- 1、[LG] Regularization is all you Need: Simple Neural Nets can Excel on Tabular Data
- 2、[LG] Revisiting Deep Learning Models for Tabular Data
- 3、[LG] Randomness In Neural Network Training: Characterizing The Impact of Tooling
- 4、[LG] Dangers of Bayesian Model Averaging under Covariate Shift
- 5、[CV] Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
- [CV] DocFormer: End-to-End Transformer for Document Understanding
- [CV] Towards Reducing Labeling Cost in Deep Object Detection
- [CV] Unsupervised Object-Level Representation Learning from Scene Images
- [CV] A Latent Transformer for Disentangled and Identity-Preserving Face Editing
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] Regularization is all you Need: Simple Neural Nets can Excel on Tabular Data
A Kadra, M Lindauer, F Hutter, J Grabocka
[University of Freiburg & Leibniz University Hannover]
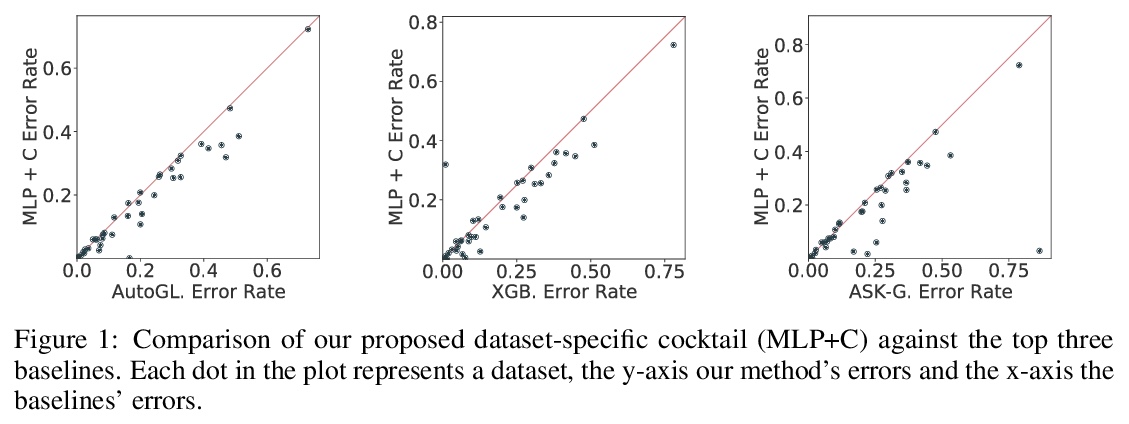
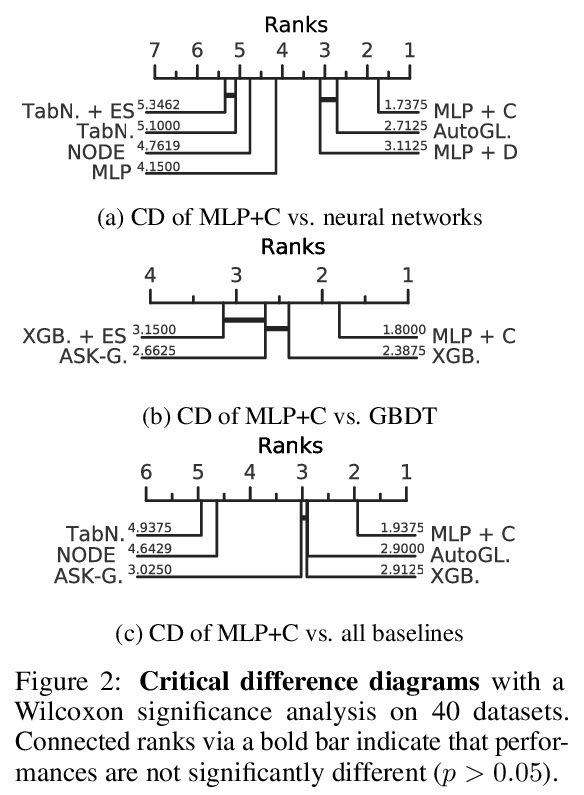
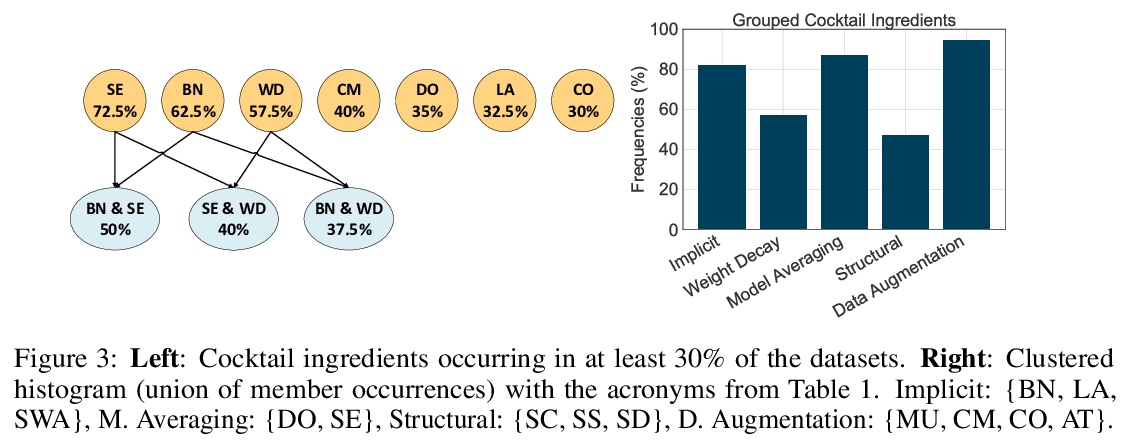
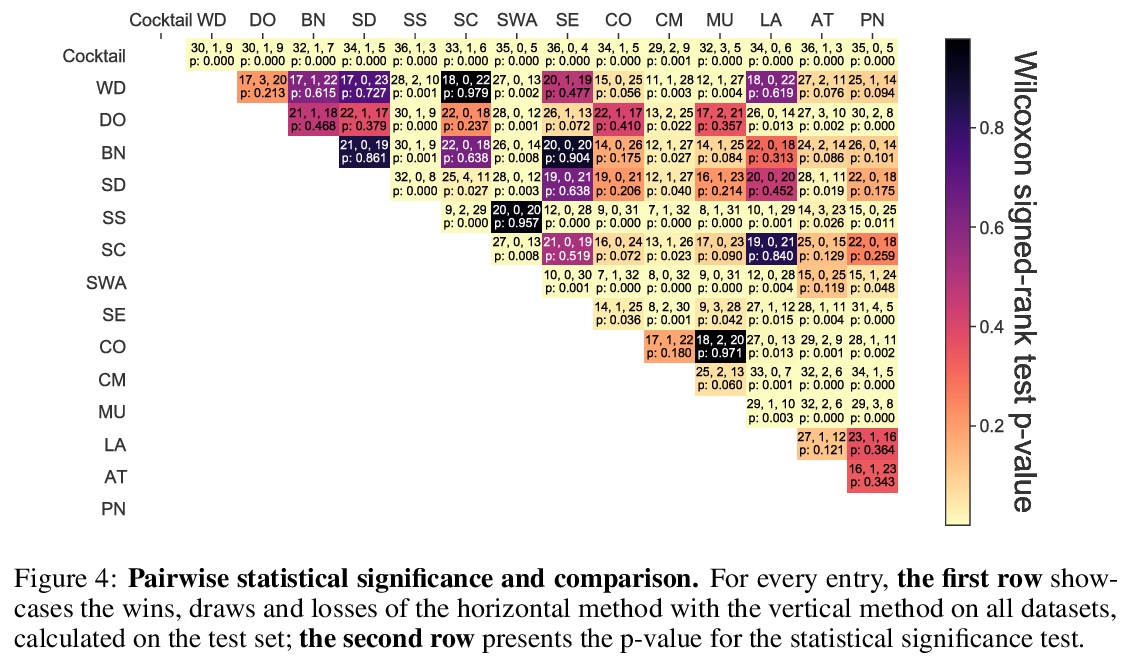
正则化就够了:简单神经网络可以在表格数据上表现出色。表格数据集是深度学习最后一个”未攻克的堡垒”,传统机器学习方法,如梯度提升决策树,即使面对最近的专业神经架构,仍表现强劲。本文假设提升神经网络性能的关键,在于重新思考一整套现代正则化技术的联合及共用。通过为每个数据集寻找13种正则化技术的最佳组合/混合,对决定应用哪些正则化技术及其附属超参数进行联合优化,使普通多层感知器(MLP)网络正则化。在一项包括40个表格数据集的大规模实证研究中,评估了这些正则化混合方案对MLP的影响,并证明(i)经过良好正则化的普通MLP明显优于目前最先进的专业神经网络架构,(ii)甚至优于强大的传统机器学习方法,如XGBoost。
Tabular datasets are the last “unconquered castle” for deep learning, with traditional ML methods like Gradient-Boosted Decision Trees still performing strongly even against recent specialized neural architectures. In this paper, we hypothesize that the key to boosting the performance of neural networks lies in rethinking the joint and simultaneous application of a large set of modern regularization techniques. As a result, we propose regularizing plain Multilayer Perceptron (MLP) networks by searching for the optimal combination/cocktail of 13 regularization techniques for each dataset using a joint optimization over the decision on which regularizers to apply and their subsidiary hyperparameters. We empirically assess the impact of these regularization cocktails for MLPs on a large-scale empirical study comprising 40 tabular datasets and demonstrate that (i) well-regularized plain MLPs significantly outperform recent state-of-the-art specialized neural network architectures, and (ii) they even outperform strong traditional ML methods, such as XGBoost.
https://weibo.com/1402400261/KlBh8e0aX
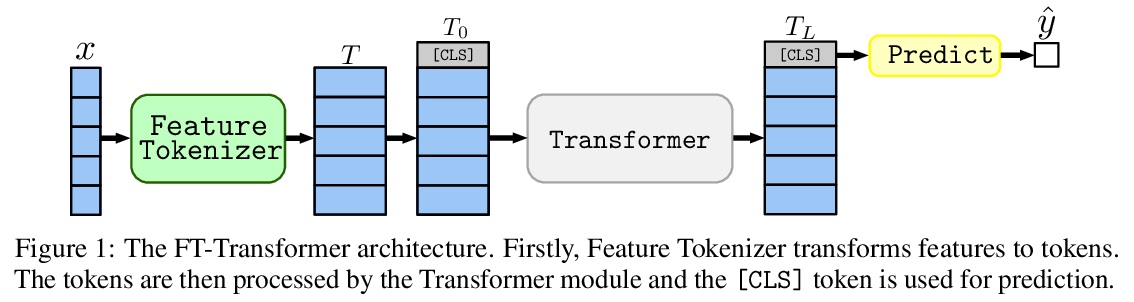
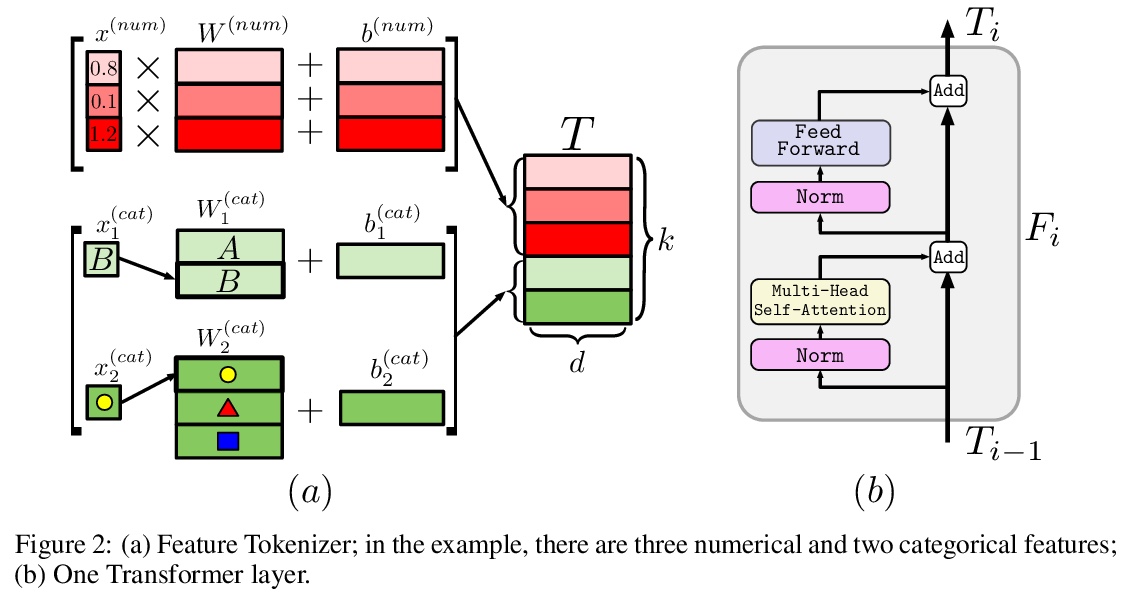
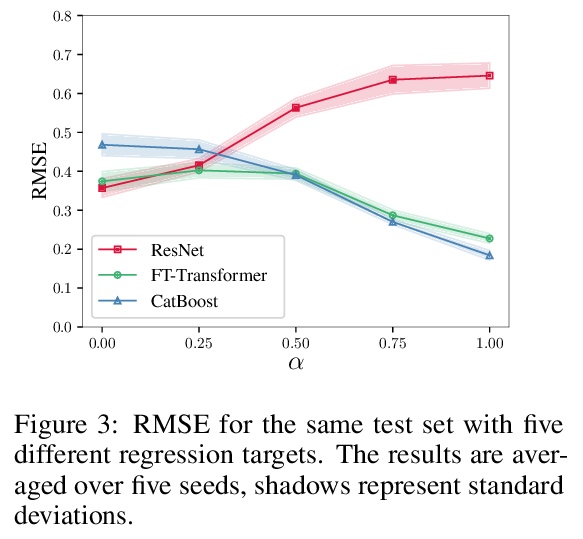
2、[LG] Revisiting Deep Learning Models for Tabular Data
Y Gorishniy, I Rubachev, V Khrulkov, A Babenko
[Yandex]
重新审视表格数据深度学习模型。深度学习对于表格数据的必要性,仍然是个集中了大量研究工作而尚未得到解决的问题。最近关于表格数据的文献提出了几个深度架构,据说比传统的”浅层”模型(如梯度提升决策树)要好。然而,由于现有的工作经常使用不同的基准和微调协议,目前还不清楚所提出的模型是否普遍地优于GBDT。此外,这些模型往往没有相互比较,因此,为从业者确定最佳的深度模型是具有挑战性的。本文彻底回顾了最近为表格数据开发的深度学习模型族。在广泛的数据集上仔细微调和评估它们,揭示了两个重要发现。首先,在GBDT和深度学习模型之间的选择高度依赖于数据,仍然没有普遍优越的解决方案。其次,证明了一个简单的类似于ResNet的架构是令人惊讶的有效基线,优于深度学习文献中的大多数复杂模型。为表格数据设计了一个简单的Transformer架构,成为一个新的强大的深度学习基线,并在GBDT占主导地位的数据集上缩小了GBDT和深度学习模型之间的差距。
The necessity of deep learning for tabular data is still an unanswered question addressed by a large number of research efforts. The recent literature on tabular DL proposes several deep architectures reported to be superior to traditional “shallow” models like Gradient Boosted Decision Trees. However, since existing works often use different benchmarks and tuning protocols, it is unclear if the proposed models universally outperform GBDT. Moreover, the models are often not compared to each other, therefore, it is challenging to identify the best deep model for practitioners. In this work, we start from a thorough review of the main families of DL models recently developed for tabular data. We carefully tune and evaluate them on a wide range of datasets and reveal two significant findings. First, we show that the choice between GBDT and DL models highly depends on data and there is still no universally superior solution. Second, we demonstrate that a simple ResNet-like architecture is a surprisingly effective baseline, which outperforms most of the sophisticated models from the DL literature. Finally, we design a simple adaptation of the Transformer architecture for tabular data that becomes a new strong DL baseline and reduces the gap between GBDT and DL models on datasets where GBDT dominates.
https://weibo.com/1402400261/KlBkD6q2j
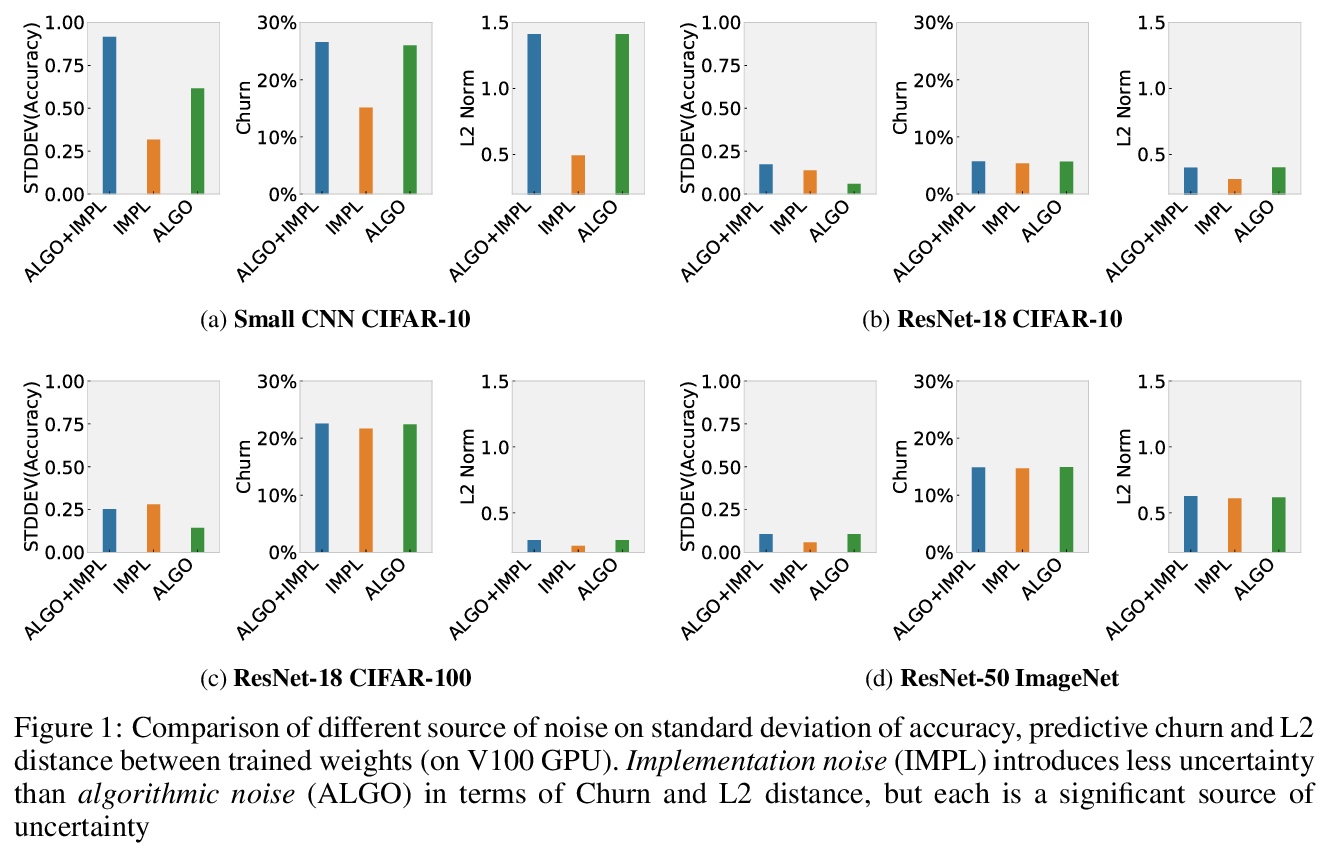
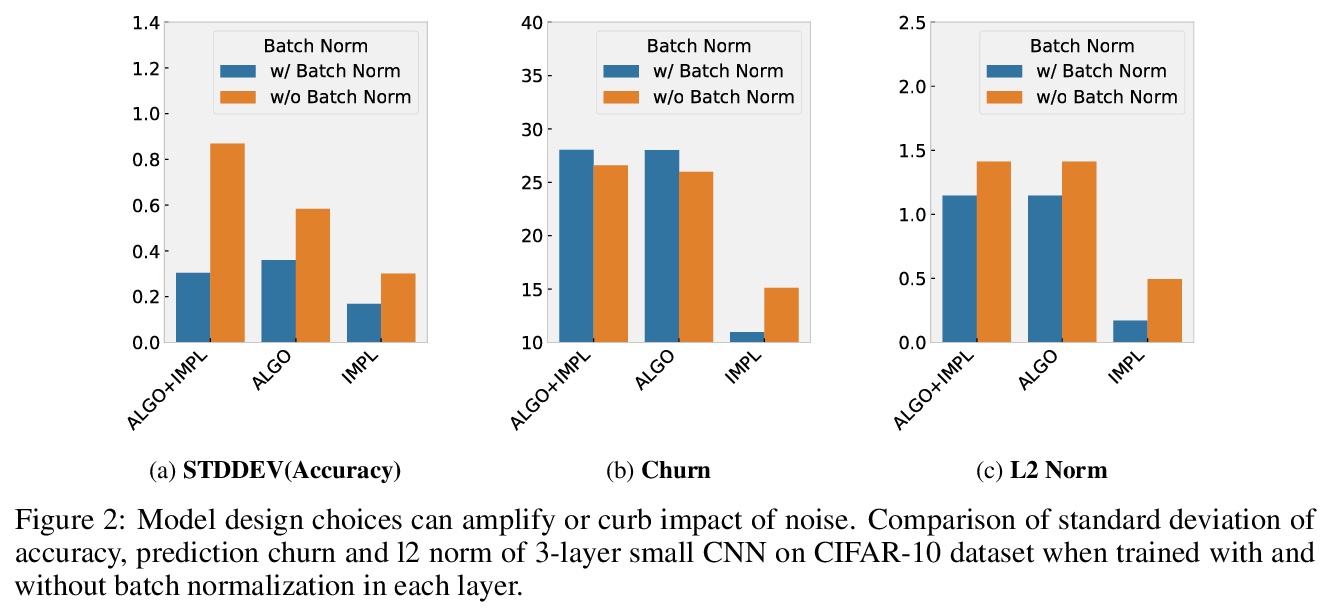
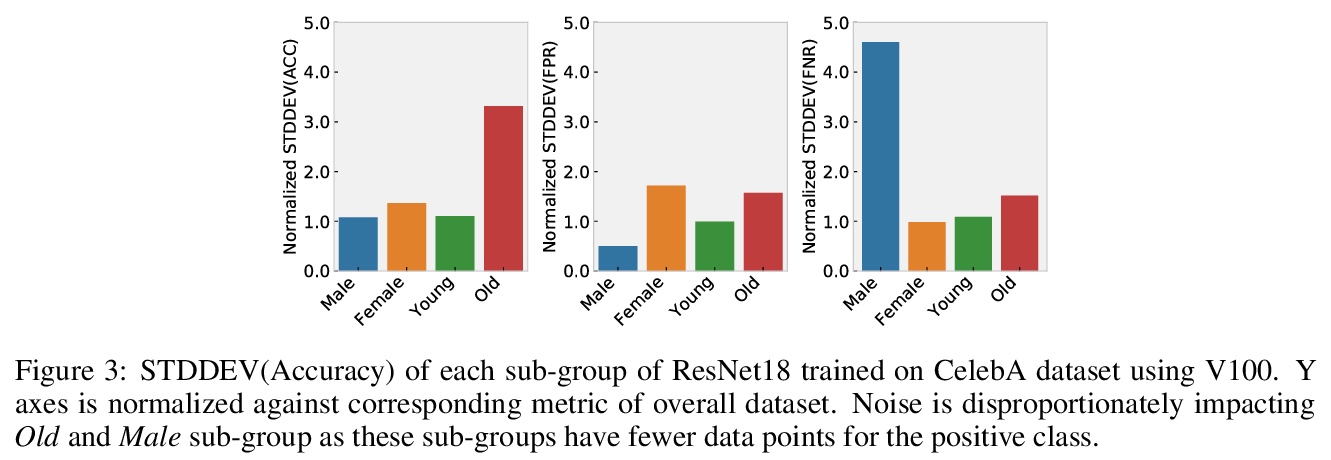
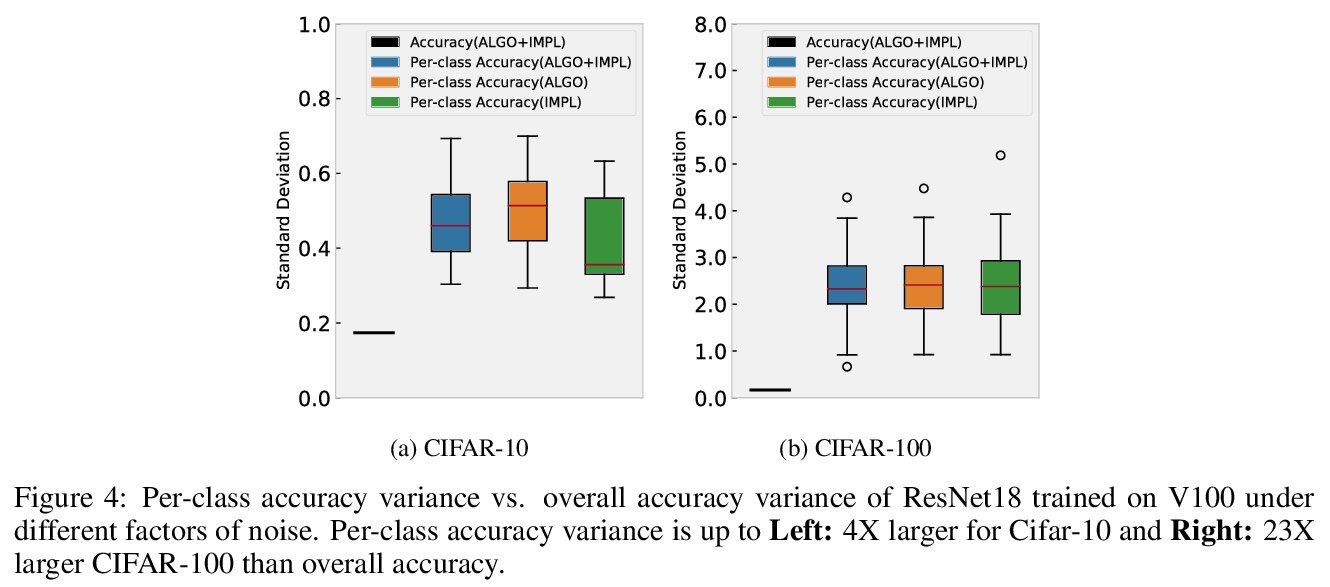
3、[LG] Randomness In Neural Network Training: Characterizing The Impact of Tooling
D Zhuang, X Zhang, S L Song, S Hooker
[The University of Sydney & University of Washington & Google Research]
神经网络训练的随机性:工具影响的刻画。对机器学习中确定性的追求,已经不成比例地集中在描述算法设计选择所引入噪音的影响上。本文解决了一个不太被理解和研究的问题:工具的选择如何将随机性引入深度神经网络训练。在不同类型的硬件、加速器、最先进的网络和开源数据集上进行了大规模实验,以确定工具的选择如何促进系统中的非确定性水平、所述非确定性的影响以及消除不同噪音来源的成本。最后的发现是令人惊讶的,非确定性的影响是细微的。虽然top-1的准确性等一线指标没有受到明显影响,但模型在数据分布的某些部分的性能,对随机性的引入要敏感得多。结果表明,确定性的工具对人工智能的安全性至关重要。确保确定性的成本在不同的神经网络架构和硬件类型之间有很大的差异,例如,相对于非确定性的训练,在广泛使用的GPU加速器架构上,开销高达746%、241%和196%。
The quest for determinism in machine learning has disproportionately focused on characterizing the impact of noise introduced by algorithmic design choices. In this work, we address a less well understood and studied question: how does our choice of tooling introduce randomness to deep neural network training. We conduct large scale experiments across different types of hardware, accelerators, state of art networks, and open-source datasets, to characterize how tooling choices contribute to the level of non-determinism in a system, the impact of said non-determinism, and the cost of eliminating different sources of noise. Our findings are surprising, and suggest that the impact of non-determinism in nuanced. While top-line metrics such as top-1 accuracy are not noticeably impacted, model performance on certain parts of the data distribution is far more sensitive to the introduction of randomness. Our results suggest that deterministic tooling is critical for AI safety. However, we also find that the cost of ensuring determinism varies dramatically between neural network architectures and hardware types, e.g., with overhead up to 746%, 241%, and 196% on a spectrum of widely used GPU accelerator architectures, relative to non-deterministic training.
https://weibo.com/1402400261/KlBnEu5oz
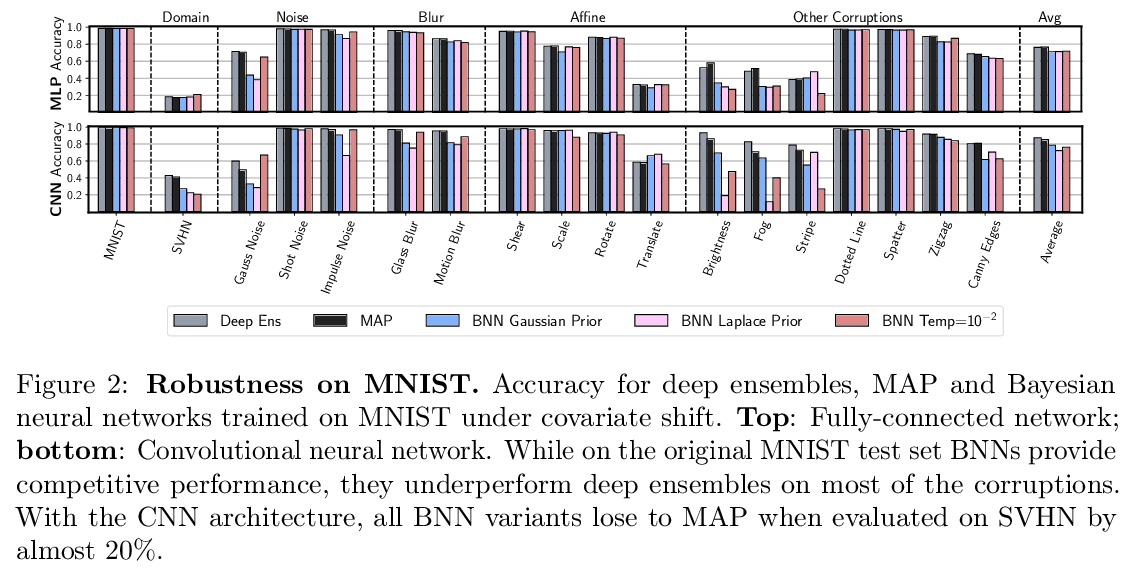
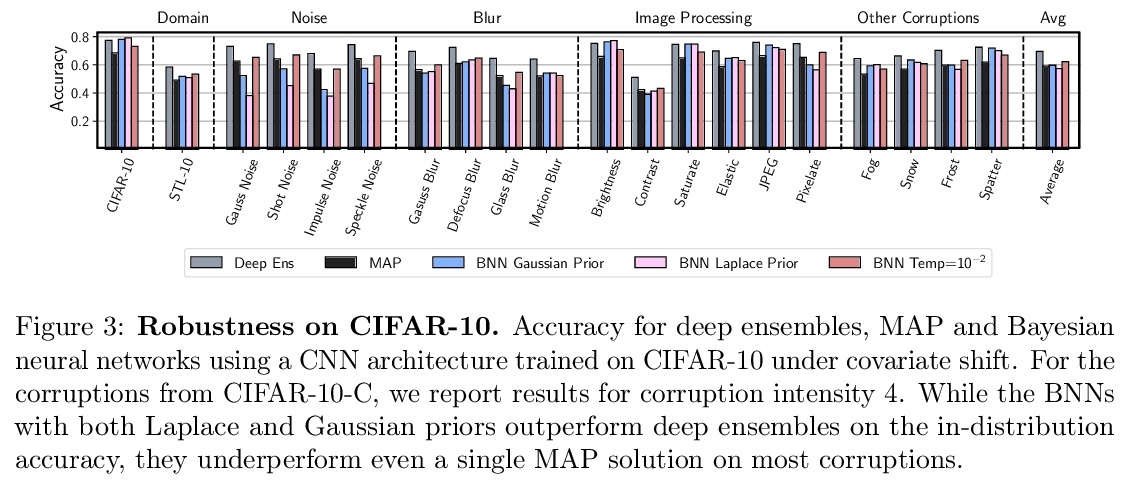
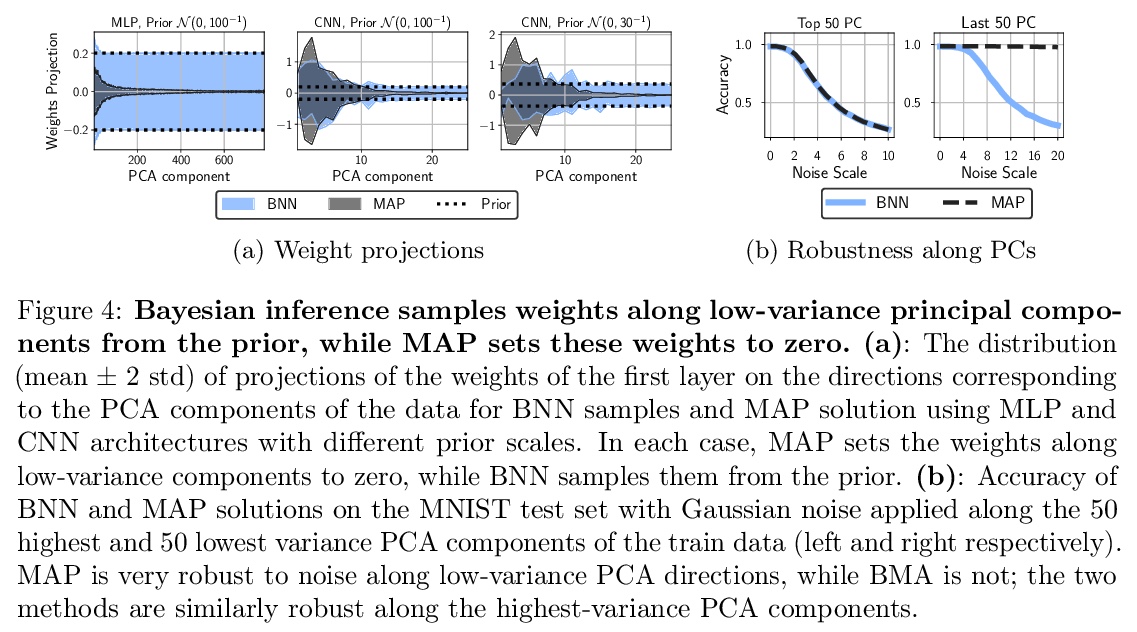
4、[LG] Dangers of Bayesian Model Averaging under Covariate Shift
P Izmailov, P Nicholson, S Lotfi, A G Wilson
[New York University & Stevens Capital Management]
协变量偏移下贝叶斯模型平均化的危险性。神经网络的近似贝叶斯推断,被认为是标准训练的鲁棒替代方案,通常在分布外数据上提供良好的性能。然而,通过全批量汉密尔顿蒙特卡洛进行高保真近似推理的贝叶斯神经网络(BNN)在协变量偏移下的泛化效果很差,甚至不如经典估计的表现。本文解释了这一令人惊讶的结果,表明贝叶斯模型的平均值在协变量偏移下实际上是有问题的,特别是在输入特征的线性依赖导致缺乏后验收缩的情况下。本文展示了为什么同样的问题不会影响许多近似推理程序或是经典最大后验(MAP)训练。提出了新的先验,提高了BNN对许多协变量偏移来源的鲁棒性。
Approximate Bayesian inference for neural networks is considered a robust alternative to standard training, often providing good performance on out-of-distribution data. However, Bayesian neural networks (BNNs) with high-fidelity approximate inference via full-batch Hamiltonian Monte Carlo achieve poor generalization under covariate shift, even underperforming classical estimation. We explain this surprising result, showing how a Bayesian model average can in fact be problematic under covariate shift, particularly in cases where linear dependencies in the input features cause a lack of posterior contraction. We additionally show why the same issue does not affect many approximate inference procedures, or classical maximum a-posteriori (MAP) training. Finally, we propose novel priors that improve the robustness of BNNs to many sources of covariate shift.
https://weibo.com/1402400261/KlBrGtgIe

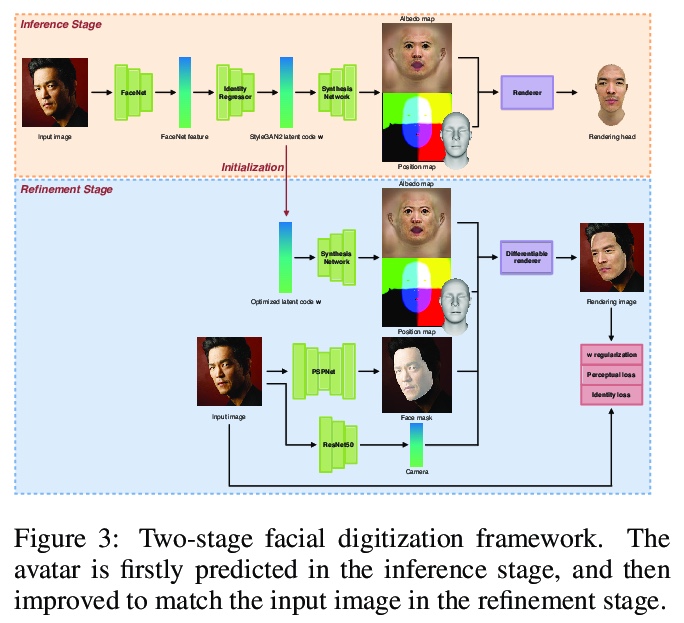
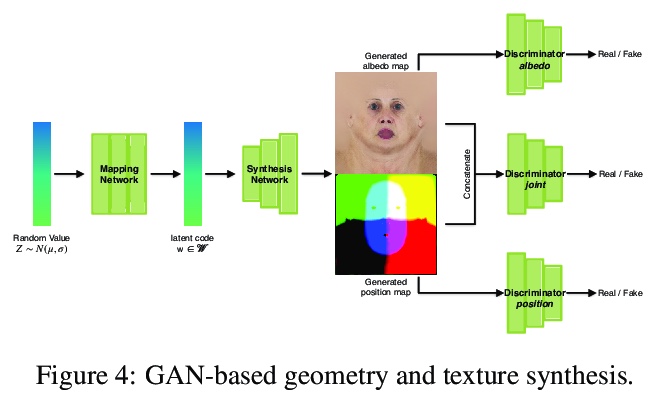
5、[CV] Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
H Luo, K Nagano, H Kung, M Goldwhite, Q Xu, Z Wang, L Wei, L Hu, H Li
[Pinscreen]
基于StyleGAN和感知细化的标准化3D头像合成。本文引入一个高度健壮的基于GAN的框架,用于从一张无约束的照片中数字化一个人的标准化3D头像。 输入图像可以是一个微笑的人,也可以是在极端光照条件下拍摄的,该方法可以在漫射光照条件下可靠地生成具有中性表情和皮肤纹理的人脸的高质量纹理模型。最新的3D人脸重建方法使用非线性可变形人脸模型结合基于GAN的解码器来捕捉人的肖像和细节,但无法生成具有无阴影反照率纹理的中性头部模型,这对于创建可重打光和动画友好的用于在虚拟环境中集成的化身至关重要。现有方法的主要挑战是缺乏包含归一化3D人脸的训练和真值数据。本文提出解决这个问题的两阶段方法。首先,通过将非线性可变形人脸模型嵌入到StyleGAN2网络中,采用高度鲁棒的标准化3D人脸生成器,生成详细但规范化的人脸模型。推断之后是一个感知上的细化步骤,使用生成的模型作为正则化,以应对有限的正常化人脸的可用训练样本。提出了规范化人脸数据集,由摄影测量扫描、精心挑选的照片以及在漫反射照明条件下生成的具有中性表情的假人组成,对于非常具有挑战性的无约束的输入图像,有可能产生高质量的归一化人脸模型,并显示出优于目前最先进的性能。
We introduce a highly robust GAN-based framework for digitizing a normalized 3D avatar of a person from a single unconstrained photo. While the input image can be of a smiling person or taken in extreme lighting conditions, our method can reliably produce a high-quality textured model of a person’s face in neutral expression and skin textures under diffuse lighting condition. Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments. The key challenges for existing methods to work is the lack of training and ground truth data containing normalized 3D faces. We propose a Hao Li is affiliated with Pinscreen and UC Berkeley; Koki Nagano is currently at NVIDIA. This work was fully conducted at Pinscreen. two-stage approach to address this problem. First, we adopt a highly robust normalized 3D face generator by embedding a non-linear morphable face model into a StyleGAN2 network. This allows us to generate detailed but normalized facial assets. This inference is then followed by a perceptual refinement step that uses the generated assets as regularization to cope with the limited available training samples of normalized faces. We further introduce a Normalized Face Dataset, which consists of a combination photogrammetry scans, carefully selected photographs, and generated fake people with neutral expressions in diffuse lighting conditions. While our prepared dataset contains two orders of magnitude less subjects than cutting edge GAN-based 3D facial reconstruction methods, we show that it is possible to produce high-quality normalized face models for very challenging unconstrained input images, and demonstrate superior performance to the current state-of-the-art.
https://weibo.com/1402400261/KlBwH3bUC


另外几篇值得关注的论文:
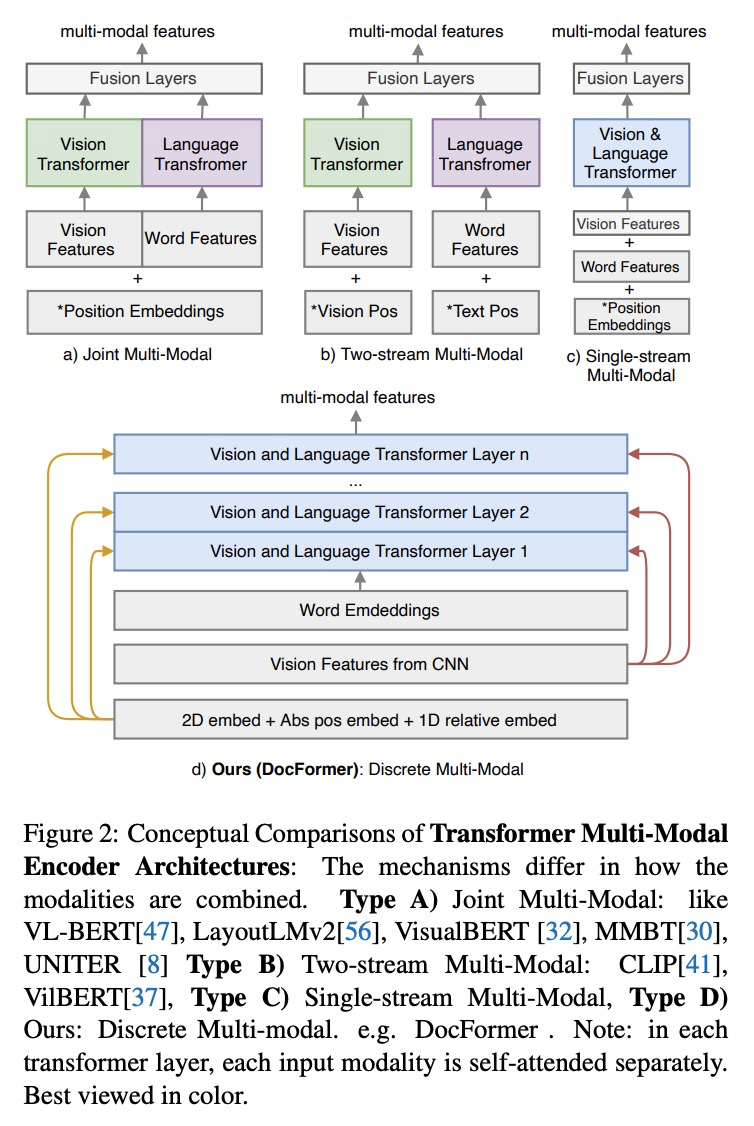
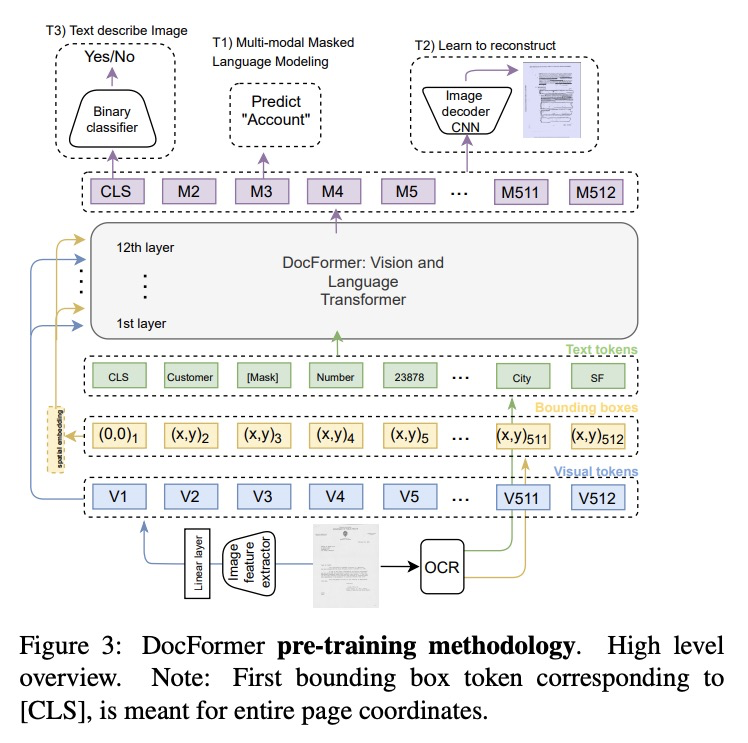
[CV] DocFormer: End-to-End Transformer for Document Understanding
DocFormer:面向文档理解的端到端Transformer
S Appalaraju, B Jasani, B U Kota, Y Xie, R. Manmatha
[AWS AI]
https://weibo.com/1402400261/KlBDCFDoP


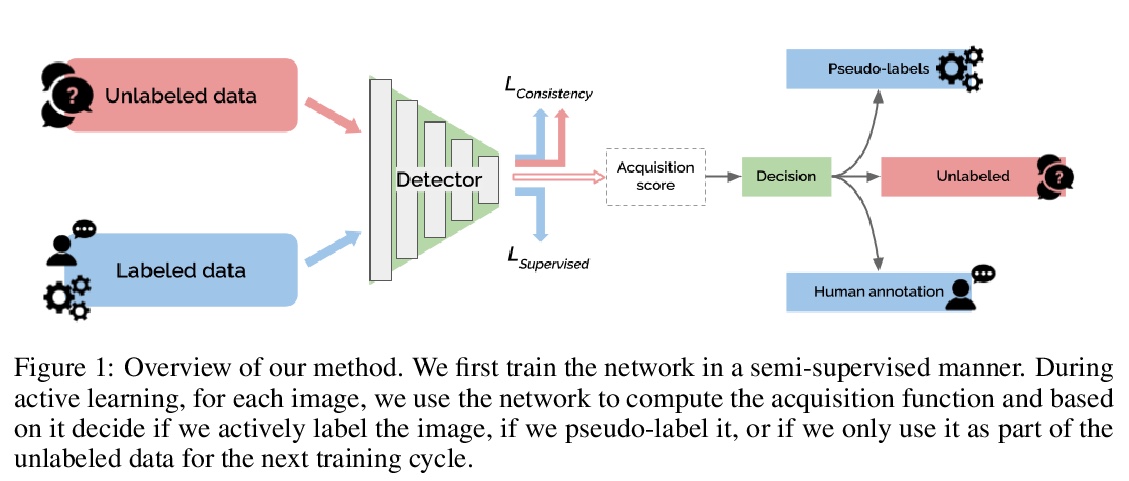
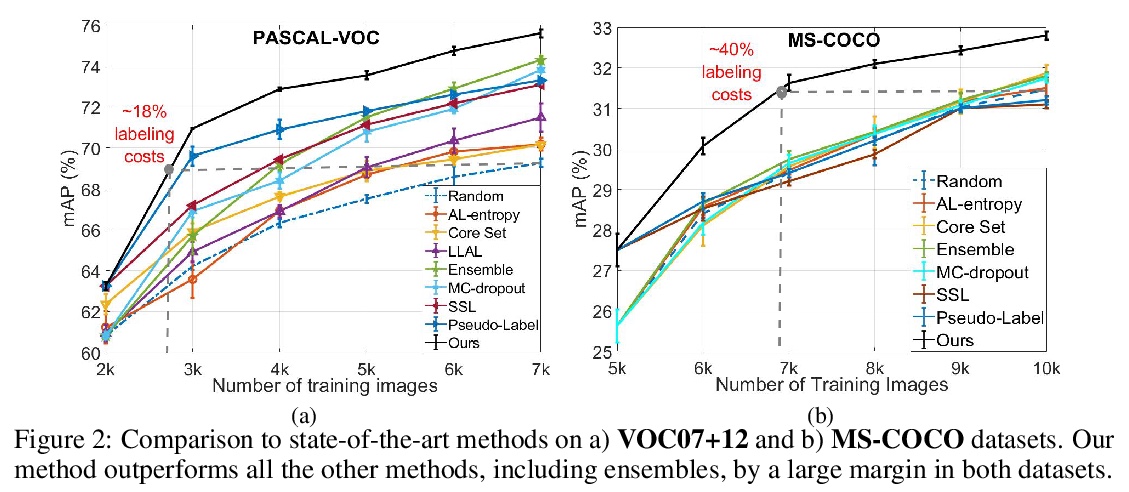
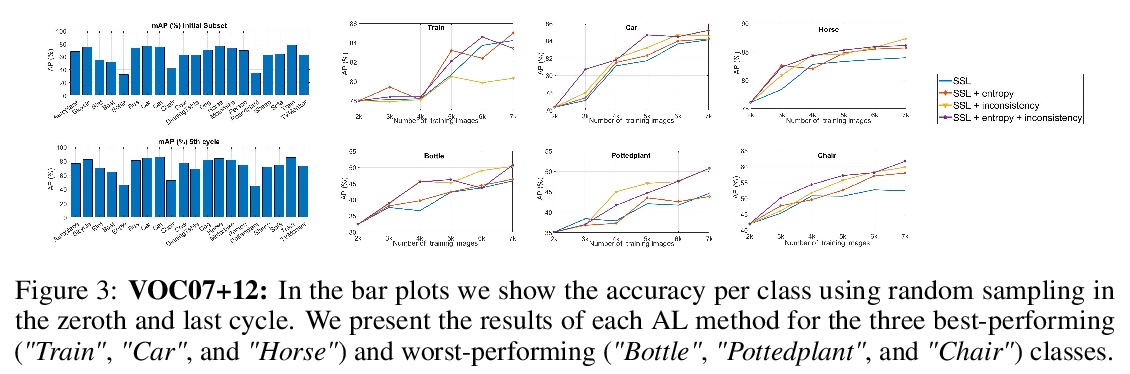
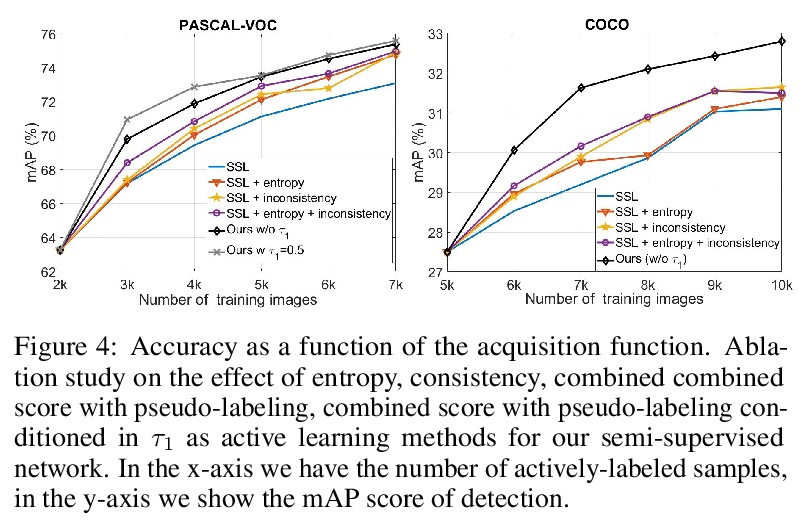
[CV] Towards Reducing Labeling Cost in Deep Object Detection
降低深度目标检测中的标记成本
I Elezi, Z Yu, A Anandkumar, L Leal-Taixe, J M. Alvarez
[TUM & NVIDIA]
https://weibo.com/1402400261/KlBEX4189
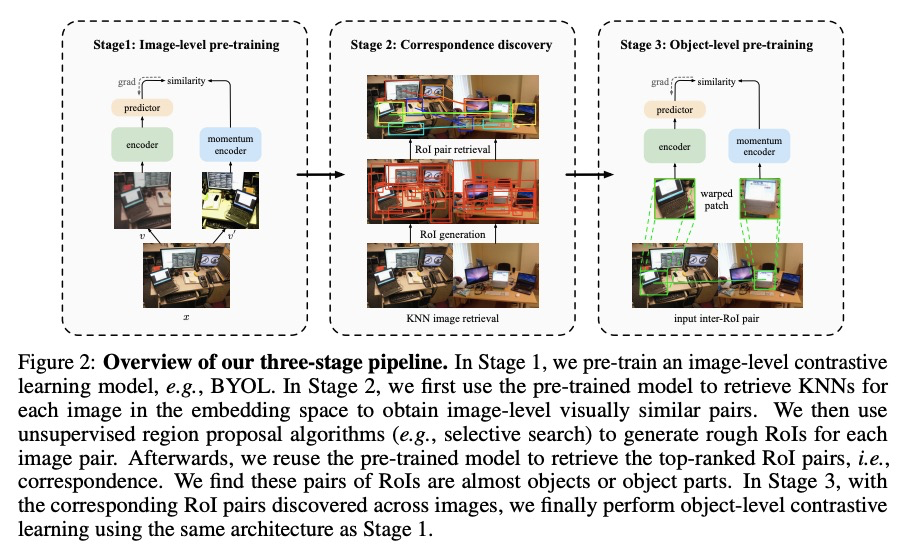
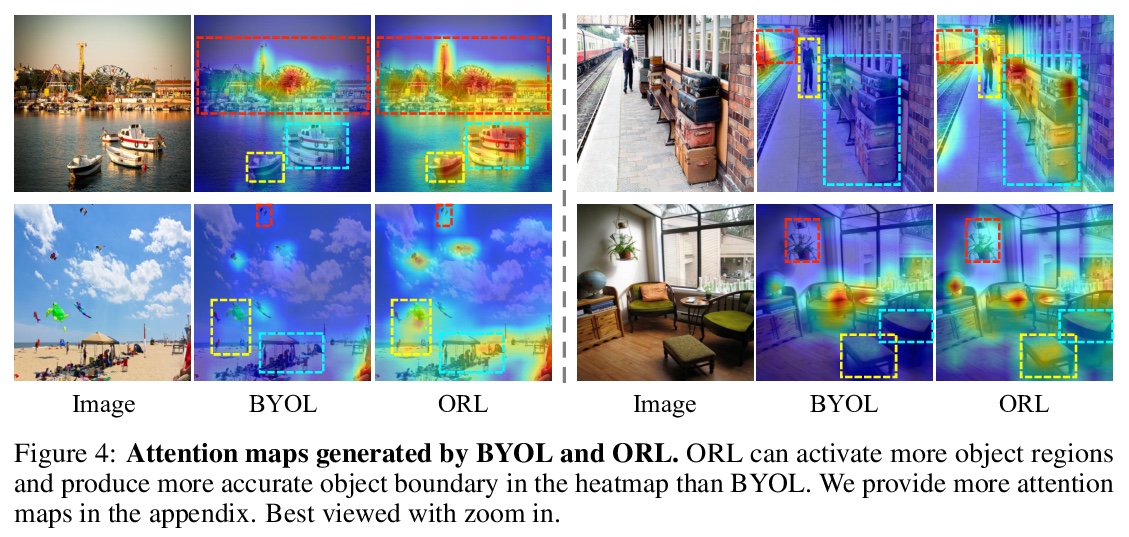
[CV] Unsupervised Object-Level Representation Learning from Scene Images
场景图像无监督目标级表示学习
J Xie, X Zhan, Z Liu, Y S Ong, C C Loy
[Nanyang Technological University & The Chinese University of Hong Kong]
https://weibo.com/1402400261/KlBGug9SO


[CV] A Latent Transformer for Disentangled and Identity-Preserving Face Editing
面向人脸编辑身份解缠与保持的潜Transformer
X Yao, A Newson, Y Gousseau, P Hellier
[Institut Polytechnique de Paris]
https://weibo.com/1402400261/KlBJ8dQgb





若有收获,就点个赞吧
0 人点赞
