- 1、[CV] Revisiting ResNets: Improved Training and Scaling Strategies
- 2、[CV] Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
- 3、[CV] Probabilistic two-stage detection
- 4、[CL] Few-Shot Text Classification with Triplet Networks, Data Augmentation, and Curriculum Learning
- 5、[CV] Spatially-Adaptive Pixelwise Networks for Fast Image Translation
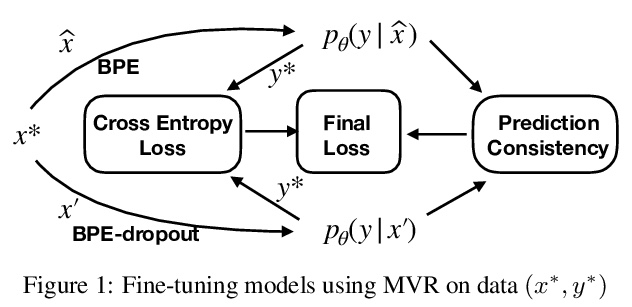
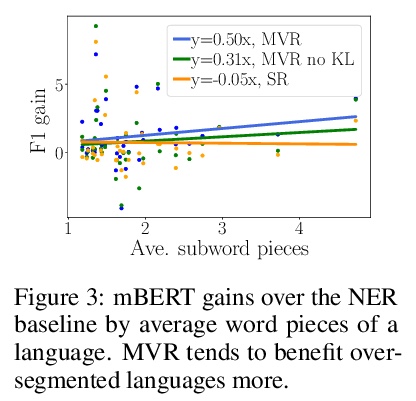
- [CL] Multi-view Subword Regularization
- [CV] PhotoApp: Photorealistic Appearance Editing of Head Portraits
- [CL] ReportAGE: Automatically extracting the exact age of Twitter users based on self-reports in tweets
- [CV] TransFG: A Transformer Architecture for Fine-grained Recognition
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Revisiting ResNets: Improved Training and Scaling Strategies
I Bello, W Fedus, X Du, E D. Cubuk, A Srinivas, T Lin, J Shlens, B Zoph
[Google Brain & UC Berkeley]
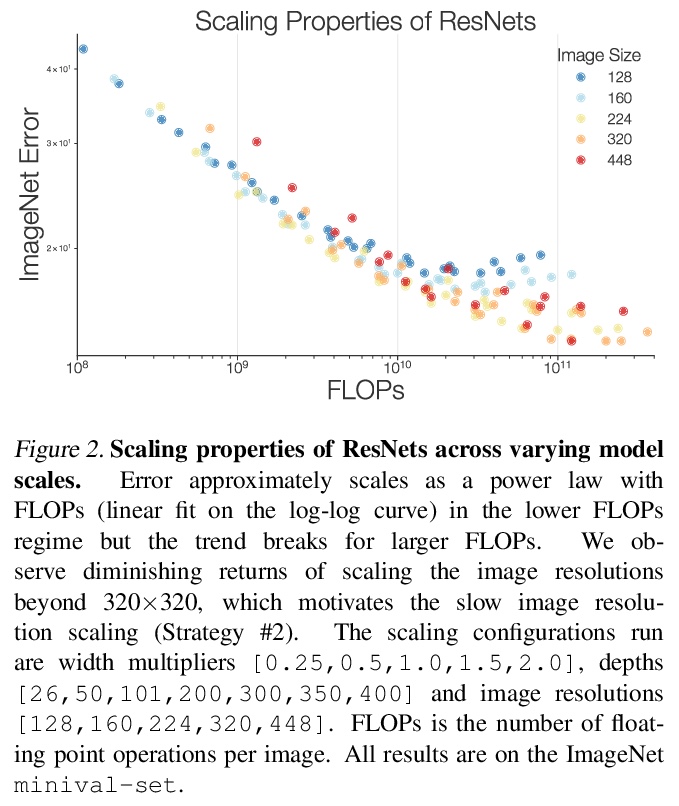
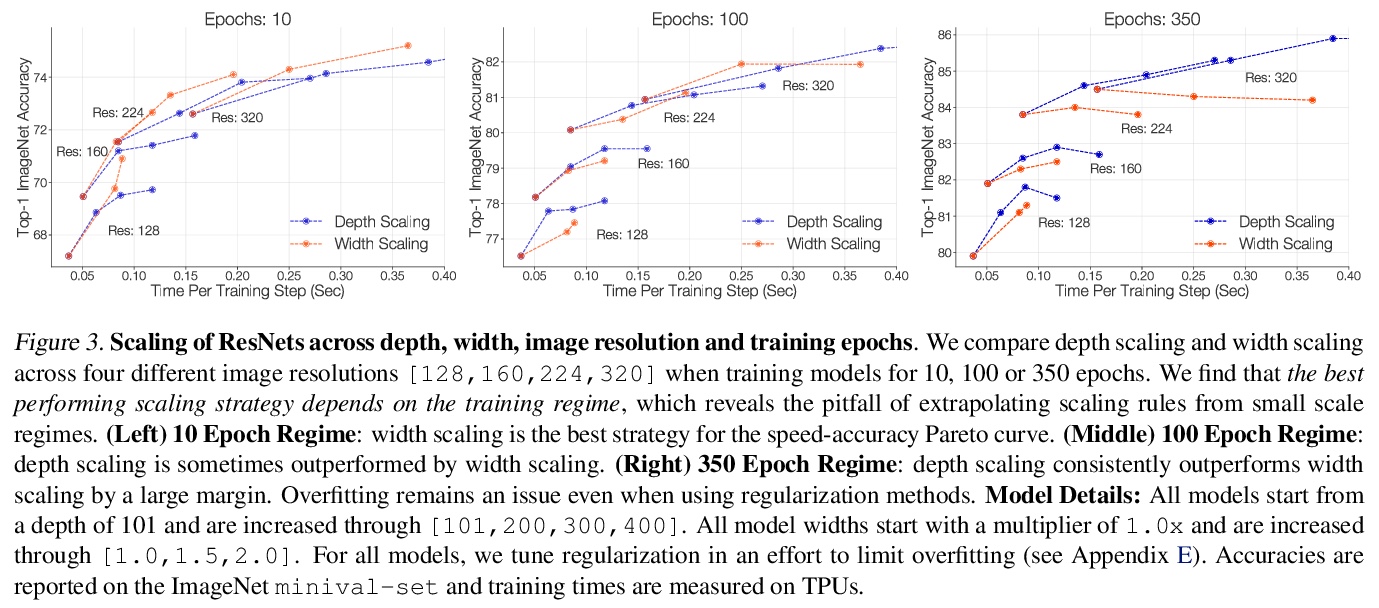
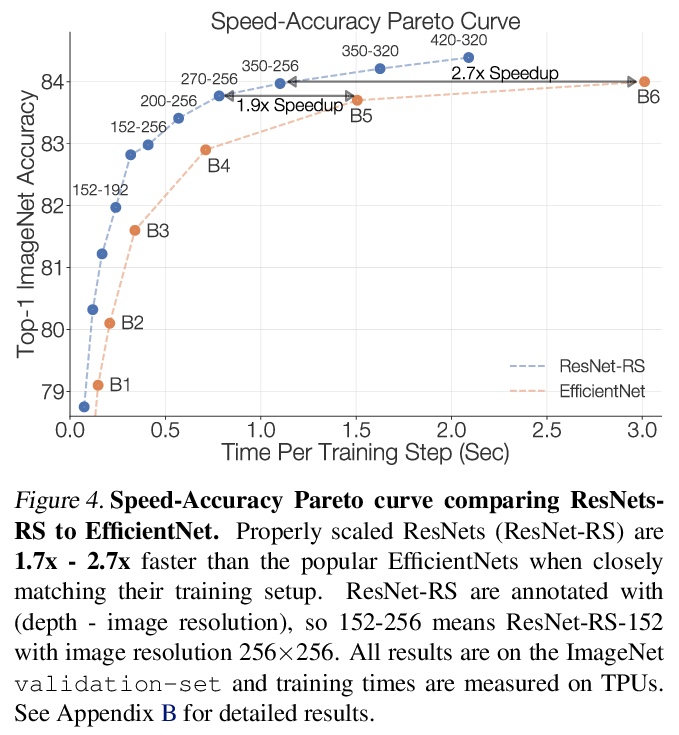
反思ResNets:改进训练和扩展策略。重新研究了标准的ResNet,发现训练和扩展策略可能比架构变化更重要,所产生的ResNets与最近的最先进模型相匹敌,性能最好的扩展策略取决于训练方式。对正则化技术及其相互作用进行了实证研究,得出了一种正则化策略,在不改变模型架构的情况下,实现了强大的性能(+3%的top 1精度)。提出了两种新的扩展策略:(1)当可能发生过拟合时,对深度进行扩展(否则优先扩展宽度);(2)更慢地扩展图像分辨率。这种扩展策略改善了ResNets和EfficientNets的速度-精度帕累托曲线。使用改进的训练和扩展策略,设计了一个ResNet架构系列,ResNet-RS,在TPU上比EfficientNets快1.7-2.7倍,同时在ImageNet上实现类似的精度。在大规模的半监督学习环境下,ResNet-RS实现了86.2%的Top-1 ImageNet精度,同时比EfficientNetNoisyStudent快4.7倍。训练技术提高了一系列下游任务的传输性能(可与最先进的自监督算法相比),将训练方法和架构变化扩展到视频分类,3D ResNet-RS。所得模型比基线提高了4.8%的Top-1 Kinetics-400准确率。
Novel computer vision architectures monopolize the spotlight, but the impact of the model architecture is often conflated with simultaneous changes to training methodology and scaling strategies. Our work revisits the canonical ResNet (He et al., 2015) and studies these three aspects in an effort to disentangle them. Perhaps surprisingly, we find that training and scaling strategies may matter more than architectural changes, and further, that the resulting ResNets match recent state-of-the-art models. We show that the best performing scaling strategy depends on the training regime and offer two new scaling strategies: (1) scale model depth in regimes where overfitting can occur (width scaling is preferable otherwise); (2) increase image resolution more slowly than previously recommended (Tan & Le, 2019). Using improved training and scaling strategies, we design a family of ResNet architectures, ResNet-RS, which are 1.7x - 2.7x faster than EfficientNets on TPUs, while achieving similar accuracies on ImageNet. In a large-scale semi-supervised learning setup, ResNet-RS achieves 86.2% top-1 ImageNet accuracy, while being 4.7x faster than EfficientNet NoisyStudent. The training techniques improve transfer performance on a suite of downstream tasks (rivaling state-of-the-art self-supervised algorithms) and extend to video classification on Kinetics-400. We recommend practitioners use these simple revised ResNets as baselines for future research.
https://weibo.com/1402400261/K6xYmzoMd
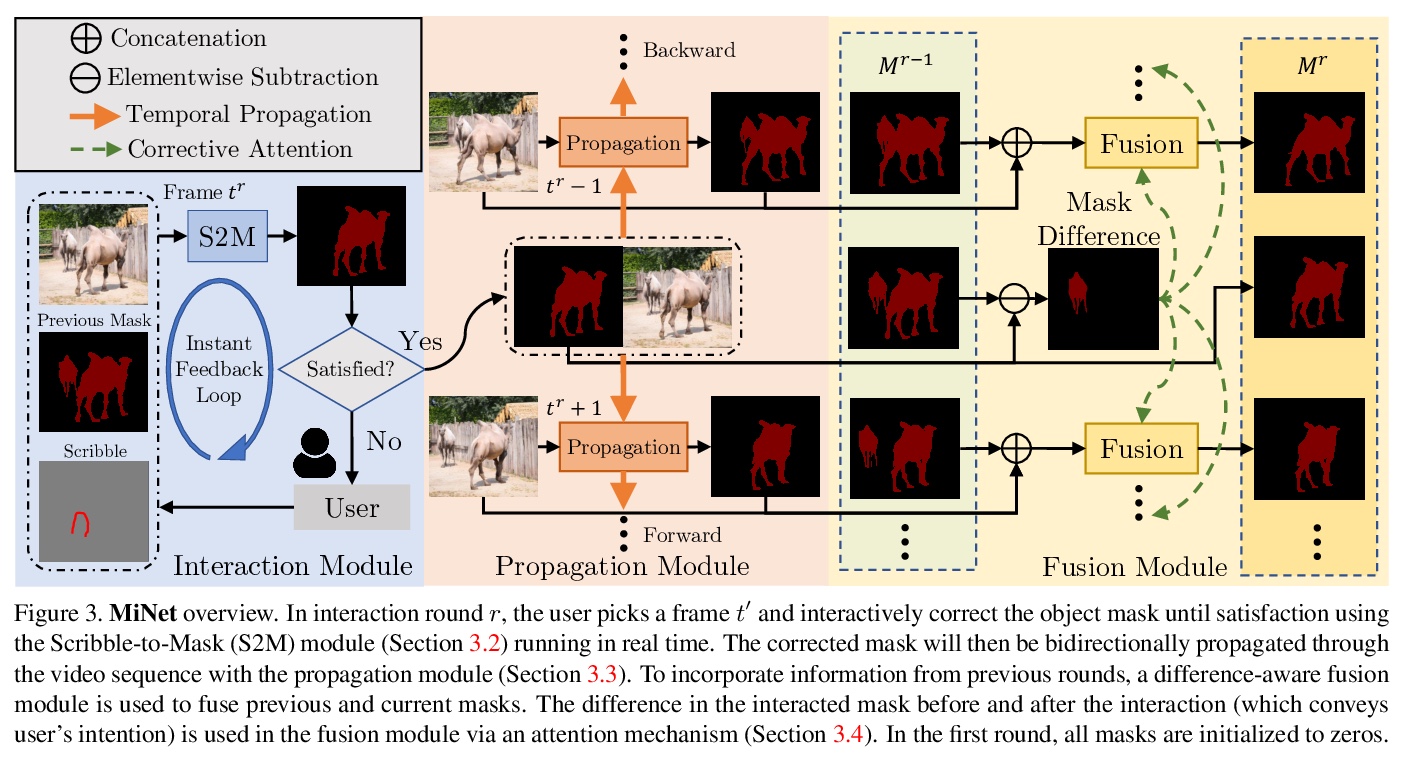
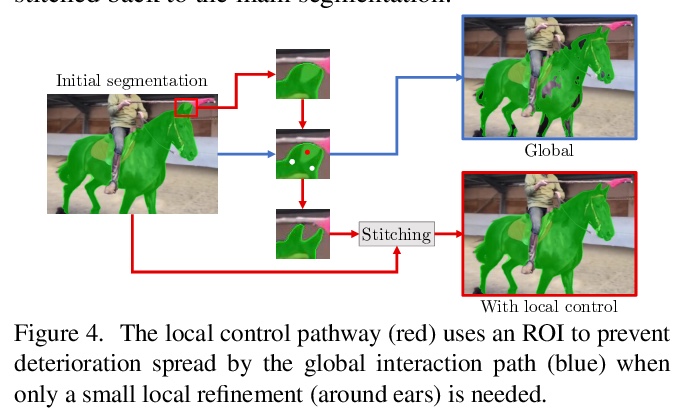
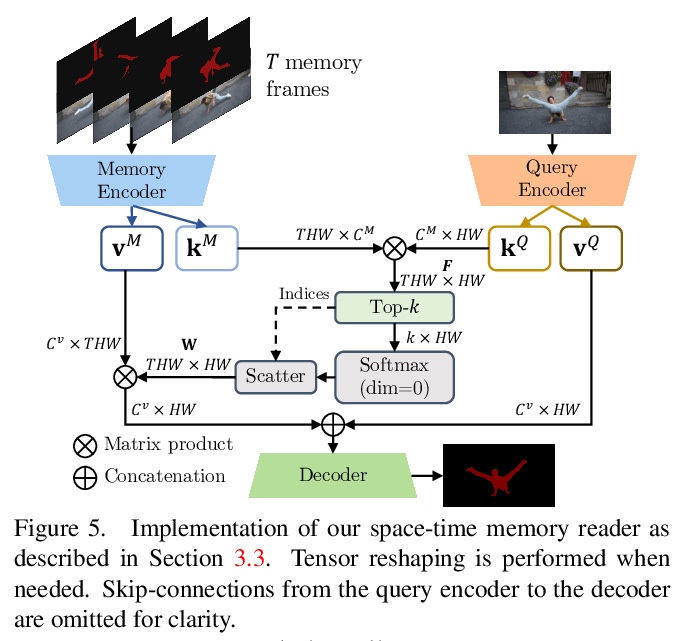
2、[CV] Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
H K Cheng, Y Tai, C Tang
[UIUC/HKUST & Kuaishou Technology]
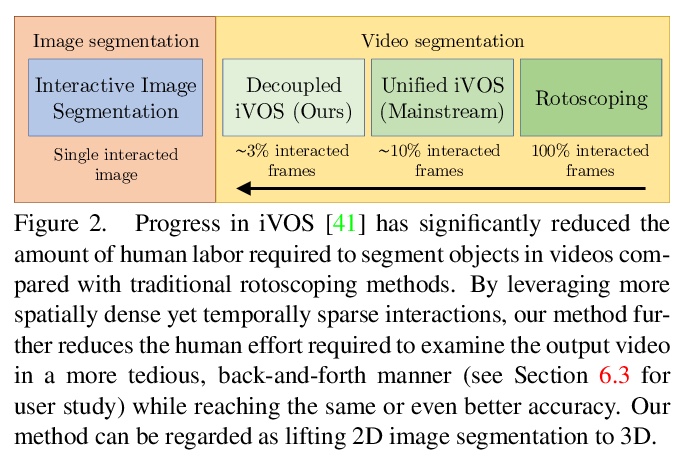
模块化交互式视频目标分割:交互掩模、传播与差异感知融合。提出模块化交互式视频目标分割(MiVOS)框架,将交互掩模和掩模传播解耦,可实现更高的通用性和更好的性能。交互模块单独训练,将用户交互转换为目标掩模,传播模块在读取时空记忆时用新的top-k过滤策略进行时空传播。为有效考虑用户意图,提出了新的差异感知模块,学习如何正确地融合每次交互前后的掩模,用时空记忆使掩模与目标帧对齐。通过忠实地捕捉用户意图,来调和交互和传播,减轻解耦过程中的信息损失,使MiVOS既准确又高效。
We present Modular interactive VOS (MiVOS) framework which decouples interaction-to-mask and mask propagation, allowing for higher generalizability and better performance. Trained separately, the interaction module converts user interactions to an object mask, which is then temporally propagated by our propagation module using a novel top-> k filtering strategy in reading the space-time memory. To effectively take the user’s intent into account, a novel difference-aware module is proposed to learn how to properly fuse the masks before and after each interaction, which are aligned with the target frames by employing the space-time memory. We evaluate our method both qualitatively and quantitatively with different forms of user interactions (e.g., scribbles, clicks) on DAVIS to show that our method outperforms current state-of-the-art algorithms while requiring fewer frame interactions, with the additional advantage in generalizing to different types of user interactions. We contribute a large-scale synthetic VOS dataset with pixel-accurate segmentation of 4.8M frames to accompany our source codes to facilitate future research.
https://weibo.com/1402400261/K6y4rlKyZ
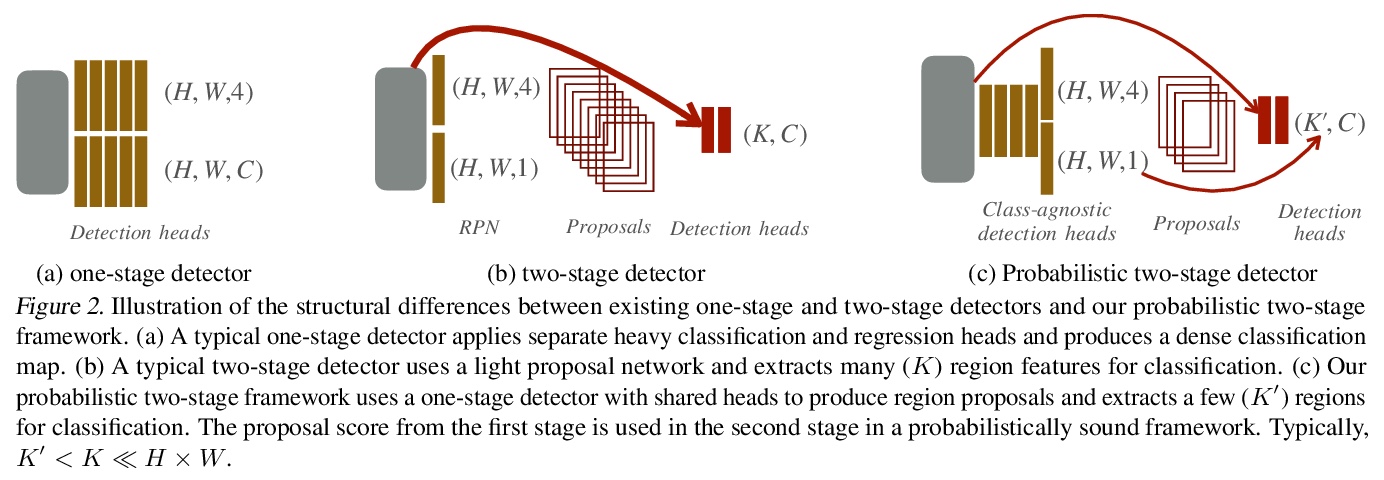
3、[CV] Probabilistic two-stage detection
X Zhou, V Koltun, P Krähenbühl
[UT Austin & Intel Labs]
概率两阶段检测。提出一种对两阶段目标检测的概率解释,通过优化两阶段联合概率目标下限,改进标准两阶段探测器训练的简单方法。概率处理建议对两阶段架构进行修改,用一个强大的第一阶段,学习估计目标似然,而不是最大化召回。该似然与第二阶段的分类得分相结合,产生最终检测的原则性概率得分。概率两阶段检测器比单级或两级检测器更快、更准确。
We develop a probabilistic interpretation of two-stage object detection. We show that this probabilistic interpretation motivates a number of common empirical training practices. It also suggests changes to two-stage detection pipelines. Specifically, the first stage should infer proper object-vs-background likelihoods, which should then inform the overall score of the detector. A standard region proposal network (RPN) cannot infer this likelihood sufficiently well, but many one-stage detectors can. We show how to build a probabilistic two-stage detector from any state-of-the-art one-stage detector. The resulting detectors are faster and more accurate than both their one- and two-stage precursors. Our detector achieves 56.4 mAP on COCO test-dev with single-scale testing, outperforming all published results. Using a lightweight backbone, our detector achieves 49.2 mAP on COCO at 33 fps on a Titan Xp, outperforming the popular YOLOv4 model.
https://weibo.com/1402400261/K6y8L4Pa0

4、[CL] Few-Shot Text Classification with Triplet Networks, Data Augmentation, and Curriculum Learning
J Wei, C Huang, S Vosoughi, Y Cheng, S Xu
[ProtagoLabs & International Monetary Fund & Dartmouth College & Microsoft AI]
基于三元组网络、数据增强和课程学习的少样本文本分类。将流行的数据增强技术应用于少样本、高度多类分类的通用三元组损失方法,发现开箱即用的增强技术可明显提高性能。提出一种简单的训练策略,课程数据增强,利用课程学习,只对原始样本进行训练,随着训练的进展引入增强数据。探索了一个两阶段和渐进的时间表,与标准的单阶段训练相比,课程数据增强训练速度更快,提高了性能,并对增强的高量噪声保持鲁棒。
Few-shot text classification is a fundamental NLP task in which a model aims to classify text into a large number of categories, given only a few training examples per category. This paper explores data augmentation — a technique particularly suitable for training with limited data — for this few-shot, highly-multiclass text classification setting. On four diverse text classification tasks, we find that common data augmentation techniques can improve the performance of triplet networks by up to 3.0% on average.To further boost performance, we present a simple training strategy called curriculum data augmentation, which leverages curriculum learning by first training on only original examples and then introducing augmented data as training progresses. We explore a two-stage and a gradual schedule, and find that, compared with standard single-stage training, curriculum data augmentation trains faster, improves performance, and remains robust to high amounts of noising from augmentation.
https://weibo.com/1402400261/K6ychDYNI
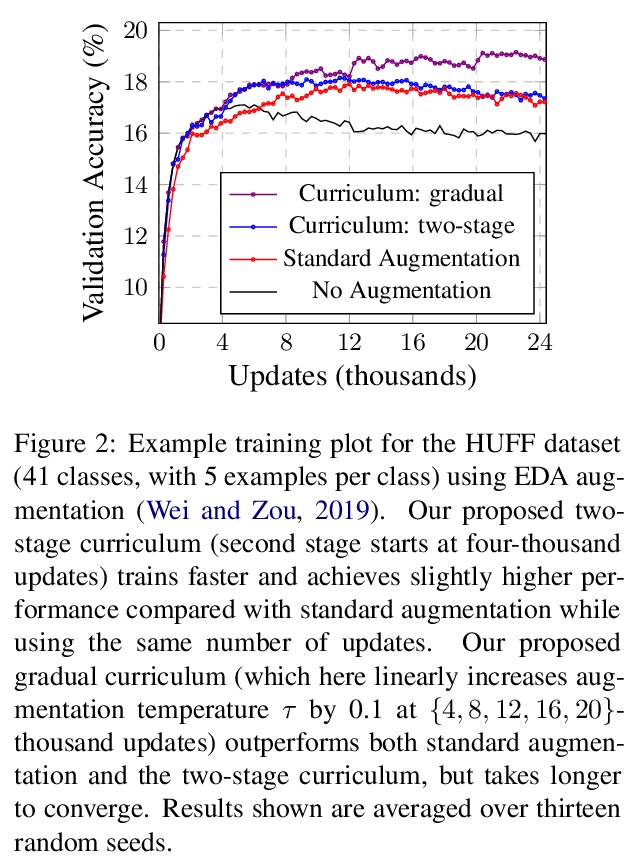
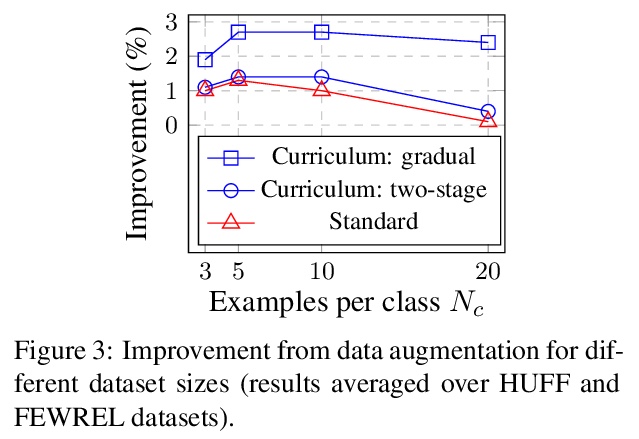
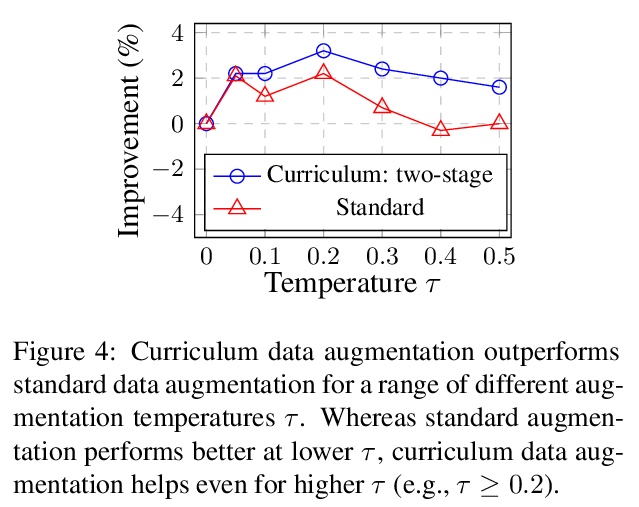
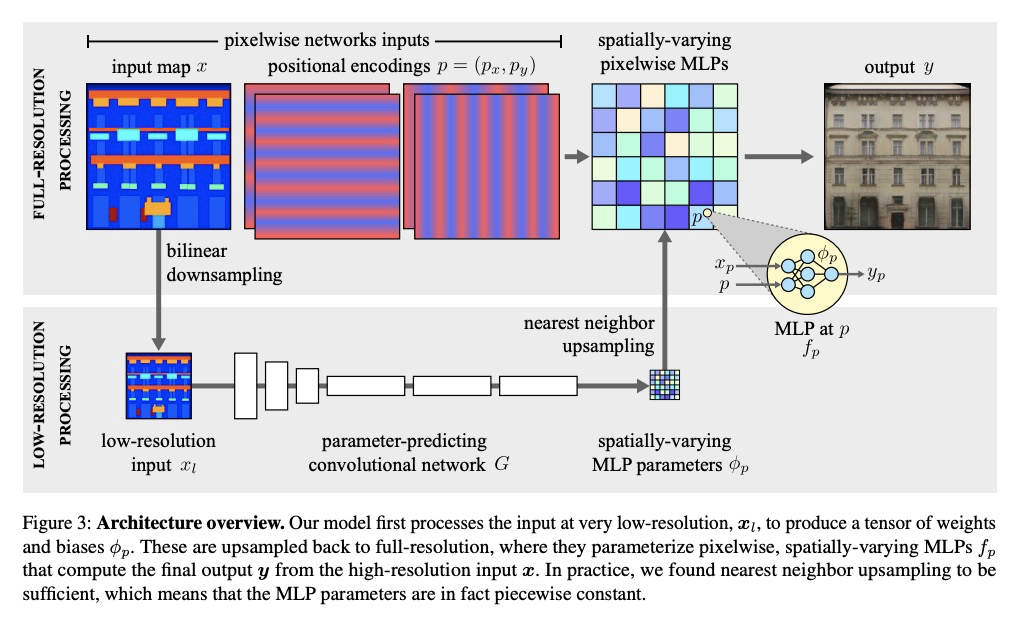
5、[CV] Spatially-Adaptive Pixelwise Networks for Fast Image Translation
T R Shaham, M Gharbi, R Zhang, E Shechtman, T Michaeli
[Technion & Adobe Research]
面向快速图像变换的空间自适应像素网络。提出一种新的像素级神经网络,每个像素都是通过简单的仿射变换和非线性组合来独立处理的,用于生成式对抗图像到图像变换问题,比之前的工作快一个数量级,但仍保持同样的高水平视觉质量。通过一种新的图像合成方法来实现这一加速:在全分辨率下,用一系列空间变化的轻量级网络,以像素级方式运行。这些网络的参数是由一个在低得多的分辨率下运行的卷积网络预测的。由于对输入像素进行了位置编码,尽管是低分辨率处理和像素化操作,模型仍然可以生成高频细节。
We introduce a new generator architecture, aimed at fast and efficient high-resolution image-to-image translation. We design the generator to be an extremely lightweight function of the full-resolution image. In fact, we use pixel-wise networks; that is, each pixel is processed independently of others, through a composition of simple affine transformations and nonlinearities. We take three important steps to equip such a seemingly simple function with adequate expressivity. First, the parameters of the pixel-wise networks are spatially varying so they can represent a broader function class than simple 1x1 convolutions. Second, these parameters are predicted by a fast convolutional network that processes an aggressively low-resolution representation of the input; Third, we augment the input image with a sinusoidal encoding of spatial coordinates, which provides an effective inductive bias for generating realistic novel high-frequency image content. As a result, our model is up to 18x faster than state-of-the-art baselines. We achieve this speedup while generating comparable visual quality across different image resolutions and translation domains.
https://weibo.com/1402400261/K6yh7ztL5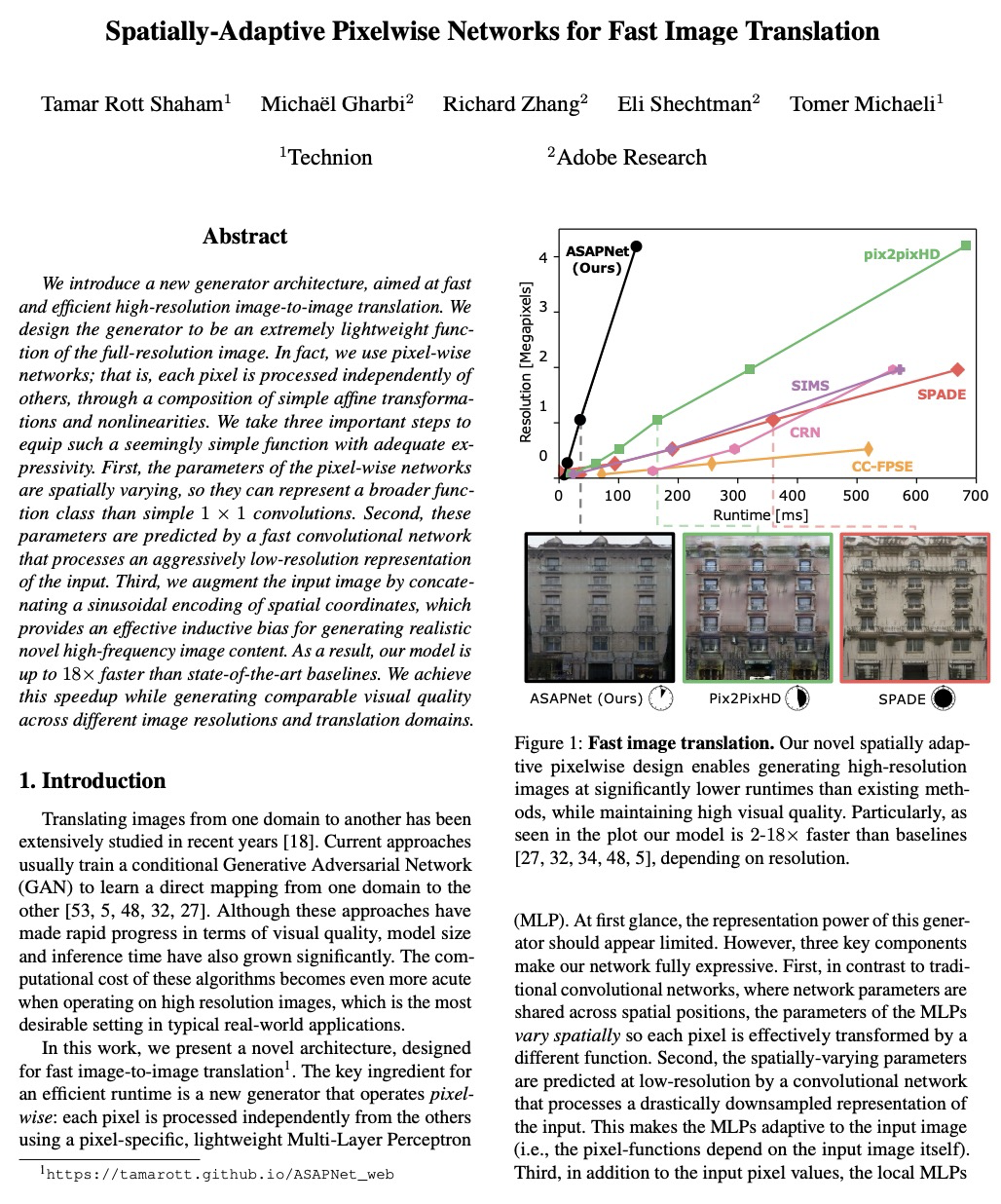


另外几篇值得关注的论文:
[CL] Multi-view Subword Regularization
多视子词正则化(MVR)
X Wang, S Ruder, G Neubig
[CMU & DeepMind]
https://weibo.com/1402400261/K6ykwk4en
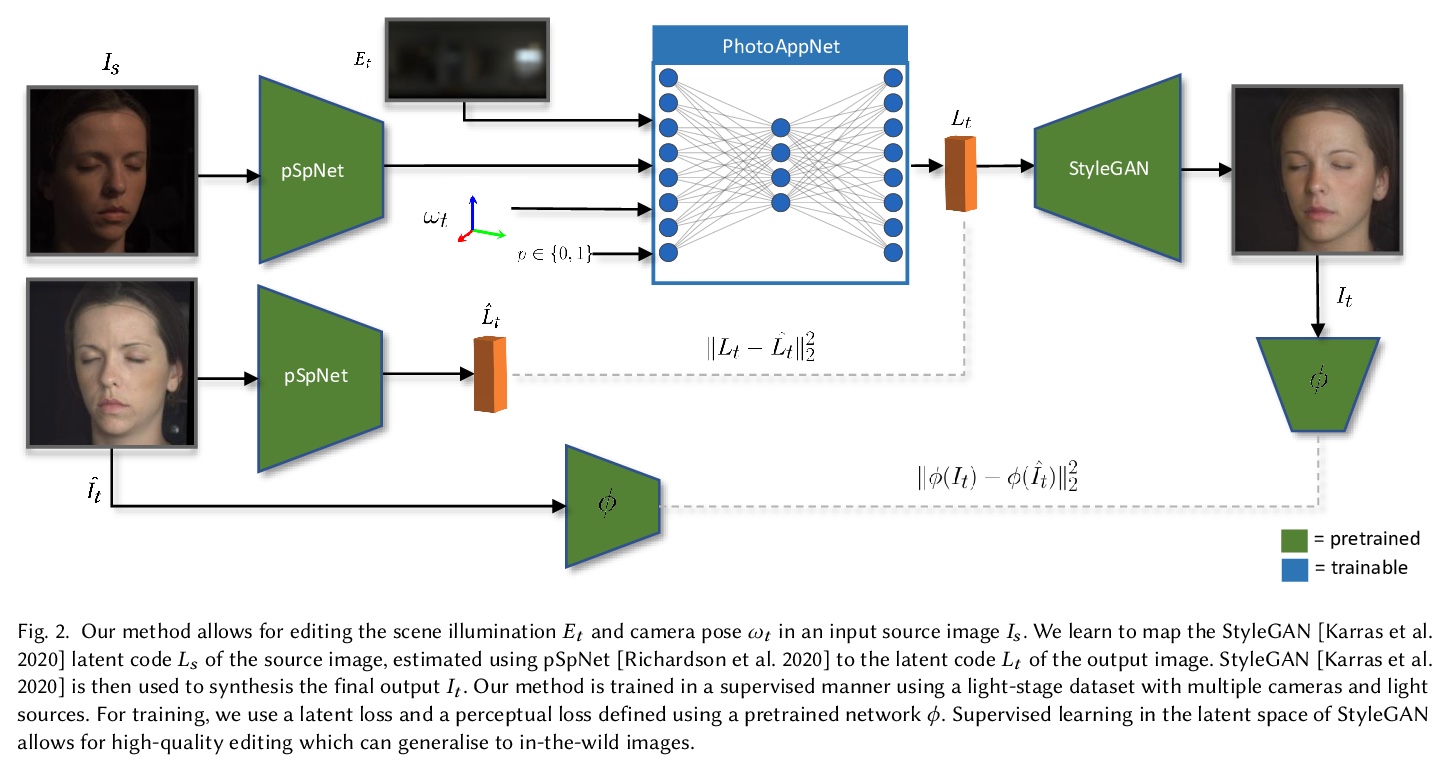
[CV] PhotoApp: Photorealistic Appearance Editing of Head Portraits
PhotoApp:头像照片逼真外观编辑
M B R, A Tewari, A Dib, T Weyrich, B Bickel, H Seidel, H Pfister, W Matusik, L Chevallier, M Elgharib, C Theobalt
[MPI for Informatics & InterDigital R&I & University College London & IST Austria…]
https://weibo.com/1402400261/K6ymGbBos


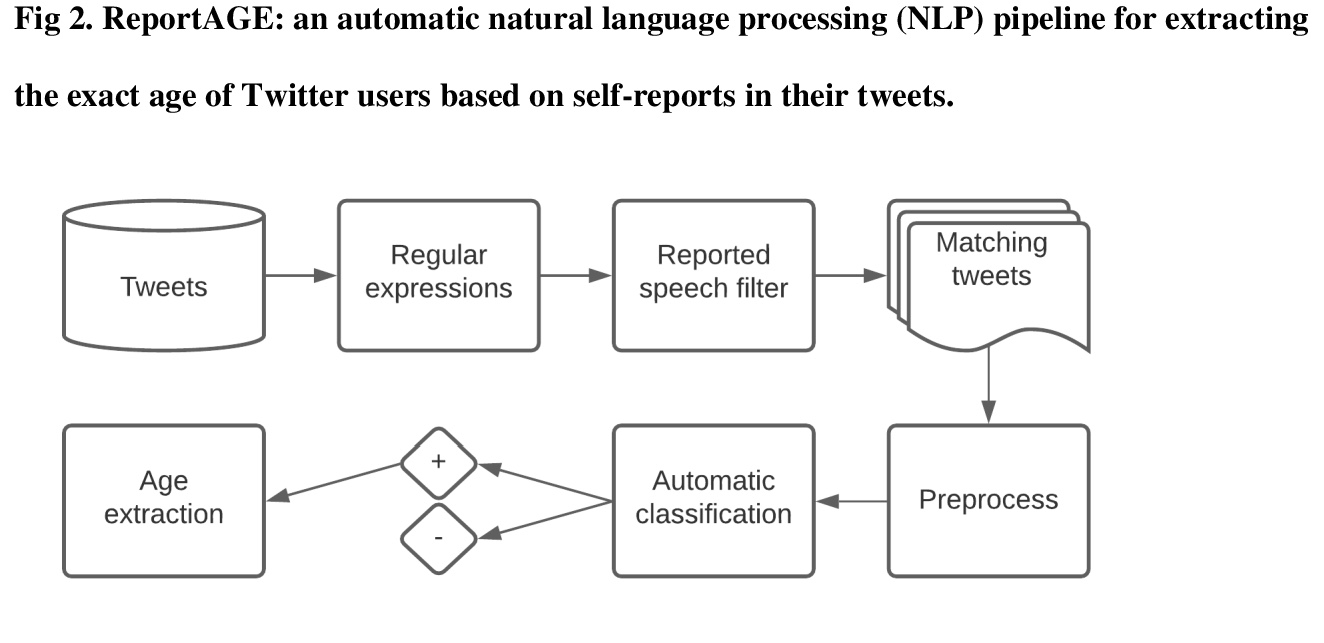
[CL] ReportAGE: Automatically extracting the exact age of Twitter users based on self-reports in tweets
ReportAGE:从推特自我报告自动提取用户确切年龄
A Z. Klein, A Magge, G Gonzalez-Hernandez
[University of Pennsylvania]
https://weibo.com/1402400261/K6ynIgEGC

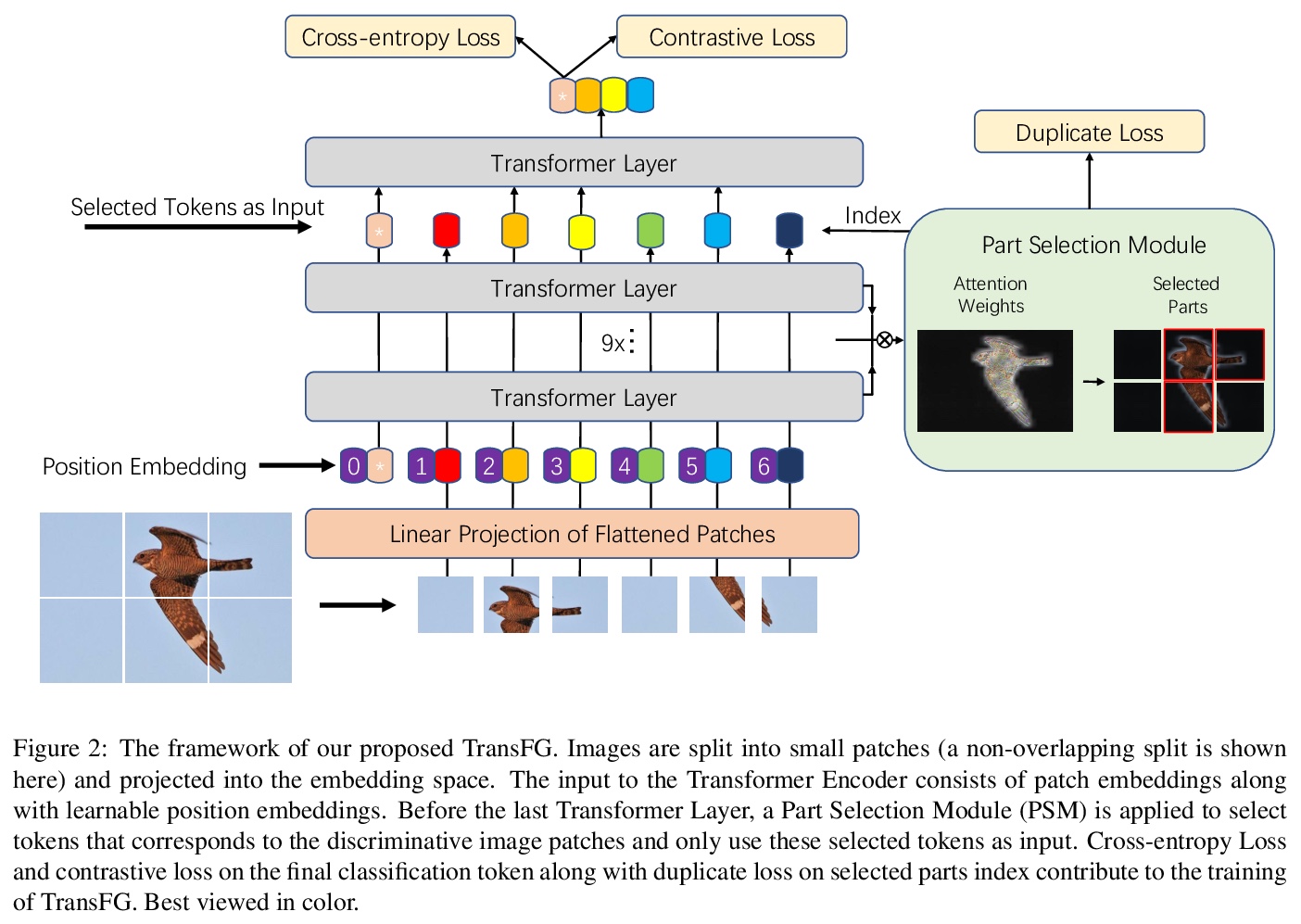
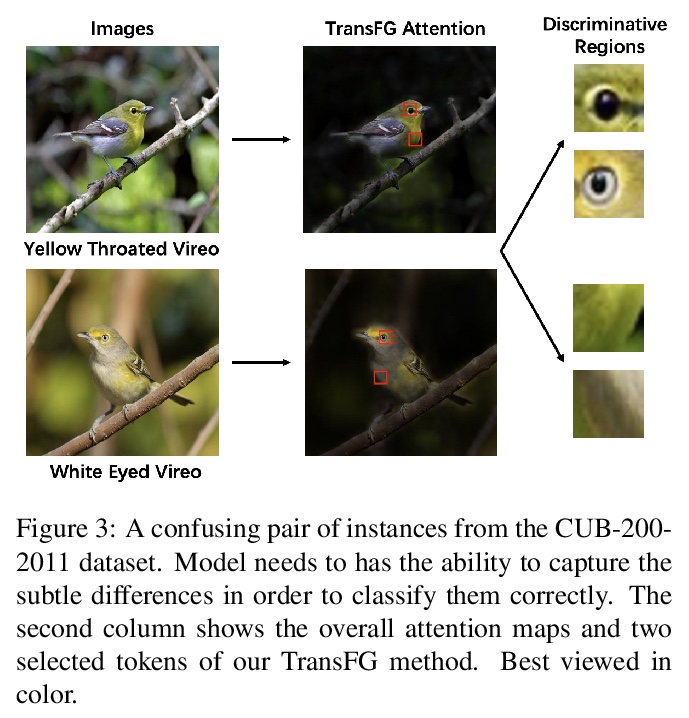
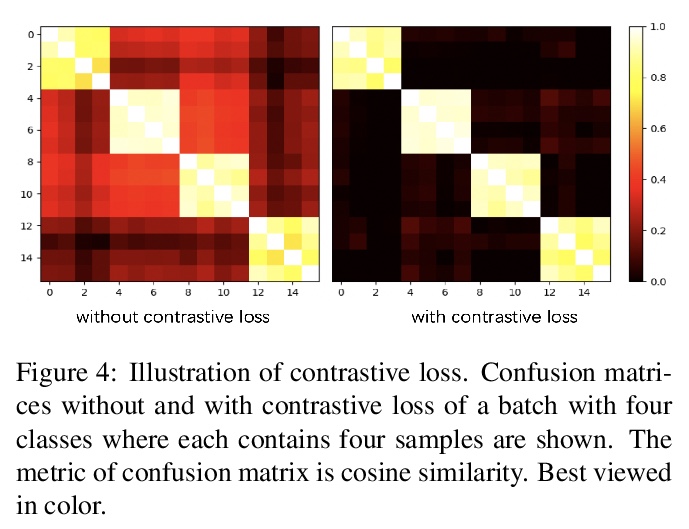
[CV] TransFG: A Transformer Architecture for Fine-grained Recognition
TransFG:用于细粒度识别的Transformer架构
J He, J Chen, S Liu, A Kortylewski, C Yang, Y Bai, C Wang, A Yuille
[Johns Hopkins University & ByteDance Inc]
https://weibo.com/1402400261/K6yoU95OY

若有收获,就点个赞吧
0 人点赞
