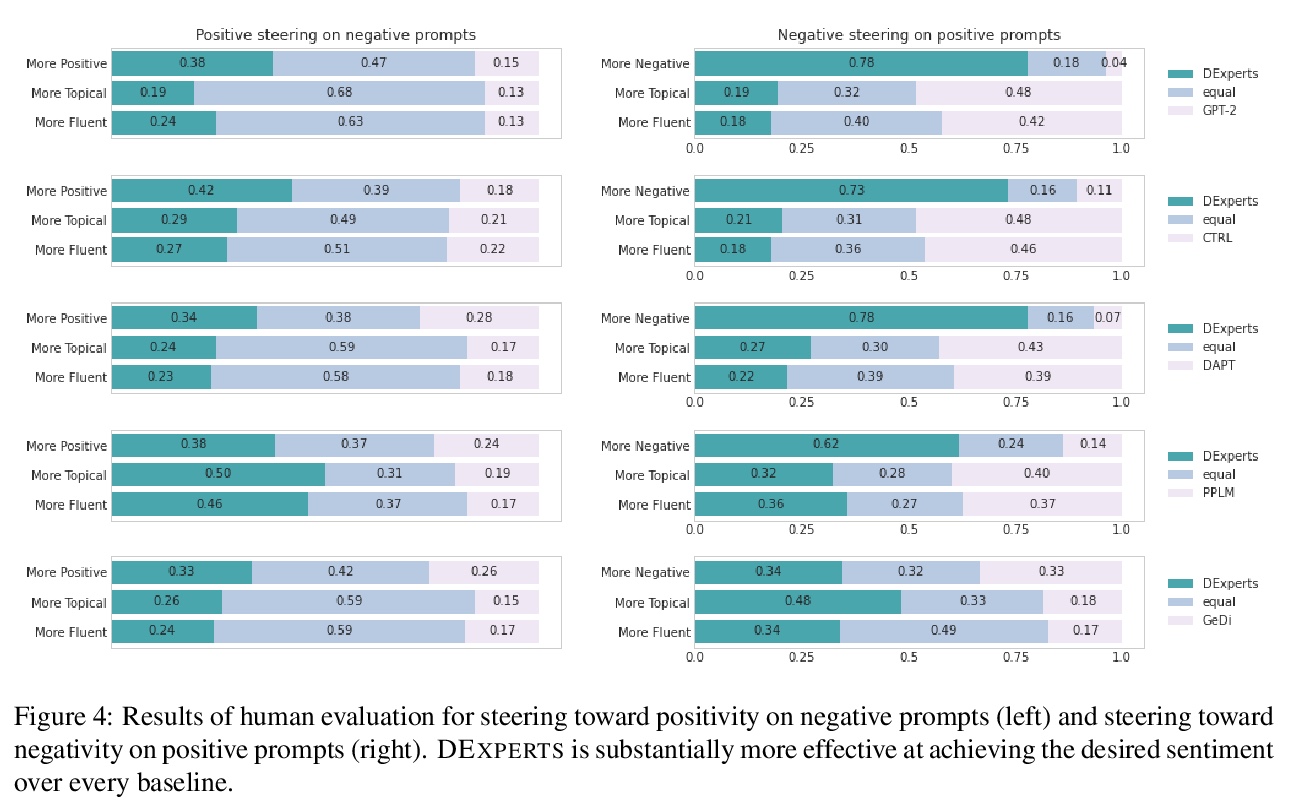
- 4、[CL] DExperts: Decoding-Time Controlled Text Generation with Experts and Anti-Experts
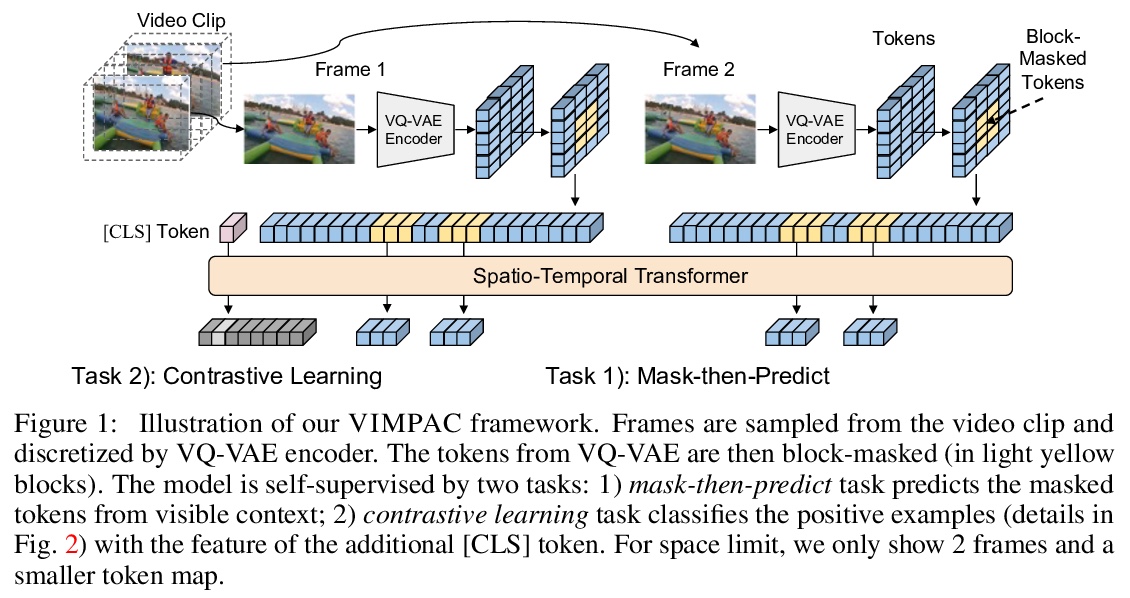
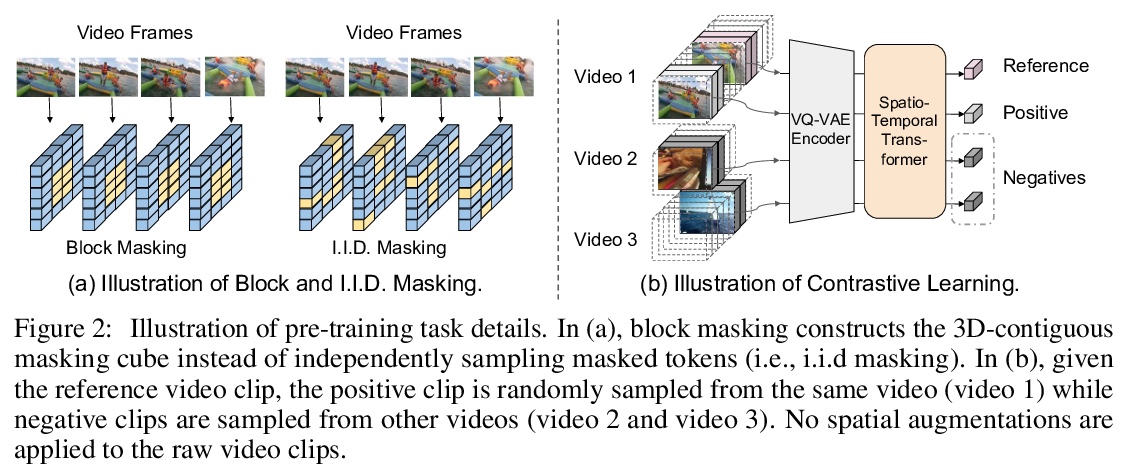
- 5、[CV] VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning
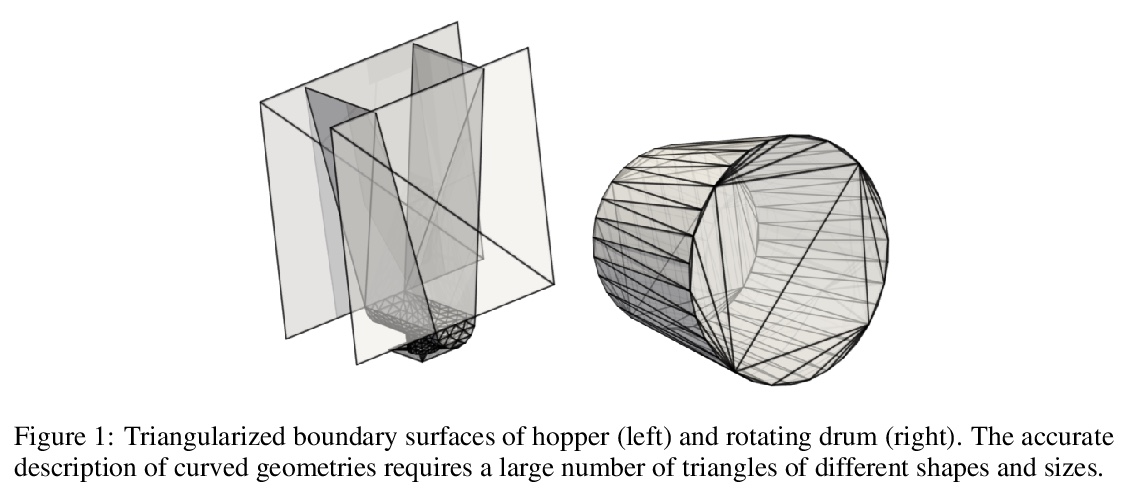
- [LG] Boundary Graph Neural Networks for 3D Simulations
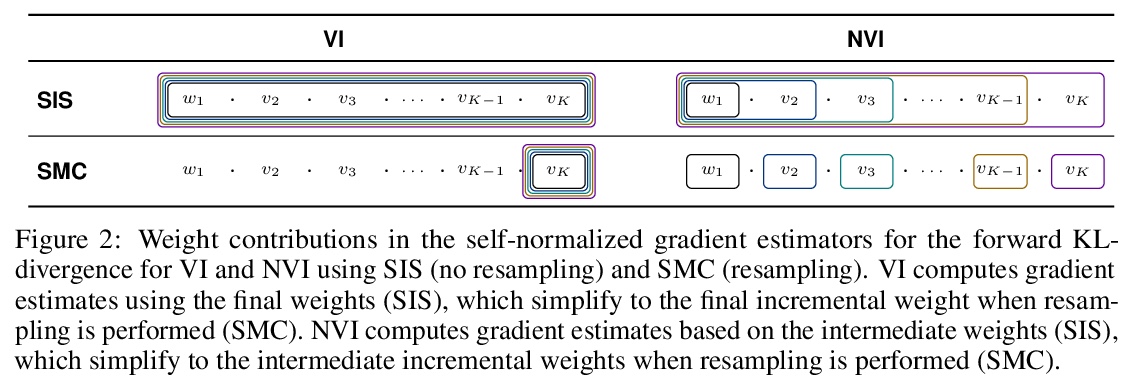
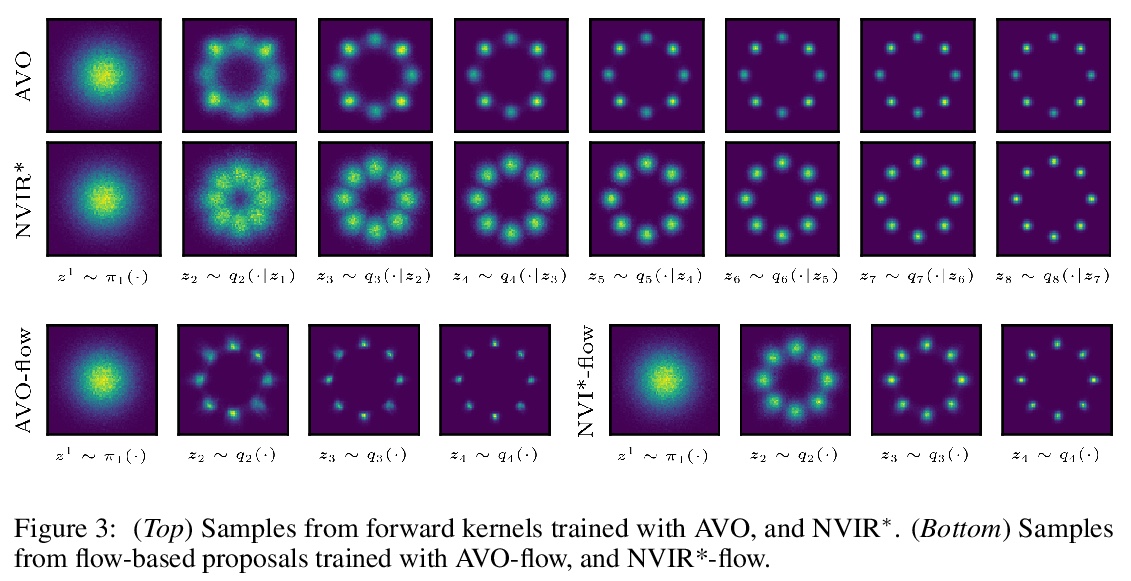
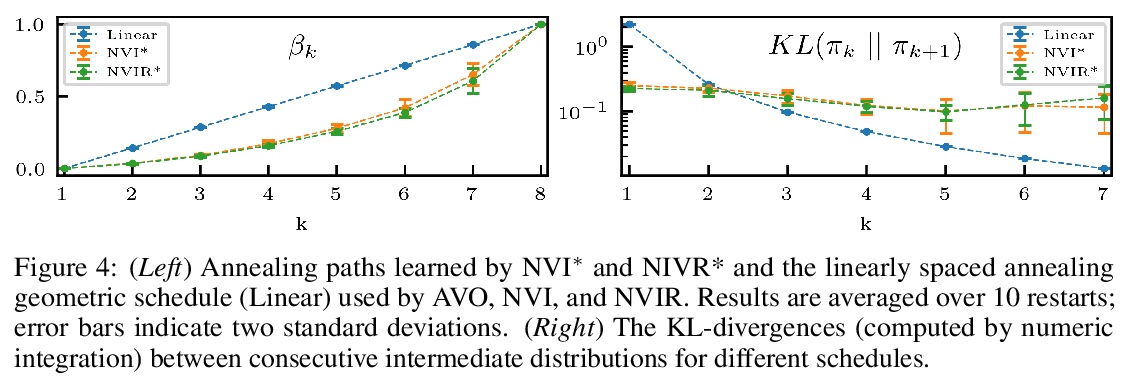
- [LG] Nested Variational Inference
- [CV] Understanding Object Dynamics for Interactive Image-to-Video Synthesis
- [CV] Towards Long-Form Video Understanding
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] GRAND: Graph Neural Diffusion
B P Chamberlain, J Rowbottom, M Gorinova, S Webb, E Rossi, M M. Bronstein
[Twitter]
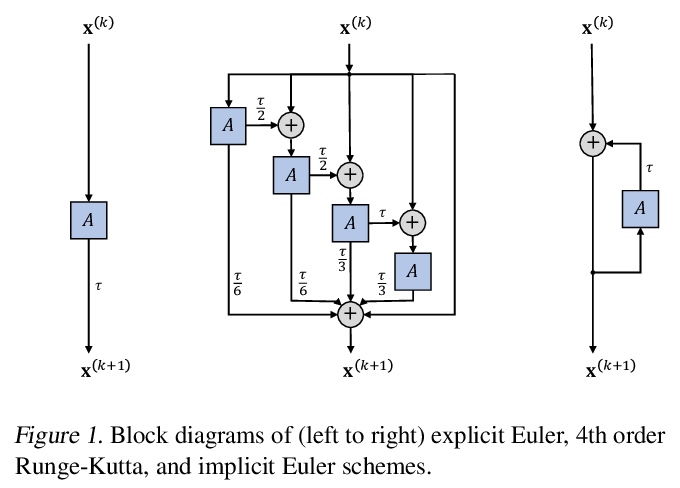
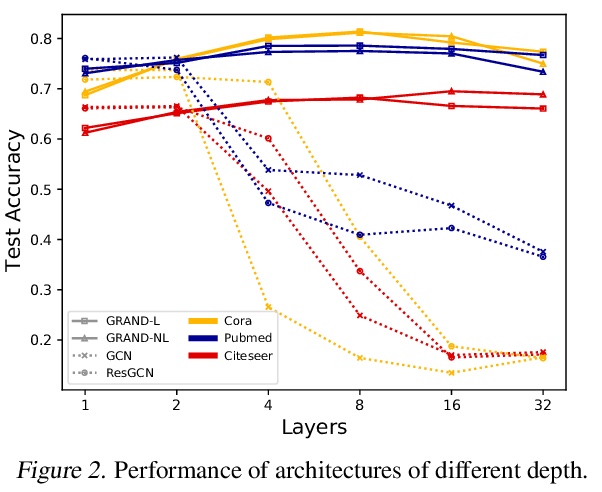
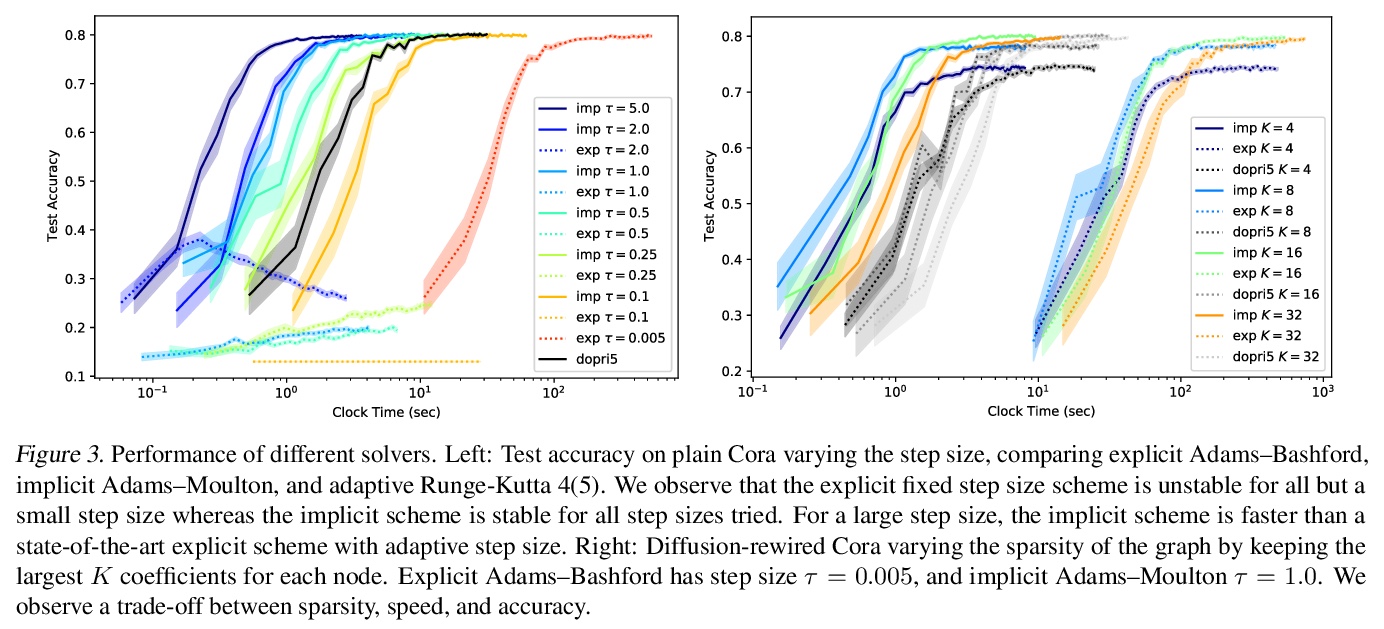
GRAND:图神经扩散。本文提出图神经扩散(GRAND),将图深度学习作为连续的扩散过程,并将图神经网络(GNNs)作为底层PDE的离散化。在该模型中,层结构和拓扑结构对应于时间和空间算子的离散化选择,允许有原则地开发一类广泛的新的GNN,解决图学习模型的常见困境,如深度、过平滑和瓶颈。模型成功的关键是对数据扰动的稳定性,在隐式和显式离散化方案中都得到了解决。开发了GRAND的线性和非线性版本,在许多标准图的基准上取得了有竞争力的结果。
We present Graph Neural Diffusion (GRAND) that approaches deep learning on graphs as a continuous diffusion process and treats Graph Neural Networks (GNNs) as discretisations of an underlying PDE. In our model, the layer structure and topology correspond to the discretisation choices of temporal and spatial operators. Our approach allows a principled development of a broad new class of GNNs that are able to address the common plights of graph learning models such as depth, oversmoothing, and bottlenecks. Key to the success of our models are stability with respect to perturbations in the data and this is addressed for both implicit and explicit discretisation schemes. We develop linear and nonlinear versions of GRAND, which achieve competitive results on many standard graph benchmarks.
https://weibo.com/1402400261/KlrFktAv5

2、[CV] Efficient Self-supervised Vision Transformers for Representation Learning
C Li, J Yang, P Zhang, M Gao, B Xiao, X Dai, L Yuan, J Gao
[Microsoft Research at Redmond & Microsoft Cloud + AI]
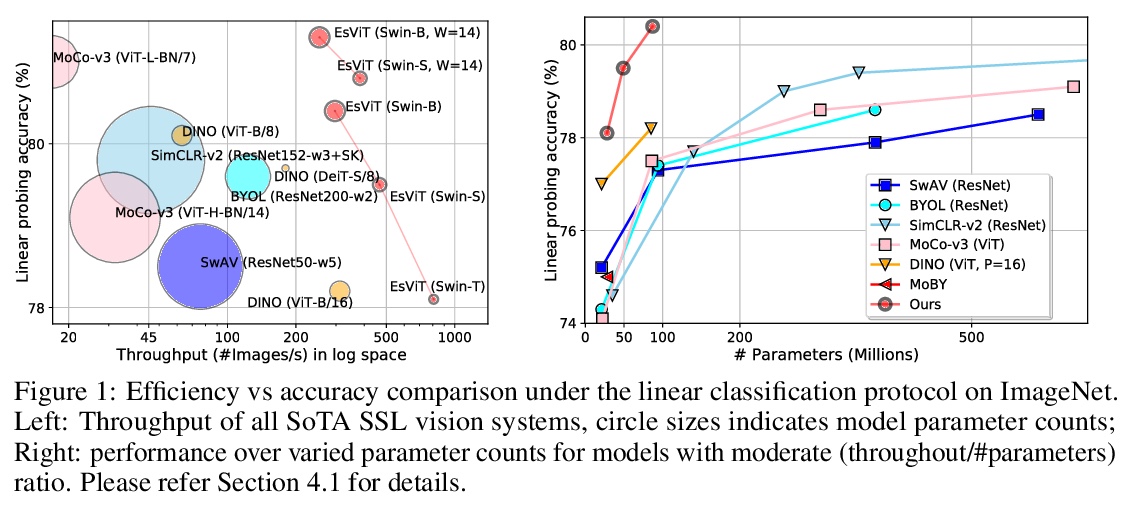
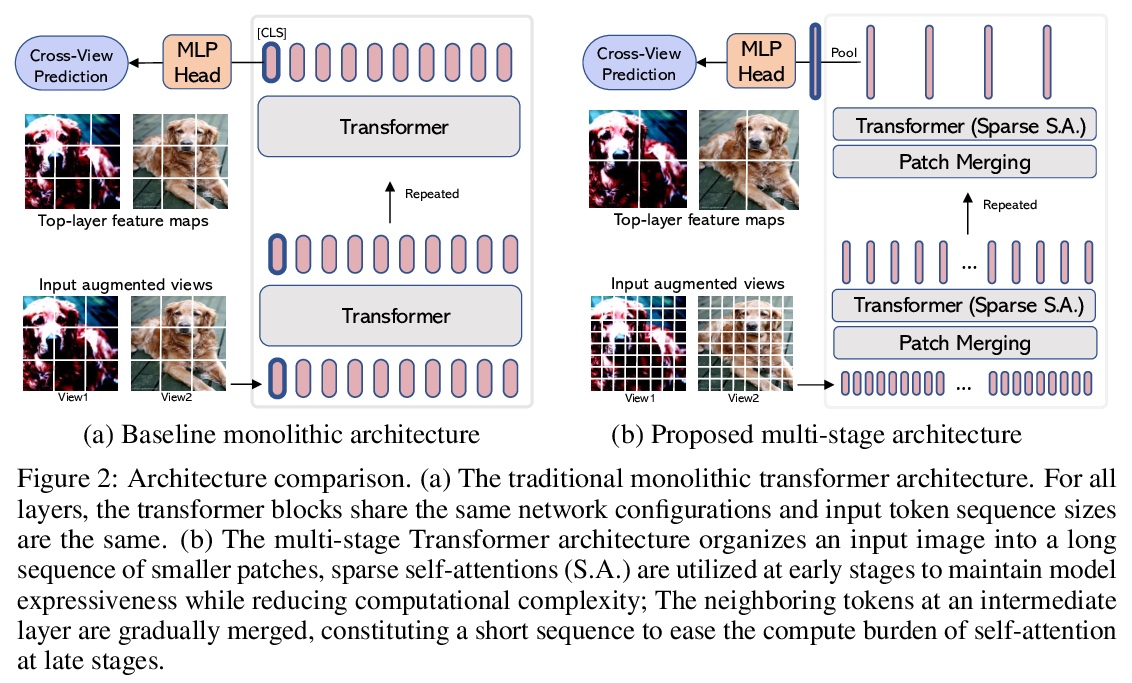
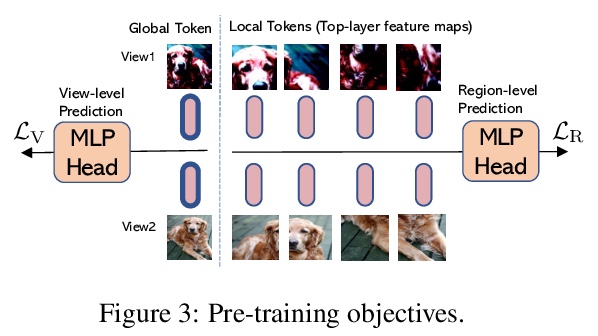
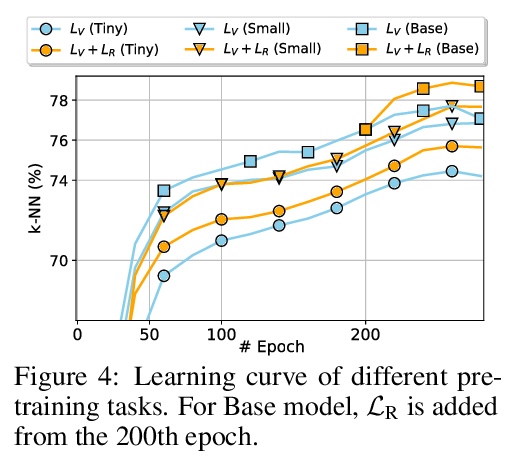
高效自监督视觉Transformer表示学习。为视觉表示学习开发了高效自监督视觉Transformer(EsViT)的两种技术。通过全面实证研究表明,具有稀疏自注意力的多阶段架构,可显著降低建模复杂度,但代价是失去了捕捉图像区域间细粒度对应关系的能力。提出一种新的区域匹配预训练任务,使模型能捕捉到细粒度区域依赖关系,从而显著提高了学到的视觉表示的质量。结果表明,结合两种技术,EsViT在ImageNet线性探测评估中取得了81.3%的最高分,超过了之前最先进水平,同时吞吐量高一个数量级。当迁移到下游线性分类任务时,EsViT在18个数据集中的17个数据集上,表现优于其有监督的对应方法。
This paper investigates two techniques for developing efficient self-supervised vision transformers (EsViT) for visual representation learning. First, we show through a comprehensive empirical study that multi-stage architectures with sparse self-attentions can significantly reduce modeling complexity but with a cost of losing the ability to capture fine-grained correspondences between image regions. Second, we propose a new pre-training task of region matching which allows the model to capture fine-grained region dependencies and as a result significantly improves the quality of the learned vision representations. Our results show that combining the two techniques, EsViT achieves 81.3% top-1 on the ImageNet linear probe evaluation, outperforming prior arts with around an order magnitude of higher throughput. When transferring to downstream linear classification tasks, EsViT outperforms its supervised counterpart on 17 out of 18 datasets. The code and models will be publicly available.
https://weibo.com/1402400261/KlrJYxCUS
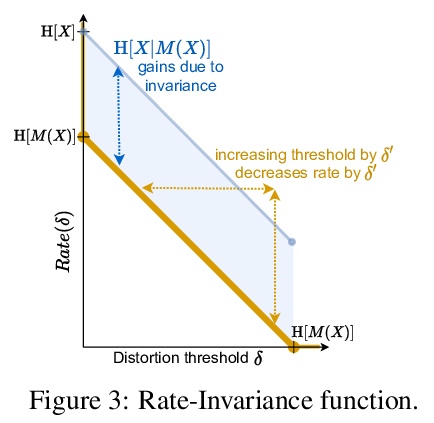
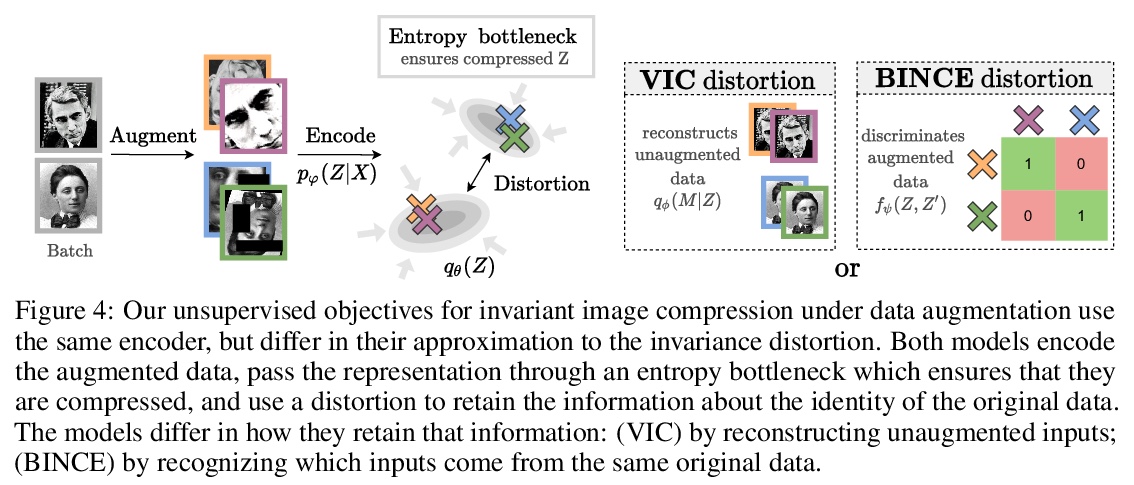
3、[LG] Lossy Compression for Lossless Prediction
Y Dubois, B Bloem-Reddy, K Ullrich, C J. Maddison
[Vector Institute & The University of British Columbia & Facebook AI Research]
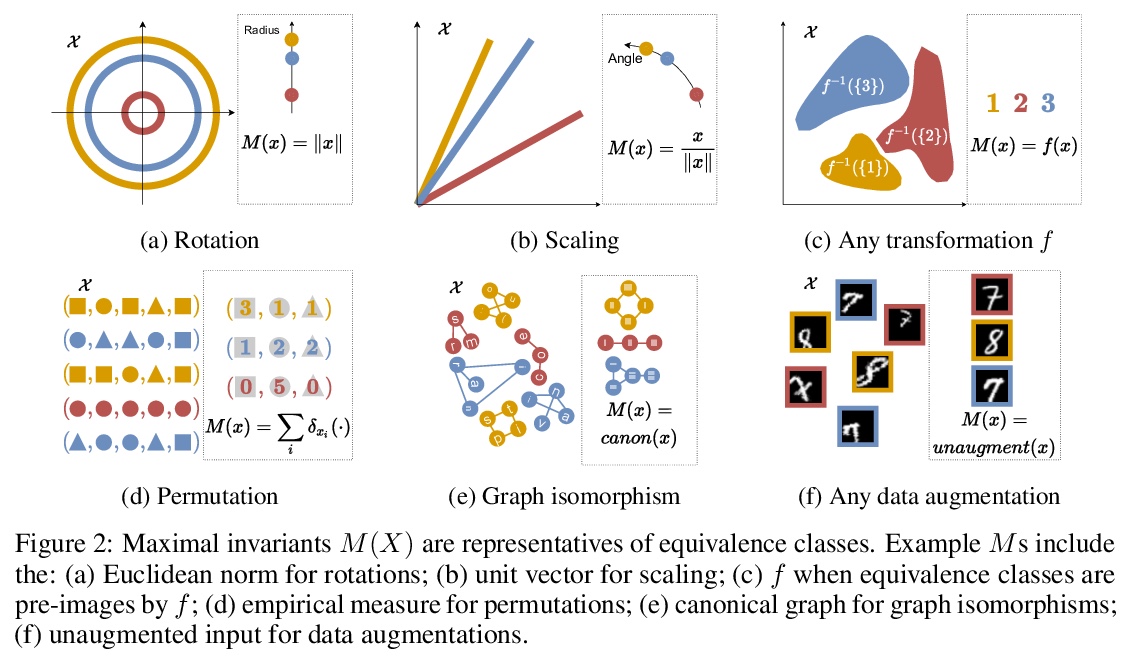
不影响预测性能的更好的有损压缩。大多数数据都是自动收集的,只用来给算法”看”。数据压缩器保留了感知的保真度,而不仅仅是执行下游任务的算法所需要的信息。本文描述了为确保所有预测任务的高性能所需的比特率,该比特率在一组变换下保持不变,如数据增强。基于该理论,为训练神经压缩器设计了无监督目标。利用这些目标,训练了一个通用的图像压缩器,与JPEG相比,在8个数据集上实现了大幅的速率提升(在ImageNet上超过1000倍),而没有降低下游的分类性能。
Most data is automatically collected and only ever “seen” by algorithms. Yet, data compressors preserve perceptual fidelity rather than just the information needed by algorithms performing downstream tasks. In this paper, we characterize the bit-rate required to ensure high performance on all predictive tasks that are invariant under a set of transformations, such as data augmentations. Based on our theory, we design unsupervised objectives for training neural compressors. Using these objectives, we train a generic image compressor that achieves substantial rate savings (more than 1000× on ImageNet) compared to JPEG on 8 datasets, without decreasing downstream classification performance.
https://weibo.com/1402400261/KlrN5ewA5

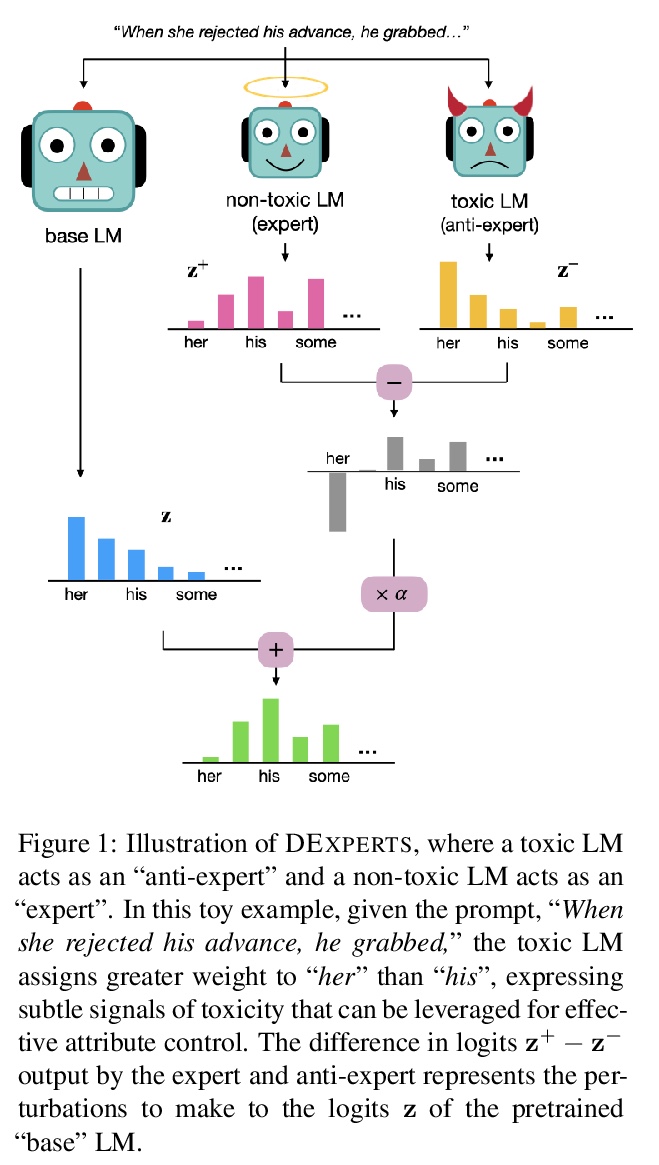
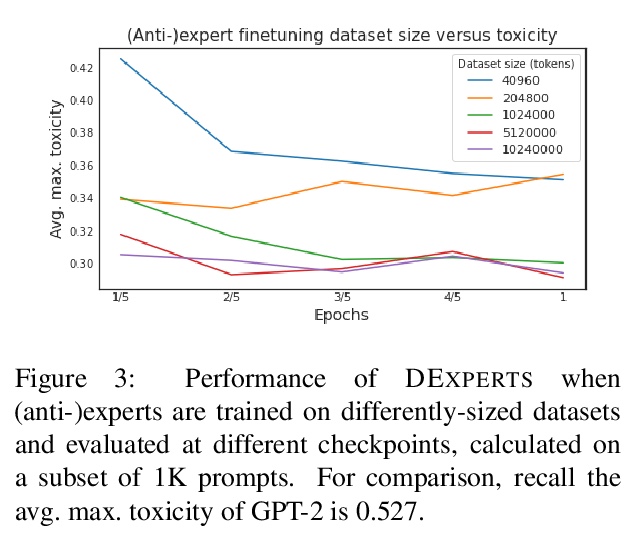
4、[CL] DExperts: Decoding-Time Controlled Text Generation with Experts and Anti-Experts
A Liu, M Sap, X Lu, S Swayamdipta, C Bhagavatula, N A. Smith, Y Choi
[University of Washington & Allen Institute for Artificial Intelligence]
DEXPERTS:基于专家和反专家的解码时控制文本生成。尽管最近在自然语言生成方面取得了进展,但控制生成文本的属性仍然具有挑战性。本文提出DEXPERTS:解码时专家,一种用于控制文本生成的解码时方法,将预训练语言模型与专家产品中的”专家”语言模型和/或”反专家”语言模型相结合。集成之后,只有当专家认为有可能,而反专家认为不可能的时候,token才会得到高概率。将DEXPERTS应用于语言解毒和情感控制生成,在自动和人工评估方面,表现都超过了现有的可控生成方法。此外,由于DEXPERTS只对预训练的语言模型的输出进行操作,对规模较小的(反)专家是有效的,包括在GPT-3上操作时。本工作强调了在具有(不)理想属性的文本上调整小型语言模型以实现高效解码时引导的前景。
Despite recent advances in natural language generation, it remains challenging to control attributes of generated text. We propose DEXPERTS: Decoding-time Experts, a decodingtime method for controlled text generation that combines a pretrained language model with “expert” LMs and/or “anti-expert” LMs in a product of experts. Intuitively, under the ensemble, tokens only get high probability if they are considered likely by the experts and unlikely by the anti-experts. We apply DEXPERTS to language detoxification and sentiment-controlled generation, where we outperform existing controllable generation methods on both automatic and human evaluations. Moreover, because DEXPERTS operates only on the output of the pretrained LM, it is effective with (anti-)experts of smaller size, including when operating on GPT-3. Our work highlights the promise of tuning small LMs on text with (un)desirable attributes for efficient decoding-time steering.
https://weibo.com/1402400261/KlrQXuIYc

5、[CV] VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning
H Tan, J Lei, T Wolf, M Bansal
[UNC Chapel Hill & Huggingface]
VIMPAC: 基于掩码标记预测和对比学习的视频预训练。视频理解依赖于对整体内容的感知和对其内部联系的建模(例如,因果关系、运动和时空对应)。为学习这些相互作用,在通过VQ-VAE生成的离散视频标记上应用了一个掩码-预测的预训练任务。与语言不同的是,在语言中文本标记是比较独立的,而相邻的视频标记通常有很强的相关性(例如,连续的视频帧通常看起来非常相似),因此,统一掩码单个标记会使任务过于琐碎,无法学到有用的表示。为解决该问题,提出了一个块掩码策略,在空间和时间域掩码相邻的视频标记。增加了一个非增强对比学习方法,通过预测视频片段是否来自同一视频进一步捕捉全局内容。在非策展视频上预训练模型,可以在几个视频理解数据集(如SSV2,Diving48)上达到最先进的结果。对模型的可扩展性和预训练方法的设计进行了详细分析。
Video understanding relies on perceiving the global content and modeling its internal connections (e.g., causality, movement, and spatio-temporal correspondence). To learn these interactions, we apply a mask-then-predict pre-training task on discretized video tokens generated via VQ-VAE. Unlike language, where the text tokens are more independent, neighboring video tokens typically have strong correlations (e.g., consecutive video frames usually look very similar), and hence uniformly masking individual tokens will make the task too trivial to learn useful representations. To deal with this issue, we propose a block-wise masking strategy where we mask neighboring video tokens in both spatial and temporal domains. We also add an augmentation-free contrastive learning method to further capture the global content by predicting whether the video clips are sampled from the same video. We pre-train our model on uncurated videos and show that our pre-trained model can reach state-of-the-art results on several video understanding datasets (e.g., SSV2, Diving48). Lastly, we provide detailed analyses on model scalability and pre-training method design.
https://weibo.com/1402400261/KlrTw9qdk


另外几篇值得关注的论文:
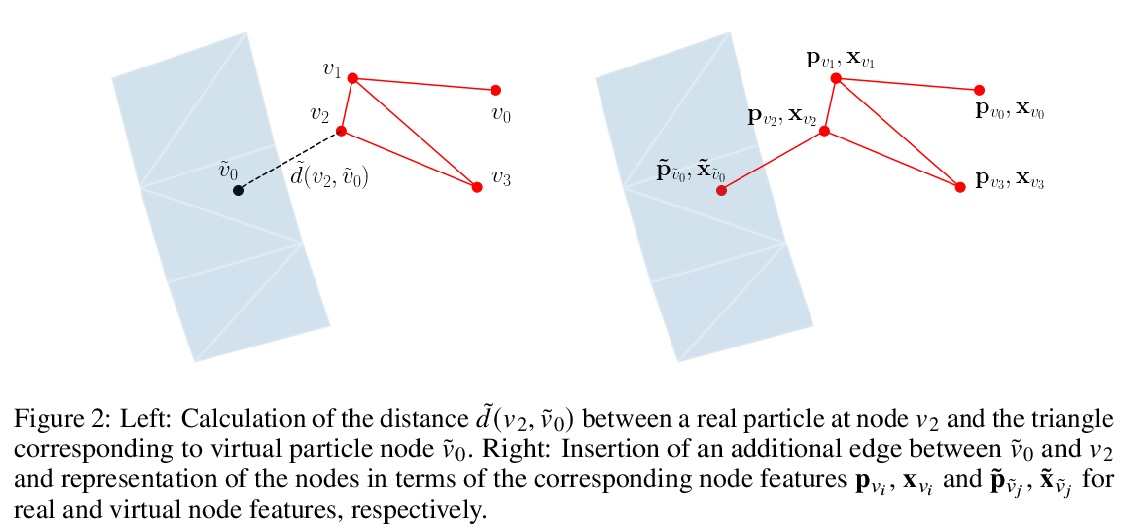
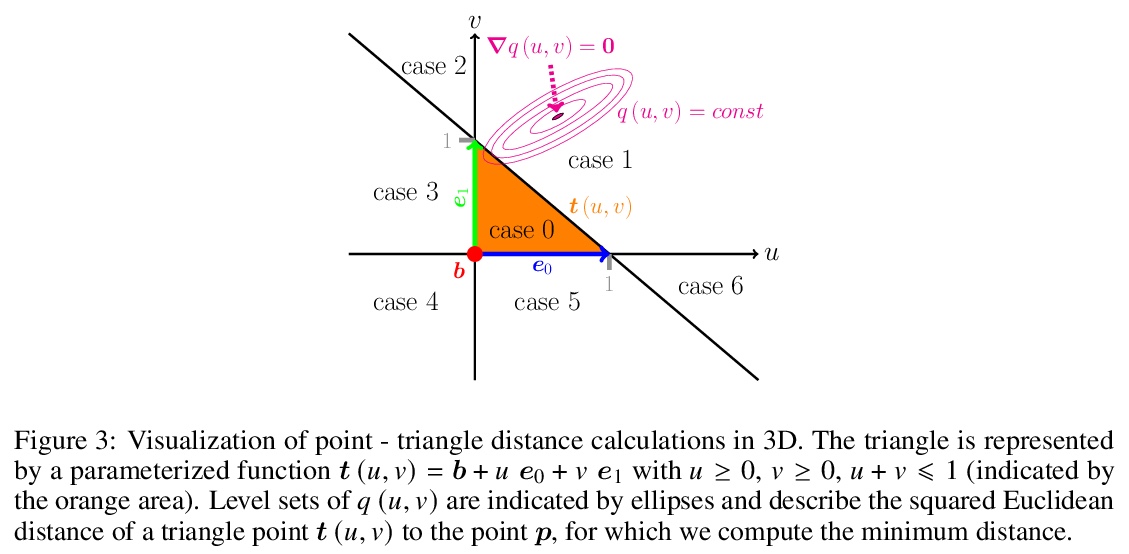
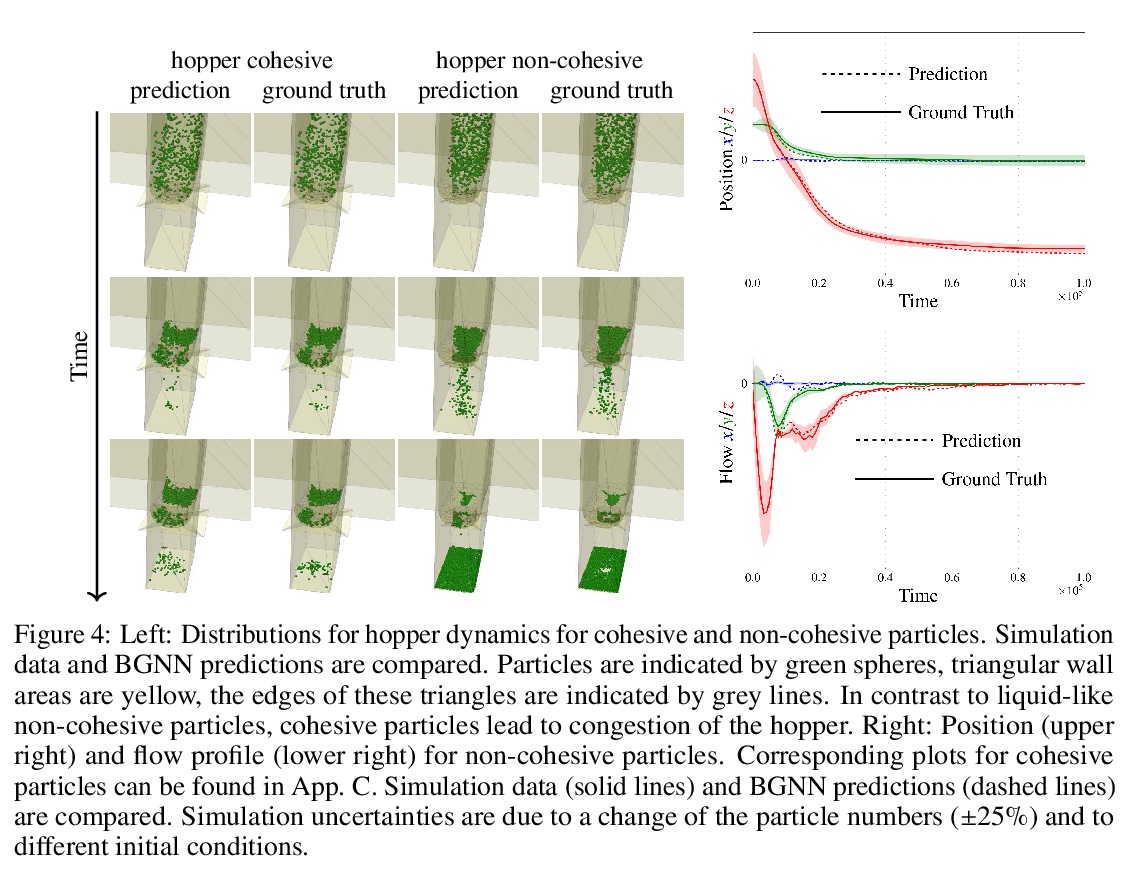
[LG] Boundary Graph Neural Networks for 3D Simulations
面向三维模拟的边界图神经网络
A Mayr, S Lehner, A Mayrhofer, C Kloss, S Hochreiter, J Brandstetter
[Johannes Kepler University Linz & DCS Computing GmbH & University of Amsterdam]
https://weibo.com/1402400261/KlrXBljDW
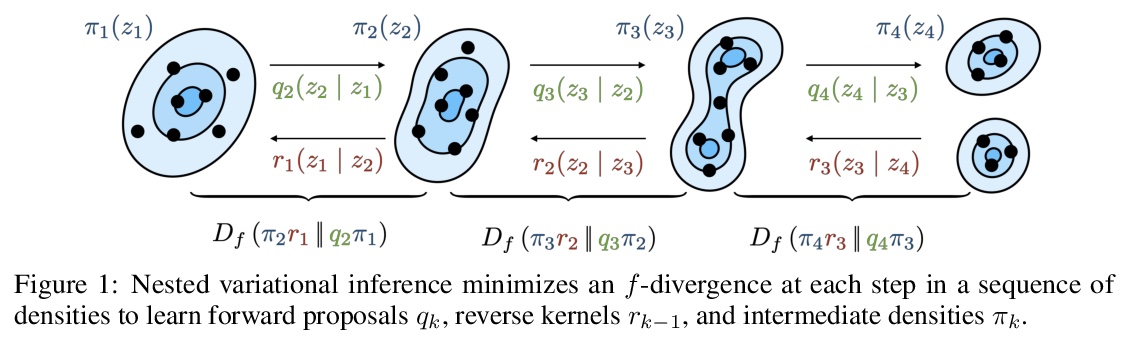
[LG] Nested Variational Inference
嵌套变分推理
H Zimmermann, H Wu, B Esmaeili, J v d Meent
[Northeastern University]
https://weibo.com/1402400261/KlrZKmUFL
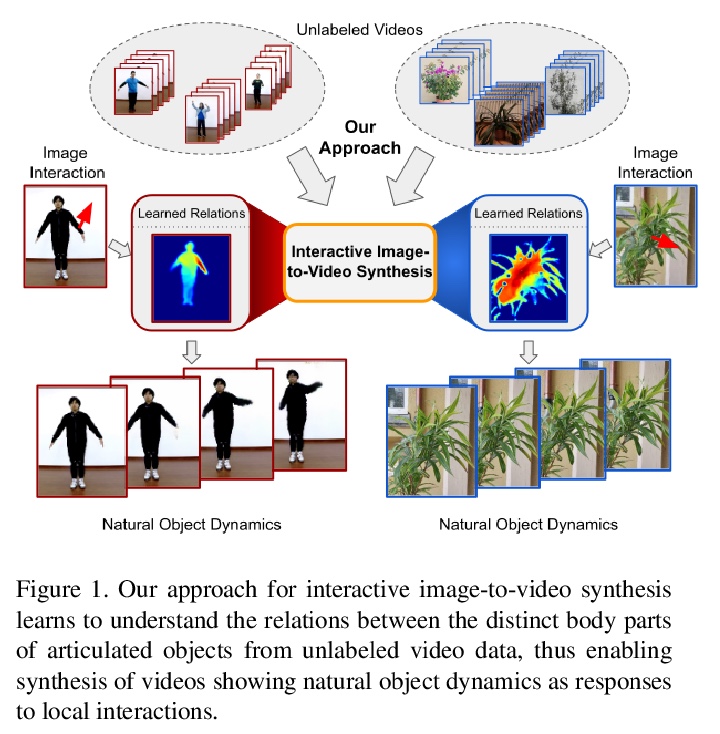
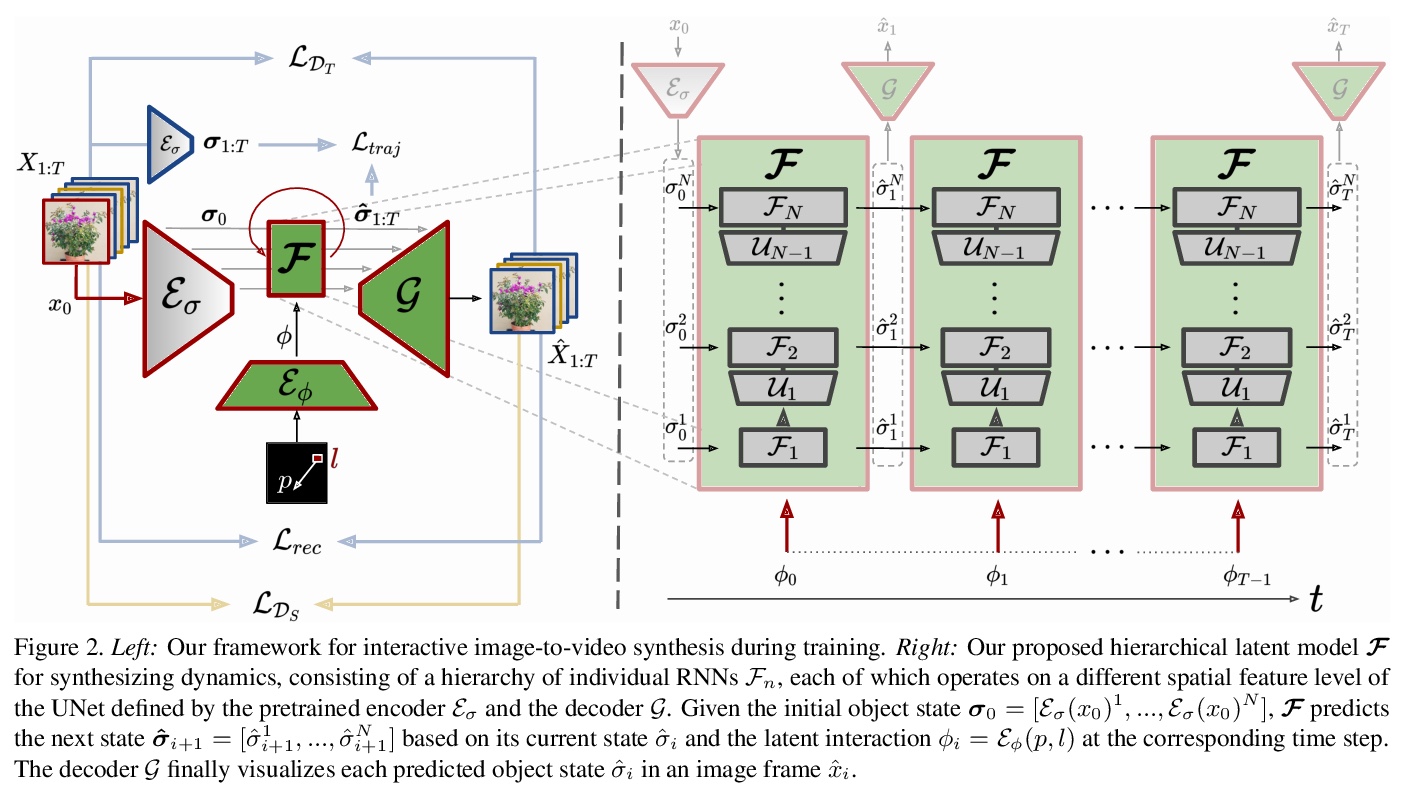
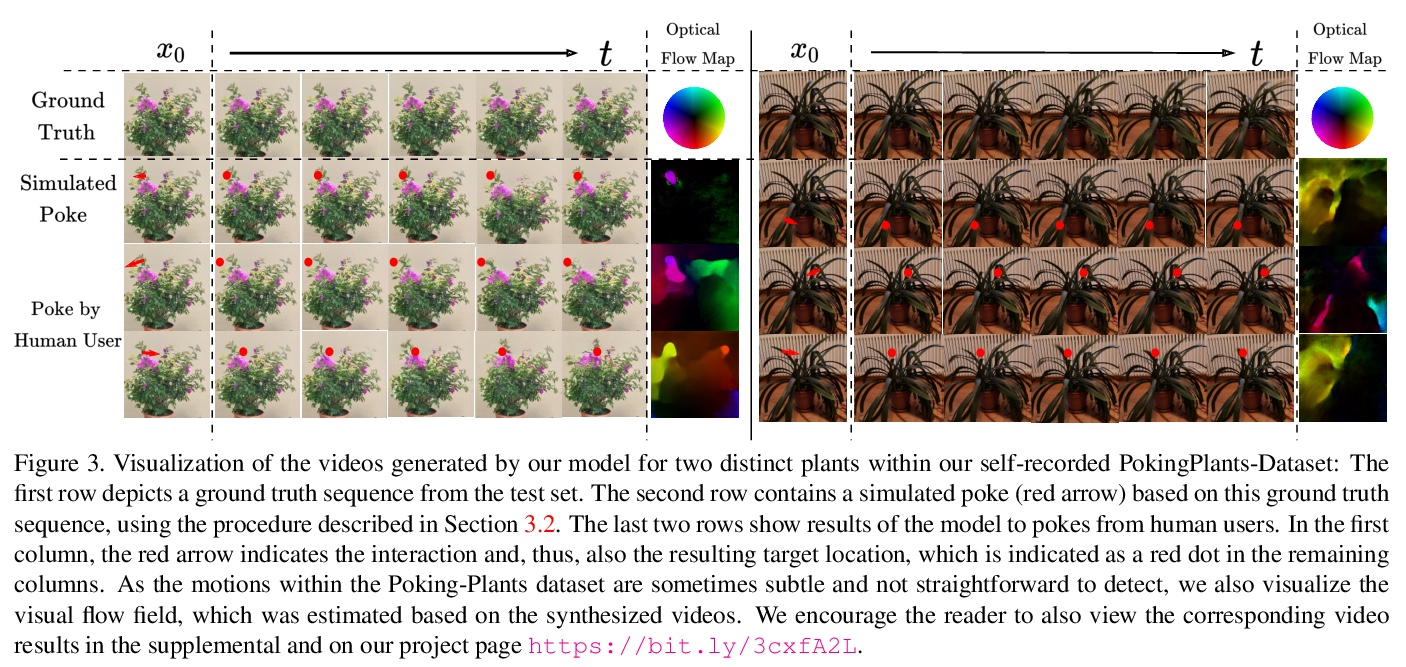
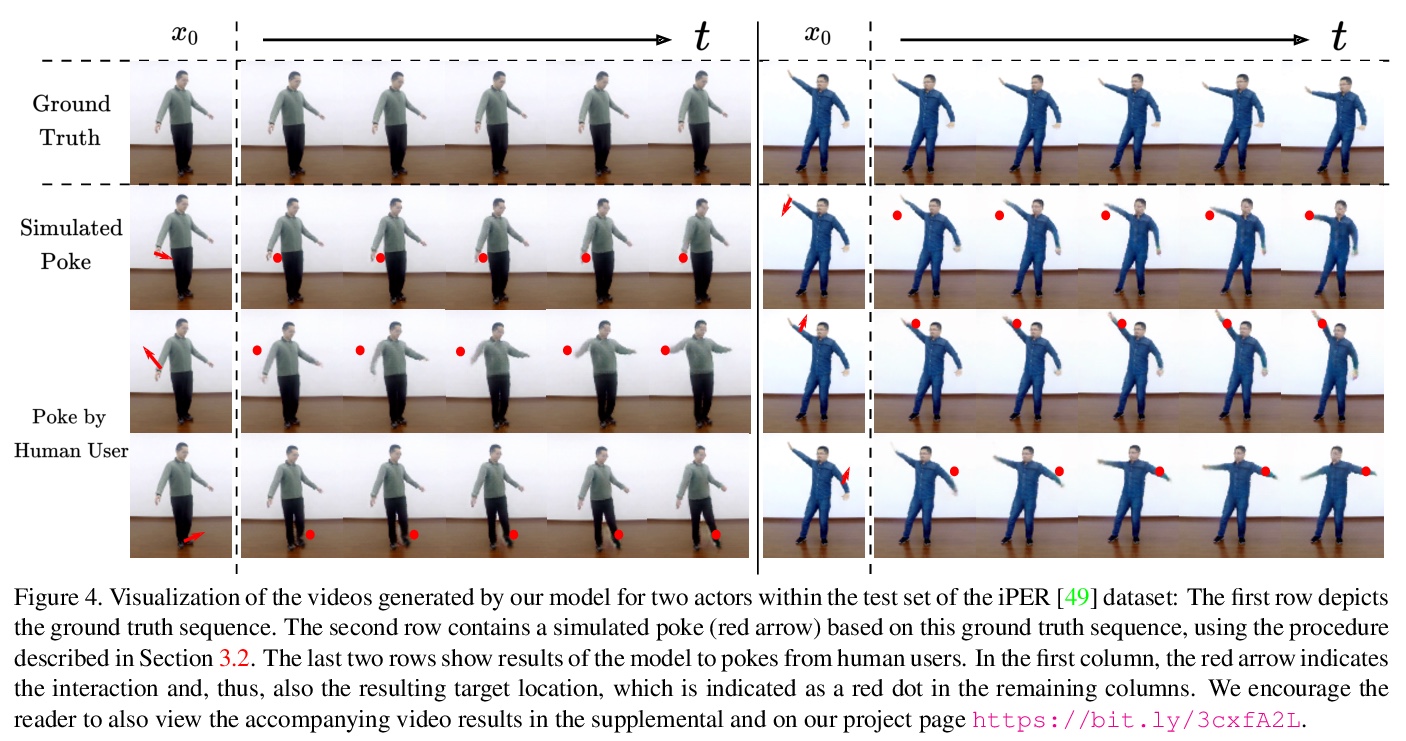
[CV] Understanding Object Dynamics for Interactive Image-to-Video Synthesis
理解交互式图像-视频合成的目标动力学
A Blattmann, T Milbich, M Dorkenwald, B Ommer
[Heidelberg University]
https://weibo.com/1402400261/Kls1vnZB1
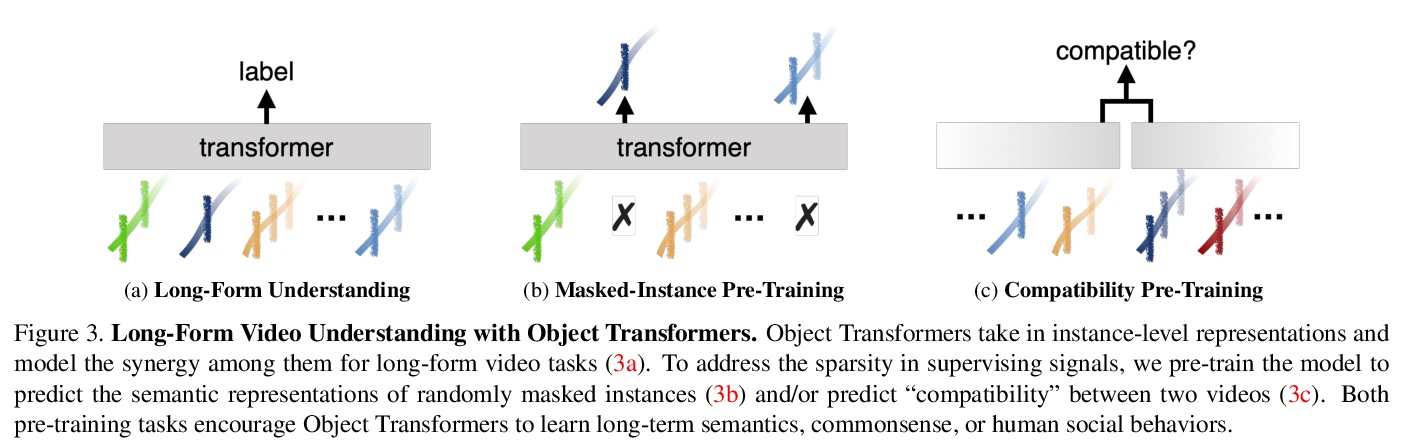
[CV] Towards Long-Form Video Understanding
长程视频理解探索
C Wu, P Krähenbühl
[The University of Texas at Austin]
https://weibo.com/1402400261/Kls5s35p8



若有收获,就点个赞吧
0 人点赞
