- 1、[CV] DriveGAN: Towards a Controllable High-Quality Neural Simulation
- 2、[CL] Entailment as Few-Shot Learner
- 3、[CV] Text2Video: Text-driven Talking-head Video Synthesis with Phonetic Dictionary
- 4、[CV] Diverse Image Inpainting with Bidirectional and Autoregressive Transformers
- 5、[CV] StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing
- [CV] CoCon: Cooperative-Contrastive Learning
- [CV] M3DeTR: Multi-representation, Multi-scale, Mutual-relation 3D Object Detection with Transformers
- [CL] Let’s Play Mono-Poly: BERT Can Reveal Words’ Polysemy Level and Partitionability into Senses
- [CV] GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] DriveGAN: Towards a Controllable High-Quality Neural Simulation
S W Kim, J Philion, A Torralba, S Fidler
[NVIDIA & MIT]
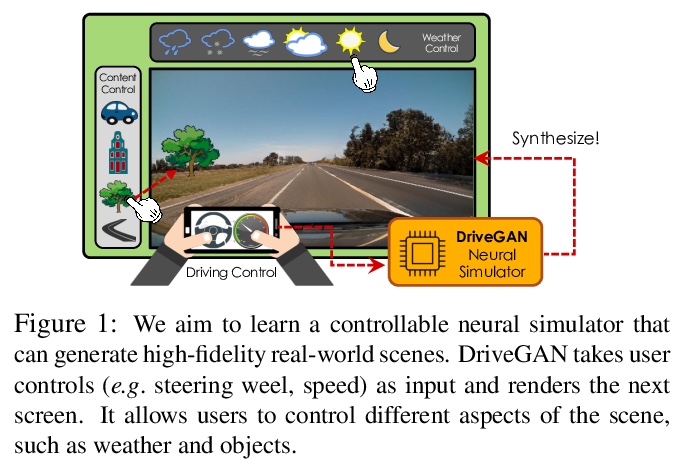
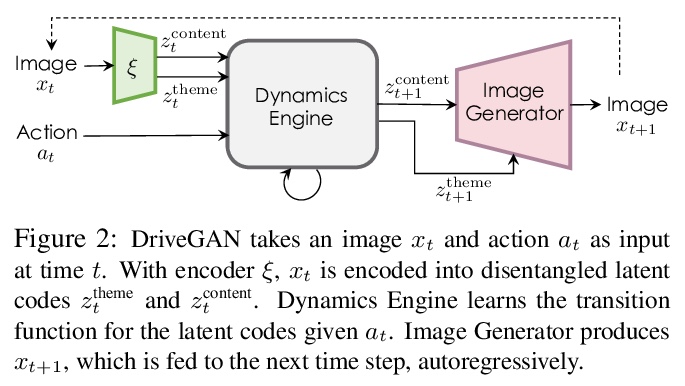
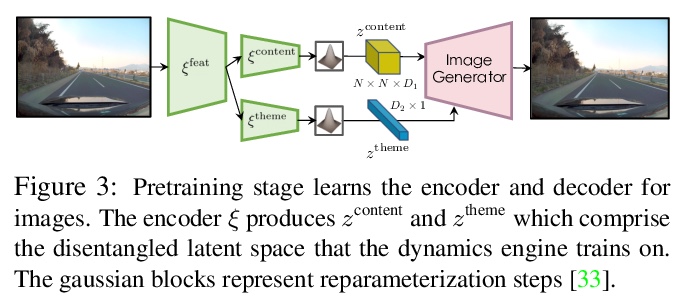
DriveGAN:可控高质量神经网络模拟探索。逼真的模拟器对于训练和验证机器人系统至关重要。虽然大多数当代模拟器都是手工打造的,但建立模拟器的一个可扩展方法是采用机器学习,直接从数据中学习环境对某一行为的反应。本文的目标,是通过观察未经标注的帧序列及其相关动作,直接在像素空间中学习如何模拟动态环境。引入了一个新的高质量的神经网络模拟器DriveGAN,利用新的编码器和图像GAN来产生潜空间,所提出的动力学引擎在该空间中学习帧间的过度转换,在无监督情况下解缠组件来实现可控性。除转向控制外,还包括对场景特征的采样控制,如天气及非操作目标的位置。由于DriveGAN是一个完全可微的模拟器,可对给定视频序列进行再模拟,让智能体采取不同的行动、再次驾驶通过一个记录场景。允许用户在模拟过程中互动编辑场景,并产生独特的场景。在多个数据集上训练DriveGAN,包括160小时的真实世界驾驶数据。该方法大大超过了以前的数据驱动模拟器的性能,并允许使用以前没有探索过的新的关键功能。
Realistic simulators are critical for training and verifying robotics systems. While most of the contemporary simulators are hand-crafted, a scaleable way to build simulators is to use machine learning to learn how the environment behaves in response to an action, directly from data. In this work, we aim to learn to simulate a dynamic environment directly in pixel-space, by watching unannotated sequences of frames and their associated action pairs. We introduce a novel high-quality neural simulator referred to as DriveGAN that achieves controllability by disentangling different components without supervision. In addition to steering controls, it also includes controls for sampling features of a scene, such as the weather as well as the location of non-player objects. Since DriveGAN is a fully differentiable simulator, it further allows for re-simulation of a given video sequence, offering an agent to drive through a recorded scene again, possibly taking different actions. We train DriveGAN on multiple datasets, including 160 hours of real-world driving data. We showcase that our approach greatly surpasses the performance of previous data-driven simulators, and allows for new features not explored before.
https://weibo.com/1402400261/KdQF9oeYL

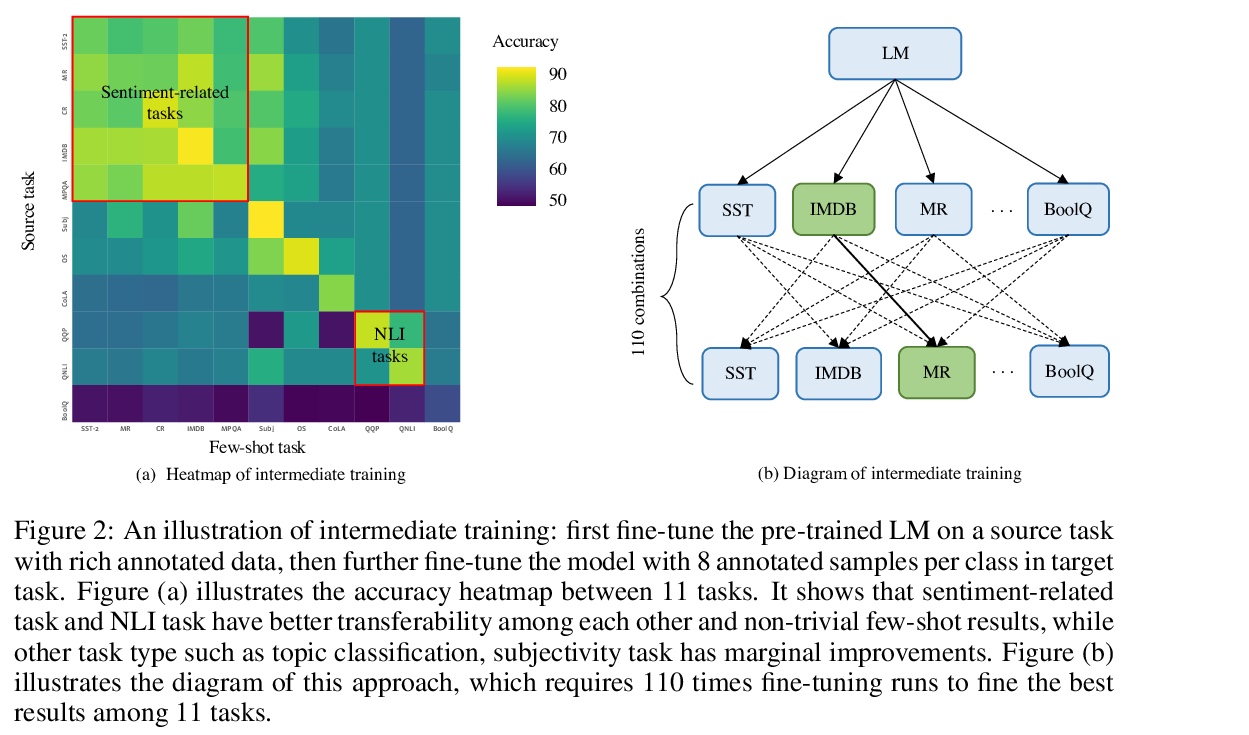
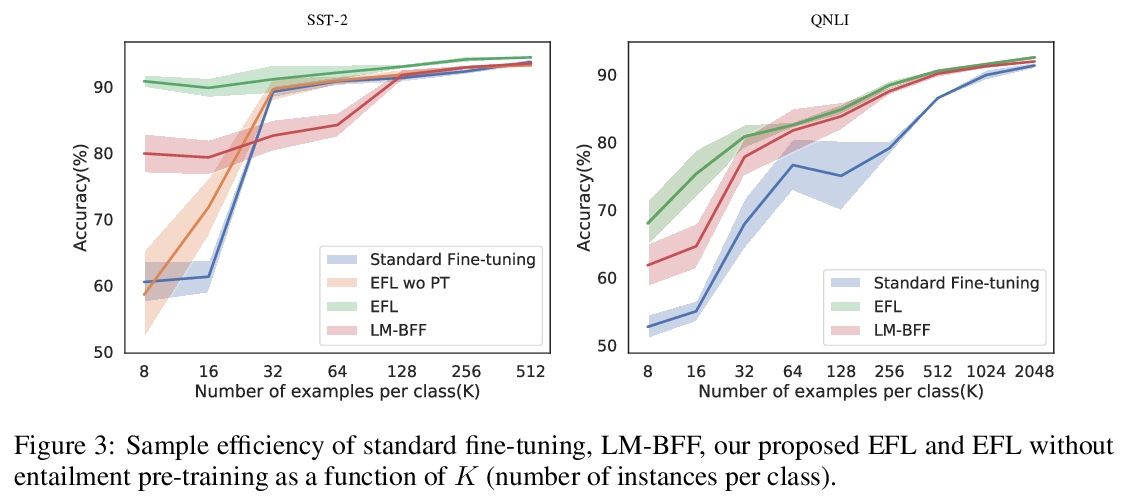
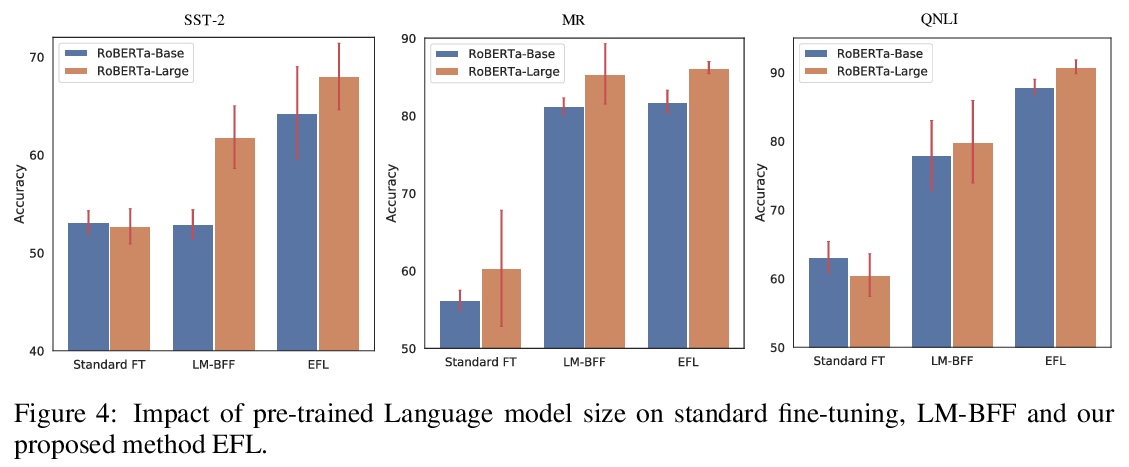
2、[CL] Entailment as Few-Shot Learner
S Wang, H Fang, M Khabsa, H Mao, H Ma
[Facebook AI]
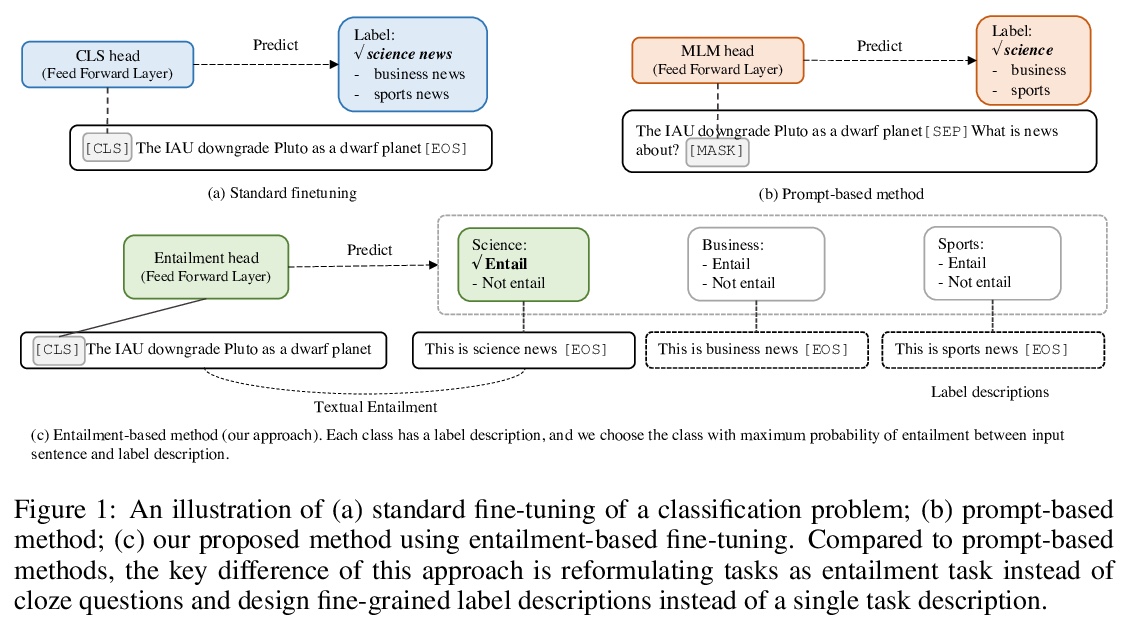
蕴含少样本学习器。大规模预训练语言模型(LM)作为少样本学习器表现出了显著的能力。但其成功在很大程度上取决于模型参数的规模化扩展,使得其训练和服务具有挑战性。本文提出了一种新方法EFL,可将小的语言模型变成更好的少样本学习器。关键思想是将潜在的NLP任务重新表述为一个文本蕴含任务,用少至8个样本来微调模型。所提出方法可以 (i)与基于无监督对比学习的数据增强方法自然结合;(ii)容易扩展到多语言的少样本学习。对18个标准NLP任务的系统评估表明,该方法将现有的各种SOTA少样本学习方法提高了12%,并产生了与500倍大的模型(如GPT-3)竞争的少样本性能。
Large pre-trained language models (LMs) have demonstrated remarkable ability as few-shot learners. However, their success hinges largely on scaling model parameters to a degree that makes it challenging to train and serve. In this paper, we propose a new approach, named as EFL, that can turn small LMs into better few-shot learners. The key idea of this approach is to reformulate potential NLP task into an entailment one, and then fine-tune the model with as little as 8 examples. We further demonstrate our proposed method can be: (i) naturally combined with an unsupervised contrastive learning-based data augmentation method; (ii) easily extended to multilingual few-shot learning. A systematic evaluation on 18 standard NLP tasks demonstrates that this approach improves the various existing SOTA few-shot learning methods by 12\%, and yields competitive few-shot performance with 500 times larger models, such as GPT-3.
https://weibo.com/1402400261/KdQKSz344
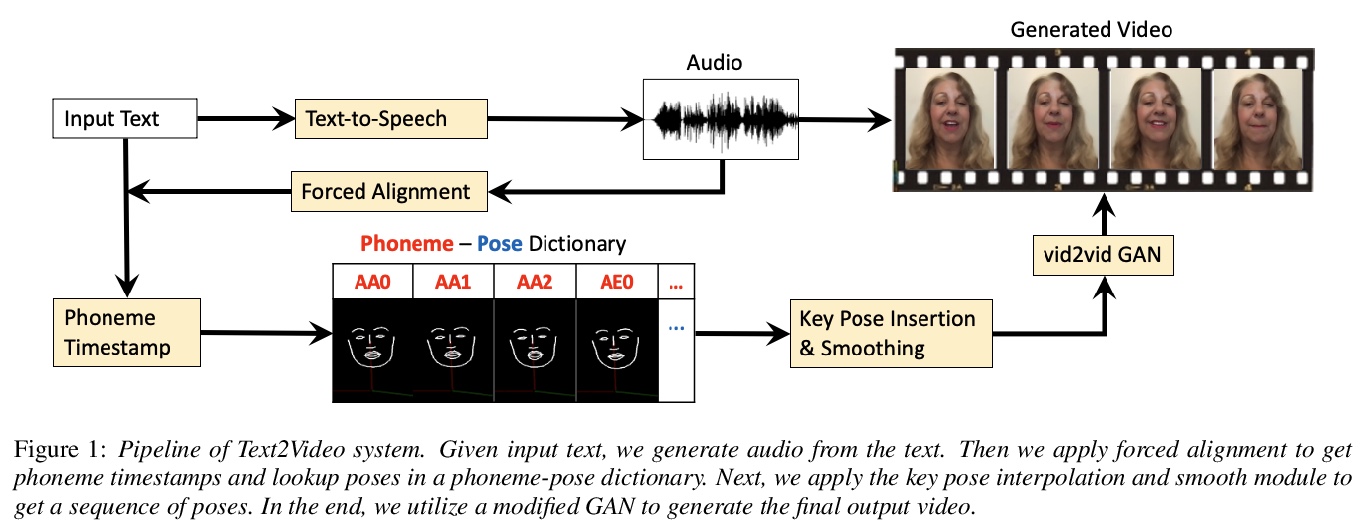
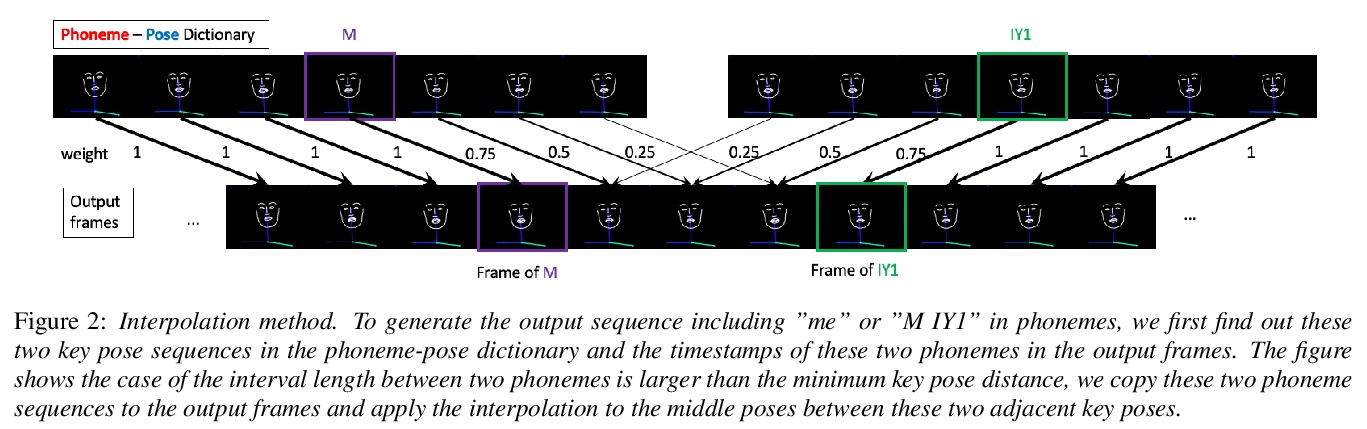
3、[CV] Text2Video: Text-driven Talking-head Video Synthesis with Phonetic Dictionary
S Zhang, J Yuan, M Liao, L Zhang
[Baidu Research]
Text2Video:基于语音词典的文本驱动说话头像视频合成。随着深度学习技术的发展,从音频或文本中自动生成视频成为一个新兴的、有前景的研究课题。本文提出一种从文本合成视频的新方法,从任何文本输入,包括英文、中文、数字和标点符号等,合成说话人语音视频,通过自动姿态提取,从视频中建立音素-姿态字典,训练生成式对抗网络(GAN),利用插值和平滑方法,从音素姿态生成视频。只需44个单词或20个句子,就能建立一个包含英语所有音素的音素-姿态字典。与音频驱动的视频生成算法相比,该方法优势在于:1)只需要音频驱动方法所用训练数据的一小部分;2)更灵活,不受说话人变化的影响;3)大大减少了预处理、训练和推理时间。通过实验证明了该方法的有效性和优越性。
With the advance of deep learning technology, automatic video generation from audio or text has become an emerging and promising research topic. In this paper, we present a novel approach to synthesize video from the text. The method builds a phoneme-pose dictionary and trains a generative adversarial network (GAN) to generate video from interpolated phoneme poses. Compared to audio-driven video generation algorithms, our approach has a number of advantages: 1) It only needs a fraction of the training data used by an audio-driven approach; 2) It is more flexible and not subject to vulnerability due to speaker variation; 3) It significantly reduces the preprocessing, training and inference time. We perform extensive experiments to compare the proposed method with state-of-the-art talking face generation methods on a benchmark dataset and datasets of our own. The results demonstrate the effectiveness and superiority of our approach.
https://weibo.com/1402400261/KdQQd0eJ9

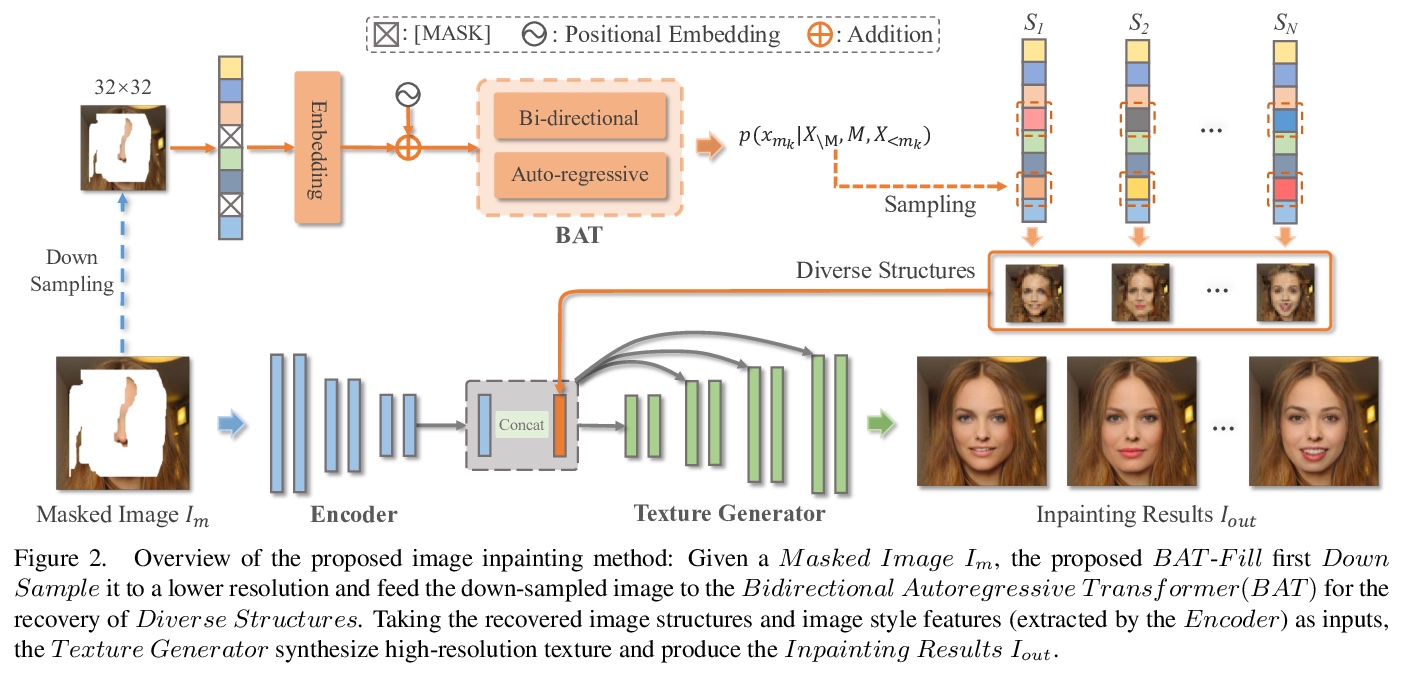
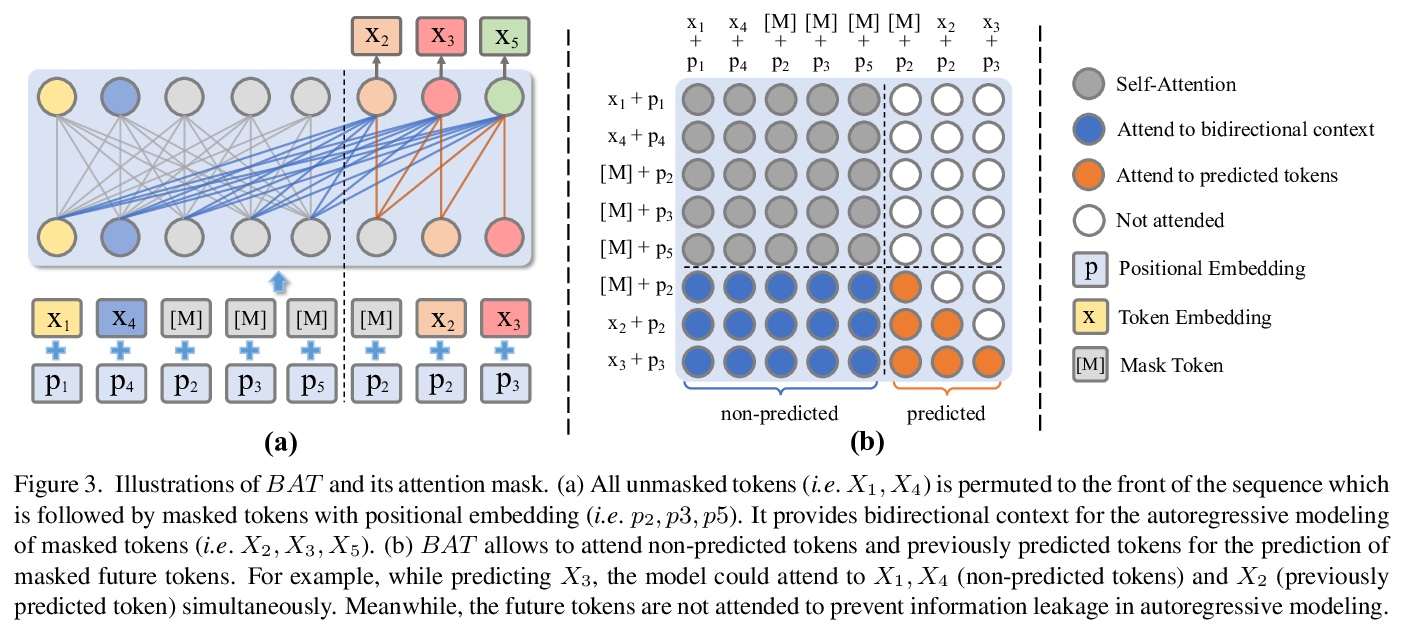
4、[CV] Diverse Image Inpainting with Bidirectional and Autoregressive Transformers
Y Yu, F Zhan, R Wu, J Pan, K Cui, S Lu, F Ma, X Xie, C Miao
[Nanyang Technological University & DAMO Academy]
基于双向自回归Transformer的多样化图像补全。图像补全是一个不确定的逆向问题,它自然允许多样化的内容,合理而真实地填补缺失或损坏的区域。用卷积神经网络(CNN)的普遍方法可以合成视觉上令人愉悦的内容,但CNN在捕捉全局特征方面受感受野限制。通过图像级注意力,Transformer可建立长程依赖关系,并通过像素序列分布自回归建模产生不同的内容。但Transformer中的单向注意力是次优的,因为被破坏区域可以有任意形状和来自任意方向的背景。本文提出BAT-Fill,一个基于新的双向自回归Transformer(BAT)的图像补全框架,该Transformer为深度双向语境建模,用于自回归生成多样化的补全内容。BAT-Fill以两阶段方式继承了Transformer和CNN的优点,可生成高分辨率内容,不受Transformer中注意力的二次复杂性限制。通过自适应Transformer生成低分辨率多元图像结构,再用基于CNN的上采样网络合成高分辨率的逼真纹理细节。在多个数据集上进行的广泛实验表明,BAT-Fill在质量和数量上实现了图像补全的改进多样性和保真度。
Image inpainting is an underdetermined inverse problem, it naturally allows diverse contents that fill up the missing or corrupted regions reasonably and realistically. Prevalent approaches using convolutional neural networks (CNNs) can synthesize visually pleasant contents, but CNNs suffer from limited perception fields for capturing global features. With image-level attention, transformers enable to model long-range dependencies and generate diverse contents with autoregressive modeling of pixel-sequence distributions. However, the unidirectional attention in transformers is suboptimal as corrupted regions can have arbitrary shapes with contexts from arbitrary directions. We propose BAT-Fill, an image inpainting framework with a *Equal contribution †Corresponding author novel bidirectional autoregressive transformer (BAT) that models deep bidirectional contexts for autoregressive generation of diverse inpainting contents. BAT-Fill inherits the merits of transformers and CNNs in a two-stage manner, which allows to generate high-resolution contents without being constrained by the quadratic complexity of attention in transformers. Specifically, it first generates pluralistic image structures of low resolution by adapting transformers and then synthesizes realistic texture details of high resolutions with a CNN-based up-sampling network. Extensive experiments over multiple datasets show that BAT-Fill achieves superior diversity and fidelity in image inpainting qualitatively and quantitatively.
https://weibo.com/1402400261/KdQXRuiNd


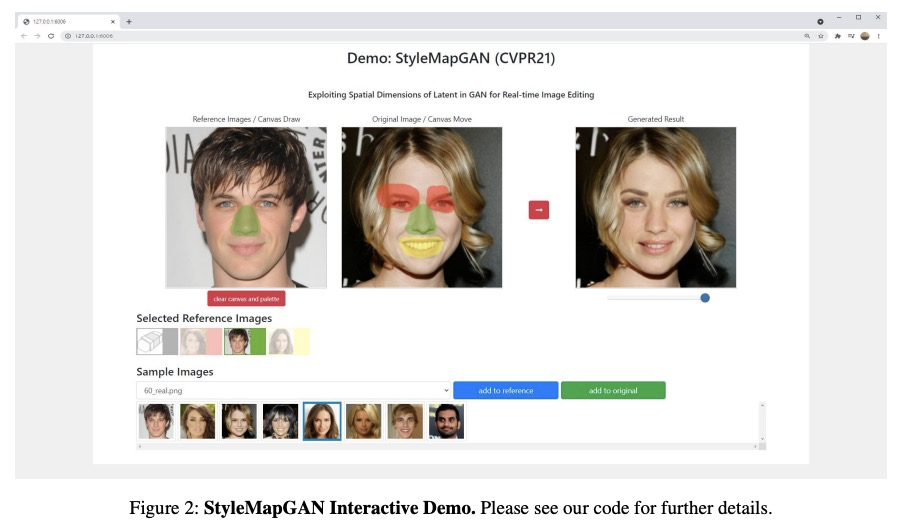
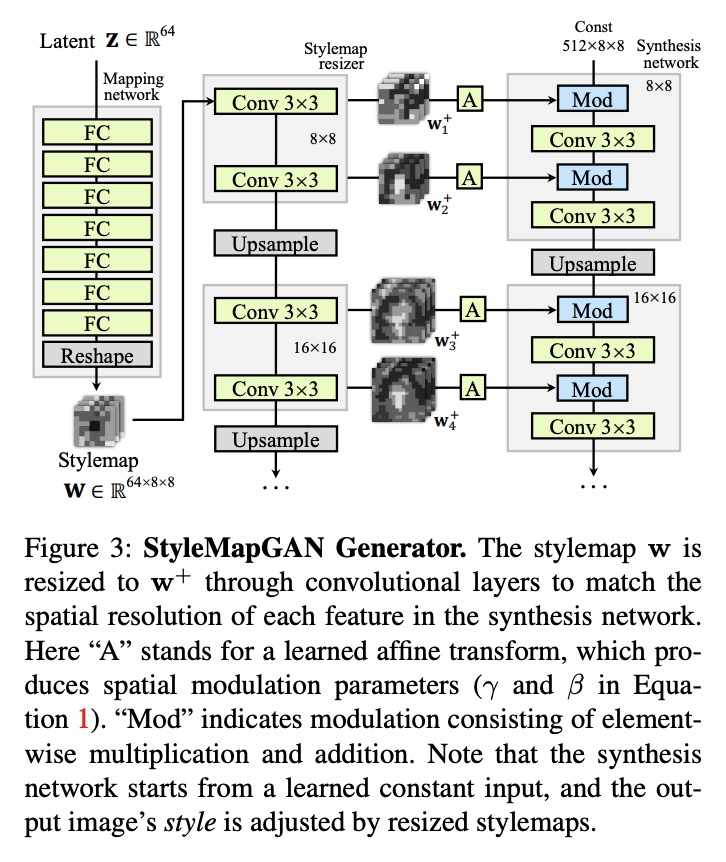
5、[CV] StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing
H Kim, Y Choi, J Kim, S Yoo, Y Uh
[NAVER AI Lab & Seoul National University & Yonsei University]
StyleMapGAN:基于GAN潜空间维度的实时图像编辑。生成对抗网络(GAN)从随机潜向量中合成真实图像。尽管操纵潜向量可控制合成的输出,但用GAN编辑真实图像存在以下问题:i)将真实图像投射到潜向量上的耗时优化;ii)编码器的不准确嵌入。本文提出StyleMapGAN:中间潜空间具有空间维度,用空间变分调制取代AdaIN。使通过编码器的嵌入比现有基于优化方法更准确,同时保持GAN的特性。实验结果表明,该方法在各种图像处理任务(如局部编辑和图像插值)中明显优于最先进模型。
Generative adversarial networks (GANs) synthesize realistic images from random latent vectors. Although manipulating the latent vectors controls the synthesized outputs, editing real images with GANs suffers from i) timeconsuming optimization for projecting real images to the latent vectors, ii) or inaccurate embedding through an encoder. We propose StyleMapGAN: the intermediate latent space has spatial dimensions, and a spatially variant modulation replaces AdaIN. It makes the embedding through an encoder more accurate than existing optimization-based methods while maintaining the properties of GANs. Experimental results demonstrate that our method significantly outperforms state-of-the-art models in various image manipulation tasks such as local editing and image interpolation. Last but not least, conventional editing methods on GANs are still valid on our StyleMapGAN. Source code is available at https://github.com/naver-ai/ StyleMapGAN .
https://weibo.com/1402400261/KdR6H3jre

另外几篇值得关注的论文:
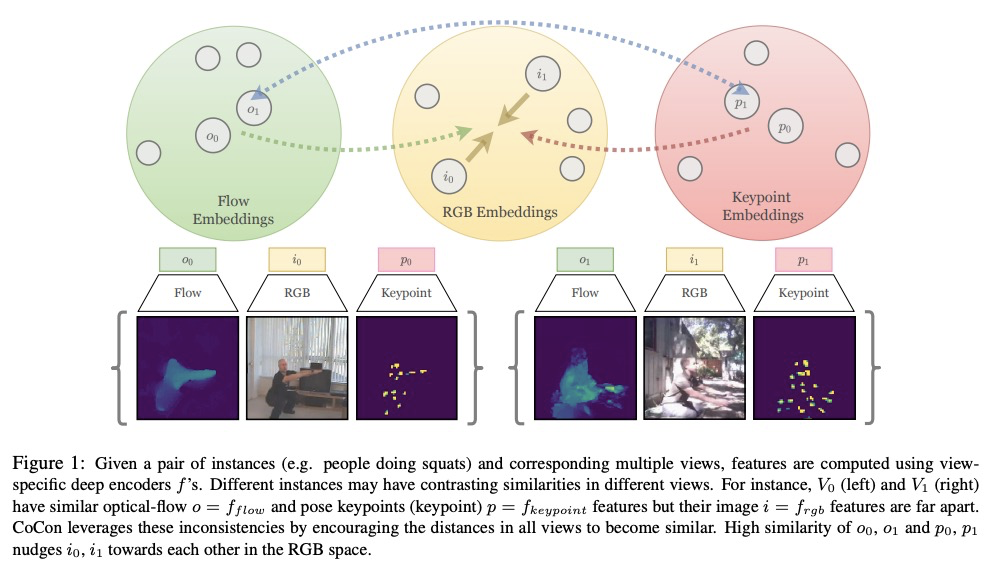
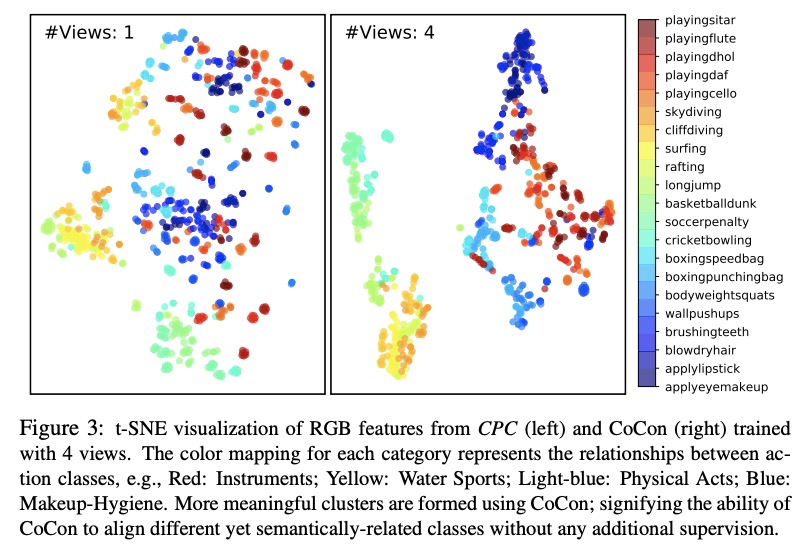
[CV] CoCon: Cooperative-Contrastive Learning
CoCon:合作对比学习
N Rai, E Adeli, K Lee, A Gaidon, J C Niebles
[Stanford University & Toyota Research Institute]
https://weibo.com/1402400261/KdRcUCYbw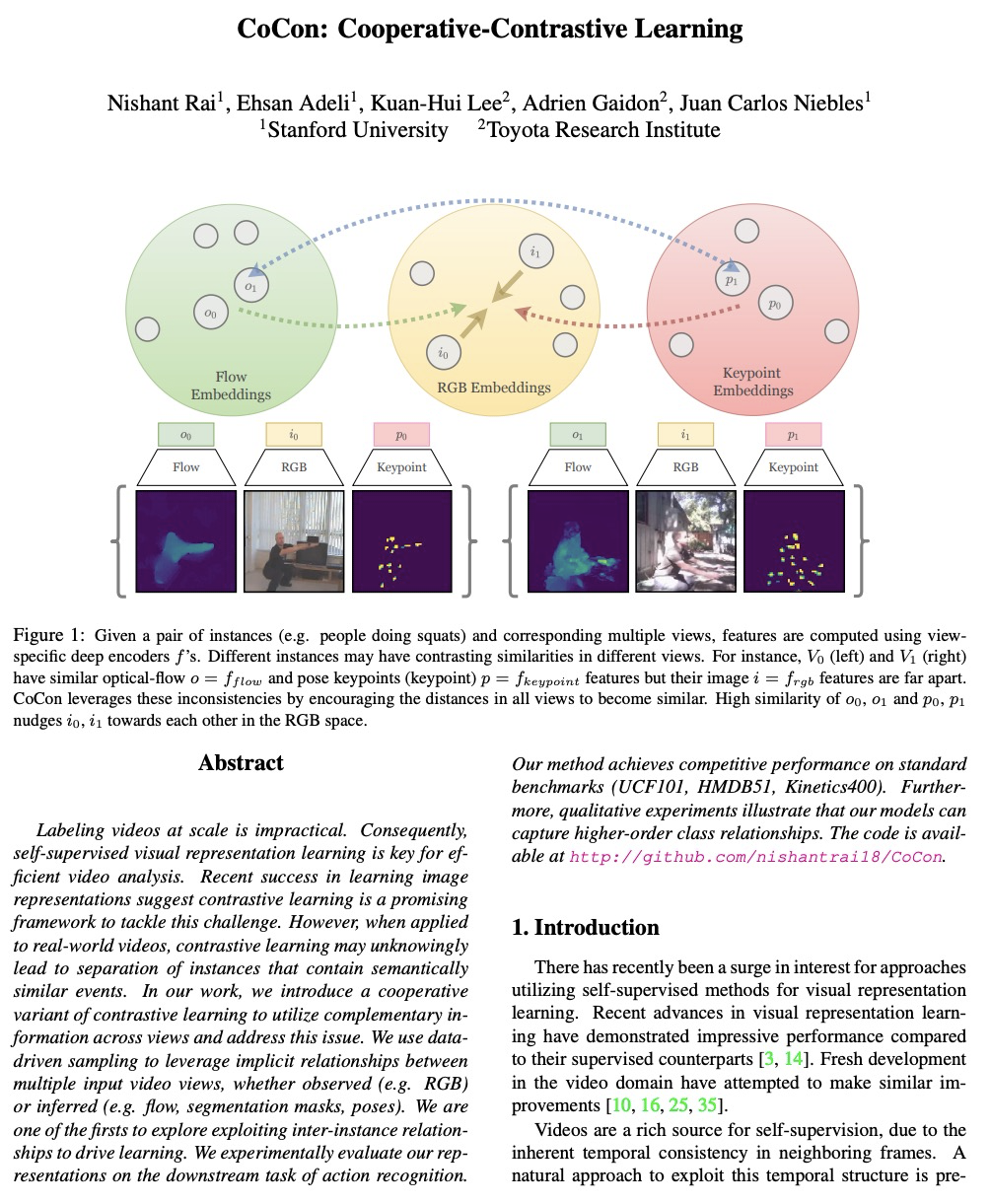

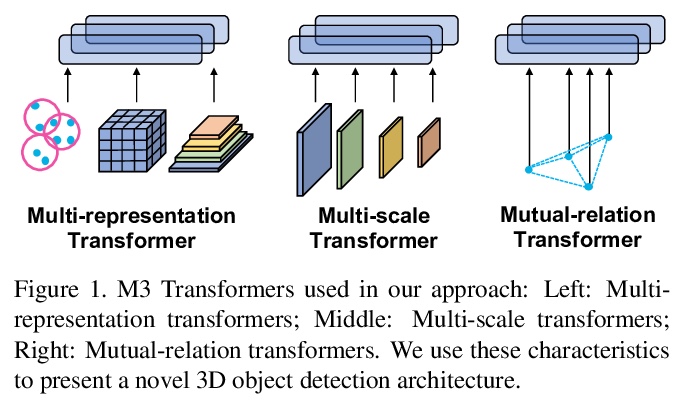
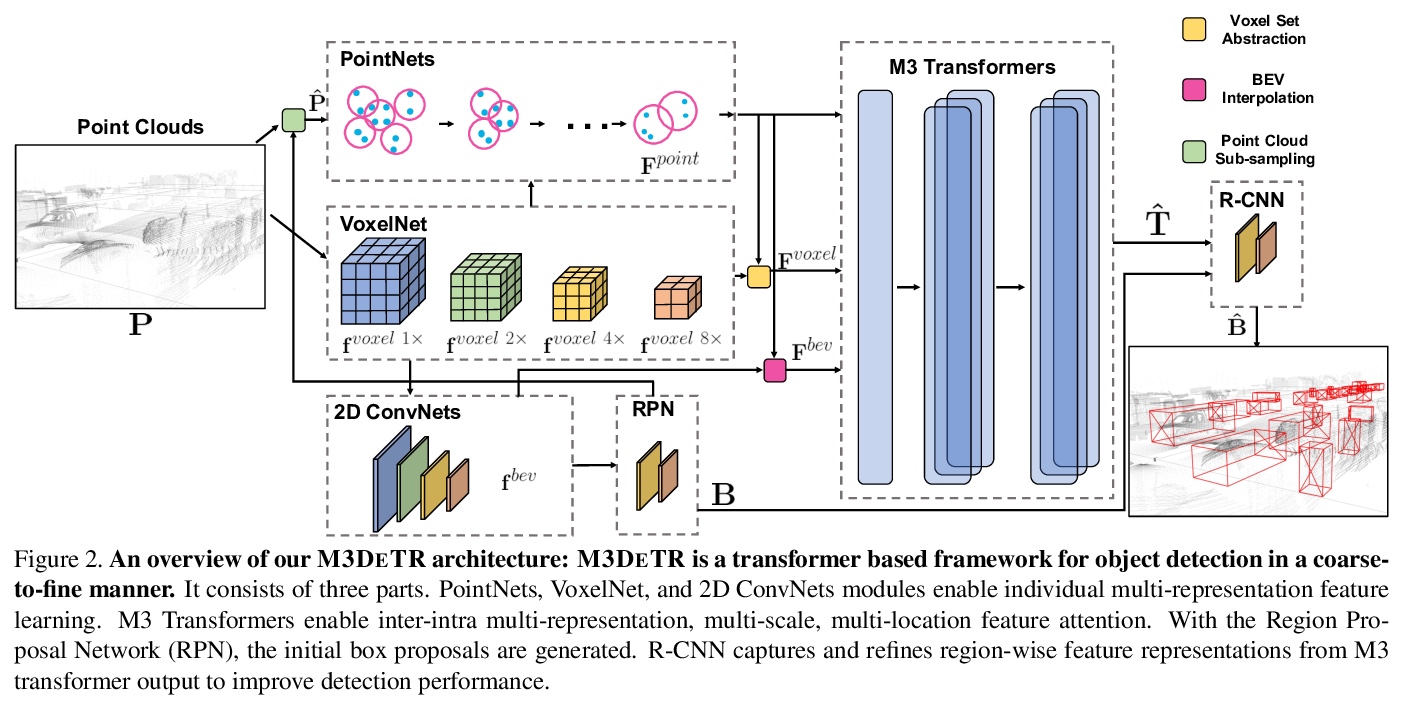
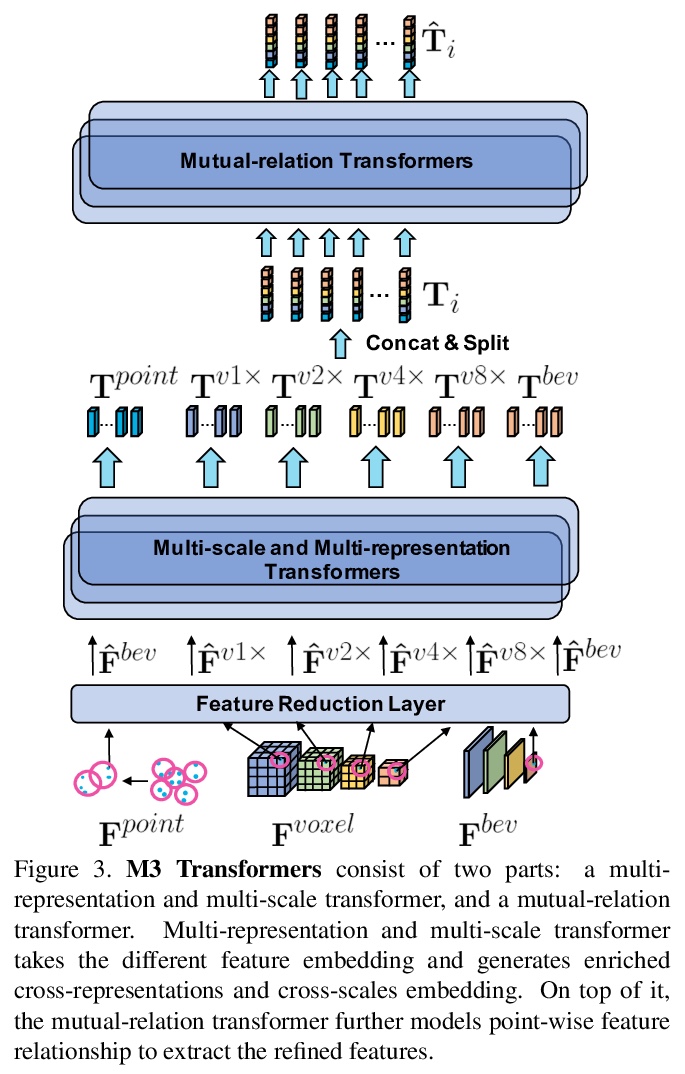
[CV] M3DeTR: Multi-representation, Multi-scale, Mutual-relation 3D Object Detection with Transformers
M3DeTR:基于Transformer的多表示多尺度互关联三维目标检测
T Guan, J Wang, S Lan, R Chandra, Z Wu, L Davis, D Manocha
[University of Maryland & Fudan University]
https://weibo.com/1402400261/KdReWfitG

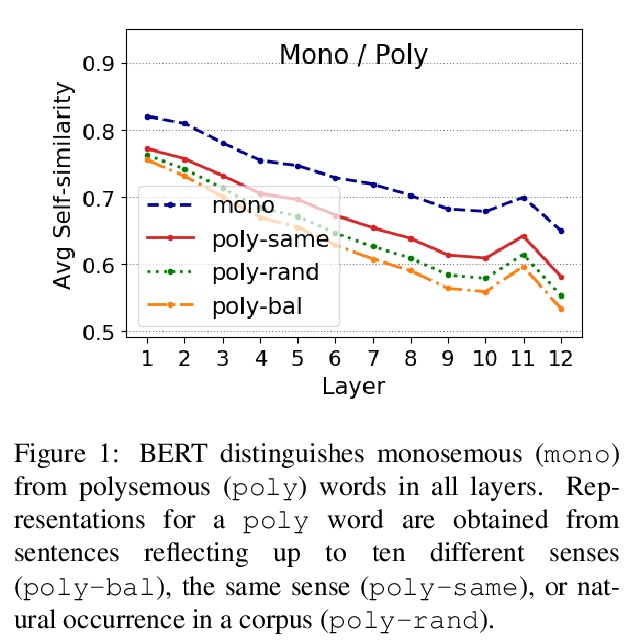
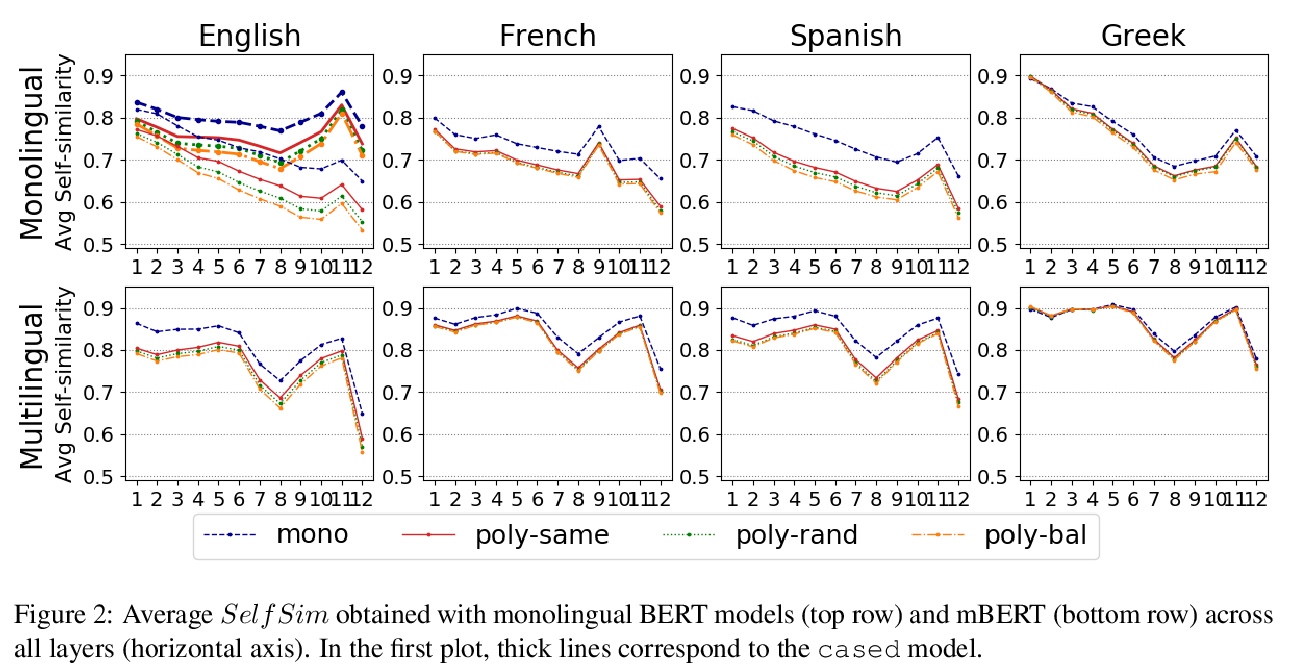
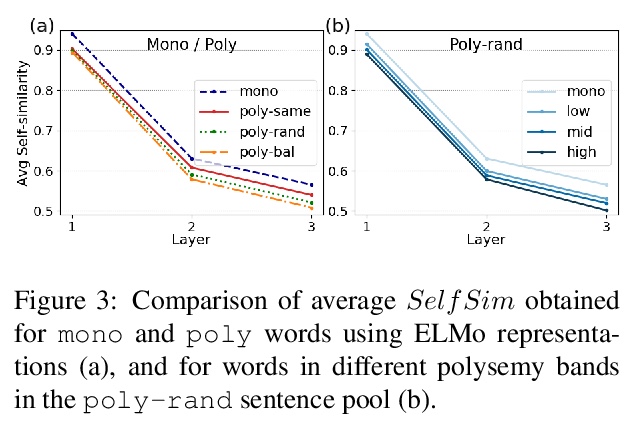
[CL] Let’s Play Mono-Poly: BERT Can Reveal Words’ Polysemy Level and Partitionability into Senses
用BERT揭示单词的多义性水平和意义可分性
A G Soler, M Apidianaki
[Université Paris-Saclay & University of Helsinki]
https://weibo.com/1402400261/KdRgBlKyU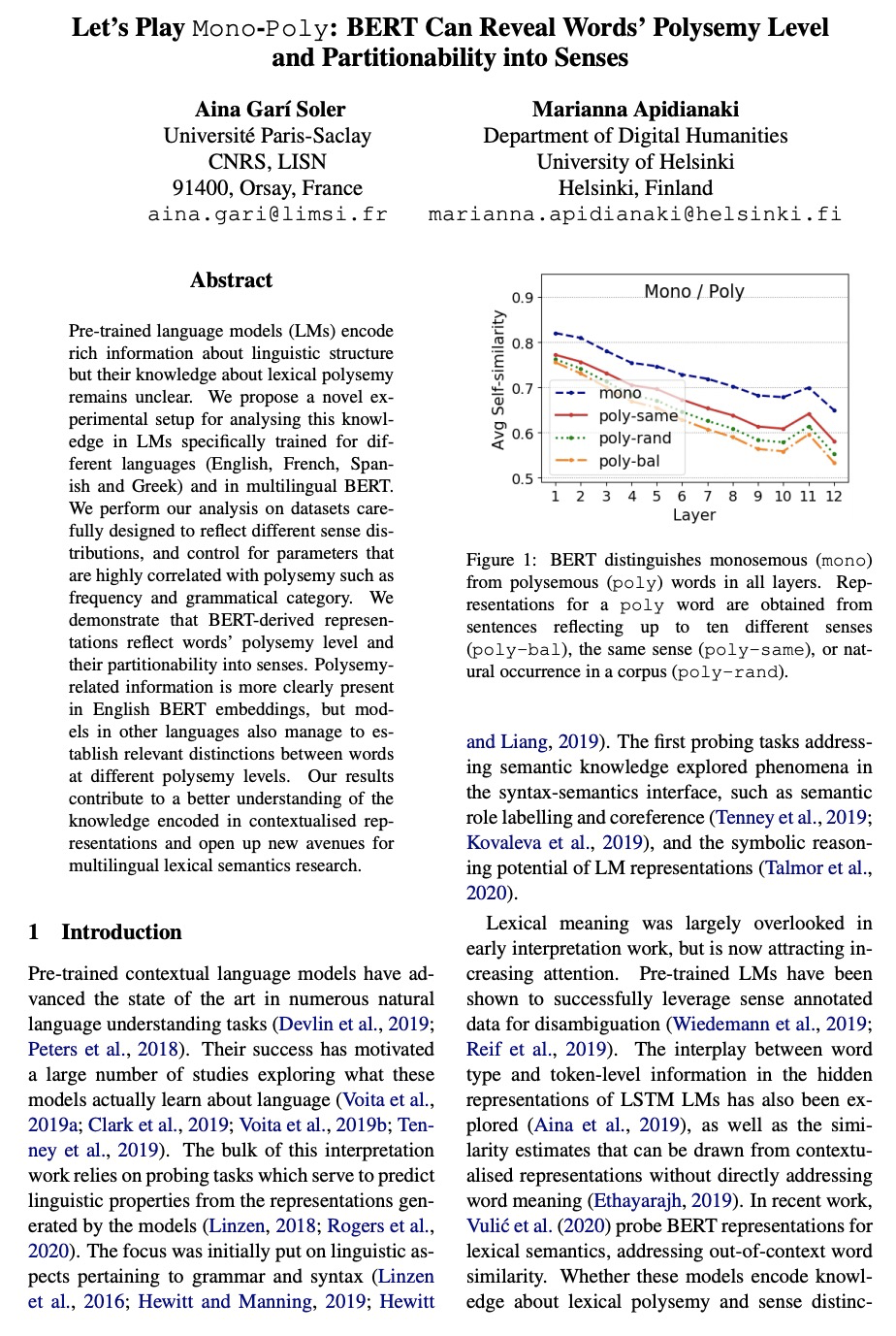
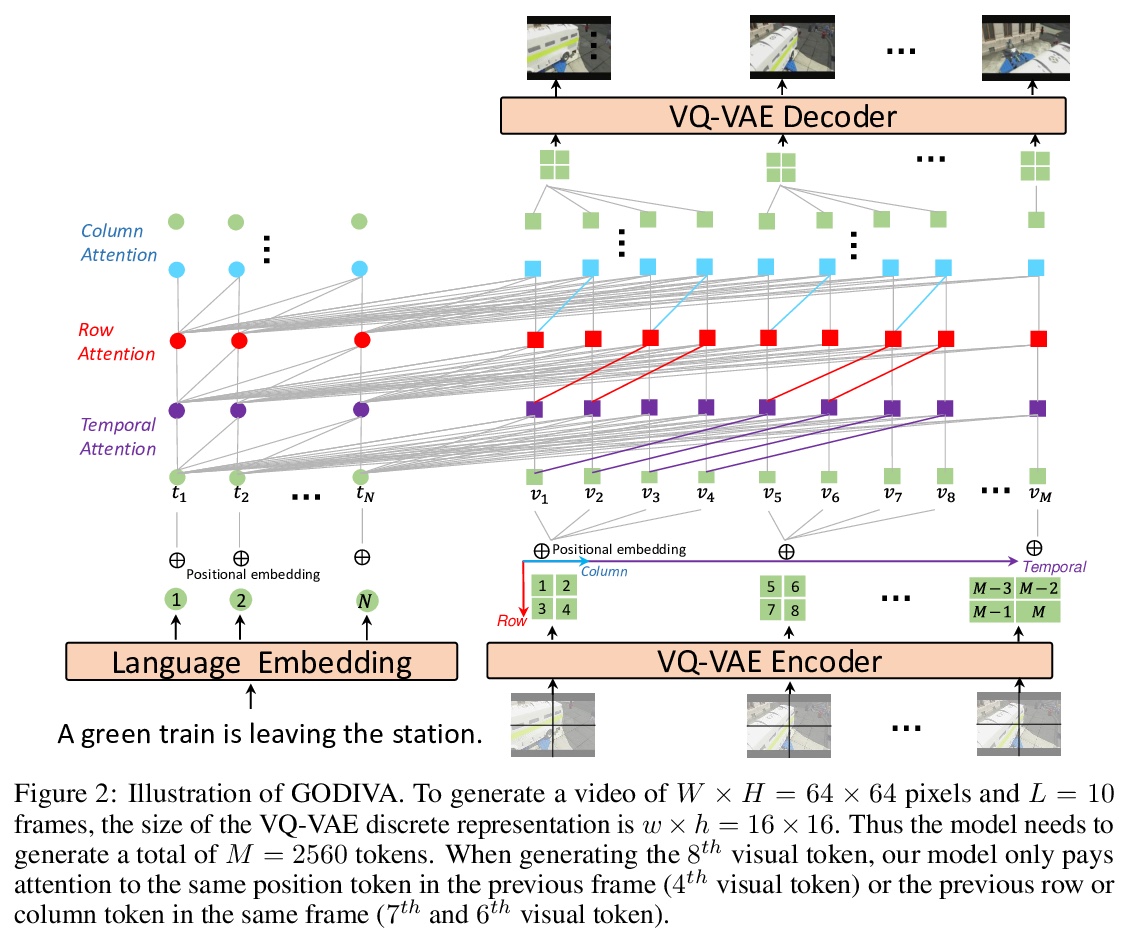
[CV] GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions
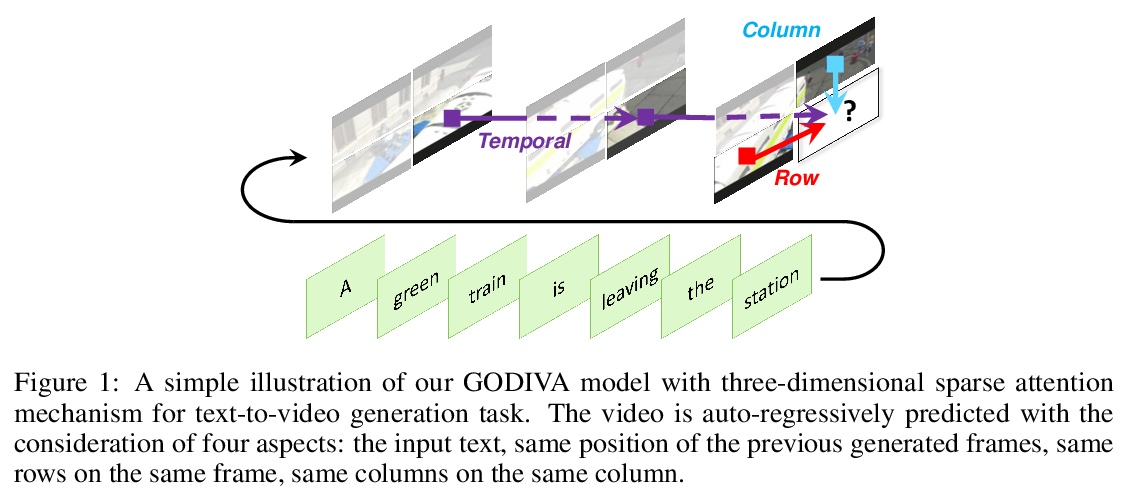
GODIVA:从自然描述生成开放域视频
C Wu, L Huang, Q Zhang, B Li, L Ji, F Yang, G Sapiro, N Duan
[Microsoft Research Asia & Duke University]
https://weibo.com/1402400261/KdRiE7ORV



若有收获,就点个赞吧
0 人点赞
