- 1、[CV] Scene Essence
- 2、[CV] On Robustness and Transferability of Convolutional Neural Networks
- 3、[CV] Augmented Shortcuts for Vision Transformers
- 4、[LG] Stabilizing Equilibrium Models by Jacobian Regularization
- 5、[CV] Single Image Texture Translation for Data Augmentation
- [CV] Self-Damaging Contrastive Learning
- [LG] GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings
- [CL] Visual Conceptual Blending with Large-scale Language and Vision Models
- [LG] Secure Quantized Training for Deep Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] Scene Essence
J Qiu, Y Yang, X Wang, D Tao
[The University of Sydney & Stevens Institute of Technology & National University of Singapore]
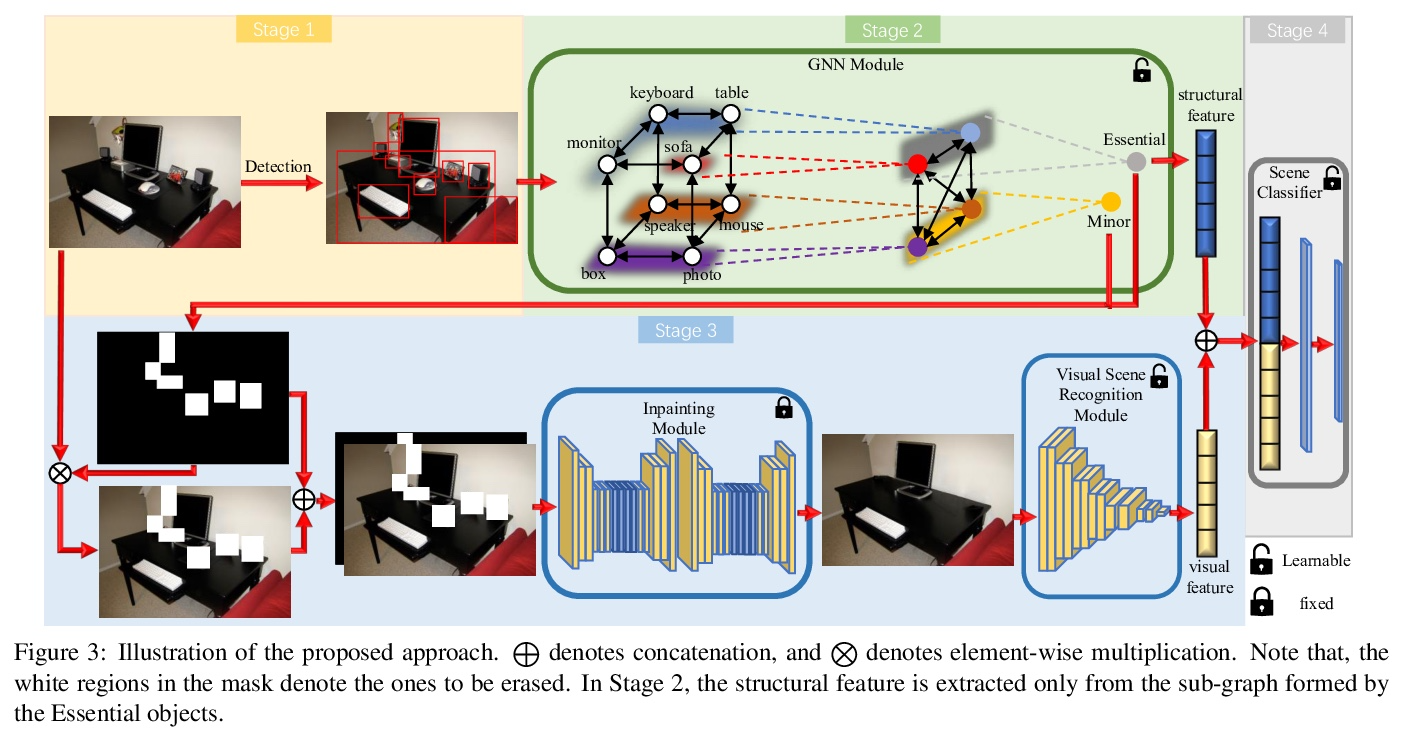
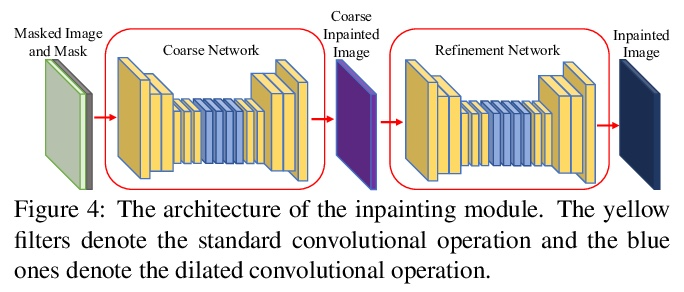
场景精华。哪些场景元素,是识别一个场景所不可缺少的?本文试图通过外在的学习方案来回答这个问题,目标是确定这种关键元素的集合,称为”场景精华”,即那些如果从场景中取出来会改变场景识别的元素。为此,设计了一种新方法,学习将场景对象分成两组,即基本的和次要的,在这样的监督下,如果在输入图像中只保留基本的而删除次要的,场景识别器将保留其原始预测。具体来说,引入了一个可学习的图神经网络(GNN)来标记场景对象,用一个现成的图像擦除器擦去次要对象。以这种方式得出的擦除图像的特征,加上从修剪了次要物体节点的GNN中学到的特征,有望骗过场景判别器。对Places365、SUN397和MIT67数据集的主观和客观评价都表明,学习到的场景精华产生了视觉上可信的图像,令人信服地保留了原始场景类别。还展示了场景精华提供了一种廉价的方式来实现场景迁移。
What scene elements, if any, are indispensable for recognizing a scene? We strive to answer this question through the lens of an exotic learning scheme. Our goal is to identify a collection of such pivotal elements, which we term as Scene Essence, to be those that would alter scene recognition if taken out from the scene. To this end, we devise a novel approach that learns to partition the scene objects into two groups, essential ones and minor ones, under the supervision that if only the essential ones are kept while the minor ones are erased in the input image, a scene recognizer would preserve its original prediction. Specifically, we introduce a learnable graph neural network (GNN) for labelling scene objects, based on which the minor ones are wiped off by an off-the-shelf image inpainter. The features of the inpainted image derived in this way, together with those learned from the GNN with the minor-object nodes pruned, are expected to fool the scene discriminator. Both subjective and objective evaluations on Places365, SUN397, and MIT67 datasets demonstrate that, the learned Scene Essence yields a visually plausible image that convincingly retains the original scene category.
https://weibo.com/1402400261/KngVN02iM 


2、[CV] On Robustness and Transferability of Convolutional Neural Networks
J Djolonga, J Yung, M Tschannen, R Romijnders, L Beyer, A Kolesnikov, J Puigcerver, M Minderer, A D’Amour, D Moldovan, S Gelly, N Houlsby, X Zhai, M Lucic
[Google Research]
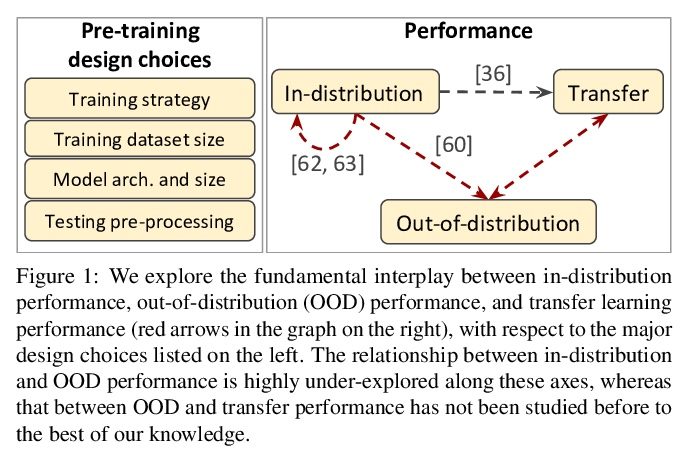
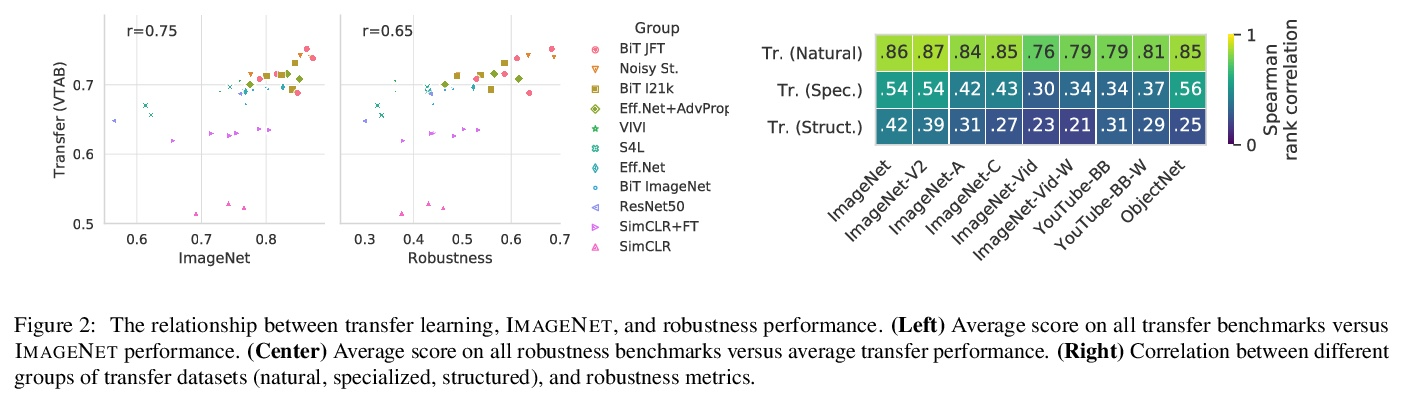
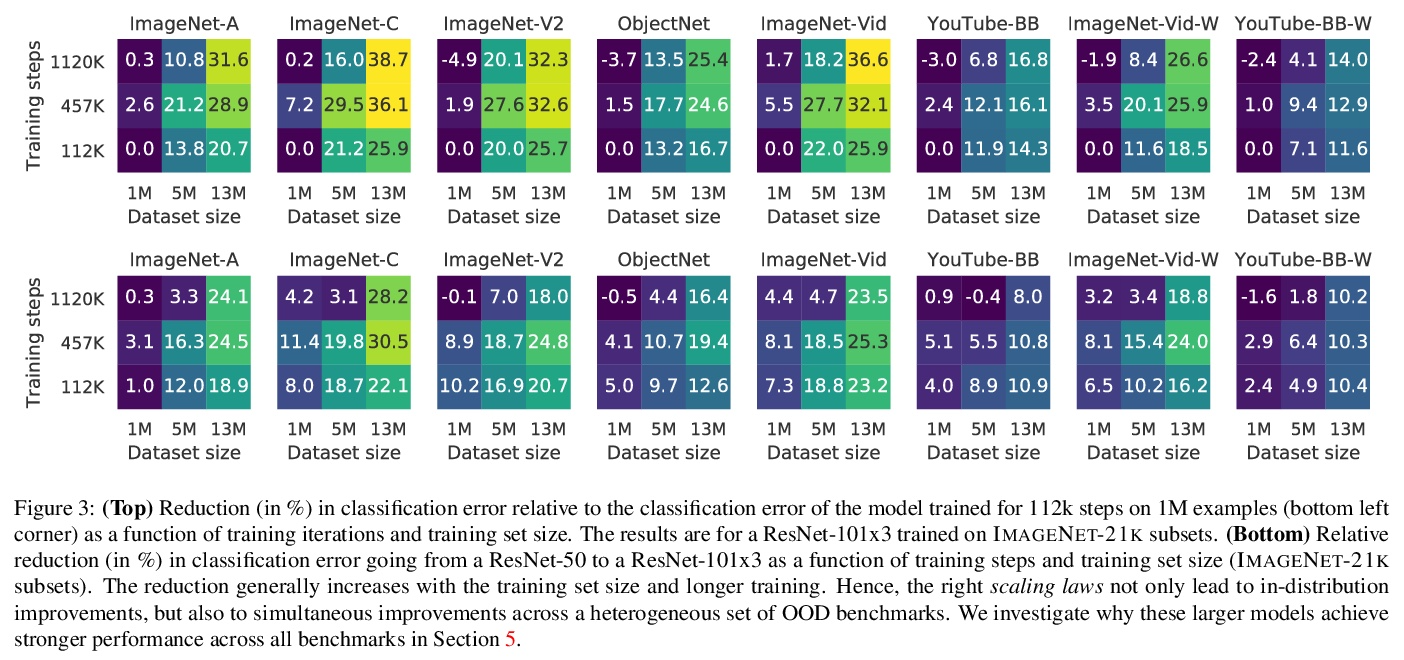
卷积神经网络的鲁棒性和可迁移性。现代深度卷积网络(CNN)经常被批评为在分布变化的情况下没有泛化能力。然而,最近在迁移学习方面的一些突破表明,这些网络可以应对严重的分布变化,并成功地适应来自少数训练样本的新任务。本文首次研究了现代图像分类CNN的分布外和迁移性能之间的相互作用,并研究了预训练数据大小、模型规模和数据预处理管道的影响。增加训练集和模型规模能明显改善分布迁移的鲁棒性。预处理中的简单变化,如修改图像分辨率,在某些情况下可以大大缓解鲁棒性问题。概述了现有鲁棒性评估数据集的缺点,引入了一个合成数据集SI-SCORE,用它来系统分析视觉数据中常见的变化因素,如物体大小和位置。
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we study the interplay between outof-distribution and transfer performance of modern image classification CNNs for the first time and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset SI-SCORE we use for a systematic analysis across factors of variation common in visual data such as object size and position.
https://weibo.com/1402400261/Knh0Tay3h 
3、[CV] Augmented Shortcuts for Vision Transformers
Y Tang, K Han, C Xu, A Xiao, Y Deng, C Xu, Y Wang
[Peking University & Huawei Technologies & University of Sydney]
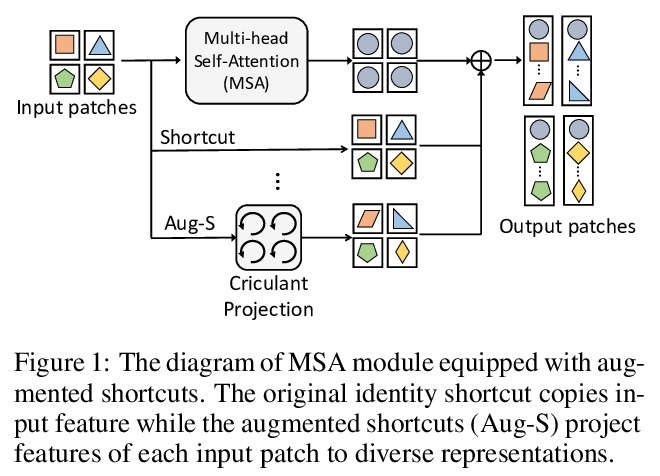
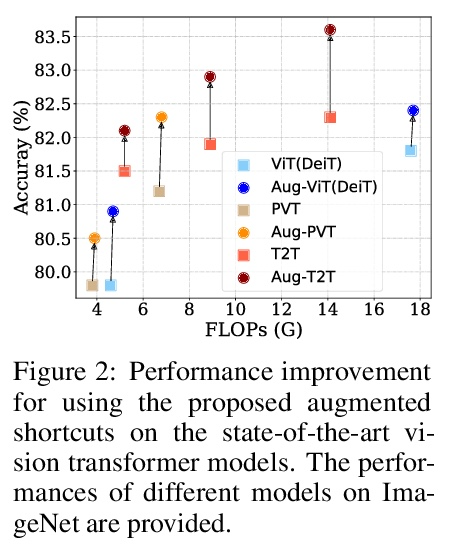
视觉Transformer的增强捷径。Transformer模型最近在计算机视觉任务上取得了很大的进展。视觉Transformer的快速发展主要是由于其从输入图像中提取信息性特征的强表示能力。然而,主流的Transformer模型都是采用深度架构设计的,随着深度的增加,特征的多样性会不断减少,也就是特征坍缩。本文从理论上分析了特征坍缩现象,研究了这些Transformer模型中捷径和特征多样性之间的关系。提出了一个增强捷径方案,该方案在原始捷径上并行插入了具有可学习参数的额外路径。为节省计算成本,进一步探索了一种高效方法,用块循环投影来实现增强捷径。在基准数据集上进行的广泛实验证明了所提出方法的有效性,使最先进的视觉Transformer的准确度提高了1%,而没有明显增加它们的参数和FLOPs。
Transformer models have achieved great progress on computer vision tasks recently. The rapid development of vision transformers is mainly contributed by their high representation ability for extracting informative features from input images. However, the mainstream transformer models are designed with deep architectures, and the feature diversity will be continuously reduced as the depth increases, i.e., feature collapse. In this paper, we theoretically analyze the feature collapse phenomenon and study the relationship between shortcuts and feature diversity in these transformer models. Then, we present an augmented shortcut scheme, which inserts additional paths with learnable parameters in parallel on the original shortcuts. To save the computational costs, we further explore an efficient approach that uses the block-circulant projection to implement augmented shortcuts. Extensive experiments conducted on benchmark datasets demonstrate the effectiveness of the proposed method, which brings about 1% accuracy increase of the state-of-the-art visual transformers without obviously increasing their parameters and FLOPs.
https://weibo.com/1402400261/Knh4jwnkR 
4、[LG] Stabilizing Equilibrium Models by Jacobian Regularization
S Bai, V Koltun, J. Z Kolter
[CMU & Intel Labs]
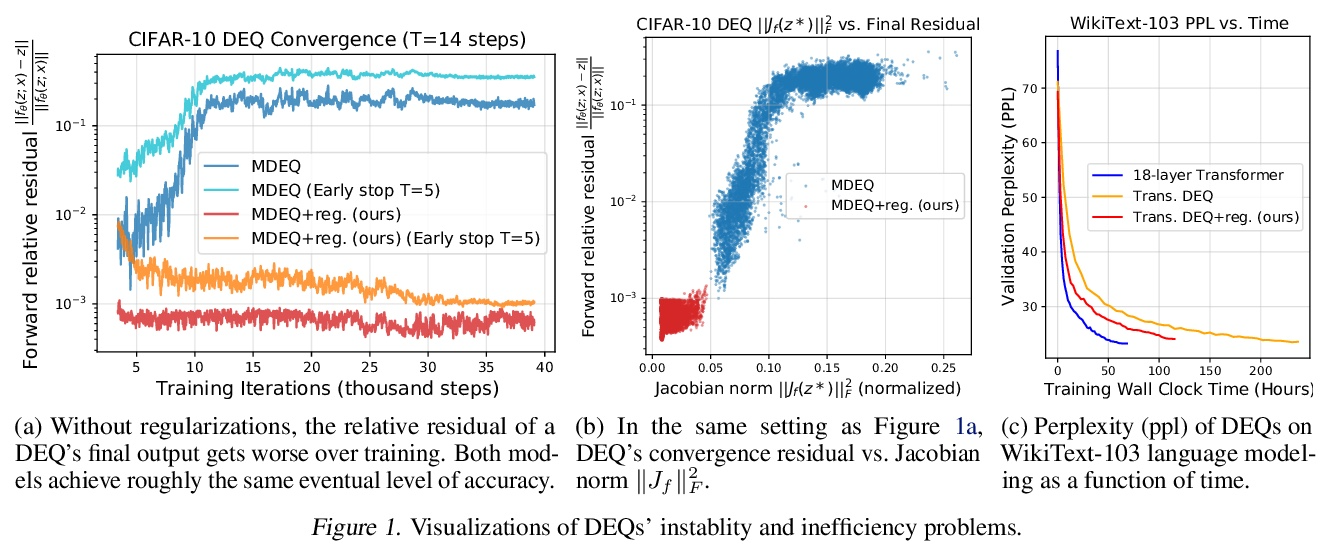
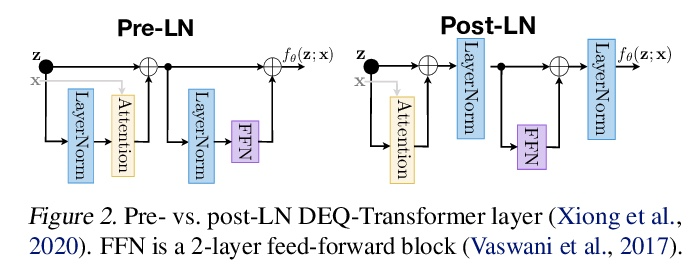
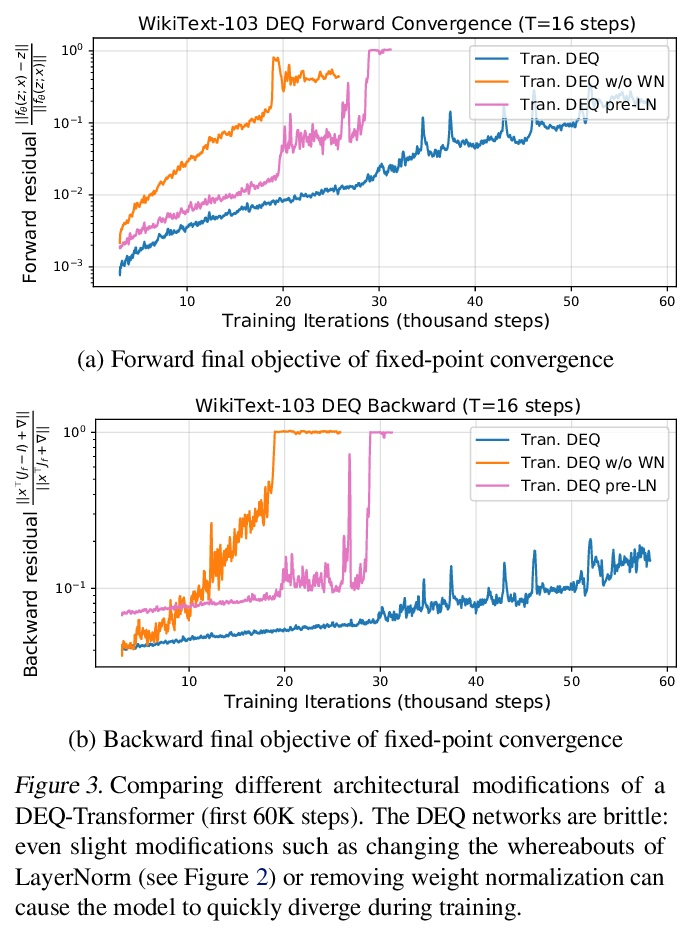
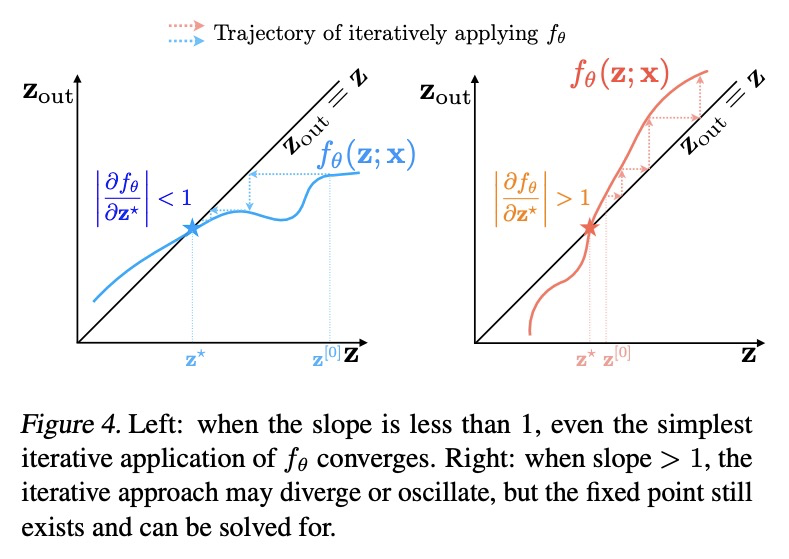
基于雅各布正则化稳定平衡模型。深度平衡网络(DEQs)是一类新模型,放弃了传统的深度,而选择了寻找单一非线性层的固定点。这些模型已被证明可以实现与最先进的深度网络相竞争的性能,同时使用的内存也大大减少。然而,它们也比较慢,对架构的选择很脆弱,并给模型带来潜在的不稳定性。本文为DEQ模型提出了一种正则化方案,显式正则化定点更新方程的Jacobian,以稳定平衡模型的学习。这种正则化只增加了最小的计算成本,大大稳定了前向和后向的定点收敛,能很好地扩展到高维的现实领域(例如WikiText-103语言建模和ImageNet分类)。采用这种方法,展示了一种隐深度模型,其运行速度和性能水平与流行的传统深度网络(如ResNet-101)大致相同,同时仍然保持了DEQ的恒定内存形式和架构简单性。
Deep equilibrium networks (DEQs) are a new class of models that eschews traditional depth in favor of finding the fixed point of a single nonlinear layer. These models have been shown to achieve performance competitive with the stateof-the-art deep networks while using significantly less memory. Yet they are also slower, brittle to architectural choices, and introduce potential instability to the model. In this paper, we propose a regularization scheme for DEQ models that explicitly regularizes the Jacobian of the fixed-point update equations to stabilize the learning of equilibrium models. We show that this regularization adds only minimal computational cost, significantly stabilizes the fixed-point convergence in both forward and backward passes, and scales well to high-dimensional, realistic domains (e.g., WikiText-103 language modeling and ImageNet classification). Using this method, we demonstrate, for the first time, an implicit-depth model that runs with approximately the same speed and level of performance as popular conventional deep networks such as ResNet-101, while still maintaining the constant memory footprint and architectural simplicity of DEQs. Code is available here.
https://weibo.com/1402400261/Knh86wSF4 
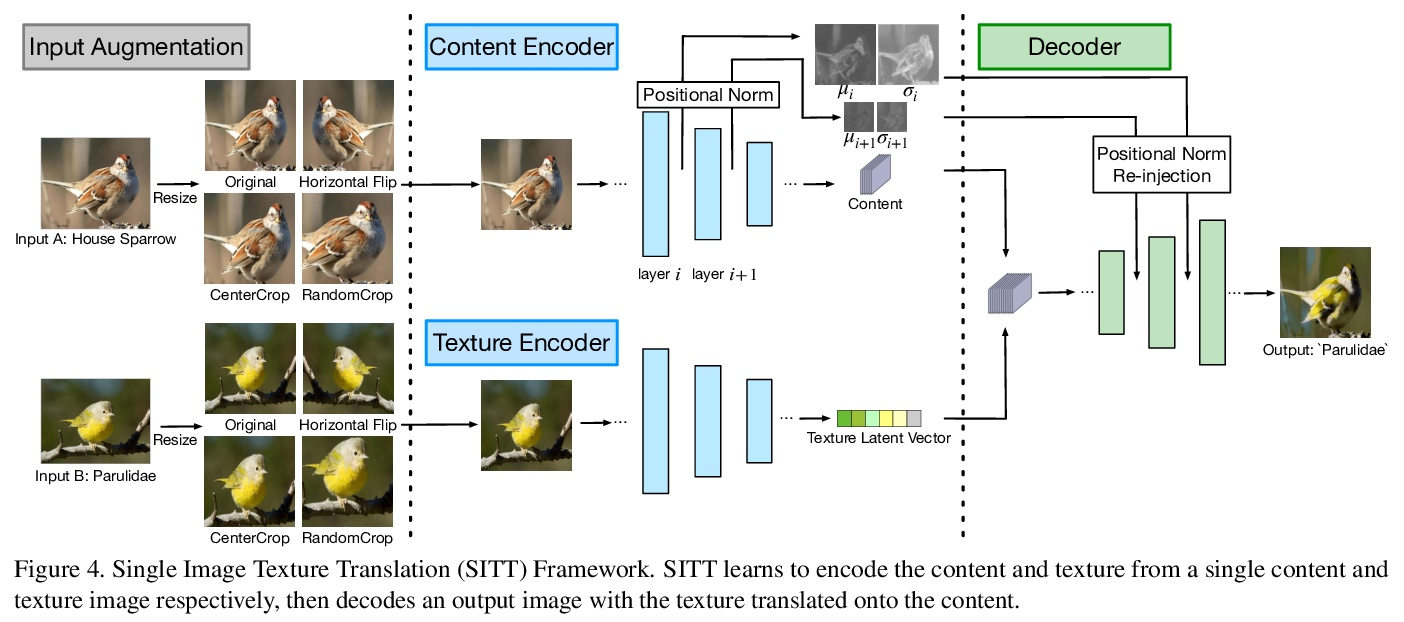
5、[CV] Single Image Texture Translation for Data Augmentation
B Li, Y Cui, T Lin, S Belongie
[Cornell University & Google Research]
面向数据增强的单图像纹理变换。图像合成方面的最新进展,使人们能够通过学习源域和目标域之间的映射来变换图像。现有的方法倾向于通过在各种数据集上训练一个模型来学习分布,其结果主要以主观方式进行评估。然而,这一领域中相对较少的工作研究了语义图像变换方法在图像识别任务中的潜在用途。本文探讨了使用单图像纹理变换(SITT)来增加数据,在目标物体(形状)和示范物体(纹理)之间交换纹理。提出一种轻量模型,用于基于源纹理的单个输入将纹理变换成图像,允许快速训练和测试。在SITT的基础上,探索了在长尾和少样本图像分类任务中使用增强的数据。我们发现所提出的方法能够将输入数据转化为目标域,导致图像识别性能的持续提高。研究了SITT和相关的图像变换方法如何为高数据效率的模型训练增强工程方法提供基础。
Recent advances in image synthesis enables one to translate images by learning the mapping between a source domain and a target domain. Existing methods tend to learn the distributions by training a model on a variety of datasets, with results evaluated largely in a subjective manner. Relatively few works in this area, however, study the potential use of semantic image translation methods for image recognition tasks. In this paper, we explore the use of Single Image Texture Translation (SITT) for data augmentation. We first propose a lightweight model for translating texture to images based on a single input of source texture, allowing for fast training and testing. Based on SITT, we then explore the use of augmented data in long-tailed and few-shot image classification tasks. We find the proposed method is capable of translating input data into a target domain, leading to consistent improved image recognition performance. Finally, we examine how SITT and related image translation methods can provide a basis for a data-efficient, augmentation engineering approach to model training.
https://weibo.com/1402400261/KnhbI8LRl 


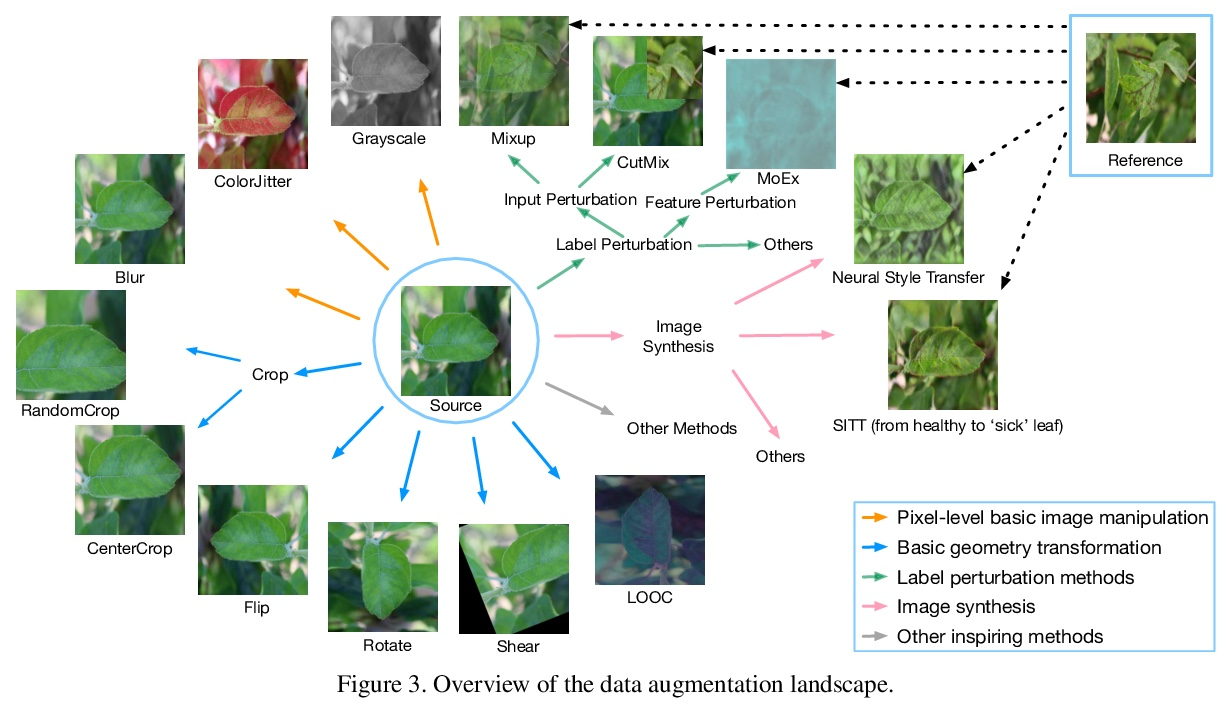
另外几篇值得关注的论文:
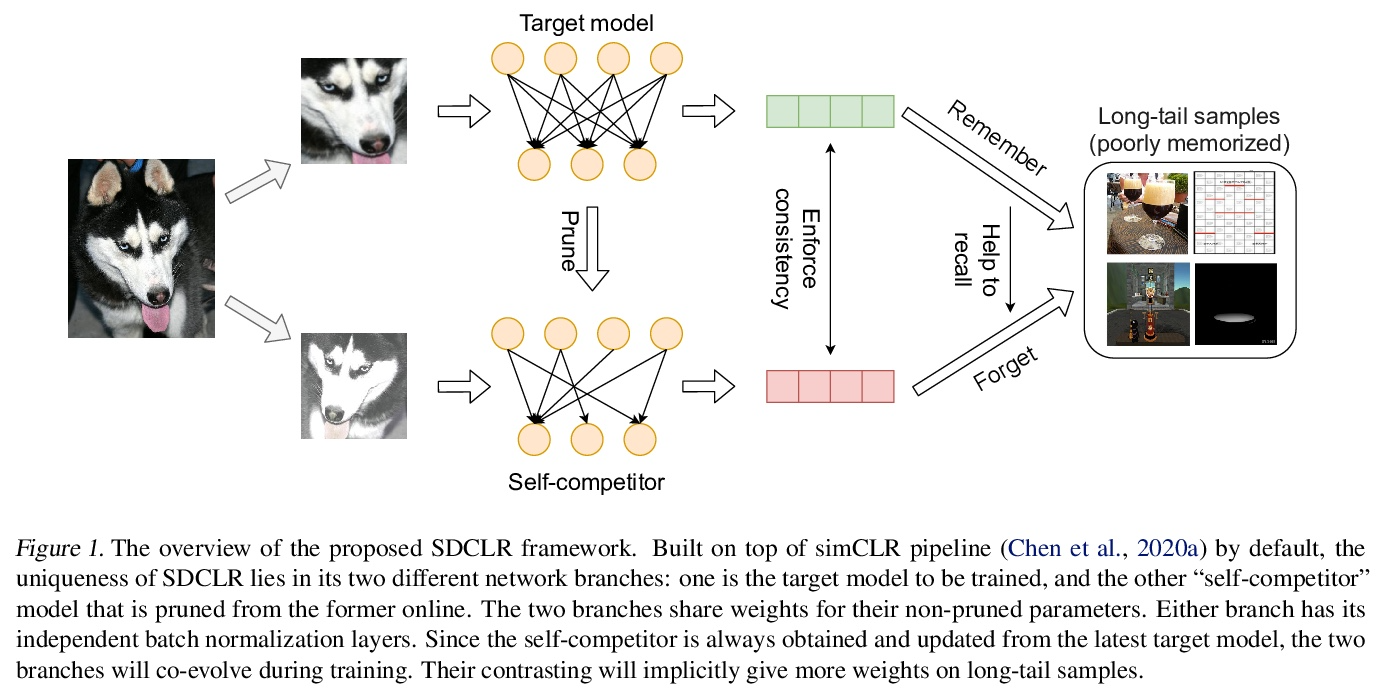
[CV] Self-Damaging Contrastive Learning
自损式对比学习
Z Jiang, T Chen, B Mortazavi, Z Wang
[Texas A&M University & University of Texas at Austin]
https://weibo.com/1402400261/Knhf55MrV 
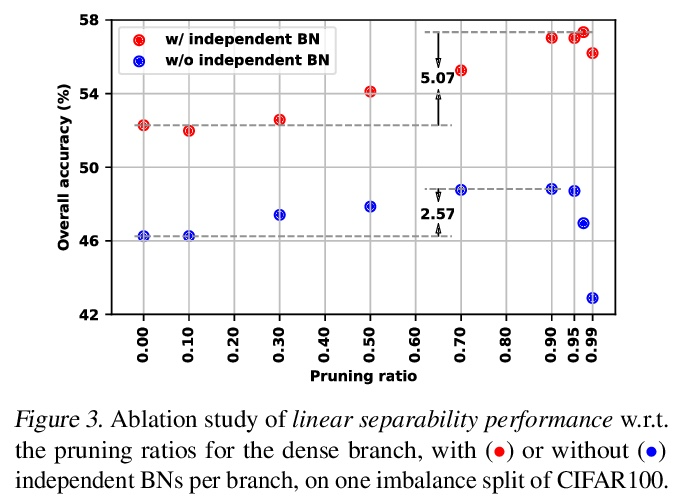
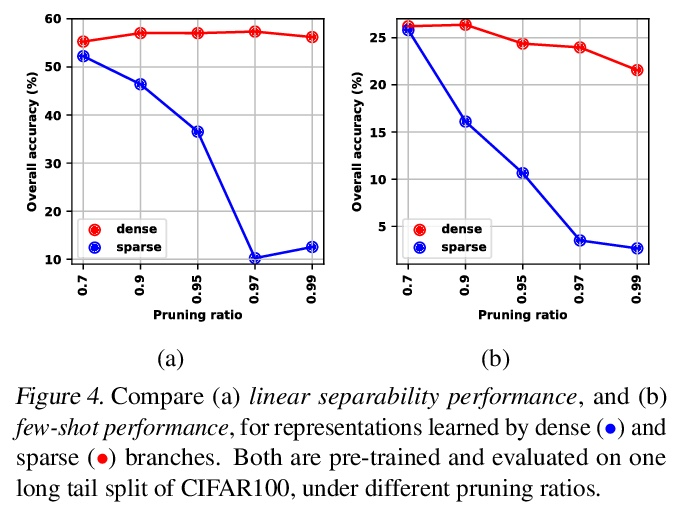
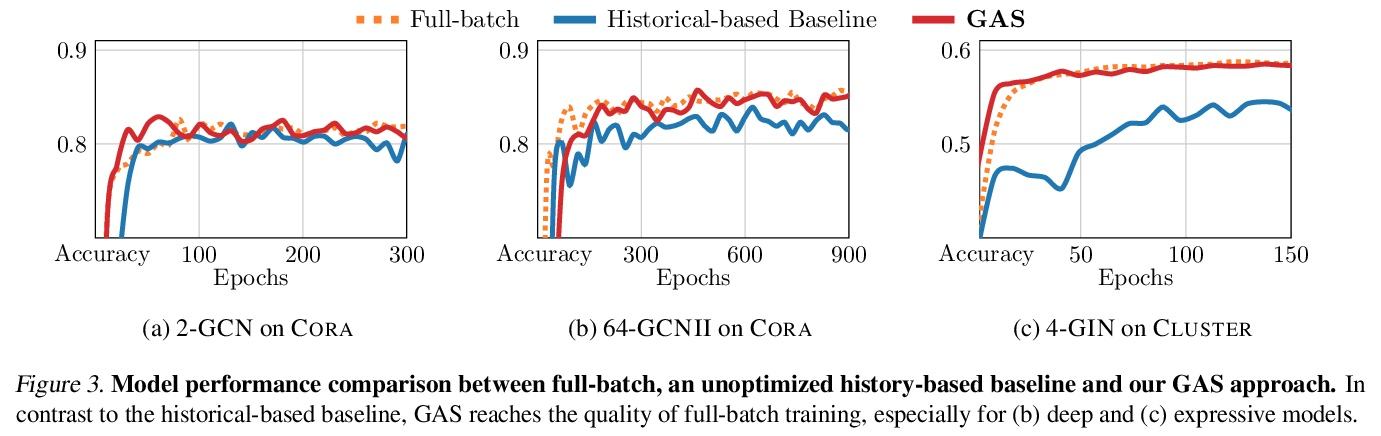
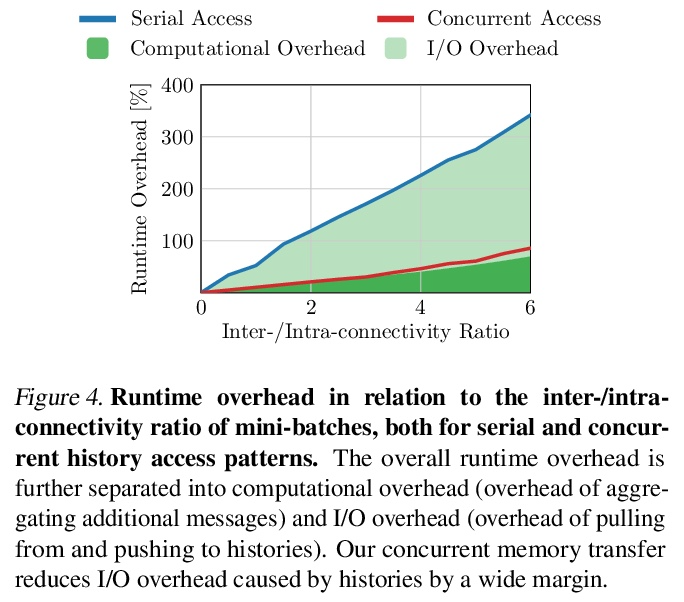
[LG] GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings
GNNAutoScale:基于历史嵌入的可扩展表达性图神经网络
M Fey, J E. Lenssen, F Weichert, J Leskovec
[TU Dortmund University & Stanford University]
https://weibo.com/1402400261/Knhh63aKR 
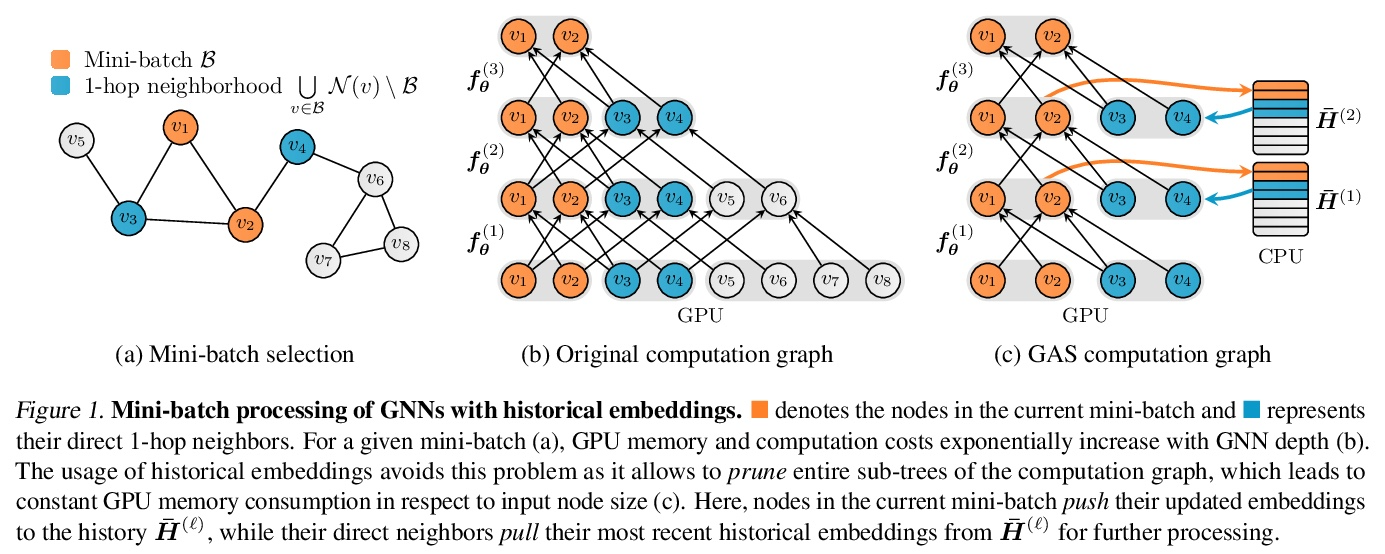
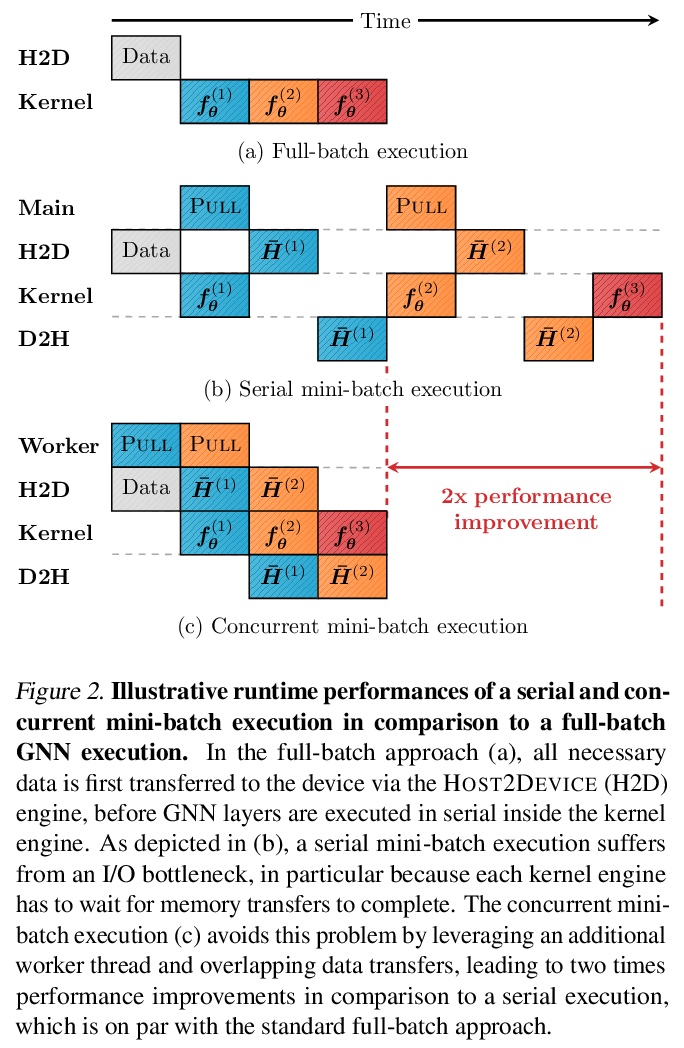
[CL] Visual Conceptual Blending with Large-scale Language and Vision Models
基于大规模语言和视觉模型的视觉概念整合
S Ge, D Parikh
[University of Maryland & Facebook AI Research]
https://weibo.com/1402400261/KnhisfZv2 


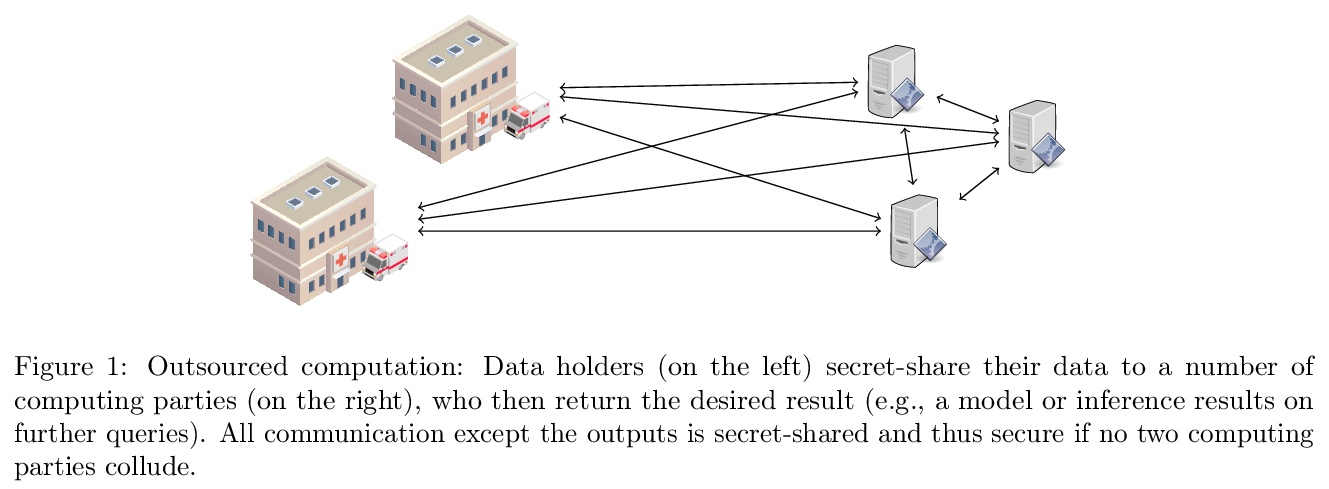
[LG] Secure Quantized Training for Deep Learning
深度学习的安全量化训练
M Keller, K Sun
[CSIRO’s Data61]
https://weibo.com/1402400261/Knhkpp1UO 


若有收获,就点个赞吧
0 人点赞
