LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] *Gradient Starvation: A Learning Proclivity in Neural Networks
M Pezeshki, S Kaba, Y Bengio, A Courville, D Precup, G Lajoie
[Mila]
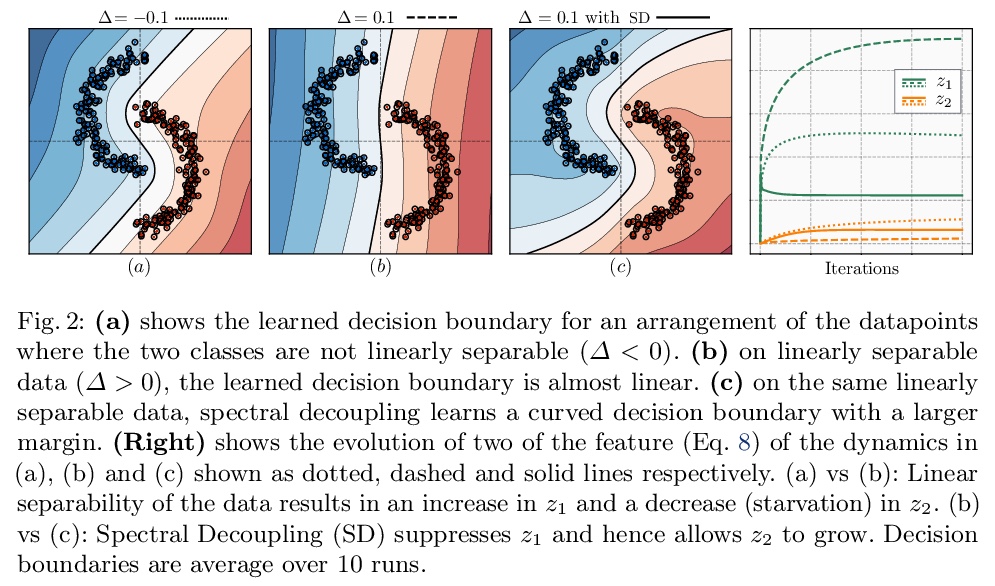
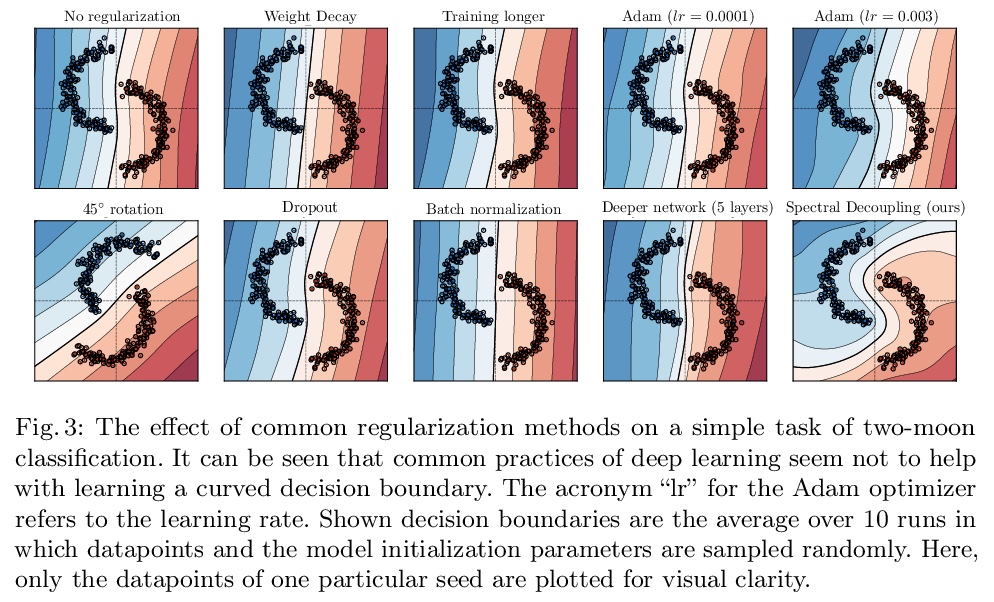
梯度饥饿:神经网络的学习倾向。发现并形式化了一种基本的梯度下降现象——梯度饥饿,这种现象导致了过参数化神经网络的学习倾向。将梯度饥饿形式化为神经网络交叉熵损失训练时出现的一种现象。通过对对偶空间学习过程对应的动力学系统分析,发现即使训练集存在某些特征,梯度饥饿也会减慢对这些特征的学习,这种现象会产生不利的和有利的后果,在训练数据中给定一定的统计结构,这种情况是可以预期的。开发了一种新的正则化方法,旨在解耦特征学习动力学,缓解梯度饥饿,提高准确性和鲁棒性。**
We identify and formalize a fundamental gradient descent phenomenon resulting in a learning proclivity in over-parameterized neural networks. Gradient Starvation arises when cross-entropy loss is minimized by capturing only a subset of features relevant for the task, despite the presence of other predictive features that fail to be discovered. This work provides a theoretical explanation for the emergence of such feature imbalance in neural networks. Using tools from Dynamical Systems theory, we identify simple properties of learning dynamics during gradient descent that lead to this imbalance, and prove that such a situation can be expected given certain statistical structure in training data. Based on our proposed formalism, we develop guarantees for a novel regularization method aimed at decoupling feature learning dynamics, improving accuracy and robustness in cases hindered by gradient starvation. We illustrate our findings with simple and real-world out-of-distribution (OOD) generalization experiments.
https://weibo.com/1402400261/JvttyBdoh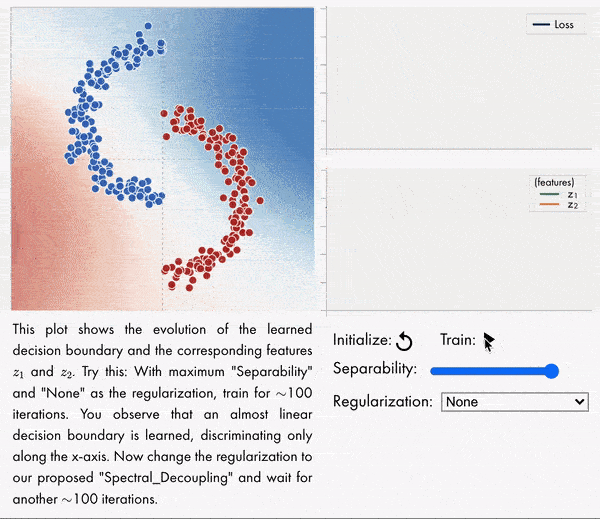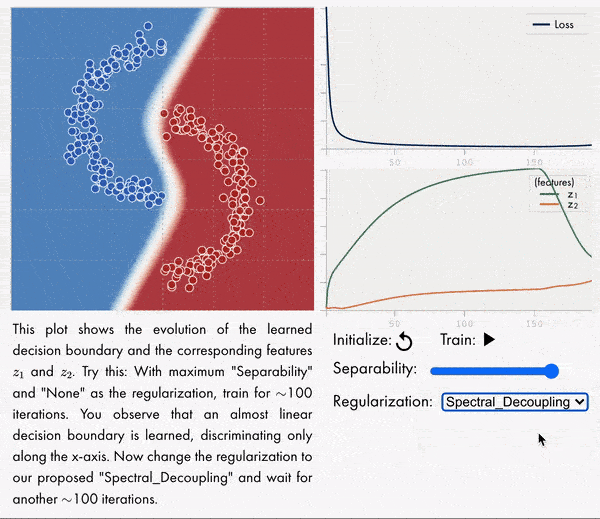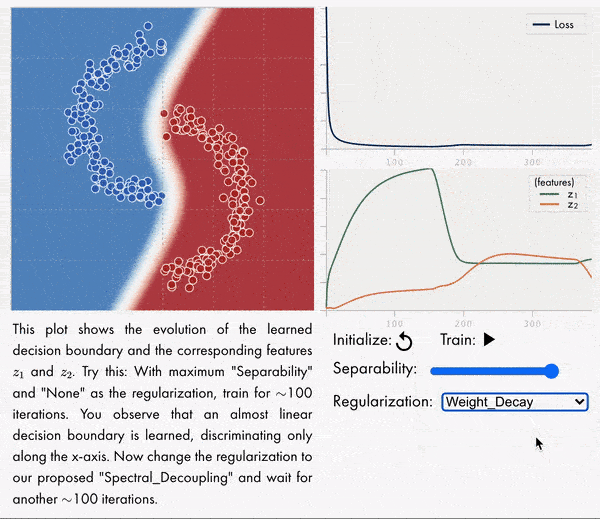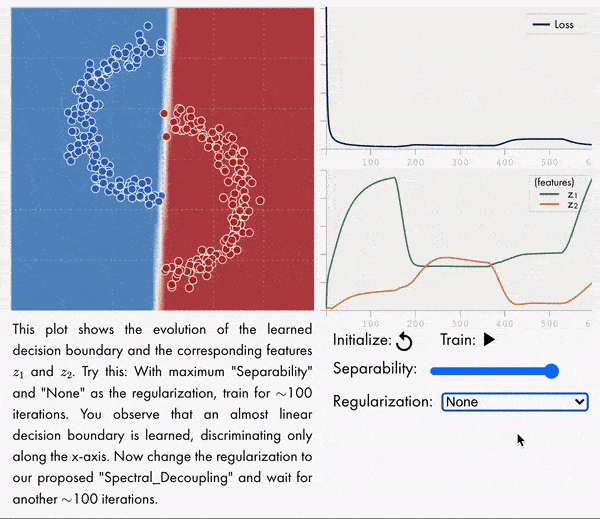

2、[CV] *Learning to Predict the 3D Layout of a Scene
J A Lin, J Brünker, D Fährmann
[TU Darmstadt]
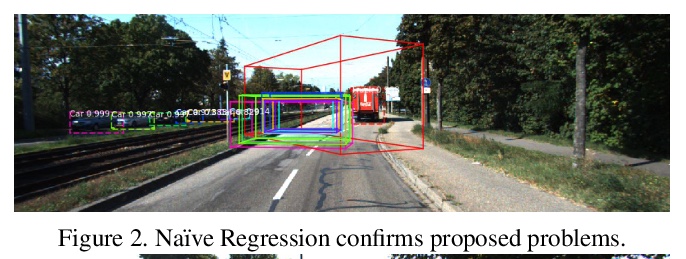
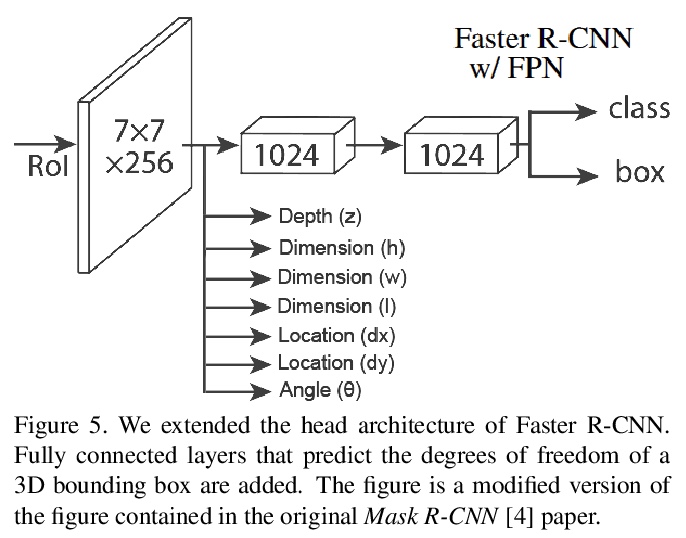
场景3D布局预测学习。无需只用单幅RGB图像,通过3D检测头扩展2D检测器,对场景3D布局进行建模。讨论了设计这种3D检测头的方法和实验,包括回归方法和分类方法。实验证明,将回归问题重新定义为分类任务可以显著提高结果,将搜索空间离散化到小区段中,可实现最先进精度的预测,用线性递增的区段大小可显著改善深度估计的结果。
While 2D object detection has improved significantly over the past, real world applications of computer vision often require an understanding of the 3D layout of a scene. Many recent approaches to 3D detection use LiDAR point clouds for prediction. We propose a method that only uses a single RGB image, thus enabling applications in devices or vehicles that do not have LiDAR sensors. By using an RGB image, we can leverage the maturity and success of recent 2D object detectors, by extending a 2D detector with a 3D detection head. In this paper we discuss different approaches and experiments, including both regression and classification methods, for designing this 3D detection head. Furthermore, we evaluate how subproblems and implementation details impact the overall prediction result. We use the KITTI dataset for training, which consists of street traffic scenes with class labels, 2D bounding boxes and 3D annotations with seven degrees of freedom. Our final architecture is based on Faster R-CNN. The outputs of the convolutional backbone are fixed sized feature maps for every region of interest. Fully connected layers within the network head then propose an object class and perform 2D bounding box regression. We extend the network head by a 3D detection head, which predicts every degree of freedom of a 3D bounding box via classification. We achieve a mean average precision of 47.3% for moderately difficult data, measured at a 3D intersection over union threshold of 70%, as required by the official KITTI benchmark; outperforming previous state-of-the-art single RGB only methods by a large margin.
https://weibo.com/1402400261/JvtyI4bkQ


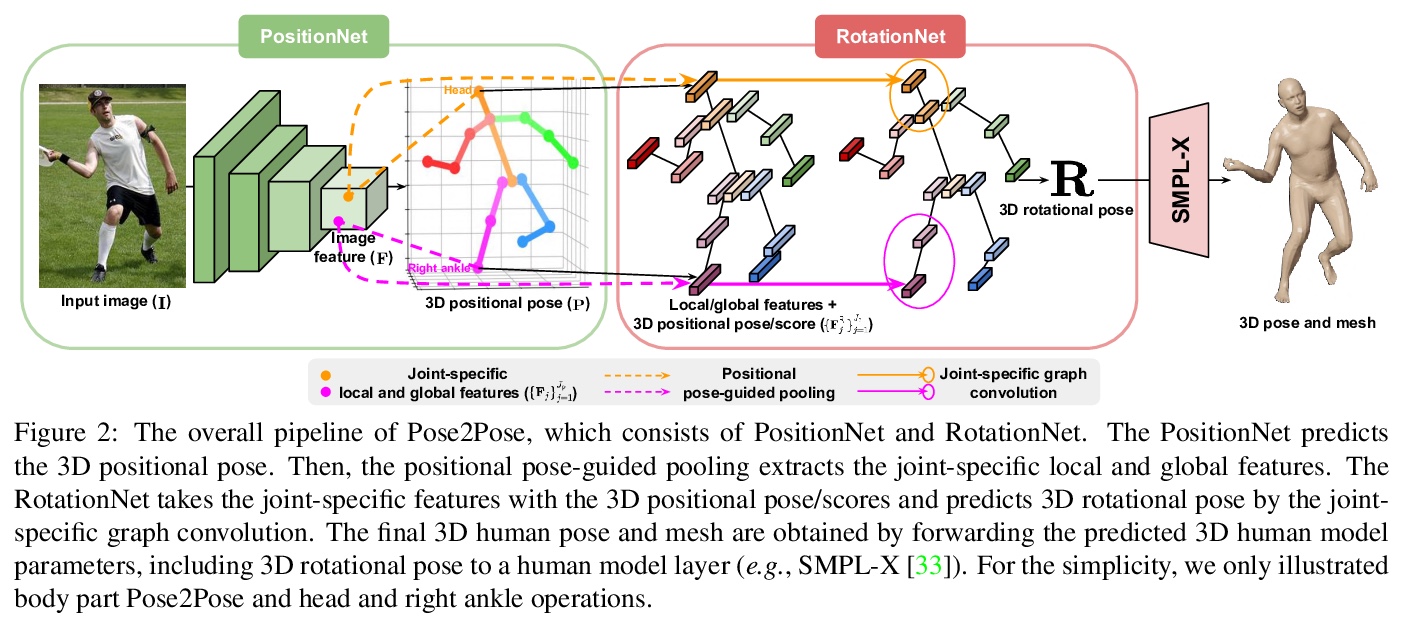
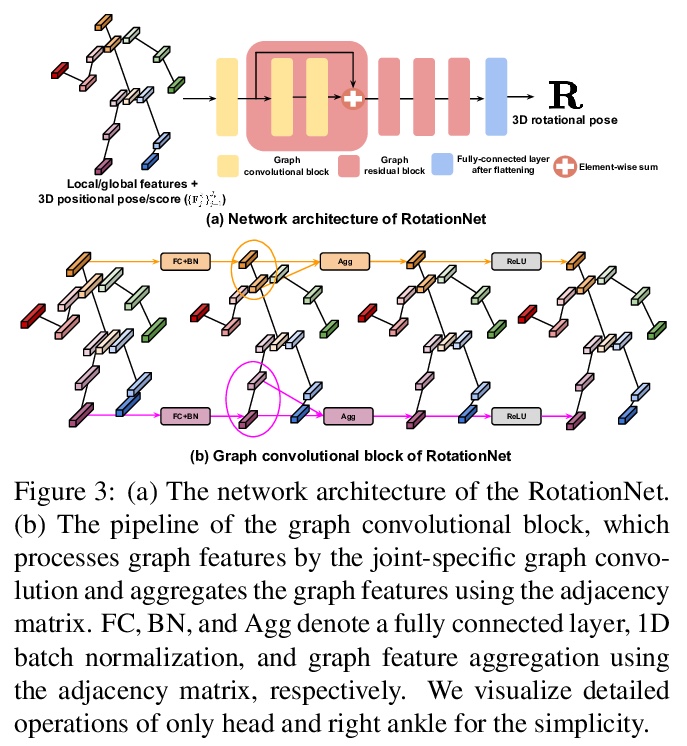
3、[CV] **Pose2Pose: 3D Positional Pose-Guided 3D Rotational Pose Prediction for Expressive 3D Human Pose and Mesh Estimation
G Moon, K M Lee
[Seoul National University]
Pose2Pose:3D位姿引导的3D旋转姿态预测。提出一种三维位置姿态引导的三维旋转姿态预测网络Pose2Pose,从单幅RGB图像估计表达性3D人体姿态和网格。与之前只依赖全局图像特征的工作不同,利用联合特定局部和全局特征,结合特定图卷积,通过位置姿态引导池化进行特征提取。**
Previous 3D human pose and mesh estimation methods mostly rely on only global image feature to predict 3D rotations of human joints (i.e., 3D rotational pose) from an input image. However, local features on the position of human joints (i.e., positional pose) can provide joint-specific information, which is essential to understand human articulation. To effectively utilize both local and global features, we present Pose2Pose, a 3D positional pose-guided 3D rotational pose prediction network, along with a positional pose-guided pooling and joint-specific graph convolution. The positional pose-guided pooling extracts useful joint-specific local and global features. Also, the joint-specific graph convolution effectively processes the joint-specific features by learning joint-specific characteristics and different relationships between different joints. We use Pose2Pose for expressive 3D human pose and mesh estimation and show that it outperforms all previous part-specific and expressive methods by a large margin. The codes will be publicly available.
https://weibo.com/1402400261/JvtEAox58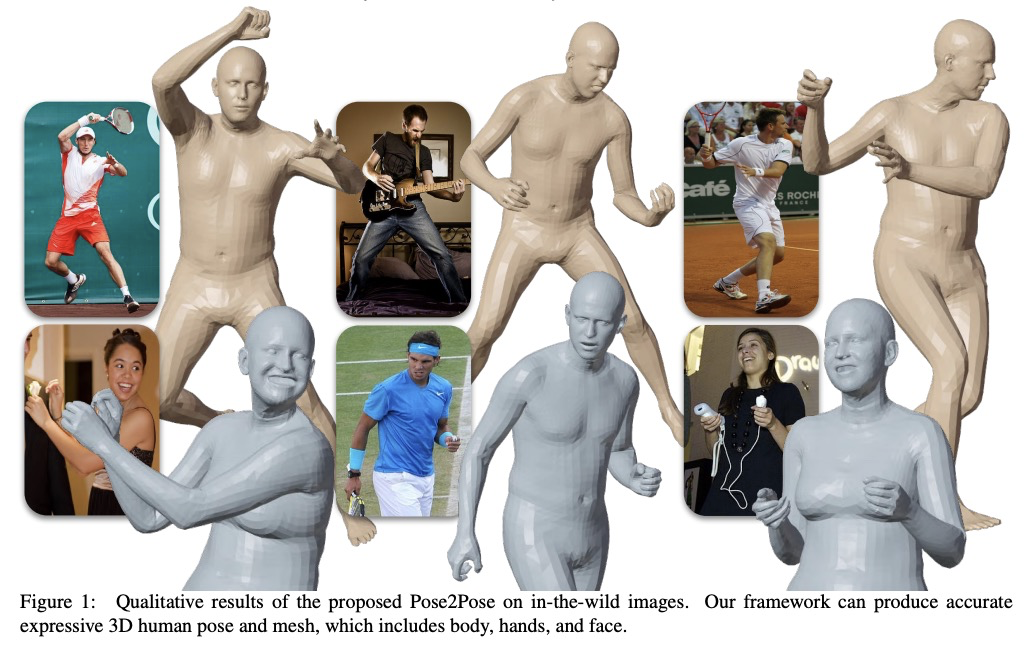
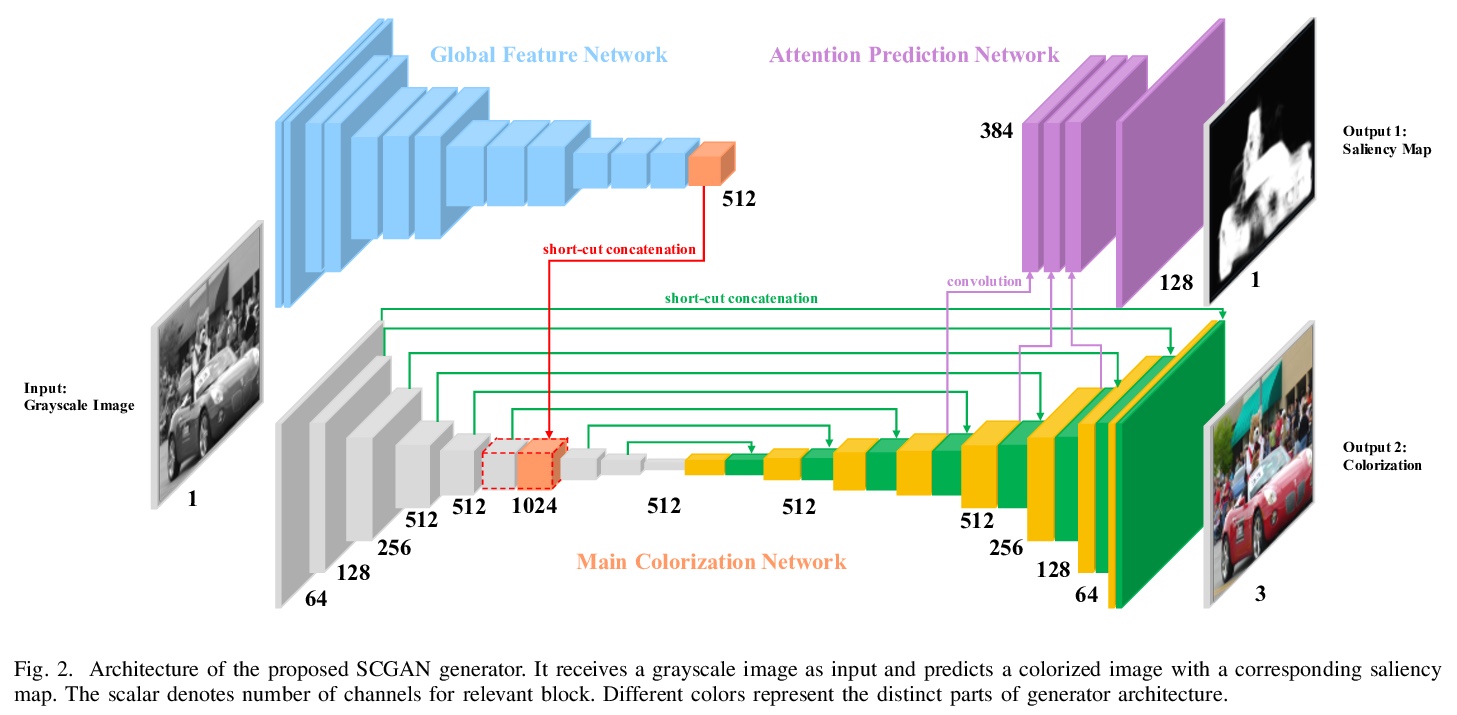
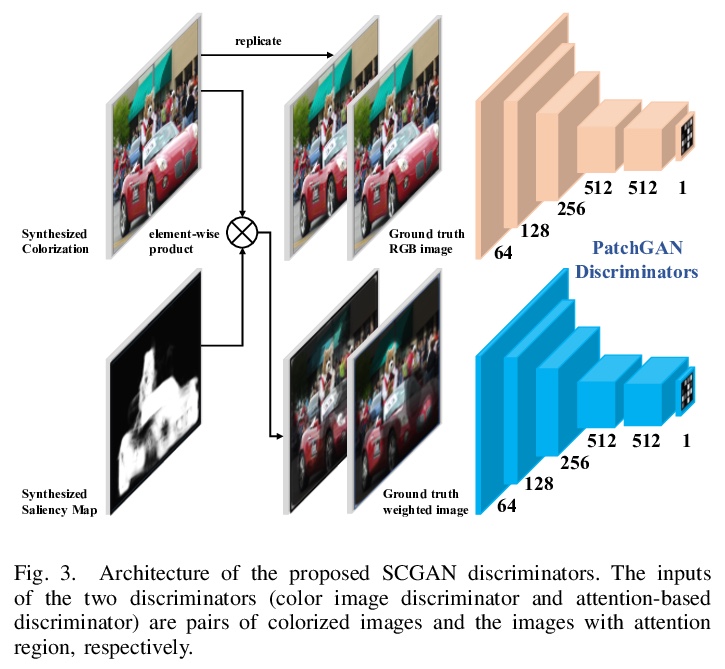
4、[CV] **SCGAN: Saliency Map-guided Colorization with Generative Adversarial Network
Y Zhao, L Po, K Cheung, W Yu, Y A U Rehman
[City University of Hong Kong & Hang Seng University of Hong Kong & TCL Corporate Research Hong Kong]
SCGAN:生成对抗网络显著图引导着色。提出了一种基于生成对抗网络框架的灰度图像全自动显著图引导着色方法(SCGAN),联合预测着色和显著图,最大限度减少着色图像的语义混淆和渗色。预训练VGG-16-Gray网络的全局特征被嵌入到着色编码器中,可用更少数据进行训练,实现感知上的合理着色。提出了一种新的基于显著图的引导方法,着色解码器分支作为代理目标用于显著图预测。**
Given a grayscale photograph, the colorization system estimates a visually plausible colorful image. Conventional methods often use semantics to colorize grayscale images. However, in these methods, only classification semantic information is embedded, resulting in semantic confusion and color bleeding in the final colorized image. To address these issues, we propose a fully automatic Saliency Map-guided Colorization with Generative Adversarial Network (SCGAN) framework. It jointly predicts the colorization and saliency map to minimize semantic confusion and color bleeding in the colorized image. Since the global features from pre-trained VGG-16-Gray network are embedded to the colorization encoder, the proposed SCGAN can be trained with much less data than state-of-the-art methods to achieve perceptually reasonable colorization. In addition, we propose a novel saliency map-based guidance method. Branches of the colorization decoder are used to predict the saliency map as a proxy target. Moreover, two hierarchical discriminators are utilized for the generated colorization and saliency map, respectively, in order to strengthen visual perception performance. The proposed system is evaluated on ImageNet validation set. Experimental results show that SCGAN can generate more reasonable colorized images than state-of-the-art techniques.
https://weibo.com/1402400261/JvtKFaST8
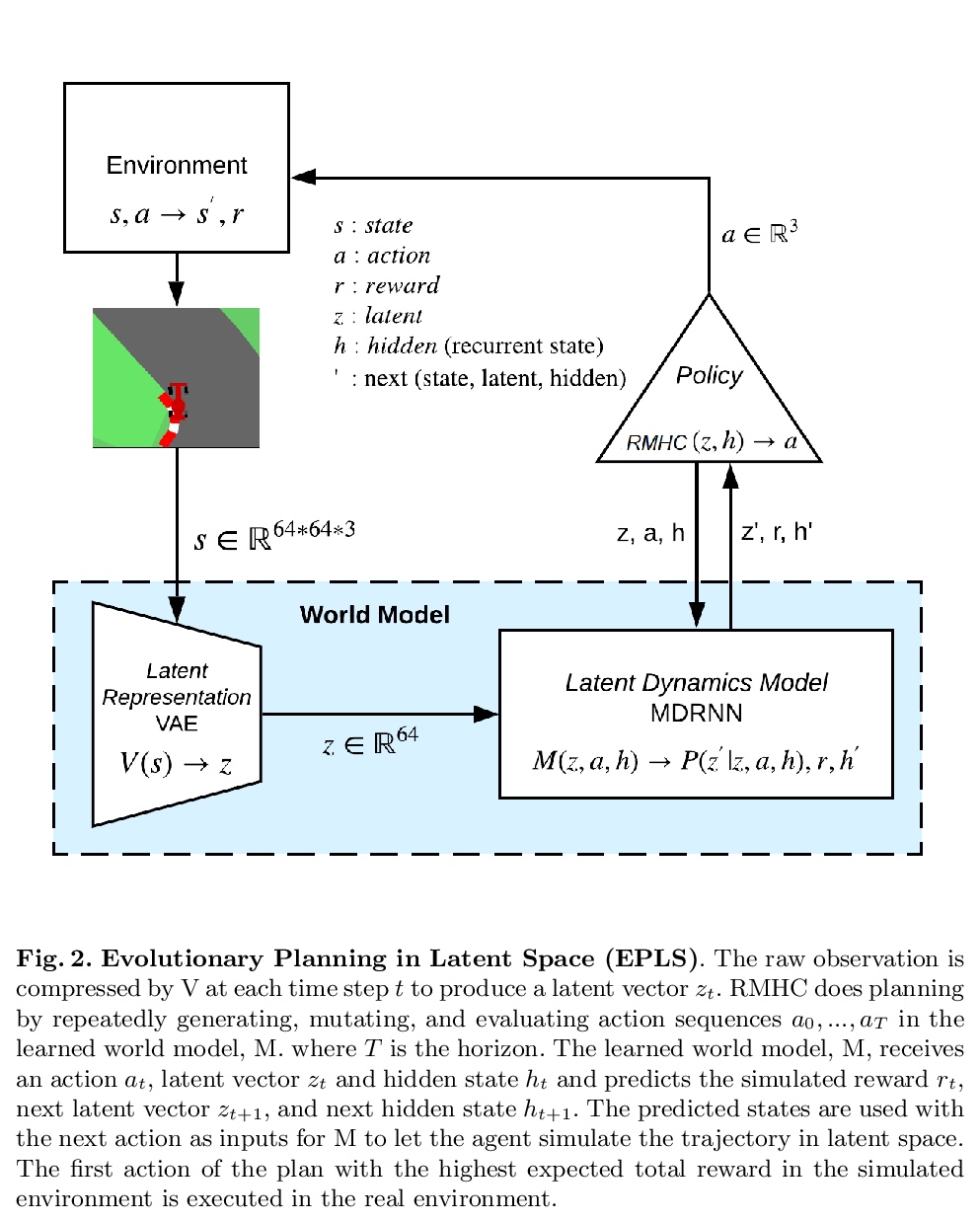
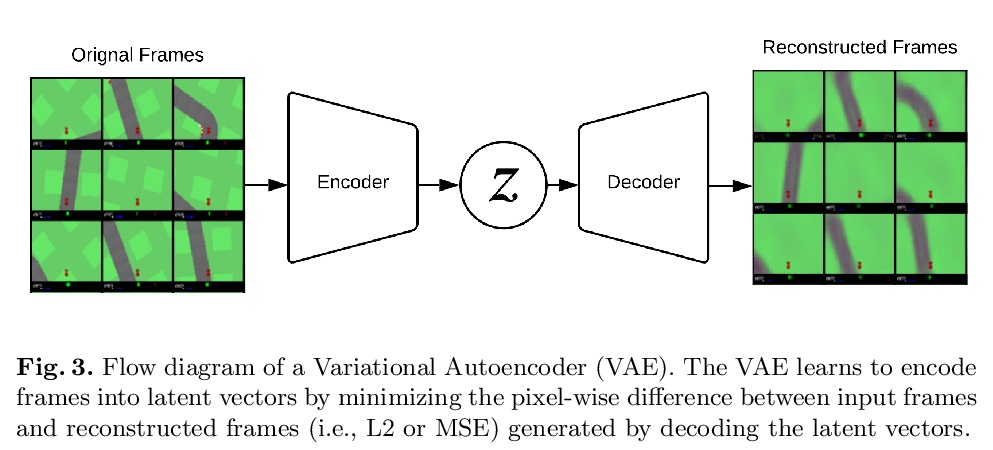
5、[LG] **Evolutionary Planning in Latent Space
T V.A.N. Olesen, D T.T. Nguyen, R B Palm, S Risi
[IT-University of Copenhagen]
潜空间进化规划。建议学习一个世界模型,使潜空间的进化规划(EPLS)成为可能。用变分自编码器(VAE)来学习个体观测的压缩潜在表示,扩展混合密度递归神经网络(MDRNN)来学习可用于规划的世界的随机、多模态正演模型。用随机突变爬山(RMHC)在这个学习的世界模型中找到一系列的行动,使期望回报最大化。**
Planning is a powerful approach to reinforcement learning with several desirable properties. However, it requires a model of the world, which is not readily available in many real-life problems. In this paper, we propose to learn a world model that enables Evolutionary Planning in Latent Space (EPLS). We use a Variational Auto Encoder (VAE) to learn a compressed latent representation of individual observations and extend a Mixture Density Recurrent Neural Network (MDRNN) to learn a stochastic, multi-modal forward model of the world that can be used for planning. We use the Random Mutation Hill Climbing (RMHC) to find a sequence of actions that maximize expected reward in this learned model of the world. We demonstrate how to build a model of the world by bootstrapping it with rollouts from a random policy and iteratively refining it with rollouts from an increasingly accurate planning policy using the learned world model. After a few iterations of this refinement, our planning agents are better than standard model-free reinforcement learning approaches demonstrating the viability of our approach.
https://weibo.com/1402400261/JvtPdyB0s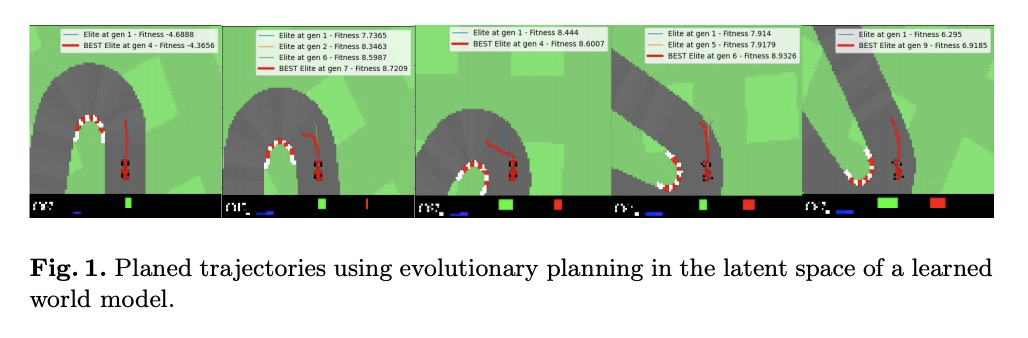
其他几篇值得关注的论文:
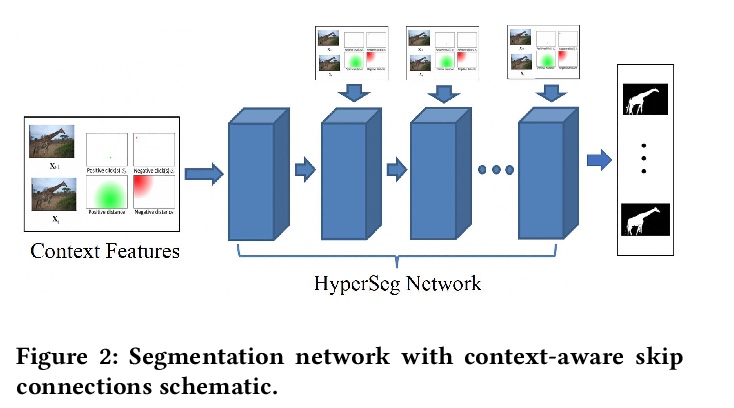
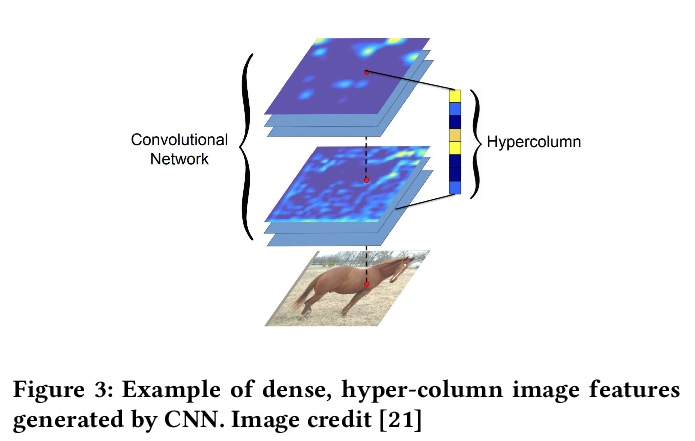
[CV] High Fidelity Interactive Video Segmentation Using Tensor Decomposition Boundary Loss Convolutional Tessellations and Context Aware Skip Connections
基于张量分解边界损失卷积镶嵌和上下文感知跳过连接的高保真交互式视频分割
A D. Rhodes, M Goel
[Intel Corporation]
https://weibo.com/1402400261/JvtU749d1
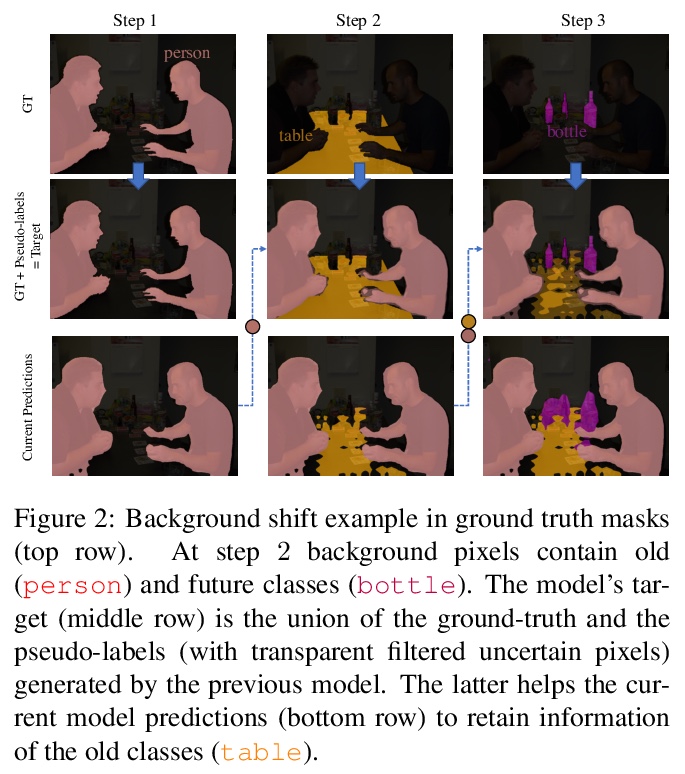
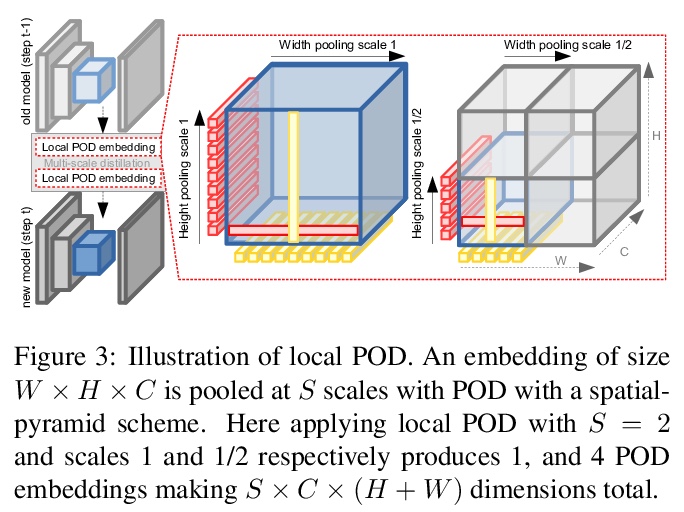
[CV] PLOP: Learning without Forgetting for Continual Semantic Segmentation
PLOP:无遗忘学习持续语义分割
A Douillard, Y Chen, A Dapogny, M Cord
[Sorbonne University & Dakatalab]
https://weibo.com/1402400261/JvtWn6Oqd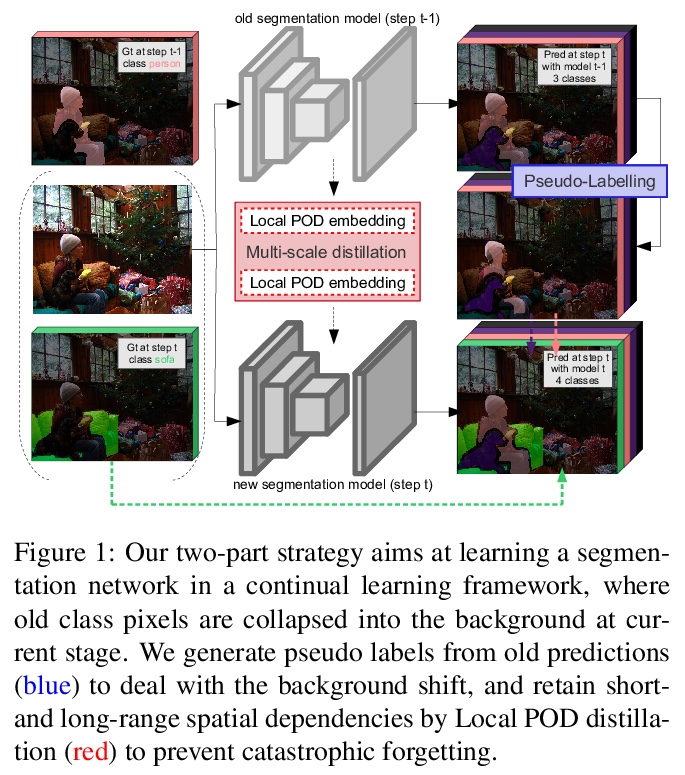

若有收获,就点个赞吧
0 人点赞
