- 1、[CL] Making Pre-trained Language Models Better Few-shot Learners
- 2、[CV] Information-Theoretic Segmentation by Inpainting Error Maximization
- 3、[CL] Studying Strategically: Learning to Mask for Closed-book QA
- 4、[CV] NeuralMagicEye: Learning to See and Understand the Scene Behind an Autostereogram
- 5、[LG] Is Pessimism Provably Efficient for Offline RL?
- [LG] Combinatorial Pure Exploration with Full-bandit Feedback and Beyond: Solving Combinatorial Optimization under Uncertainty with Limited Observation
- [CL] Linguistic calibration through metacognition: aligning dialogue agent responses with expected correctness
- [CL] Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection
- [CV] Sparse Signal Models for Data Augmentation in Deep Learning ATR
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] Making Pre-trained Language Models Better Few-shot Learners
T Gao, A Fisch, D Chen
[Princeton University & MIT]
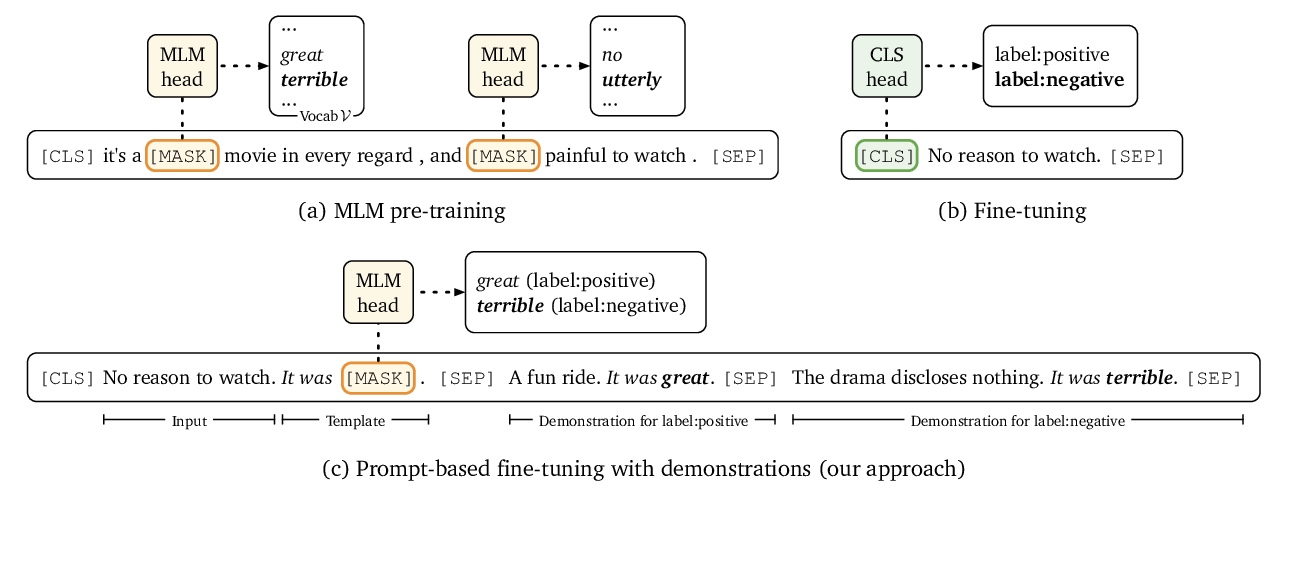
让预训练语言模型成为更好的少样本学习器。提出LM-BFF,一套简单有效只需少量样本的语言模型微调技术。LM-BFF方法建议(1)用基于提示(prompt)的微调自动搜索提示;(2)将动态选择的任务示范(训练样本)作为输入上下文的一部分。通过一系列系统评价表明,该方法比vanilla微调的性能高出30%(平均11%)。
The recent GPT-3 model (Brown et al., 2020) achieves remarkable few-shot performance solely by leveraging a natural-language prompt and a few task demonstrations as input context. Inspired by their findings, we study few-shot learning in a more practical scenario, where we use smaller language models for which fine-tuning is computationally efficient. We present LM-BFF—better few-shot fine-tuning of language models—a suite of simple and complementary techniques for fine-tuning language models on a small number of annotated examples. Our approach includes (1) prompt-based fine-tuning together with a novel pipeline for automating prompt generation; and (2) a refined strategy for dynamically and selectively incorporating demonstrations into each context. Finally, we present a systematic evaluation for analyzing few-shot performance on a range of NLP tasks, including classification and regression. Our experiments demonstrate that our methods combine to dramatically outperform standard fine-tuning procedures in this low resource setting, achieving up to 30% absolute improvement, and 11% on average across all tasks. Our approach makes minimal assumptions on task resources and domain expertise, and hence constitutes a strong task-agnostic method for few-shot learning.
https://weibo.com/1402400261/JByForref
2、[CV] Information-Theoretic Segmentation by Inpainting Error Maximization
P Savarese, S S. Y. Kim, M Maire, G Shakhnarovich, D McAllester
[TTI-Chicago & Princeton University & University of Chicago]
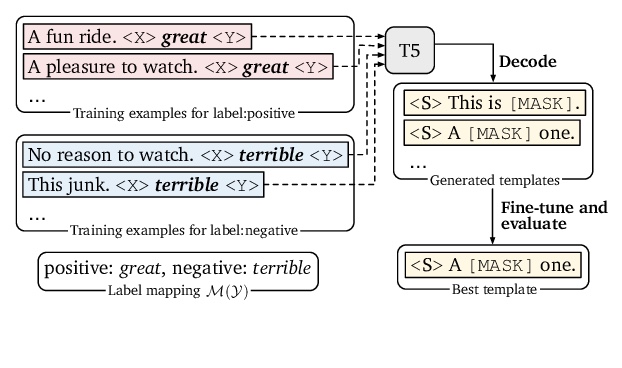
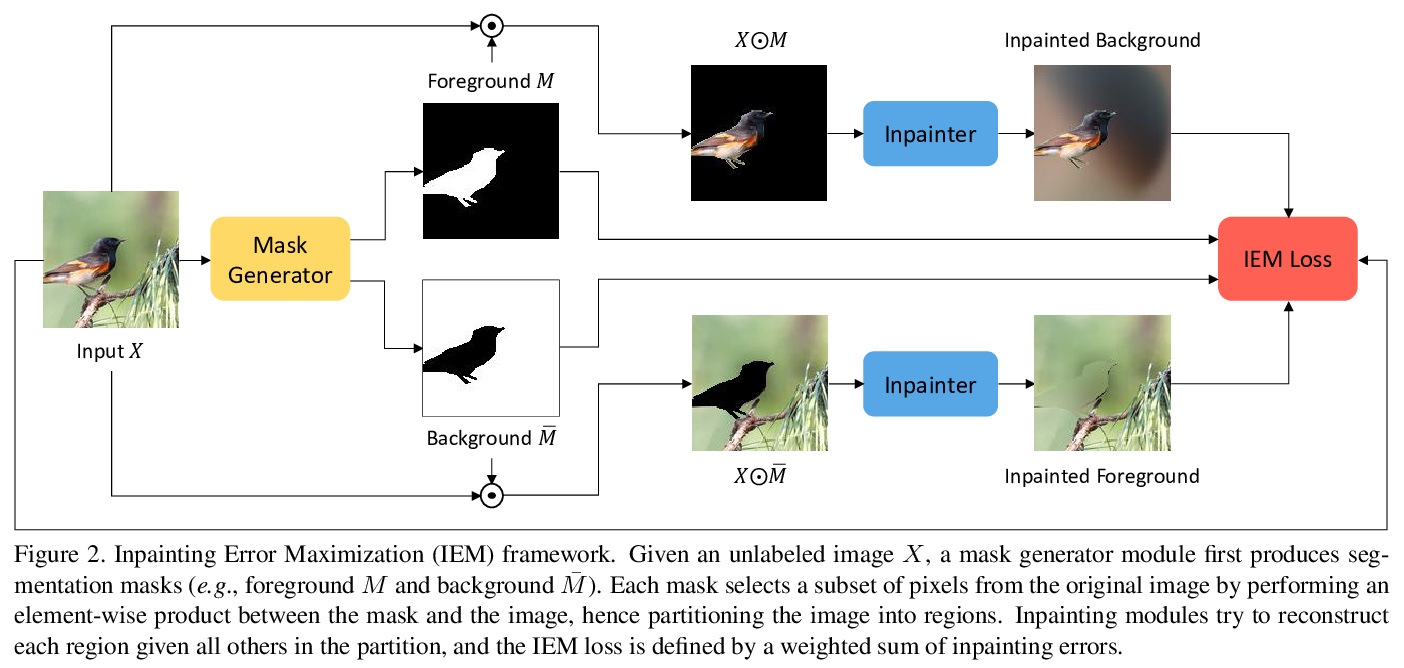
基于补全误差最大化的信息论图像分割方法。从信息论角度研究图像分割,提出一种新的对抗式方法,通过将图像分割成最大限度的独立集,来进行无监督分割。将图像像素分为前景和背景,目标是最小化从一个集到另一个集的可预测性。采用由易计算的损失驱动的贪婪搜索过程,在这些区域上最大化补全误差。该方法不需要训练深度网络,计算成本低,无需知道目标分类,可单独用于一张未标记图像。实验表明,在无监督分割质量方面,达到了新的最先进水平,同时比其他方法更快、更通用。
We study image segmentation from an information-theoretic perspective, proposing a novel adversarial method that performs unsupervised segmentation by partitioning images into maximally independent sets. More specifically, we group image pixels into foreground and background, with the goal of minimizing predictability of one set from the other. An easily computed loss drives a greedy search process to maximize inpainting error over these partitions. Our method does not involve training deep networks, is computationally cheap, class-agnostic, and even applicable in isolation to a single unlabeled image. Experiments demonstrate that it achieves a new state-of-the-art in unsupervised segmentation quality, while being substantially faster and more general than competing approaches.
https://weibo.com/1402400261/JByLj9UyQ

3、[CL] Studying Strategically: Learning to Mask for Closed-book QA
Q Ye, B Z. Li, S Wang, B Bolte, H Ma, X Ren, W Yih, M Khabsa
[University of Southern California & MIT CSAIL & Facebook AI]
策略性学习:闭卷QA中的掩蔽学习。提出一种简单直观的方法,在中级预训练时,将任务相关知识编码到语言模型。该方法类似于学生准备闭卷考试的方式:提前阅读书籍(在维基百科上进行预训练),弄清楚哪些内容可能会出现在考试中,并专注于这些内容(通过掩蔽任务相关的范围)。通过训练掩蔽策略,利用下游任务本身的监督,来提取可能被测试的范围,在中级预训练期间部署学到的策略,将与任务相关的知识集成到语言模型的参数中。
Closed-book question-answering (QA) is a challenging task that requires a model to directly answer questions without access to external knowledge. It has been shown that directly fine-tuning pre-trained language models with (question, answer) examples yields surprisingly competitive performance, which is further improved upon through adding an intermediate pre-training stage between general pre-training and fine-tuning. Prior work used a heuristic during this intermediate stage, whereby named entities and dates are masked, and the model is trained to recover these tokens. In this paper, we aim to learn the optimal masking strategy for the intermediate pretraining stage. We first train our masking policy to extract spans that are likely to be tested, using supervision from the downstream task itself, then deploy the learned policy during intermediate pre-training. Thus, our policy packs task-relevant knowledge into the parameters of a language model. Our approach is particularly effective on TriviaQA, outperforming strong heuristics when used to pre-train BART.
https://weibo.com/1402400261/JByQkBJhB

4、[CV] NeuralMagicEye: Learning to See and Understand the Scene Behind an Autostereogram
Z Zou, T Shi, Y Yuan, Z Shi
[University of Michigan & NetEase Fuxi AI Lab & Beihang University]
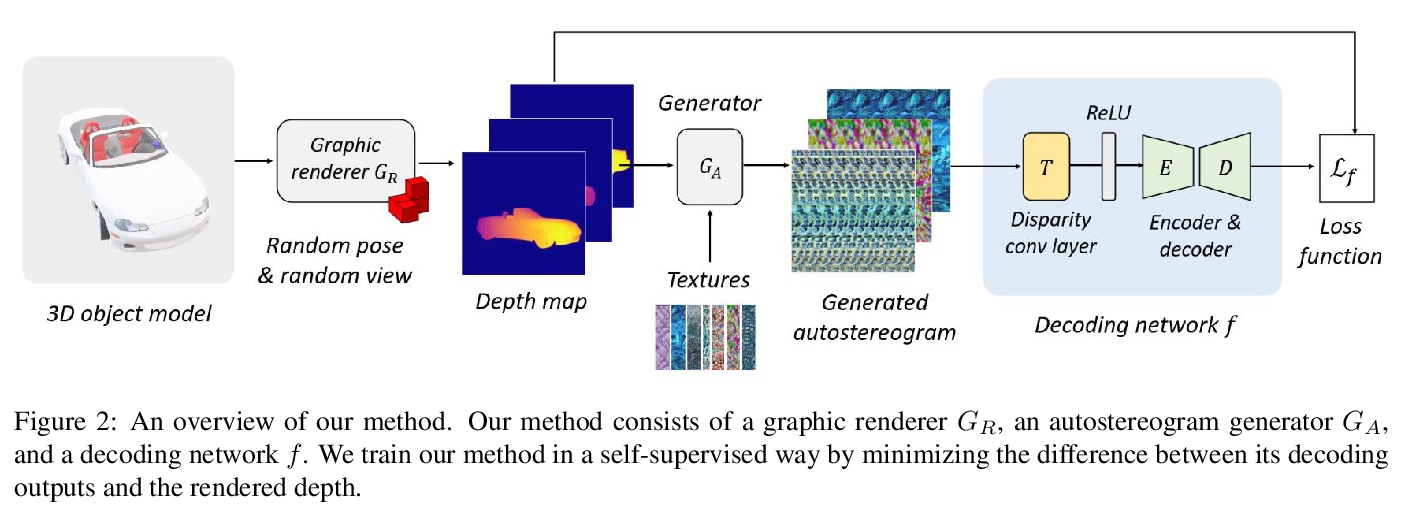
立体图学习及其场景理解。提出了NeuralMagicEye,一种基于深度网络的方法,用于感知和理解立体图背后的场景。在自监督学习方式下,在一个大型3D物体数据集上训练网络,结果显示出良好的鲁棒性,解码精度好于其他方法。提出一种新的卷积形式——视差卷积,可大大提高深度CNN的立体图解码精度。实验同时还显示,神经网络感知立体图深度的方式与人眼不同。
An autostereogram, a.k.a. magic eye image, is a single-image stereogram that can create visual illusions of 3D scenes from 2D textures. This paper studies an interesting question that whether a deep CNN can be trained to recover the depth behind an autostereogram and understand its content. The key to the autostereogram magic lies in the stereopsis - to solve such a problem, a model has to learn to discover and estimate disparity from the quasi-periodic textures. We show that deep CNNs embedded with disparity convolution, a novel convolutional layer proposed in this paper that simulates stereopsis and encodes disparity, can nicely solve such a problem after being sufficiently trained on a large 3D object dataset in a self-supervised fashion. We refer to our method as ``NeuralMagicEye’’. Experiments show that our method can accurately recover the depth behind autostereograms with rich details and gradient smoothness. Experiments also show the completely different working mechanisms for autostereogram perception between neural networks and human eyes. We hope this research can help people with visual impairments and those who have trouble viewing autostereograms. Our code is available at \url{> this https URL}.
https://weibo.com/1402400261/JByWc6nOd
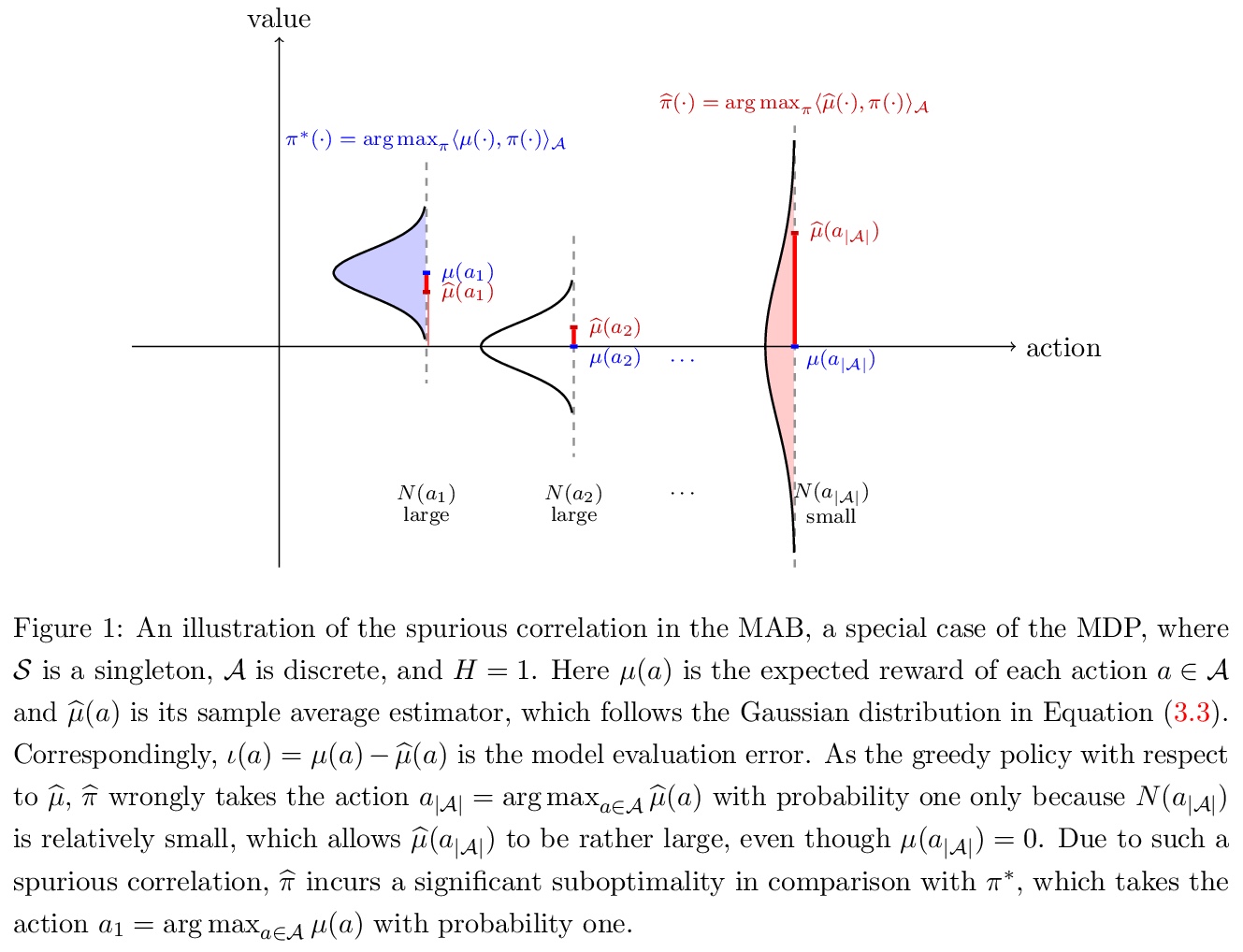
5、[LG] Is Pessimism Provably Efficient for Offline RL?
Y Jin, Z Yang, Z Wang
[Stanford University & Princeton University & Northwestern University]
悲观对离线强化学习可证有效吗?提出一种价值迭代算法的悲观变体(PEVI),加入了一个不确定性量化器作为惩罚函数,这样的惩罚函数只是简单地翻转用于促进在线强化学习的探索函数的符号,这使得它很容易实现,并与一般函数逼近器兼容。在不假设数据集的充分覆盖率的情况下,建立了对一般马尔科夫决策过程(MDPs)的PEVI次优性数据依赖性上界。当专门针对线性MDPs时,与信息理论下限相匹配。悲观不仅被证明是有效的,而且是极小极大最优的。
We study offline reinforcement learning (RL), which aims to learn an optimal policy based on a dataset collected a priori. Due to the lack of further interactions with the environment, offline RL suffers from the insufficient coverage of the dataset, which eludes most existing theoretical analysis. In this paper, we propose a pessimistic variant of the value iteration algorithm (PEVI), which incorporates an uncertainty quantifier as the penalty function. Such a penalty function simply flips the sign of the bonus function for promoting exploration in online RL, which makes it easily implementable and compatible with general function approximators.Without assuming the sufficient coverage of the dataset, we establish a data-dependent upper bound on the suboptimality of PEVI for general Markov decision processes (MDPs). When specialized to linear MDPs, it matches the information-theoretic lower bound up to multiplicative factors of the dimension and horizon. In other words, pessimism is not only provably efficient but also minimax optimal. In particular, given the dataset, the learned policy serves as the best effort'' among all policies, as no other policies can do better. Our theoretical analysis identifies the critical role of pessimism in eliminating a notion of spurious correlation, which emerges from theirrelevant’’ trajectories that are less covered by the dataset and not informative for the optimal policy.
https://weibo.com/1402400261/JBz0DeIPa
另外几篇值得关注的论文:
[LG] Combinatorial Pure Exploration with Full-bandit Feedback and Beyond: Solving Combinatorial Optimization under Uncertainty with Limited Observation
具有Full-bandit反馈的组合性纯探索:用有限观测值求解不确定性下的组合优化
Y Kuroki, J Honda, M Sugiyama
[The University of Tokyo]
https://weibo.com/1402400261/JBz8ps63r
[CL] Linguistic calibration through metacognition: aligning dialogue agent responses with expected correctness
通过元认知进行语言校准:对话主体回答与预期正确性的对齐
S J. Mielke, A Szlam, Y Boureau, E Dinan
[Johns Hopkins University & Facebook AI Research]
https://weibo.com/1402400261/JBz9yAqoR
[CL] Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection
从最差中学习:动态生成数据集以改进在线仇恨检测
B Vidgen, T Thrush, Z Waseem, D Kiela
[The Alan Turing Institute & Simon Fraser University & Facebook AI Research]
https://weibo.com/1402400261/JBzbx2eUH
[CV] Sparse Signal Models for Data Augmentation in Deep Learning ATR
深度学习自动目标识别数据增强的稀疏信号模型
T Agarwal, N Sugavanam, E Ertin
[The Ohio State University]
https://weibo.com/1402400261/JBzdzugA3


若有收获,就点个赞吧
0 人点赞
