LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] *Bayesian Image Reconstruction using Deep Generative Models
R V Marinescu, D Moyer, P Golland
[MIT]
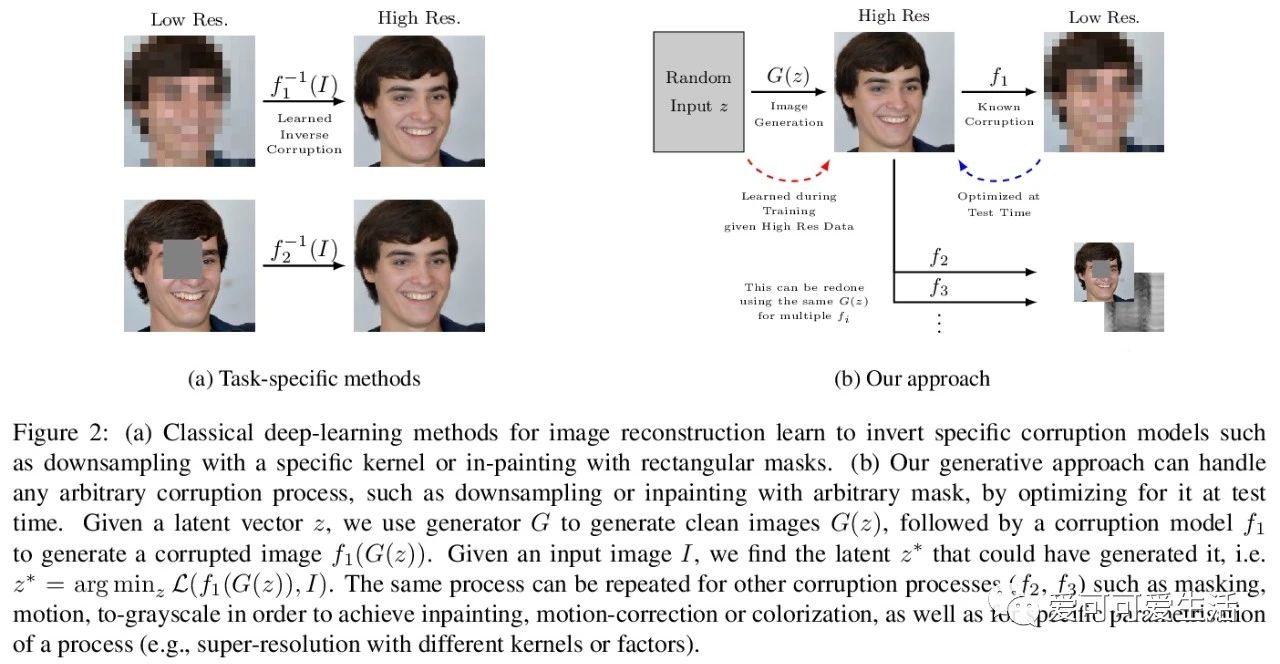
深度生成模型贝叶斯图像重建。提出生成模型贝叶斯重建(BRGM),用预训练生成器模型来执行不同的重建任务。利用最先进的生成模型(如StyleGAN2)来构建强大的图像先验,将贝叶斯定理应用于多种下游重建任务。在两个重建任务和三个不同数据集(包括两个具有挑战性的医学数据集)上进行了实验,在低分辨率输入上获得了比SOTA模型更好的超分辨率结果,以及通过定性和定量评估确认的图像补全效果。
Machine learning models are commonly trained end-to-end and in a supervised setting, using paired (input, output) data. Classical examples include recent super-resolution methods that train on pairs of (low-resolution, high-resolution) images. However, these end-to-end approaches require re-training every time there is a distribution shift in the inputs (e.g., night images vs daylight) or relevant latent variables (e.g., camera blur or hand motion). In this work, we leverage state-of-the-art (SOTA) generative models (here StyleGAN2) for building powerful image priors, which enable application of Bayes’ theorem for many downstream reconstruction tasks. Our method, called Bayesian Reconstruction through Generative Models (BRGM), uses a single pre-trained generator model to solve different image restoration tasks, i.e., super-resolution and in-painting, by combining it with different forward corruption models. We demonstrate BRGM on three large, yet diverse, datasets that enable us to build powerful priors: (i) 60,000 images from the Flick Faces High Quality dataset karras2019style (ii) 240,000 chest X-rays from MIMIC III and (iii) a combined collection of 5 brain MRI datasets with 7,329 scans. Across all three datasets and without any dataset-specific hyperparameter tuning, our approach yields state-of-the-art performance on super-resolution, particularly at low-resolution levels, as well as inpainting, compared to state-of-the-art methods that are specific to each reconstruction task. We will make our code and pre-trained models available online.
https://weibo.com/1402400261/JxKWbfBNc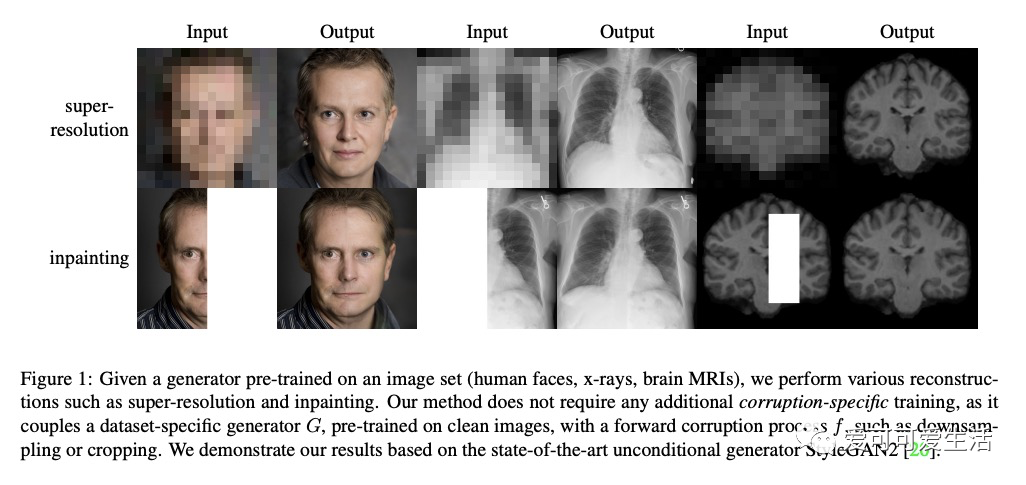

2、 [CV] Vid2CAD: CAD Model Alignment using Multi-View Constraints from Videos
K Maninis, S Popov, M Nießner, V Ferrari
[Google Research & Technical University of Munich]
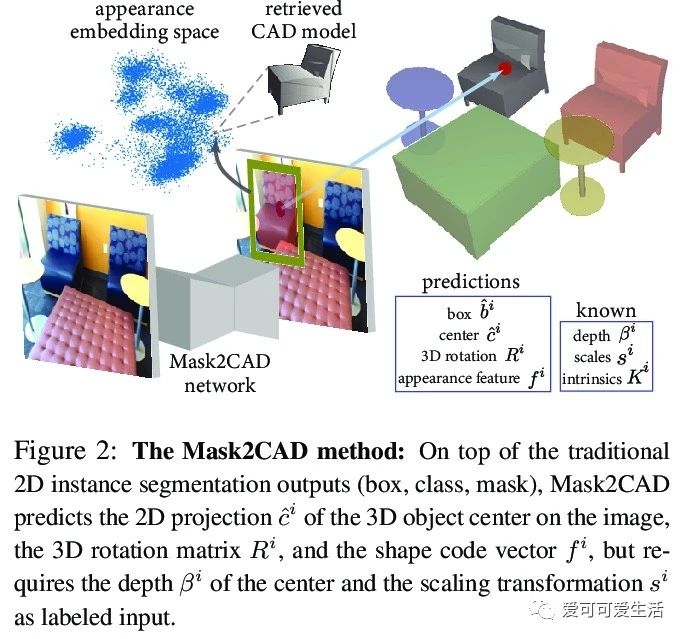
视频多视图约束CAD模型对齐。提出了Vid2CAD,将CAD模型与包含多个对象的复杂场景的视频序列对齐,能处理任意视频,全自动恢复其中出现的每个物体的9自由度姿态,并在共同的三维坐标系中对齐它们。其核心思想是利用多视图约束,来整合跨时间各帧的网络预测,获得由底层CAD模型表示的全局一致的3D场景。与最佳的单帧方法Mask2CAD相比,Vid2CAD得了显著的提高,类平均精度从11.6%提高到30.2%。
We address the task of aligning CAD models to a video sequence of a complex scene containing multiple objects. Our method is able to process arbitrary videos and fully automatically recover the 9 DoF pose for each object appearing in it, thus aligning them in a common 3D coordinate frame. The core idea of our method is to integrate neural network predictions from individual frames with a temporally global, multi-view constraint optimization formulation. This integration process resolves the scale and depth ambiguities in the per-frame predictions, and generally improves the estimate of all pose parameters. By leveraging multi-view constraints, our method also resolves occlusions and handles objects that are out of view in individual frames, thus reconstructing all objects into a single globally consistent CAD representation of the scene. In comparison to the state-of-the-art single-frame method Mask2CAD that we build on, we achieve substantial improvements on Scan2CAD (from 11.6% to 30.2% class average accuracy).
https://weibo.com/1402400261/JxL4taBW0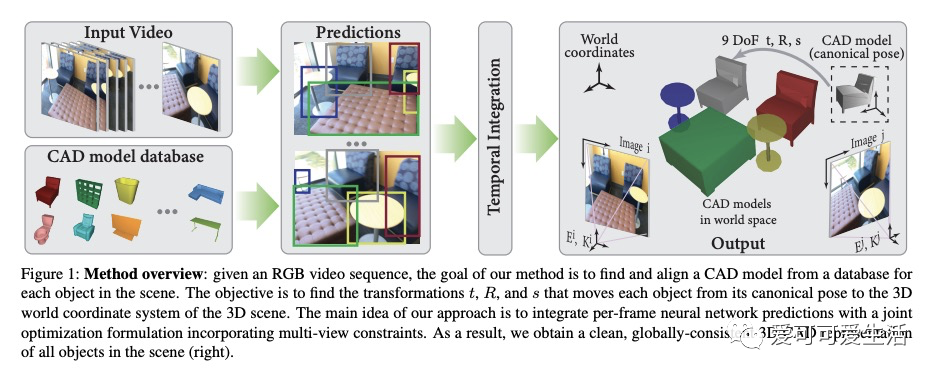

3、 [ME] What are the most important statistical ideas of the past 50 years?
A Gelman, A Vehtari
[Columbia University & Aalto University]
50年来最重要的统计思想。认为过去半个世纪最重要的统计思想是:反事实因果推理、bootstrapping和基于仿真的推理、超参数化模型和正则化、多级模型、通用计算算法、自适应决策分析、稳健推断和探索性数据分析。讨论了这些想法的共同特点,它们如何与现代计算和大数据相关联,以及在未来几十年将如何被开发和扩展。
We argue that the most important statistical ideas of the past half century are: counterfactual causal inference, bootstrapping and simulation-based inference, overparameterized models and regularization, multilevel models, generic computation algorithms, adaptive decision analysis, robust inference, and exploratory data analysis. We discuss common features of these ideas, how they relate to modern computing and big data, and how they might be developed and extended in future decades. The goal of this article is to provoke thought and discussion regarding the larger themes of research in statistics and data science.
https://weibo.com/1402400261/JxL8V4uP3
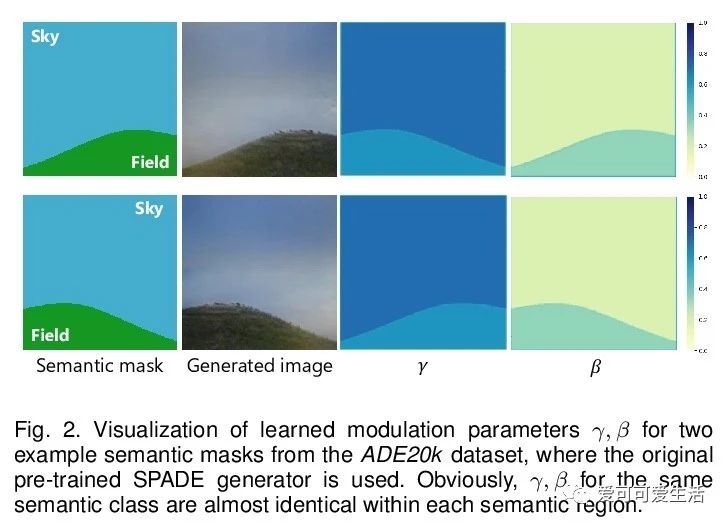
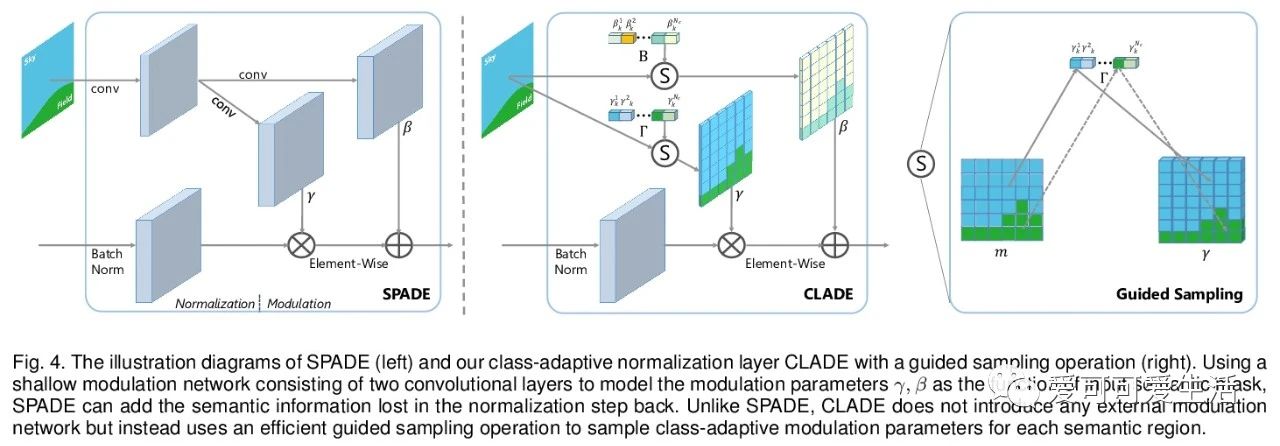
4、[CV] Semantic Image Synthesis via Efficient Class-Adaptive Normalization
Z Tan, D Chen, Q Chu, M Chai, J Liao, M He, L Yuan, G Hua, N Yu
[University of Science and Technology of China & Microsoft Research & City University of Hong Kong]
基于高效类自适应规范化的语义图像合成。提出了类自适应规范化(CLADE),一种轻量级、与空间自适应归一化(SPADE)同等有效的变体,只对语义类进行自适应。引入由语义布局计算的类内位置图编码来调整CLADE的归一化参数,提出了真正的空间自适应CLADE变体CLADE-ICPE,大大降低了计算成本,同时能在生成过程中保留语义信息。通过实验,证明了CLADE可推广到各种基于SPADE的方法,获得与SPADE相当的生成质量,但效率更高,额外参数更少,计算成本更低。**
Spatially-adaptive normalization (SPADE) is remarkably successful recently in conditional semantic image synthesis, which modulates the normalized activation with spatially-varying transformations learned from semantic layouts, to prevent the semantic information from being washed away. Despite its impressive performance, a more thorough understanding of the advantages inside the box is still highly demanded to help reduce the significant computation and parameter overhead introduced by this novel structure. In this paper, from a return-on-investment point of view, we conduct an in-depth analysis of the effectiveness of this spatially-adaptive normalization and observe that its modulation parameters benefit more from semantic-awareness rather than spatial-adaptiveness, especially for high-resolution input masks. Inspired by this observation, we propose class-adaptive normalization (CLADE), a lightweight but equally-effective variant that is only adaptive to semantic class. In order to further improve spatial-adaptiveness, we introduce intra-class positional map encoding calculated from semantic layouts to modulate the normalization parameters of CLADE and propose a truly spatially-adaptive variant of CLADE, namely CLADE-ICPE. %Benefiting from this design, CLADE greatly reduces the computation cost while being able to preserve the semantic information in the generation. Through extensive experiments on multiple challenging datasets, we demonstrate that the proposed CLADE can be generalized to different SPADE-based methods while achieving comparable generation quality compared to SPADE, but it is much more efficient with fewer extra parameters and lower computational cost.
https://weibo.com/1402400261/JxLcgg7W5
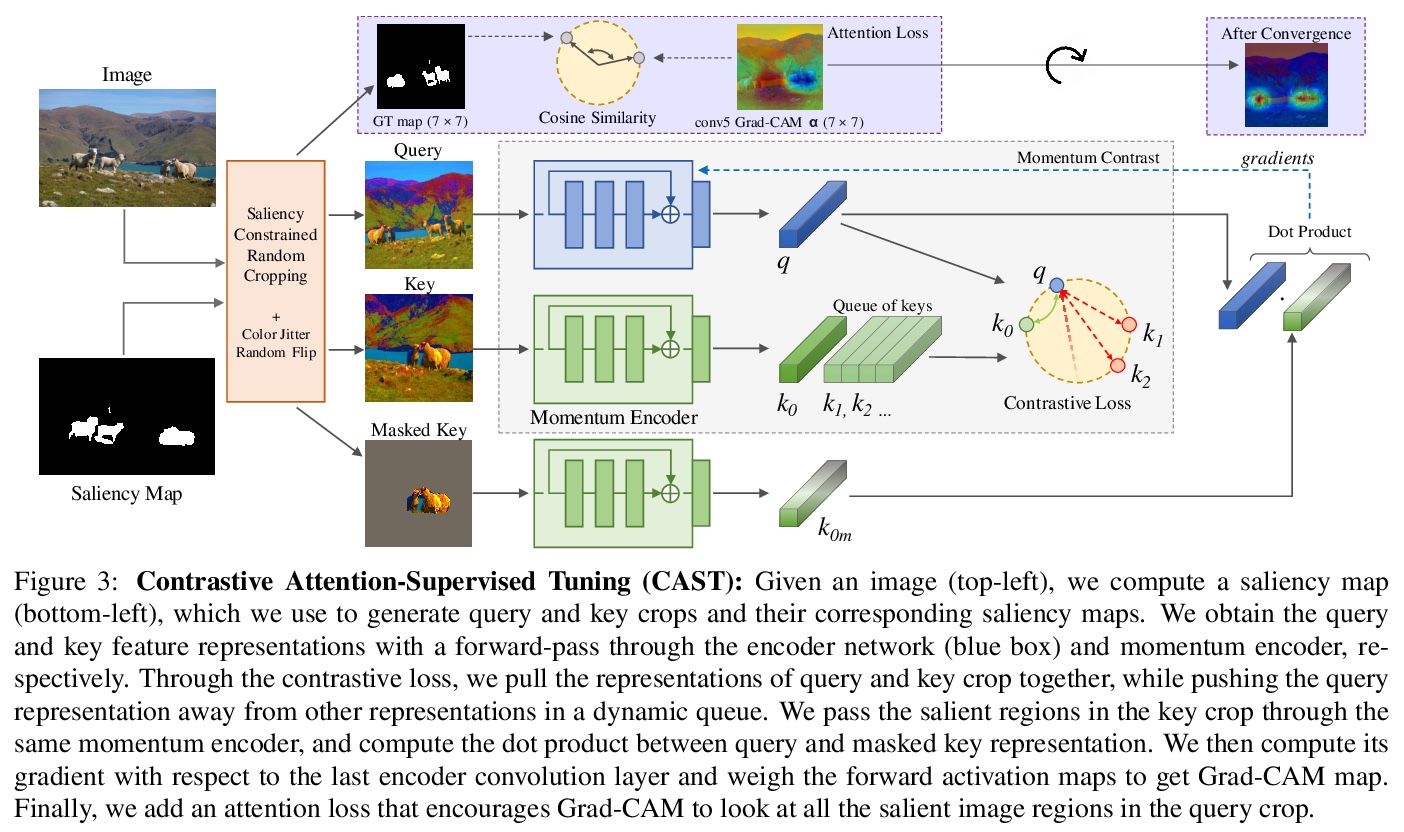
5、[CV] CASTing Your Model: Learning to Localize Improves Self-Supervised Representations
R R. Selvaraju, K Desai, J Johnson, N Naik
[Salesforce Research & University of Michigan]
学习局部化改善自监督表示。提出对比注意力监督微调(CAST),用无监督显著图对目标智能采样,通过Grad-CAM注意力损失提供监督。CAST改进了从场景图像学习的特征表示,与仅使用对比学习训练的特征相比,这些特征表征对背景相关性的依赖程度更低,具有更好的分布外表现,对上下文偏差和对抗背景具有更强的鲁棒性。
Recent advances in self-supervised learning (SSL) have largely closed the gap with supervised ImageNet pretraining. Despite their success these methods have been primarily applied to unlabeled ImageNet images, and show marginal gains when trained on larger sets of uncurated images. We hypothesize that current SSL methods perform best on iconic images, and struggle on complex scene images with many objects. Analyzing contrastive SSL methods shows that they have poor visual grounding and receive poor supervisory signal when trained on scene images. We propose Contrastive Attention-Supervised Tuning(CAST) to overcome these limitations. CAST uses unsupervised saliency maps to intelligently sample crops, and to provide grounding supervision via a Grad-CAM attention loss. Experiments on COCO show that CAST significantly improves the features learned by SSL methods on scene images, and further experiments show that CAST-trained models are more robust to changes in backgrounds.
https://weibo.com/1402400261/JxLgQwUOM

其他几篇值得关注的论文:
[LG] Generalization bounds for deep learning
深度学习的泛化界
G Valle-Pérez, A A. Louis
[University of Oxford]
https://weibo.com/1402400261/JxLoVk7Me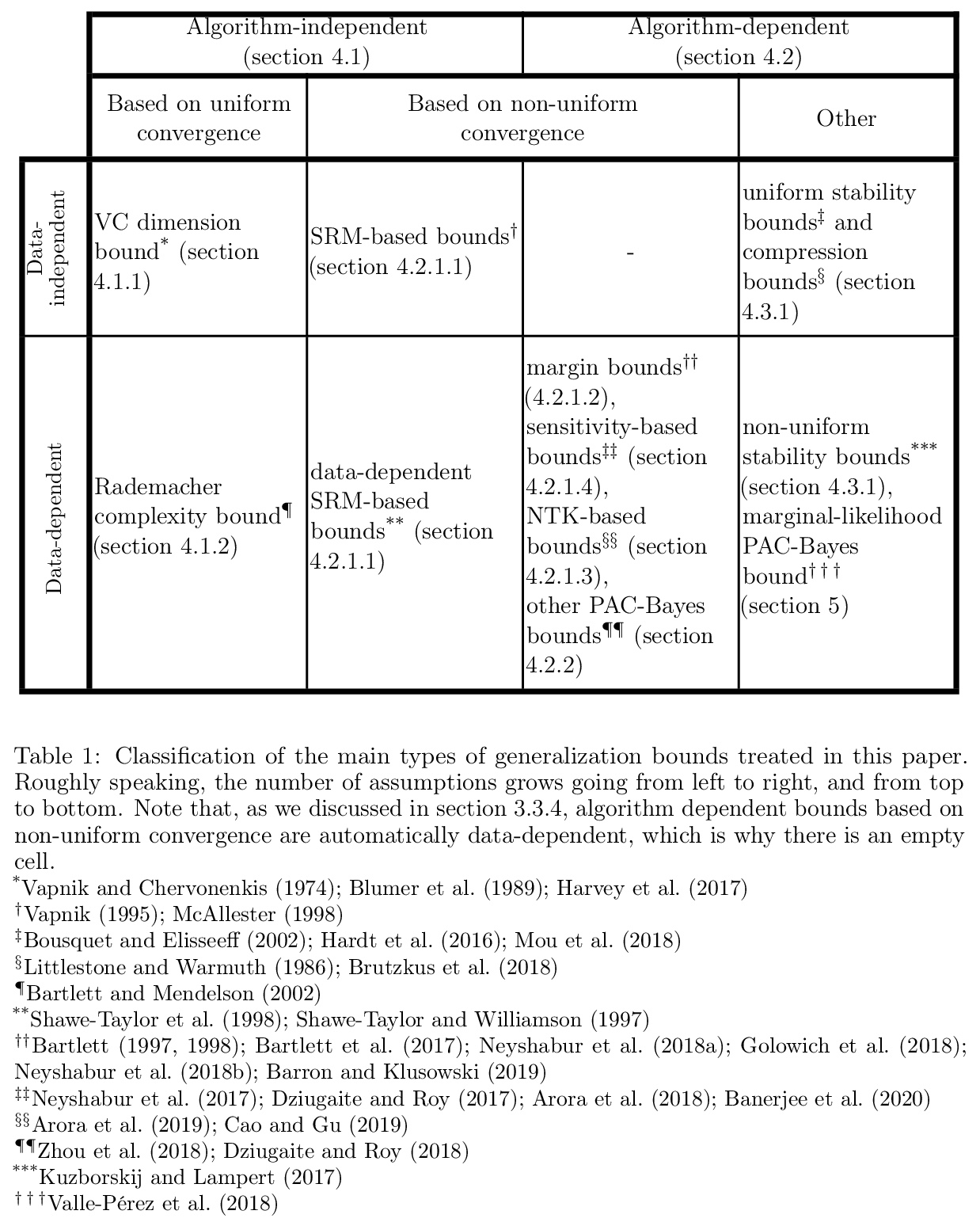
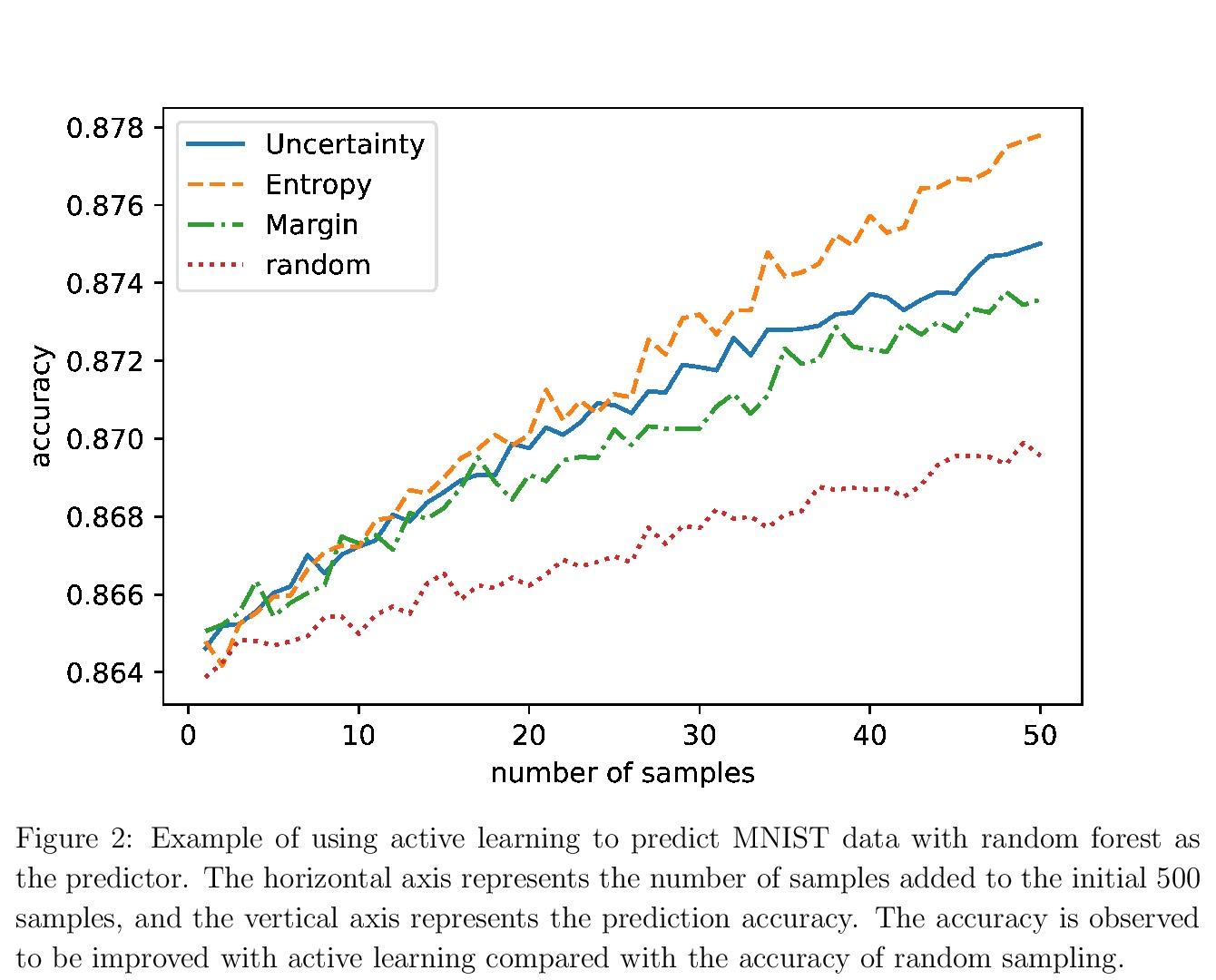
[LG] Active Learning: Problem Settings and Recent Developments
主动学习:问题设置与最新进展
H Hino
[The Institute of Statistical Mathematics]
https://weibo.com/1402400261/JxLpXbY8S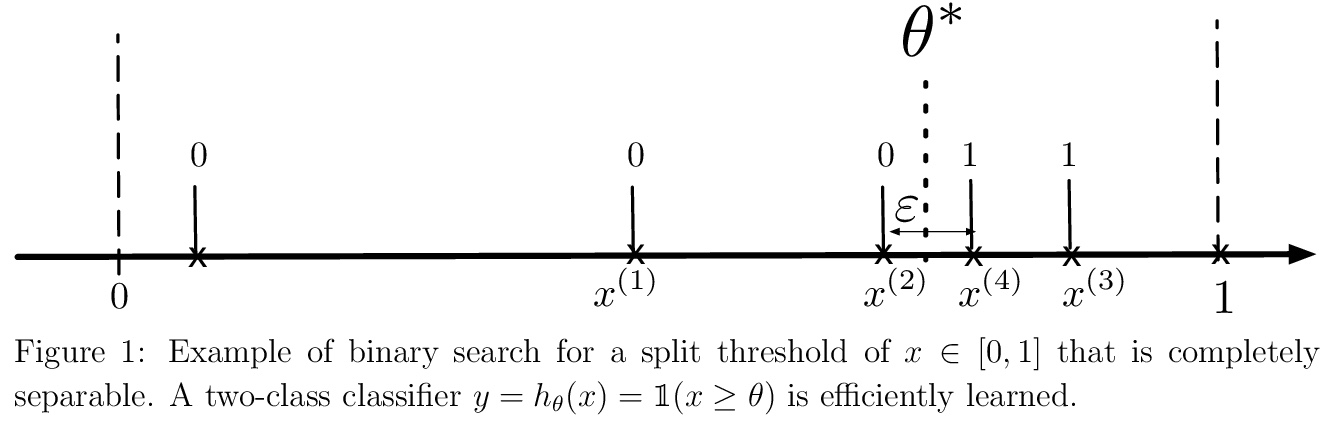
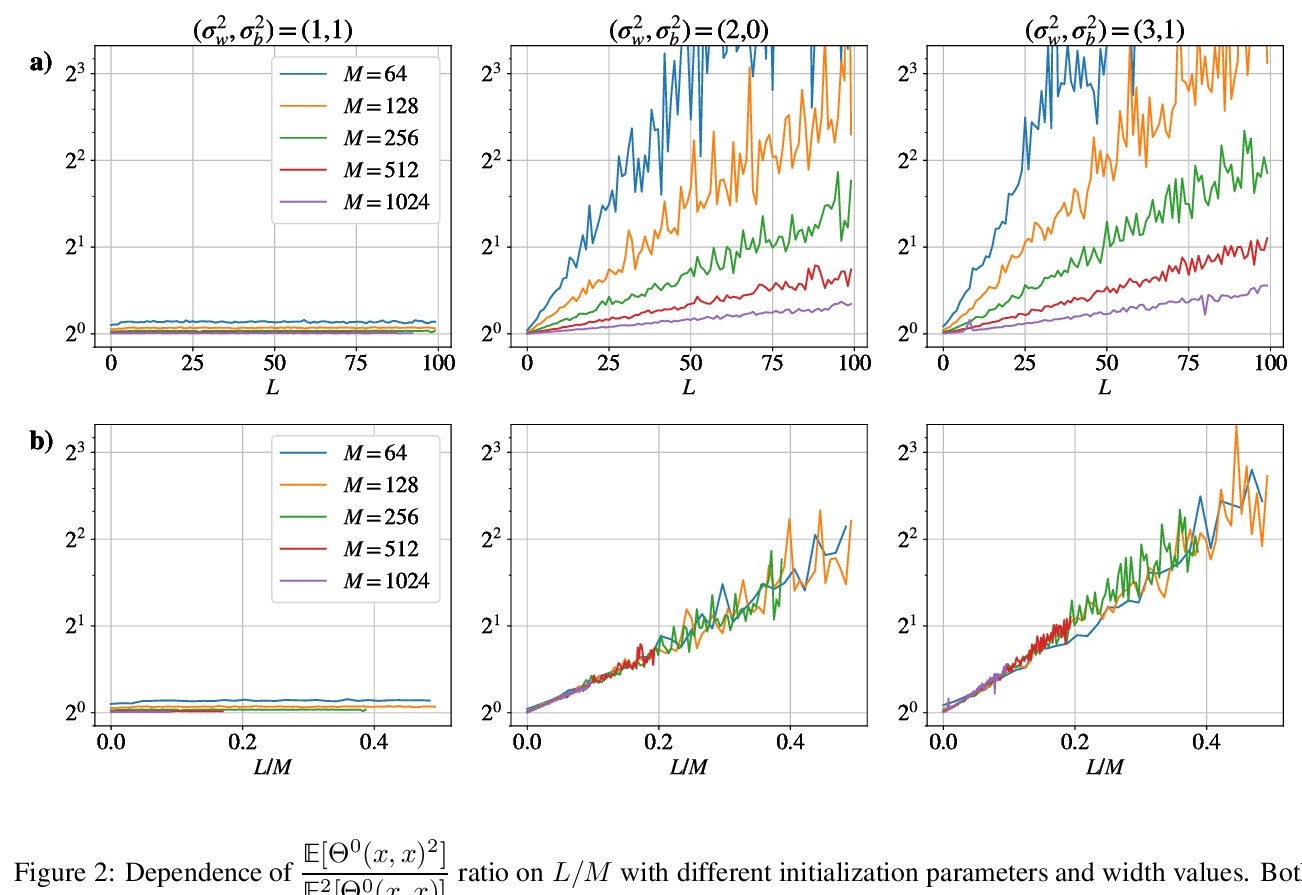
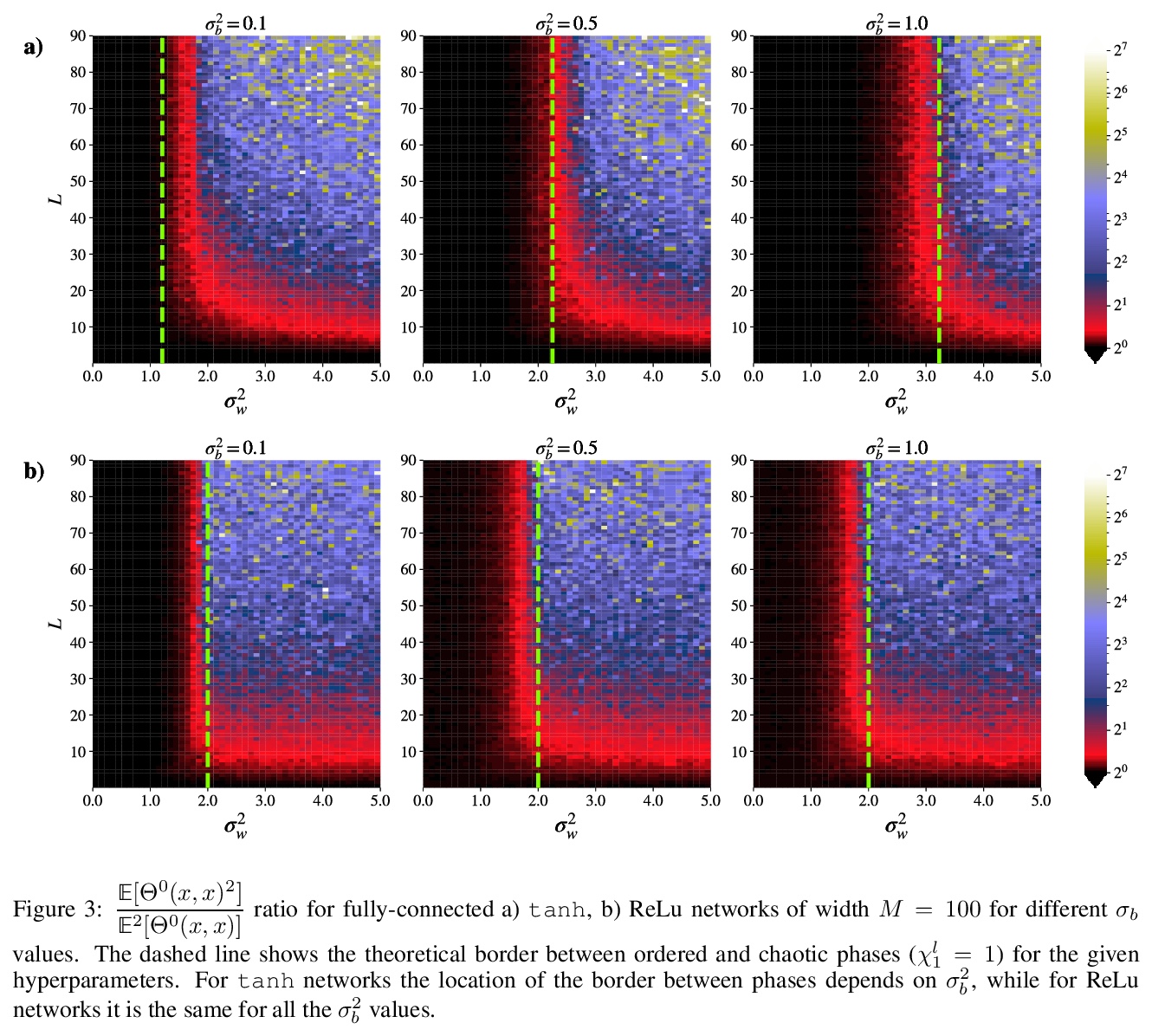
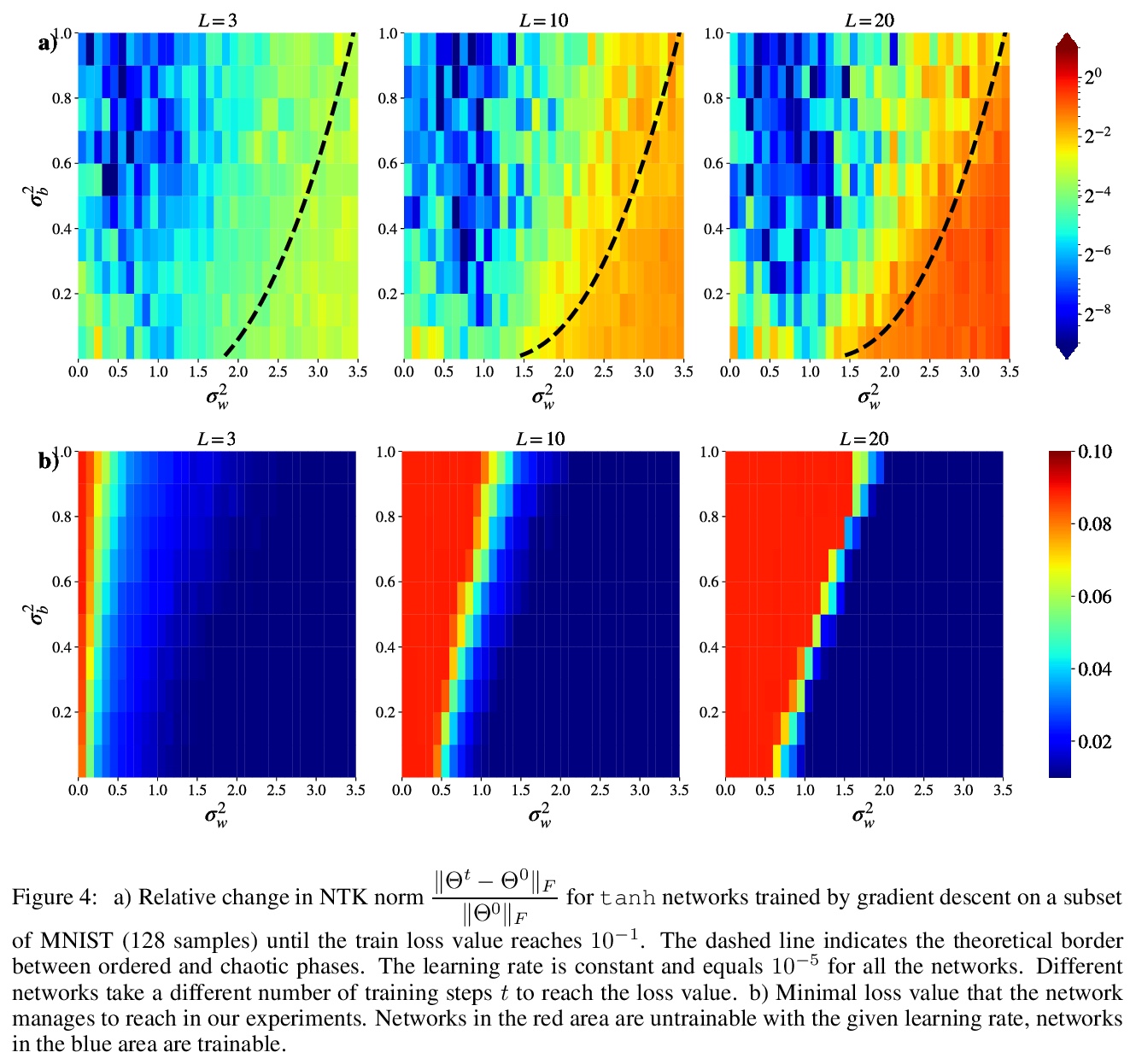
[LG] Analyzing Finite Neural Networks: Can We Trust Neural Tangent Kernel Theory?
有限神经网络分析:神经正切核理论可信吗?
M Seleznova, G Kutyniok
[LMU Munich]
https://weibo.com/1402400261/JxLrrliZL
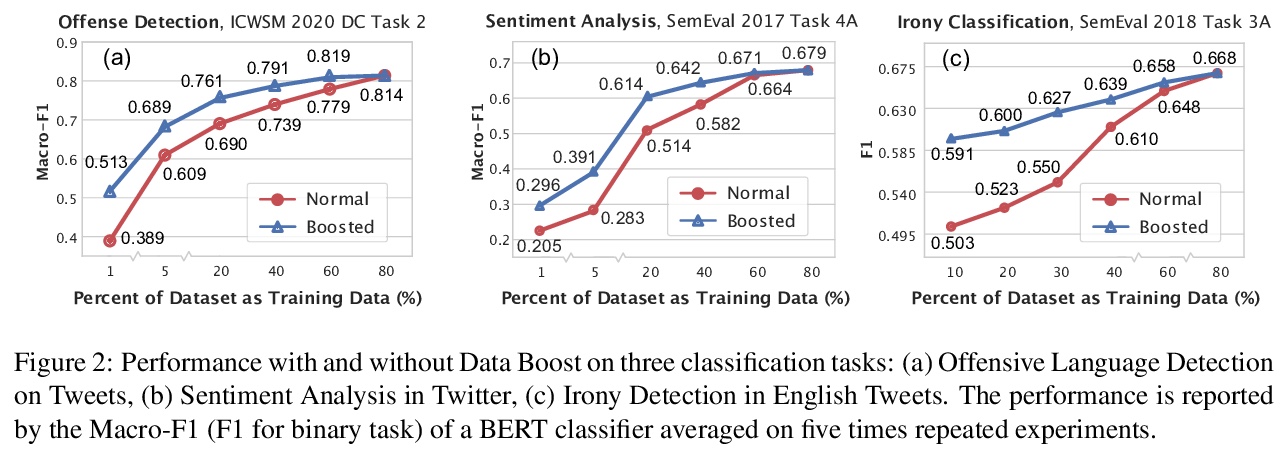
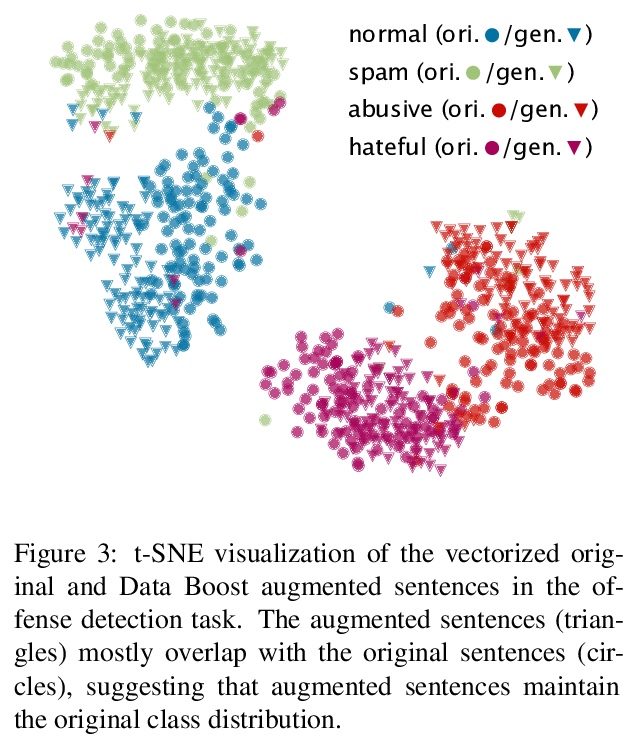
[CL] Data Boost: Text Data Augmentation Through Reinforcement Learning Guided Conditional Generation
Data Boost:基于强化学习引导条件生成的文本数据增强
R Liu, G Xu, C Jia, W Ma, L Wang, S Vosoughi
[Dartmouth College & University of Texas at Austin]
https://weibo.com/1402400261/JxLtL2pMM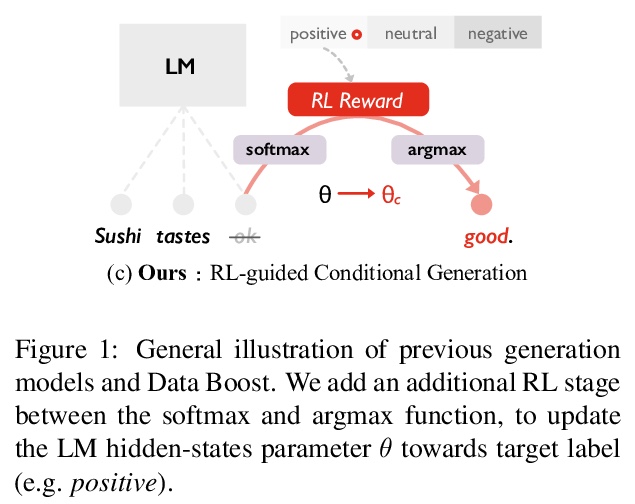

若有收获,就点个赞吧
0 人点赞
