LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] *Score-Based Generative Modeling through Stochastic Differential Equations
Y Song, J Sohl-Dickstein, D P. Kingma, A Kumar, S Ermon, B Poole
[Stanford University & Google Brain]
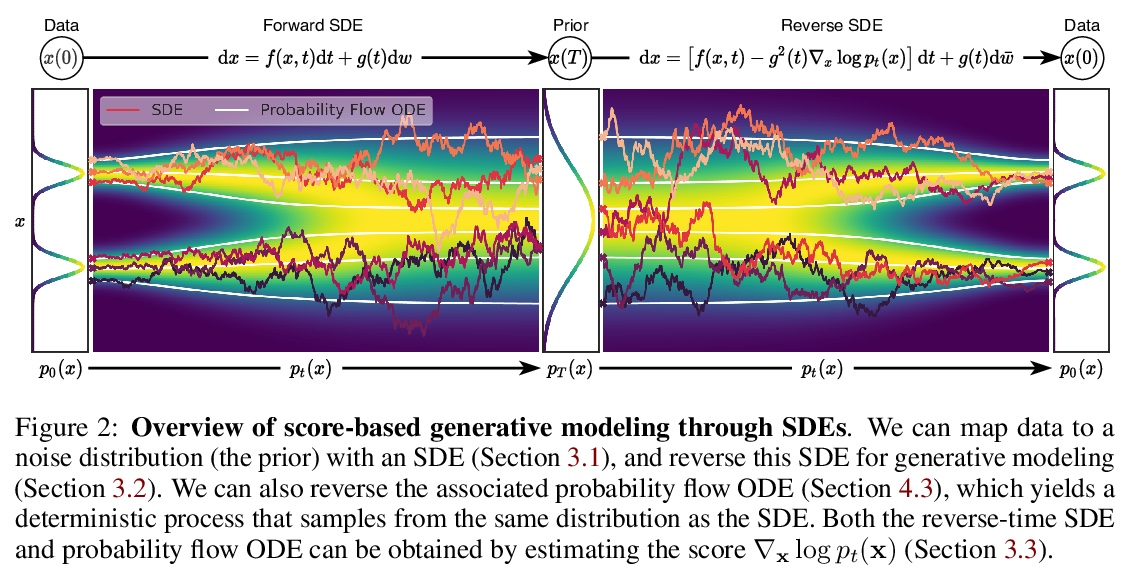
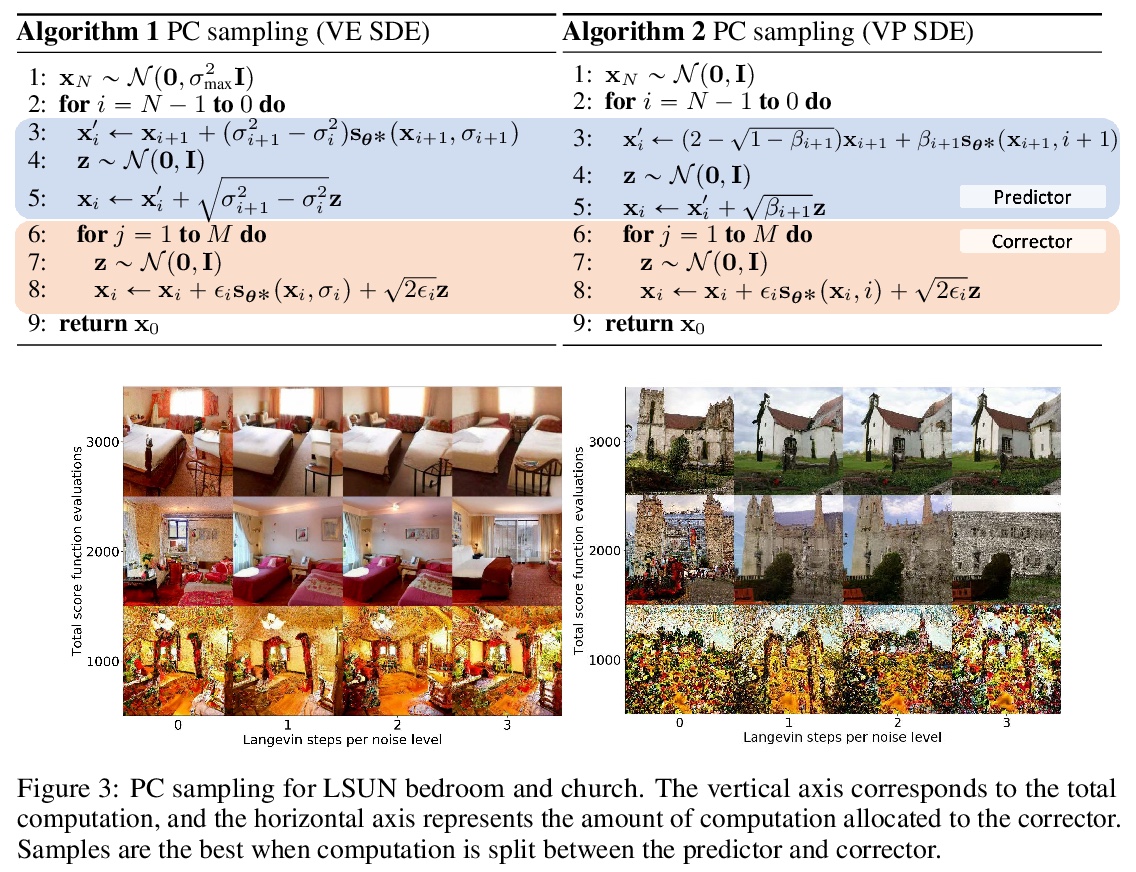
基于随机微分方程的分数生成式建模。提出基于随机微分方程(SDEs)的分数式生成模型框架,SDE通过缓慢注入噪声平稳地将一个复杂的数据分布转换为一个已知的先验分布,相应的逆时SDE通过缓慢去除噪声将先验分布转换回数据分布。逆时SDE只依赖于扰动数据分布随时间变化的梯度场(分数),引入了预测-校正框架来纠正离散逆时SDE演化中的错误,推导了与SDE相同的分布采样的等效神经ODE,使精确的似然计算成为可能,并提高了采样效率。
Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (a.k.a., score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in diffusion probabilistic modeling and score-based generative modeling, and allows for new sampling procedures. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, which enables exact likelihood computation, and improved sampling efficiency. In addition, our framework enables conditional generation with an unconditional model, as we demonstrate with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 3.10 bits/dim, and demonstrate high fidelity generation of > 1024×1024 images for the first time from a score-based generative model.
https://weibo.com/1402400261/Jx9oqBS8m
2、**[LG] Inductive Biases for Deep Learning of Higher-Level Cognition
A Goyal, Y Bengio
[University of Montreal]
高层次认知深度学习的归纳偏差。为了处理动态的、不断变化的条件,需要从能执行系统1任务的深度统计模型,转移到能通过利用系统1能力的计算力来执行系统2任务的深度结构化模型。如今的深度网络可能得益于额外的结构和归纳偏差,从而在系统2任务、自然语言理解、非分布系统泛化和高效迁移学习方面表现得更好。本文试图澄清这些归纳偏差可能是什么,但还需要做很多工作来提高对这些偏差的理解,并找到适当的方法将这些先验纳入神经结构和训练框架中。*
A fascinating hypothesis is that human and animal intelligence could be explained by a few principles (rather than an encyclopedic list of heuristics). If that hypothesis was correct, we could more easily both understand our own intelligence and build intelligent machines. Just like in physics, the principles themselves would not be sufficient to predict the behavior of complex systems like brains, and substantial computation might be needed to simulate human-like intelligence. This hypothesis would suggest that studying the kind of inductive biases that humans and animals exploit could help both clarify these principles and provide inspiration for AI research and neuroscience theories. Deep learning already exploits several key inductive biases, and this work considers a larger list, focusing on those which concern mostly higher-level and sequential conscious processing. The objective of clarifying these particular principles is that they could potentially help us build AI systems benefiting from humans’ abilities in terms of flexible out-of-distribution and systematic generalization, which is currently an area where a large gap exists between state-of-the-art machine learning and human intelligence.
https://weibo.com/1402400261/Jx9u0xDD9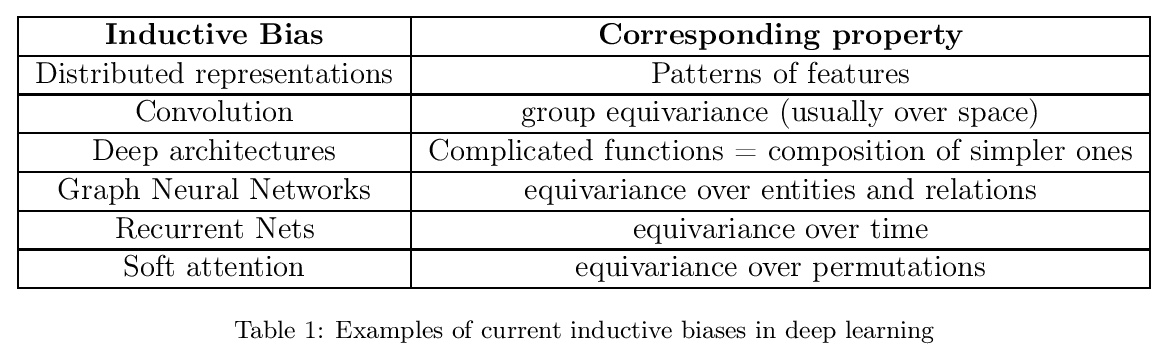
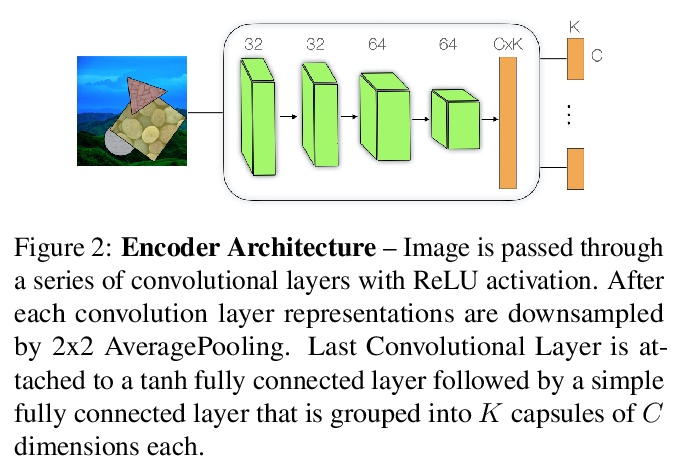
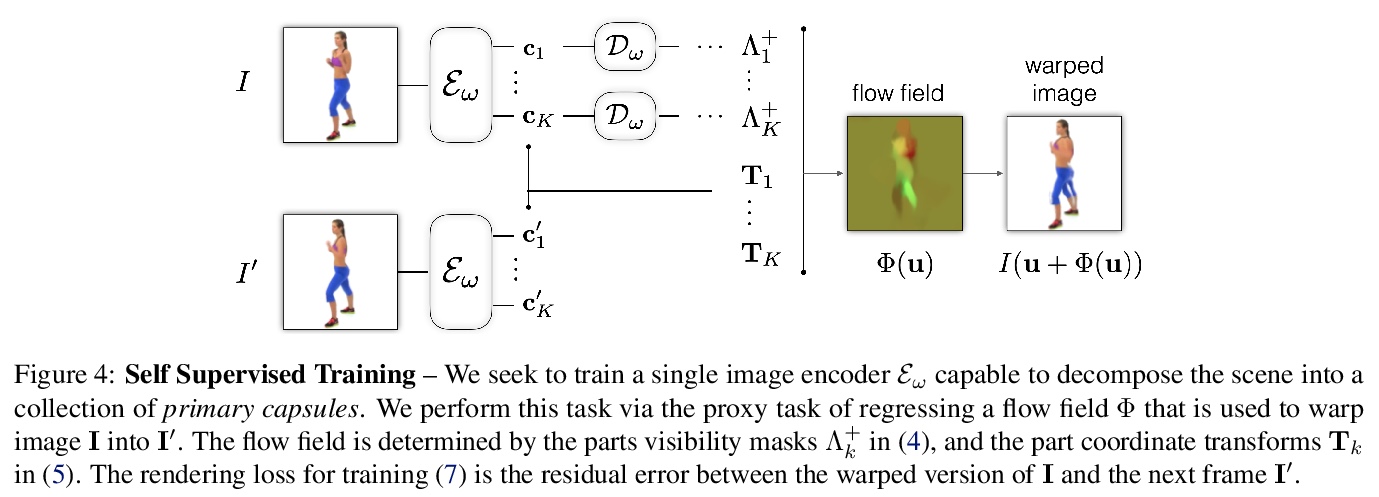
3、**[CV] Unsupervised part representation by Flow Capsules
S Sabour, A Tagliasacchi, S Yazdani, G E. Hinton, D J. Fleet
[University of Toronto & Google research]
流胶囊无监督部分表示。提出一种学习胶囊部分表示(主胶囊)的方法,称为流胶囊(FlowCapsules),用自监督方法学习图像的部分描述子。胶囊编码器以单帧作为输入,估计一组主胶囊,每个主胶囊包括标准坐标下的形状掩模、转换为图像坐标的位姿和相对深度信息。对视频连续帧以自监督方式进行训练,用运动作为部分定义的感知线索,用表达式解码器实现部分生成和带遮挡的分层图像形成。得到的部分描述子,即部分胶囊,结合单个图像上的相对深度,被解码成形状掩模,填充被遮挡像素。*
Capsule networks are designed to parse an image into a hierarchy of objects, parts and relations. While promising, they remain limited by an inability to learn effective low level part descriptions. To address this issue we propose a novel self-supervised method for learning part descriptors of an image. During training, we exploit motion as a powerful perceptual cue for part definition, using an expressive decoder for part generation and layered image formation with occlusion. Experiments demonstrate robust part discovery in the presence of multiple objects, cluttered backgrounds, and significant occlusion. The resulting part descriptors, a.k.a. part capsules, are decoded into shape masks, filling in occluded pixels, along with relative depth on single images. We also report unsupervised object classification using our capsule parts in a stacked capsule autoencoder.
https://weibo.com/1402400261/Jx9yH5ieh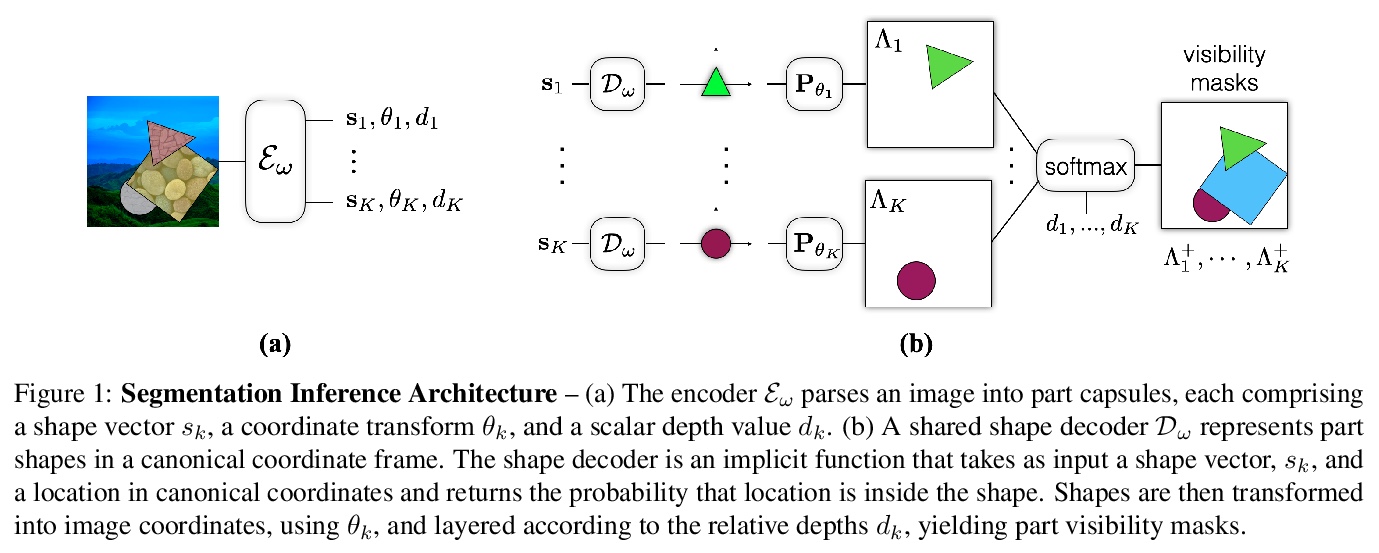
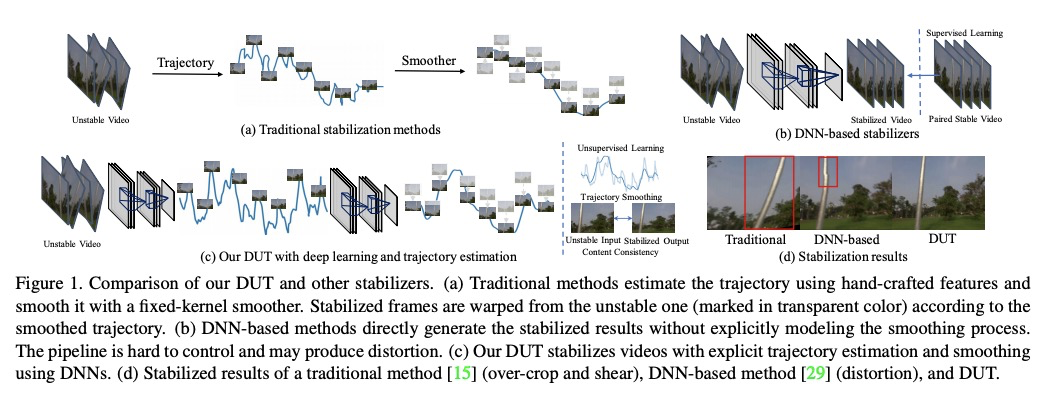
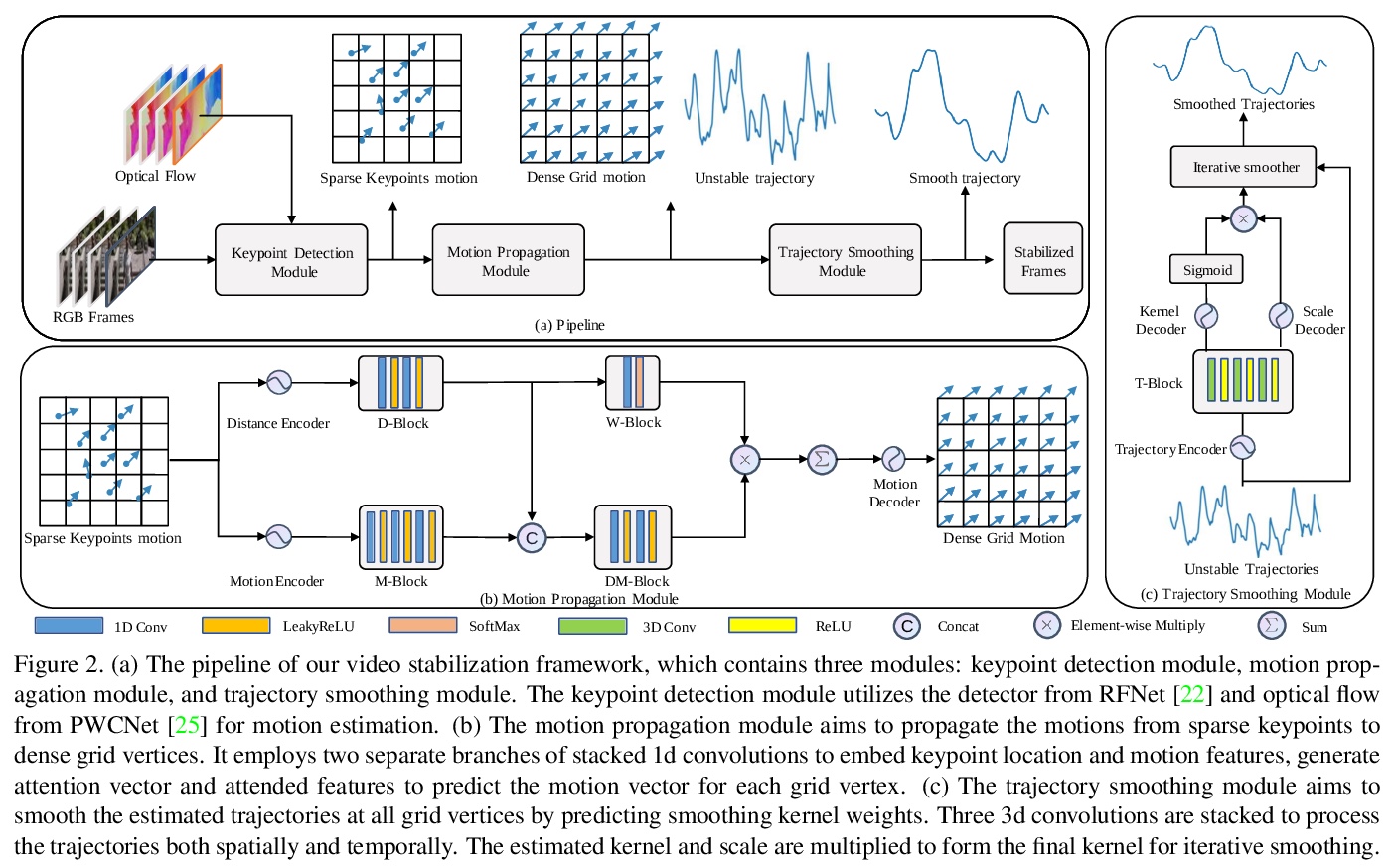
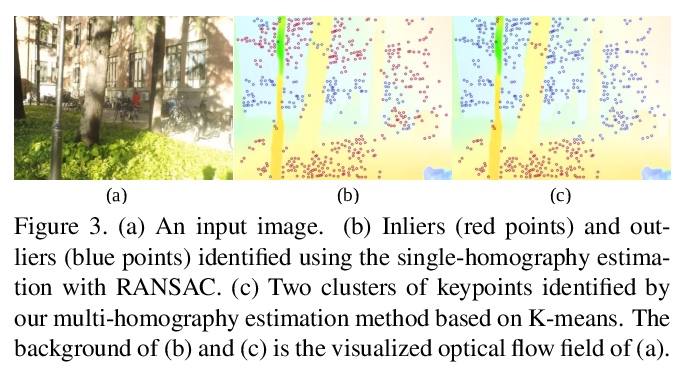
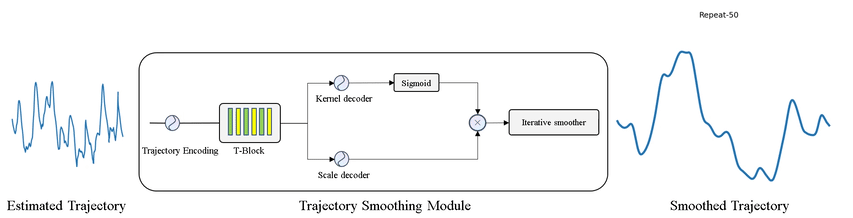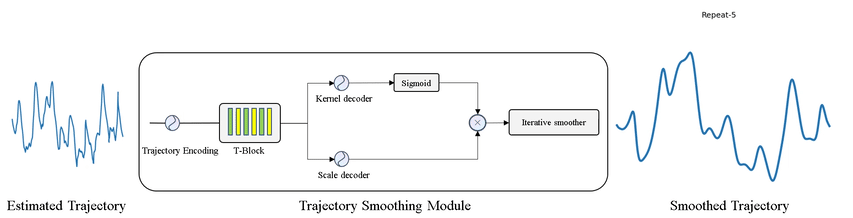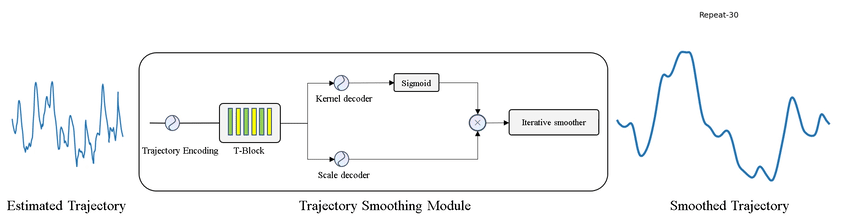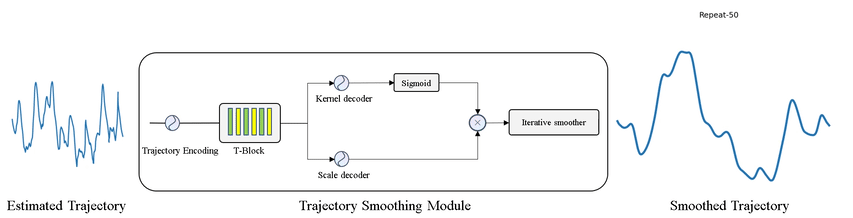
4、** **[CV] DUT: Learning Video Stabilization by Simply Watching Unstable Videos
Y Xu, J Zhang, S J. Maybank, D Tao
[The University of Sydney & Birkbeck College]
通过看不稳定视频来学习视频稳定。提出基于深度无监督轨迹的稳定框架(DUT),由深度学习关键点检测器和运动估计器来生成基于网格的轨迹,结合轨迹平滑器来稳定视频。DUT在继承深度网络可解释和可控制能力的同时,利用了深度网络的表示能力,与其他深度学习稳定器相比,其采用了运动传播网络和CNN平滑器,可以以无监督的方式进行训练,生成失真更小的稳定视频,在质量和性能上都优于具有代表性的最新方法。
We propose a Deep Unsupervised Trajectory-based stabilization framework (DUT) in this paper. Traditional stabilizers focus on trajectory-based smoothing, which is controllable but fragile in occluded and textureless cases regarding the usage of hand-crafted features. On the other hand, previous deep video stabilizers directly generate stable videos in a supervised manner without explicit trajectory estimation, which is robust but less controllable and the appropriate paired data are hard to obtain. To construct a controllable and robust stabilizer, DUT makes the first attempt to stabilize unstable videos by explicitly estimating and smoothing trajectories in an unsupervised deep learning manner, which is composed of a DNN-based keypoint detector and motion estimator to generate grid-based trajectories, and a DNN-based trajectory smoother to stabilize videos. We exploit both the nature of continuity in motion and the consistency of keypoints and grid vertices before and after stabilization for unsupervised training. Experiment results on public benchmarks show that DUT outperforms representative state-of-the-art methods both qualitatively and quantitatively.
https://weibo.com/1402400261/Jx9J3t6q3

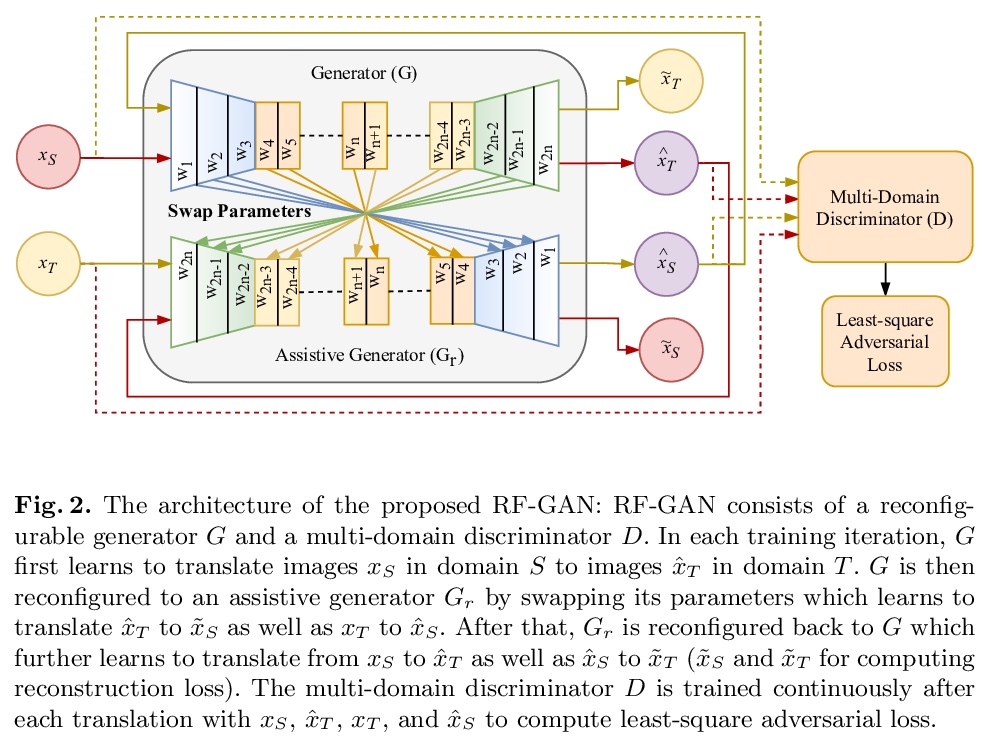
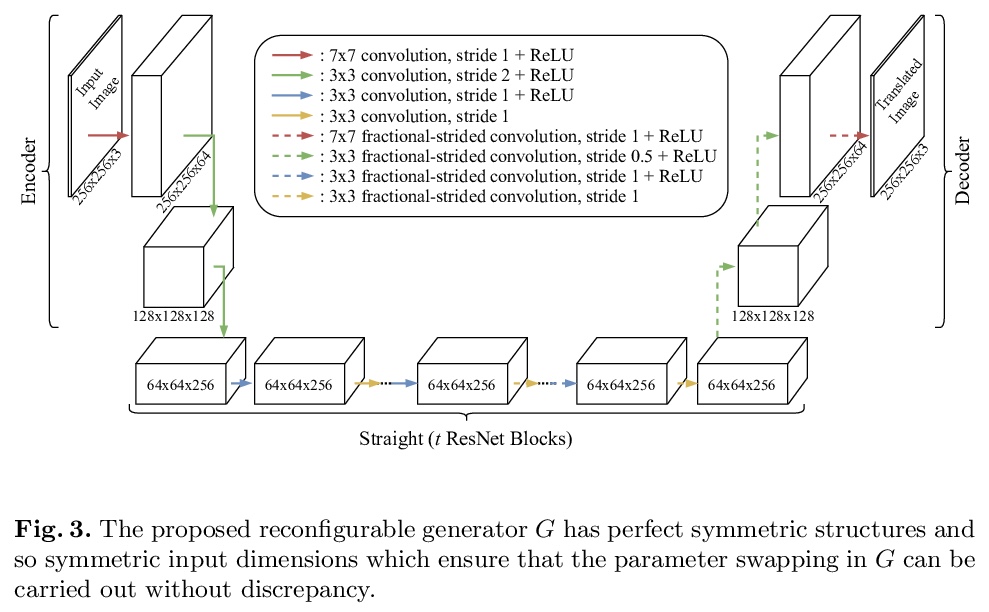
5、**[CV] RF-GAN: A Light and Reconfigurable Network for Unpaired Image-to-Image Translation
A Koksal, S Lu
[A*Star & Nanyang Technological University]
RF-GAN:用于未配对图-图转换的轻量可重构网络。提出一种体积小但能实现图像变换的可重构GAN(RF-GAN)。与之前模型更大、网络参数更多的最先进的变换用GANs不同,RF-GAN学习单独的可重构生成器,可通过交换参数实现双向变换,包含多域鉴别器,可实现双向鉴别,无需领域特定鉴别器或额外分类器。与最先进的变换GANs相比,RF-GAN的模型大小减少了75%,在8个数据集上的实验证明了其优越的性能。**
Generative adversarial networks (GANs) have been widely studied for unpaired image-to-image translation in recent years. On the other hand, state-of-the-art translation GANs are often constrained by large model sizes and inflexibility in translating across various domains. Inspired by the observation that the mappings between two domains are often approximately invertible, we design an innovative reconfigurable GAN (RF-GAN) that has a small size but is versatile in high-fidelity image translation either across two domains or among multiple domains. One unique feature of RF-GAN lies with its single generator which is reconfigurable and can perform bidirectional image translations by swapping its parameters. In addition, a multi-domain discriminator is designed which allows joint discrimination of original and translated samples in multiple domains. Experiments over eight unpaired image translation datasets (on various tasks such as object transfiguration, season transfer, and painters’ style transfer, etc.) show that RF-GAN reduces the model size by up to 75% as compared with state-of-the-art translation GANs but produces superior image translation performance with lower Fr´echet Inception Distance consistently.
https://weibo.com/1402400261/Jx9QOf8RU
另外几篇值得关注的论文:
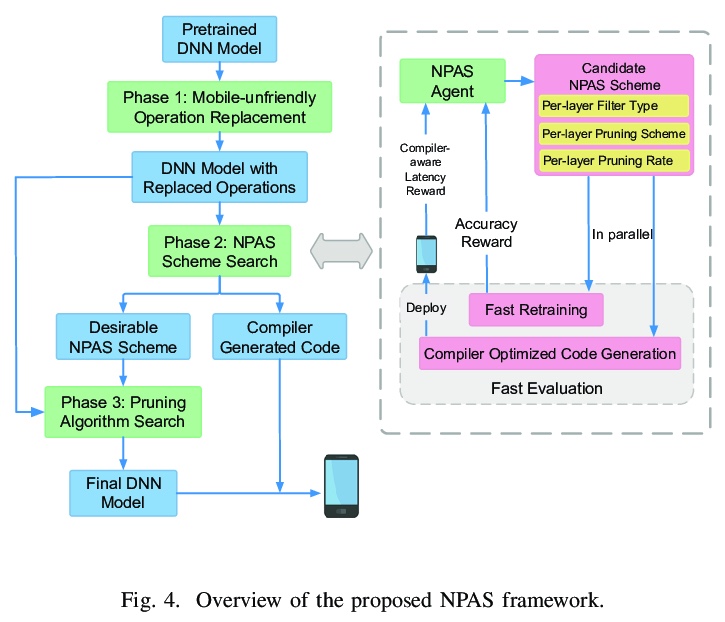
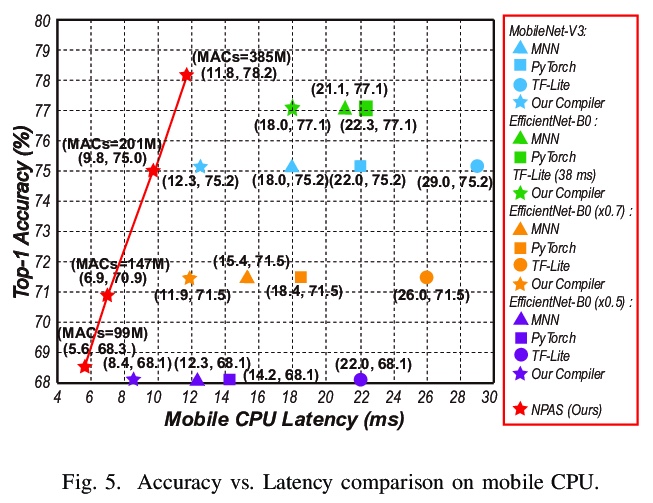
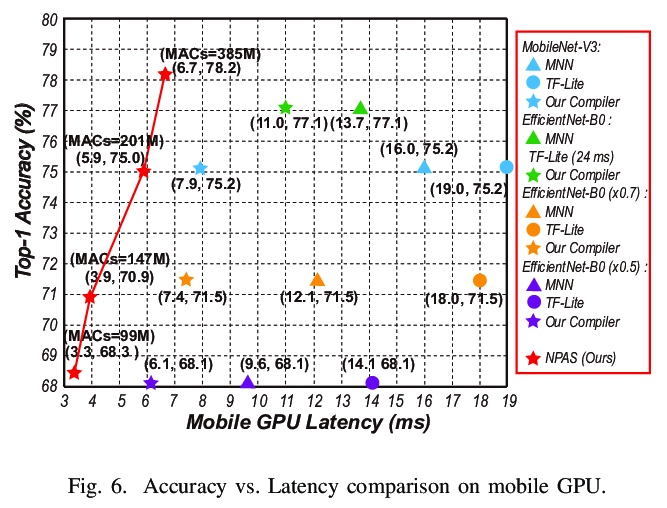
[LG] 6.7ms on Mobile with over 78% ImageNet Accuracy: Unified Network Pruning and Architecture Search for Beyond Real-Time Mobile Acceleration
手机端ImageNet的6.7毫秒延迟/78%+准确率:基于统一网络修剪和架构搜索的实时移动端加速
Z Li, G Yuan, W Niu, Y Li, P Zhao, Y Cai, X Shen, Z Zhan, Z Kong, Q Jin, Z Chen, S Liu, K Yang, B Ren, Y Wang, X Lin
[Northeastern University & College of William and Mary & Rice University & MIT-IBM Watson AI Lab]
https://weibo.com/1402400261/Jx9VUrRbH
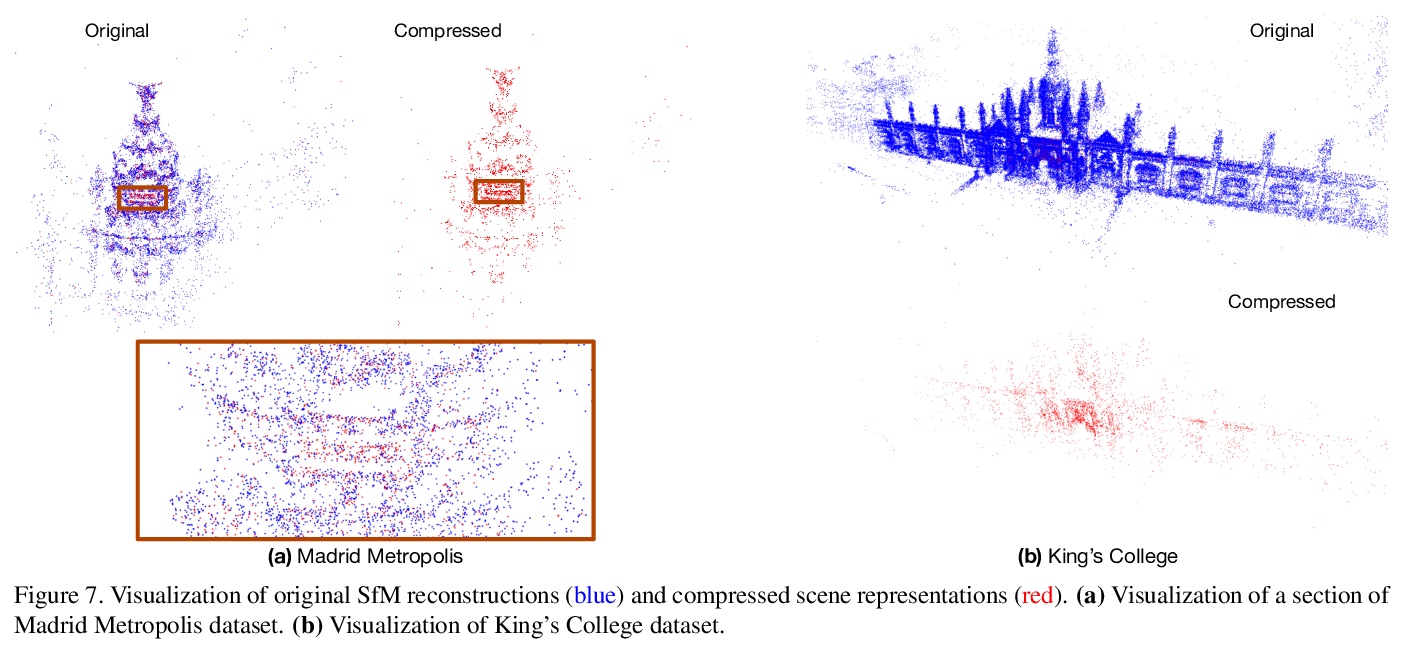
[CV] Efficient Scene Compression for Visual-based Localization
基于视觉定位的高效场景压缩
M Mera-Trujillo, B Smith, V Fragoso
[West Virginia University & Microsoft]
https://weibo.com/1402400261/Jx9YECSbe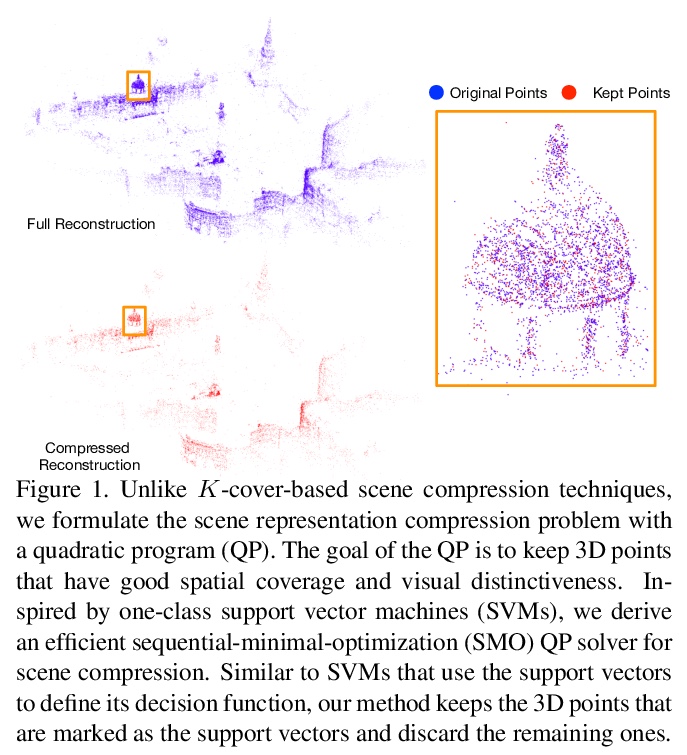
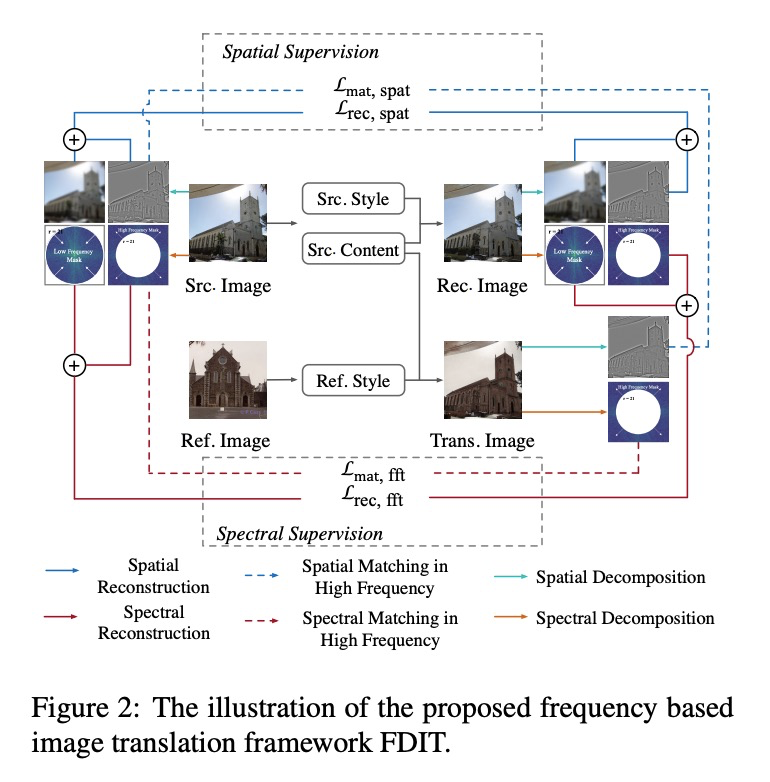
[CV] Frequency Domain Image Translation: More Photo-realistic, Better Identity-preserving
频域图像变换:更逼真的照片,更好的身份保护
M Cai, H Zhang, H Huang, Q Geng, G Huang
[University of Wisconsin-Madison & Kwai Inc & Beihang University & Tsinghua University]
https://weibo.com/1402400261/Jxa2q6xuU
[CL] Language Through a Prism: A Spectral Approach for Multiscale Language Representations
透过棱镜的语言:多尺度语言表示的谱方法
A Tamkin, D Jurafsky, N Goodman
[Stanford University]
https://weibo.com/1402400261/Jxa44iEL9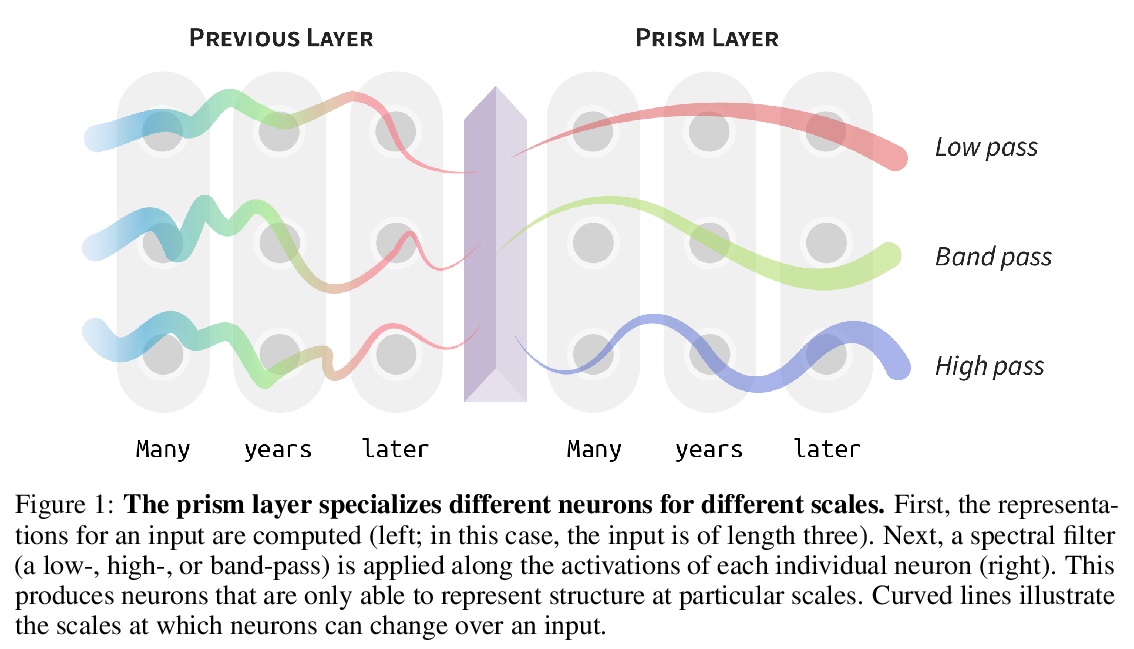

若有收获,就点个赞吧
0 人点赞
