- 1、[CV] VOGUE: Try-On by StyleGAN Interpolation Optimization
- 2、[CV] Who’s a Good Boy? Reinforcing Canine Behavior using Machine Learning in Real-Time
- 3、[LG] Coding for Distributed Multi-Agent Reinforcement Learning
- 4、[CV] PandaNet : Anchor-Based Single-Shot Multi-Person 3D Pose Estimation
- 5、[CV] VisualVoice: Audio-Visual Speech Separation with Cross-Modal Consistency
- [LG] SE(3)-Equivariant Graph Neural Networks for Data-Efficient and Accurate Interatomic Potentials
- [CV] InMoDeGAN: Interpretable Motion Decomposition Generative Adversarial Network for Video Generation
- [CV] One-Class Classification: A Survey
- [AS] Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] VOGUE: Try-On by StyleGAN Interpolation Optimization
K M Lewis, S Varadharajan, I Kemelmacher-Shlizerman
[Google Research]
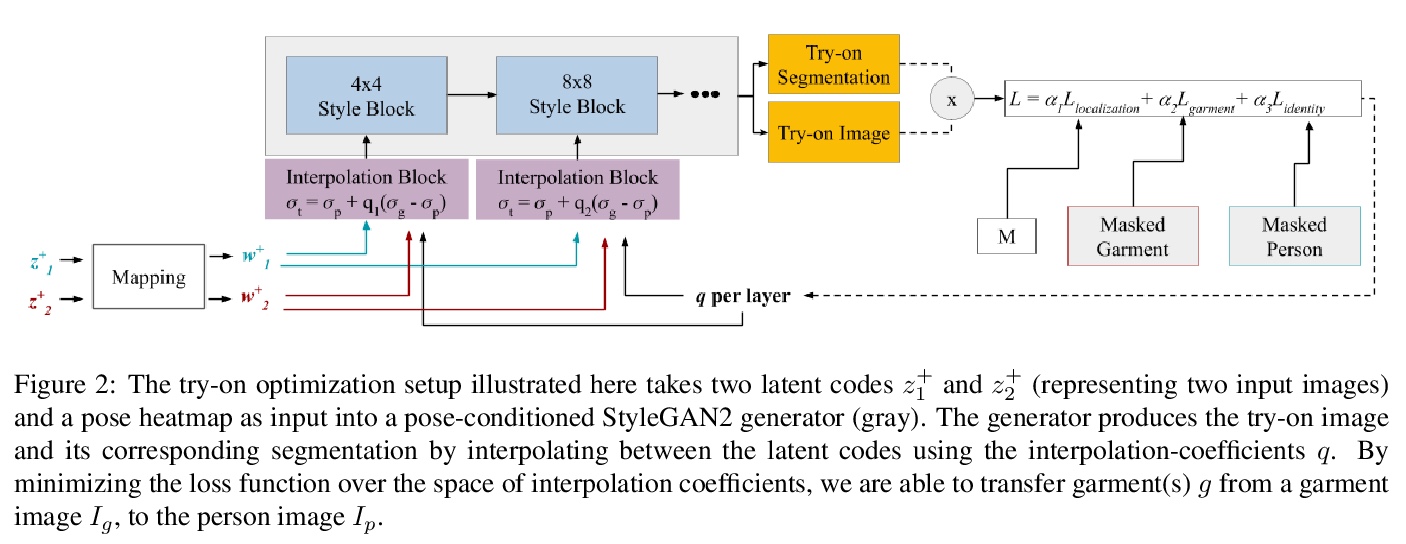
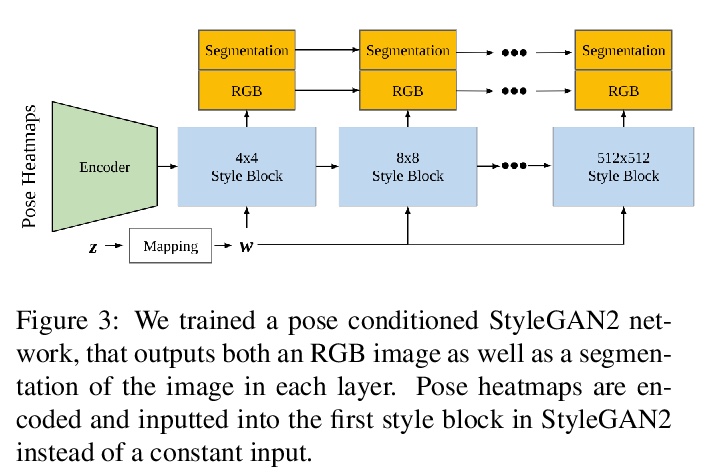
VOGUE:基于StyleGAN插值优化的虚拟试衣。提出了一种使用StyleGAN2强大功能的面向高质量试穿的优化方法,通过学习每层的内部插值系数来创造试穿体验,给定目标人物图像和另一个着装人图像,可自动生成穿着给定服装的目标人物图像。VOGUE的核心是一种以姿势为条件的StyleGAN2潜空间插值,将每张图像中感兴趣区域无缝结合,体型、头发和肤色来自目标人物,服装褶皱、材料质地和形状来自着装图像。通过自动优化潜空间每层的插值系数,对服装和目标人物进行无缝且逼真的合并。该算法允许服装根据给定身体形状进行变形,同时保留图案和材料细节。
Given an image of a target person and an image of another person wearing a garment, we automatically generate the target person in the given garment. At the core of our method is a pose-conditioned StyleGAN2 latent space interpolation, which seamlessly combines the areas of interest from each image, i.e., body shape, hair, and skin color are derived from the target person, while the garment with its folds, material properties, and shape comes from the garment image. By automatically optimizing for interpolation coefficients per layer in the latent space, we can perform a seamless, yet true to source, merging of the garment and target person. Our algorithm allows for garments to deform according to the given body shape, while preserving pattern and material details. Experiments demonstrate state-of-the-art photo-realistic results at high resolution (> 512×512).
https://weibo.com/1402400261/JCM649v37

2、[CV] Who’s a Good Boy? Reinforcing Canine Behavior using Machine Learning in Real-Time
J Stock, T Cavey
[Colorado State University]
用机器学习实时强化犬类行为。概述了一个自动犬粮投喂器的开发方法,结合机器学习和嵌入式硬件,实时识别和奖励犬类的积极行为。利用机器学习技术训练图像分类模型,以每秒39帧的速度识别犬类的三种行为:”坐”、”站 “和 “躺”,测试准确率达到92%。评价了各种神经网络架构、可解释性方法、模型量化和优化技术,为NVIDIA Jetson Nano开发了一个模型。通过实时检测上述行为,用Jetson Nano进行推理来强化积极行为,将信号传输给伺服电机,以从犒赏输送装置中释放奖励。
In this paper we outline the development methodology for an automatic dog treat dispenser which combines machine learning and embedded hardware to identify and reward dog behaviors in real-time. Using machine learning techniques for training an image classification model we identify three behaviors of our canine companions: “sit”, “stand”, and “lie down” with up to 92% test accuracy and 39 frames per second. We evaluate a variety of neural network architectures, interpretability methods, model quantization and optimization techniques to develop a model specifically for an NVIDIA Jetson Nano. We detect the aforementioned behaviors in real-time and reinforce positive actions by making inference on the Jetson Nano and transmitting a signal to a servo motor to release rewards from a treat delivery apparatus.
https://weibo.com/1402400261/JCMcfCSOu



3、[LG] Coding for Distributed Multi-Agent Reinforcement Learning
B Wang, J Xie, N Atanasov
[San Diego State University]
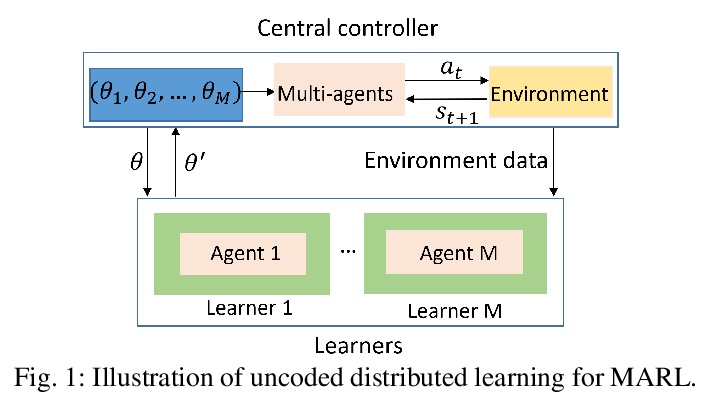
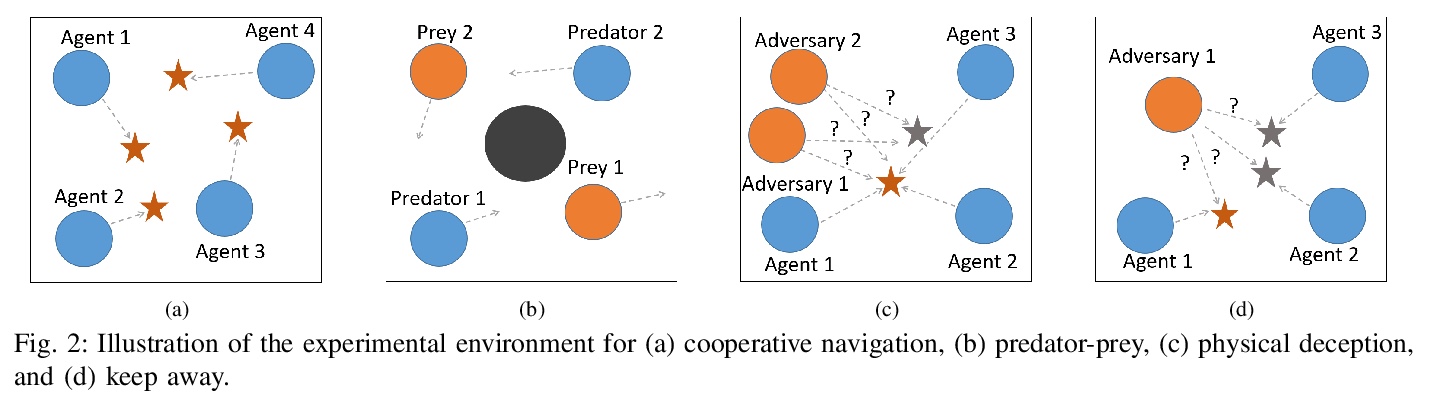
分布式多智能体强化学习编码方法。在分布式学习系统中,由于各种系统干扰的存在,如计算节点减速或故障及通信瓶颈等,Straggler经常出现。为了解决这个问题,提出一种针对多智能体强化学习(MARL)的分布式学习编码框架,在不降低精度的前提下,提高了策略梯度算法在存在Straggler时的训练效率。开发并评价了一个多智能体深度确定性策略梯度(MADDPG)算法的分布式编码版本。研究了不同的编码方案,包括最大距离可分离(MDS)编码、随机稀疏编码、基于复制的编码和常规低密度奇偶校验(LDPC)编码。在几个多机器人问题的仿真中表明了所提出的框架的良好性能。
This paper aims to mitigate straggler effects in synchronous distributed learning for multi-agent reinforcement learning (MARL) problems. Stragglers arise frequently in a distributed learning system, due to the existence of various system disturbances such as slow-downs or failures of compute nodes and communication bottlenecks. To resolve this issue, we propose a coded distributed learning framework, which speeds up the training of MARL algorithms in the presence of stragglers, while maintaining the same accuracy as the centralized approach. As an illustration, a coded distributed version of the multi-agent deep deterministic policy gradient(MADDPG) algorithm is developed and evaluated. Different coding schemes, including maximum distance separable (MDS)code, random sparse code, replication-based code, and regular low density parity check (LDPC) code are also investigated. Simulations in several multi-robot problems demonstrate the promising performance of the proposed framework.
https://weibo.com/1402400261/JCMgU3aek
4、[CV] PandaNet : Anchor-Based Single-Shot Multi-Person 3D Pose Estimation
A Benzine, F Chabot, B Luvison, Q C Pham, C Achrd
[CEA LIST Vision and Learning Lab for Scene Analysis]
PandaNet:基于锚点的单样本多人3D姿态估计。提出PandaNet,一种基于锚点的单样本多人姿态估计模型,能有效处理人数众多、规模变化大、人员重叠的场景。模型以单样本方式预测人体边框及其对应的2D和3D姿态。为了正确地管理人员重叠的状况,引入了一种姿态感知锚点选择策略,丢弃有歧义的锚点。提供了一种自动加权策略,用以平衡任务特定损失、补偿人员规模不平衡、管理与关节坐标相关的不确定性。
Recently, several deep learning models have been proposed for 3D human pose estimation. Nevertheless, most of these approaches only focus on the single-person case or estimate 3D pose of a few people at high resolution. Furthermore, many applications such as autonomous driving or crowd analysis require pose estimation of a large number of people possibly at low-resolution. In this work, we present PandaNet (Pose estimAtioN and Dectection Anchor-based Network), a new single-shot, anchor-based and multi-person 3D pose estimation approach. The proposed model performs bounding box detection and, for each detected person, 2D and 3D pose regression into a single forward pass. It does not need any post-processing to regroup joints since the network predicts a full 3D pose for each bounding box and allows the pose estimation of a possibly large number of people at low resolution. To manage people overlapping, we introduce a Pose-Aware Anchor Selection strategy. Moreover, as imbalance exists between different people sizes in the image, and joints coordinates have different uncertainties depending on these sizes, we propose a method to automatically optimize weights associated to different people scales and joints for efficient training. PandaNet surpasses previous single-shot methods on several challenging datasets: a multi-person urban virtual but very realistic dataset (JTA Dataset), and two real world 3D multi-person datasets (CMU Panoptic and MuPoTS-3D).
https://weibo.com/1402400261/JCMmo9N7A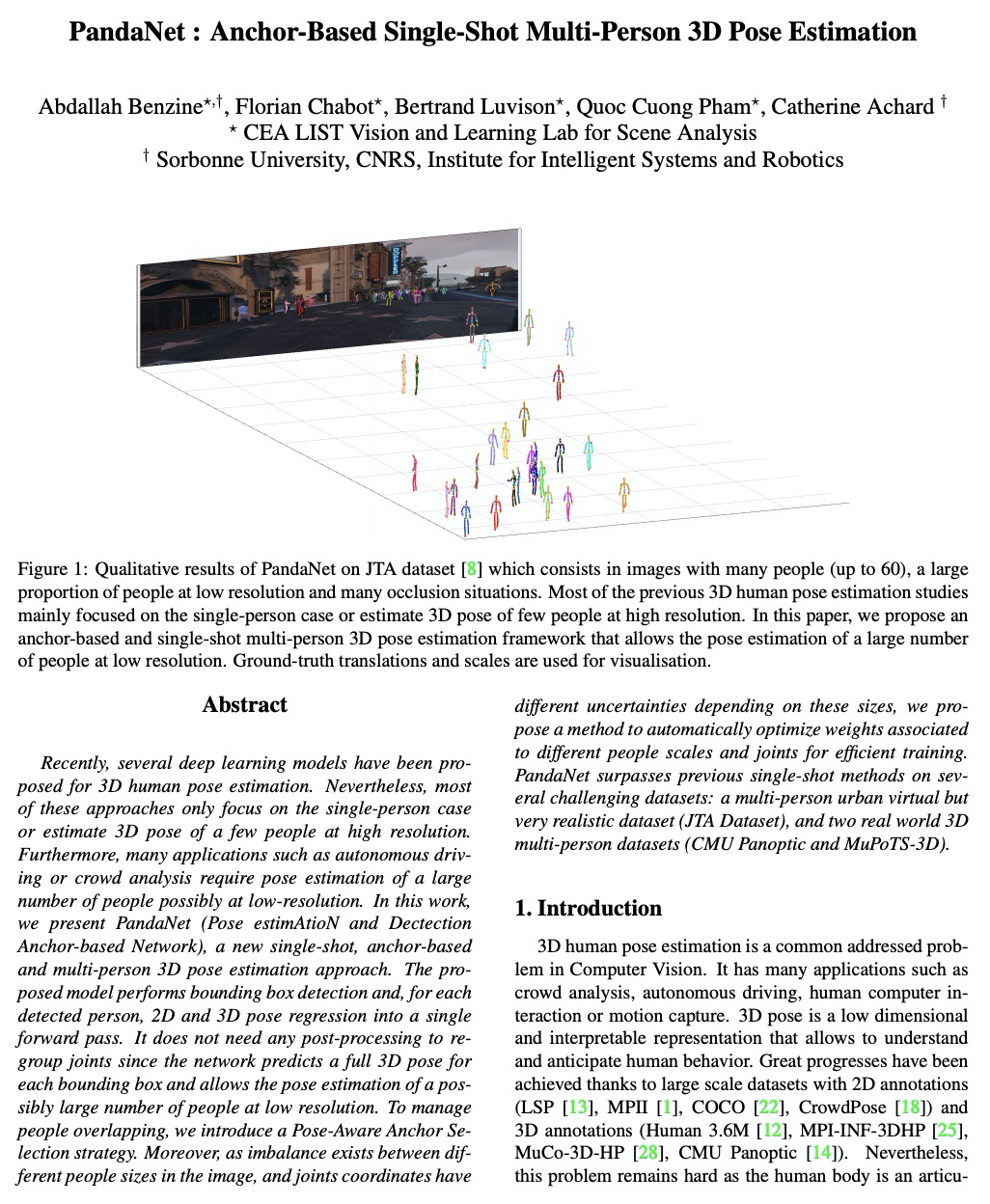

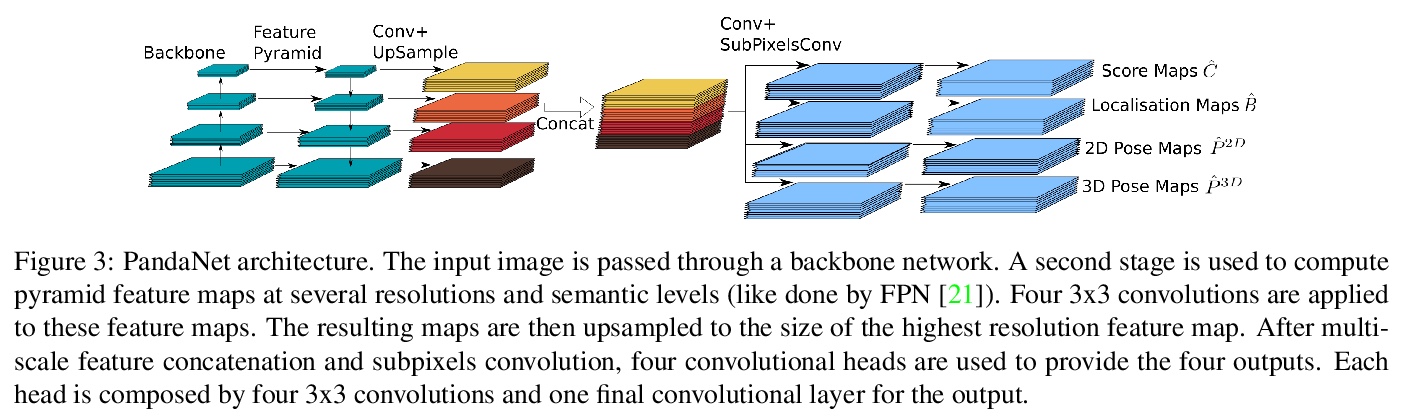

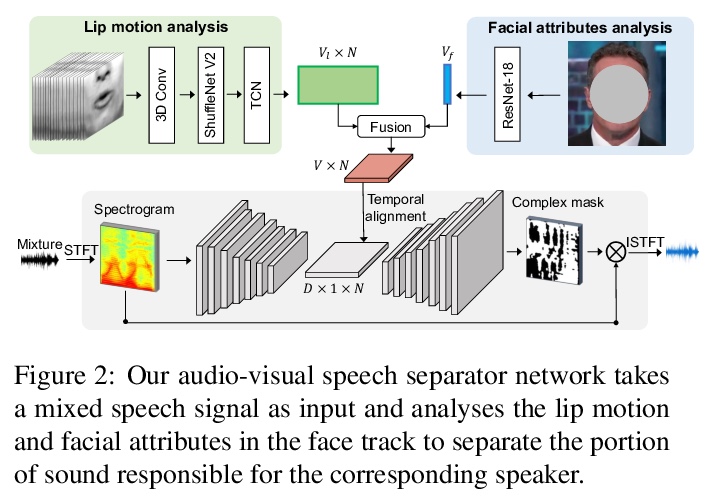
5、[CV] VisualVoice: Audio-Visual Speech Separation with Cross-Modal Consistency
R Gao, K Grauman
[The University of Texas at Austin]
VisualVoice: 基于跨模态一致性的音-画语音分离。提出了一个音-画语音分离框架,在多任务环境下同时学习跨模态说话人嵌入和语音分离。其目标是在给定视频的情况下,提取与人脸相关的语音,尽管同时存在背景声音和/或其他说话人。VISUALVOICE方法利用了唇部运动和跨模态面部属性之间的互补线索,在音-画语音分离上取得了最先进结果,能很好地推广到具有挑战性的现实世界视频中。
We introduce a new approach for audio-visual speech separation. Given a video, the goal is to extract the speech associated with a face in spite of simultaneous background sounds and/or other human speakers. Whereas existing methods focus on learning the alignment between the speaker’s lip movements and the sounds they generate, we propose to leverage the speaker’s face appearance as an additional prior to isolate the corresponding vocal qualities they are likely to produce. Our approach jointly learns audio-visual speech separation and cross-modal speaker embeddings from unlabeled video. It yields state-of-the-art results on five benchmark datasets for audio-visual speech separation and enhancement, and generalizes well to challenging real-world videos of diverse scenarios. Our video results and code: > this http URL.
https://weibo.com/1402400261/JCMsAlpjP

另外几篇值得关注的论文:
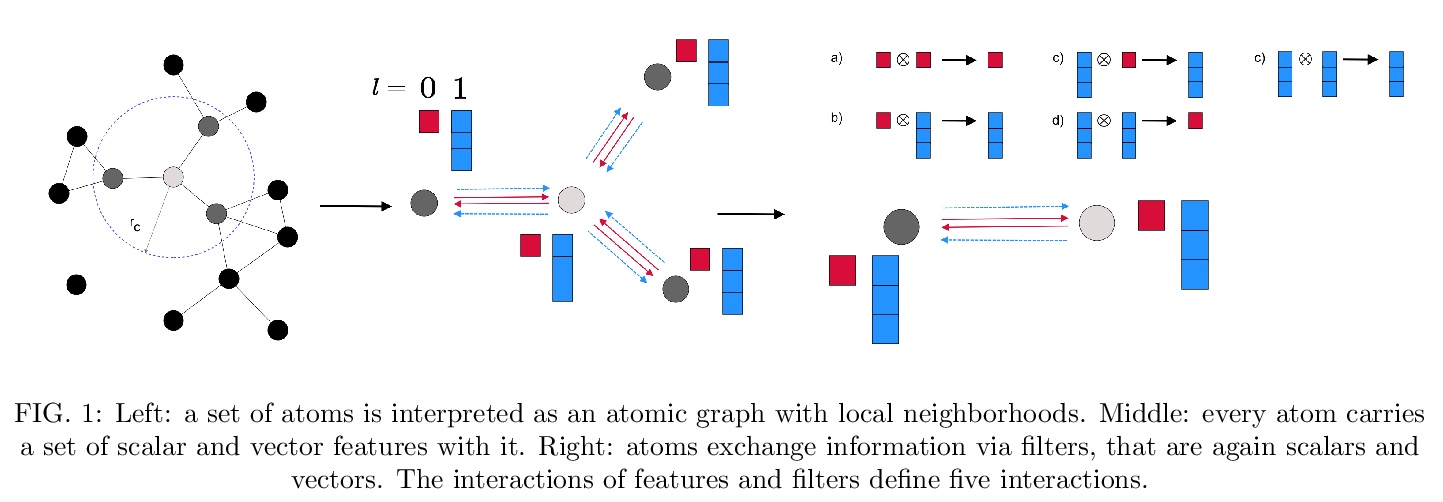
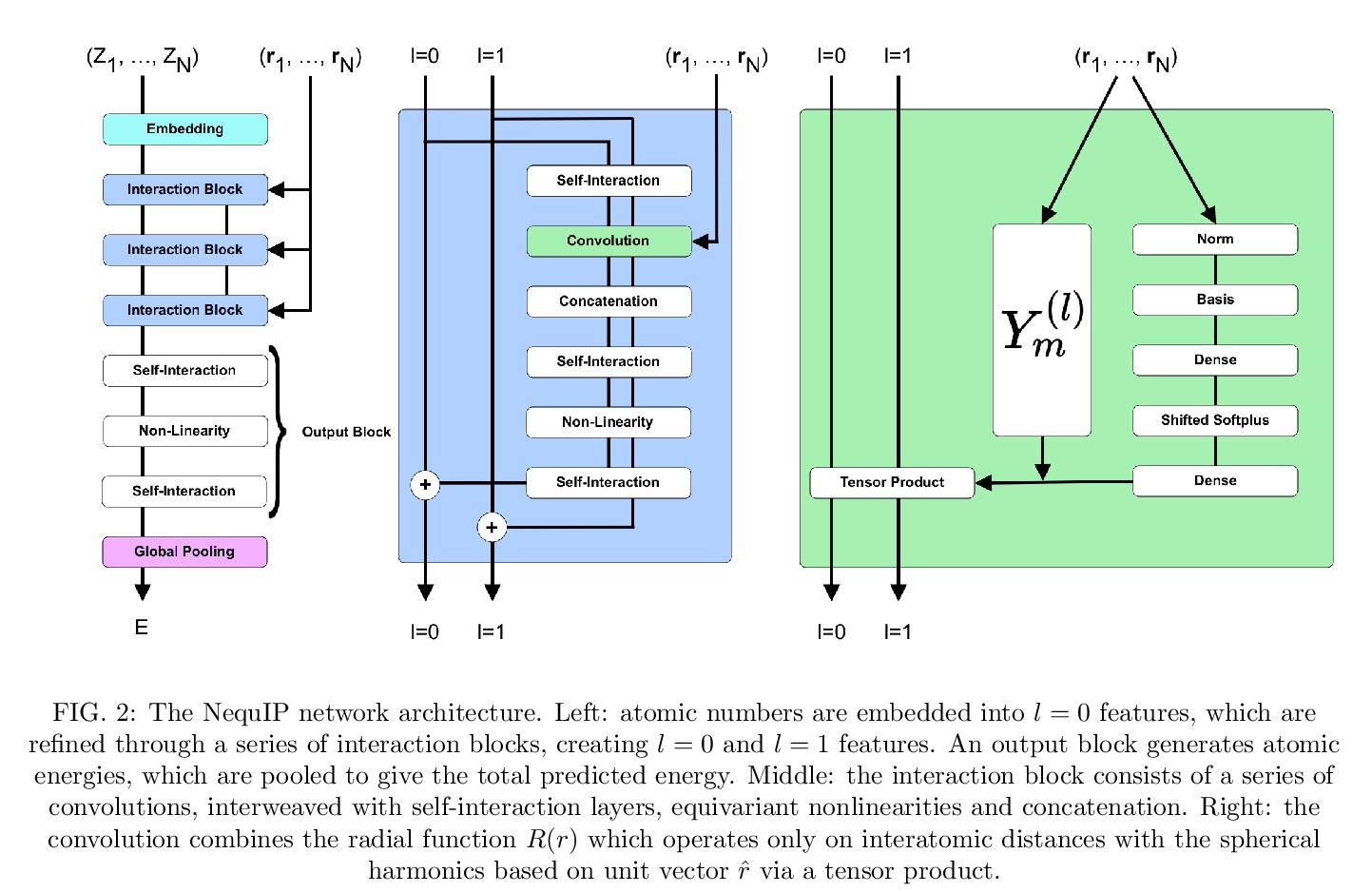
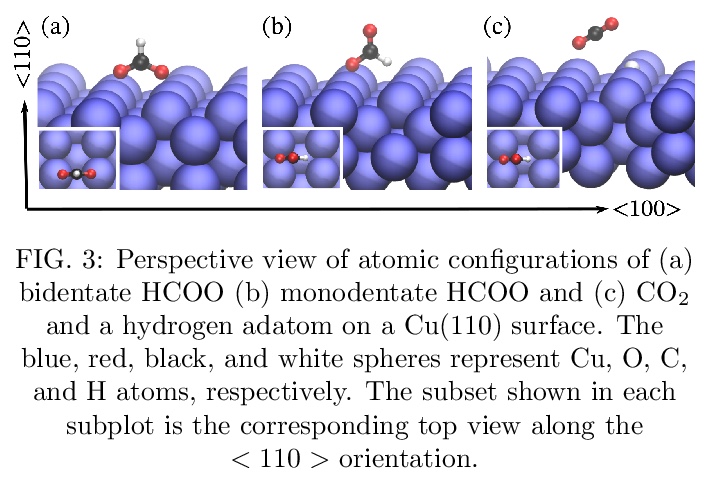
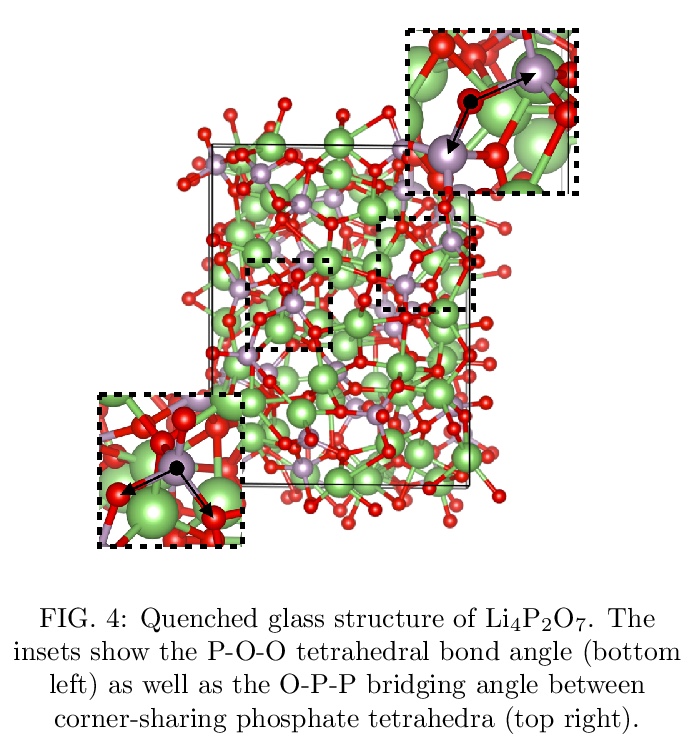
[LG] SE(3)-Equivariant Graph Neural Networks for Data-Efficient and Accurate Interatomic Potentials
NequIP:面向数据高效且精确的原子间相互作用势学习的SE(3)-等变图神经网络
S Batzner, T E. Smidt, L Sun, J P. Mailoa, M Kornbluth, N Molinari, B Kozinsky
[Harvard University & Lawrence Berkeley National Laboratory & Robert Bosch Research and Technology Center]
https://weibo.com/1402400261/JCMwAfpRZ
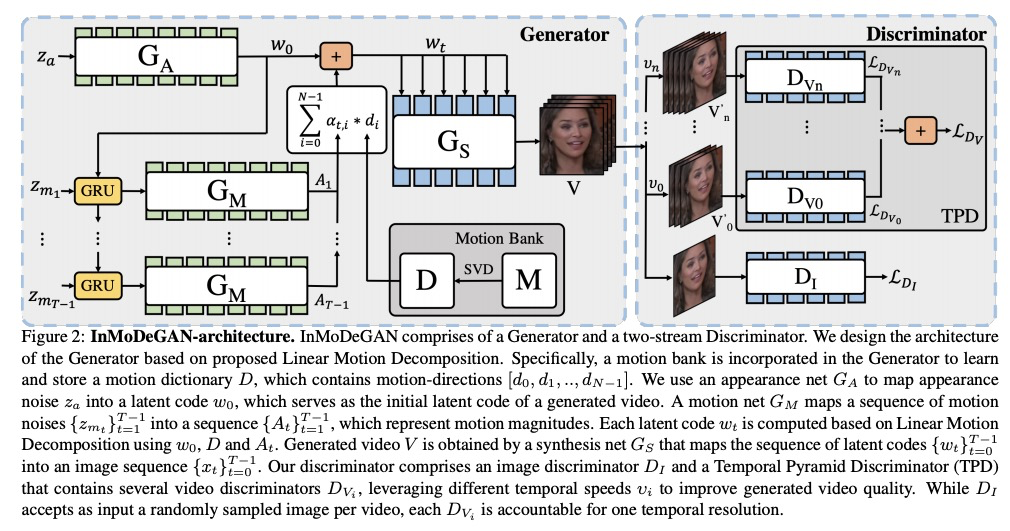
[CV] InMoDeGAN: Interpretable Motion Decomposition Generative Adversarial Network for Video Generation
InMoDeGAN:基于可解释运动分解生成对抗网络的视频生成
Y Wang, F Bremond, A Dantcheva
[Université Côte d’Azur]
https://weibo.com/1402400261/JCMHnhg18
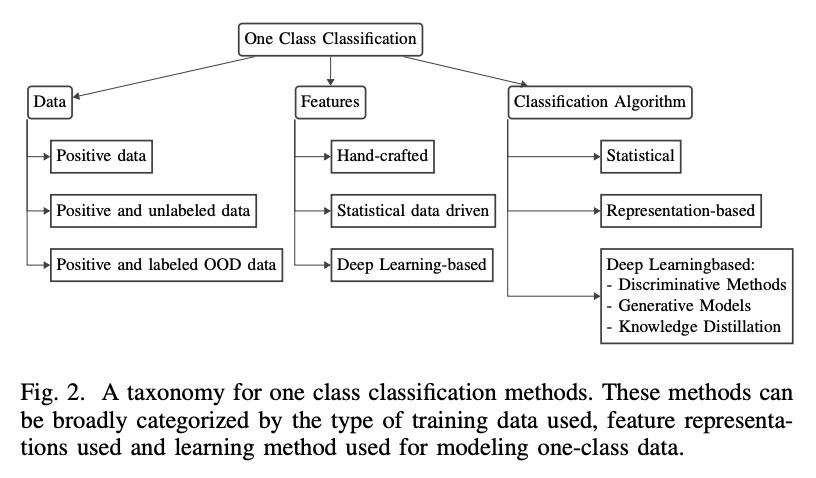
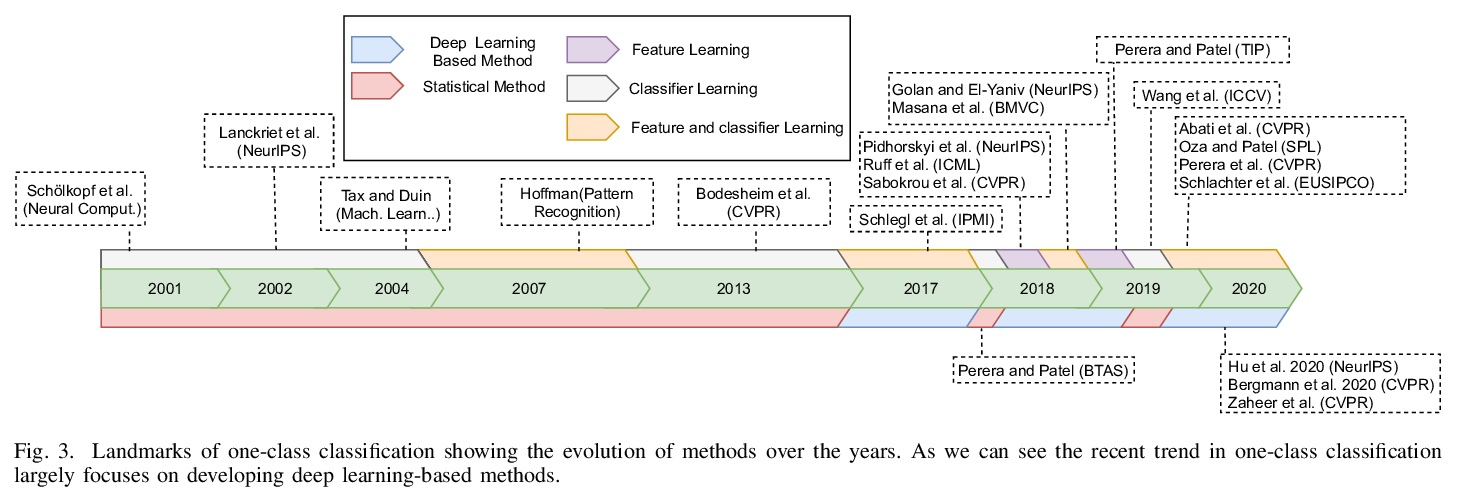
[CV] One-Class Classification: A Survey
单分类(one-class classification)综述
P Perera, P Oza, V M. Patel
[Johns Hopkins Univeristy]
https://weibo.com/1402400261/JCMLQlYtk
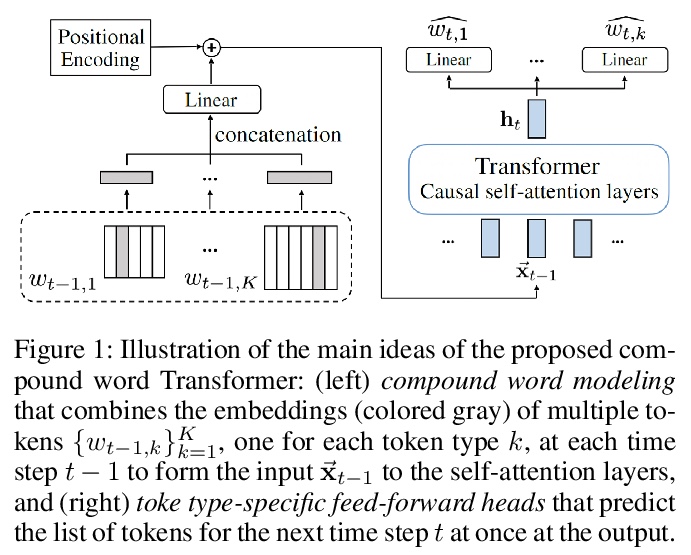
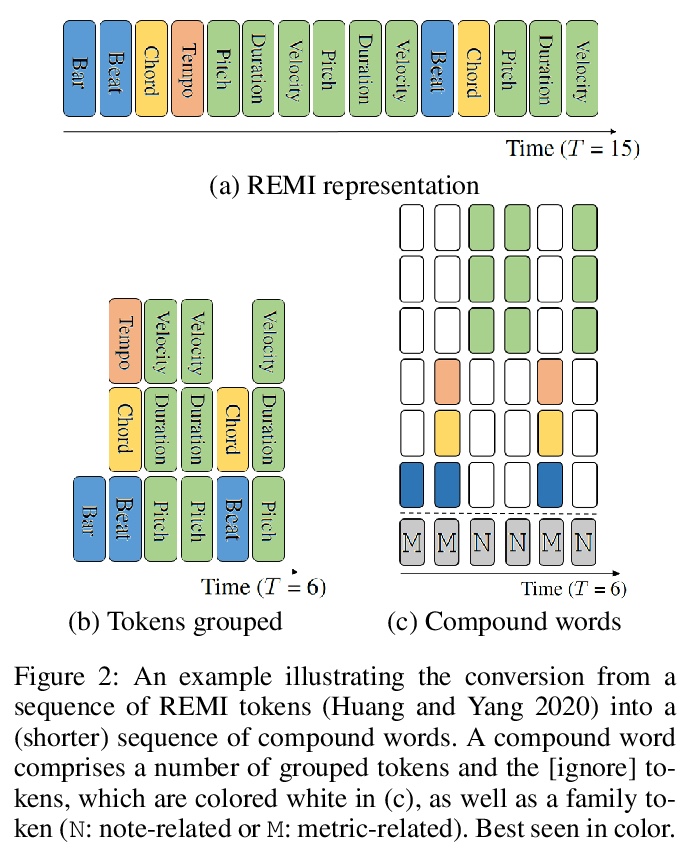
[AS] Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs
复合词Transformer:在动态有向超图上学习创作全曲音乐
W Hsiao, J Liu, Y Yeh, Y Yang
[Taiwan AI Labs]
https://weibo.com/1402400261/JCMNzk6iX

若有收获,就点个赞吧
0 人点赞
