LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] **Learning Efficient GANs via Differentiable Masks and co-Attention Distillation
S Li, M Lin, Y Wang, M Xu, F Huang, Y Wu, L Shao, R Ji
[Xiamen University & Pinterest & Zhengzhou University & Tencent Youtu Lab]
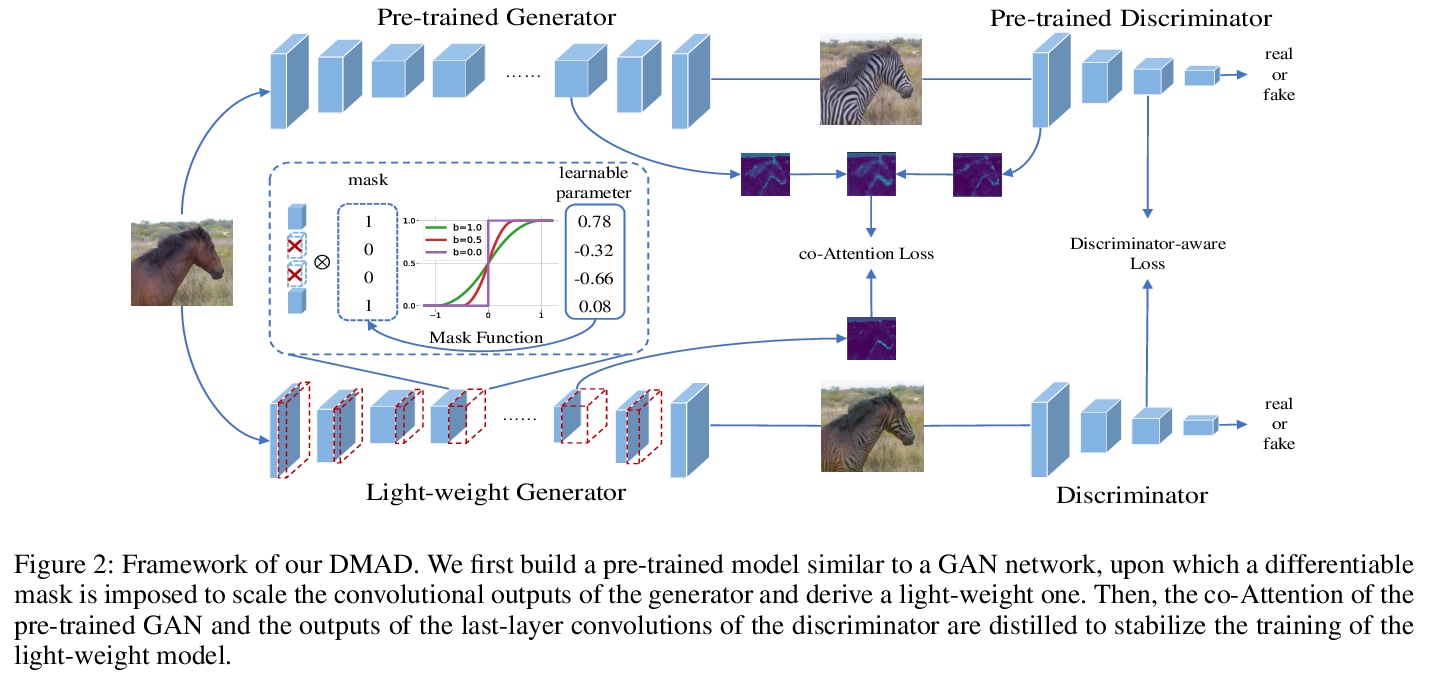
基于可微掩模和共注意力蒸馏(DMAD)的高效GAN学习。提出一种可微掩模,以训练自适应的方式,用架构搜索找到合适的轻量生成器,自适应交叉块组稀疏性被进一步纳入块级剪枝,将预训练模型的生成器和鉴别器中提取的注意力图蒸馏到轻量生成器中,使训练更稳定,获得更优性能。**
Generative Adversarial Networks (GANs) have been widely-used in image translation, but their high computational and storage costs impede the deployment on mobile devices. Prevalent methods for CNN compression cannot be directly applied to GANs due to the complicated generator architecture and the unstable adversarial training. To solve these, in this paper, we introduce a novel GAN compression method, termed DMAD, by proposing a Differentiable Mask and a co-Attention Distillation. The former searches for a light-weight generator architecture in a training-adaptive manner. To overcome channel inconsistency when pruning the residual connections, an adaptive cross-block group sparsity is further incorporated. The latter simultaneously distills informative attention maps from both the generator and discriminator of a pre-trained model to the searched generator, effectively stabilizing the adversarial training of our light-weight model. Experiments show that DMAD can reduce the Multiply Accumulate Operations (MACs) of CycleGAN by 13x and that of Pix2Pix by 4x while retaining a comparable performance against the full model. Code is available at > this https URL.
https://weibo.com/1402400261/JuyZ8Bl5N
2、[LG] **Avoiding Tampering Incentives in Deep RL via Decoupled Approval
J Uesato, R Kumar, V Krakovna, T Everitt, R Ngo, S Legg
[DeepMind]
用解耦审批避免深度强化学习激励机制的篡改。从理论和实证方面,证明了标准的强化学习算法具有篡改用户反馈的动机。即使是使用审批反馈的算法,这种篡改动机仍然存在。解耦审批算法通过简单的改变,避免了篡改奖励,无论在实践中,还是在附加查询独立的假设下。解耦审批与标准深度强化学习技术自然兼容,应用到3D环境时,可以在不受干扰的情况下表现出强大的性能。
How can we design agents that pursue a given objective when all feedback mechanisms are influenceable by the agent? Standard RL algorithms assume a secure reward function, and can thus perform poorly in settings where agents can tamper with the reward-generating mechanism. We present a principled solution to the problem of learning from influenceable feedback, which combines approval with a decoupled feedback collection procedure. For a natural class of corruption functions, decoupled approval algorithms have aligned incentives both at convergence and for their local updates. Empirically, they also scale to complex 3D environments where tampering is possible.
https://weibo.com/1402400261/Juz3UlogL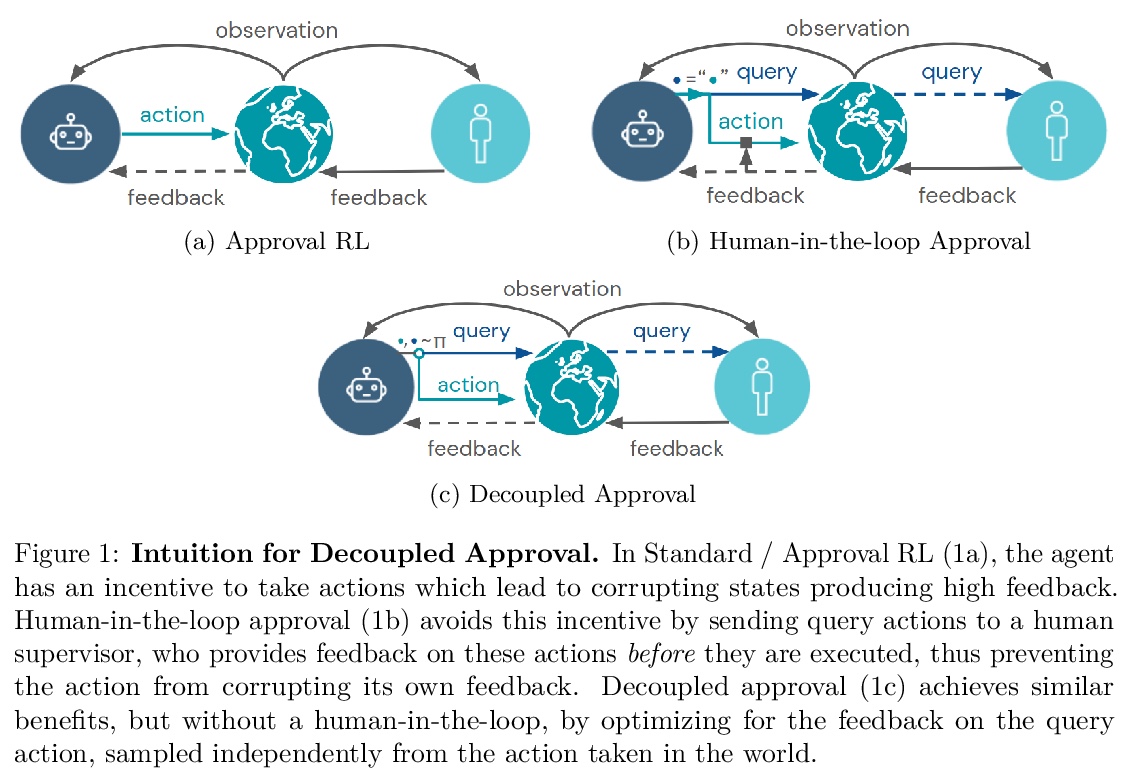

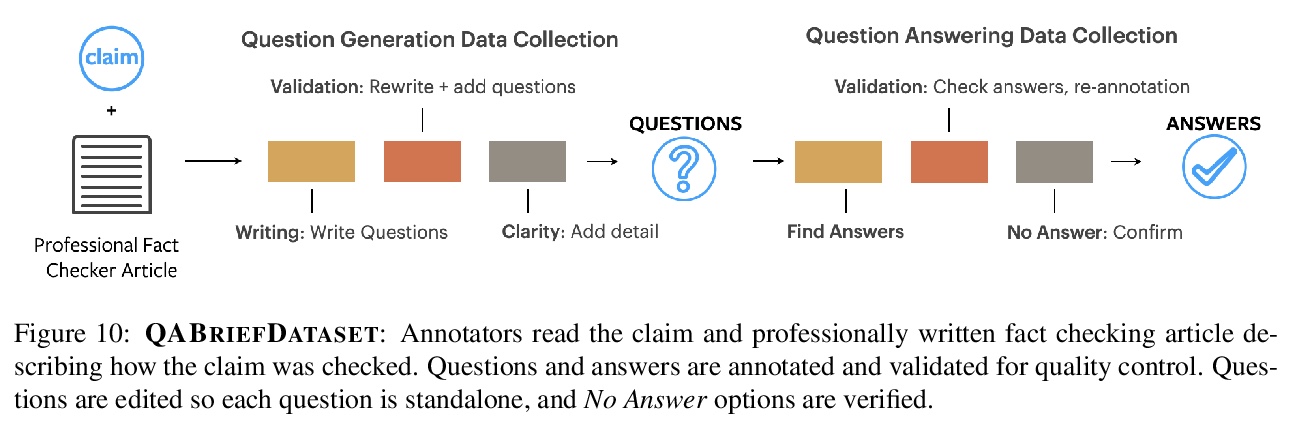
3、[CL] **Generating Fact Checking Briefs
A Fan, A Piktus, F Petroni, G Wenzek, M Saeidi, A Vlachos, A Bordes, S Riedel
[Facebook AI Research]
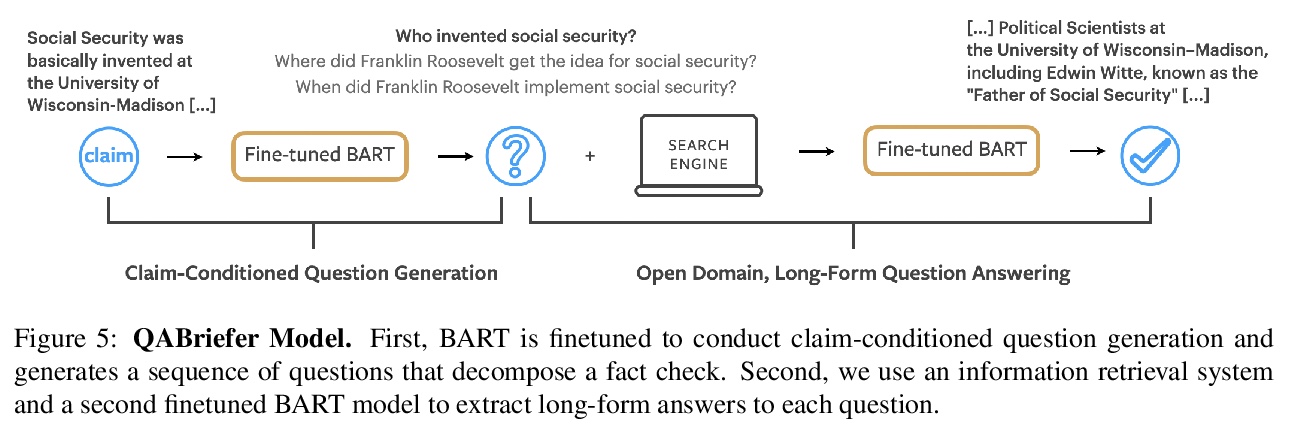
事实核查概要的生成。研究了基于篇章的摘要(包含来自维基百科的相关段落)、以实体为中心的摘要(由提到的实体组成的维基百科页面)和问答摘要(分解声明的问题及答案),提出事实核查概要的概念,开发了QABriefer模型,能生成一组以声明为条件的问题,在网络上搜索证据,并生成答案,为训练其组件,引入了通过众包收集的QABriefDataset。使用摘要(尤其是QABriefs)进行事实核查,可将众包工作人员的准确性提高10%,同时略微缩短所需时间,提高了事实核查的准确性和效率。
Fact checking at scale is difficult — while the number of active fact checking websites is growing, it remains too small for the needs of the contemporary media ecosystem. However, despite good intentions, contributions from volunteers are often error-prone, and thus in practice restricted to claim detection. We investigate how to increase the accuracy and efficiency of fact checking by providing information about the claim before performing the check, in the form of natural language briefs. We investigate passage-based briefs, containing a relevant passage from Wikipedia, entity-centric ones consisting of Wikipedia pages of mentioned entities, and Question-Answering Briefs, with questions decomposing the claim, and their answers. To produce QABriefs, we develop QABriefer, a model that generates a set of questions conditioned on the claim, searches the web for evidence, and generates answers. To train its components, we introduce QABriefDataset which we collected via crowdsourcing. We show that fact checking with briefs — in particular QABriefs — increases the accuracy of crowdworkers by 10% while slightly decreasing the time taken. For volunteer (unpaid) fact checkers, QABriefs slightly increase accuracy and reduce the time required by around 20%.
https://weibo.com/1402400261/Juz8mFFfw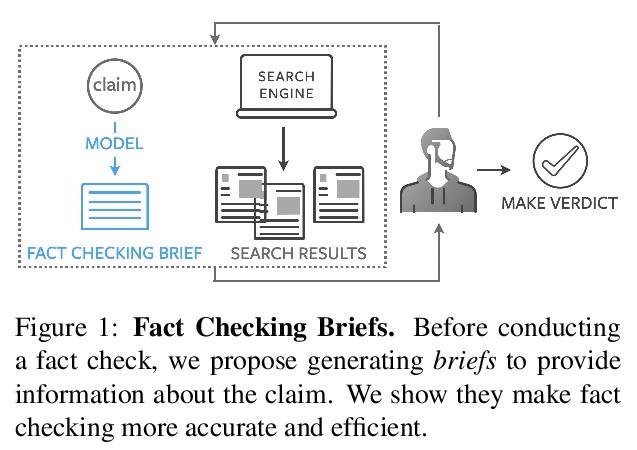
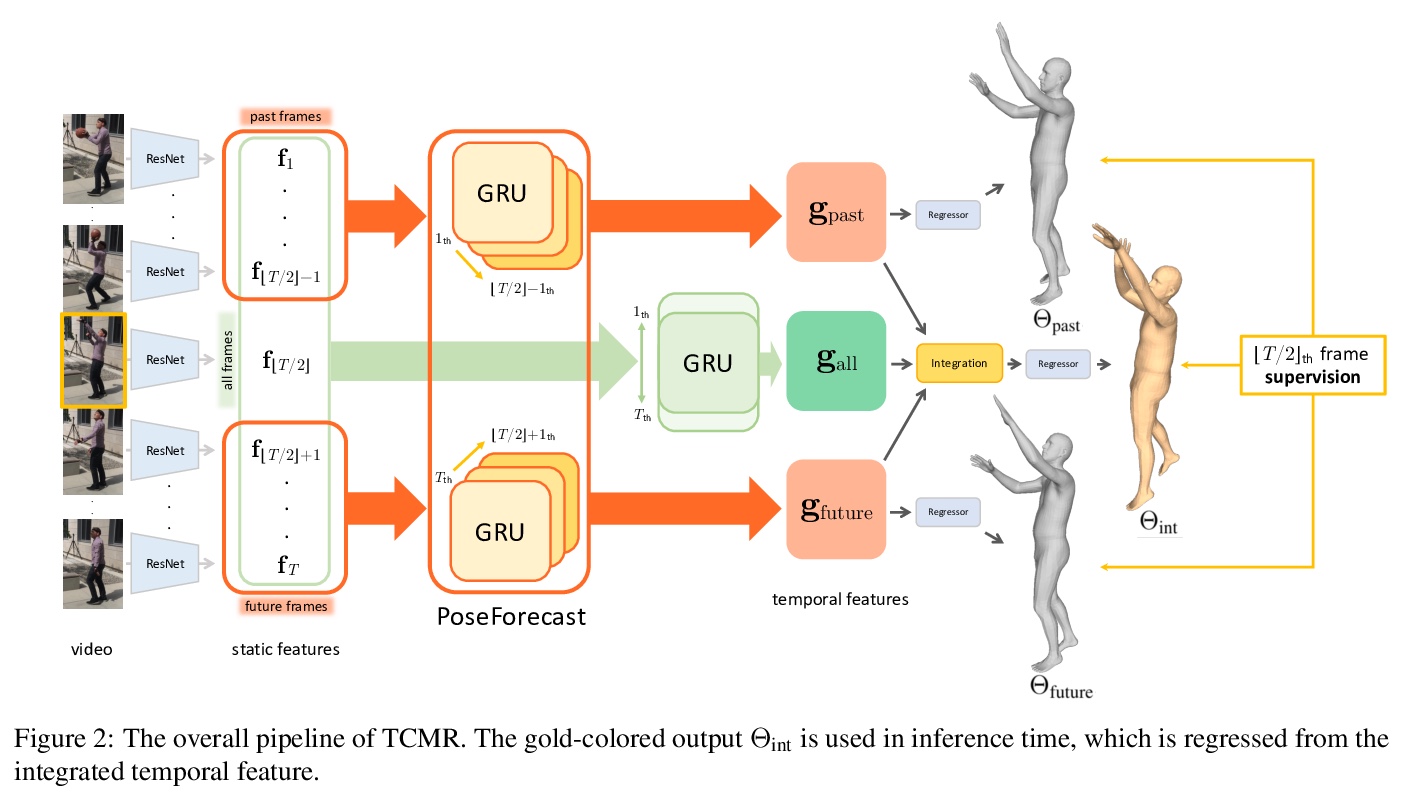
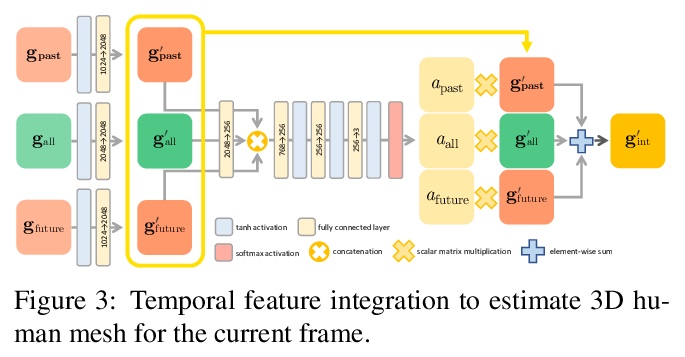
4、[CV]Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video
H Choi, G Moon, K M Lee
[Seoul National University]
超越静态特征的视频时间一致3D人体姿态和形状估计。提出了时间一致网格恢复系统(TCMR),从RGB视频中估计3D人体网格,通过移除静态特征和时效特征间的残差连接,用PoseForecast预测过去和未来帧中当前时效特征来解决时间不一致的问题,有效关注过去和未来帧的时间信息,免受当前静态特征的支配。TCMR在时间一致性上显著优于之前的基于视频的方法,在每帧3D姿态和形状精度上有更好的表现。
Despite the recent success of single image-based 3D human pose and shape estimation methods, recovering temporally consistent and smooth 3D human motion from a video is still challenging. Several video-based methods have been proposed; however, they fail to resolve the single image-based methods’ temporal inconsistency issue due to a strong dependency on a static feature of the current frame. In this regard, we present a temporally consistent mesh recovery system (TCMR). It effectively focuses on the past and future frames’ temporal information without being dominated by the current static feature. Our TCMR significantly outperforms previous video-based methods in temporal consistency with better per-frame 3D pose and shape accuracy. We will release the codes.
https://weibo.com/1402400261/Juzg4pZsR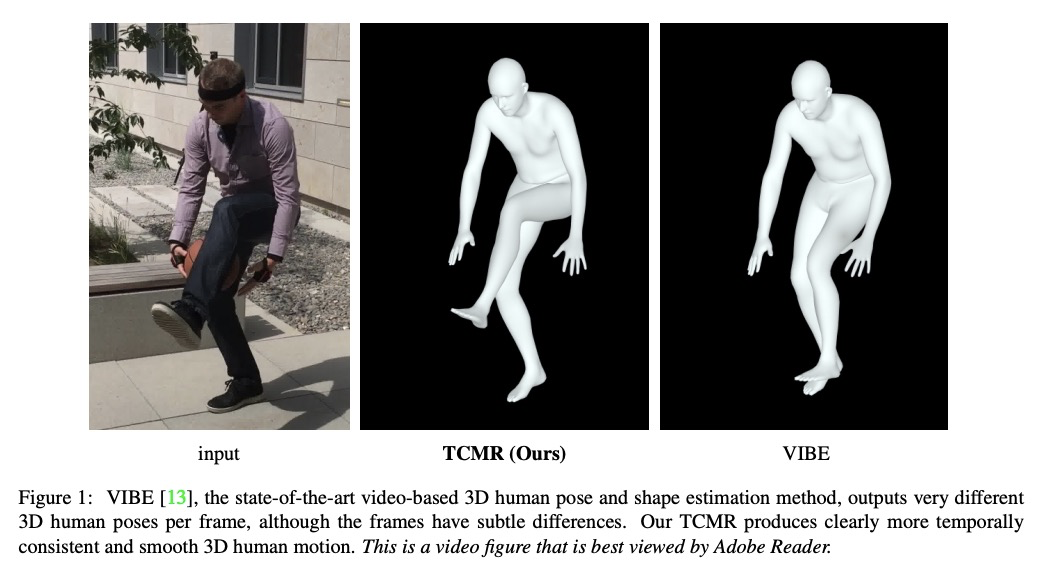
5、[CL] NLPGym — A toolkit for evaluating RL agents on Natural Language Processing Tasks
R Ramamurthy, R Sifa, C Bauckhage
[Fraunhofer IAIS]
NLPGym:自然语言处理任务强化学习智能体评价工具包。发布了开源Python工具包NLPGym,为标准NLP任务(如序列标记、多标签分类和问题回答)提供交互式文本环境,这些环境可以与默认组件和数据集一起随时使用。文中还提供了6个NLP任务使用不同强化学习算法的实验结果。
Reinforcement learning (RL) has recently shown impressive performance in complex game AI and robotics tasks. To a large extent, this is thanks to the availability of simulated environments such as OpenAI Gym, Atari Learning Environment, or Malmo which allow agents to learn complex tasks through interaction with virtual environments. While RL is also increasingly applied to natural language processing (NLP), there are no simulated textual environments available for researchers to apply and consistently benchmark RL on NLP tasks. With the work reported here, we therefore release NLPGym, an open-source Python toolkit that provides interactive textual environments for standard NLP tasks such as sequence tagging, multi-label classification, and question answering. We also present experimental results for 6 tasks using different RL algorithms which serve as baselines for further research. The toolkit is published at > this https URL
https://weibo.com/1402400261/Juzk5BqHd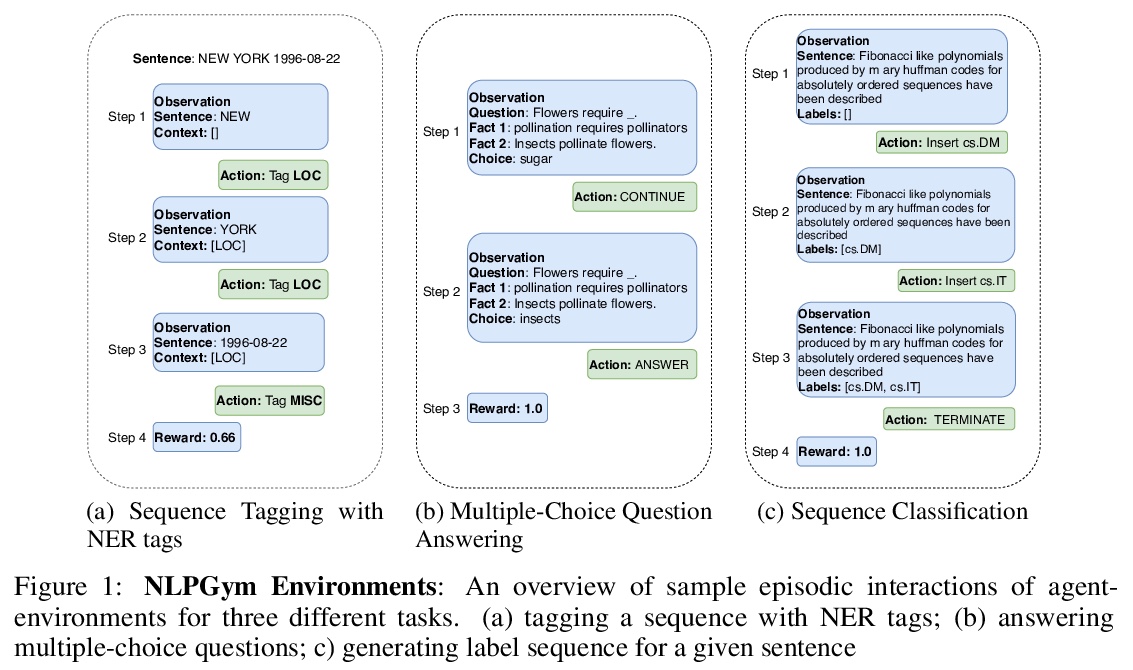
另外几篇值得关注的论文:
[LG] REALab: An Embedded Perspective on Tampering
REALab:嵌入视角看(强化学习)篡改
R Kumar, J Uesato, R Ngo, T Everitt, V Krakovna, S Legg
[DeepMind]
https://weibo.com/1402400261/Juzdquv7k

[SI] International expert communities on Twitter become more isolated during the COVID-19 pandemic
新冠肺炎流行期间推特上的国际专家群体变得更加孤立
F Durazzi, M Müller, M Salathé, D Remondini
[University of Bologna & Ecole polytechnique fédérale de Lausanne (EPFL)]
https://weibo.com/1402400261/JuznSarmL?ref=home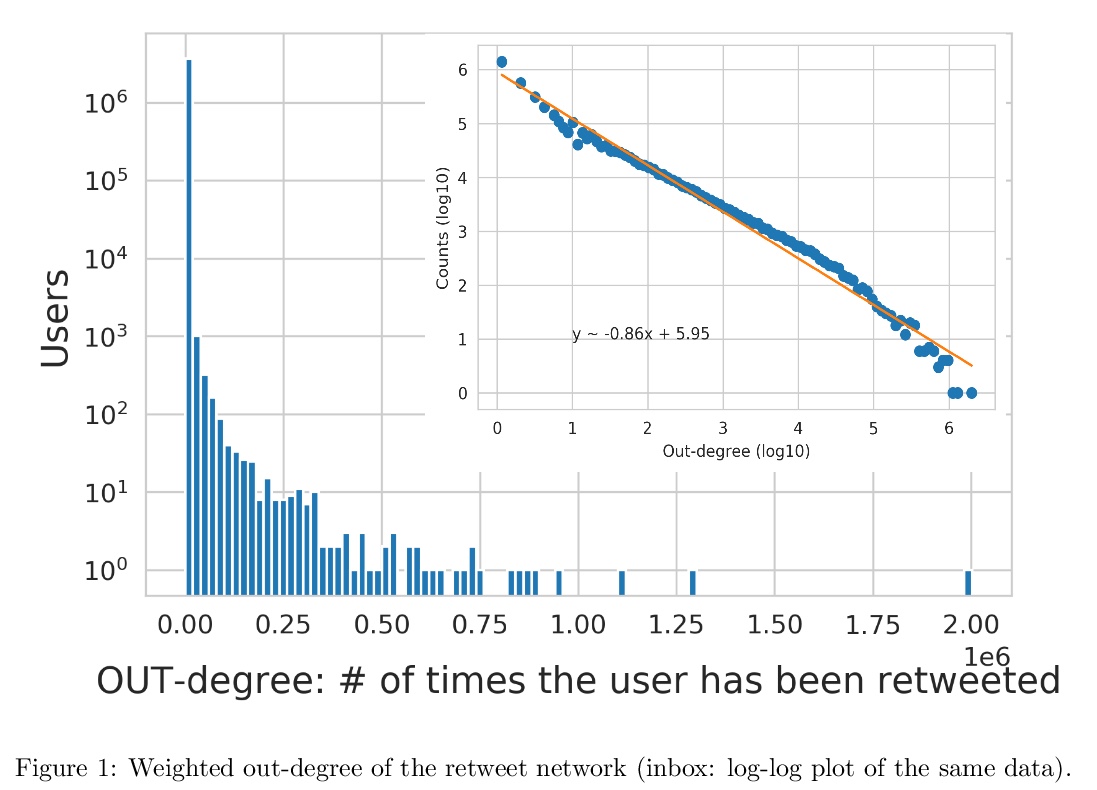
[CV] A Divide et Impera Approach for 3D Shape Reconstruction from Multiple Views
分而治之实现多视角3D形状重建**
R Spezialetti, D J Tan, A Tonioni, K Tateno, F Tombari
[University of Bologna & Google Inc]
https://weibo.com/1402400261/JuzpOaQAe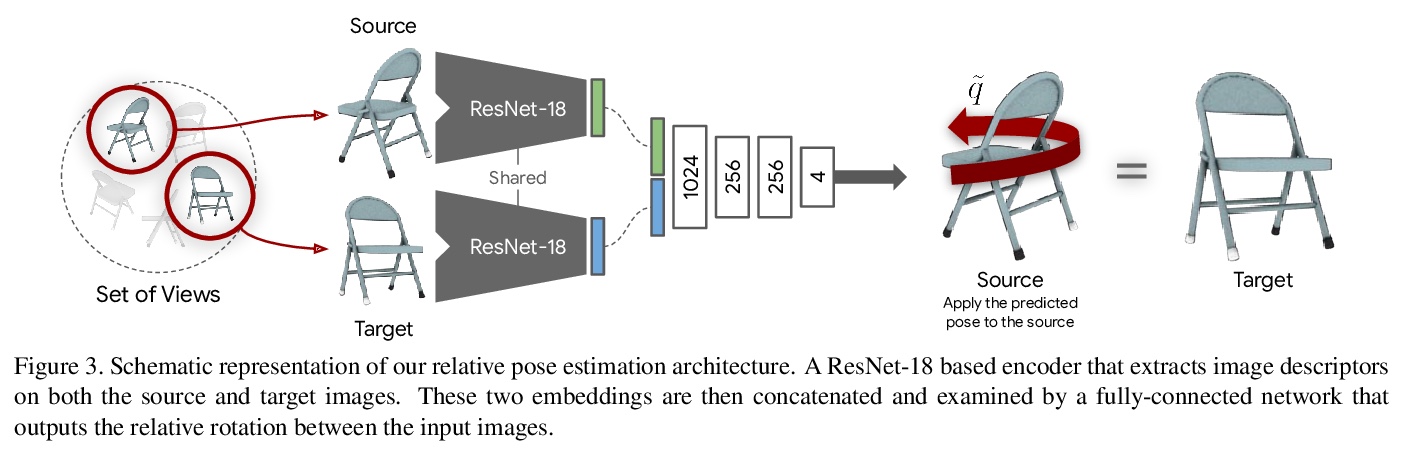

若有收获,就点个赞吧
0 人点赞
