LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、** **[CV] Positional Encoding as Spatial Inductive Bias in GANs
R Xu, X Wang, K Chen, B Zhou, C C Loy
[CUHK-SenseTime Joint Lab & Nanyang Technological University & Applied Research Center & SenseTime Research]
GAN中的位置编码与空间诱导偏差。对卷积生成器零填充偶尔编码空间偏差的机制进行了深入研究,讨论了在各种现有生成器体系结构中,引入显式位置编码(包括CSG和SPE)的优点。利用灵活的显式位置编码,提出了新的多尺度训练策略(MS-PIE),用单个2562 StyleGAN2可实现多尺度高质量的图像合成。实验表明,采用显式位置编码,可提高SinGAN的通用性和鲁棒性。
SinGAN shows impressive capability in learning internal patch distribution despite its limited effective receptive field. We are interested in knowing how such a translation-invariant convolutional generator could capture the global structure with just a spatially i.i.d. input. In this work, taking SinGAN and StyleGAN2 as examples, we show that such capability, to a large extent, is brought by the implicit positional encoding when using zero padding in the generators. Such positional encoding is indispensable for generating images with high fidelity. The same phenomenon is observed in other generative architectures such as DCGAN and PGGAN. We further show that zero padding leads to an unbalanced spatial bias with a vague relation between locations. To offer a better spatial inductive bias, we investigate alternative positional encodings and analyze their effects. Based on a more flexible positional encoding explicitly, we propose a new multi-scale training strategy and demonstrate its effectiveness in the state-of-the-art unconditional generator StyleGAN2. Besides, the explicit spatial inductive bias substantially improve SinGAN for more versatile image manipulation.
https://weibo.com/1402400261/JxUkG1p83
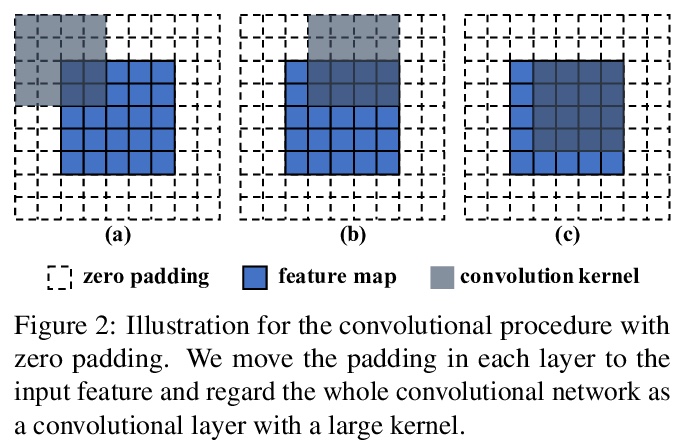

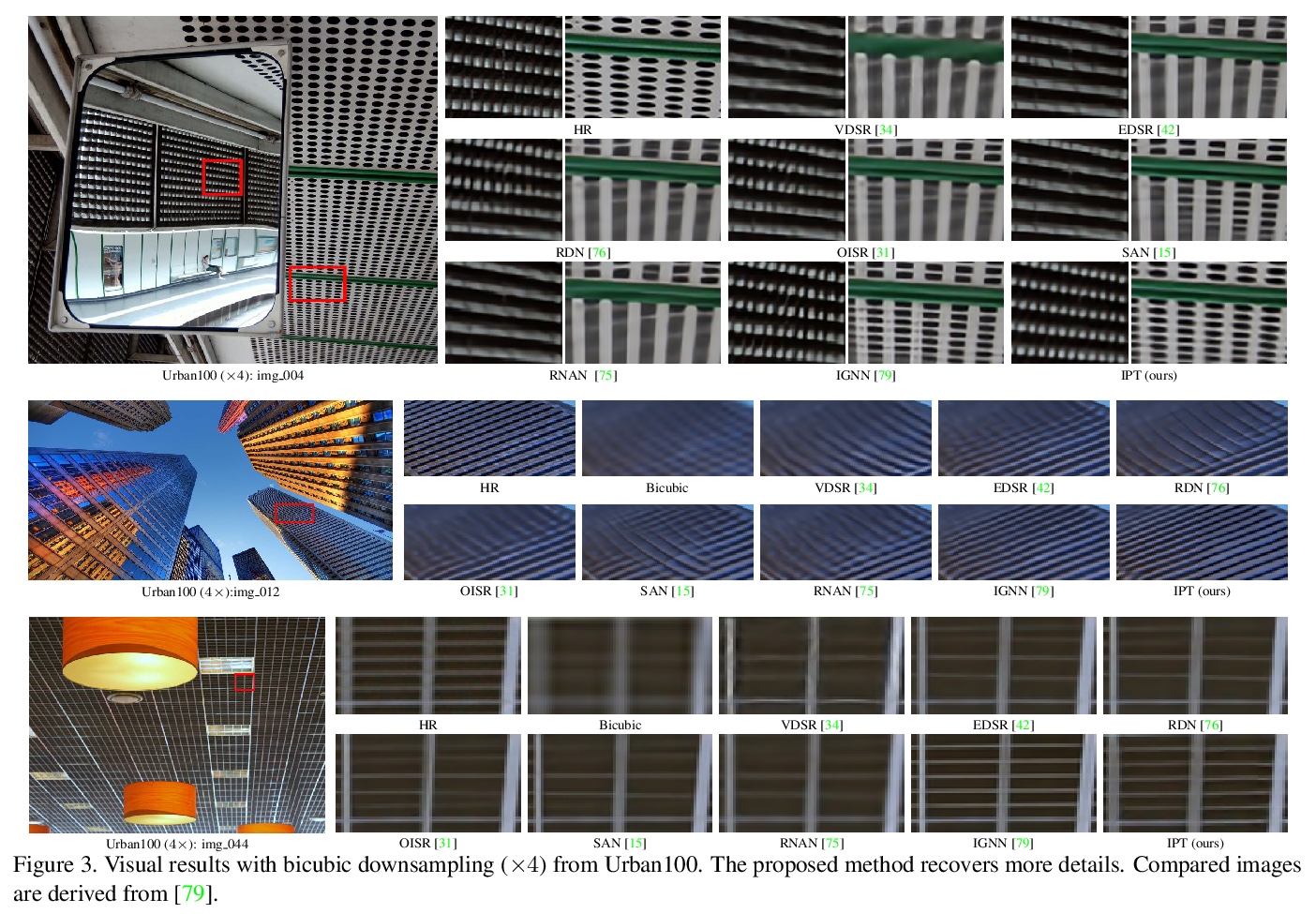
2、** **[CV] Pre-Trained Image Processing Transformer
H Chen, Y Wang, T Guo, C Xu, Y Deng, Z Liu, S Ma, C Xu, C Xu, W Gao
[Peking University & Huawei Technologies & The University of Sydney]
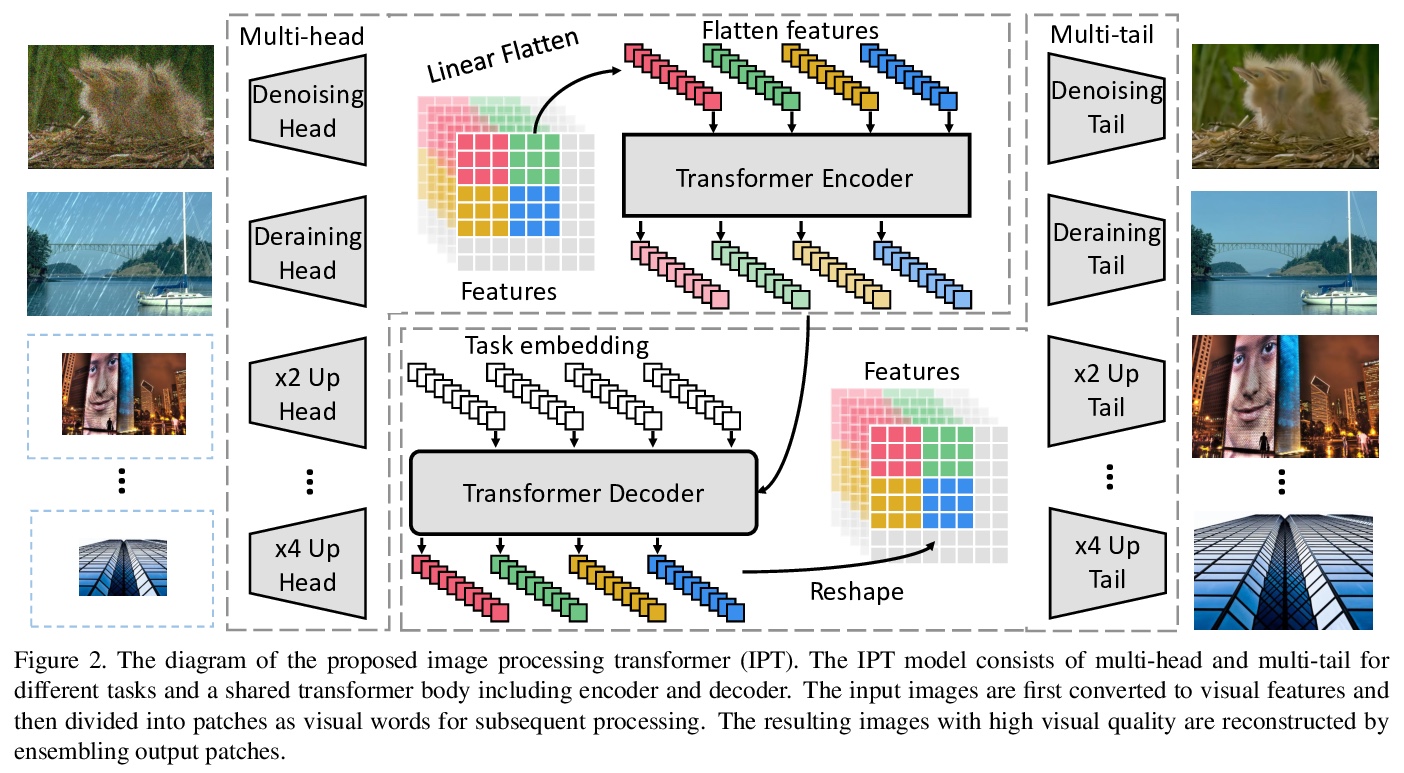
预训练图像处理Transformer。旨在解决用预训练Transformer模型进行图像处理(IPT)的问题,用多头、多尾共享transformer体,处理图像超分辨和去噪等各种图像处理任务。为最大限度挖掘transformer架构在各种任务上的性能,探索了合成ImageNet数据集,每幅原始图像被降级为用于配对训练的一系列对应图像,用有监督和自监督方法训练IPT模型,显示了较强的捕获内在特征、用于低级图像处理的能力。实验结果表明,IPT在快速微调后,仅用单个预训练模型,就可超过目前的方法。
As the computing power of modern hardware is increasing strongly, pre-trained deep learning models (e.g., BERT, GPT-3) learned on large-scale datasets have shown their effectiveness over conventional methods. The big progress is mainly contributed to the representation ability of transformer and its variant architectures. In this paper, we study the low-level computer vision task (e.g., denoising, super-resolution and deraining) and develop a new pre-trained model, namely, image processing transformer (IPT). To maximally excavate the capability of transformer, we present to utilize the well-known ImageNet benchmark for generating a large amount of corrupted image pairs. The IPT model is trained on these images with multi-heads and multi-tails. In addition, the contrastive learning is introduced for well adapting to different image processing tasks. The pre-trained model can therefore efficiently employed on desired task after fine-tuning. With only one pre-trained model, IPT outperforms the current state-of-the-art methods on various low-level benchmarks.
https://weibo.com/1402400261/JxUr2wiIQ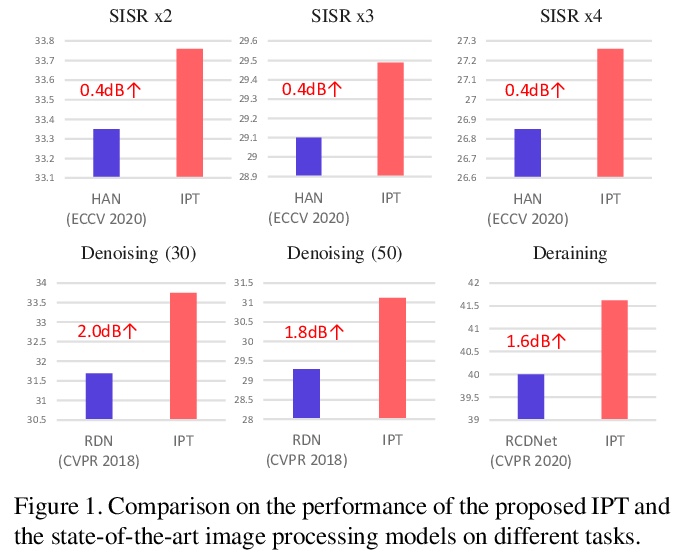
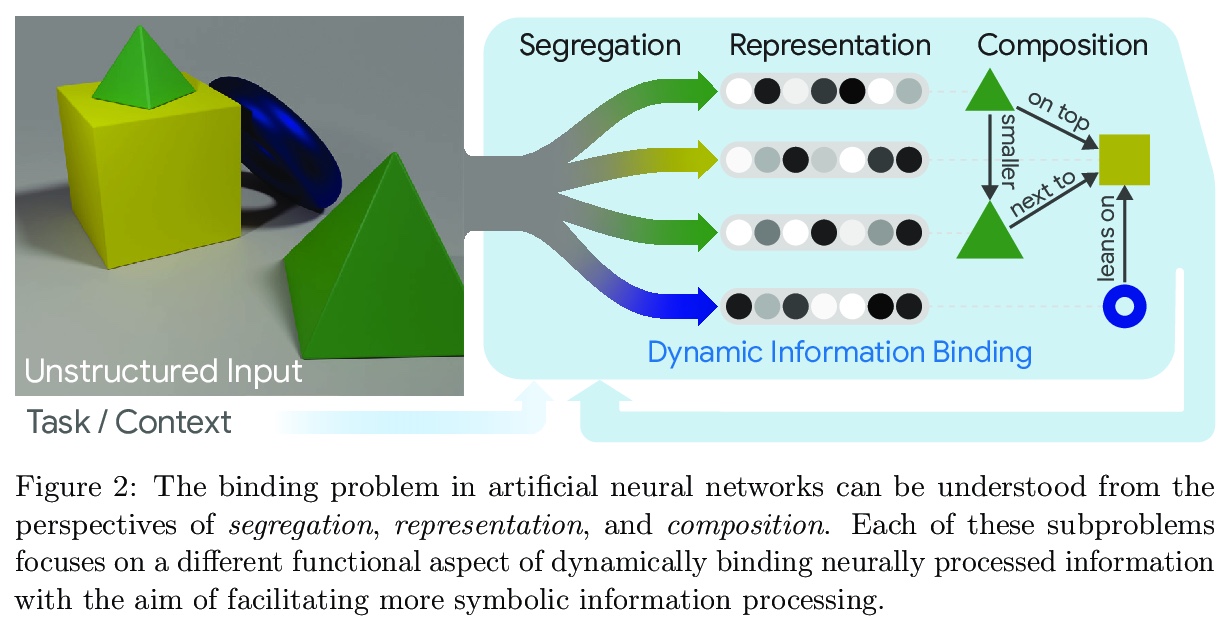
3、[LG] On the Binding Problem in Artificial Neural Networks
K Greff, S v Steenkiste, J Schmidhuber
[Google Research & Università della Svizzera Italiana]
人工神经网络中的绑定问题。认为神经网络没有达到人类泛化水平,根本原因是其无法动态、灵活地绑定分布在整个网络中的信息,影响了从象征性实体角度获得综合理解世界的能力,这对于以可预测、系统方式进行泛化,是至关重要的。为解决该问题,提出了一个统一框架,围绕着从非结构化的感觉输入(分离),形成有意义的实体,在表示级别上保持信息的分离(表示),用这些实体来构建新的推断、预测和行为(组合)。
Contemporary neural networks still fall short of human-level generalization, which extends far beyond our direct experiences. In this paper, we argue that the underlying cause for this shortcoming is their inability to dynamically and flexibly bind information that is distributed throughout the network. This binding problem affects their capacity to acquire a compositional understanding of the world in terms of symbol-like entities (like objects), which is crucial for generalizing in predictable and systematic ways. To address this issue, we propose a unifying framework that revolves around forming meaningful entities from unstructured sensory inputs (segregation), maintaining this separation of information at a representational level (representation), and using these entities to construct new inferences, predictions, and behaviors (composition). Our analysis draws inspiration from a wealth of research in neuroscience and cognitive psychology, and surveys relevant mechanisms from the machine learning literature, to help identify a combination of inductive biases that allow symbolic information processing to emerge naturally in neural networks. We believe that a compositional approach to AI, in terms of grounded symbol-like representations, is of fundamental importance for realizing human-level generalization, and we hope that this paper may contribute towards that goal as a reference and inspiration.
https://weibo.com/1402400261/JxUw6fDuX

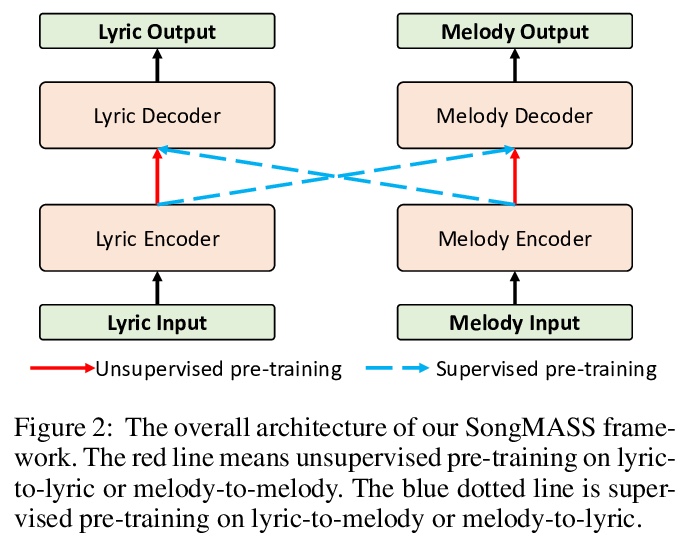
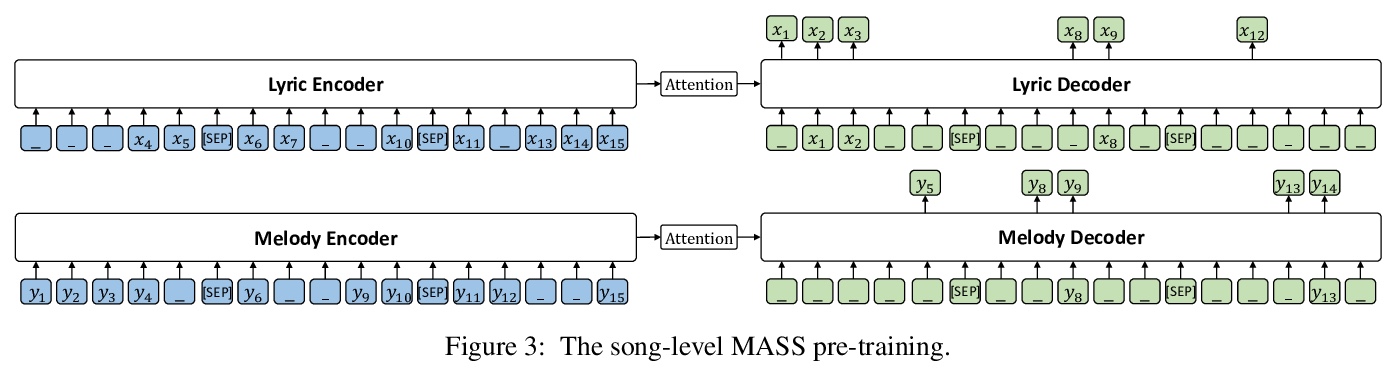
4、** **[AS] SongMASS: Automatic Song Writing with Pre-training and Alignment Constraint
Z Sheng, K Song, X Tan, Y Ren, W Ye, S Zhang, T Qin
[Peking University & Nanjing University of Science and Technology & Microsoft Research Asia & Zhejiang University]
基于预训练与对齐约束的自动写歌。提出了自动歌曲写作系统SongMASS,利用隐含序列的预训练,和基于注意力的对齐约束,实现歌词到旋律和旋律到歌词的生成。引入基于MASS的歌词-歌词和音乐-旋律预训练,包括歌曲级无监督预训练和监督预训练损失,以学习歌词和旋律之间共享的潜空间。在此基础上,引入句子级和符号级对齐约束,提出了动态规划算法来实现歌词与旋律的精确对齐。
Automatic song writing aims to compose a song (lyric and/or melody) by machine, which is an interesting topic in both academia and industry. In automatic song writing, lyric-to-melody generation and melody-to-lyric generation are two important tasks, both of which usually suffer from the following challenges: 1) the paired lyric and melody data are limited, which affects the generation quality of the two tasks, considering a lot of paired training data are needed due to the weak correlation between lyric and melody; 2) Strict alignments are required between lyric and melody, which relies on specific alignment modeling. In this paper, we propose SongMASS to address the above challenges, which leverages masked sequence to sequence (MASS) pre-training and attention based alignment modeling for lyric-to-melody and melody-to-lyric generation. Specifically, 1) we extend the original sentence-level MASS pre-training to song level to better capture long contextual information in music, and use a separate encoder and decoder for each modality (lyric or melody); 2) we leverage sentence-level attention mask and token-level attention constraint during training to enhance the alignment between lyric and melody. During inference, we use a dynamic programming strategy to obtain the alignment between each word/syllable in lyric and note in melody. We pre-train SongMASS on unpaired lyric and melody datasets, and both objective and subjective evaluations demonstrate that SongMASS generates lyric and melody with significantly better quality than the baseline method without pre-training or alignment constraint.
https://weibo.com/1402400261/JxUBfqLCn
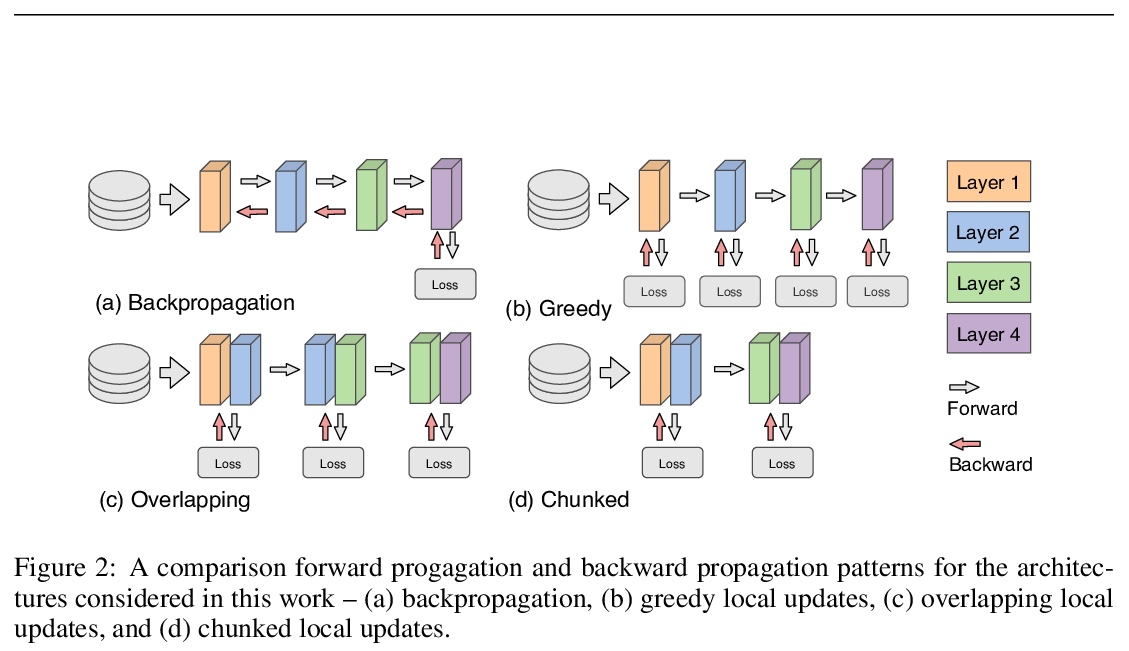
5、** **[LG] Parallel Training of Deep Networks with Local Updates
M Laskin, L Metz, S Nabarrao, M Saroufim, B Noune, C Luschi, J Sohl-Dickstein, P Abbeel
[University of Berkeley & Google Research & Graphcore Research]
基于局部更新的深度网络并行训练。研究了通过局部并行,不受收益递减限制,继续有效进行大规模计算,通过将全局反向传播替换为截断的分层反向传播,来并行化深度网络各层训练。与模型并行相比,局部并行支持完全异步的分层并行,占用内存较少,需要的通信开销也很少。
Deep learning models trained on large data sets have been widely successful in both vision and language domains. As state-of-the-art deep learning architectures have continued to grow in parameter count so have the compute budgets and times required to train them, increasing the need for compute-efficient methods that parallelize training. Two common approaches to parallelize the training of deep networks have been data and model parallelism. While useful, data and model parallelism suffer from diminishing returns in terms of compute efficiency for large batch sizes. In this paper, we investigate how to continue scaling compute efficiently beyond the point of diminishing returns for large batches through local parallelism, a framework which parallelizes training of individual layers in deep networks by replacing global backpropagation with truncated layer-wise backpropagation. Local parallelism enables fully asynchronous layer-wise parallelism with a low memory footprint, and requires little communication overhead compared with model parallelism. We show results in both vision and language domains across a diverse set of architectures, and find that local parallelism is particularly effective in the high-compute regime.
https://weibo.com/1402400261/JxUIXybI0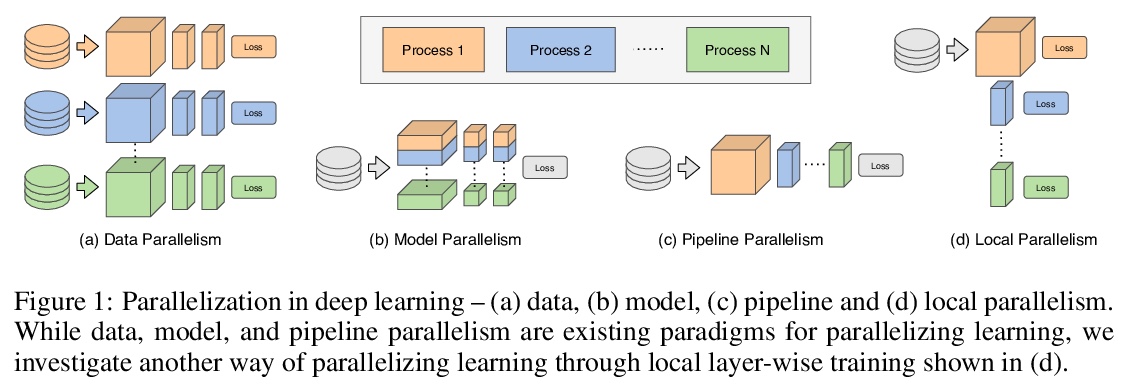
另外几篇值得关注的论文:
[LG] Gauge equivariant neural networks for quantum lattice gauge theories
面向量子晶格规范理论的规范等变神经网络
D Luo, G Carleo, B K. Clark, J Stokes
[University of Illinois at Urbana-Champaign & Ecole Polytechnique Federale de Lausanne (EPFL)]
https://weibo.com/1402400261/JxUGWgZRC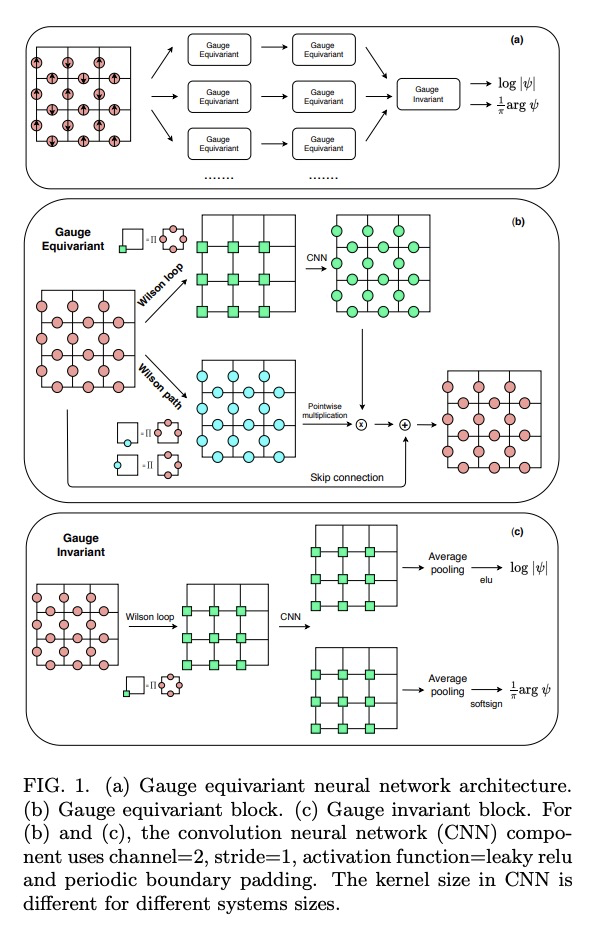
[CV] Lipschitz Regularized CycleGAN for Improving Semantic Robustness in Unpaired Image-to-image Translation
用Lipschitz正则化CycleGAN提高非配对图像变换语义鲁棒性
Z Jia, B Yuan, K Wang, H Wu, D Clifford, Z Yuan, H Su
[UC San Diego & X]
https://weibo.com/1402400261/JxUMUenFX


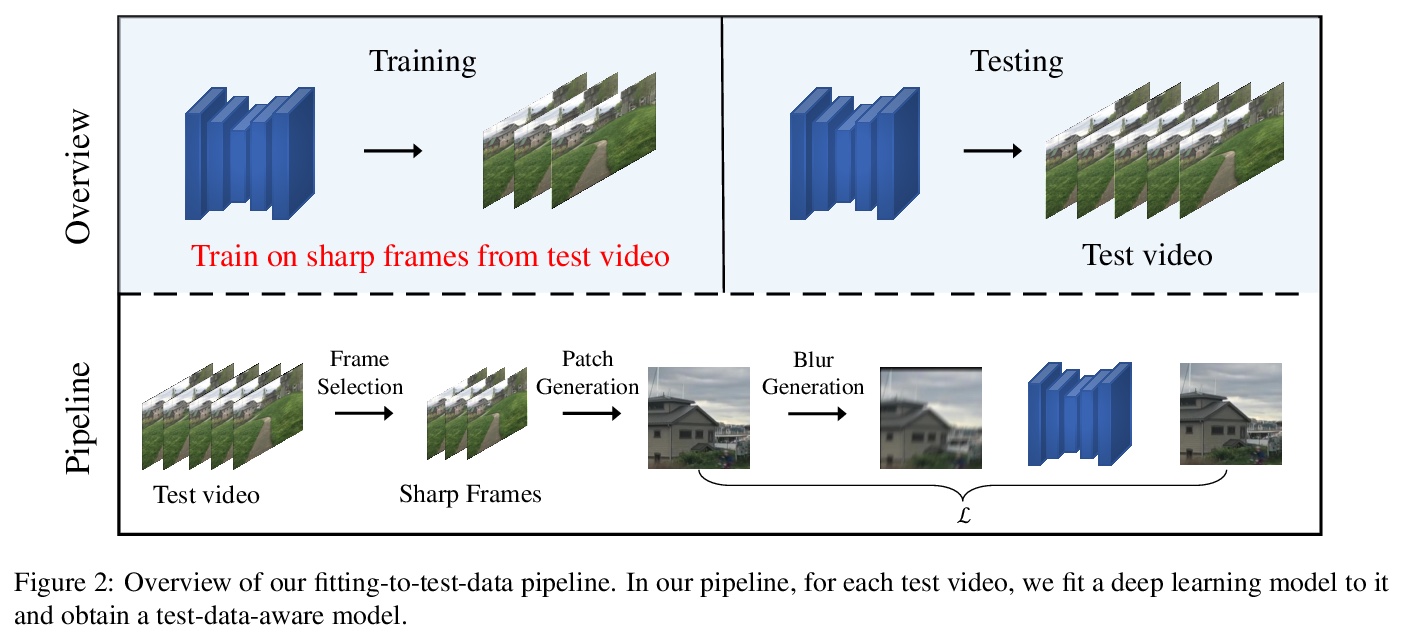
[CV] Video Deblurring by Fitting to Test Data
通过拟合测试数据实现视频去模糊
X Ren, Z Qian, Q Chen
[The Hong Kong University of Science and Technology]
https://weibo.com/1402400261/JxUOB40Mb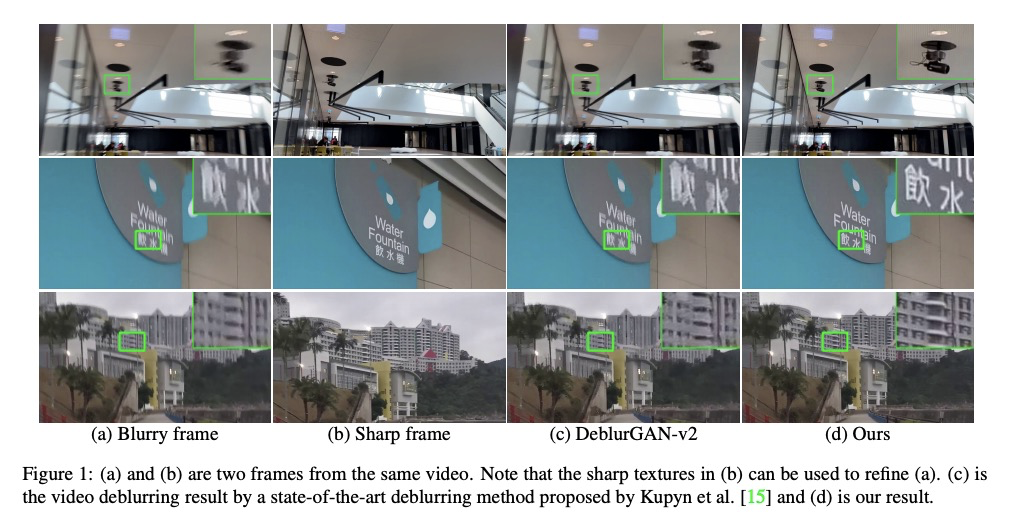
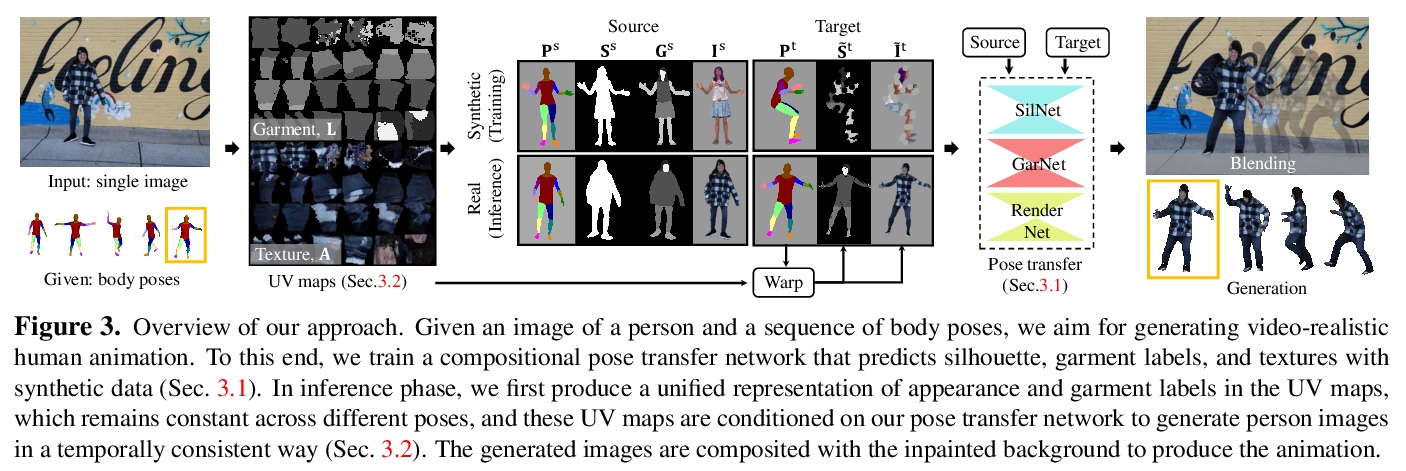
[CV] Pose-Guided Human Animation from a Single Image in the Wild
自然场景的单图像姿态引导人体动画
J S Yoon, L Liu, V Golyanik, K Sarkar, H S Park, C Theobalt
[University of Minnesota & Max Planck Institute for Informatics]
https://weibo.com/1402400261/JxUSHweIp


若有收获,就点个赞吧
0 人点赞
