- LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
- 1、[CV] ViViT: A Video Vision Transformer
- 2、[CV] Labels4Free: Unsupervised Segmentation using StyleGAN
- 3、[CV] Few-shot Semantic Image Synthesis Using StyleGAN Prior
- 4、[CV] CvT: Introducing Convolutions to Vision Transformers
- 5、[RO] Autonomous Overtaking in Gran Turismo Sport Using Curriculum Reinforcement Learning
- [LG] Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
- [CV] Drop the GAN: In Defense of Patches Nearest Neighbors as Single Image Generative Models
- [CV] High-Fidelity and Arbitrary Face Editing
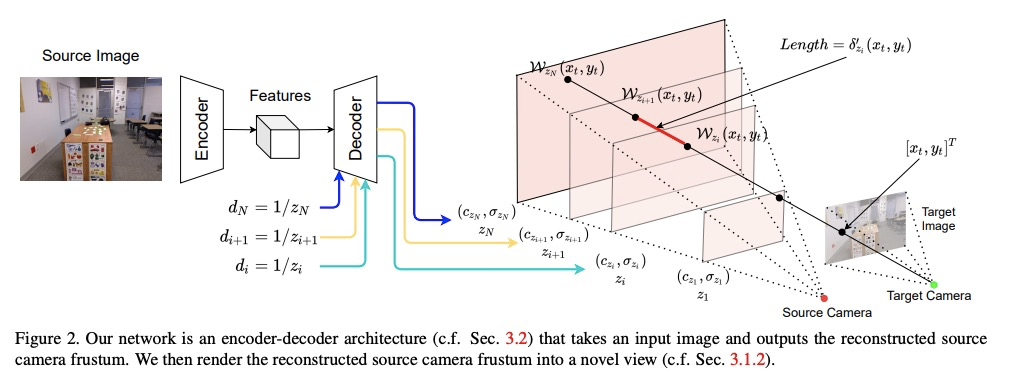
- [CV] NeMI: Unifying Neural Radiance Fields with Multiplane Images for Novel View Synthesis
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、[CV] ViViT: A Video Vision Transformer
A Arnab, M Dehghani, G Heigold, C Sun, M Lučić, C Schmid
[Google Research]
ViViT:视频视觉Transformer。提出四种面向视频分类的纯Transformer模型,从输入视频中提取时空标记,由一系列Transformer层进行编码,具有不同的准确率和效率曲线。展示了如何有效规范化这种高容量模型,以便在较小数据集上进行训练。在五个流行的数据集上取得了最先进的结果,表现优于之前基于深度3D卷积网络的方法。
We present pure-transformer based models for video classification, drawing upon the recent success of such models in image classification. Our model extracts spatio-temporal tokens from the input video, which are then encoded by a series of transformer layers. In order to handle the long sequences of tokens encountered in video, we propose several, efficient variants of our model which factorise the spatial- and temporal-dimensions of the input. Although transformer-based models are known to only be effective when large training datasets are available, we show how we can effectively regularise the model during training and leverage pretrained image models to be able to train on comparatively small datasets. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple video classification benchmarks including Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time, outperforming prior methods based on deep 3D convolutional networks. To facilitate further research, we will release code and models.
https://weibo.com/1402400261/K8FRLgI5G
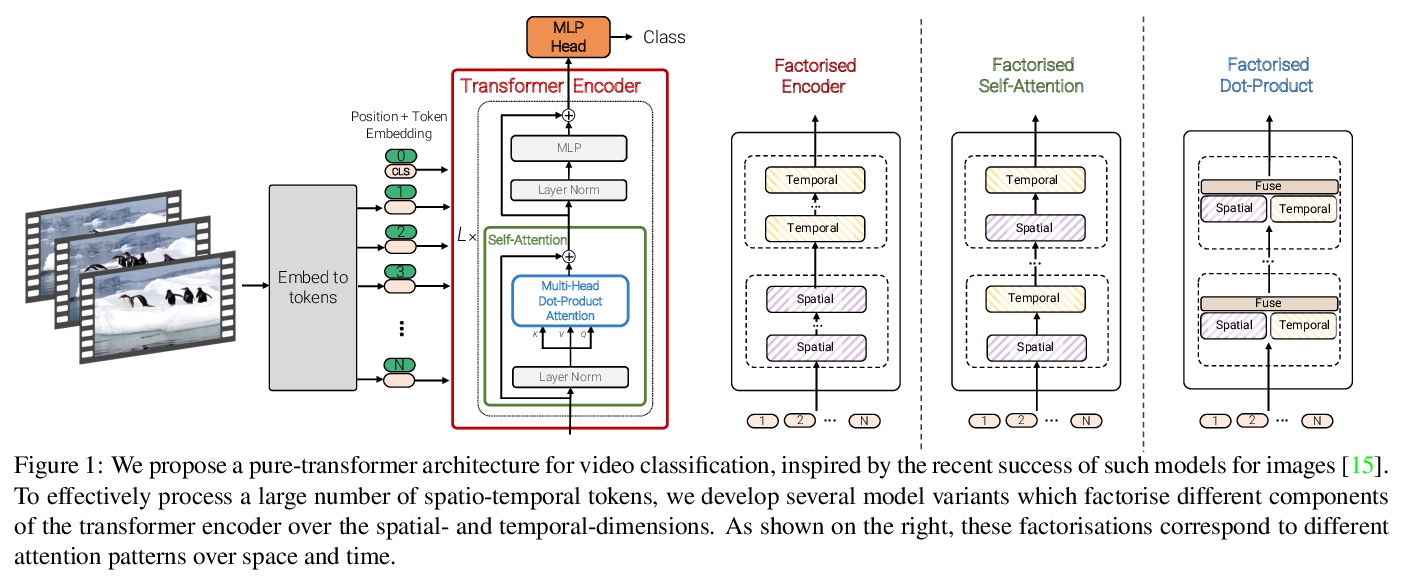
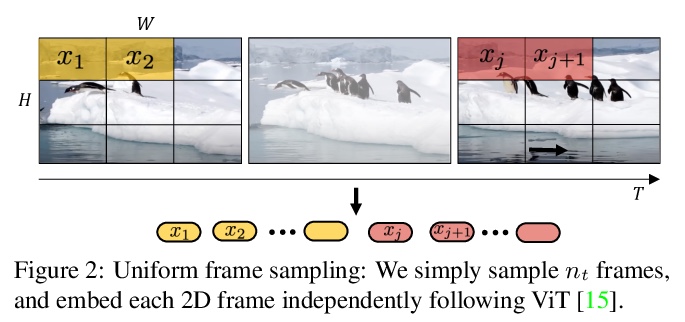
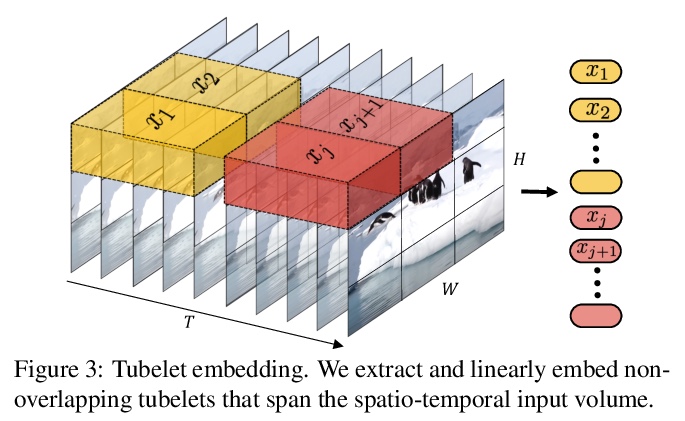
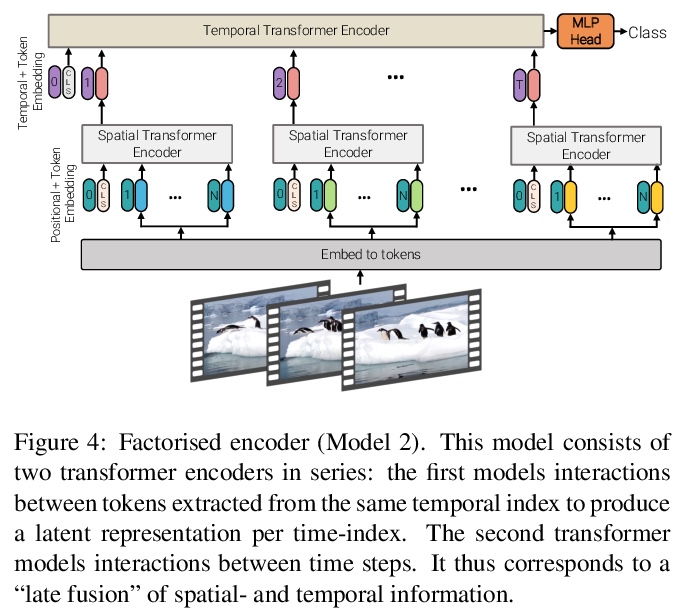
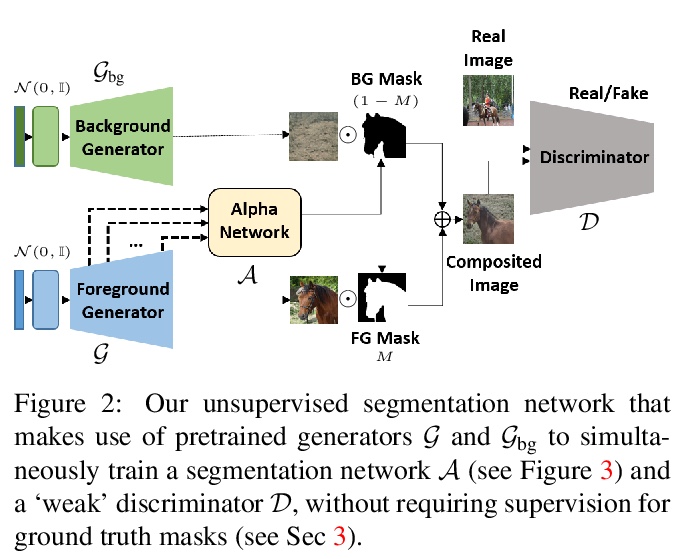
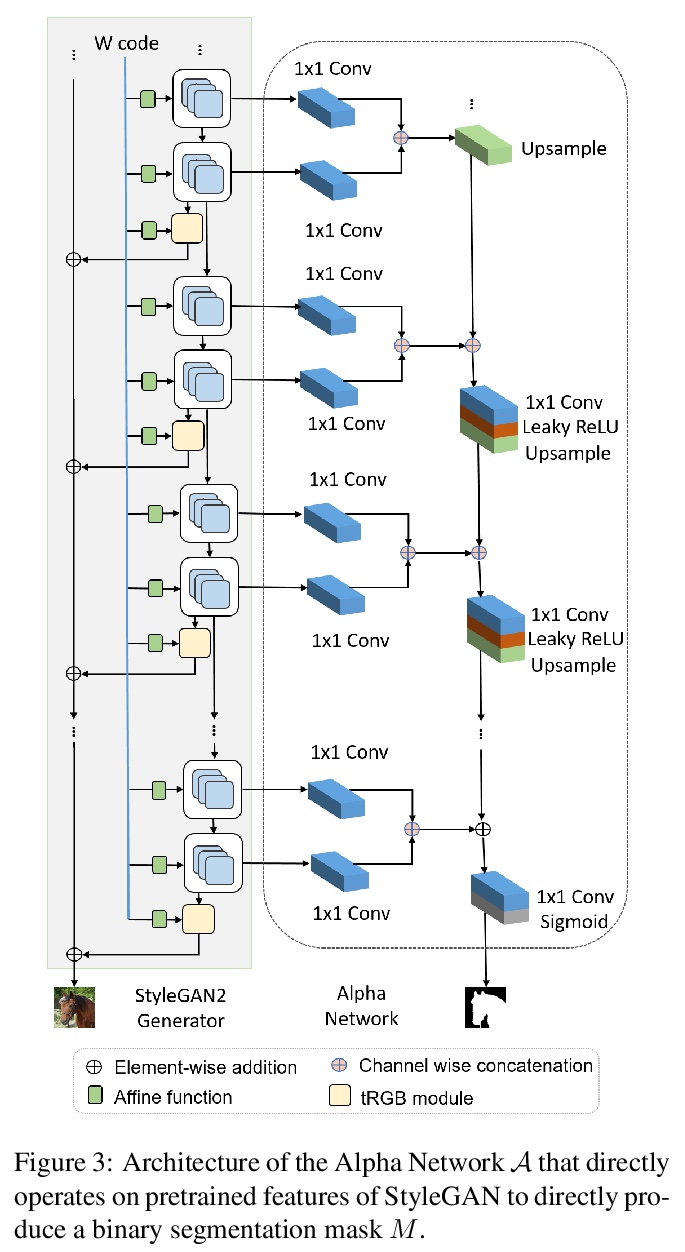
2、[CV] Labels4Free: Unsupervised Segmentation using StyleGAN
R Abdal, P Zhu, N Mitra, P Wonka
[KAUST & UCL]
Labels4Free:基于StyleGAN的无监督分割。提出一种无监督分割框架,将StyleGAN生成的图像分割成前景层和背景层。Labels4Free基于两个主要的观察:StyleGAN生成的特征包含宝贵的信息,可用来训练分割网络;前景和背景通常可被处理成很大程度上相互独立,并以不同方式组合。生成了面向分割的合成数据集,该框架可用来以无监督方式创建完整的带标记高质量GAN生成图像数据集,可用于训练其他最先进的分割网络,以产生引人注目的结果。
We propose an unsupervised segmentation framework for StyleGAN generated objects. We build on two main observations. First, the features generated by StyleGAN hold valuable information that can be utilized towards training segmentation networks. Second, the foreground and background can often be treated to be largely independent and be composited in different ways. For our solution, we propose to augment the StyleGAN2 generator architecture with a segmentation branch and to split the generator into a foreground and background network. This enables us to generate soft segmentation masks for the foreground object in an unsupervised fashion. On multiple object classes, we report comparable results against state-of-the-art supervised segmentation networks, while against the best unsupervised segmentation approach we demonstrate a clear improvement, both in qualitative and quantitative metrics.
https://weibo.com/1402400261/K8FVOsVPk

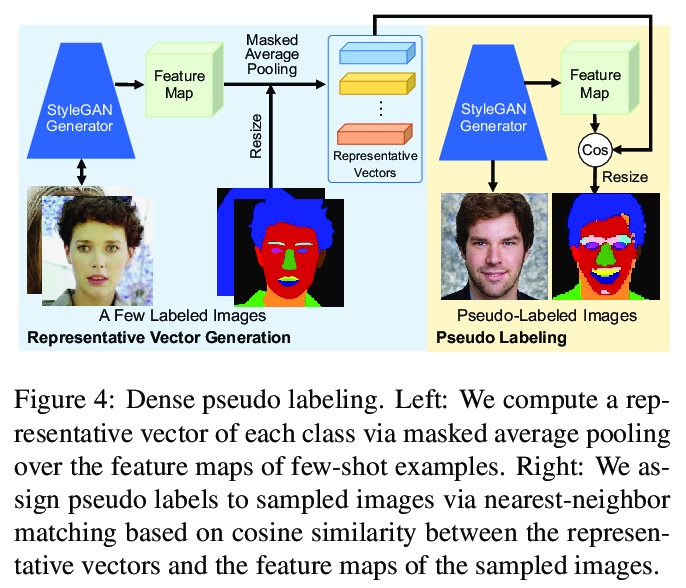
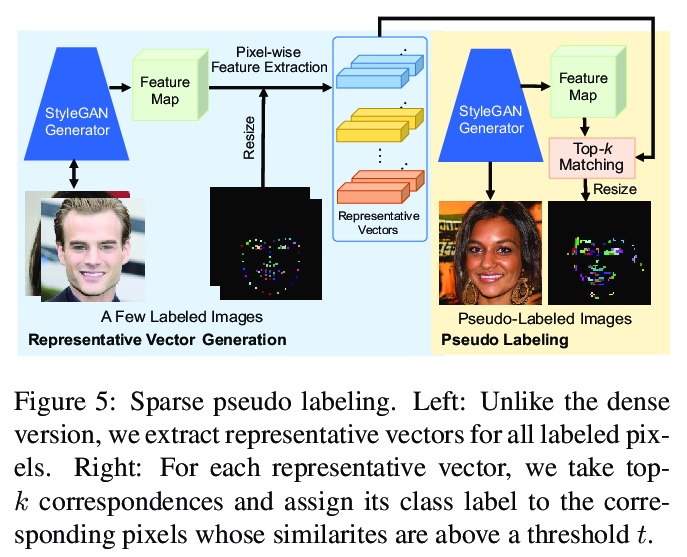
3、[CV] Few-shot Semantic Image Synthesis Using StyleGAN Prior
Y Endo, Y Kanamori
[University of Tsukuba]
基于StyleGAN先验的少样本语义图像合成方法。探索了一种新的少样本语义图像合成问题,用户甚至可从训练过程中提供的极少且粗糙的语义布局中合成高质量的目标域各种图像。提出一种简单有效的方法,通过基于StyleGAN先验的伪采样和标记,在无需复杂损失函数的超参数调整的情况下,训练StyleGAN编码器用于少样本场景下的语义图像合成。通过在各种数据集上的大量实验,证明了该方法在布局保真度和视觉质量上明显优于现有方法。
This paper tackles a challenging problem of generating photorealistic images from semantic layouts in few-shot scenarios where annotated training pairs are hardly available but pixel-wise annotation is quite costly. We present a training strategy that performs pseudo labeling of semantic masks using the StyleGAN prior. Our key idea is to construct a simple mapping between the StyleGAN feature and each semantic class from a few examples of semantic masks. With such mappings, we can generate an unlimited number of pseudo semantic masks from random noise to train an encoder for controlling a pre-trained StyleGAN generator. Although the pseudo semantic masks might be too coarse for previous approaches that require pixel-aligned masks, our framework can synthesize high-quality images from not only dense semantic masks but also sparse inputs such as landmarks and scribbles. Qualitative and quantitative results with various datasets demonstrate improvement over previous approaches with respect to layout fidelity and visual quality in as few as one- or five-shot settings.
https://weibo.com/1402400261/K8G1w96o2
4、[CV] CvT: Introducing Convolutions to Vision Transformers
H Wu, B Xiao, N Codella, M Liu, X Dai, L Yuan, L Zhang
[McGill University & Microsoft Cloud + AI]
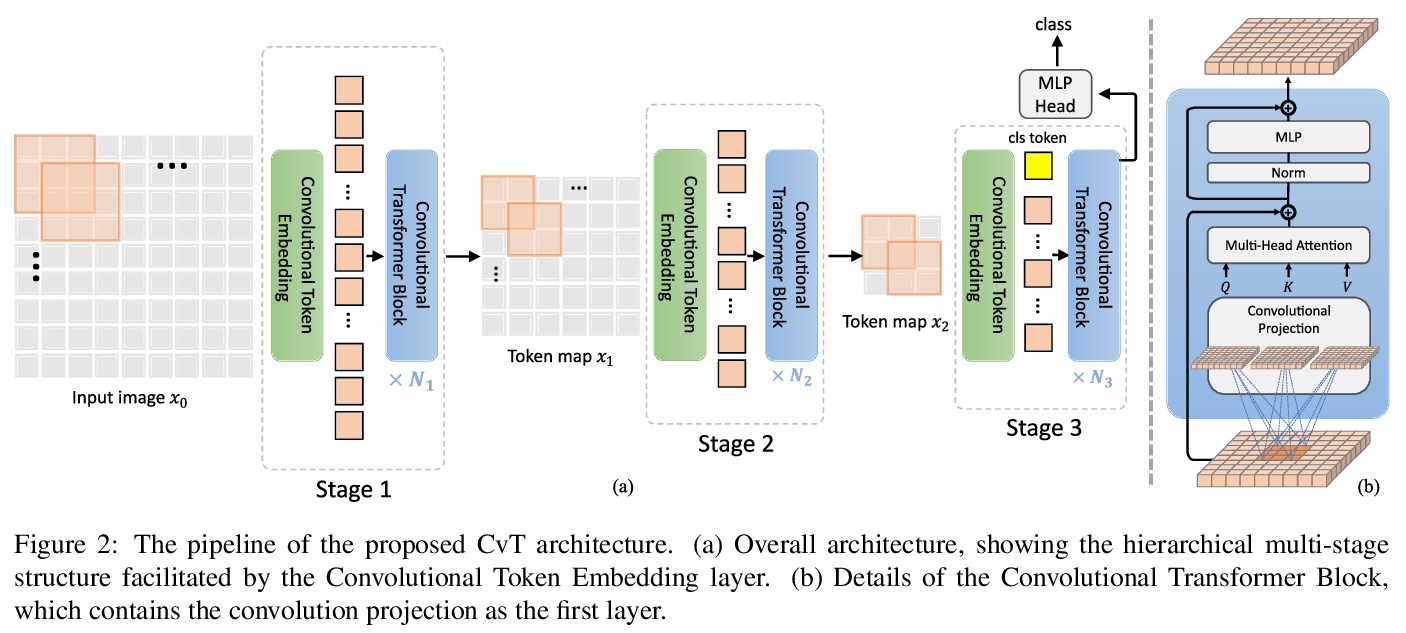
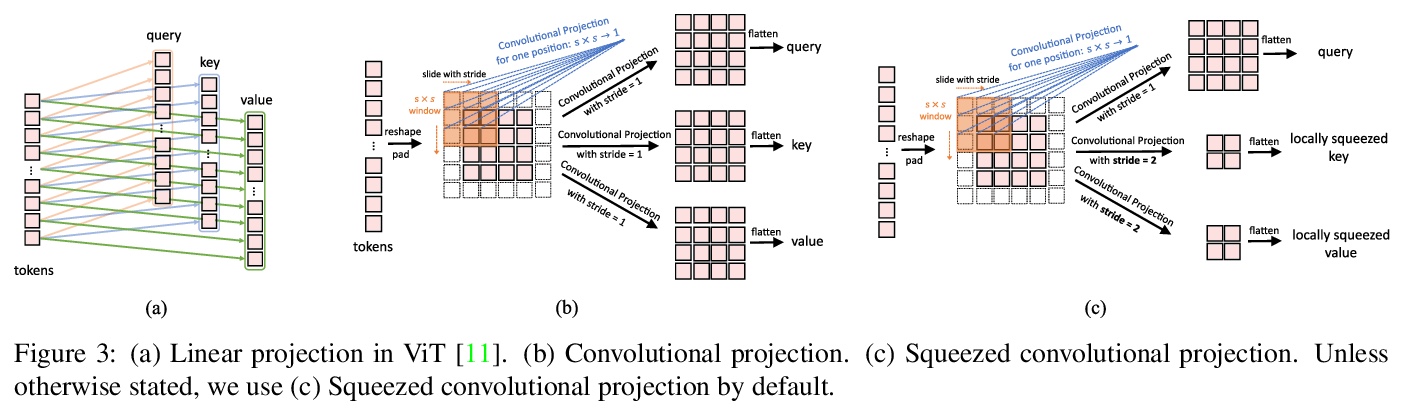
CvT: 将卷积引入视觉Transformer。提出一种新架构——卷积视觉Transformer(CvT),通过将卷积引入到视觉Transformer中,结合Transformer和CNN的优点,提高视觉Transformer(ViT)的性能和效率,产生最佳效果。通过两个主要修改来实现:一种包含新的卷积token嵌入的Transformer架构,以及一种利用卷积投影的卷积Transformer块。这些改变将CNNs的理想特性引入到ViT架构中(即移位、规模和失真不变性),同时保持了Transformer的优点(即动态注意力、全局上下文和更好的泛化)。
We present in this paper a new architecture, named Convolutional vision Transformer (CvT), that improves Vision Transformer (ViT) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs. This is accomplished through two primary modifications: a hierarchy of Transformers containing a new convolutional token embedding, and a convolutional Transformer block leveraging a convolutional projection. These changes introduce desirable properties of convolutional neural networks (CNNs) to the ViT architecture (\ie shift, scale, and distortion invariance) while maintaining the merits of Transformers (\ie dynamic attention, global context, and better generalization). We validate CvT by conducting extensive experiments, showing that this approach achieves state-of-the-art performance over other Vision Transformers and ResNets on ImageNet-1k, with fewer parameters and lower FLOPs. In addition, performance gains are maintained when pretrained on larger datasets (\eg ImageNet-22k) and fine-tuned to downstream tasks. Pre-trained on ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding, a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks. Code will be released at > this https URL.
https://weibo.com/1402400261/K8G3OlloY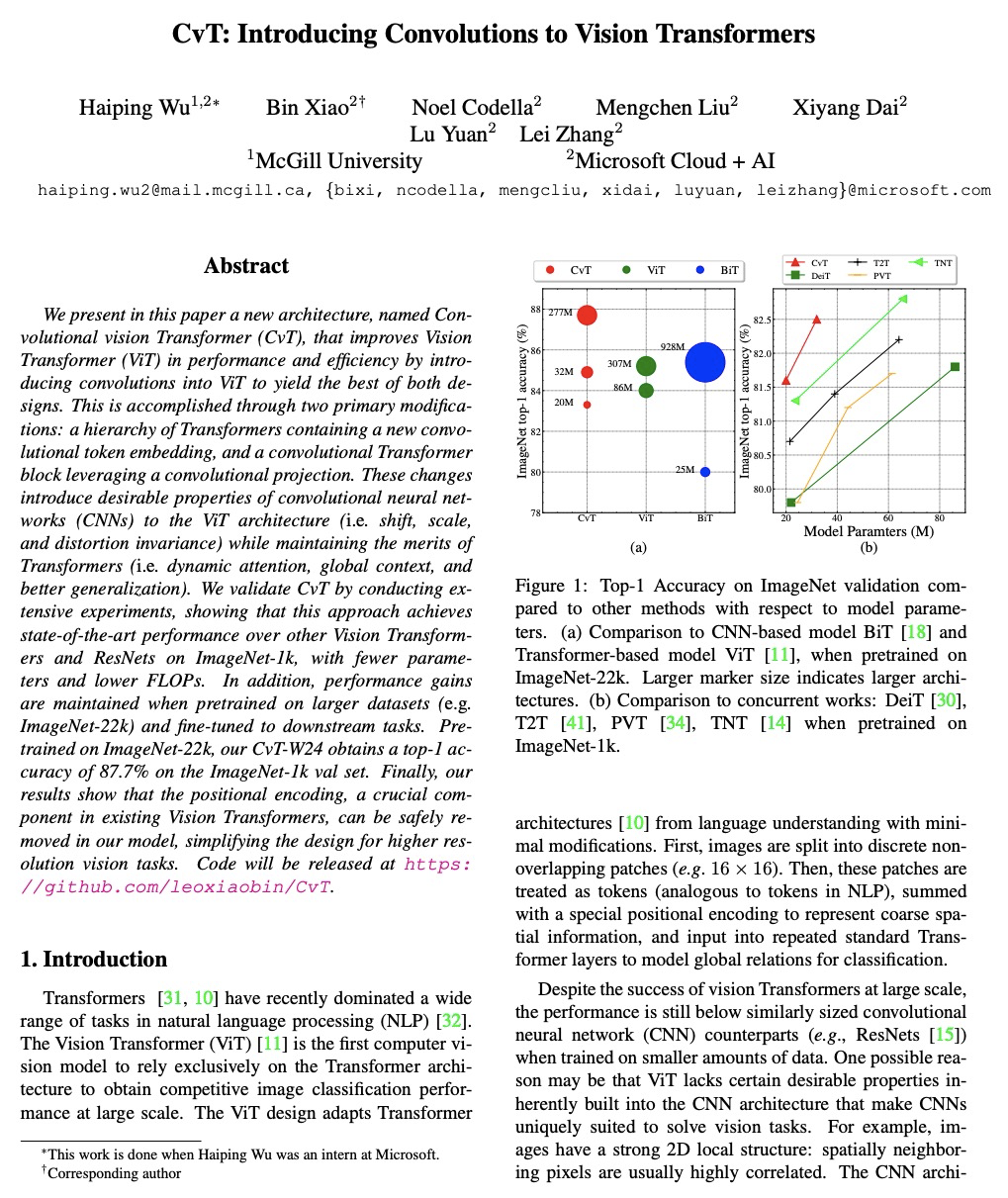
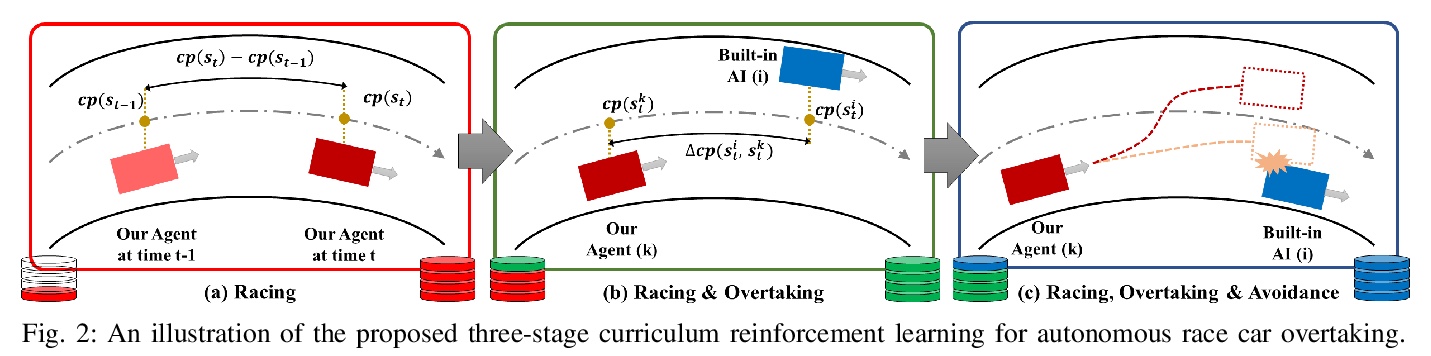
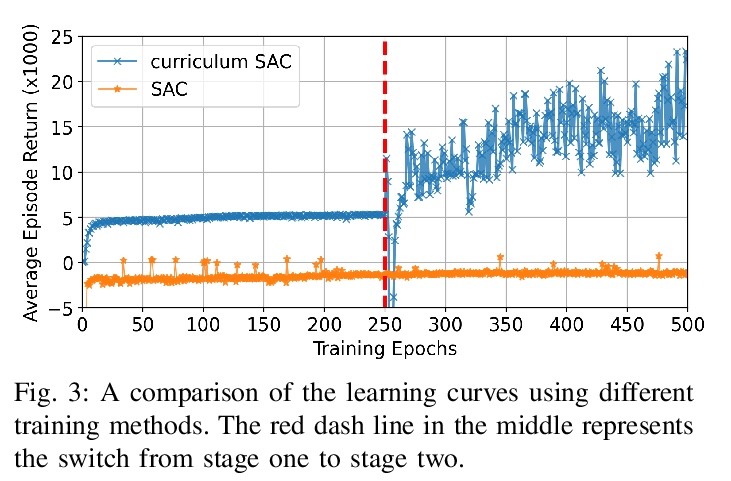
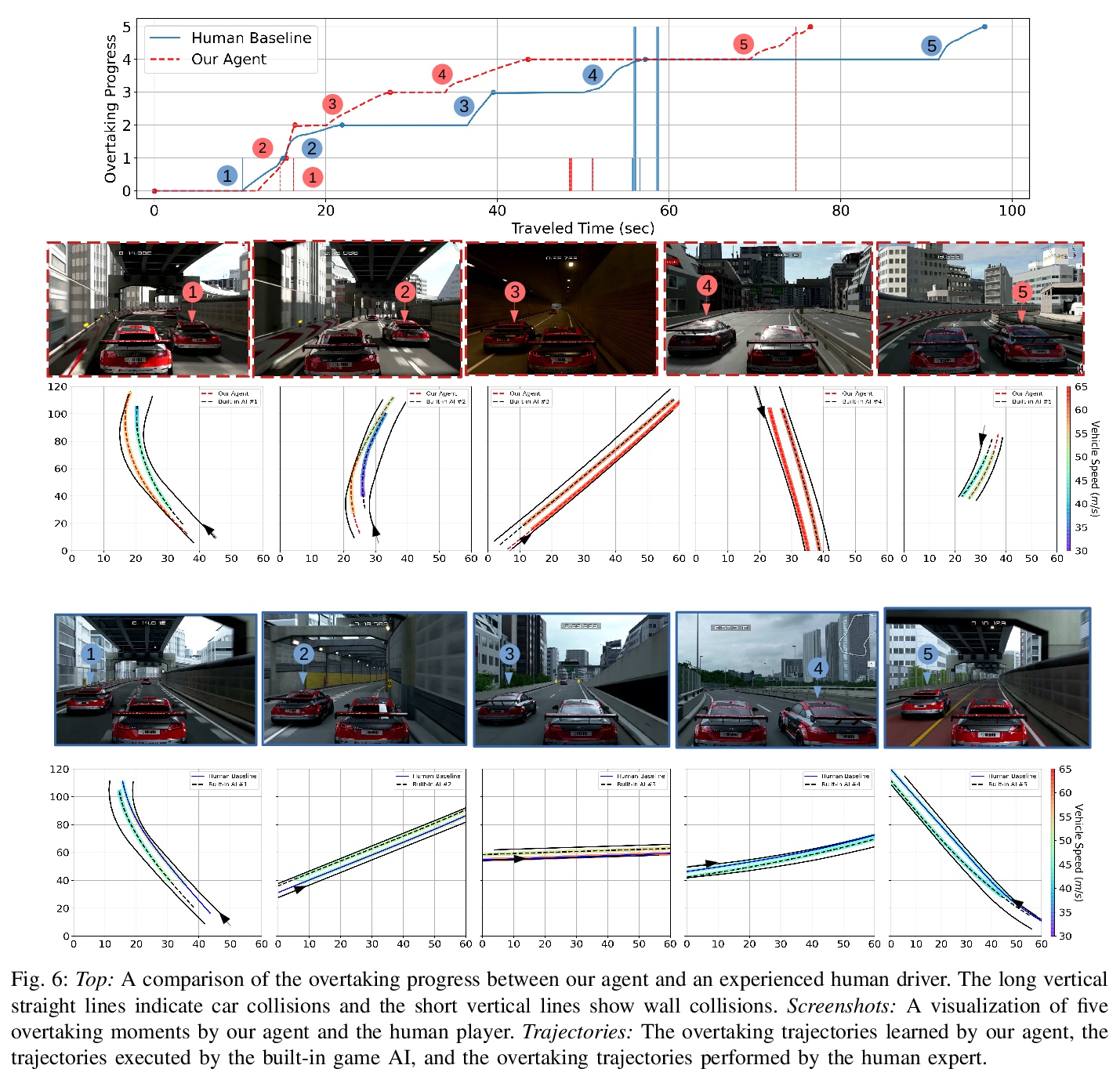
5、[RO] Autonomous Overtaking in Gran Turismo Sport Using Curriculum Reinforcement Learning
Y Song, H Lin, E Kaufmann, P Duerr, D Scaramuzza
[University of Zurich & ETH Zurich & Sony AI Zurich]
基于课程强化学习在赛车游戏”Gran Turismo Sport”中自主超车。提出一种新的基于学习的方法来解决自主超车问题,在以对各种车辆和赛道进行详细建模而闻名的热门赛车游戏”Gran Turismo Sport”中,对该方法进行了评估。通过利用课程学习,该方法与一般强化学习相比,不仅提高了性能,还加快了收敛速度。经过训练的控制器的性能,超过了基于模型的内置游戏AI,实现了与经验丰富的人类驾驶员相当的超车性能。
Professional race car drivers can execute extreme overtaking maneuvers. However, conventional systems for autonomous overtaking rely on either simplified assumptions about the vehicle dynamics or solving expensive trajectory optimization problems online. When the vehicle is approaching its physical limits, existing model-based controllers struggled to handle highly nonlinear dynamics and cannot leverage the large volume of data generated by simulation or real-world driving. To circumvent these limitations, this work proposes a new learning-based method to tackle the autonomous overtaking problem. We evaluate our approach using Gran Turismo Sport — a world-leading car racing simulator known for its detailed dynamic modeling of various cars and tracks. By leveraging curriculum learning, our approach leads to faster convergence as well as increased performance compared to vanilla reinforcement learning. As a result, the trained controller outperforms the built-in model-based game AI and achieves comparable overtaking performance with an experienced human driver.
https://weibo.com/1402400261/K8G7vA1lX
另外几篇值得关注的论文:
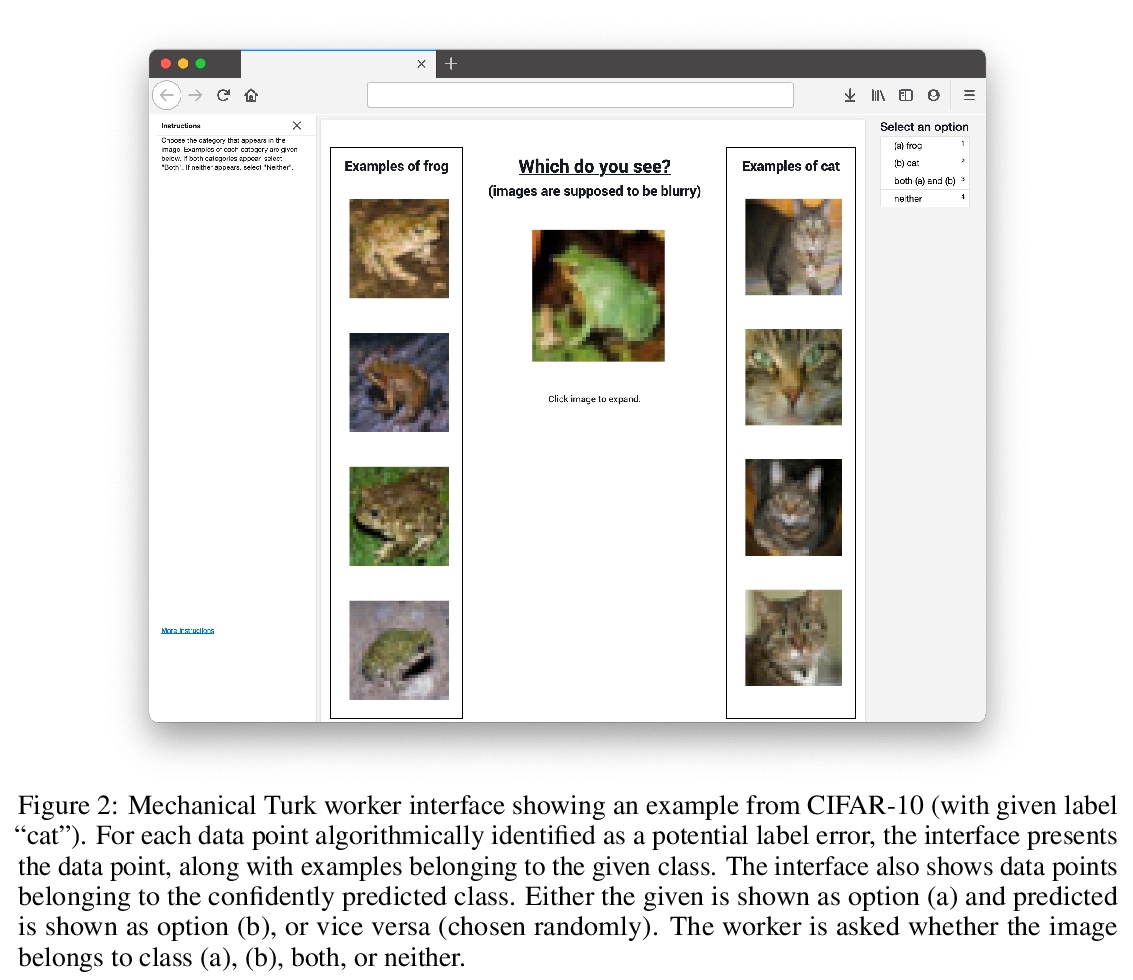
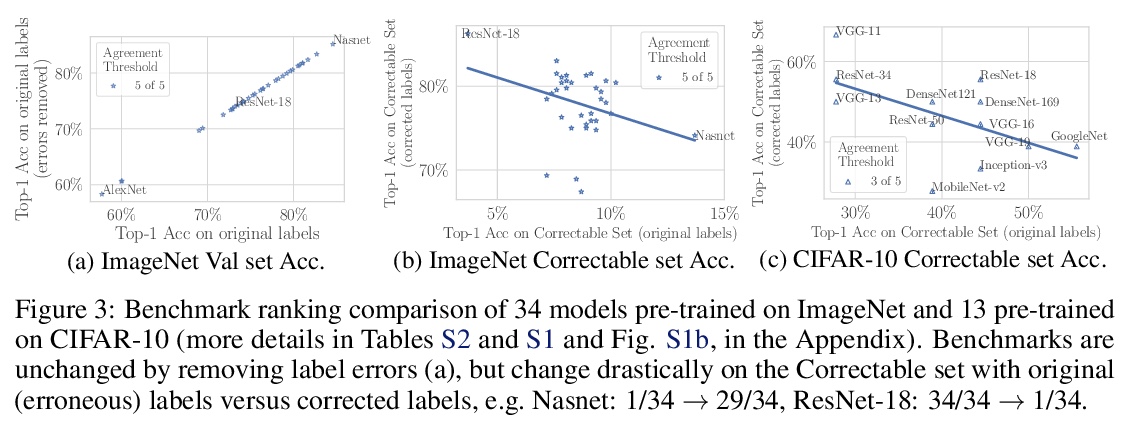
[LG] Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
测试集中普遍存在的标注错误破坏了机器学习基准的稳定性
C G. Northcutt, A Athalye, J Mueller
[ChipBrain & MIT & Amazon]
https://weibo.com/1402400261/K8Ga1Bcqi

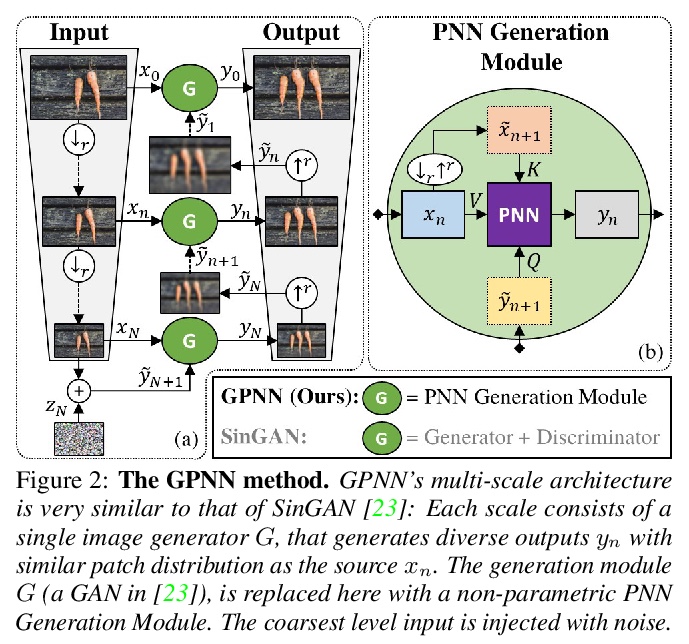
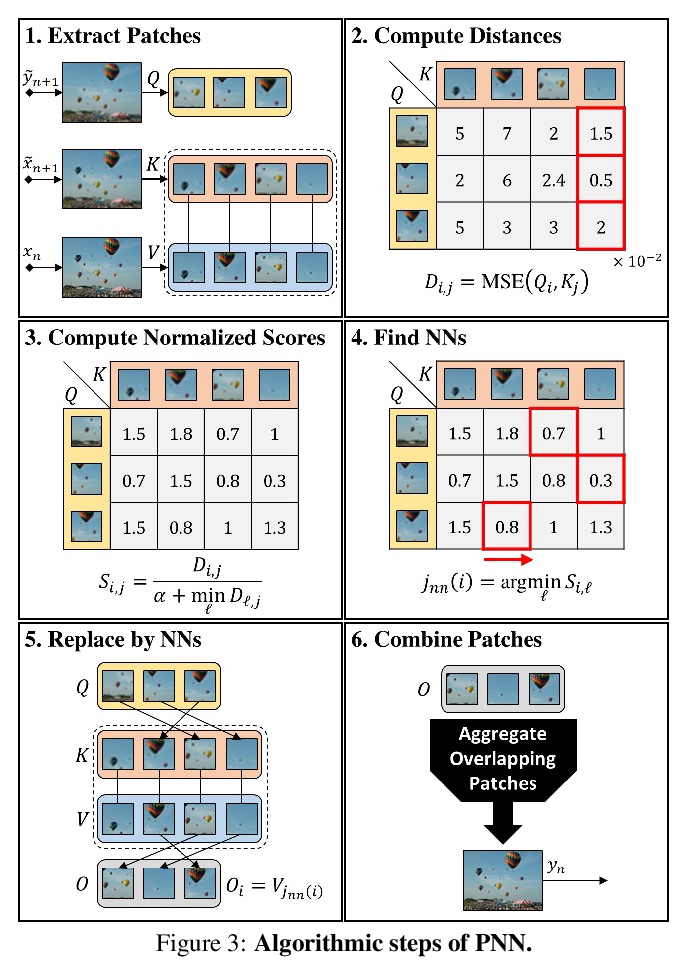
[CV] Drop the GAN: In Defense of Patches Nearest Neighbors as Single Image Generative Models
用基于图块-最近邻的单图像生成模型挑战GAN
N Granot, A Shocher, B Feinstein, S Bagon, M Irani
[The Weizmann Institute of Science & Weizmann Artificial Intelligence Center (WAIC)]
https://weibo.com/1402400261/K8GchDRS3

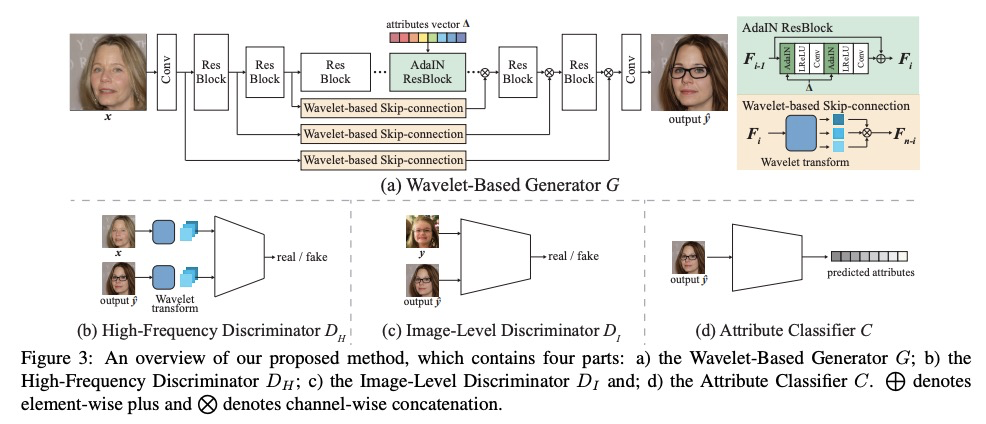
[CV] High-Fidelity and Arbitrary Face Editing
高保真任意人脸编辑
Y Gao, F Wei, J Bao, S Gu, D Chen, F Wen, Z Lian
[Peking University & Microsoft Research Asia & University of Science and Technology of China]
https://weibo.com/1402400261/K8Ggbr8V9


[CV] NeMI: Unifying Neural Radiance Fields with Multiplane Images for Novel View Synthesis
NeMI:将神经辐射场与多平面图像统一用于新视图合成
J Li, Z Feng, Q She, H Ding, C Wang, G H Lee
[ByteDance & National University of Singapore]
https://weibo.com/1402400261/K8GjaoJtL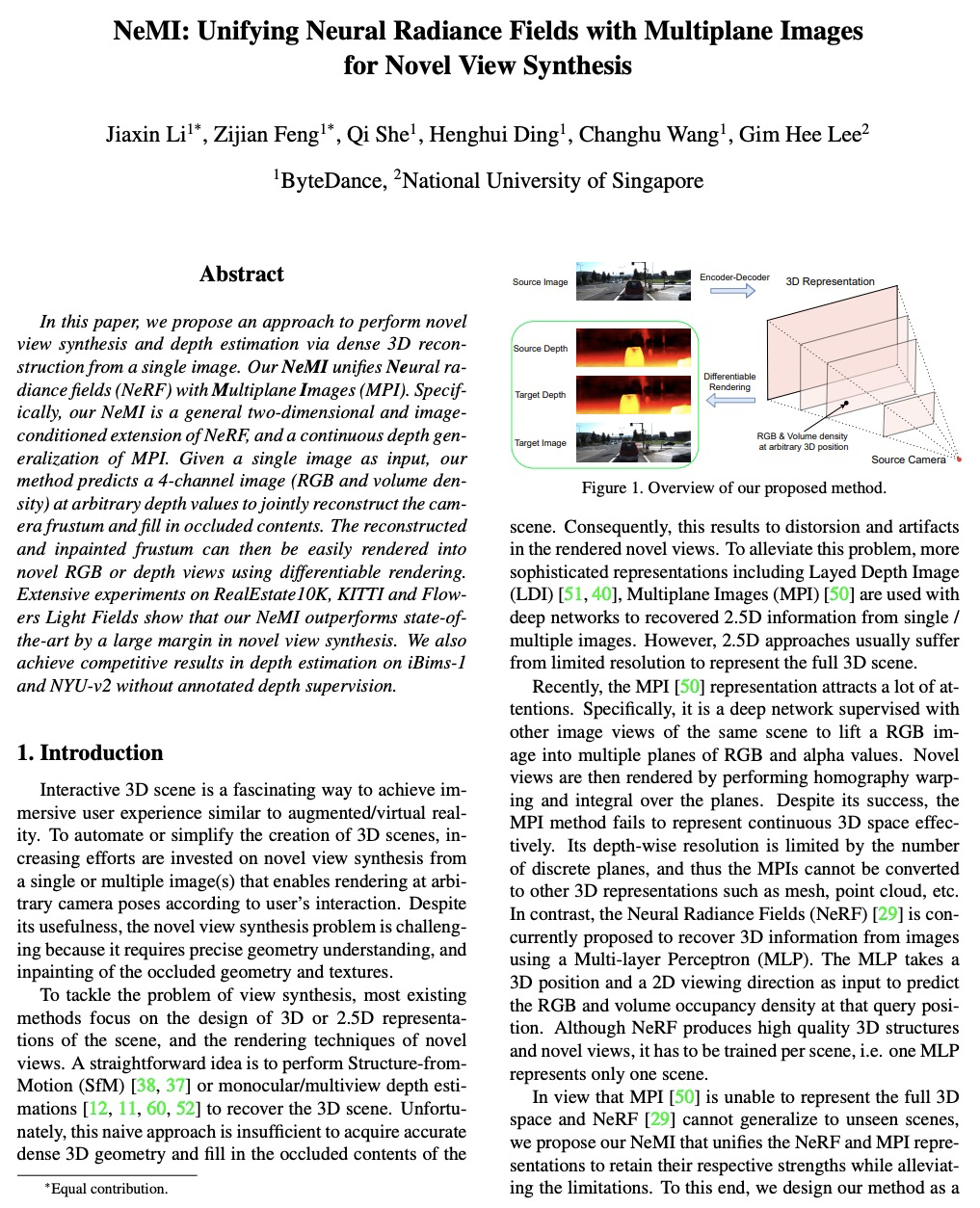



若有收获,就点个赞吧
0 人点赞
